这里根据个人理解,将数据库表层各种命令根据不同的作用对象和功能做成以下划分图:
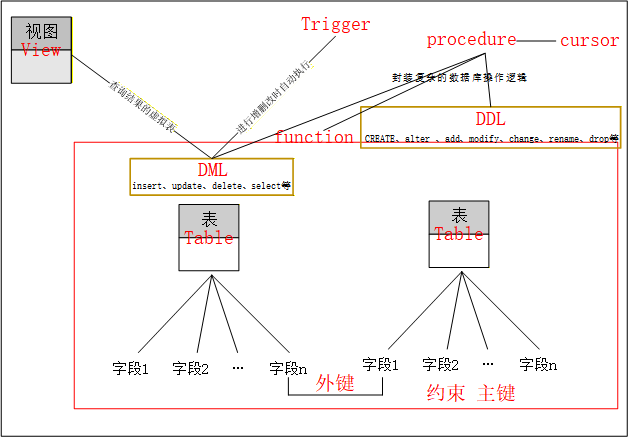
注:全文中各种操作以【MySQL示例数据库-CSDN博客】中建立的数据库为基础进行练习。
[0.0 什么是MySQL?](#0.0 什么是MySQL?)
[0.1 MySQL中的运算符](#0.1 MySQL中的运算符)
[0.1.1 算术运算符](#0.1.1 算术运算符)
[0.1.2 比较运算符](#0.1.2 比较运算符)
[0.2 MySQL中的数据类型](#0.2 MySQL中的数据类型)
[0.3 MySQL中的约束](#0.3 MySQL中的约束)
[0.3.1 主键约束](#0.3.1 主键约束)
[0.3.2 外键约束](#0.3.2 外键约束)
[0.3.3 修改约束的sql语句](#0.3.3 修改约束的sql语句)
[0.4 MySQL中的函数](#0.4 MySQL中的函数)
[0.4.2 聚合函数](#0.4.2 聚合函数)
[0.4.3 流程函数](#0.4.3 流程函数)
[0.5 正则表达式regexp](#0.5 正则表达式regexp)
[0.5.1 匹配单个实例](#0.5.1 匹配单个实例)
[0.5.2 匹配多个实例](#0.5.2 匹配多个实例)
[2.1 创建Table](#2.1 创建Table)
[2.2 修改Table](#2.2 修改Table)
[2.3 修改Colume](#2.3 修改Colume)
[3.1 插入数据insert](#3.1 插入数据insert)
[3.2 更新数据update](#3.2 更新数据update)
[3.3 删除数据](#3.3 删除数据)
[3.3.1 物理删除delete](#3.3.1 物理删除delete)
[3.3.2 假删除](#3.3.2 假删除)
[3.4 查询数据select](#3.4 查询数据select)
[3.4.1 基础查询](#3.4.1 基础查询)
[3.4.2 高级查询](#3.4.2 高级查询)
[1. 排序order by](#1. 排序order by)
[2. 限制数量limit](#2. 限制数量limit)
[3. 去重distinct](#3. 去重distinct)
[4. 组合查询union](#4. 组合查询union)
[5. 分组查询group](#5. 分组查询group)
[3.4.3 select子句的顺序](#3.4.3 select子句的顺序)
[3.4.4 多表连接查询](#3.4.4 多表连接查询)
[3.4.5 子查询](#3.4.5 子查询)
〇、基础
0.0 什么是MySQL?
MySQL是一种关系型数据库管理系统(DBMS),由瑞典 MySQL AB 公司开发,属于 Oracle 旗下产品。MySQL是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的RDBMS (Relational Database Management System,关系数据库管理系统)应用软件之一。
关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
MySQL所使用的 SQL 语言是用于访问数据库的最常用标准化语言。MySQL 软件采用了双授权政策,分为社区版和商业版,由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型和大型网站的开发都选择 MySQL作为网站数据库。
0.1 MySQL中的运算符
0.1.1 算术运算符
+加 -减 *乘 /除 %取余
0.1.2 比较运算符
>大于 <小于 >=大于等于 <=小于等于 =等于 <>/!=不等于
sql
#判断是否为空
is [not] NULL
#判断一个值是否在两个值之间
between and
#判断一个值是否是列表中的值
[not] in (元素1,元素2,...,元素n)
#通配符匹配(支持'%'和'_'占位符)
like【四道例题】
【例1】:在tabel_01表中,当create_time为'2026-01-24'时,判断content是否为空;
【例2】:在tabel_01表中,判断create_time在'2026-01-19'到'2026-01-22'之间的id有哪些;
【例3】:判断5是否在列表(1,2,3,4,6,7)中;
【例4】:在tabel_01表中,找到contest中符合"%外_"的id和contest
sql
select id,content is null from table_01 where create_time = '2026-01-24';
select id from table_01 where create_time between '2026-01-19' and '2026-01-22';
select 5 in (1,2,3,4,6,7);
select id,content from table_01 where content like '%外_';0.2 MySQL中的数据类型
| 类别 | 数据类型 | 存储范围(有符号 / 无符号) | 字节数 | 说明 |
| 整型 | TINYINT | -128 ~ 127 / 0 ~ 255 | 1 | 小整数 |
| | SMALLINT | -32768 ~ 32767 / 0 ~ 65535 | 2 | 短整数 |
| | MEDIUMINT | -8388608 ~ 8388607 / 0 ~ 16777215 | 3 | 中等整数 |
| | INT | -2147483648 ~ 2147483647 / 0 ~ 4294967295 | 4 | 常用整数 |
| | BIGINT | -2^63 ~ 2^63-1 / 0 ~ 2^64-1 | 8 | 大整数 |
| 浮点型 / 定点型 | FLOAT[(M,D)] | 约 ±3.4E+38,精度约 7 位小数 | 4 | 单精度浮点数 |
| | DOUBLE[(M,D)] | 约 ±1.8E+308,精度约 15 位小数 | 8 | 双精度浮点数 |
| | DECIMAL[(M,D)] | 精确小数,M 为总位数,D 为小数位数 | 可变 | 精确小数类型 |
| 日期时间型 | YEAR | 1901 ~ 2155 | 1 | 年份 |
| | TIME | -838:59:59 ~ 838:59:59 | 3 | 时间 |
| | DATE | 1000-01-01 ~ 9999-12-31 | 4 | 日期 |
| | DATETIME | 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 | 8 | 日期 + 时间 |
| | TIMESTAMP | 1970-01-01 08:00:01 ~ 2038-01-19 11:14:07 | 4 | 时间戳(受时区影响) |
| 字符型 | CHAR(M) | 定长,0 ≤ M ≤ 255 | M 字节 | 固定长度字符串 |
| | VARCHAR(M) | 变长,0 ≤ M ≤ 65535 | L+1 字节 (L 为实际长度) | 可变长度字符串 |
| | TINYTEXT | 最多 255 字符 | 0~255 字节 | 短文本 |
| | TEXT | 最多 65535 字符 | 0~65535 字节 | 普通文本 |
| | MEDIUMTEXT | 最多 2^24-1 字符 | 约 16MB | 中等长度文本 |
| | LONGTEXT | 最多 2^32-1 字符 | 约 4GB | 长文本 |
| | ENUM(...) | 从枚举值中选一个 | 1~2 字节 | 枚举类型,只能选一个值 |
SET(...) |
从集合中选多个 | 1~8 字节 | 集合类型,可选多个值 |
|---|
其中用" "重点标记的是比较常用的数据类型。
这里要注意一下:
-
- Tinyint类型在MySQL中常用来定义bool,因为MySQL中并没有原生的bool类型的值。
-
- 设置varchar和char的时候要想到,一个汉字占两个字节,所以不要设置太小
0.3 MySQL中的约束
|-----------------------------------------|-------------|
| 非空约束 (就是说设置这个约束的字段不能未知或空值,这一列必须有值。) | Not null |
| 默认约束 | Default |
| 唯一约束 | Unique |
| 主键约束 | Primary key |
| 外键约束 | Foreign key |
**注:**这里为空指的是NULL,和传统意义上的空字符串' '是不一样的概念,不要混淆!
0.3.1 主键约束
唯一标识一个表的字段为该表的主键。主键的主要特点:
- **唯一性:**主键要求每一行数据的主键值都必须是唯一的,不允许有重复值;
- **非空性:**主键要求主键列的值不能费控,不能为NULL;
- **单一性:**每个表都必须有主键并且只能有一个主键,主键可以由一个列或多个列组成,形成复合主键。
使用主键需要注意以下几点:
- 主键的值不应该更改
- 不使用可能会修改值的列作为主键
|------|----------------------------------------------------|
| 列级主键 | 字段名 字段类型 primary key |
| 表级主键 | constraint 约束名 primary key (字段1, 字段2, ...) |
| 删除主键 | alter table 表名; drop primary key; |
主键使用时通常和一个列属性绑定起来,就是自增(auto_increment),但是要注意,每个表中只有一个auto_increment列。
|-------|------------------------------|
| 定义自增列 | 字段1 字段类型 auto_increment; |
0.3.2 外键约束
外键是++表中的一个字段,而这个字段同时是另一个表的主键值++ 。外键通常用来连接两个表。与主键不同的是,一个表可以定义一个或多个外键,来保证数据的一致性和完整性。
外键引用把表分为父表 和子表,父表和子表的关系构建过程中需要保证以下要求:
- 创建表时先创建父表,再创建子表;
- 插入数据时,先插入父表数据,在插入子表数据;
- 删除时先删除子表,再删除父表。
子表外键类型要与父表的主键类型一致。
|----------|--------------------------------------------------------------------------------------------------------------------------|
| 在子表中创建外键 | 表 A: 列a 数据类型 primary key 表 B: 列a 数据类型 约束条件, constraint 外键名 foreign key (列a) references 父表A(主键列a) |
通过上面的代码解释,就能明确父表和子表的逻辑关系了。
0.3.3 修改约束的sql语句
|---------------------------------------------------------------------------------|-------------------------------------------------------------|
| 添加非空约束 | alter table 表名 modify column 字段名 字段类型 not null |
| 删除非空约束 (修改表) | alter table 表名 modify column 字段名 字段类型 |
| 添加默认约束 | default 默认值 |
| 添加唯一约束(单字段) **注:**唯一约束允许空值,多个空值不违反唯一约束。 | unique |
| 添加唯一约束(多字段) 注: 这时候约束是针对两个列,当两个列同时相同时,无法插入 比如(a,b)(a,c)√ (a,b)(a,b)× | unique(字段1,字段2.....) |
| 已有字段添加唯一约束 1. 修改表时增加约束 2. 直接增加约束 | alter table 表名 modify column 字段名 字段类型 unique |
| 已有字段添加唯一约束 1. 修改表时增加约束 2. 直接增加约束 | alter table 表名 add constraint 约束名 unique (字段名); |
| 删除唯一约束 | alter table 表名 drop index 约束名 |
| 删除唯一约束 | alter table 表名 drop key 约束名 |
0.4 MySQL中的函数
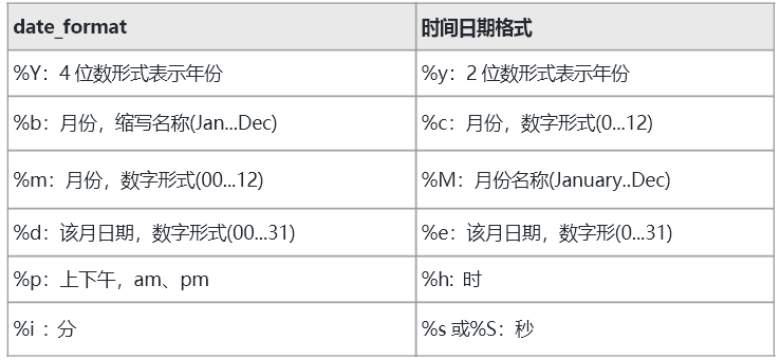
0.4.1数值函数、字符函数与日期时间函数
以下是MySQL中常用的函数:

0.4.2 聚合函数
|----------|-------------|
| 返回某列的平均值 | avg() |
| 返回某列值的和 | sum() |
| 返回某列的行数 | count() |
| 返回某列的最大值 | max() |
| 返回某列的最小值 | min() |
注:
- 聚合函数会自动忽略空值,所以这里不需要手动增加条件排除NULL
- 聚合函数不能作为where子句后的限制条件
0.4.3 流程函数
|-------------------------------------------------------------------------------------------------------------|---------------------------|
| 如果value为真就返回t,否则返回f | if(value, t, f) |
| 如果column为空就返回value,否则返回column **注:**主要用处为:防止数学计算中因为出现NULL而无意义,也就是说为了防止计算结果出现NULL,建议使用ifnull空值处理函数做预先处理。 | ifnull(column, value) |
0.5 正则表达式regexp
正则表达式的作用是匹配文本,将一个模式与一个文本串进行比较。正则表达式的操作符regexp和前文提到的比较运算符like的区别如下:
|---------------|------------|----------------|
| 特性 | LIKE | REGEXP (RLIKE) |
| 全称 | 简单的模式匹配 | 正则表达式匹配 |
| 功能 | 简单通配符匹配 | 强大的正则表达式匹配 |
| 性能 | 通常更快 | 通常较慢(更复杂) |
| 通配符 | 固定两个:% 和 _ | 完整的正则表达式语法 |
| 区分大小写 | 取决于数据库排序规则 | 默认不区分大小写(可设置) |
0.5.1 匹配单个实例
|----------------------------------------------------------------------------------|-----------------------------------|
| 匹配其中之一(包括且不限于字符),功能上相当于or | | |
| 匹配字符之一,功能上相当于or | |
| 匹配范围,使用"-"来定义一个范围 | - 如:1-3、a-z |
| 转义字符 **注:**多数正则表达式使用单个反斜杠作为转义字符,但MySQL要求两个反斜杠(MySQL自己解释一个,正则表达式库解释另一个) | \\ |
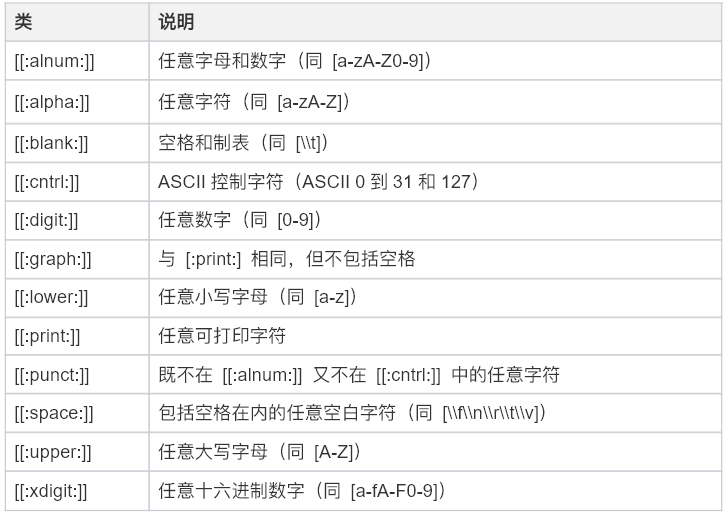
| 匹配字符类 **字符类的定义:**将自己工作过程中常用的数字、字母字符或混合字符等进行整体预定义,使其成为一个能够用正则表达式匹配的字符集,就是字符类。 | 如下表↓ |
0.5.2 匹配多个实例
1.常用元字符
|------------------------|--------|
| 匹配任意字符 | . |
| 匹配字符串的开始,^在 中表示否定 | ^ |
| 匹配字符串的结束 | $ |
2.重复元字符
|------------|----------------|
| 任意个匹配 | * |
| 一个或多个匹配 | + |
| 0个或1个 | ? |
| 指定数目的匹配 | {n} |
| 不少于指定数目的匹配 | {n,} |
| 匹配数目的匹配 | {n,m}(m不超过255) |
【n个练习】
sql
#例1:查找content中含有"侠侣"或"血液"的数据
select * from table_01 where content regexp '血液|侠侣';
#例2
select "a" regexp "[a-z]";
#例3
SELECT "abc" REGEXP "^a.c$";
/*
解析一下:以a为首字符,以c为尾字符,中间匹配任意字符
*/
#例4
select "bn" regexp "ba*n"
/*
解析一下:b 任意匹配数的字符a n
*/
#例5
select "pi" regexp "^(pi|apa)$";
/*
解析一下:以pi|apa为首,以pi|apa为尾,所以只能和字符串"pi""apa"相匹配
*/
#例6
select "fo\eo" regexp "^fo\\eo$";
/*
解析一下:对\进行转义,这样以fo\eo为首,以fo\eo为尾,所以只能和"fo\eo"相匹配
*/一、Database相关命令
|---------------------------------------|-----------------------------------------|
| 显示数据库 | show databases; |
| 创建数据库 | create database if not exists 数据库名; |
| 使用特定的数据库 | use 数据库名; |
| 删除数据库 | drop database if exists 数据库名; |
| 显示数据库中的表 | show tables; |
| 导入数据库程序脚本(无分号) | source 脚本文件路径 |
| 查看表的基本结构 字段、类型、约束等 | desc 表名 |
| 查看数据库/表的创建语句 | show create database/table 数据库名/表名 |
| 查询当前连接的数据库 | select database(); |
| 查询当前的数据库版本 | select version(); |
| 查询当前的日期 格式形如"2026-01-29 18:50:56" | select now(); |
| 查询当前的用户 | select user(); |
二、DDL
DDL(数据定义语言)是用来定义和管理数据库中的对象和结构的,如表、索引、列等。
**注:**下面的SQL语句是一个整体,不是多个语句,这时应注意有没有分号分隔。
2.1 创建Table
表的创建语句框架如下,下面的三级目录会根据建立表所需的各种元素作为整体框架。
sql
create table if not exists 表名(
字段1 字段类型 [列级约束条件],
字段2 字段类型 [列级约束条件],
...
[表级约束条件]
);**注:**创建设计表时,一般在已知的字段的基础上额外添加"id""创建时间""修改时间"等字段。部分表中存在"假删除"的逻辑需求时还要设立isDelete字段。
2.2 修改Table
|------|----------------------------------------------------------------|
| 重命名表 | alter table 表名 rename to 新名称 |
| 删除表 | alter table 表名 drop table if exists 表1,表2,表3.. |
2.3 修改Colume
|-----------|-----------------------------------------------------------------------------------------------------------------------------------------|
| 增加字段 | alter table 表名 add column 字段名 字段类型 约束条件 first\|after 列名; |
| 修改字段的类型 | alter table 表名 modify column 字段名 新字段类型 约束条件 |
| 修改字段的相对位置 | 把字段放到某字段后: alter table 表名 modify column 字段名 字段类型 after 某字段 把字段放到首位: alter table 表名 modify column 字段名 字段类型 first |
| 更改字段名 | alter table 表名 change column 字段名 新字段名 字段类型 |
| 删除字段 | alter table 表名 drop column 字段名 |
【n道例题】
【例1】:为
table_01添加以下字段:
添加一个
status字段,类型为TINYINT,默认值为1,放在is_delete字段后面添加一个
priority字段,类型为INT,不允许为空,默认值为0,放在表的第一列【例2】:修改
table_01表的字段类型:
将
content字段的类型从TEXT修改为VARCHAR(1000)将
is_delete字段的类型从TINYINT修改为INT,并设置默认值为0
【例3】:调整table_01表的字段顺序:
将
priority字段移动到id字段后面将
status字段移动到表的首列【例4】:重命名
table_01表的字段:
将
modification_time字段重命名为update_time,类型不变将
is_delete字段重命名为deleted_flag,类型不变
sql
#例1
alter table table_01
add column status TINYINT DEFAULT 1 AFTER is_delete;
alter table table_01
add column priority INT NOT NULL default 1 first;
desc table_01;
#例2
alter table table_01
modify column content VARCHAR(1000);
alter table table_01
modify column is_delete INT default 0;
desc table_01;
#例3
alter table table_01
modify column priority int after id;
alter table table_01
modify column status tinyint(4) first;
desc table_01;
#例4
alter table table_01
change column modification_time update_time datetime;
alter table table_01
change column is_delete deleted_flag tinyint;
desc table_01;三、DML
DML(数据操作语言)是用于操作数据库中实际存在的数据。
3.1 插入数据insert
|----------------------------------------------------------------|----------------------------------------------------------|
| 插入数据 注:每个字段必须提供一个值,如果该字段没有值,就必须用NULL代替,每个字段也必须以他们在表中的顺序给出。 | insert into 表名 values( 字段1的值, 字段2的值 )(); |
| 插入数据 注:字段顺序需要与值的顺序一一对应,而不一定与表中顺序一一对应,没有值的字段可以不提供。 | insert into 表名( 字段1, 字段2 ) values( 字段1的值, 字段2的值 )(); |
3.2 更新数据update
|--------------------------------------------------------------------------------------------------------------|-----------------------------------------------------|
| 更新数据 注: 1. 必须加where限制条件,如果全局更新,就用 where 1=1 代替,否则会导致非部分更新造成损失 2. 更新前要用select检验更新域(更新范围)。 | update 表名 set 字段1=字段1的值, 字段2=字段2的值, ... Where 限制条件; |
3.3 删除数据
根据业务需求,有一些数据为了便于后期的可追溯性,会进行假删除(非物理意义上的删除),故删除分为物理删除 和假删除两种。
3.3.1 物理删除delete
|----------------------------------------------------------------------------------------------|----------------------------|
| 删除数据(物理删除) 注: 1. 无法恢复 2. 必须要加where限定条件,否则会删除数据库中的每一条数据。 3. 删除前要用select检验更新域。 | delete from 表名 where 限制条件; |
3.3.2 假删除
|-----------|-----------------------------------------------------|
| 假删除(逻辑删除) | 通过建立表时增加一个"is_Delete(是否删除)"的字段,假删除时只需要设置bool变量的值即可。 |
【n道例题】
【例1】:向
table_01表中插入一条新记录
status: 0
id: 100
priority: 11
create_time: '2024-12-15 10:30:00'
modification_time: '2024-12-15 10:30:00'
is_delete: 0
content: '这是一条测试记录'
【例2】:更新
table_01表中所有deleted_flag = 0的记录,将它们的update_time更新为当前时间
【例3】:删除table_01表中create_time在 '2026-01-30' 之前且content为空的记录
sql
#例1
insert into table_01
value (0,100,11,'2024-12-15 10:30:00','2024-12-15 10:30:00',0,'这是一条测试记录');
select * from table_01;
#例2
update table_01 set update_time = NOW() where deleted_flag = 0;
select * from table_01;
#例3
delete from table_01 where create_time <= '2026-01-24 00:00:00' and content is NULL;
select * from table_01;3.4 查询数据select
3.4.1 基础查询
常用的基本查询语句如下:
|--------|-----------------------|
| 筛选列 | select 列名1... from 表名 |
| 查询全部字段 | select * from 表名 |
3.4.2 高级查询
1. 排序order by
|---------------------------|-------------------------------------------------------|
| 指定select列表中列进行排序 (降序|升序) | select * from 表名 order by 列1,列2... desc|asc |
**注:**当未指定是降序还是升序时,order by默认的是升序;多个列进行排序是指当列1相同时,对列2进行排序;没有排序语句时候的默认排序不是按照主键排序的。
2. 限制数量limit
|--------------|--------------------|
| 限制行数 | limit 行数 |
| 从第i+1行开始限制行数 | limit 开始行(从0开始),行数 |
3. 去重distinct
不能查询目标列以外的列,distinct对象有几列就查询几列。
|----------|-------------------------------|
| 先查询再去重 | select distinct 列名 from 表名 |
| 同时作用两列去重 | select distinct 列1,列2 from 表名 |
4. 组合查询union
union用来执行多个查询,将结果合并成单个结果集返回。
|-----------------------------------------------------------|-----------------------------------------------------------|
| 联合多表查询(去重) 注: 每个查询都要包含相同数量的列 各个表对应列必须有相似的数据类型 | select 列a,列b,...from 表1 union select 列b,列c,...from 表2 |
| 联合两表查询(允许重复行) | select 列a,列b,...from 表1 union all select 列b,列c,...from 表2 |
5. 分组查询group
|-----------------------------------------------------------------------------------------|----------------------------------------|
| 创建分组 注: * 分组时如果有null,就会将null单独分为一组。 * Group by子句必须出现在where子句之后,order by子句之前 | Select 字段|聚合函数 from 表 Group by 字段 |
| 过滤分组 注: * Where是用来过滤行,having用来过滤分组的 * Having必须和where一起使用 | Select ... From 表 Group by 列 Having 条件 |
【n道例题】
【例1】:查询
table_01表中所有未删除的记录,按create_time降序排列【例2】:查询
table_01表,按is_delete升序、create_time降序排列【例3】
:查询table_01表中content字段长度前5长的记录,按内容长度降序排列【例4】:查询
table_01表中从第6条记录开始的10条记录(实现分页效果)【例5】:统计
table_01表中每个不同状态下的记录数量【例6】:将表
table_01实现多级排序:先按是否删除,再按内容长度,最后按创建时间
sql
#【例1】
select * from table_01 order by create_time desc;
#【例2】
select * from table_01 order by deleted_flag asc, create_time desc;
#【例3】
select * from table_01 order by length(content) desc limit 5;
#【例4】
select * from table_01 limit 5,5;
#【例5】
select distinct deleted_flag, count(*) as num from table_01 group by deleted_flag;
#【例6】
select * from table_01 order by deleted_flag, length(content), create_time;3.4.3 select子句的顺序

3.4.4 多表连接查询
|-----|------|---|--------------------------------------------------------|
| 笛卡尔积 || select * from 表1,表2; ||
| 内连接 | 等值连接 | select * from 表1 join 表2 on 表1.列=表2.列 ||
| | 非等值: | 注:连接条件不为相等判断的 ||
| | 自连接 | select 名字1.字段,名字2.字段 from 表 名字1 join 表 名字2 on 条件 注:涉及的两个表都是同一张表的查询 ||
| 外连接 | 左外连接 | left outer join 注:显示左表全部记录,右表满足连接条件的记录 ||
| | 右外连接 | right outer join 注:显示右表全部记录,左表满足连接条件的记录 ||
| 多次join on ||| select * from 表名 join 表1 on 条件1 join 表2 on 条件2 ...... |
【n道例题】
【例1】:查询同时出现在 table_03 和 table_04 中的水果
【例2】:通过水果关联对应的的蔬菜和动物(等值连接)
【例3】:查询夏季水果对应的动物相关信息
【例4】:查询维C含量高、价格适中、关联的动物不是濒危物种的水果
sql
#例1
select table_03.fruit_kind from table_03 join table_04 on table_03.fruit_kind = table_04.fruit_kind;
#例2
select t3.vegetable_kind,t4.animal_kind from table_03 as t3 join table_04 as t4 on t3.fruit_kind = t4.fruit_kind;
#例3
select fd.fruit_name,t4.animal_kind from fruits_detail as fd join table_04 as t4 on fd.fruit_name = t4.fruit_kind where fd.season = "夏季";
#例4:查询维C含量高、价格适中、关联的动物不是濒危物种的水果
SELECT DISTINCT t4.fruit_kind FROM table_04 as t4
JOIN fruits_detail as fd on t4.fruit_kind = fd.fruit_name
JOIN animals_detail as ad on t4.animal_kind = ad.animal_name
WHERE ad.is_endangered = 0 /*关联动物非濒危*/
AND fd.price BETWEEN 12 AND 20/*价格适中(自定)*/
ORDER BY fd.vitamin_c desc /*高维C*/
LIMIT 53.4.5 子查询
子查询一般指完成一个复杂的查询时,需要借助辅助查询的结果进行过滤或计算。 功用和"调用有返回值函数获取返回值"是类似的。子查询的SQL语句如下:
|---|---|---|---|
| 子查询 || select 字段1,... ,(select 字段|函数 from 表2 where ....)from 表1 where 条件 ||
子查询需要注意的如下:
- 嵌套在其他SQL语句内的查询语句,且必须出现在圆括号内(查询一般指select语句)
- 子查询的结果可以作为外层查询的过滤条件或计算字段。
- 子查询一般与not in结合使用,也可与其他运算符> < = !=一起使用
|------------------------------------------|
| all 表示与子查询结果集中的所有值进行比较,需要满足条件的是所有值。 |
| any和some 含义相同,与子查询的结果集中的值比较,有任意一个满足条件即可。 |
四、自定义SQL---Function
|------|------------------------------------------------------------------------------------------------------------------------------------------|
| 创建函数 | create function 函数名(参数1 数据类型....) returns 返回值类型 begin declare...; #使用SQL的方法来声明函数中的变量 函数逻辑代码; return...; end; |
| 调用函数 | select 函数名(参数1.....); |
| 删除函数 | drop function if exists 函数名; |
【例】:创建一个函数计算1+2+3+...+100 = ?
sql
# 如果函数已存在,先删除
DROP FUNCTION IF EXISTS f;
# 创建一个函数f计算1+2+3+...+100 = ?
create function f()
returns int
begin
declare sum int default 0;
declare i int default 1;
repeat
set sum = sum + i;
set i = i + 1;
until i > 100
end repeat;
return sum;
end;
##调用函数f
select f();其中使用repeat循环,使用方法很简单,仿照上面代码即可。