本章目标
1.线程的优点和缺点
2.线程异常
3.同进程下的多线程共享
4.posix线程库原理
1.线程的优点和缺点
在前面我们聊过了什么是线程,在Linux当中线程是如何实现的.但是与进程相比,线程它有哪些好处和缺点呢?
1.1线程优点
1.创建一个新的线程去处理任务,它的消耗实际上是比创建进程消耗小很多的.我们知道创建一个进程不仅仅要创建管理它的内核数据结构,也需要位它单独创建一个进程地址空间在内核当中要为它创建很多东西.而相对于线程来说,所以线程都是在进程内部实现的,它除了为它在内核当中创建LWP,在进程地址空间中申请一片空间,作为自己独立的线程栈(这里还会申请一些其他东西.我们放到posix线程库的原理部分去说这个事情),它与进程相比,它的消耗是小很多的.
并且每个进程之间是相互独立的,在我们之前进行IPC进程间通信的,我们无论是管道还是共享内存,还是其他什么方式.我们都是要让他们首先看到同一份资源.这对于进程来说,这个操作我们一般只能够由内核去完成.作为用户态的我们是不能够直接去打破进程与进程之间的独立性的.
而对于线程来说,它的所有东西都是在同一个进程内部,我们线程与线程间的所有操作基本上都是在用户态就能够直接完成,绝大多数情况是会避免通过系统调用的,因为在前面我们页说过,系统调用是通过软中断实现,是由时间上的消耗的
2.进程之间的调度切换的消耗时绝对大于线程之间的调度切换的,进程之间切换除了要保存当前的上下文数据,也要更换进程地址空间,pcb等等这些需要内核去完成的事情.而对于线程来说,它的切换,仍然时处于同一个进程地址空间的,唯一的消耗基本上就是上下文数据了
3.另外⼀个隐藏的损耗是上下⽂的切换会扰乱处理器的缓存机制。简单的说,⼀旦去切换上下⽂,处理器中所有已经缓存的内存地址⼀瞬间都作废了。还有⼀个显著的区别是当你改变虚拟内存空间的时候,处理的⻚表缓冲TLB (快表)会被全部刷新,这将导致内存的访问在⼀段时间内相当的低效。但是在线程的切换中,不会出现这个问题,当然还有硬件cache。
4.对于一个线程来说,它占有的资源一定时比进程少的.这一点时毋庸置疑的
5.我们的电脑再买回来的时候,我们的电脑的cpu一定是多核的,而多线程是能够充分利用这一点,让同一时刻由多个执行流在跑,例如我的电脑就是24核32线程
6.多线程可以在执行一些io的时候去执行其他的计算任务.在前面,我们信号部分alarm的部分曾经测过,io这种操作实际上是一种慢速操作,但是对于多线程来说,我们可以再执行的io的同时去执行其他任务
1.2线程的缺点
1,在多线程的场景下,我们的线程数量如果多于实际的任务数量的话,我们还要对不在执行任务的线程进行管理,这在后面我们会介绍条件变量以及信号量这样的方法去维持这个顺序,当多执行流按照一定的顺去去执行任务的时候,我们叫做同步.
也就是说,我们如果创建的线程过多是会有性能上的损失的
2.多线程让程度代码的安全性降低.我们可能会出现之前我们说过的可重入问题,也可能会出现类似对同一块资源进行修改读取.会导致数据不一致的问题.
2.线程异常
多线程与多进程在报错上的异常不同的就是,多进程如果某个子进程报错了,子进程自己会直接退出,该子进程只要通过父进程回收,或者去走一个孤儿进程的方法,让操作系统代替回收.亦或者通过忽略SIGCHILD这个信号.回收掉子进程的内核数据结构,就不会造成问题.
但是对于线程来说,这个问题就与多进程的情况不同.所有的多线程都是在同一个进程的内部,如果进程的内部,而所有的线程都是进程内部的执行流,如果一格执行流出错,异常退出会导致其他所有线程也会同时退出的
3.同进程下的多线程共享
我们在前面了解过同进程下的所有线程都有自己的内核数据结构,以及相对应的独立的线程栈.这些是线程私有的.但是处于同一进程下,他们的即使名义上是自己私有的.其他的线程也能够看到.只不过方法是比较间接的
cpp
#include<iostream>
#include<unistd.h>
#include<pthread.h>
int* a = nullptr;
void* hander(void* arg)
{
int b = 10;
a = &b;
sleep(100);
return nullptr;
}
int main()
{
pthread_t tid;
pthread_create(&tid,nullptr,hander,nullptr);
sleep(5);
std::cout<<*a<<std::endl;
return 0;
}
在这里我们在全局中定义了一个指针去拿子线程当中定义的变量的值,并在主线程当中打印,我们是看到我们是能够拿到的.
对于子线程的函数返回是表示着该执行流的结束
在主线程当中的返回值表示的是该进程的结束.当主线程返回的时候,其他子线程不管是不是执行完,也会同时结束.着也就是再这里我们看到的即使我们的子线程休眠100秒,但是只跑了5秒,我们就结束了.
再这里我们还要介绍一个关键字
__thread
cpp
#include<iostream>
#include<unistd.h>
#include<pthread.h>
int* a = nullptr;
__thread int c;
void* hander(void* arg)
{
int b = 10;
a = &b;
c = 100;
std::cout<<c<<std::endl;
sleep(100);
return nullptr;
}
int main()
{
pthread_t tid;
pthread_create(&tid,nullptr,hander,nullptr);
sleep(5);
c = 20;
std::cout<<c<<std::endl;
std::cout<<*a<<std::endl;
return 0;
}__thread是gcc自己提供的线程局部存储设施,线程局部存储就是,该变量会在所有线程中都开辟空间.
但是他们使用同一个变量名.但是互相并不干扰.它可以修饰全局变量.
但是它也有自己缺点,它只能够用来修饰内置类型.

4.posix线程库原理
在前面我们说过我们的Linux线程库实际上是一个封装LWP做出来的一个第三方库.我们的Linux在内核当中是不存在线程这个概念的.我们只有轻量级进程,但是我们轻量级进程,它本身的所支持的功能与属性是不支持我们去完成去描述的线程的这个结构体的.所以在posix库当中它会维持住一个在用户态的数据结构去描述线程这个概念.这个数据结构就是我们真正意义上的线程tcb.
而这个数据结构包括线程栈的具体位置都和动态库被放在了当前进程的共享区.它是通过我们之前介绍的mmap进行匿名映射实现出来的
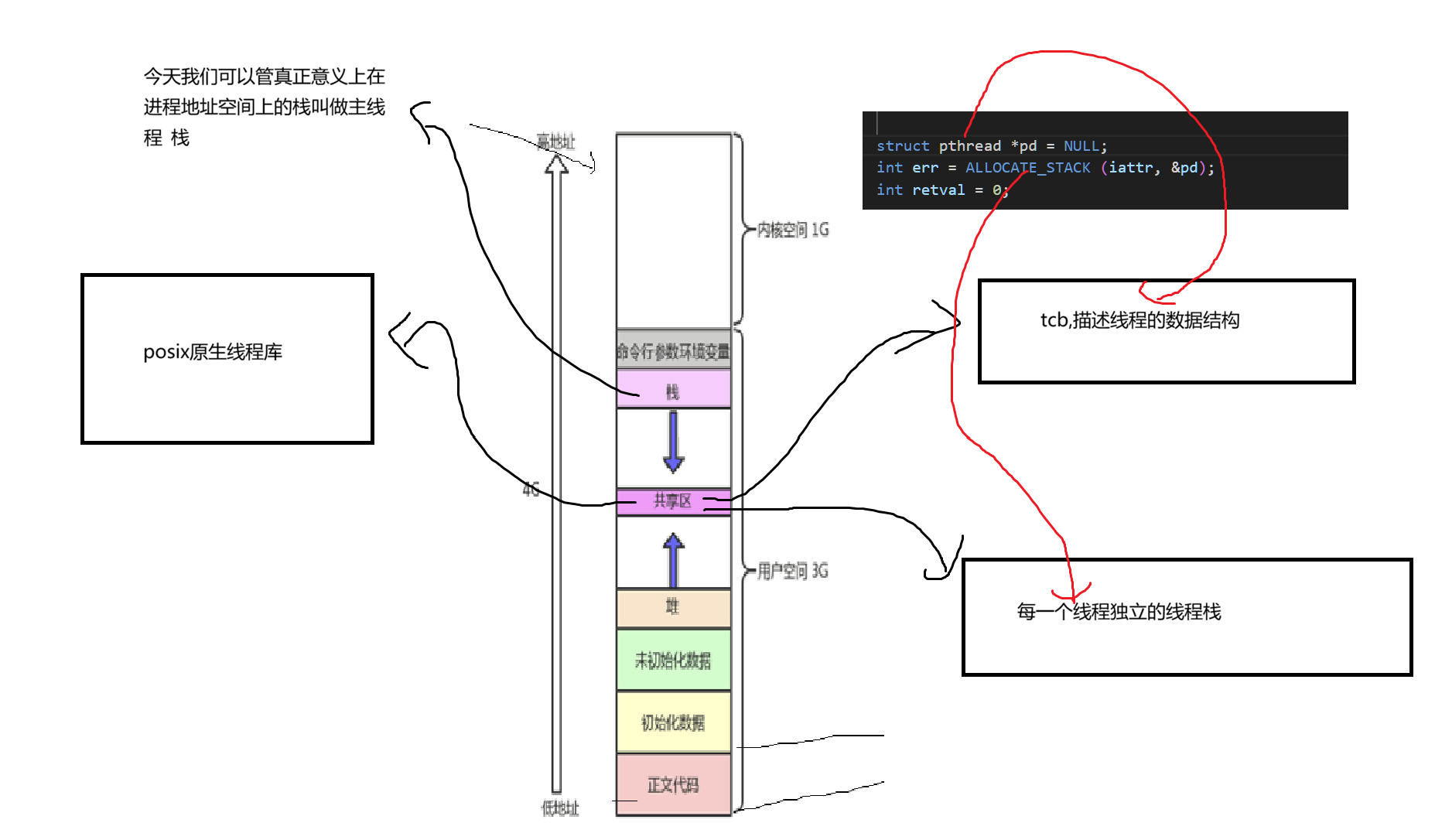
2.1线程创建的整体流程
我们可以在glibc标准库中找到这个,线程创建的整个过程
路径:nptl/pthread_create.c
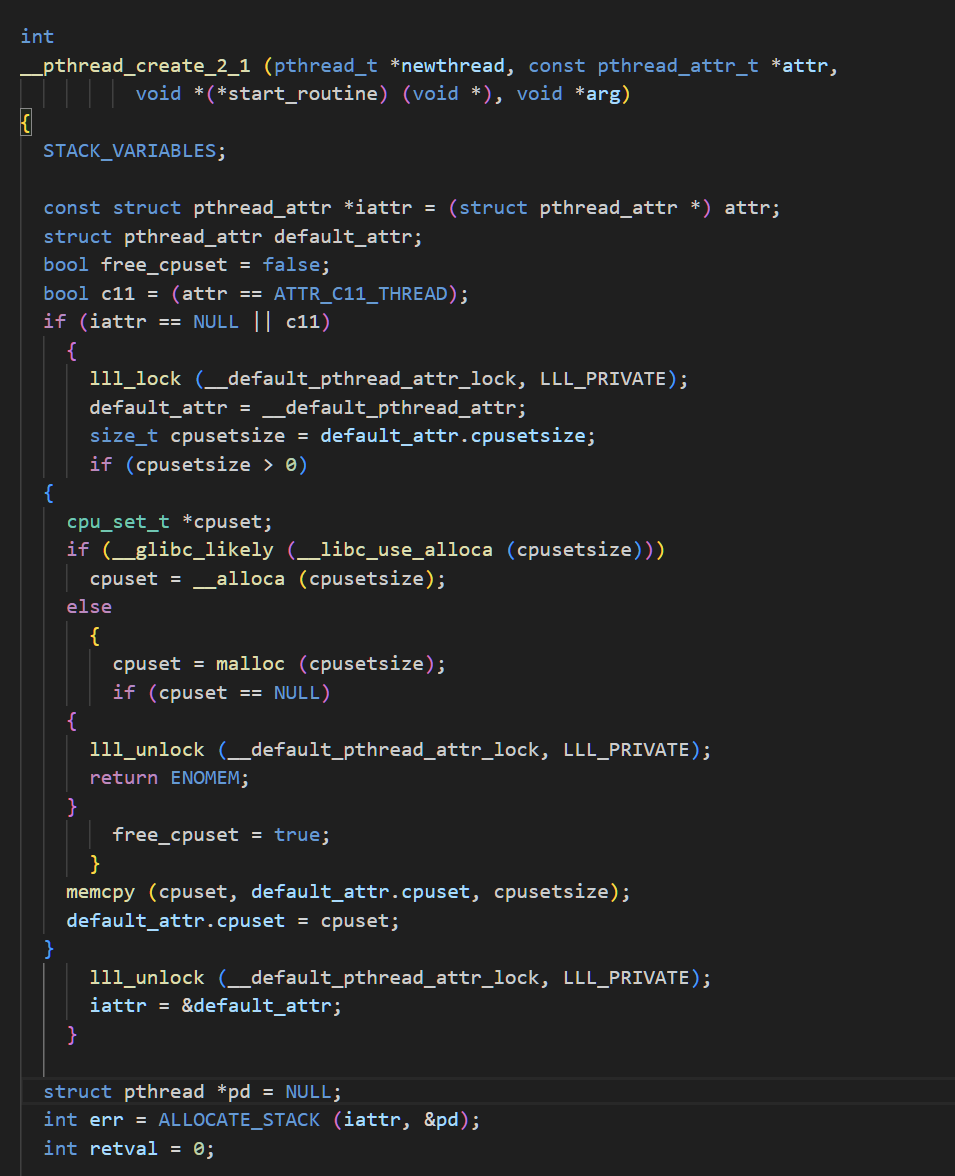
c
const structpthread_attr *iattr = (structpthread_attr *)attr;在上面我们能够找到这一条,这就是我们创建线程时设置的线程属性
c
struct pthread *pd = NULL;而这个就是我们真正在内核当中维护的tcb,描述线程具体信息的结构
c
int err = ALLOCATE_STACK(iattr, &pd);这个操作就是在初始化线程栈
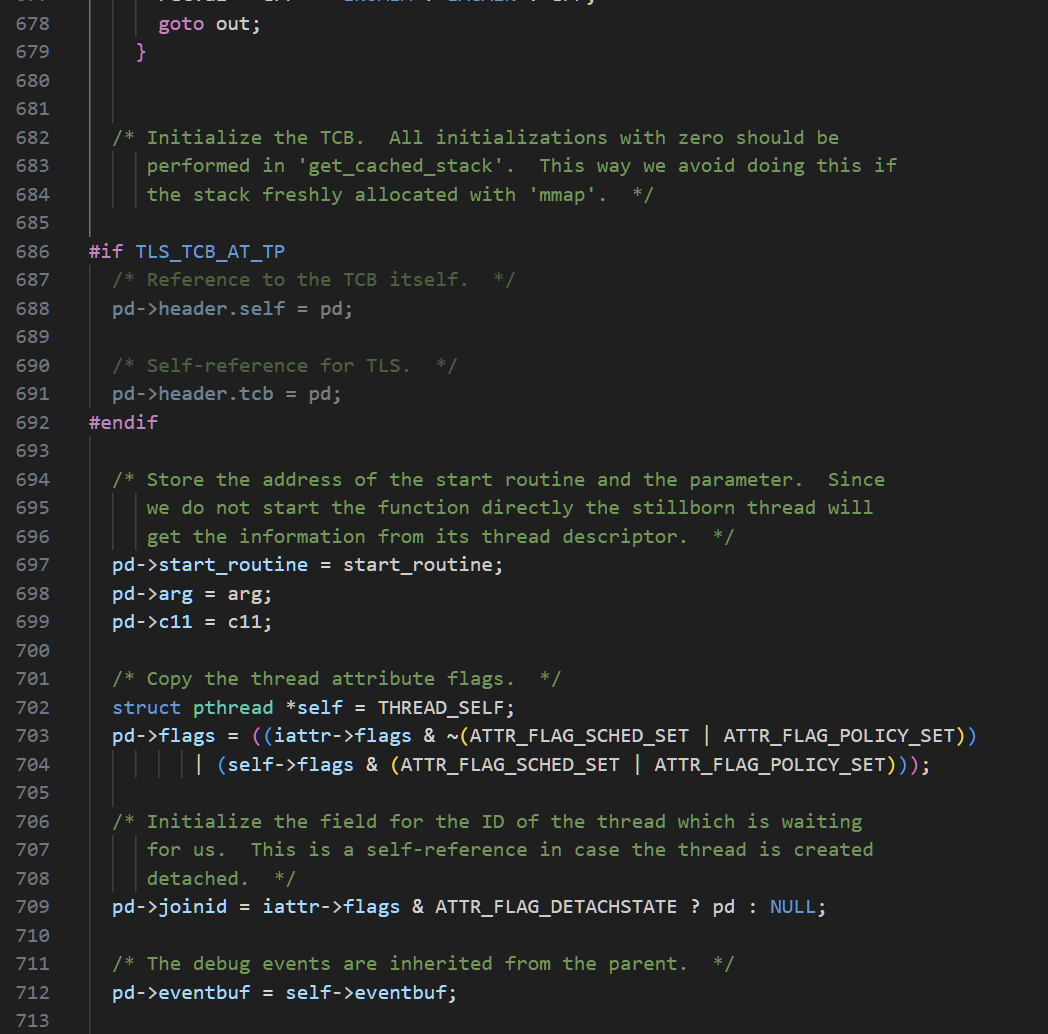
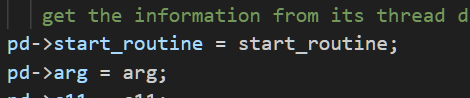
我们再找到这两个操作,就是再向pthread当中设置我们的线程方法.
c
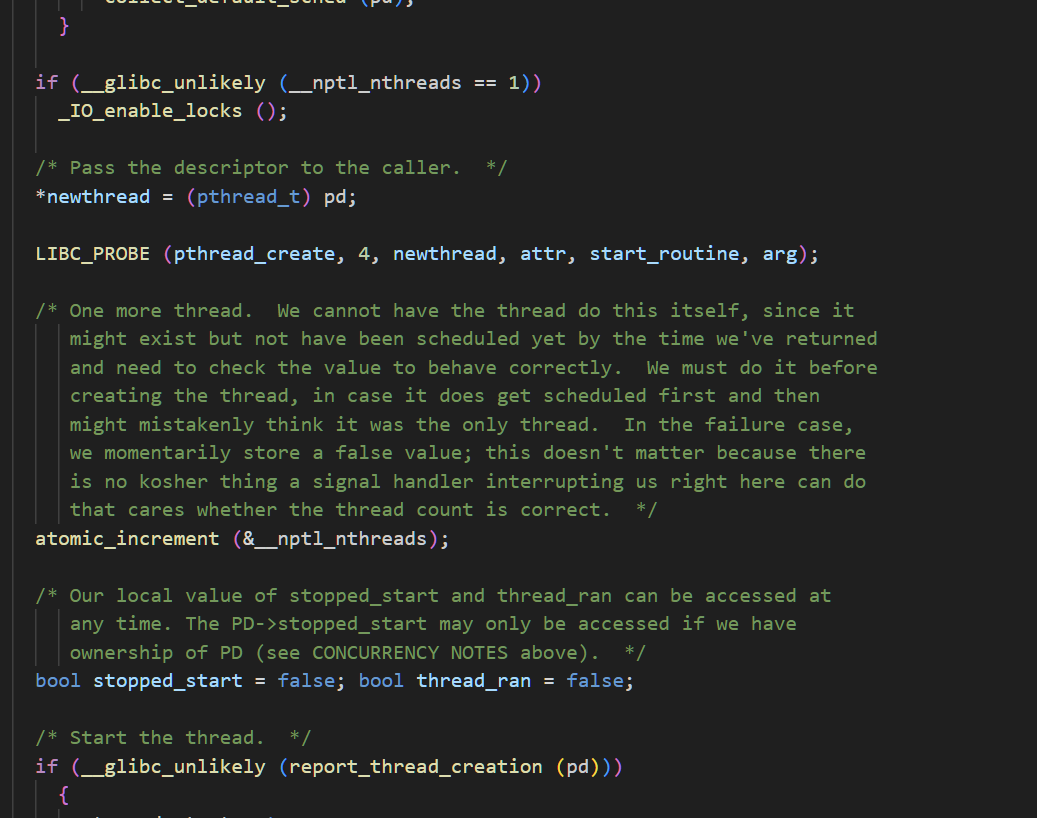
*newthread = (pthread_t) pd;这个操作把pd(就是线程控制块地址)作为ID,传递出去,所以上层拿到的就是⼀个虚拟地址,只要拿到起始地址皆能够找到这个结构
c
bool is_detached = IS_DETACHED(pd);检测下线程是否分离,什么时分离,我们会在下一章线程如何进行控制的话题介绍

这个很好理解,拿我们上面创建好的各种消息然后去创建启动线程
c
struct pthread_attr
{
/* Scheduler parameters and priority. */
struct sched_param schedparam;
int schedpolicy;
/* Various flags like detachstate, scope, etc. */
int flags;
/* Size of guard area. */
size_t guardsize;
/* Stack handling. */
void *stackaddr;
size_t stacksize;
/* Affinity map. */
cpu_set_t *cpuset;
size_t cpusetsize;
};线程属性的结构体
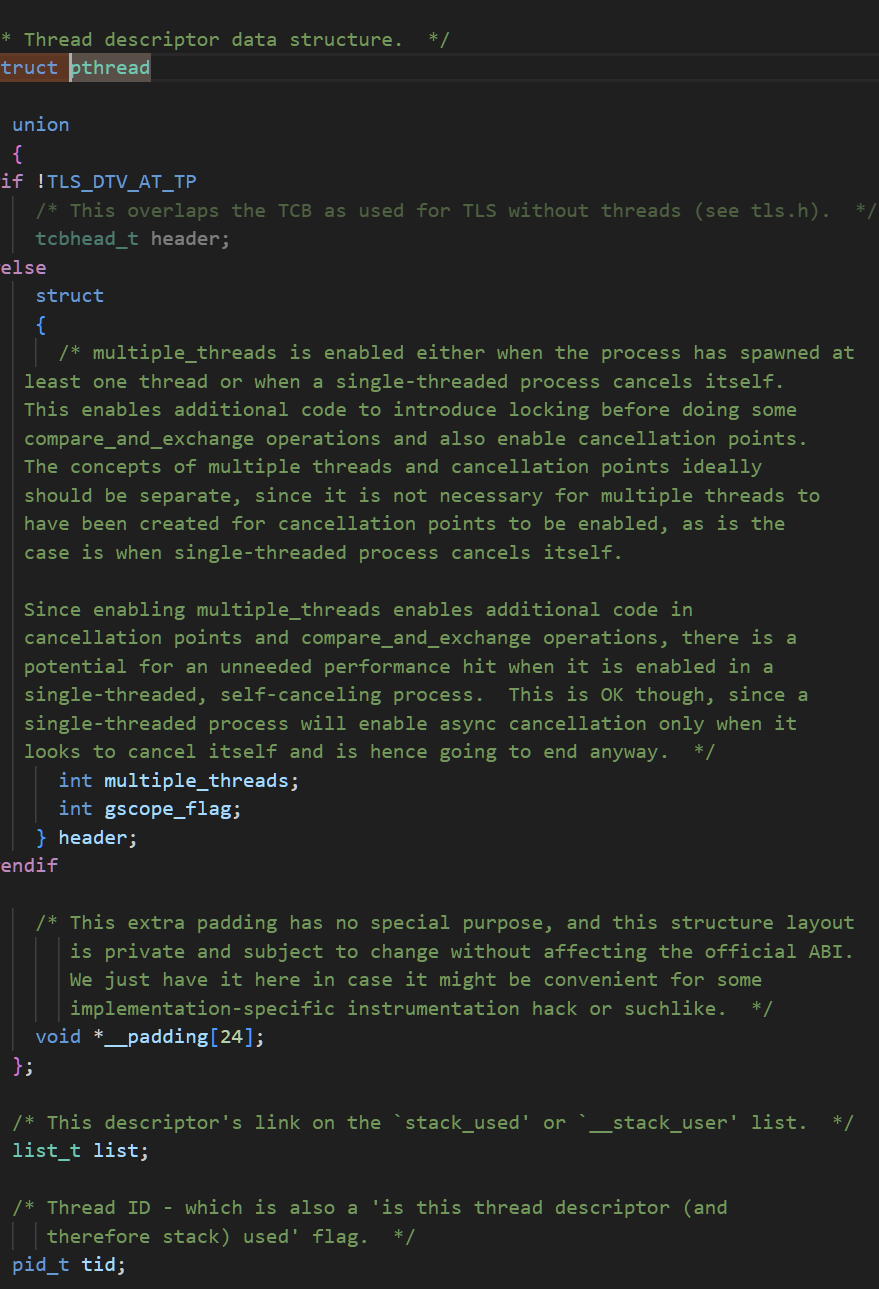
posix当中的tcb结构
可以在这个路径下找到

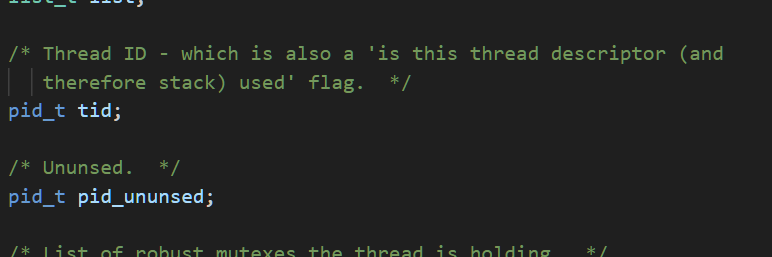
在这里我们就跟找到一格pid_t类型的tid,他就是我们在内核当中的LWP,就是说,我们这个thread,是给用户看的.而在内核当中的表示仍然时LWP
2,2线程栈的创建

我们看到我们之前的线程栈的创建时通过这个宏创建的

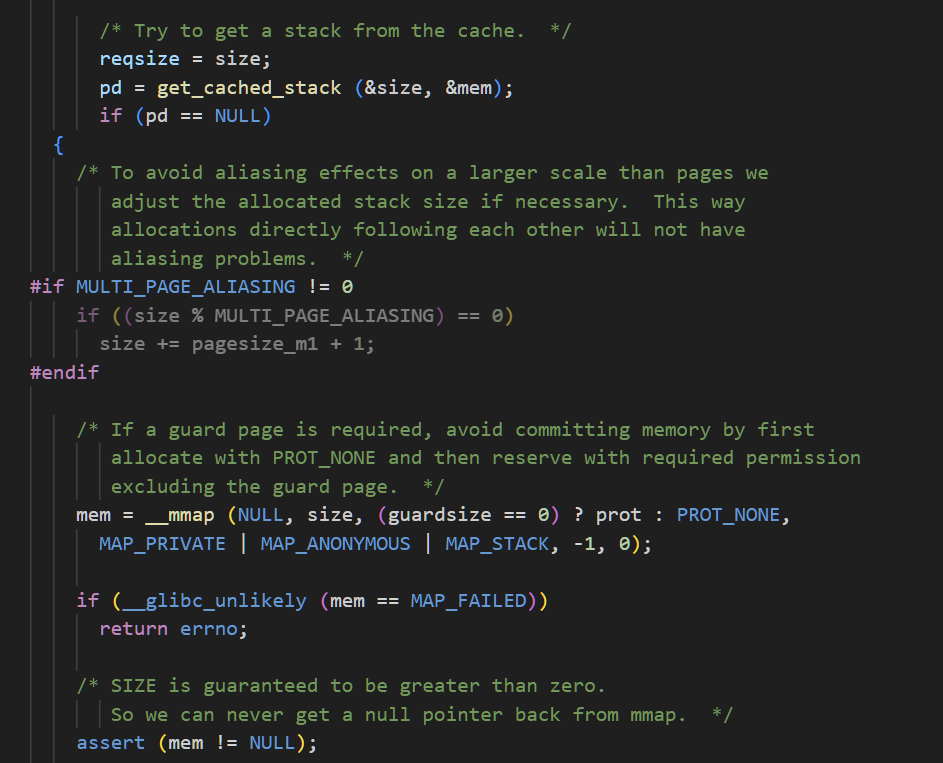
我们跳转到最后,可以找到这里是使用mmap进行匿名映射的,当通过这个mmap开出空间了之后
底层将会调用sys_clone这个系统调用.将mmap得到的栈地址作为参数传给sys_clone,让新线程使用这块内存作为栈
c
int sys_clone(struct pt_regs *regs)
{
unsigned long clone_flags;
unsigned long newsp;
int __user *parent_tidptr, *child_tidptr;
clone_flags = regs->bx;
//获取了mmap得到的线程的stack指针
newsp = regs->cx;
parent_tidptr = (int __user *)regs->dx;
child_tidptr = (int __user *)regs->di;
if (!newsp)
newsp = regs->sp;
return do_fork(clone_flags, newsp, regs, 0, parent_tidptr, child_tidptr);
}因此,对于⼦线程的stack ,它其实是在进程的地址空间中map出来的⼀块内存区域,原则上是
线程私有的,但是同⼀个进程的所有线程⽣成的时候,其他线程想访问该线程的变量还是可以做到的.
• 对于Linux进程或者说主线程,简单理解就是main函数的栈空间,在fork的时候,实际上就是复
制了⽗亲的stack 空间地址,然后写时拷⻉(cow)以及动态增⻓。如果扩充超出该上限则栈溢出会报段错误(发送段错误信号给该进程)。进程栈是唯⼀可以访问未映射⻚⽽不⼀定会发⽣段错
误⸺超出扩充上限才报。
• 然⽽对于主线程⽣成的⼦线程⽽⾔,其stack 将不再是向下⽣⻓的,⽽是事先固定下来的。线程栈⼀般是调⽤glibc/uclibc等的pthread 库接⼝射区(或称之为共享区)。其中使⽤pthread_create 创建的线程,在⽂件映mmap 系统调⽤,这个可以从nptl/allocatestack.c 中的glibc 的allocate_stack 函数中看到.这就是我们上面所追踪源码找到的
• 对于这种线程栈来说一般是8M,它是从一开始就已经确定好了的.也就是说这种栈是不会向主线程栈那样继续增长的