本文是 DTS按业务场景批量迁移阿里云MySQL表实战(上):技术选型和API对接 的后续,应用状态模式,完成业务系统中的迁移模块。DTS的对接方式可参考前文。
迁移管理平台设计与实现
完成DTS API对接后,就需要考虑如何将DTS和业务系统有机结合实现整套的迁移流程。
出于信息安全角度的考虑,本文删除了大量涉及实际业务的实现代码。
业务约束
从业务出发,最好的体验肯定是用户无感的,即迁移完成后,确认新旧表数据一致,直接切换到新表查询。
显然过于理想化了,如果迁移期间,用户对旧表进行了写入,新表可能会少数据,不能贸然切换,要做数据的对比。如果用户一直在写入,就要一直反复的对比、确认,有增量数据就要删除新表重新迁移,流程复杂。
和业务方沟通,得知对方可以禁止写入正在迁移的公司的表,等迁移完成后再恢复使用。这样流程就简单多了,开始迁移时,将旧表重命名增加特殊的后缀,就能防止用户操作,并确保旧表数据不发生变更。
技术校验
如何判断一个公司是否迁移成功?最严谨的方式是逐表逐行数据对比,但是在使用DTS的情况下并无必要。我采取的比较策略是,在迁移前后:
-
源表目标表数量相同
-
对应表数据量相同、数据最后更新时间(如有此列)相同
只要满足以上要求,就认为数据是一致的。可以通过SELECT COUNT(*), MAX(updateTime) FROM table_name一次性获取。
迁移状态机
经过分析和简化,迁移状态机如下:
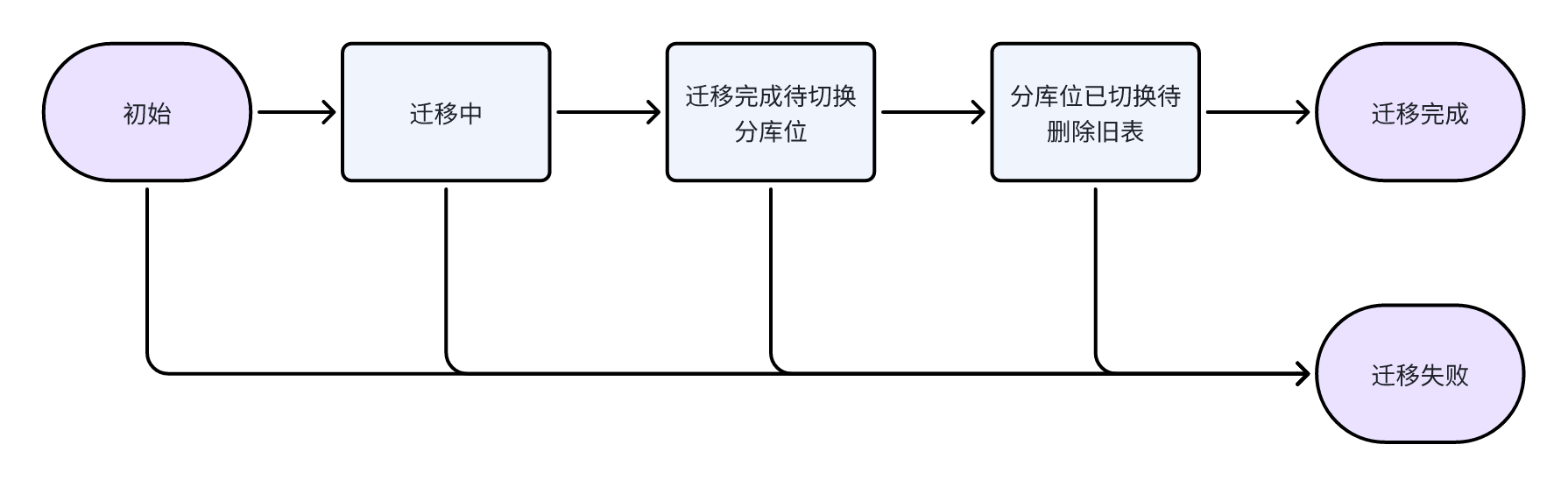
可以发现,每个状态都可以进行"推进"和"回滚"两个动作,很适合使用状态模式来实现。状态模式的实现先放一放,看看几个基本数据结构:
迁移任务
Java
@Data
public class TableMigrateTask {
// 主键
private Long id;
// 公司id
private Long companyId;
// 原始分库位
private Long oldSchemaId;
// 新分库位
private Long newSchemaId;
// 任务状态
private Integer state;
// DTS任务状态,和阿里云定义一致
private String dtsStatus;
// DTS任务已删除(释放)
private Boolean dtsDeleted;
// DTS实例id
private String dtsInstanceId;
// DTS任务id
private String dtsJobId;
// 失败原因
private String failedReason;
// 状态跳转时的信息,辅助排查问题
private String transitInfo;
// 迁移前表数据统计,json格式,表名、数据量、最后更新时间
private String tableStatisticsSrc;
// 迁移表结果统计,json格式kv结构,表名-数据量
private String tableStatisticsDest;
}迁移上下文
迁移状态机实际处理的对象,封装了一些服务,可以视为领域对象(充血模型)。
Java
@Setter
public class TableMigrateExecuteContext {
// 持有的任务对象
@Getter
private TableMigrateTask tableMigrateTask;
// 当前的状态
@Getter
private TableMigrateState currentState;
private TableMigrateTaskRepository tableMigrateTaskRepository;
private TableMigrateQueryService tableMigrateQueryService;
private TableMigrateService tableMigrateService;
private TableArchiveService tableArchiveService;
private DataSourceHolder dataSourceHolder;
public void createInstanceAndConfigureDtsJob() {
// 调用DTS API创建任务
}
public DescribeDtsJobDetailResponse queryDtsMigJob() {
// 调用DTS API查询
}
public void switchRoute(long oldSchemaId, long newSchemaId) {
// 将分表以外的单表update为newSchemaId
}
public void stopDtsMigJob() {
// 调用DTS API停止
}
public void updateTableMigrateTask(TableMigrateTask modifiedTask) {
// 更新持有的任务(持久化)
}
/**
* 状态推进
*
* @return 返回信息,不成功时非空
*/
public String forward() {
return currentState.forward(this);
}
/** 状态回滚 */
public String rollback() {
return currentState.rollback(this);
}
/**
* 重命名旧表
*
* @param forward true-迁移场景,加------migold,反之则不加
* @param ignoreExited 是否忽略已存在的表,仅在初始态的回滚场景可用
*/
public void renameOldTableNames(boolean forward, boolean ignoreExited) {
// 注意要考虑源库中是否存在和旧表相同的同名表
}
public void updateDestTableInfo() {
// 更新目标表的统计信息
}
public void archiveNewTables(List<String> needArchiveTables) {
// 归档新表
}
/**
* 删除表
*
* @param newTable true-新表,false-旧表
*/
public void deleteTables(boolean newTable) {
// 批量执行DROP TABLE
}
public void deleteDtsInstanceAndJob() {
// 调用DTS API释放实例
}
}工厂类
Java
@Component
public class TableMigrateContextFactory {
@Resource private TableMigrateTaskRepository tableMigrateTaskRepository;
@Resource private TableMigrateQueryService tableMigrateQueryService;
@Resource private TableMigrateService tableMigrateService;
@Resource private TableArchiveService tableArchiveService;
@Resource private DataSourceHolder dataSourceHolder;
public TableMigrateExecuteContext buildContext(long taskId) {
TableMigrateTask task = tableMigrateTaskRepository.getById(taskId);
if (task == null || task.getStatus() == 0) {
throw new BizException("表迁移任务不存在或已被删除");
}
TableMigrateExecuteContext context = new TableMigrateExecuteContext();
context.setTableMigrateTask(task);
context.setCurrentState(buildState(TableMigrateStateEnum.getByValue(task.getState())));
// 服务注入
context.setTableMigrateTaskRepository(tableMigrateTaskRepository);
context.setTableMigrateQueryService(tableMigrateQueryService);
context.setTableMigrateService(tableMigrateService);
context.setTableArchiveService(tableArchiveService);
context.setDataSourceHolder(dataSourceHolder);
return context;
}
private TableMigrateState buildState(TableMigrateStateEnum stateEnum) {
switch (stateEnum) {
case INIT:
return new MigrateInitState();
case FAILED:
return new MigrateFailedState();
case PROCESSING:
return new MigrateProcessingState();
case NEED_SWITCH:
return new MigrateNeedSwitchState();
case SWITCHED:
return new MigrateSwitchedState();
case FINISH:
return new MigrateFinishState();
default:
throw new BizException("迁移状态非法");
}
}
}迁移状态
我在做本次的系统设计时,对状态模式做了一些回顾和参考。迁移状态是状态模式的核心,从设计模式的角度来看,状态模式"允许对象在其内部状态改变时动态调整自身行为,使得对象的表现形态如同修改了其所属类。"
以下是各个类的继承关系:
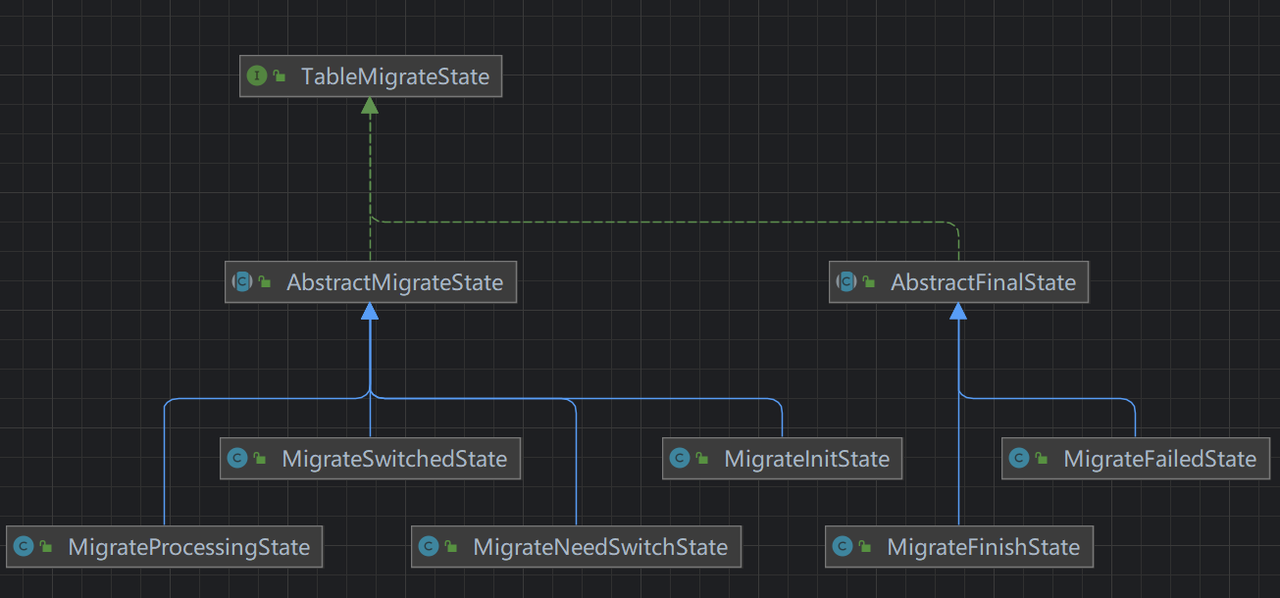
对应的状态如下:
| 类名 | 含义 | 说明 |
| TableMigrateState | 接口定义 | |
| AbstractMigrateState | 状态抽象类 | |
| AbstractFinalState | 终态抽象类 | 终态很多操作都是不支持的,和AbstractMigrateState分开更简洁 |
| MigrateInitState | 初始 | 记录要迁移的统计数据和配置 |
| MigrateProcessingState | 迁移中 | DTS进行迁移动作的状态 |
| MigrateNeedSwitchState | 迁移完成待切换分库位 | 数据已同步在新表,但还不可以通过业务功能直接访问 |
| MigrateSwitchedState | 分库位已切换待删除旧表 | 数据已同步在新表,且能通过业务功能直接访问 |
| MigrateFinishState | 迁移完成 | 数据已同步在新表且能访问,旧表已删除 |
| MigrateFailedState | 迁移失败 | 回滚,旧表恢复访问,新表如果有则删除 |
状态接口
Java
public interface TableMigrateState {
/**
* 前进到下一状态
*
* @param context
* @return 失败的提示信息
*/
String forward(TableMigrateExecuteContext context);
/**
* 回滚操作
*
* @param context
* @return 失败的提示信息
*/
String rollback(TableMigrateExecuteContext context);
/**
* 获取当前的状态对应枚举
*/
TableMigrateStateEnum getState();
/**
* 获取下一个状态
*/
TableMigrateState getNextState();
/**
* 获取回滚的状态
*/
TableMigrateState getRollbackState();
}状态抽象类
TypeScript
public abstract class AbstractMigrateState implements TableMigrateState {
@Override
public String forward(TableMigrateExecuteContext context) {
TableMigrateTask task = context.getTableMigrateTask();
// 1. 前置校验
// 根据校验结果,判断是留在当前状态,还是直接回滚到迁移失败状态
// 2. 实际动作,由实现类完成
// 简单起见,在实际动作里的异常都自动回滚
// 3. 状态跳转
transit(context, getNextState());
return null;
}
@Override
public String rollback(TableMigrateExecuteContext context) {
TableMigrateTask task = context.getTableMigrateTask();
// 1. 当前状态校验
checkCurrentState(context);
// 2. 回滚操作,如果发生异常,保持在当前状态
// 3. 状态跳转
transit(context, getRollbackState());
return null;
}
/**
* 前置校验
*
* @param context
*/
protected PreCheckResult preCheck(TableMigrateExecuteContext context) {
return checkCurrentState(context);
}
protected PreCheckResult checkCurrentState(TableMigrateExecuteContext context) {
// 检查当前状态是否符合预期,构造检查结果
}
/**
* 改变当前执行上下文状态, 不做其他的业务操作
*
* @param context
* @param nextState
*/
private void transit(TableMigrateExecuteContext context, TableMigrateState nextState) {
TableMigrateTask task = context.getTableMigrateTask();
task.setState(nextState.getState().getValue());
context.updateTableMigrateTask(task);
context.setCurrentState(nextState);
}
protected abstract void doForward(TableMigrateExecuteContext context);
/**
* 回滚操作
*
* <p>需要保证幂等,如果单个回滚操作失败,可以重复执行
*
* @param context
*/
protected abstract void doRollback(TableMigrateExecuteContext context);
/**
* 旧表更名
*
* @param context
* @param forward true-迁移场景,旧表加后缀; false-回滚场景,旧表删除后缀
*/
protected void renameOldTableNames(
TableMigrateExecuteContext context, boolean forward, boolean ignoreExited) {
context.renameOldTableNames(forward, ignoreExited);
}
/**
* 删除新表
*
* <p>新表的删除,最好不要共用这个方法
*
* @param context
*/
protected void deleteNewTables(TableMigrateExecuteContext context) {
context.deleteTables(true);
}
/** 前置校验结果 */
@Data
@AllArgsConstructor
public static class PreCheckResult {
/** 中断,需要回滚 */
public static final int ABORT = -1;
/** 校验通过 */
public static final int PASS = 0;
/** 校验不通过,保持原有状态 */
public static final int NOT_PASS = 1;
private int code;
private String msg;
public static PreCheckResult buildPass() {
return new PreCheckResult(PASS, null);
}
public boolean isPass() {
return this.code == PASS;
}
}
}终态抽象类
TypeScript
public abstract class AbstractFinalState implements TableMigrateState {
@Override
public String forward(TableMigrateExecuteContext context) {
return "当前状态【" + getState().getValue() + " " + getState().getDes() + "】已是终态,不能进行下一步操作";
}
@Override
public String rollback(TableMigrateExecuteContext context) {
return "当前状态【" + getState().getValue() + " " + getState().getDes() + "】已是终态,不能进行撤销操作";
}
@Override
public TableMigrateState getNextState() {
throw new BizException("当前状态" + getState().getValue() + "已是终态,没有后续状态可跳转");
}
@Override
public TableMigrateState getRollbackState() {
throw new BizException("当前状态" + getState().getValue() + "已是终态,没有后续撤销态可跳转");
}
}初始
TypeScript
public class MigrateInitState extends AbstractMigrateState {
@Override
protected void doForward(TableMigrateExecuteContext context) {
TableMigrateTask task = context.getTableMigrateTask();
if (task.getOldSchemaId().equals(task.getNewSchemaId())) {
throw new BizException("迁移前后的分库位id相同");
}
// 1. 旧表更名, 直接阻止后续的变更
// 归档不影响RENAME
renameOldTableNames(context, true, false);
// 2. 创建DTS任务并回写到task字段
// 创建失败则直接抛异常,回滚
// 此处DTS任务是直接提交执行的,并不能确定当前实际是哪个状态,因此状态留空
context.createInstanceAndConfigureDtsJob();
}
@Override
protected void doRollback(TableMigrateExecuteContext context) {
// 初始态回滚时,旧表可能还没有更名
renameOldTableNames(context, false, true);
}
@Override
public TableMigrateStateEnum getState() {
return TableMigrateStateEnum.INIT;
}
@Override
public TableMigrateState getNextState() {
return new MigrateProcessingState();
}
@Override
public TableMigrateState getRollbackState() {
return new MigrateFailedState();
}
}迁移中
TypeScript
public class MigrateProcessingState extends AbstractMigrateState {
/** DTS-未初始化的状态 */
private static final Set<String> DTS_NOT_INIT =
Sets.newHashSet(
DtsJobStatusEnum.NOT_STARTED.getCode(), DtsJobStatusEnum.NOT_CONFIGURED.getCode());
/** DTS-处理中的状态 */
private static final Set<String> DTS_PROCESSING =
Sets.newHashSet(
DtsJobStatusEnum.PRECHECKING.getCode(),
DtsJobStatusEnum.PRECHECK_PASS.getCode(),
DtsJobStatusEnum.INITIALIZING.getCode(),
DtsJobStatusEnum.SYNCHRONIZING.getCode(),
DtsJobStatusEnum.MIGRATING.getCode(),
DtsJobStatusEnum.SUSPENDING.getCode(),
DtsJobStatusEnum.MODIFYING.getCode(),
DtsJobStatusEnum.RETRYING.getCode(),
DtsJobStatusEnum.UPGRADING.getCode(),
DtsJobStatusEnum.DOWNGRADING.getCode(),
DtsJobStatusEnum.LOCKED.getCode());
/** DTS-失败的状态 */
private static final Set<String> DTS_FAILED =
Sets.newHashSet(
DtsJobStatusEnum.PRECHECK_FAILED.getCode(),
DtsJobStatusEnum.INITIALIZE_FAILED.getCode(),
DtsJobStatusEnum.FAILED.getCode(),
DtsJobStatusEnum.MIGRATION_FAILED.getCode());
@Override
public PreCheckResult preCheck(TableMigrateExecuteContext context) {
checkCurrentState(context);
// 校验DTS任务已完成
TableMigrateTask task = context.getTableMigrateTask();
DescribeDtsJobDetailResponse dtsJobDetailResponse = context.queryDtsMigJob();
if (dtsJobDetailResponse == null || dtsJobDetailResponse.getBody() == null) {
return new PreCheckResult(
PreCheckResult.NOT_PASS,
String.format(
"DTS任务结果查询失败, 返回结果为空。instanceId=%s, jobId=%s",
task.getDtsInstanceId(), task.getDtsJobId()));
}
DescribeDtsJobDetailResponseBody responseBody = dtsJobDetailResponse.getBody();
if (BooleanUtils.isNotTrue(responseBody.getSuccess())) {
return new PreCheckResult(
PreCheckResult.NOT_PASS,
String.format(
"DTS任务结果查询失败, 接口调用结果为失败。instanceId=%s, jobId=%s",
task.getDtsInstanceId(), task.getDtsJobId()));
}
DtsJobStatusEnum dtsJobStatusEnum = DtsJobStatusEnum.getByCode(responseBody.getStatus());
if (dtsJobStatusEnum == null) {
return new PreCheckResult(
PreCheckResult.NOT_PASS,
String.format(
"DTS任务状态非法,请稍后重试。instanceId=%s, jobId=%s, 阿里云状态=%s",
task.getDtsInstanceId(), task.getDtsJobId(), responseBody.getStatus()));
}
task.setDtsStatus(dtsJobStatusEnum.getCode());
if (DTS_NOT_INIT.contains(dtsJobStatusEnum.getCode())) {
return new PreCheckResult(
PreCheckResult.NOT_PASS,
String.format(
"DTS任务状态异常,尚未初始化。instanceId=%s, jobId=%s, 阿里云状态=%s",
task.getDtsInstanceId(), task.getDtsJobId(), responseBody.getStatus()));
}
if (DTS_PROCESSING.contains(dtsJobStatusEnum.getCode())) {
return new PreCheckResult(
PreCheckResult.NOT_PASS,
String.format(
"DTS任务仍在处理中。instanceId=%s, jobId=%s, 阿里云状态=%s",
task.getDtsInstanceId(), task.getDtsJobId(), responseBody.getStatus()));
}
if (DTS_FAILED.contains(dtsJobStatusEnum.getCode())) {
return new PreCheckResult(
PreCheckResult.ABORT,
String.format(
"DTS任务执行失败。instanceId=%s, jobId=%s, 阿里云状态=%s",
task.getDtsInstanceId(), task.getDtsJobId(), responseBody.getStatus()));
}
if (StringUtils.equals(DtsJobStatusEnum.FINISHED.getCode(), dtsJobStatusEnum.getCode())) {
return PreCheckResult.buildPass();
}
return new PreCheckResult(
PreCheckResult.NOT_PASS,
String.format(
"DTS任务状态非法。instanceId=%s, jobId=%s, 阿里云状态=%s",
task.getDtsInstanceId(), task.getDtsJobId(), responseBody.getStatus()));
}
@Override
protected void doForward(TableMigrateExecuteContext context) {
// 已在校验时更新任务状态,并根据DTS执行状态判断要不要回滚
// 1. 将迁移后的表,按照原表的状态进行归档
// 2. 写入迁移后的表统计信息
context.updateDestTableInfo();
}
@Override
protected void doRollback(TableMigrateExecuteContext context) {
// 1. 尝试中止DTS任务,对已完成的DTS任务调用不会抛异常
// 2. 新表删除
deleteNewTables(context);
// 3. 旧表名称还原
renameOldTableNames(context, false, false);
}
@Override
public TableMigrateStateEnum getState() {
return TableMigrateStateEnum.PROCESSING;
}
@Override
public TableMigrateState getNextState() {
return new MigrateNeedSwitchState();
}
@Override
public TableMigrateState getRollbackState() {
return new MigrateFailedState();
}
}迁移完成待切换分库位
TypeScript
public class MigrateNeedSwitchState extends AbstractMigrateState {
@Override
protected void doForward(TableMigrateExecuteContext context) {
// 单表路由切换
context.switchRoute(
context.getTableMigrateTask().getOldSchemaId(),
context.getTableMigrateTask().getNewSchemaId());
}
@Override
protected void doRollback(TableMigrateExecuteContext context) {
// 1. 新表删除
deleteNewTables(context);
// 2. 旧表名称还原
renameOldTableNames(context, false, false);
// 3. 单表和路由恢复
// 可能已经在forward时做过,因此也做复原
context.switchRoute(
context.getTableMigrateTask().getNewSchemaId(),
context.getTableMigrateTask().getOldSchemaId());
}
@Override
public TableMigrateStateEnum getState() {
return TableMigrateStateEnum.NEED_SWITCH;
}
@Override
public TableMigrateState getNextState() {
return new MigrateSwitchedState();
}
@Override
public TableMigrateState getRollbackState() {
return new MigrateFailedState();
}
}分库位已切换待删除旧表
TypeScript
public class MigrateSwitchedState extends AbstractMigrateState {
@Override
protected void doForward(TableMigrateExecuteContext context) {
// 删除旧表
context.deleteTables(false);
}
@Override
protected void doRollback(TableMigrateExecuteContext context) {
// 1. 新表删除
deleteNewTables(context);
// 2. 旧表名称还原
renameOldTableNames(context, false, false);
// 3. 单表和路由恢复
context.switchRoute(
context.getTableMigrateTask().getNewSchemaId(),
context.getTableMigrateTask().getOldSchemaId());
}
@Override
public TableMigrateStateEnum getState() {
return TableMigrateStateEnum.SWITCHED;
}
@Override
public TableMigrateState getNextState() {
return new MigrateFinishState();
}
@Override
public TableMigrateState getRollbackState() {
return new MigrateFailedState();
}
}迁移完成
Java
public class MigrateFinishState extends AbstractFinalState {
@Override
public TableMigrateStateEnum getState() {
return TableMigrateStateEnum.FINISH;
}
}迁移失败
Java
public class MigrateFailedState extends AbstractFinalState {
@Override
public TableMigrateStateEnum getState() {
return TableMigrateStateEnum.FAILED;
}
}操作流程
-
创建迁移任务TableMigrateTask
-
通过工厂类,使用任务id创建包含迁移任务TableMigrateTask的迁移上下文TableMigrateExecuteContext
-
调用TableMigrateExecuteContext的forward()推进状态、rollback()回滚状态
查询相关功能实现
DTS任务列表查询
因为已经把DTS的相关字段持久化了,可以通过业务系统相关的迁移任务表实现分页查询。
不过在"迁移中"跳转到"迁移完成待切换分库位"的过程中,DTS也会经历多个状态,典型的有Prechecking、Migrating、Finished等(见DescribeDtsJobDetail_数据传输_API文档的Status字段说明),可以通过接口获取最新的状态并写入迁移任务表。
如何查询待迁移的表?
回顾一下,要迁移的表分以下三种形式:
-
后缀是公司id,如table_companyId
-
后缀是 公司_年份,如table_company_year
-
后缀是业务id,如table_bizId
对于同一个前缀,以companyId=123为例,第一、三种表都可以精确匹配:
-
第一种表每个公司只有一张,比如table_a_123、table_b_123;
-
第三种表每个bizId同一个公司只有一张,比如bizId可以取1、2,那么会存在table_c_1、table_c_2、table_d_1、table_d_2,并且,bizId是有限的,可以从一张bizId_table表获取所有可选值。
-
对于第二种表year的取值范围,虽然可以类似bizId一样去找,但是并没有直接的关系表。
我想到了两种方案,最后选择了第二种。
SHOW TABLES LIKE查询指定前缀
这是最先考虑到的方案,比较直接,而且在开发、测试环境中运行良好。但是在线上就不行了,将所有表查询一次要数分钟,调用早已超时。我想这应该和线上环境表数量过多导致元数据获取变慢有关,每次查询需要上百ms,累计耗时长达数分钟。
DatabaseMetaData一次性获取所有表后过滤
可以通过DataSource的元数据,一次性获取数据源对应库的所有的表,再将表名进行过滤。经过测试,10W级数据获取全部表的时间在3~7S之间,和方案一相比快很多。
以下代码片段展示了如何获取所有表名,忽略异常处理。
Java
String physicalSchemaName = dataSourceHolder.getPhysicalSchemaName(logicalSchemaName);
HikariDataSource dataSource = dataSourceHolder.getDataSourceByPhysicalSchemaName(physicalSchemaName);
try (Connection connection = dataSource.getConnection()) {
DatabaseMetaData metaData = connection.getMetaData();
ResultSet catalogs = metaData.getCatalogs();
while (catalogs.next()) {
String tableCat = catalogs.getString("TABLE_CAT");
if (!StringUtils.equals(tableCat, physicalSchemaName)) {
// 判断库名是否一致。如果多个库实际上在同一个RDS实例,元数据实际上是这些库的,而非单个库的
continue;
}
// 获取指定数据库中的所有表名
ResultSet tableResultSet =
metaData.getTables(physicalSchemaName, null, "%", new String[] {"TABLE"});
int count = 0;
while (tableResultSet.next()) {
count++;
String physicalTableName = tableResultSet.getString("TABLE_NAME");
// 确定是否是要查的表,判断逻辑此处省略【注1】
}
LoggerUtils.info("本次共查询了" + count + "个表的元数据");
}
LoggerUtils.info(
"获取" + physicalSchemaName + "库的所有表元数据总耗时:" + (System.currentTimeMillis() - t1) + "ms");
} catch (SQLException e) {
LoggerUtils.error("获取分库元数据失败, 发生SQL异常", e);
throw new BizException("获取分库元数据失败, 发生SQL异常", e);
}
}对数据库中每个表判定它是否是当前公司的表,对于第一、三种表,可以将后者放到一个HashSet中,每次循环时对比;对于第二种表,字符串前缀匹配无疑要花大量的时间。
为了加速前缀匹配,可以使用经典的数据结构------前缀匹配树。前缀匹配树的代码如下:
Java
public class StringPrefixTrie {
private final Node root = new Node();
static class Node {
boolean isEnd;
Map<Character, Node> children = new HashMap<>();
}
/**
* 增加一个待匹配的模式
*
* @param pattern
*/
public void addPattern(String pattern) {
Node current = root;
for (char c : pattern.toCharArray()) {
current = current.children.computeIfAbsent(c, k -> new Node());
}
current.isEnd = true;
}
/**
* 是否满足前缀匹配
*
* @param str
* @return
*/
public String match(String str) {
Node current = root;
for (int i = 0; i < str.length(); i++) {
current = current.children.get(str.charAt(i));
if (current == null) {
// 没有匹配到任何前缀
return null;
}
if (current.isEnd) {
// 返回匹配到的任意一个前缀
return str.substring(0, i + 1);
}
}
return null;
}
}对所有需要前缀匹配的表的前缀调用addPattern(),在循环中先判断是否满足前缀匹配,再判断精准匹配即可。
后续规划
-
批量迁移功能,将迁移批量化、自动化:
-
批量捞取公司,判断是否需要迁移、迁移成本。理想情况下,数据量少但表多的公司,是迁移到其他库的最佳候选,大大降低源库的表量又节约了复制数据的时间
-
多个公司id提交、创建任务、状态流转
-
-
自动校验迁移是否成功