author:何绍泽前言:
SQL解析广义上分为词法解析和语法解析,pg数据库中词法解析用的是Flex语言,语法解析用的是Bison语言。而其他产品也会使用yacc语言,但本质上都是对sql语言文本的解析成语法树,语法树再经语义解析转为查询树。从而形成一个对于pg而言更好处理的结构。
词法解析:
词法解析相对于语法解析属于一个独立的模块,但两者又是相互关联。词法解析独立来讲,是把一条text文本切分为单个的TOKEN格式,而TOKEN正是我们在语法解析中所定义的如下:
src/backend/parser/gram.y 675:
/*选自gram.y文件代码片段*/
%token <str> IDENT UIDENT FCONST SCONST USCONST BCONST XCONST Op
%token <ival> ICONST PARAM
%token TYPECAST DOT_DOT COLON_EQUALS EQUALS_GREATER
%token LESS_EQUALS GREATER_EQUALS NOT_EQUALS规则又是由于不同的TOKEN组成,而规则是语法解析的主要部分,我们放在后续讲解。接上,在词法解析阶段,当一条text文本进入,根据定义的TOKEN识别文本被解析成不同的TOKEN。(如果你的TOKEN未定义则报语法错)
而所有的TOKEN,我们将定义在src/include/parser/kwlist.h文件中,词法解析的依据就是该文件中你定义的TOKEN。部分片段如下:
src/include/parser/kwlist.h 27:
/* name, value, category, is-bare-label */
PG_KEYWORD("abort", ABORT_P, UNRESERVED_KEYWORD, BARE_LABEL)
PG_KEYWORD("absent", ABSENT, UNRESERVED_KEYWORD, BARE_LABEL)
PG_KEYWORD("absolute", ABSOLUTE_P, UNRESERVED_KEYWORD, BARE_LABEL)因此,词法分析主要内容就是对token进行解析,当然token的样式很多,也就对应了不同的处理规则。不同的符号等都定义了不同的规则,具体请学习Flex语言。上述就是简单的一个词法解析要走的过程,当然它的功能远不止这些,这里只引入了比较易懂的例子。
语法解析:
语法解析看似是在词法之后,实则在pg过程中一边解析TOEKN,一边就开始进行语法分析了。
语法解析也有它自己的主要功能:定义一系列语法规则,我们大量SQL语句每个SQL语句组合内容都不同,同一条建表语句,表名不同,列数量不同都是另一条sql语句,如下:
create table t1(id int,name varchar);
create table b1(id int,name varchar);
create table t1(id int);上述都是属于不同的sql语句,但都嵌套在同一条规则中,这就是语法解析规则定义的作用。
上述的语句中 我们可以把表明 t1、b1抽象成一个变量叫table_name ,把括号里的列用一个list变量管理起来叫optlist;那么上述语句就可以抽象成:
create table table_name '(' optlist')' 这就是一条规则,因为规则最终也是需要被存储或者标识,所以给规则一个lable,creatstmt:
creatstmt:
create table table_name '(' optlist')' 至此,上述你就写成了一条规则,在任何create table table_name '(' optlist')' 这一类的sql语句都会被这个规则识别被标为createstmt 如下:
src/backend/parser/gram.y 3510:
/*****************************************************************************
*
* QUERY :
* CREATE TABLE relname
*
*****************************************************************************/
CreateStmt: CREATE OptTemp TABLE qualified_name '(' OptTableElementList ')'
OptInherit OptPartitionSpec table_access_method_clause OptWith
OnCommitOption OptTableSpace
{
CreateStmt *n = makeNode(CreateStmt);
$4->relpersistence = $2;
n->relation = $4;
n->tableElts = $6;
n->inhRelations = $8;
n->partspec = $9;
n->ofTypename = NULL;
n->constraints = NIL;
n->accessMethod = $10;
n->options = $11;
n->oncommit = $12;
n->tablespacename = $13;
n->if_not_exists = false;
$$ = (Node *) n;
}那么他是如何识别的?
这就是语法解析最关键的一个理论知识移进规约。
移进归约
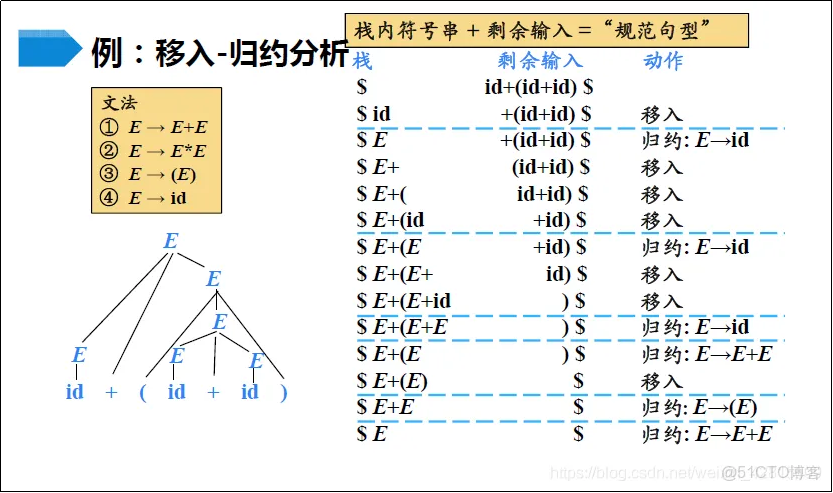
如上图所示,什么时候移进?什么时候归约?
当token被词法切分完以后,就开始来做移进归约。我们所定义的规则对应的就是图1中的文法。
解读图中的步骤:
1 切分好的文本输入,正如id+(id+id)这对应的就是我们的sql语句部分。
2 第一个token id入栈。
3 检查栈内token是否有适配的文法,id 可以归约成E(这在文法中定义了),所以这一步做归约操作。id换成E。
4 继续在栈里填入token + 。
5 检查栈内 E + 没有文法对应,则继续移进。
6 一直移进直到有相应的文法对应。如 ( 后id移进后就又可以归约成E,id部分用替换,其余不变。
7重复上述步骤 直至所有token 移入完成。
上述就是一个完整的移进归约原理。用这样的方式在我们语法解析的众多规则中,寻找到你这条sql语句对应的规则。
移进归约冲突
当在添加语法规则时,容易出现移进归约冲突,学了上述原理我们应该知道,移进归约冲突是因为,一个TOEKN,语法解析在处理时不知道这个TOKEN该规约还是该移进。
常见的冲突:
reduce/reduce冲突:多条规则可规约当前token.
shift/reduce冲突:既可移进也可规约token.
查找冲突位置:
命令如下:
cd src/backend/parser
/usr/bin/bison -Wno-deprecated -d -o gram.c gram.y -Wcounterexamples
bison -W gram.y 打印出状态
bison -v gram.y 生成.Out文件总结
词法解析和语法解析协同工作,构成了 SQL 语句理解的前端。词法解析提供结构化的"单词",语法解析则通过"移进归约"算法,使用预定义的规则将这些"单词"组装成"句子",最终生成可执行的抽象语法树。深入理解这一过程及其潜在的冲突,是进行数据库内核开发、语法扩展及深度定制的关键基础。