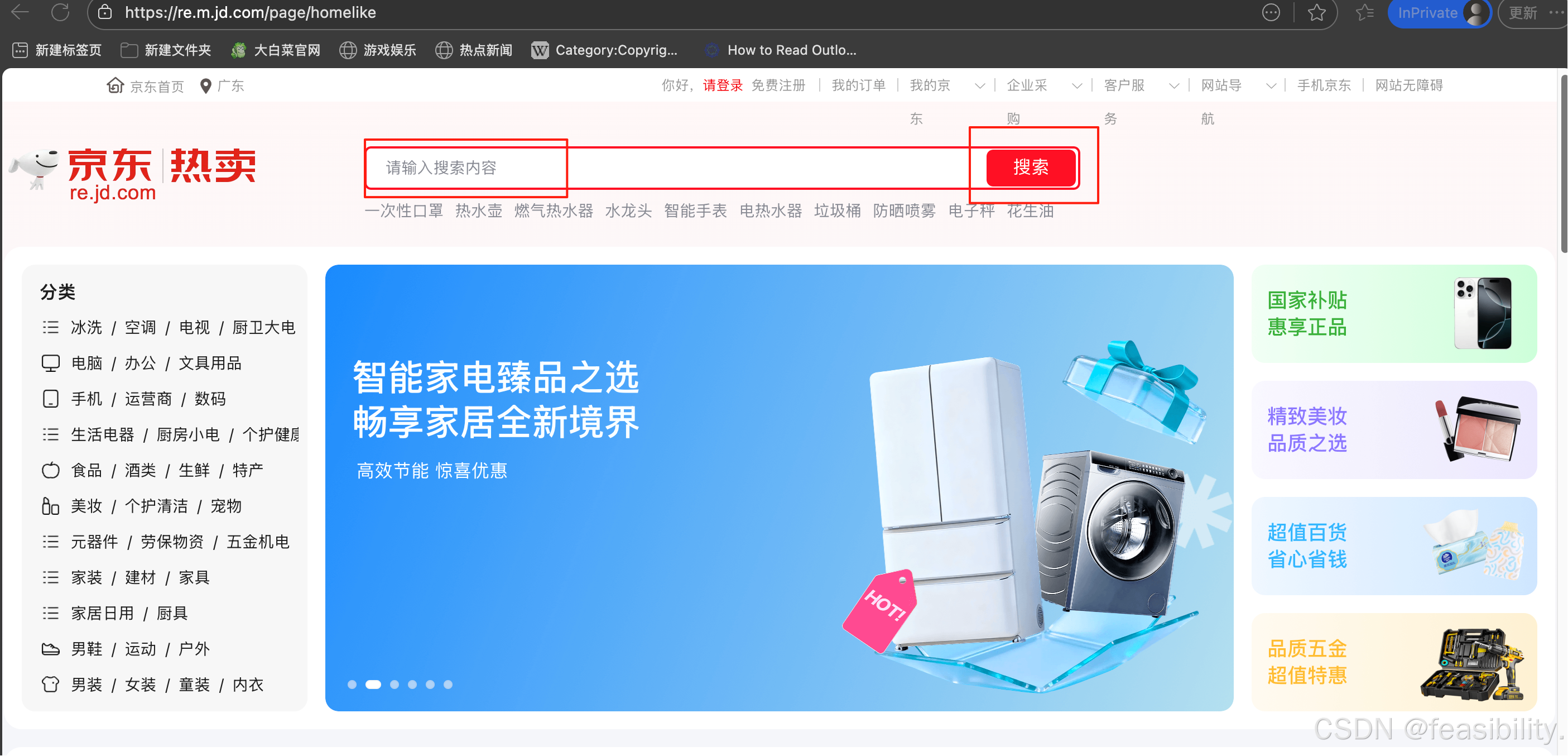
打开京东平台(https://re.m.jd.com/page/homelike),点击搜索框,输入你感兴趣的商品,比如衣服,点击搜索按钮
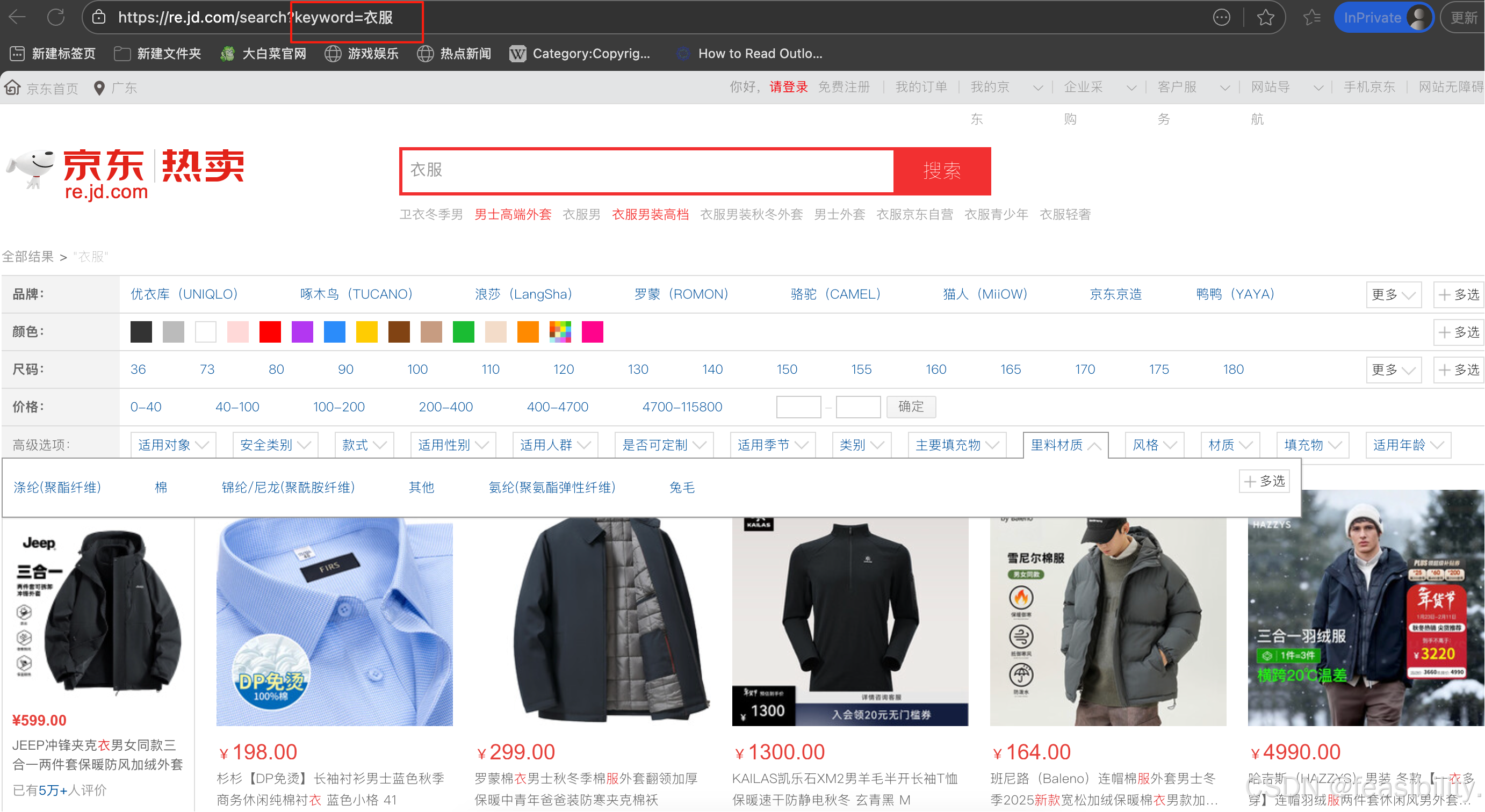
你可以发现链接https://re.jd.com/search?keyword=关键词
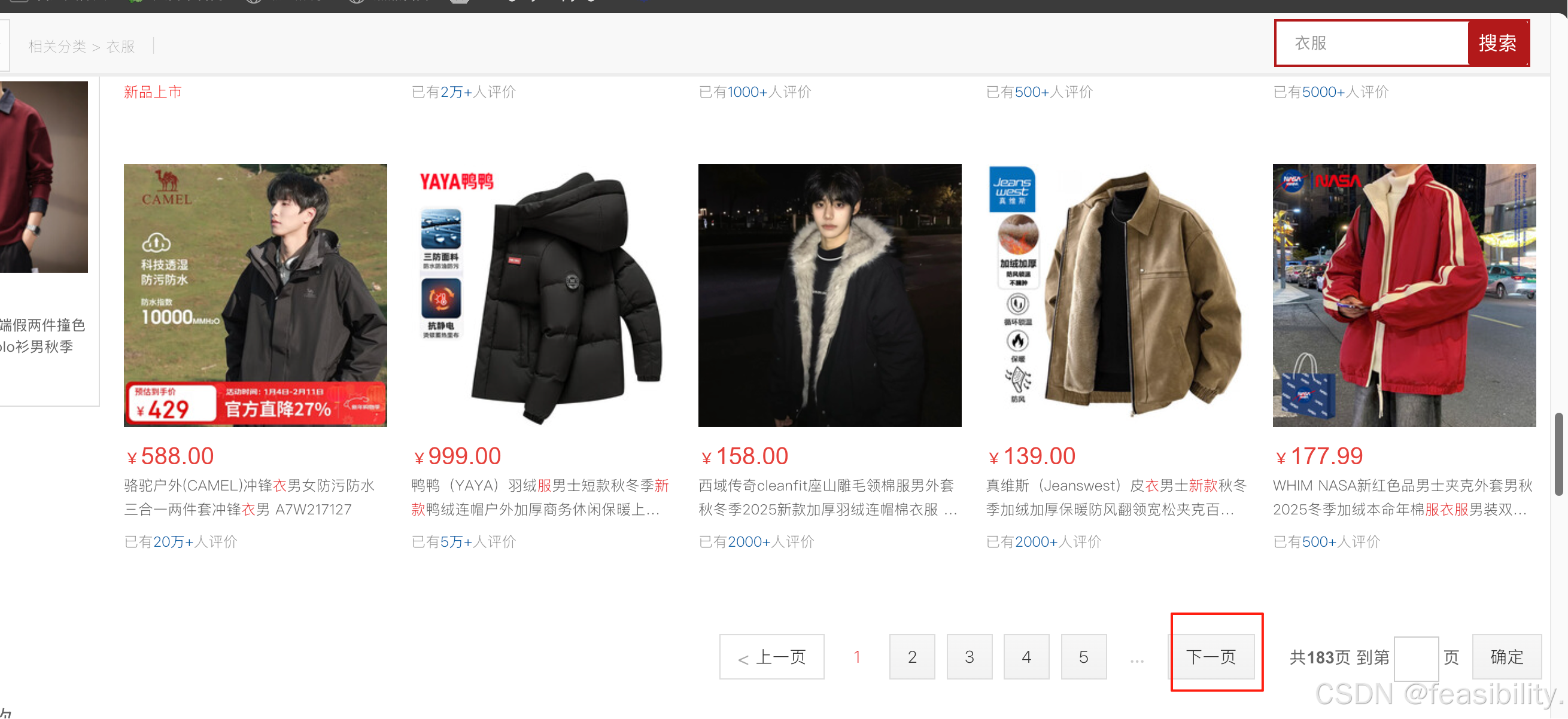
下拉,点击下一页按钮
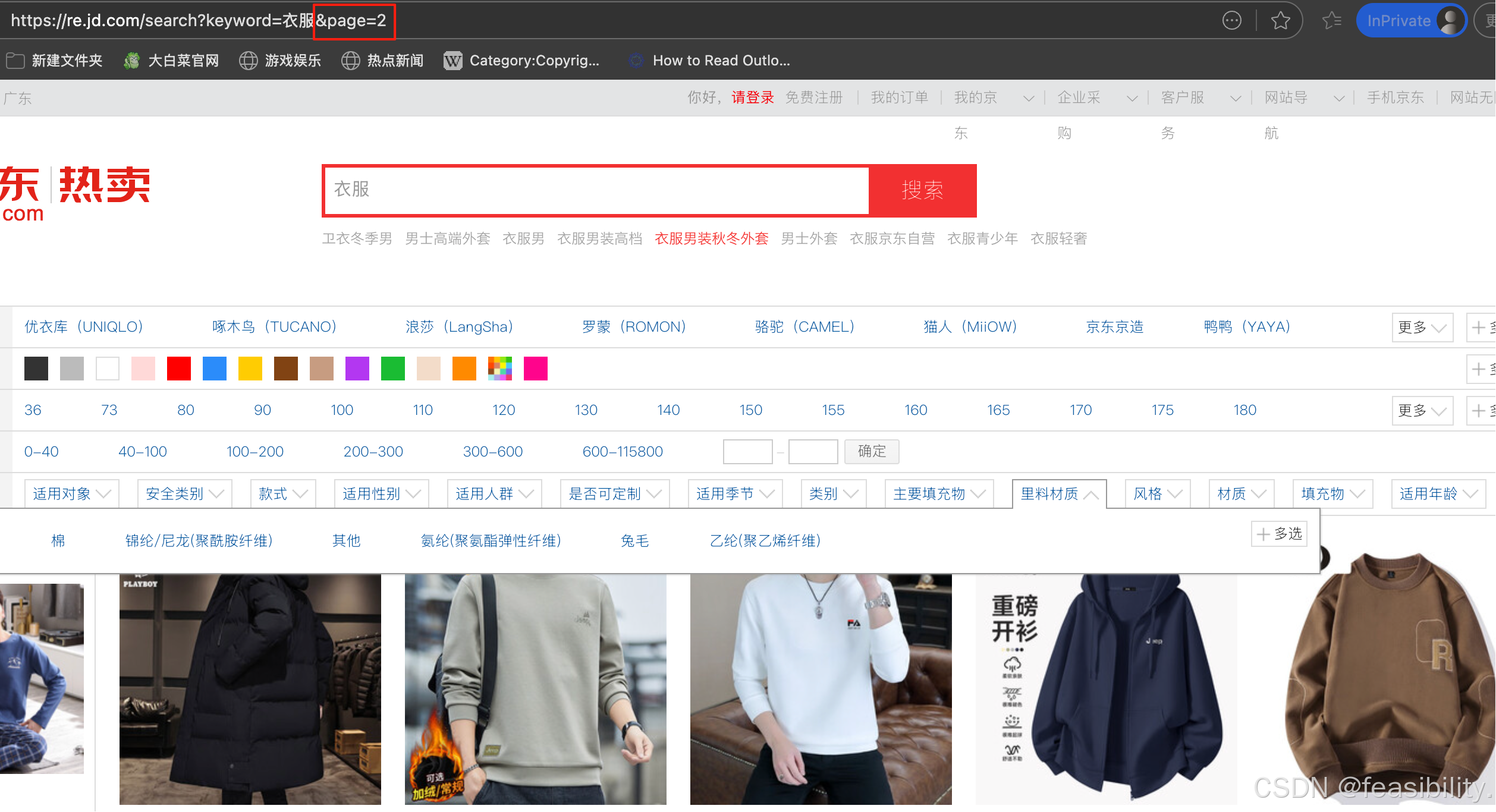
可以看出page是页面参数
点击鼠标右键,会出现右键菜单,里面有"检查"(Chrome/Edge)或"检查元素"(Firefox)等类似选项(这与浏览器相关),点击后会出现开发者工具(DevTools),选择元素,再点击下图1的'鼠标'图标,然后指向商品,你会发现主页商品的元素与"shop_list"这个id元素有关,按CTRL+F,输入xpath语句//ul@id="shop_list"/li,可以发现找到40个元素
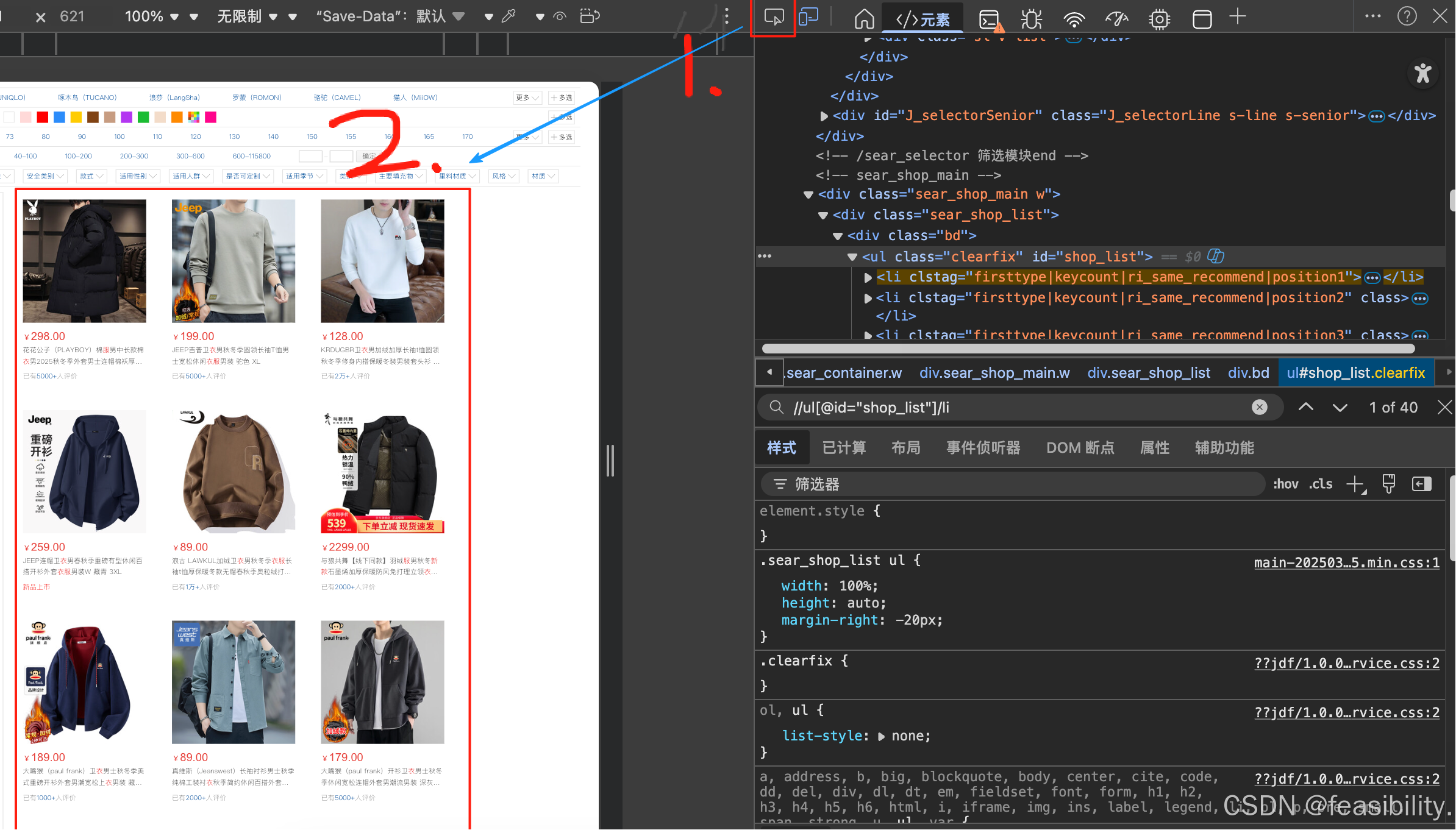
点击红框可以一次确认是否都是商品元素
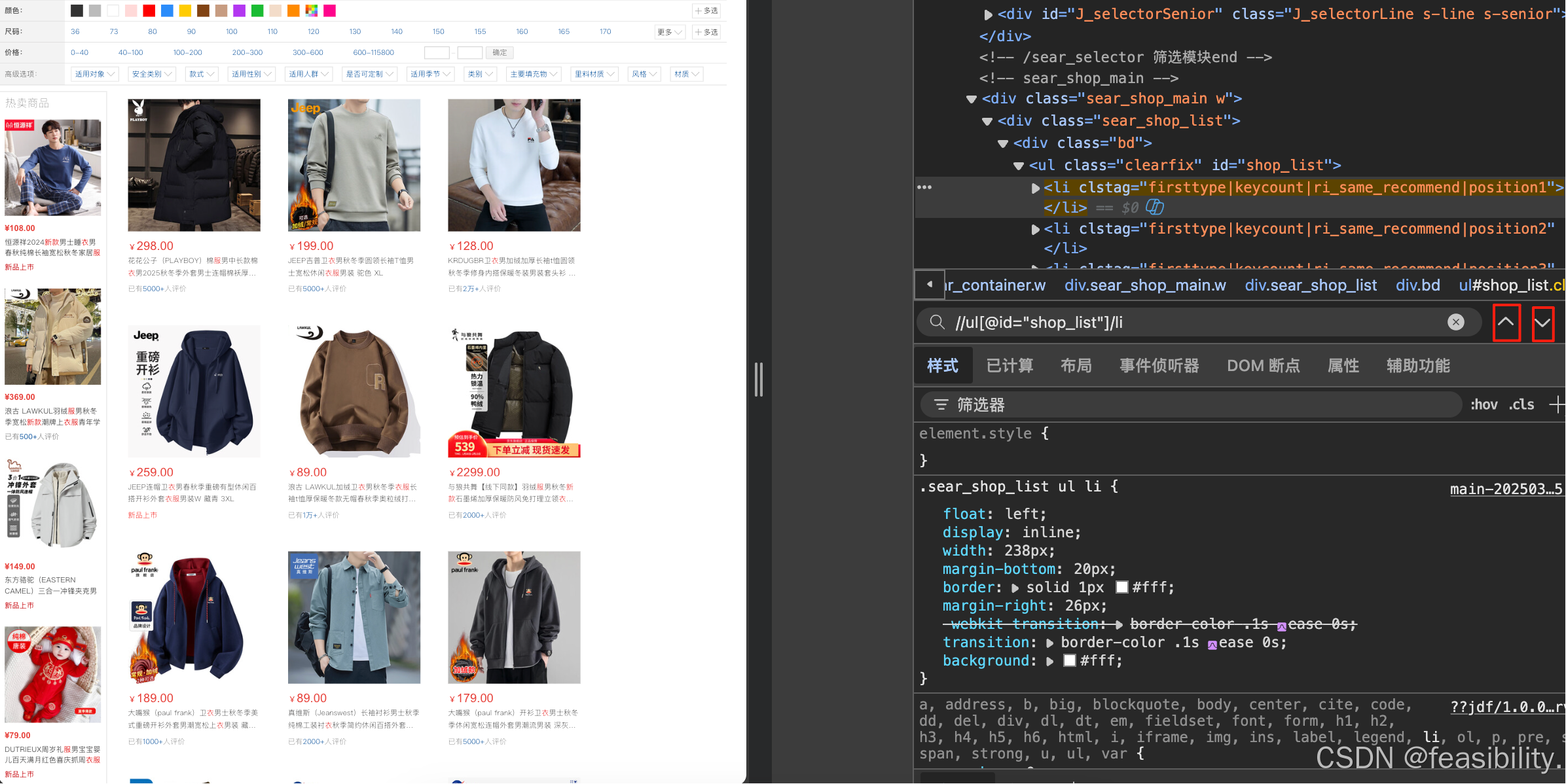
同样的方法,可以定位到价格元素,这里//是可以跳过中间间隔的xpath元素路径,其他xpath定位类似,这里不做演示
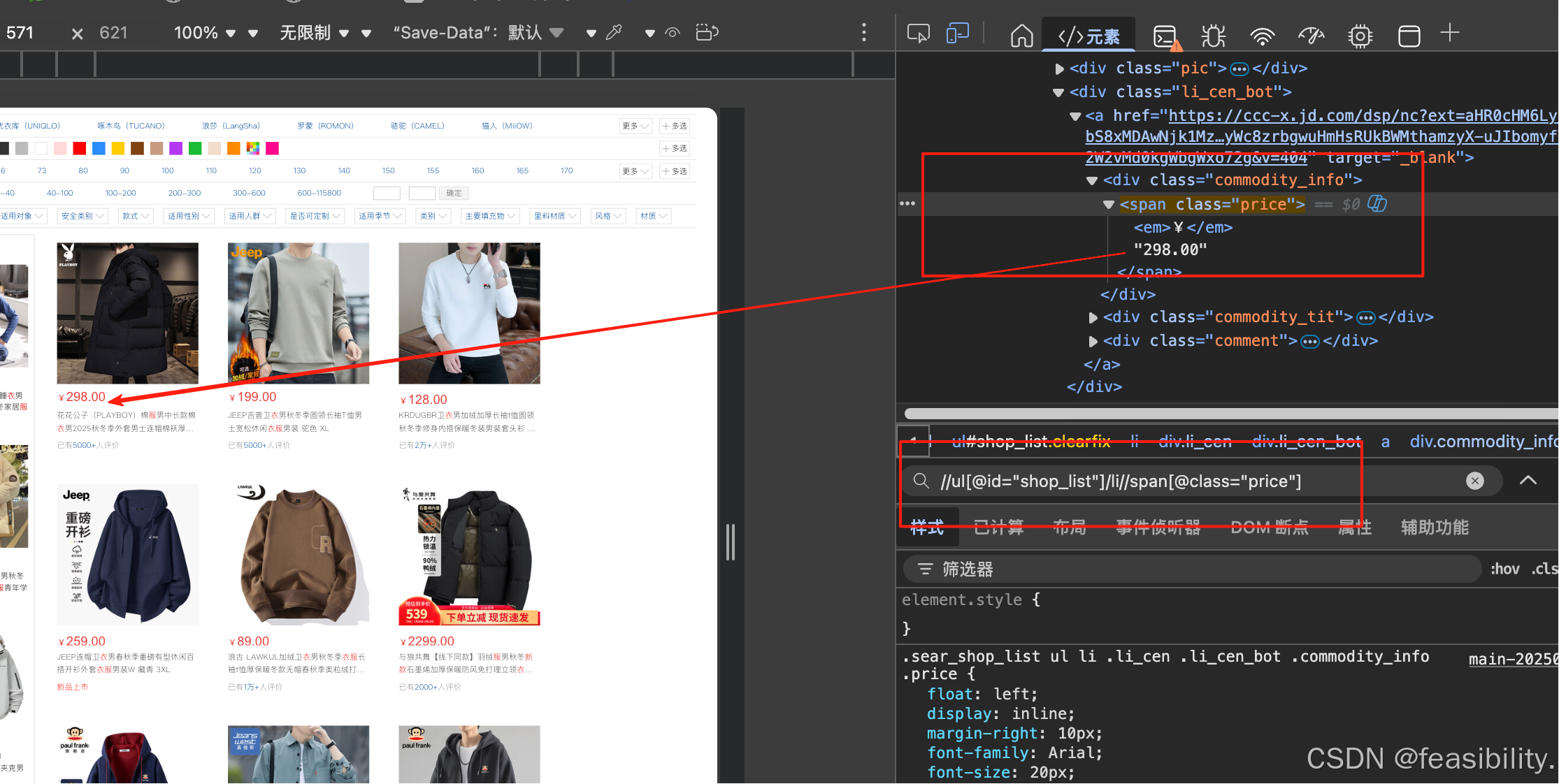
编写爬虫脚本采集商品的标题、图片、价格等信息,为了提高加载网页速度,没有渲染图片,还采用添加请求头、模拟滚动、随机等待和去除自动化标记等反反爬措施简单应对风控
python
import asyncio
import csv
import random
from pathlib import Path
import aiohttp
from playwright.async_api import async_playwright, TimeoutError as PlaywrightTimeoutError
# 配置
BASE_URL = 'https://re.jd.com/search?keyword={keyword}&page={page}'
OUTPUT_DIR = Path('./jd_data')
OUTPUT_DIR.mkdir(exist_ok=True)
IMAGE_DIR = OUTPUT_DIR / 'images'
IMAGE_DIR.mkdir(exist_ok=True)
OUTPUT_FILE = OUTPUT_DIR / 'all_data.csv'
MAX_IMAGE_SIZE = 1000 # 最大宽高
FIELDNAMES = ['title', 'price', 'img_url', 'img_name', 'page', 'status']
async def fetch_page(page, url, retries=3):
delays = [3, 4, 5]
for i in range(retries):
try:
print(f"打开页面: {url}")
await page.goto(url, timeout=15000)
return True
except PlaywrightTimeoutError:
if i < retries - 1:
await asyncio.sleep(delays[i] + random.random())
else:
print(f"页面加载失败: {url}")
return False
async def scroll_page(page):
"""模拟人类不规则滚动"""
for _ in range(random.randint(3, 8)):
scroll_amount = random.randint(300, 1200)
await page.mouse.wheel(0, scroll_amount)
# 非线性等待,模拟阅读时间
await asyncio.sleep(random.uniform(0.5, 4.0))
# 随机回滚(真实用户常回滚查看)
if random.random() < 0.3:
await page.mouse.wheel(0, -random.randint(100, 400))
await asyncio.sleep(random.uniform(0.5, 1.5))
async def parse_page(page, page_num):
data = []
items = await page.query_selector_all('//ul[@id="shop_list"]/li')
for idx, item in enumerate(items):
try:
img = await item.eval_on_selector('div.li_cen > div > a > img', 'e => e.getAttribute("src")')
if img and img.startswith('//'):
img = 'https:' + img
title = await item.eval_on_selector('//div[@class="commodity_tit"]', 'e => e.textContent')
price = await item.eval_on_selector('div.li_cen > div > a > div > span.price', 'e => e.textContent')
if img and title and price:
data.append({
'title': title.strip(),
'price': price.strip(),
'img_url': img,
'img_name': f'{page_num}_{idx}.jpg',
'page': page_num,
'status': 'pending'
})
except:
continue
return data
async def append_csv(data):
write_header = not OUTPUT_FILE.exists()
with open(OUTPUT_FILE, 'a', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, fieldnames=FIELDNAMES)
if write_header:
writer.writeheader()
writer.writerows(data)
async def download_image(session, item):
url = item['img_url']
filename = IMAGE_DIR / item['img_name']
delays = [1, 3, 5]
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36',
'Referer': 'https://re.jd.com/', # 必须添加
'Accept': 'image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8',
}
for i in range(3):
try:
async with session.get(url, timeout=20, headers=headers) as resp:
if resp.status == 200:
content = await resp.read()
with open(filename, 'wb') as f:
f.write(content)
item['status'] = 'success'
print(f"下载图片成功: {filename}")
return
except:
if i < 2:
await asyncio.sleep(delays[i] + random.random())
item['status'] = 'failed'
print(f"图片下载失败: {url}")
async def main(keyword, max_page):
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)#True
context = await browser.new_context(
java_script_enabled=True,
viewport={'width': 1280, 'height': 800},
user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36',
bypass_csp=True,
accept_downloads=False
)
#去除自动化工具标记
await context.add_init_script("""
Object.defineProperty(navigator, 'webdriver', {get: () => undefined});
Object.defineProperty(navigator, 'plugins', {get: () => [
{name: "Chrome PDF Plugin", filename: "internal-pdf-viewer"},
{name: "Widevine Content Decryption Module", filename: "widevinecdmadapter.dll"}
]});
Object.defineProperty(navigator, 'languages', {get: () => ['zh-CN', 'zh', 'en-US', 'en']});
window.chrome = { runtime: {} };
// 覆盖 permissions API
const originalQuery = window.navigator.permissions.query;
window.navigator.permissions.query = (parameters) => (
parameters.name === 'notifications' ?
Promise.resolve({state: Notification.permission}) :
originalQuery(parameters)
);
""")
async def route_intercept(route, request):
if request.resource_type == "image":
await route.abort()
else:
await route.continue_()
page = await context.new_page()
await page.route("**/*", route_intercept)
all_data = []
# 先采集所有页面数据并追加写入CSV
for page_num in range(1, max_page + 1):
url = BASE_URL.format(keyword=keyword, page=page_num)
success = await fetch_page(page, url)
if not success:
continue
await asyncio.sleep(2 + random.random()*3)
await scroll_page(page)
page_data = await parse_page(page, page_num)
print(f"采集页面 {page_num} 数据: {len(page_data)} 条")
all_data.extend(page_data)
await append_csv(page_data)
if page_num%5==0:
await asyncio.sleep(random.uniform(2,5))
if page_num % 10 == 0:
await asyncio.sleep(5)
await asyncio.sleep(10)
# 下载图片
async with aiohttp.ClientSession() as session:
for idx, item in enumerate(all_data):
await download_image(session, item)
await asyncio.sleep(3 + random.random())
if (idx + 1) % 10 == 0:
await asyncio.sleep(5)
# 最后更新下载状态到CSV
with open(OUTPUT_FILE, 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, fieldnames=FIELDNAMES)
writer.writeheader()
writer.writerows(all_data)
if __name__ == '__main__':
keyword = '服装'#input('请输入搜索关键词: ')
max_page = 10#int(input('请输入最大页数: '))
asyncio.run(main(keyword, max_page))运行展示
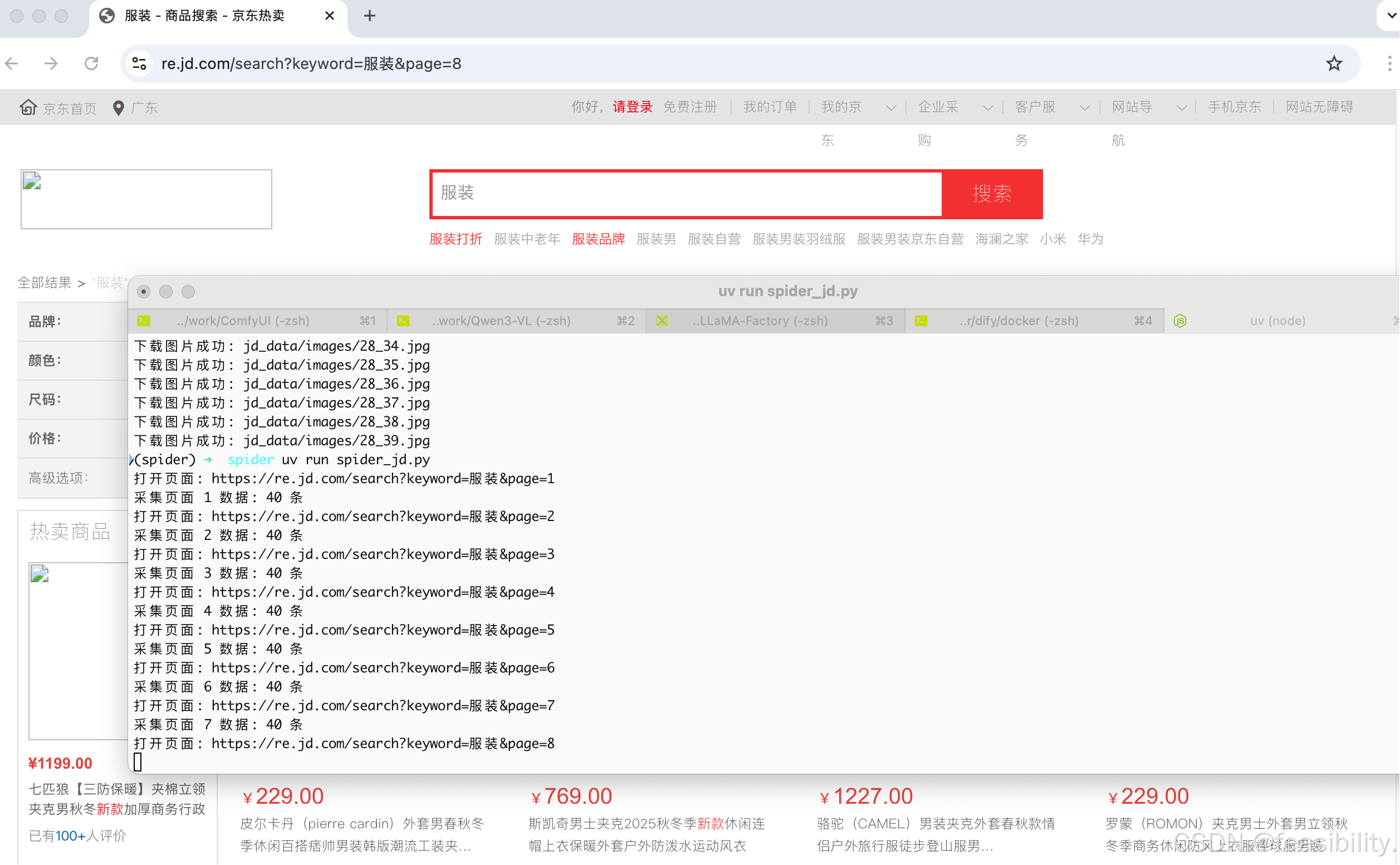
大概15页就会采集不到数据,可以采取代理池切换ip、增加延时等待时间和多账号模拟登陆等手段应对
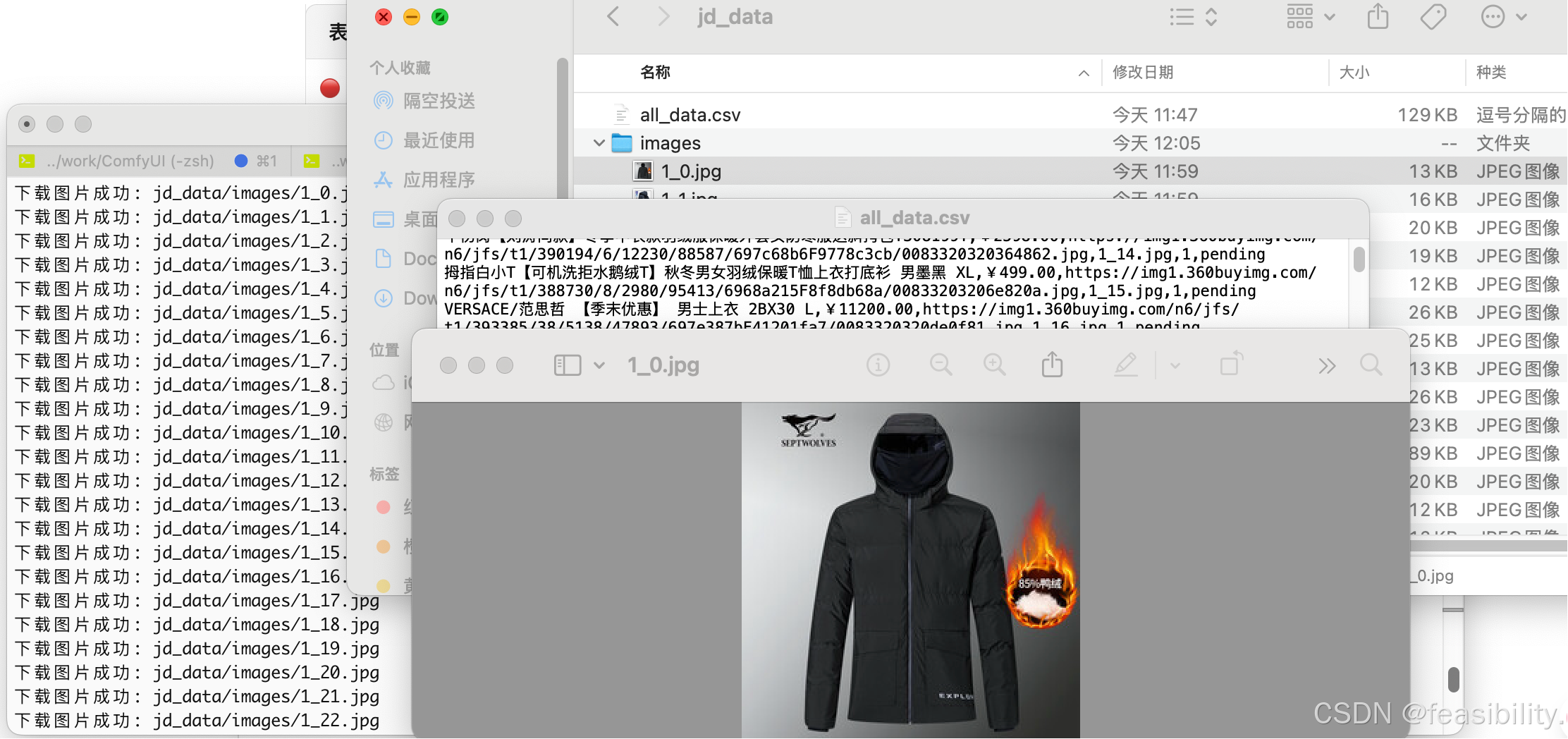
结果展示
本文仅供学习参考,不得用于违法犯罪
创作不易,禁止抄袭,转载请附上原文链接及标题