项目场景:
一个甲方的ceph集群,osd日志拉满导致根目录100%
问题描述
甲方联系说有点问题,远程处理。
首先登陆到控制节点发现根目录满了,检查定位到日志目录,所有osd日志大小几乎一致。
然后检查所有存储节点都有类似问题。
打开日志文件分析原因,下面放三个osd日志的截图
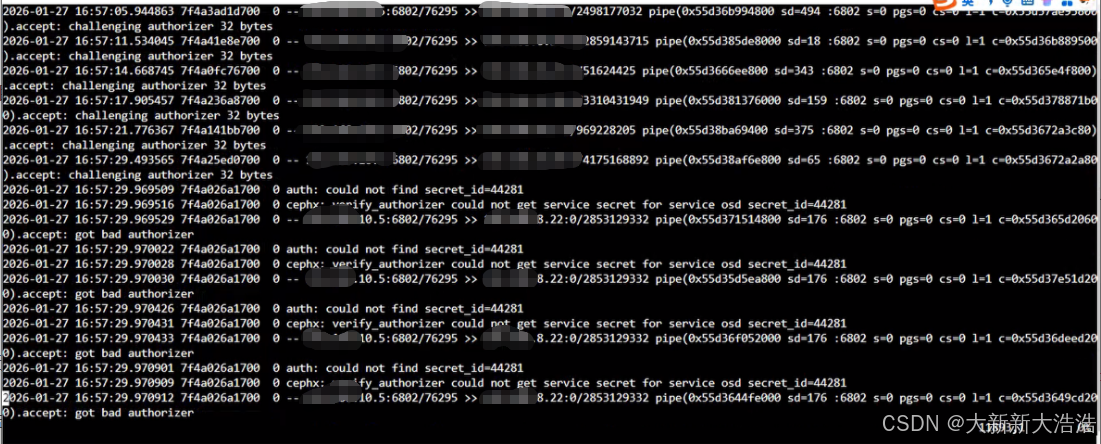
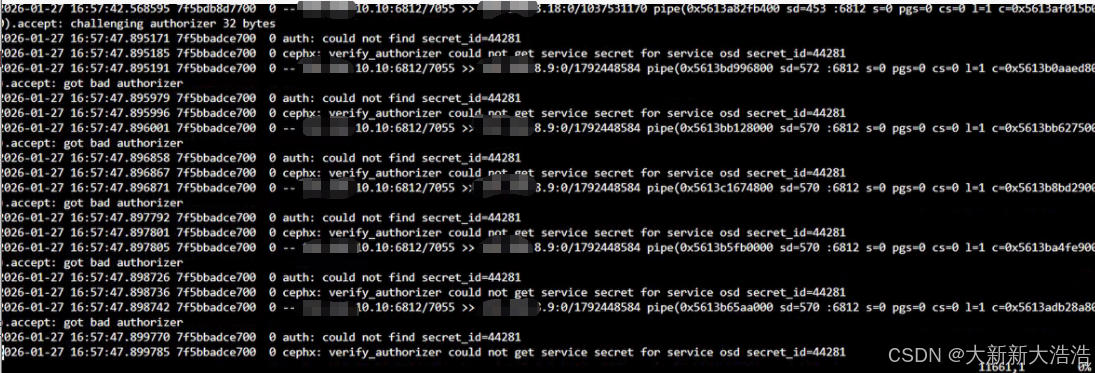
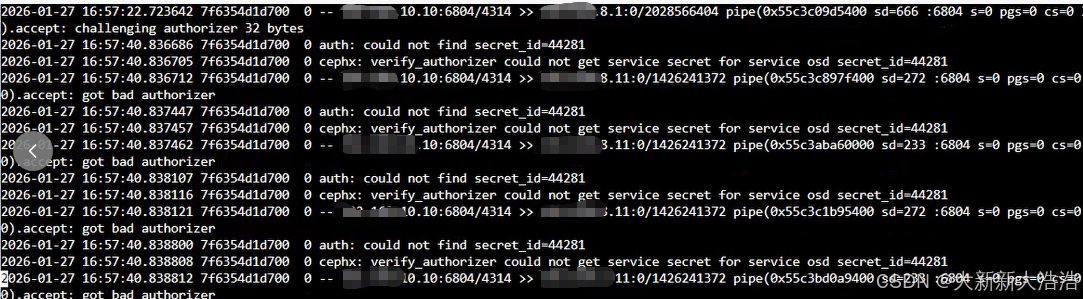
全部在16:57 指向到secret_id:44281
原因分析:
千问的回答
- auth: could not find secret_id=44281
含义:Ceph Monitor(或 OSD)在验证某个客户端身份时,找不到 ID 为 44281 的密钥。
✅ 这个 secret_id 是 Ceph 内部生成的唯一标识,用于关联一个实体(如 osd.5)的认证密钥。 - cephx: verify_authorizer could not get service secret for service osd secret_id=44281
含义:使用 cephx 协议验证时,无法获取对应 osd 服务的密钥。
❌ 表明:该 OSD 的 keyring 已被删除、损坏,或未正确同步到 MON 数据库。 - .accept: got bad authorizer
含义:连接被拒绝,因为客户端提供的认证票据无效。
⚠️ 通常出现在:
OSD 使用旧密钥尝试连接 MON
OSD 被删除后仍在运行
keyring 文件被手动修改或丢失
操作
感觉是坏掉的osd没有及时删除的问题。
第一步: 先处理根目录100%
所有ceph节点的所有osd日志追空
第二步:执行ceph osd命令
ceph命令没有返回,检查mon服务,全死。挨个mon节点重启mon服务
第三步:通过osd相关命令找到坏掉的osd,然后完全删除掉
执行删除命令后,集群进入恢复模式
第四步:观察集群恢复,同时不定期检查osd日志大小,看是否还有异常
shell
for X in {1..14} ;do ssh XX.XXX.X.$X 'hostname ; rm -rf /var/log/ceph/*.gz ;ls -ln -h /var/log/ceph/ ' ; done第五步:等待集群恢复完毕后,重启所有osd服务
第六步:持续多天检查osd日志大小和集群状态
解决方案:
osd坏了及时换盘,没有的话要及时完全删除掉