文章目录
-
- 前言
- 一、多任务的概念
- 二、进程的概念
- 三、多进程完成多任务
- 四、获取进程编号
- 五、进程应用注意点
- 六、线程的概念
- 七、多线程完成多任务
- 八、进程和线程对比
- 九、协程
-
- 1、协程的定义与优势
- 2、协程适用场景
- [3、Python 协程的实现方式](#3、Python 协程的实现方式)
- [5、协程爬虫(结合 aiohttp )](#5、协程爬虫(结合 aiohttp ))
- 6、协程爬虫综合应用
- 结语
前言
在日常开发中,"让程序同时干多件事" 是提升效率的核心需求 ------ 比如一边下载文件一边处理数据,或是批量爬取网页。Python 提供了进程、线程、协程三种多任务实现方式,它们各有适用场景与优劣。本文从基础概念出发,结合代码实例拆解这三种技术的用法、注意事项与实战场景,帮你掌握 Python 多任务编程的核心逻辑。
一、多任务的概念
1、什么是多任务?
在日常生活中,多任务的场景无处不在,比如在电脑运行时,你可以同时打开浏览器查资料、用微信聊天、用播放器听音乐等等。而在程序开发中,"多任务"就是让程序同时执行多个任务,从而提高程序的执行效率,提升资源利用率。
多任务是指在同一时间内,程序能够处理多个独立的任务。从用户视角来看,这些任务似乎是"同时进行"的;从技术视角看,多任务的实现依赖于操作系统对CPU等资源的调度。需要注意的是,对于单CPU核心来说,真正的"同时执行"是不存在的,操作系统会快速切换多任务的执行权,由于切换速度极快(一般为毫秒级),用户就会产生"多个任务同时运行"的错觉。
2、多任务的两种表现形式
多任务主要有两种核心表现形式,分别对应不同的资源调度策略:
- 并发:多个任务在"同一时间段内"交替执行。比如单CPU核心下,操作系统快速切换"下载文档"和"编辑文档"两个任务,每个任务执行一小段时间后暂停,切换到另一个任务继续执行。从宏观上看,两个任务在同一时间段内都在推进,但微观上是交替执行的。
- 并行:多个任务在"同一时刻"真正同时执行。这需要依赖多CPU核心,比如电脑有两个CPU核心,一个核心专门执行"下载文件"任务,另一个核心专门执行"编辑文档"任务,两个任务在同一时刻都在运行,是真正的同时执行。
简单总结:并发是"交替执行",并行是"同时执行";并发可以在单CPU核心实现,并发必须依赖多CPU核心。
二、进程的概念
1、程序中实现多任务的方式
在Python中,实现多任务的核心有三种:进程。线程、协程。其中,进程是操作系统进行资源分配和调度的基本单位,也是实现多任务的最基础方式。通过创建多个进程,操作系统会为每个进程分配独立的内存空间、CPU时间片等资源,让多个进程交替或同时执行,从而实现多任务。
2、进程的概念
进程可以理解为"正在运行的程序实例"。当我们双击打开一个软件(比如微信),操作系统会加载该软件的代码到内存中,创建一个对应的进程,然后CPU开始执行进程中的代码。一个程序可以对应多个进程,比如同时打开两个微信窗口,操作系统会创建两个微信进程,每个进程拥有独立的内存空间,互不干扰。
进程的核心特点:每个进程都有独立的内存空间和系统资源,进程之间的资源不共享,通信需要通过特定的机制(如管道、队列、共享内存等)。
3、多进程的作用
多进程的核心作用是让程序能够并行处理多个任务,提升执行效率。
下面通过对比"未使用多进程"和"使用多进程"的代码实例,来感受多进程的优势。
- 未使用多进程(单进程)
- 单进程模式下,任务只能顺序执行,耗时等于所有任务耗时之和。
python
import time
# 定义任务1:模拟下载文件
def download_file(file_name, cost_time):
print(f"开始下载{file_name}...")
time.sleep(cost_time) # 模拟下载耗时
print(f"{file_name}下载完成!")
# 单进程执行两个下载任务
if __name__ == "__main__":
start_time = time.time() # 记录开始时间
# 顺序执行两个任务
download_file("文件A", 3) # 耗时3秒
download_file("文件B", 4) # 耗时4秒
end_time = time.time() # 记录结束时间
print(f"总耗时:{end_time - start_time:.2f}秒")运行结果如下:

单进程顺序执行,总耗时=7秒。
- 使用多进程
使用多进程时,两个任务可以同时执行(并发或并行),总耗时等于耗时最长的任务耗时。Python中可以通过multiprocessing模块创建多进程。
python
import time
from multiprocessing import Process # 导入Process类
# 定义任务1:模拟下载文件
def download_file(file_name, cost_time):
print(f"开始下载{file_name}...")
time.sleep(cost_time) # 模拟下载耗时
print(f"{file_name}下载完成!")
# 多进程执行两个下载任务
if __name__ == "__main__":
start_time = time.time()
# 1. 创建进程对象:target指定任务函数,args指定任务参数(元组形式)
p1 = Process(target=download_file, args=("文件A", 3))
p2 = Process(target=download_file, args=("文件B", 4))
# 2. 启动进程
p1.start()
p2.start()
# 3. 等待进程执行完成(主进程阻塞,直到子进程结束)
p1.join()
p2.join()
end_time = time.time()
print(f"总耗时:{end_time - start_time:.2f}秒")运行结果如下:

多进程并行执行,总耗时4秒(等于耗时最长的任务),效率大幅度提升。
三、多进程完成多任务
1、多进程完成多任务的核心逻辑
多进程完成多任务的核心步骤:
- 定义需要执行的任务函数;
- 通过Process类创建多个进程对象,每个进程对象绑定一个任务;
- 调用进程对象的start()方法启动进程;
- (可选)调用join()方法让主进程等待子进程执行完成,避免主进程提前结束。
2、通过进程类创建进程对象
Process类的核心参数说明:
- target:指定进程要执行的任务函数(不需要加括号);
- args:指定任务函数的参数,必须是元组(tuple)类型,即使只有一个参数,也要加逗号(如args=(10,));
- name:指定进程的名称(可选,默认是Process-1、Process-2...)。
基础示例(创建3个进程执行不同任务):
python
import time
from multiprocessing import Process
# 任务1:打印数字
def print_numbers(name, count):
for i in range(count):
print(f"{name}: {i}")
time.sleep(0.5)
# 任务2:打印字母
def print_letters(name, count):
for i in range(count):
print(f"{name}: {chr(65 + i)}") # 65是'A'的ASCII码
time.sleep(0.5)
if __name__ == "__main__":
# 创建3个进程
p1 = Process(name="数字进程", target=print_numbers, args=("数字进程", 3))
p2 = Process(name="字母进程1", target=print_letters, args=("字母进程1", 3))
p3 = Process(name="字母进程2", target=print_letters, args=("字母进程2", 3))
# 启动所有进程
p1.start()
p2.start()
p3.start()
# 等待所有进程结束
p1.join()
p2.join()
p3.join()
print("所有任务执行完成!")运行结果如下:

3、进程执行带有参数的任务
当任务函数需要接收参数时,通过Process类的args参数传递,注意参数必须是元组类型。下面是一个更具体的示例:模拟多人同时下载不同大小的文件。
python
import time
from multiprocessing import Process
# 任务函数:模拟下载文件,参数为用户名、文件名、文件大小(决定下载耗时)
def download(user, file_name, file_size):
print(f"{user}开始下载{file_name}(大小:{file_size}MB)...")
# 假设1MB需要1秒下载时间
time.sleep(file_size)
print(f"{user}的{file_name}下载完成!")
if __name__ == "__main__":
# 创建4个进程,执行不同参数的下载任务
tasks = [
("用户A", "电影.mp4", 5),
("用户B", "文档.pdf", 2),
("用户C", "图片.png", 1),
("用户D", "音乐.mp3", 3)
]
# 存储所有进程对象
processes = []
for task in tasks:
# 解包元组,分别赋值给三个变量user, file_name, size
user, file_name, size = task
p = Process(target=download, args=(user, file_name, size))
processes.append(p)
p.start()
# 等待所有进程完成
for p in processes:
p.join()
print("所有用户下载任务完成!")运行结果如下:
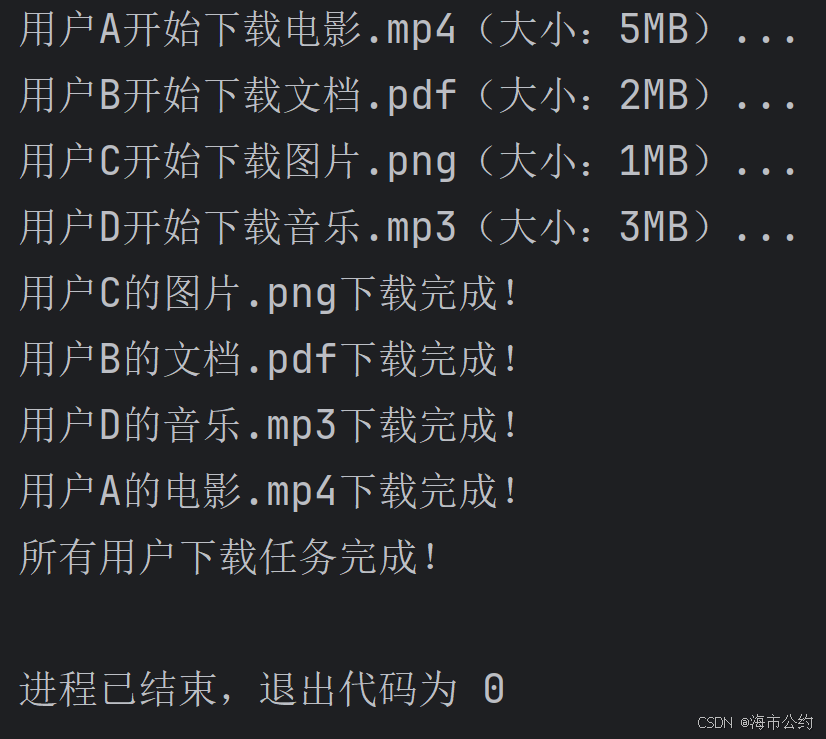
四、获取进程编号
1、进程编号的作用
进程编号(PID)是操作系统为每个进程分配的唯一标识,用于区分不同的进程。其核心作用包括:
- 定位和管理进程(如通过PID终止异常进程);
- 实现进程间的通信和同步(如通过PID识别通信对象);
- 调试程序(如查看哪个进程出现问题)。
2、两种进程编号
- 当前进程编号(PID):当前进程的唯一标识;
- 父进程编号(PPID):当前进程的父进程(创建当前进程的进程)的唯一标识。
比如在Python程序中,主进程创建的子进程,子进程的PPID就是主进程的PID。
3、获取当前进程编号
Python中获取进程编号需要用到两个模块:
- os模块:通过os.getpid()获取当前进程PID,os.getppid()获取父进程PPID;
- multiprocessing模块:通过current_process()获取当前进程对象,再通过pid属性获取PID。
代码示例:
python
import os
import time
from multiprocessing import Process, current_process
# 任务函数:打印当前进程信息
def task(name):
# 方式1:通过os模块获取
pid = os.getpid()
ppid = os.getppid()
print(f"任务{name} - PID:{pid},PPID:{ppid}(os模块)")
# 方式2:通过current_process()获取
current_proc = current_process()
print(f"任务{name} - 进程名:{current_proc.name},PID:{current_proc.pid}(multiprocessing模块)")
time.sleep(2)
if __name__ == "__main__":
# 打印主进程信息
main_pid = os.getpid()
print(f"主进程 - PID:{main_pid}")
# 创建两个子进程
p1 = Process(name="子进程1", target=task, args=("A",))
p2 = Process(name="子进程2", target=task, args=("B",))
p1.start()
p2.start()
p1.join()
p2.join()
print("主进程结束!")运行结果如下(PID为随机分配,每次运行结果不经相同):
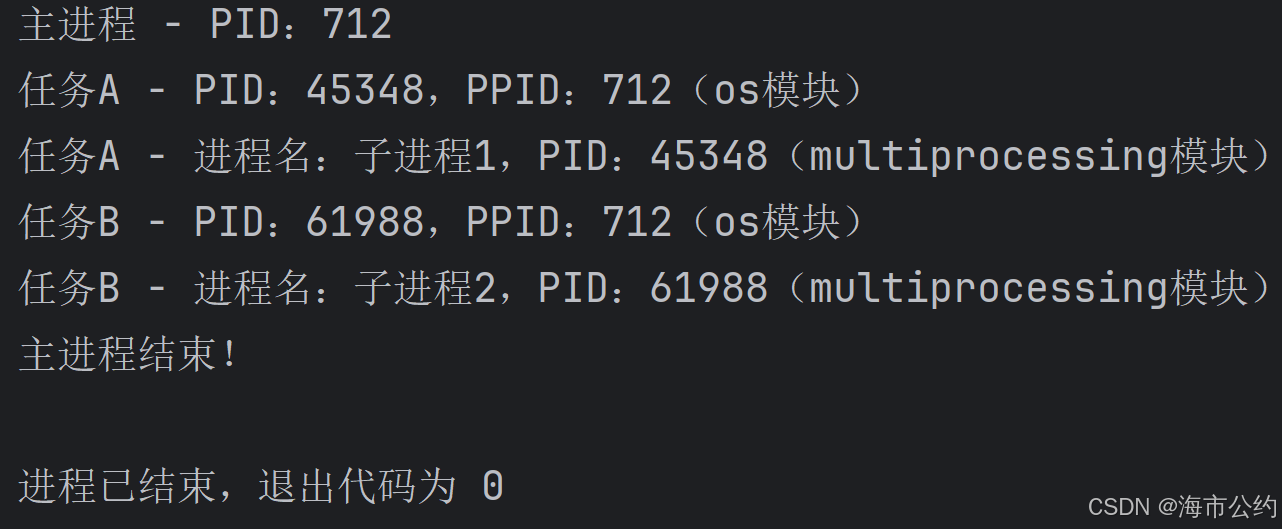
五、进程应用注意点
1、进程间不共享全局变量
每个进程都有独立的内存空间,因此进程之间的全局变量是不共享的。也就是说,在主进程中定义的全局变量,子进程对其修改不会影响主进程中的变量,反之亦然。这是进程的核心特性,也是与线程的重要区别。
示例验证:
python
from multiprocessing import Process
# 定义全局变量
global_num = 0
# 任务函数:修改全局变量
def modify_global():
global global_num # 声明使用全局变量
for i in range(1000000):
global_num += 1
print(f"子进程修改后:global_num = {global_num}")
if __name__ == "__main__":
# 创建子进程
p = Process(target=modify_global)
p.start()
p.join() # 等待子进程修改完成
# 主进程打印全局变量
print(f"主进程中:global_num = {global_num}")运行结果:
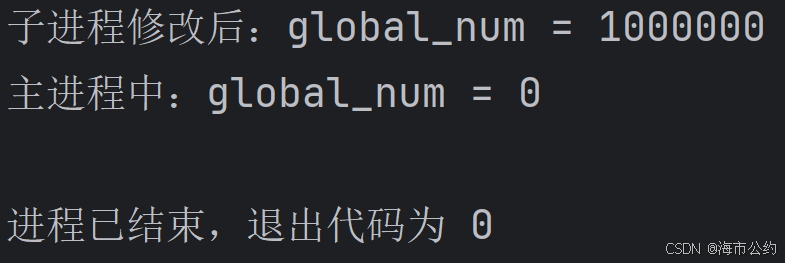
结论:子进程修改的是自己内存空间中的"全局变量副本",主进程中的全局变量并未改变,进程间不共享全局变量。如果需要实现进程间数据共享,需要使用multiprocessing模块提供的Queue(队列)、Pipe(管道)、Manager(管理器)等机制。
2、主进程与子进程的结束顺序
默认情况下,主进程会等待所有子进程执行完成后才会结束,但有时我们需要让主进程结束时,子进程也随之结束(比如主进程是一个监控程序,主进程退出后,子进程无需继续运行)。此时有两种解决方案:设置守护进程、主动销毁子进程。
解决方案一:设置守护进程
通过设置进程对象的daemon属性为True,可以将该进程设置为"守护进程"。守护进程的特点是:主进程结束时,守护进程会被强制终止,无论是否执行完成。
注意:daemon属性必须在start()方法调用前设置。
python
import time
from multiprocessing import Process
# 任务函数:模拟长时间运行
def long_task():
while True:
print("子进程正在运行...")
time.sleep(1)
if __name__ == "__main__":
# 创建子进程,设置为守护进程
p = Process(target=long_task)
p.daemon = True # 必须在start()前设置
p.start()
# 主进程运行3秒后结束
time.sleep(3)
print("主进程结束,守护子进程被强制终止!")运行结果:

解决方案二:销毁子进程
通过调用进程对象的terminate()方法,可以主动销毁子进程。这种方式适合需要灵活控制子进程生命周期的场景(比如根据特定条件终止子进程)。
python
import time
from multiprocessing import Process
# 任务函数:模拟运行
def task():
i = 0
while True:
print(f"子进程运行中,i = {i+1}")
i += 1
time.sleep(1)
if __name__ == "__main__":
p = Process(target=task)
p.start()
# 主进程运行3秒后,主动销毁子进程
time.sleep(3)
p.terminate() # 销毁子进程
print("主进程主动销毁子进程!")
print("主进程结束!")
六、线程的概念
1、线程的概念
线程是进程内部的一个"执行单元",是操作系统进行任务调度的最小单位。一个进程可以包含多个线程,这些线程共享进程的内存空间和系统资源(如文件描述符、网络连接等),线程之间的通信比进程更高效(直接访问共享内存即可)。
2、 为什么使用多线程?
虽然多进程也能实现多任务,但多线程有以下核心优势,使其在很多场景下更适合:
- 资源消耗更少:创建一个线程的资源消耗远小于创建一个进程(线程共享进程资源,无需单独分配一个内存空间);
- 通信更高效:线程之间共享全局变量,无需使用复杂的进程间通信机制;
- 切换速度更快:线程是操作系统调度的最小单位,切换线程的开销比切换进程小得多。
多线程的适用场景:IO密集型任务(如文件读写、网络请求、数据库操作等),这类任务的大部分时间都是在等待IO完成,多线程可以在一个线程等待IO时,切换到另一个线程执行,提升CPU利用率。
3、多线程的作用
多线程的核心作用是在同一个进程内实现多个任务的并发执行,提升程序的执行效率,尤其是在IO密集型场景下。下面通过对比"单线程执行"和"多线程执行"的代码实例,直观感受多线程的优势。
单线程执行
单线程模式下,任务顺序执行,总耗时等于所有任务耗时之和。
python
import time
# 任务1:模拟网络请求
def request_url(url, cost_time):
print(f"开始请求{url}...")
time.sleep(cost_time) # 模拟网络等待时间
print(f"{url}请求完成!")
# 单线程执行三个网络请求
if __name__ == "__main__":
start_time = time.time()
request_url("https://www.baidu.com", 2)
request_url("https://www.qq.com", 3)
request_url("https://www.163.com", 1)
end_time = time.time()
print(f"总耗时:{end_time - start_time:.2f}秒")运行结果如下:

多线程执行
Python中实现多线程主要使用threading模块,核心类是Thread。多线程执行时,任务并发执行,总耗时等于最长的任务耗时。
python
import time
from threading import Thread # 导入Thread类
# 任务1:模拟网络请求
def request_url(url, cost_time):
print(f"开始请求{url}...")
time.sleep(cost_time) # 模拟网络等待时间
print(f"{url}请求完成!")
# 多线程执行三个网络请求
if __name__ == "__main__":
start_time = time.time()
# 1. 创建线程对象
t1 = Thread(target=request_url, args=("https://www.baidu.com", 2))
t2 = Thread(target=request_url, args=("https://www.qq.com", 3))
t3 = Thread(target=request_url, args=("https://www.163.com", 1))
# 2. 启动线程
t1.start()
t2.start()
t3.start()
# 3. 等待线程执行完成
t1.join()
t2.join()
t3.join()
end_time = time.time()
print(f"总耗时:{end_time - start_time:.2f}秒")运行结果如下:
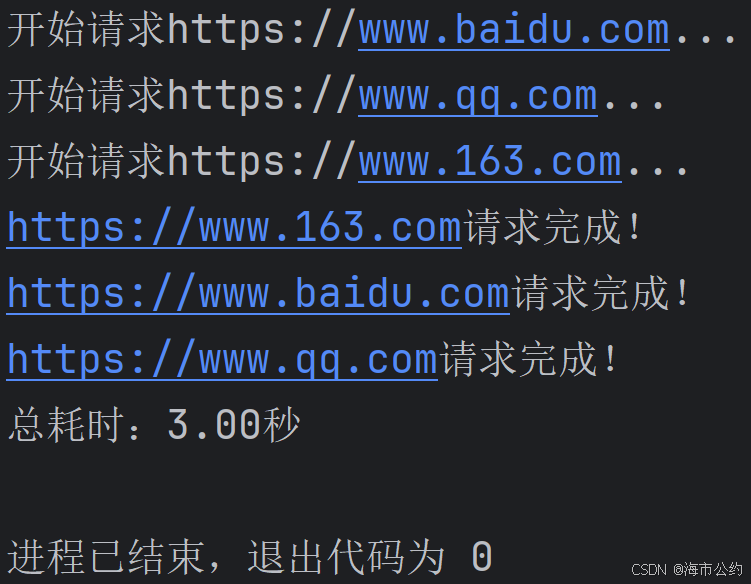
七、多线程完成多任务
1、多线程完成多任务的核心逻辑
多线程完成多任务的步骤与多进程类似:
- 定义任务函数;
- 通过Thread类创建多个线程对象,绑定任务和参数;
- 调用start()方法启动线程;
- (可选)调用join()方法让主线程等待子线程完成。
2、线程创建与启动代码
Thread类的核心参数与Process类相似:
- target:指定线程要执行的任务函数;
- args:指定任务函数的参数,元组类型;
- name:指定线程名称(可选);
基础示例(创建多个线程执行不同任务):
python
import time
from threading import Thread
# 任务1:打印时间
def print_time(name, interval):
"""
打印指定名称的当前时间,并按照指定间隔重复打印
参数:
name (str): 打印时间时显示的名称前缀
interval (int/float): 打印时间的间隔(秒)
"""
while True: # 无限循环,持续打印时间
print(f"{name}:{time.strftime('%H:%M:%S', time.localtime())}") # 格式化并打印当前时间
time.sleep(interval) # 暂停指定秒数后继续执行
# 任务2:计数
def count_numbers(name, max_count):
for i in range(max_count):
print(f"{name}:{i}")
time.sleep(1)
if __name__ == "__main__":
# 创建线程
t1 = Thread(name="时间线程", target=print_time, args=("时间线程", 2))
t2 = Thread(name="计数线程", target=count_numbers, args=("计数线程", 5))
# 启动线程
t1.start()
t2.start()
# 等待计数线程完成
t2.join()
# 计数线程完成后,终止时间线程(通过设置全局变量控制)
print("计数线程完成,程序结束!")3、线程执行带有参数的任务
线程执行带有参数的任务,与进程类似,通过args参数传递元组类型的参数。下面示例模拟多线程下载不同类型的文件:
python
import time
from threading import Thread
# 任务函数:模拟下载,参数为文件类型、文件数量、单个文件耗时
def download_files(file_type, count, cost_per):
for i in range(1, count + 1):
print(f"开始下载{file_type}{i},预计耗时{cost_per}秒...")
time.sleep(cost_per)
print(f"{file_type}{i}下载完成!")
if __name__ == "__main__":
# 定义任务列表
tasks = [
("图片", 3, 1), # 下载3张图片,每张1秒
("视频", 2, 3), # 下载2个视频,每个3秒
("文档", 4, 0.5) # 下载4个文档,每个0.5秒
]
# 存储线程对象
threads = []
for task in tasks:
file_type, count, cost = task
t = Thread(target=download_files, args=(file_type, count, cost))
threads.append(t)
t.start()
# 等待所有线程完成
for t in threads:
t.join()
print("所有文件下载完成!")运行结果如下:

4、主线程和子线程的结束顺序
默认情况下,主线程会等待所有子线程执行完成后才会结束。如果需要主线程结束时子线程也随之结束,可以通过"全局变量控制"或"守护线程"实现。
守护线程
与进程类似,线程也可以设置守护线程,通过daemon属性设置(必须在start()前设置)。主线程结束时,守护线程会被强制终止。
python
import time
from threading import Thread
def task():
while True:
print("子线程运行中...")
time.sleep(1)
if __name__ == "__main__":
t = Thread(target=task)
t.daemon = True # 设置为守护线程
t.start()
# 主线程运行3秒后结束
time.sleep(3)
print("主线程结束,守护子线程被终止!")运行结果如下:

全局变量控制
通过定义一个全局变量(如running),控制子线程的循环执行。主线程需要结束时,修改全局变量的值,子线程检测到后主动退出。这种方式比守护线程更优雅,可以让子线程在退出前完成收尾工作。
python
import time
from threading import Thread
# 全局变量:控制子线程运行状态
running = True
def task():
while running:
print("子线程运行中...")
time.sleep(1)
print("子线程检测到退出信号,正在收尾...")
time.sleep(2)
print("子线程收尾完成,退出!")
if __name__ == "__main__":
t = Thread(target=task)
t.start()
# 主线程运行3秒后,修改全局变量
time.sleep(3)
running = False
print("主线程发出退出信号!")
# 等待子线程完成收尾
t.join()
print("主线程结束!")运行结果如下:

5、线程间的执行顺序
获取当前线程信息
通过threading.current_thread()可以获取当前正在执行的线程对象,进而获取线程名称、线程ID等信息。
python
import time
from threading import Thread, current_thread
def task(name):
print(f"当前线程:{current_thread().name},线程ID:{current_thread().ident}")
time.sleep(1)
if __name__ == "__main__":
print(f"主线程:{current_thread().name},线程ID:{current_thread().ident}")
t1 = Thread(name="子线程1", target=task, args=("子线程1",))
t2 = Thread(name="子线程2", target=task, args=("子线程2",))
t1.start()
t2.start()
t1.join()
t2.join()运行结果如下:

线程间的执行顺序
线程的执行顺序由操作系统的调度器决定,是不确定的(即"抢占式调度")。也就是说,多个线程启动后,哪个线程先执行、执行多长时间,都是由操作系统决定的,程序无法直接控制。
验证示例:
python
import time
from threading import Thread
def task(name):
for i in range(3):
print(f"{name}:{i}")
time.sleep(0.1) # 短暂休眠,让线程切换更明显
if __name__ == "__main__":
t1 = Thread(name="线程A", target=task, args=("线程A",))
t2 = Thread(name="线程B", target=task, args=("线程B",))
t1.start()
t2.start()
t1.join()
t2.join()运行结果(每次可能不同):
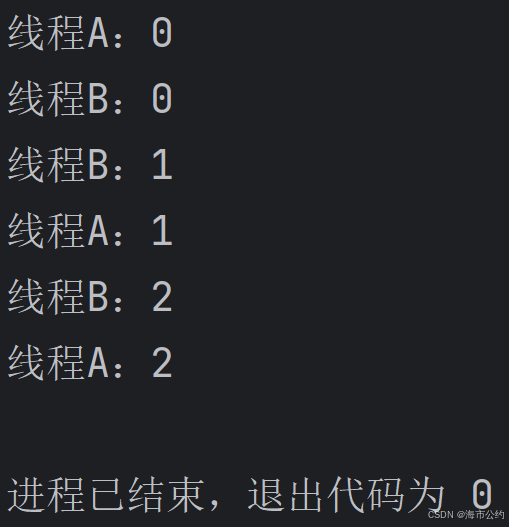
结论:线程间的执行顺序是随机的,是由操作系统调度决定。如果需要线程按特定顺序执行,需要使用同步机制(如锁、条件变量等)。
6、线程间共享全局变量
与进程不同,线程之间共享进程的内存空间,因此全局变量是共享的。也就是说,一个线程修改全局变量后,其他线程可以看到修改后的结果。
示例:
python
import time
from threading import Thread
# 全局变量
global_num = 0
# 任务函数:修改全局变量
def add_num():
global global_num
for i in range(1000000):
global_num += 1
if __name__ == "__main__":
# 创建两个线程,同时修改全局变量
t1 = Thread(target=add_num)
t2 = Thread(target=add_num)
t1.start()
t2.start()
t1.join()
t2.join()
print(f"最终global_num的值:{global_num}")
运行结果可能不是2000000。
说明:两个线程同时修改全局变量,由于global_num += 1不是原子操作(分为"读取-修改-写入"三步),会导致"竞态条件",最终结果小于预期的2000000。这就是线程安全问题,解决方法是使用"锁"(threading.Lock)保证同一时间只有一个线程修改变量。
修复后的代码:
python
import time
from threading import Thread, Lock
# 全局变量
global_num = 0
# 创建锁对象
lock = Lock()
# 任务函数:修改全局变量(加锁)
def add_num():
global global_num
for i in range(1000000):
lock.acquire() # 上锁:获取锁,若锁被占用则阻塞
global_num += 1
lock.release() # 解锁:释放锁,让其他线程可以获取
if __name__ == "__main__":
t1 = Thread(target=add_num)
t2 = Thread(target=add_num)
t1.start()
t2.start()
t1.join()
t2.join()
print(f"最终global_num的值:{global_num}") # 输出2000000
八、进程和线程对比
1、关系对比
- 一个进程可以包含多个线程,线程是进程的组成部分;
- 线程共享进程的内存空间和系统资源,进程之间资源独立;
- 进程是操作系统资源分配的基本单位,线程是操作系统调度的基本单位;
- 进程退出时,其内部的所有线程都会被强制终止;线程退出不会影响其他线程和进程。
2、区别对比
| 对比维度 | 进程 | 线程 |
|---|---|---|
| 资源分配 | 独立内存空间、系统资源 | 共享进程的资源 |
| 通信方式 | 需要使用队列、管道等机制,复杂 | 共享全局变量,简单高效 |
| 创建/切换开销 | 大 | 小 |
| 线程安全 | 无线程安全问题(资源独立) | 存在线程安全问题(共享资源) |
| 稳定性 | 高(一个进程崩溃不影响其他进程) | 低(一个线程崩溃可能导致整个进程崩溃) |
3、优缺点对比
进程的优缺点
- 优点:稳定性高,资源独立,无线程安全问题;适合CPU密集型任务(多进程可实现并行执行);
- 缺点:创建/切换开销大,通信复杂,资源消耗多。
线程的优缺点
- 优点:创建/切换开销小,通信高效,资源消耗少;适合IO密集型任务;
- 缺点:存在线程安全问题,稳定性低,一个线程崩溃可能导致整个进程崩溃。
九、协程
1、协程的定义与优势
协程的定义
协程也叫微线程、纤程,是一种在单个线程里让多个任务交替执行的编程方式。当一个任务执行到需要等待的步骤时,比如发起网络请求后等服务器回复、读文件时等磁盘数据,这个任务会主动把 CPU 的执行权让出来,让另一个任务继续跑;等原来的任务完成了等待,就会重新拿回执行权,接着从之前暂停的地方继续执行。
简单说,协程就是单线程里的任务切换工具,核心就是不浪费 CPU 的等待时间,让 CPU 一直处于工作状态。
协程的核心优势
和进程、线程比,协程的优势主要在成本、效率、安全性这几个方面,也是它能成为处理等待类任务首选的原因:
- 切换成本特别低:协程的切换是 Python 程序内部控制的,不用操作系统参与,不用保存和恢复进程、线程的运行信息,切换一次的成本只有线程的几百分之一。
- 占用资源极少:所有协程共享一个线程的内存和资源,创建几千个协程的资源消耗,还比不上创建几十个线程的消耗。
- 不用考虑数据安全问题:协程是单线程里串行执行的,同一时间只有一个协程在运行,不会出现多个任务同时修改一个数据的情况,不用像多线程那样加锁保护数据,代码写起来更简单。
- 处理等待类任务效率极高:等待类任务的大部分时间,CPU 都是闲着的,协程通过在等待时切换任务,让 CPU 全程不空闲,处理同样的任务,效率比多线程高很多。
- 代码逻辑更清晰:现在的协程语法和普通的同步代码逻辑差不多,不会出现多线程里嵌套回调函数的复杂情况。
2、协程适用场景
协程不适合处理纯计算的任务,比如大数字运算、数据加密、图片处理这类,因为这类任务会一直占用 CPU,没有等待的步骤,协程没法切换任务,这时用多进程利用多核 CPU 会更合适。
协程最适合的是有大量等待操作的 IO 密集型任务,常见的有:批量爬取网页的网络爬虫、处理高并发请求的 Web 服务、批量操作数据库、批量读写文件、处理消息队列的消息等。
3、Python 协程的实现方式
1、基础语法
python
import asyncio
# 定义⼀个异步协程函数
async def my_coroutine():
"""
⼀个简单的协程函数,⽤于演示asyncio库的基本使⽤。
此函数没有参数和返回值。
"""
print("Start")
await asyncio.sleep(1) # ⾮阻塞式休眠
print("End")
# 运⾏协程
asyncio.run(my_coroutine()) # Python3.7+推荐⽅式2、事件循环与任务创建
python
import asyncio
# 定义⼀个异步任务,该任务会在指定延迟后完成
async def task(name, delay):
"""
异步任务函数,模拟⼀个需要时间完成的任务。
参数:
name: 任务名称,⽤于标识任务。
delay: 延迟时间,任务完成前需要等待的时间(秒)。
"""
await asyncio.sleep(delay) # 模拟任务耗时
print(f"{name} completed")
# 定义主协程,⽤于管理和执⾏其他协程任务
async def main():
"""
主协程函数,负责调度和执⾏多个异步任务。
"""
# 创建任务列表
tasks = [
asyncio.create_task(task("A", 2)), # 创建任务A,延迟2秒完成
asyncio.create_task(task("B", 1)) # 创建任务B,延迟1秒完成
]
await asyncio.gather(*tasks) # 并发执⾏所有任务
# 运⾏主协程
asyncio.run(main())运行结果如下:

4、核⼼模块与API
| 模块/方法 | 作用描述 |
|---|---|
| asyncio.run() | 启动事件循环的入口函数 |
| asyncio.create_task() | 将协程包装为任务对象 |
| asyncio.gather() | 并发执行多个协程 |
| asyncio.sleep() | 非阻塞式等待(替代 time.sleep ) |
| asyncio.Queue | 协程安全队列,用于生产者-消费者模型 |
python
import asyncio # 导入官方的asyncio模块
# 用async def定义协程函数
async def simple_coro():
print("协程开始运行了")
# await后面跟asyncio.sleep,这是异步的休眠,模拟等待操作
await asyncio.sleep(1) # 不能用time.sleep,会阻塞整个线程
print("协程运行完成了")
if __name__ == "__main__":
# 1. 调用协程函数,得到协程对象,不会执行函数体
coro = simple_coro()
print("调用协程函数后,还没执行函数里的代码")
# 2. 用asyncio.run()运行协程对象,这是协程的入口函数
asyncio.run(coro)
运行结果如下:

5、协程爬虫(结合 aiohttp )
爬虫是协程最经典的实战场景,因为爬虫的核心耗时不是代码计算,而是网络请求的等待:向网站服务器发送请求后,需要等服务器返回网页数据,这个过程中 CPU 一直是空闲的。协程可以在等待一个请求的同时,发送其他的请求,实现单线程批量爬取,效率比普通的同步爬虫高很多。
python
import aiohttp
import asyncio
import time
# 异步爬取协程函数
async def async_crawl(url):
print(f"开始爬取:{url}")
# 创建异步会话对象,类似requests的session,推荐复用,减少资源消耗
async with aiohttp.ClientSession() as session:
# 异步发起GET请求,await等待请求完成
async with session.get(url) as response:
# 异步获取网页源码,await等待结果
html = await response.text()
print(f"爬取完成:{url},状态码:{response.status}")
return len(html)
async def main():
# 待爬取的网址
urls = [
"https://www.baidu.com",
"https://www.qq.com",
"https://www.163.com"
]
# 批量创建协程对象
coros = [async_crawl(url) for url in urls]
# 批量并发执行,获取所有结果
results = await asyncio.gather(*coros)
return results
if __name__ == "__main__":
start_time = time.time()
# 运行协程并获取结果
results = asyncio.run(main())
print(f"各网站源码长度:{results}")
print(f"协程爬虫总耗时:{time.time() - start_time:.2f}秒")运行结果如下:
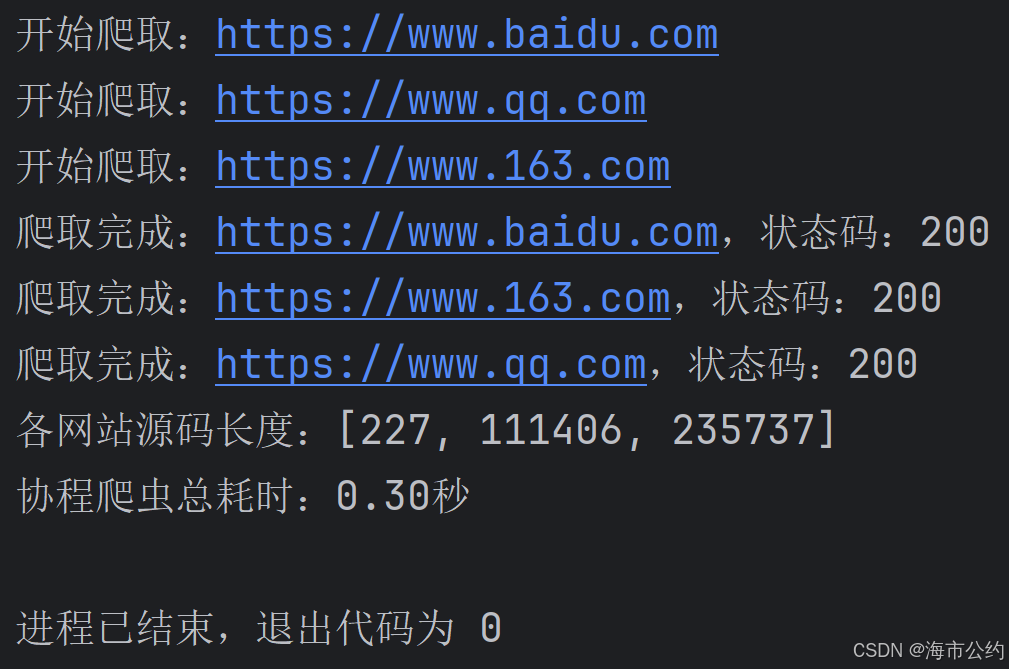
6、协程爬虫综合应用
目的:爬取网站上所有有关于迪丽热巴的图片
python
import requests
# 正则表达式模块
import re
import aiohttp
import aiofiles
import asyncio
async def aio_main():
async with aiohttp.ClientSession() as session:
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Referer": "https://www.baidu.com/",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "same-site",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36 Edg/140.0.0.0",
"sec-ch-ua": "\"Chromium\";v=\"140\", \"Not=A?Brand\";v=\"24\", \"Microsoft Edge\";v=\"140\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\""
}
cookies = {
"BDUSS_BFESS": "ZlRzhySTJzblU0b3hLU1RZMkZRMFhlcjNqUUdsS1dDYXBvZHl3RXVVWUdGVk5tSUFBQUFBJCQAAAAAAQAAAAEAAACPU~OKTEZNd29vAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAaIK2YGiCtmR3",
"BAIDUID": "7F4CD7DD1ECBFC1532A4869435DF5E63:FG=1",
"PSTM": "1760487890",
"BIDUPSID": "A28FE7D64A787D28990CDC0D49C7ECF1",
"BAIDUID_BFESS": "7F4CD7DD1ECBFC1532A4869435DF5E63:FG=1",
"H_WISE_SIDS_BFESS": "110085_652588_653264_656456_658259_660927_667683_669380_669526_670510_673692_674801_672372_675353_675487_675508_675148_675802_675860_676011_675906_676272_666750_676558_676561_675246_675232_676609_676690_676855_676887_677314_677390_677464_677701_677711_677590_677292_677776_678007_678142_678220_678243_678030_672347_675330_678499_678493_678527_678378_678376_678602_678641_678662_678548_678687_678651_678773_678787_678767_678881_678870_678915_679008_679010_678966_679028_678931_678935_679063_679061_679077_679098_679102_679242_678979_679065_679285_679299_679192_679188_679282_676451_678468_679424_679460_679433_679462_679368_679611_675091_677211_673654",
"ZFY": "wqTIA3wcBK:AoNdvIrDPioyXJA1gkGQ6JJU4Pe:AopmEM:C",
"H_PS_PSSID": "64006_66586_66594_66674_66684_66805_66852_67003_67043_67050_67094_67051_67044_67119_67149_66953_67152_67162_67170_67180_67210_67229",
"BA_HECTOR": "ag818g2h242l202521a0a0ag2g2g821klmc8526",
"BDORZ": "FFFB88E999055A3F8A630C64834BD6D0",
"BDRCVFR[qPHJWzYt5q0]": "mk3SLVN4HKm",
"delPer": "0",
"PSINO": "6",
"BCLID": "10591932941755462143",
"BCLID_BFESS": "10591932941755462143",
"BDSFRCVID": "rEDOJexroGWmTkTESnvsuOTVSmKK0gOTDYrE7z5SvfFPejIVvNwYEG0Pt8XCmL8hQ5mfogKKLmOTHPkF_2uxOjjg8UtVJeC6EG0Ptf8g0M5",
"BDSFRCVID_BFESS": "rEDOJexroGWmTkTESnvsuOTVSmKK0gOTDYrE7z5SvfFPejIVvNwYEG0Pt8XCmL8hQ5mfogKKLmOTHPkF_2uxOjjg8UtVJeC6EG0Ptf8g0M5",
"H_BDCLCKID_SF": "JRFD_KLMJID3HnRY-P4_-tAt2qoXetJyaR3HKlbvWJ5WqR7j3PcxMp0k0UTqbbQ9QNcgWlvctn3cShbXKx_b26L95xjlQPQBWGcq2t3w3l02V--9WMbVX5kJ0HoLKtRMW23rWl7mWUJOsxA45J7cM4IseboJLfT-0bc4KKJxbnLWeIJEjj6jK4JKDH0etT5P",
"H_BDCLCKID_SF_BFESS": "JRFD_KLMJID3HnRY-P4_-tAt2qoXetJyaR3HKlbvWJ5WqR7j3PcxMp0k0UTqbbQ9QNcgWlvctn3cShbXKx_b26L95xjlQPQBWGcq2t3w3l02V--9WMbVX5kJ0HoLKtRMW23rWl7mWUJOsxA45J7cM4IseboJLfT-0bc4KKJxbnLWeIJEjj6jK4JKDH0etT5P",
"H_WISE_SIDS": "66586_66594_66674_66684_66852_67003_67050_67094_67051_67119_67149_66953_67152_67162_67170_67180_67210_67229",
"ab_sr": "1.0.1_NGNjOGE2NDc4MTczNTk4M2VmM2U4Y2RkYjQwZWI3MmU0NDM4NmQyMDc0ZDRmYzk2Yzg1ZWE3ZjhhNGUxZGE3ZDU5NTQ2NDkxZDNlNzdjYzBjZjQzMzNlMjY0MmMyYmFjNjBiYjRmMGJkMThlZTg0MDA3OTE5MTI4ZmM3Mjc0YzJiMmJkNjQwZjk0NzA2MDI3OGZkN2RjNmE3MDkxMjhkYg=="
}
url = "https://image.baidu.com/search/index"
params = {
"tn": "baiduimage",
"ps": "1",
"ct": "201326592",
"lm": "-1",
"cl": "2",
"nc": "1",
"ie": "utf-8",
"lid": "ee58b5a000014496",
"dyTabStr": "MTIsMCwzLDEsMiwxMyw3LDYsNSw5",
"word": "迪丽热巴"
}
async with session.get(url, headers=headers, params=params) as response:
response_text = await response.text()
"""
问题:
1、如何从源代码中提取到所有图片的链接
2、如何将所有图片路径中的/u0026改为&
https://img2.baidu.com/it/u=2642808210,2474328228&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=750
https://img2.baidu.com/it/u=2642808210,2474328228/u0026fm=253/u0026fmt=auto/u0026app=138/u0026f=JPEG?w=500 \u0026h=750
"""
img_src = re.findall('"thumburl":"(.*?)"', response_text)
list_data = []
for i in img_src:
new_url = i.replace(r"\u0026", '&')
# res = requests.get(new_url)
a = await down_load(session, new_url)
list_data.append(a)
# index = 1
# for i in img_src:
# new_url = i.replace(r"\u0026", '&')
# res = requests.get(new_url)
# with open(f"img/{index}.png", "wb") as f:
# f.write(res.content)
# index += 1
index = 1
async def down_load(session, url):
global index
async with session.get(url) as res:
context = await res.read()
async with aiofiles.open(f"img/{index}.png", "wb") as f:
await f.write(context)
print(f"{index}下载完成")
index += 1
if __name__ == "__main__":
asyncio.run(aio_main())注:上述的headers、cookies、params这些每个人的电脑上是不同的,可以在百度搜索"迪丽热巴"点击图片,鼠标右键、点击检查、点击网络、选择全部、然后刷新。
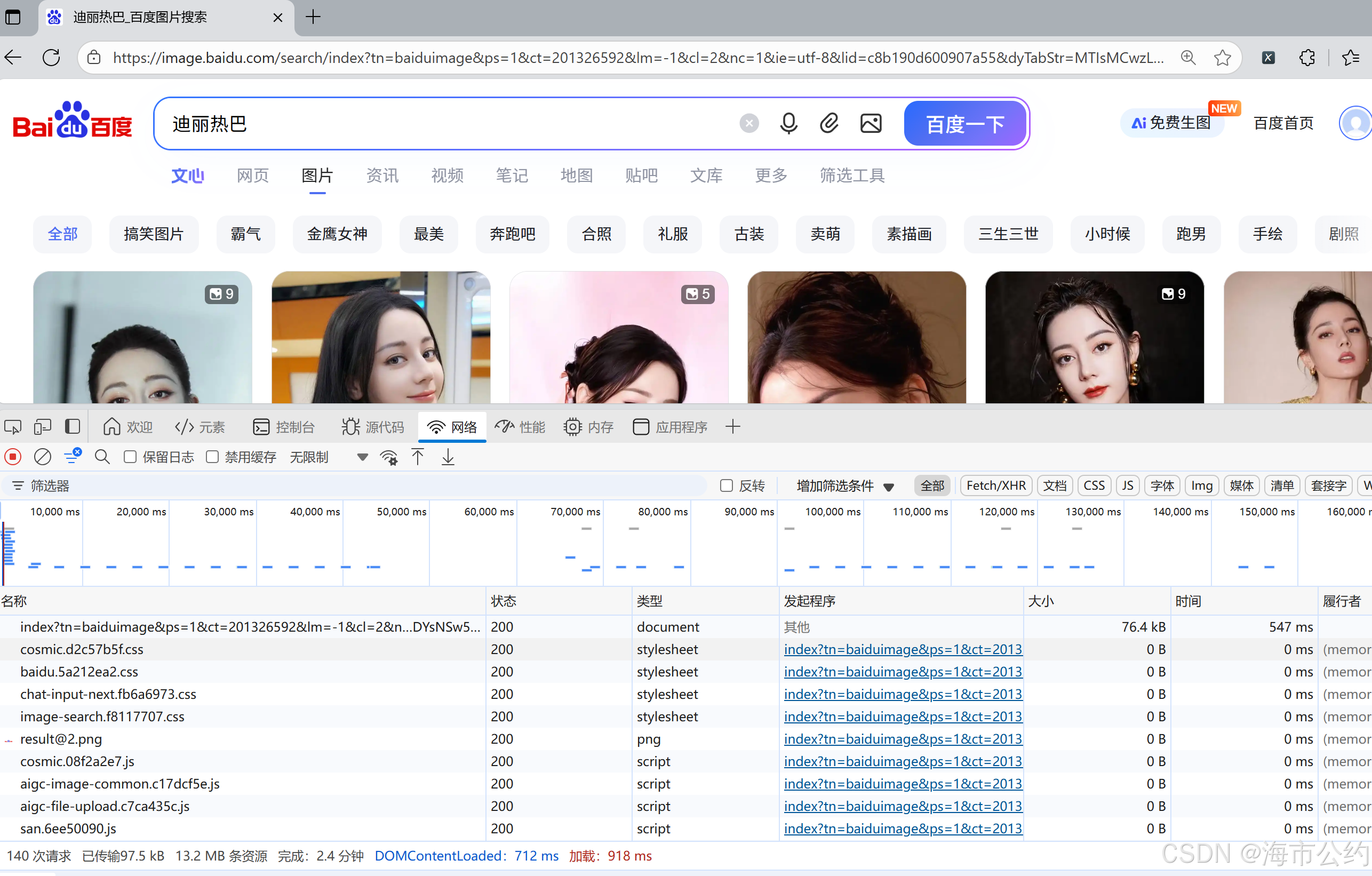
在名称一栏找到与你这个页面相同网址对应的名称,点击鼠标右键选择复制为cURL(bash),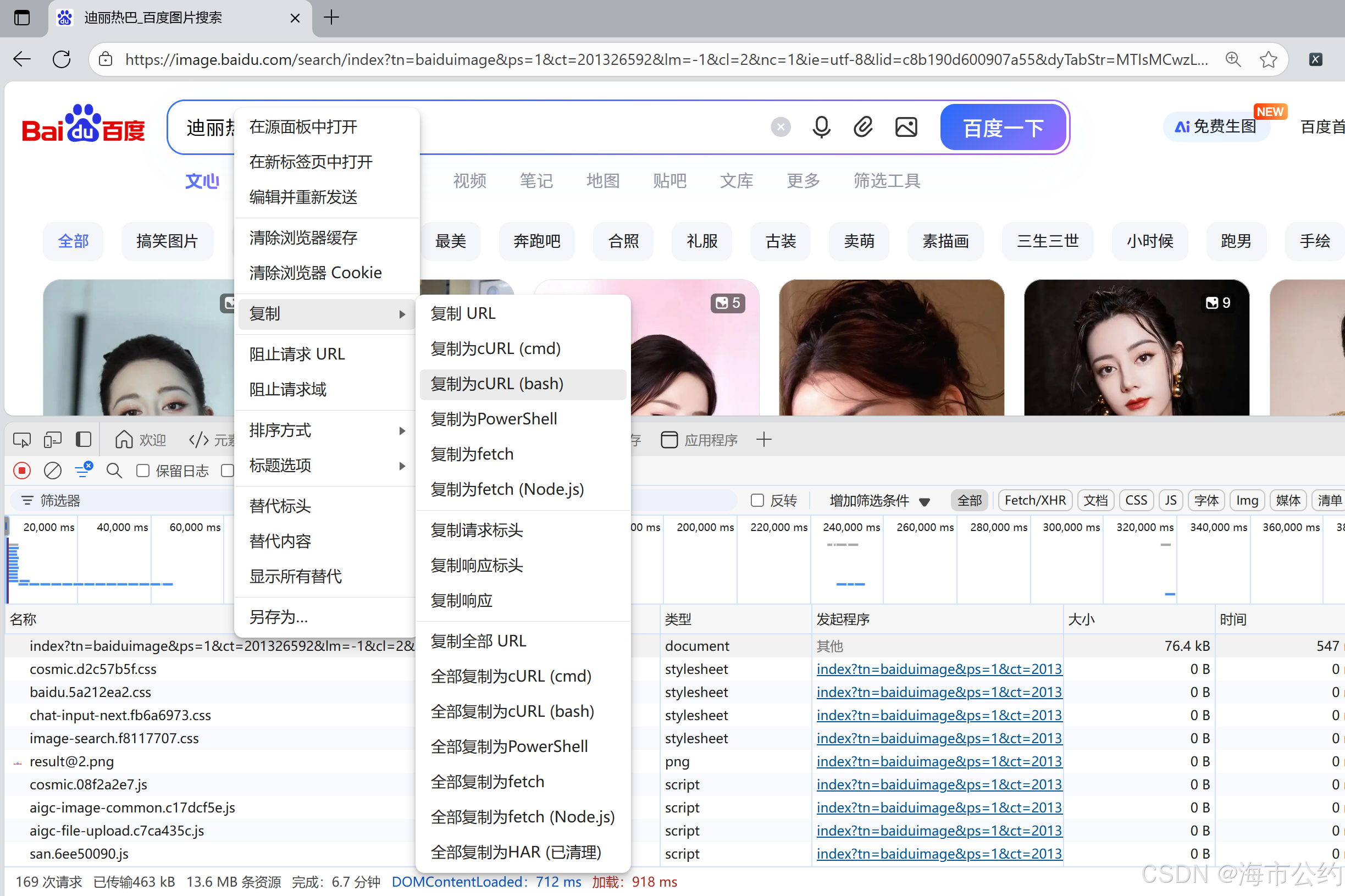
将复制好的粘贴到下面的网址处,即可获取替换为自己本机的这些数据信息
网址:https://spidertools.cn/#/curl2Request
结语
进程、线程、协程是 Python 应对不同场景的多任务工具:进程适合 CPU 密集型任务,线程适配 IO 密集型场景,协程则是单线程下的异步效率利器。掌握它们的特性与适用场景,既能让程序更高效,也能理解现代编程中 "并发" 的核心逻辑。多敲代码、多做实战,你会更精准地选择合适的多任务方案。