研究了 Clawdbot 的架构,包括它如何处理 Agent 执行、工具调用、浏览器操作等。对于 AI 工程师来说,这里有很多值得学习的地方。
深入了解 Clawd 的底层原理,能让你更好地理解这个系统的能力边界,最重要的是,搞清楚它擅长什么 以及不擅长什么。
这篇文章始于我个人的好奇心:Clawd 是如何处理内存的?它的可靠性究竟如何?在此,我将带你揭开 Clawd 运作机制的表层。
Clawd 在技术上究竟是什么?
大家都知道 Clawd 是一个个人助理,你可以在本地运行,也可以通过模型 API 在手机上轻松访问。但它的本质是什么?
从核心来看,Clawdbot 是一个 TypeScript CLI 应用程序。 它不是 Python,不是 Next.js,也不是一个网页应用。它是一个:
运行在你机器上的进程,并暴露一个 网关服务器(Gateway Server) 来处理所有频道连接(Telegram, WhatsApp, Slack 等)。
调用 LLM API(Anthropic, OpenAI, 本地模型等)。
在本地执行工具。
根据你的指令操控电脑。
核心架构
为了更简单地解释架构,以下是当你向 Clawd 发送消息到获得输出的完整过程:
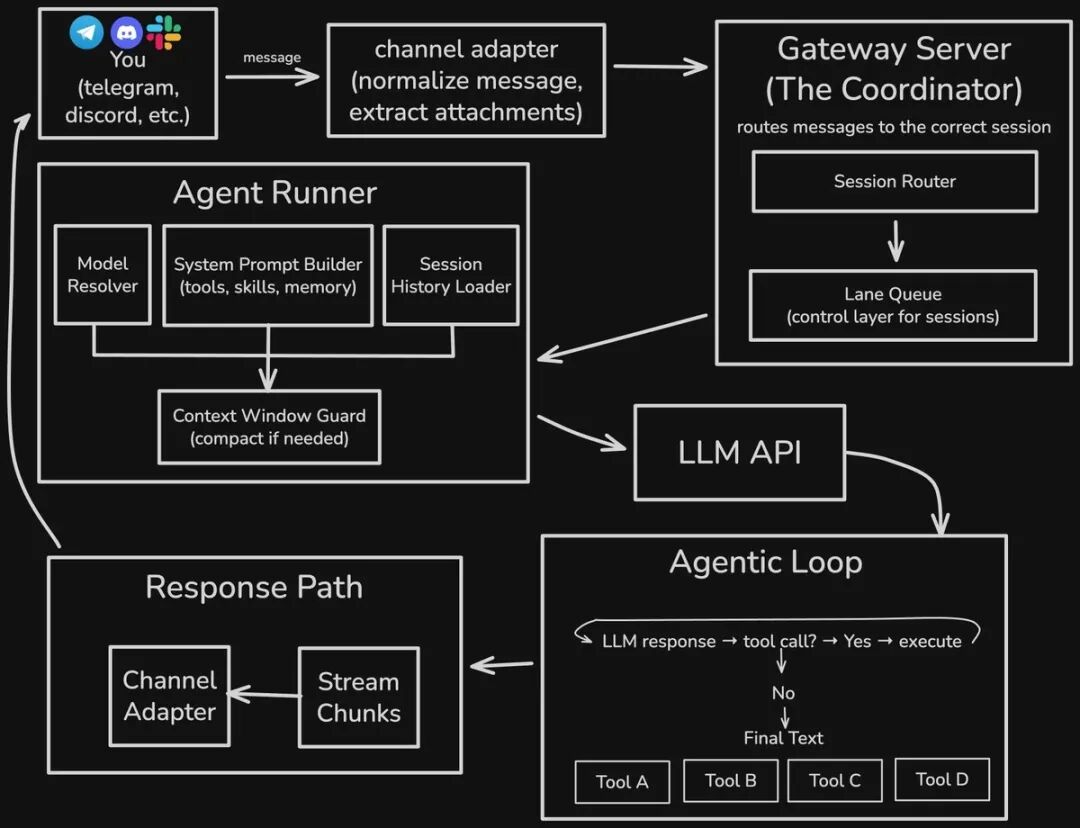
1. 频道适配器 (Channel Adapter)
适配器接收你的消息并进行预处理(标准化格式、提取附件)。不同的通讯软件和输入流都有对应的专用适配器。
2. 网关服务器 (Gateway Server)
网关服务器是任务/会话协调器,负责接收你的消息并将其分发到正确的会话中。它是 Clawd 的核心,能够处理多个重叠的请求。
为了使操作序列化 ,Clawd 使用了一种基于"泳道"(lane)的命令队列。每个会话都有其专属的泳道,而一些低风险的可并行任务(如定时任务 cron jobs)则在并行泳道中运行。
这与使用混乱的 async/await(异步逻辑乱象)形成了鲜明对比。过度并行会损害系统的可靠性,并带来海量的调试噩梦。
默认串行,显式并行
如果你开发过智能体(Agent),可能已经在某种程度上意识到这一点了。这也是 Cognition 在其《不要构建多智能体》(Don't Build Multi-Agents)博文中所表达的核心见解。
如果为每个智能体仅进行简单的异步设置,最终你会得到一堆交织在一起的垃圾信息。日志将变得不可读,而且如果它们共享状态,竞态条件(Race conditions) 将成为你在开发过程中必须时刻防范的恐惧。
"泳道"是对队列的一种抽象,它将序列化作为默认架构,而不是事后的补救措施。作为开发者,你只需编写逻辑代码,队列会自动为你处理竞态条件。
此时,你的心理模型将发生转变:从"我需要锁定(lock)什么?"变为"哪些任务是可以安全并行的?"。
3. Agent 运行器 (Agent Runner)
这是 AI 真正介入的地方。它决定使用哪个模型,选择 API 密钥(如果失效则将该配置标记为冷却并尝试下一个),并在主模型失败时切换到备用模型。
运行器会动态组装系统提示词(System Prompt) ,整合可用工具、技能、记忆,并添加会话历史(来自 .jsonl 文件)。随后通过 上下文窗口守护者 (Context Window Guard) 确保空间充足。如果窗口快满了,它会压缩会话(总结上下文)或优雅地报错。
3. 智能体运行器 (Agent Runner)
这是 AI 真正介入的地方。它负责确定使用哪个模型,挑选 API 密钥(如果所有密钥都失效,它会将该配置标记为"冷却"状态并尝试下一个),并在主模型失败时自动切换到备用模型。
智能体运行器会结合可用的工具、技能、记忆动态组装系统提示词(System Prompt),然后添加会话历史记录(来自 .jsonl 文件)。接着,这些内容会被传递给上下文窗口守护者 (Context Window Guard),以确保有足够的上下文空间。如果上下文空间即将填满,它要么会压缩会话(总结上下文内容),要么会优雅地报错并停止。
4. LLM API 调用
LLM 调用本身支持流式响应,并对不同的供应商进行了抽象层封装。如果模型支持,它还可以请求深度思考 (Extended Thinking)。
5. 智能体循环 (Agentic Loop)
如果 LLM 返回了工具调用(Tool Call)响应,Clawd 会在本地执行该操作并将结果添加到对话中。这个过程会不断重复,直到 LLM 给出最终的文本回复,或者达到了最大轮次限制(默认为 20 轮左右)。
这也是奇迹发生的地方:
电脑操作 (Computer Use):我稍后会详细介绍。
6. 响应路径 (Response Path)
这部分非常标准。响应通过频道(Channel)传回给你。同时,会话会持久化存储在一个基础的 .jsonl 文件中,每一行都是一个包含用户消息、工具调用、执行结果及模型响应的 JSON 对象。这就是 Clawd 的记忆方式(基于会话的记忆)。
以上涵盖了基础架构的内容。现在让我们深入探讨一些更为关键的组件。
Clawd 是如何"记住"的
如果没有完善的记忆系统,AI 助手就和金鱼没什么两样。Clawd 通过两个系统来处理记忆:
- 如前所述的 JSONL 格式会话转录文件。
- 存放在
MEMORY.md或memory/文件夹下的 Markdown 记忆文件。
在搜索方面,它采用了向量搜索(Vector Search)与关键词匹配(Keyword Match)的混合模式。这兼具了两者的优点:
- 当搜索"身份验证漏洞(authentication bug)"时,既能找到提到"登录问题(auth issues)"的文档(语义相关 ),也能匹配到包含精确词组的内容(关键词匹配)。
在技术实现上,向量搜索使用的是 SQLite ,而关键词搜索使用的是 FTS5(这也是一个 SQLite 扩展)。此外,嵌入模型(Embedding)的供应商是可配置的。
它还受益于 智能同步(Smart Synching) 功能,该功能由文件监控器(File Watcher)在探测到文件更改时触发。
这些 Markdown 文件是由智能体(Agent)本身使用标准的"写入文件"工具生成的。并没有专门的"记忆写入 API" ,智能体只是简单地向 memory/*.md 写入内容。当新对话开始时,一个钩子(Hook)会抓取之前的对话内容,并写下一份 Markdown 格式的摘要。
Clawd 的记忆系统简单得令人惊讶,与我们在 @CamelAIOrg 中作为"工作流记忆(Workflow Memories)"实现的方式非常相似。它没有记忆合并,也没有月度或周度的记忆压缩。
这种简洁性视视角不同,既可能是优势也可能是陷阱,但我始终更倾向于**"可解释的简洁"**,而非复杂的"意大利面式"乱麻架构。
在这种机制下,记忆会永久保存,且旧记忆与新记忆的权重基本相等,可以说它不存在"遗忘曲线"。
Clawd 的利爪:它如何操控你的电脑
这是 Clawd 的护城河 (MOAT) 之一:你直接给它一台电脑,并允许它使用。那么它是如何操控电脑的呢?基本上和你想象的差不多。
Clawd 赋予了智能体极高的电脑访问权限(风险由用户自担)。它使用一个 exec 工具在以下环境中运行 Shell 命令:
- 沙箱 (Sandbox):这是默认设置,命令在 Docker 容器中运行。
- 宿主机:直接在你的主机上运行。
- 远程设备:在远程机器上运行。
除此之外,Clawd 还拥有:
- 文件系统工具:支持读取、写入和编辑。
- 浏览器工具:基于 Playwright 开发,并使用"语义快照"。
- 进程管理 (Process tool):用于处理后台长期运行的命令、终止进程等。
安全性(或者说,真的有吗?)
与 Claude Code 类似,Clawd 拥有一个允许列表 (Allowlist),用于存放用户想要批准的命令(支持"允许一次"、"始终允许"或"拒绝"等用户提示)。
// ~/.clawdbot/exec-approvals.json
{
"agents":{
"main":{
"allowlist":[
{"pattern":"/usr/bin/npm","lastUsedAt":1706644800},
{"pattern":"/opt/homebrew/bin/git","lastUsedAt":1706644900}
]
}
}
}-
安全命令 :如
jq,grep,cut,sort,uniq,head,tail,tr,wc等,已经预先获得了批准。 -
危险的 Shell 结构:默认情况下会被拦截(例如重定向、命令替换或子 Shell 等操作)。
these get rejected before execution:
npm install $(cat /etc/passwd) # command substitution
cat file > /etc/hosts # redirection
rm -rf / || echo "failed" # chained with ||
(sudo rm -rf /) # subshell
这里的安全机制与 Claude Code 的设计非常相似。
其核心理念是:在用户允许的范围内,赋予智能体尽可能高的自主权。
浏览器:语义快照 (Semantic Snapshots)
浏览器工具并不主要依赖截图,而是使用 语义快照 。这是一种基于文本的页面 可访问性树(Accessibility Tree / ARIA) 的表示形式。
因此,智能体(Agent)看到的页面结构如下:
- button "Sign In" [ref=1]
- textbox "Email" [ref=2]
- textbox "Password" [ref=3]
- link "Forgot password?" [ref=4]
- heading "Welcome back"
- list
- listitem "Dashboard"
- listitem "Settings"这带来了四个显著优势。正如你可能已经猜到的,浏览网页的行为本质上并不一定是一项视觉任务。
- 体积差异 :一张截图的大小可能有 5 MB ,而语义快照通常不到 50 KB。
- 成本极低 :其消耗的 Token 开销仅为处理图像所需成本的一小部分。
- 精准度:相比于在像素图像上定位坐标,直接操作文本节点引用的成功率更高。
- 速度:纯文本的解析速度远快于计算机视觉(CV)对图像的理解。
原文:https://x.com/Hesamation/status/2017038553058857413\[1\]