深入 JVM 栈内存:方法调用的执行舞台
作者 :Weisian
发布时间:2026年2月5日

在之前的文章中,我们探索了类如何被"请进" JVM,以及对象如何在堆中安家落户。但程序的运行远不止于此------方法的每一次调用、局部变量的每一次使用、表达式的每一次求值,都离不开一个更轻量却至关重要的区域:栈内存。
如果说堆内存是 Java 程序的"数据仓库",那么栈内存就是 Java 程序的"执行车间"------方法的调用、局部变量的存储、指令的执行,都在这片区域有序开展。栈内存没有复杂的垃圾回收机制,也没有分代设计的繁琐,却直接决定了方法的执行流程和程序的运行效率,更是面试中高频考察的核心知识点。
接下来,我们将深入 JVM 栈内存的内部结构,揭开虚拟机栈与本地方法栈的神秘面纱,拆解栈帧的组成与方法执行的完整流程,剖析栈溢出的常见场景与排查方案,同时厘清栈与堆的核心区别,帮你彻底掌握这块 JVM 核心区域。
一、栈:线程私有的执行上下文
根据《Java 虚拟机规范》,JVM 栈是线程私有的,其生命周期与线程相同。每当一个线程被创建,JVM 就会为其分配一块独立的栈空间。
1. 核心特性(面试高频)
- 线程私有:每个线程都有自己独立的栈,互不干扰
- 生命周期:与线程生命周期一致,线程结束时栈内存被回收
- LIFO 结构:后进先出(Last In First Out)的数据结构
- 高效访问:基于栈指针直接操作,速度极快
- 自动管理:方法调用时自动入栈,返回时自动出栈
- 大小有限 :可通过
-Xss参数设置栈大小,默认 1MB(不同平台有差异)

bash
# 示例:设置线程栈大小
java -Xss512k MyApp # 每个线程栈 512KB
java -Xss2m MyApp # 每个线程栈 2MB2. JVM 中的两类栈
很多资料会将两者合并提及,但它们的核心作用有着明确区分,不可混淆。
| 区域 | 核心作用 | 执行内容 | 异常类型 | 备注 |
|---|---|---|---|---|
| 虚拟机栈 | 支撑 Java 方法 的执行 | 执行 Java 字节码指令(.class 文件中的指令) |
StackOverflowError、OutOfMemoryError(极少出现) |
日常开发中接触的所有 Java 方法(如 main()、service()),都在虚拟机栈中执行 |
| 本地方法栈 | 支撑 本地方法(Native 方法) 的执行 | 执行本地机器指令(C/C++ 编写的代码,无字节码) | StackOverflowError、OutOfMemoryError(极少出现) |
1. Native 方法以 native 关键字修饰,无方法体;2. 典型示例:Object.hashCode()、System.currentTimeMillis()、Thread.start();3. HotSpot 虚拟机将虚拟机栈与本地方法栈合并实现,两者共享同一块内存区域。 |
(1)虚拟机栈(Java Virtual Machine Stacks)
- 存储 Java 方法调用的栈帧
- 每个 Java 方法调用对应一个栈帧
- 包含局部变量表、操作数栈、动态链接、方法出口等信息
(2)本地方法栈(Native Method Stacks)
- 存储本地(Native)方法调用的栈帧
- 为 JVM 调用本地方法(如 C/C++ 函数)服务
- 具体实现由 JVM 决定,有些实现会将两者合并
java
public class StackExample {
public void javaMethod() {
// Java 方法调用 → 使用虚拟机栈
int result = calculate();
}
private native void nativeMethod();
// 本地方法调用 → 使用本地方法栈
}📌 通俗理解 :
虚拟机栈是"Java 方法的执行舞台",本地方法栈是"Java 调用本地代码的桥梁"------当 Java 方法需要调用底层操作系统 API 或硬件资源时,会通过 Native 方法进入本地方法栈,执行完后再返回虚拟机栈继续执行 Java 代码。
🔍 在 HotSpot 虚拟机中,本地方法栈和虚拟机栈是同一个,不进行区分。

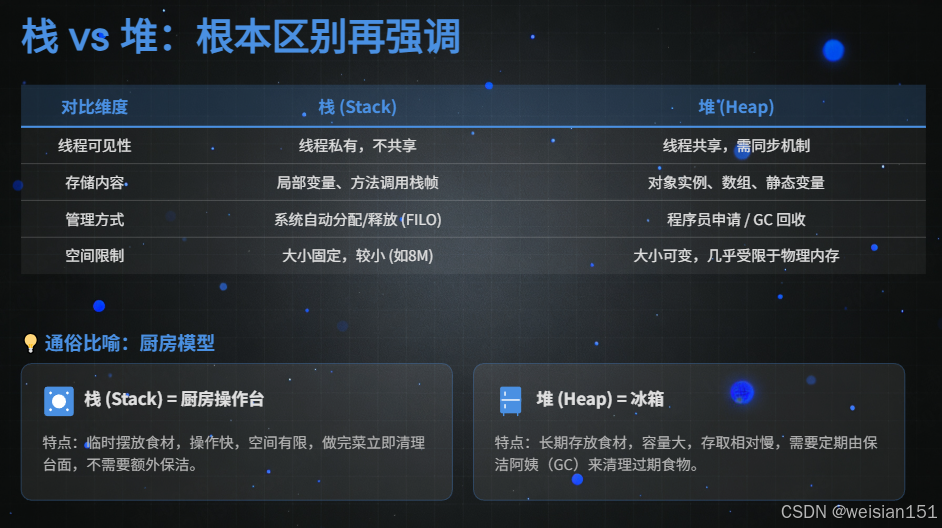
3. 栈 vs 堆:根本区别再强调
很多初学者容易混淆栈与堆,这里我们通过表格和通俗比喻,彻底厘清两者的差异,这也是面试中的高频考点。
| 对比维度 | 栈内存(虚拟机栈) | 堆内存 |
|---|---|---|
| 线程可见性 | 线程私有,其他线程无法访问 | 线程共享,所有线程均可访问堆中对象 |
| 存储内容 | 局部变量、栈帧、操作数栈、方法返回地址 | 对象实例、数组实例(所有通过 new 创建的对象) |
| 生命周期 | 与线程绑定,线程终止则栈销毁 | 与对象绑定,对象无引用后由 GC 回收,与线程生命周期无关 |
| 分配与释放 | 自动分配(方法调用创建栈帧)、自动释放(方法执行完毕弹出栈帧),无内存碎片 | 动态分配(对象创建时),由 GC 自动释放,可能产生内存碎片 |
| 大小限制 | 固定大小(可通过 -Xss 配置),容量较小 |
可动态扩容(由 -Xms 和 -Xmx 控制),容量较大 |
| 异常类型 | 栈溢出:StackOverflowError(栈深度超出限制) |
内存溢出:OutOfMemoryError: Java heap space(堆空间不足) |
| 核心作用 | 支撑方法的执行流程,完成指令调用与返回 | 存储对象实例,提供程序运行的核心数据载体 |
🧩 通俗比喻:
- 栈 = 厨房的操作台,每次做菜(方法调用)都会临时摆放食材(局部变量),做完即清;
- 堆 = 冰箱,长期存放食材(对象),需要时取出,不用时由保洁(GC)清理。
4. 栈内存的 JVM 参数配置(必掌握)
栈内存的配置参数相对简单,核心仅需掌握一个核心参数,同时了解局部变量表的相关优化参数即可。
| 参数 | 作用 | 示例 | 生产建议 |
|---|---|---|---|
-Xss |
设置每个线程的虚拟机栈大小(栈深度上限) | -Xss1m(默认值:JDK8 中约 512k~1m,不同系统/版本略有差异) |
1. 无需盲目增大,默认值可满足绝大多数应用场景;2. 若遇到 StackOverflowError,且确认不是递归死循环,可适当调大(如 -Xss2m);3. 注意:线程数量较多的应用(如高并发网络应用),-Xss 不宜过大------总栈内存 = 线程数 × 单个栈大小,过大会耗尽系统物理内存。 |
-XX:+EliminateLocalVariables |
开启局部变量消除优化(逃逸分析的一部分),减少栈中局部变量的存储开销 | -XX:+EliminateLocalVariables(默认开启) |
保持默认开启,无需手动关闭,可提升栈执行效率。 |
✅ 生产注意点 :
高并发应用中,线程数可能达到数千甚至上万,此时若将
-Xss设为 2m,总栈内存会达到 2G 以上,再加上堆内存、元空间,容易耗尽系统物理内存,引发系统级 OOM。因此,高并发场景下,建议保持-Xss为默认值或适当调小(如-Xss512k)。

二、栈帧(Stack Frame):方法执行的最小单元
虚拟机栈的内部结构非常简洁,它是一个先进后出(LIFO) 的栈结构,其中存储的核心元素就是「栈帧(Stack Frame)」。一个线程的虚拟机栈中,会存在多个栈帧,但同一时间只会有一个活跃的栈帧------当前栈帧(Current Stack Frame),对应当前正在执行的方法(称为「当前方法」)。

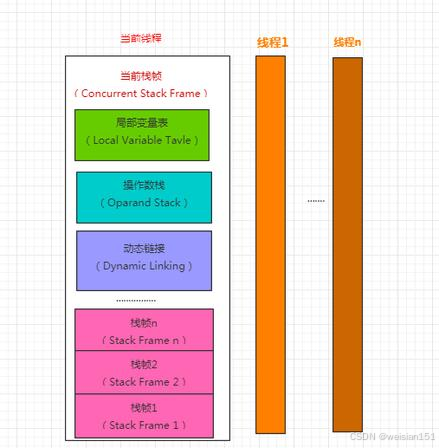
1. 栈帧的结构
┌─────────────────────────────────┐
│ 栈帧 (Stack Frame) │
├─────────────────────────────────┤
│ 局部变量表 (Local Variables) │ ← 存储方法参数和局部变量
├─────────────────────────────────┤
│ 操作数栈 (Operand Stack) │ ← 执行字节码指令的工作区
├─────────────────────────────────┤
│ 动态链接 (Dynamic Linking) │ ← 指向运行时常量池的方法引用
├─────────────────────────────────┤
│ 方法返回地址 (Return Address) │ ← 方法执行完后的返回位置
└─────────────────────────────────┘
2. 栈帧的核心特性
- 方法与栈帧一一对应:一个方法被调用,对应一个栈帧被创建并压入(push)虚拟机栈;一个方法执行完毕,对应一个栈帧被弹出(pop)虚拟机栈并销毁。
- 栈帧的大小固定:栈帧的大小在编译期就已确定,与运行时数据无关------也就是说,方法编译成字节码时,其对应的栈帧大小就已经确定,JVM 运行时无需动态调整栈帧大小。
- 栈帧的层级结构:当方法 A 调用方法 B 时,A 的栈帧会先被压入栈中,随后 B 的栈帧被压入栈顶(成为当前栈帧);B 执行完毕后,其栈帧被弹出,A 的栈帧重新成为当前栈帧,继续执行 A 中剩余的代码。
🤔 示例:方法调用的栈帧变化
执行代码:
main()调用methodA(),methodA()调用methodB()
java
public class StackFrameDemo {
public static void main(String[] args) {
methodA();
}
public static void methodA() {
methodB();
System.out.println("methodA 执行完毕");
}
public static void methodB() {
System.out.println("methodB 执行完毕");
}
}栈帧变化流程:
- 线程启动,
main()方法被调用,main()栈帧压入栈顶(当前栈帧); main()调用methodA(),methodA()栈帧压入栈顶(成为新的当前栈帧);methodA()调用methodB(),methodB()栈帧压入栈顶(成为新的当前栈帧);methodB()执行完毕,其栈帧弹出并销毁,methodA()栈帧重新成为当前栈帧;methodA()执行完毕,其栈帧弹出并销毁,main()栈帧重新成为当前栈帧;main()执行完毕,其栈帧弹出并销毁,线程终止,虚拟机栈释放。
3. 栈帧的内部结构:四大核心组成部分
每个栈帧内部包含四个核心区域,它们共同支撑着方法的执行,其中「局部变量表」和「操作数栈」是最核心、最常被考察的两个区域。
(1)局部变量表(Local Variable Table)------局部变量的"存放柜"
局部变量表是栈帧中最核心的区域之一,用于存储方法的局部变量 和方法参数,其核心特性如下:
-
存储内容:
- 基本数据类型 (8 种:
byte、short、int、long、float、double、char、boolean):直接存储其数值; - 引用数据类型 (
Object、String、数组等):存储对象在堆中的内存地址引用(并非对象本身); - 方法参数 (包括
main()方法的args[]):方法的参数会被优先存入局部变量表,参数的顺序与方法声明中的顺序一致。
- 基本数据类型 (8 种:
-
编译期确定大小:局部变量表的容量以「变量槽(Variable Slot)」为单位(1 个变量槽 = 4 字节),其大小在编译期就已确定,写入方法的字节码中,运行时无法修改。
- 基本数据类型中,
long和double占用 2 个变量槽(因为它们是 8 字节),其余基本类型占用 1 个变量槽; - 引用数据类型(无论对象大小),在 32 位 JVM 中占用 1 个变量槽,64 位 JVM 中开启压缩指针(
-XX:+UseCompressedOops,默认开启)后也占用 1 个变量槽,关闭后占用 2 个变量槽。
- 基本数据类型中,
-
线程私有,无线程安全问题:局部变量表存储在线程私有栈中,仅当前线程可访问,方法执行完毕后栈帧销毁,局部变量也随之消失,因此局部变量不存在线程安全问题(这也是局部变量比全局变量更安全的原因)。
-
无默认初始化值 :局部变量没有像成员变量那样的默认初始化值------必须显式赋值后才能使用,否则编译报错。这是因为局部变量存储在栈中,栈帧创建时局部变量表仅分配空间,不进行初始化;而成员变量存储在堆中,对象创建时会被默认初始化(如
int默认为 0,Object默认为null)。

📌 示例:局部变量表的存储示例
java
public void testLocalVariable(int a, String b) {
int c = 10;
boolean d = true;
User user = new User("张三", 20);
}局部变量表存储情况(64 位 JVM,开启压缩指针):
- 变量槽 0:存储参数
a(int类型,1 个变量槽); - 变量槽 1:存储参数
b(String引用类型,1 个变量槽); - 变量槽 2:存储局部变量
c(int类型,1 个变量槽,值为 10); - 变量槽 3:存储局部变量
d(boolean类型,1 个变量槽,值为 true); - 变量槽 4:存储局部变量
user(User引用类型,1 个变量槽,存储堆中User对象的地址)。
基本结构
- 一个变量槽(Variable Slot) 数组,用于存储方法参数和方法内定义的局部变量
- 每个 Slot 占用 32 位(4 字节),可存储:
int、float、reference(对象引用)等 long和double占用 2 个连续的 Slot(64 位)
Slot 分配规则
java
public class LocalVariableTableDemo {
// 方法描述符: (IJLjava/lang/String;[Ljava/lang/String;)V
public void example(int a, long b, String c, String[] d) {
// 局部变量表 Slot 分配:
// Slot 0: this (实例方法隐含参数)
// Slot 1: int a
// Slot 2-3: long b (占用 2 个 Slot)
// Slot 4: String c (reference)
// Slot 5: String[] d (reference)
int local1 = 10; // Slot 6
double local2 = 3.14; // Slot 7-8 (占用 2 个 Slot)
Object local3 = null; // Slot 9
// 注意:局部变量表大小在编译时确定
}
}重要特性
- 复用 Slot:当局部变量超出作用域,其 Slot 可被后续变量复用
- 默认值:局部变量不像类变量有默认值,必须显式初始化
- 性能优化:Slot 复用可减少栈帧大小,提高性能
(2)操作数栈(Operand Stack)------方法执行的"运算器"
操作数栈也称为「栈式操作数栈」,是一个先进后出(LIFO)的栈结构,用于存储方法执行过程中的中间运算结果 和待执行的指令操作数,其核心特性如下:
- 核心作用 :支撑方法的字节码指令执行,尤其是算术运算、赋值运算等。例如,执行
int c = a + b时,会先将a和b从局部变量表压入操作数栈,然后执行加法指令,将运算结果压回操作数栈,最后将结果从操作数栈弹出,存入局部变量表的c中。 - 编译期确定大小:与局部变量表类似,操作数栈的最大深度在编译期就已确定,写入方法的字节码中,运行时 JVM 会根据这个深度分配足够的空间。
- 无存储地址,仅存储数据:操作数栈是一个纯粹的栈结构,没有像局部变量表那样的变量槽和索引,只能通过「压栈(push)」和「弹栈(pop)」操作来访问数据,无法直接通过索引访问。
- 数据类型与局部变量表一致 :操作数栈中存储的数据类型与局部变量表一致,
long和double占用 2 个栈单元,其余类型占用 1 个栈单元。
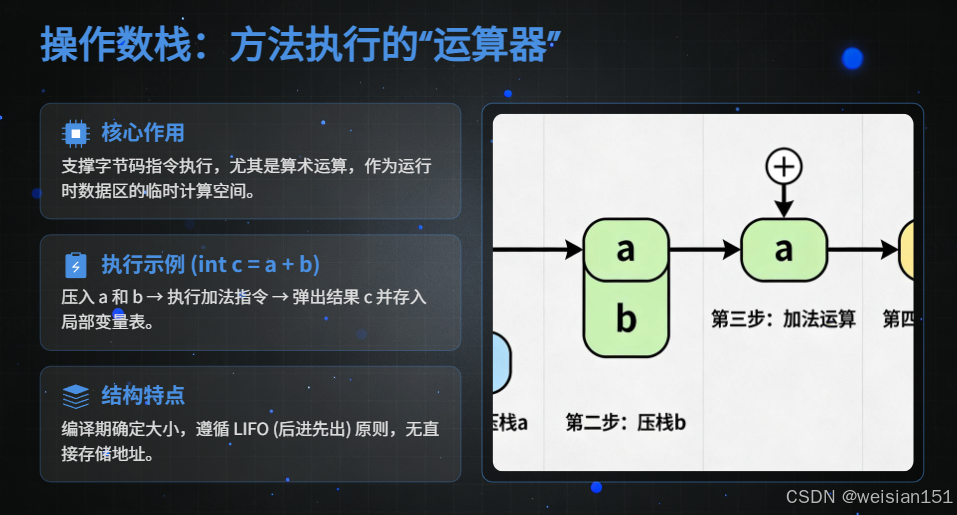
字节码执行示例
java
public int calculate(int x, int y) {
return x + y * 2;
}对应的字节码执行过程:
java
// 字节码
iload_1 // 加载 x 到操作数栈顶
iload_2 // 加载 y 到操作数栈顶
iconst_2 // 加载常量 2 到操作数栈顶
imul // 弹出栈顶两个值相乘,结果入栈
iadd // 弹出栈顶两个值相加,结果入栈
ireturn // 返回栈顶值操作数栈状态变化:
初始: []
iload_1 后: [x]
iload_2 后: [x, y]
iconst_2 后: [x, y, 2]
imul 后: [x, y*2]
iadd 后: [x + y*2]
ireturn: 返回 x + y*2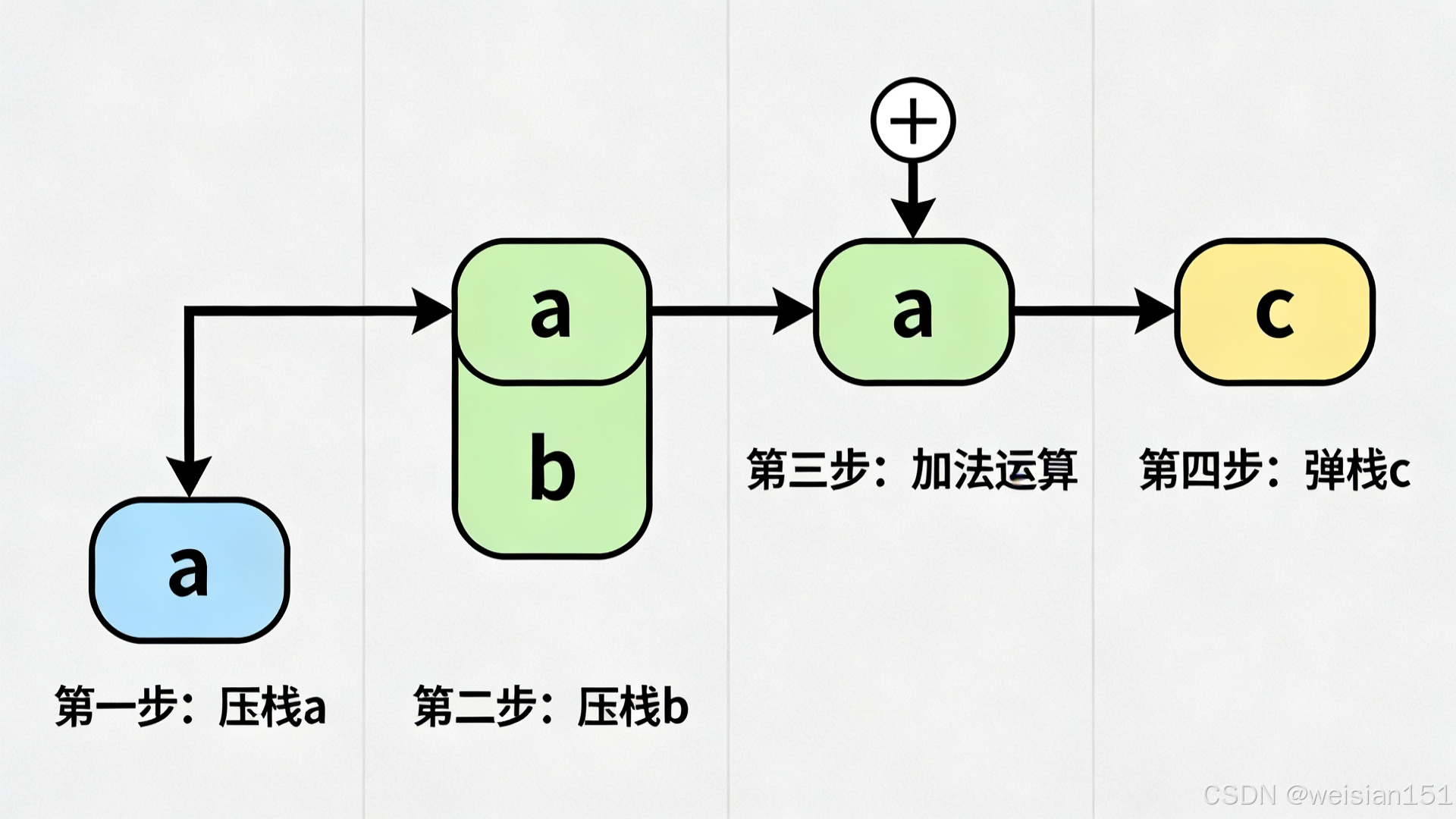
操作数栈特点
- 深度固定 :编译时确定最大深度,写入方法的
Code属性 - 类型安全:JVM 通过字节码验证确保类型操作正确
- 与局部变量表交互 :通过
load和store指令交换数据
(3)动态链接(Dynamic Linking)------指向方法区的"引用指针"
动态连接也称为「运行时常量池引用」,其核心作用是将栈帧中的符号引用转换为直接引用,从而找到方法区中对应的类元数据和方法字节码。
-
符号引用 vs 直接引用:
- 符号引用:编译期生成的、用字符串表示的引用(如方法名、类名),不直接指向内存地址,仅作为"标识";
- 直接引用:运行期生成的、指向内存地址的引用(如方法在方法区的内存地址、对象在堆中的内存地址),可以直接访问目标。
-
动态连接的核心价值 :方法调用分为「静态调用」(编译期确定,如
static方法、final方法)和「动态调用」(运行期确定,如多态、接口方法)。动态连接在运行时将符号引用转换为直接引用,支撑动态调用的实现,这也是 Java 多态特性的核心底层支撑之一。 -
生命周期:动态连接随栈帧的创建而创建,随栈帧的销毁而销毁,每次方法调用时,都会通过动态连接找到对应的方法字节码。
java
public class DynamicLinkingDemo {
public void invoke() {
// 这里的 print() 是符号引用
// 动态链接会将其解析为实际的方法地址
print();
}
private void print() {
System.out.println("Hello");
}
}(4)方法返回地址(Return Address)------方法执行完毕的"导航仪"
方法返回地址用于存储方法执行完毕后,需要返回的下一条指令地址,其核心作用是保证方法执行完毕后,线程能够回到调用该方法的位置,继续执行后续的代码。
-
核心场景:
- 正常返回 :方法执行完毕(遇到
return语句),此时返回地址是调用该方法的下一条字节码指令地址; - 异常返回:方法执行过程中抛出未捕获的异常,此时返回地址由异常处理器决定,栈帧中不会存储明确的返回地址,而是通过方法区中的异常表来找到对应的异常处理逻辑。
- 正常返回 :方法执行完毕(遇到
-
返回值的处理:方法的返回值(若有)会被先压入当前栈帧的操作数栈,然后弹出当前栈帧,将返回值压入调用方栈帧的操作数栈,最后由调用方将返回值存入其局部变量表中。
📌 通俗理解 :
方法返回地址就像是你看视频时的"进度条标记"------当你暂停视频去看广告(调用方法)时,会先标记当前视频的进度(返回地址),广告看完后(方法执行完毕),会根据这个标记回到视频的暂停位置,继续观看(继续执行后续代码)。

三、方法执行的完整流程:栈帧的压栈、执行与弹栈
为了让你更直观地理解栈内存与栈帧的工作机制,我们以一个简单的方法调用为例,拆解从方法调用到方法执行完毕的完整流程,涵盖栈帧的创建、压栈、执行、弹栈全环节。
1. 准备工作:示例代码
java
/**
* 方法执行流程示例:展示栈帧的压栈、执行与弹栈
*/
public class MethodExecuteDemo {
// 全局成员变量(存储在堆中,仅作对比)
private static int globalVar = 0;
public static void main(String[] args) {
// 步骤1:main() 方法被调用,main() 栈帧压入栈顶
int a = 10;
int b = 20;
// 步骤2:main() 调用 add() 方法,add() 栈帧压入栈顶
int sum = add(a, b);
// 步骤5:add() 执行完毕返回,main() 继续执行后续代码
globalVar = sum;
System.out.println("求和结果:" + sum);
}
/**
* 求和方法:接收两个 int 参数,返回它们的和
*/
public static int add(int x, int y) {
// 步骤3:add() 栈帧成为当前栈帧,执行方法逻辑
int result = x + y;
// 步骤4:add() 执行完毕,返回结果给 main(),add() 栈帧弹出
return result;
}
}2. 完整执行流程拆解
步骤1:main() 方法启动,栈帧压入虚拟机栈
- 线程启动,JVM 调用
main()方法,创建main()对应的栈帧,压入虚拟机栈顶,成为「当前栈帧」; - 栈帧中的「局部变量表」初始化,分配变量槽:
- 变量槽 0:存储参数
args[](String[]引用类型); - 变量槽 1:存储局部变量
a(int类型,暂未赋值); - 变量槽 2:存储局部变量
b(int类型,暂未赋值); - 变量槽 3:存储局部变量
sum(int类型,暂未赋值);
- 变量槽 0:存储参数
- 执行
int a = 10;:将 10 存入局部变量表的变量槽 1; - 执行
int b = 20;:将 20 存入局部变量表的变量槽 2; - 执行
int sum = add(a, b);:准备调用add()方法,此时需要将参数a和b的值从main()局部变量表中取出,作为add()方法的参数。
步骤2:main() 调用 add(),add() 栈帧压入栈顶
- JVM 创建
add()对应的栈帧,压入虚拟机栈顶,成为新的「当前栈帧」(main()栈帧暂时处于非活跃状态); add()栈帧的「局部变量表」初始化,分配变量槽:- 变量槽 0:存储参数
x(int类型,接收main()传递的a的值 10); - 变量槽 1:存储参数
y(int类型,接收main()传递的b的值 20); - 变量槽 2:存储局部变量
result(int类型,暂未赋值);
- 变量槽 0:存储参数
add()栈帧的「动态连接」将方法名add转换为方法区中add()方法的直接引用,找到对应的字节码指令;add()栈帧的「方法返回地址」记录main()方法中调用add()的下一条指令地址(即globalVar = sum;对应的字节码地址)。
步骤3:add() 方法执行,操作数栈完成运算
- 执行
int result = x + y;:bipush指令:将x(10)和y(20)从add()局部变量表压入操作数栈;iadd指令:弹出操作数栈顶的两个值,执行加法运算,得到结果 30,压回操作数栈;istore_2指令:弹出操作数栈顶的结果 30,存入add()局部变量表的变量槽 2(对应变量result);
- 执行
return result;:将result的值 30 从局部变量表取出,压入add()操作数栈,准备返回给main()方法。
步骤4:add() 方法执行完毕,栈帧弹出虚拟机栈
add()方法正常返回,JVM 将操作数栈中的返回值 30 传递给main()栈帧;add()栈帧被弹出虚拟机栈并销毁,其占用的栈内存被释放;main()栈帧重新成为「当前栈帧」,继续执行后续代码。
步骤5:main() 方法接收返回值,执行剩余逻辑并结束
main()栈帧将接收到的返回值 30 存入局部变量表的变量槽 3(对应变量sum);- 执行
globalVar = sum;:将sum的值 30 赋值给全局成员变量globalVar(globalVar存储在堆中,通过方法区的类元数据找到其引用); - 执行
System.out.println("求和结果:" + sum);:调用System.out.println()方法,重复上述栈帧压栈/弹栈流程; main()方法执行完毕,其栈帧被弹出虚拟机栈并销毁;- 线程终止,虚拟机栈被释放,程序运行结束。
3. 核心总结
- 方法的执行流程,本质上就是栈帧的压栈、执行、弹栈流程,遵循"先进后出"的原则;
- 栈帧是方法执行的最小单元,其内部的四大区域共同支撑着方法的指令执行、参数传递、结果返回;
- 栈内存的操作是高效且自动的,无需程序员手动干预,也无需 GC 参与,这是栈内存与堆内存的核心区别之一。
四、栈内存的常见问题:栈溢出(StackOverflowError)与排查
栈内存的常见问题远少于堆内存,核心问题只有一个------栈溢出(StackOverflowError) ,而 OutOfMemoryError 在栈内存区域极少出现(仅当创建大量线程,导致总栈内存耗尽系统物理内存时才会触发,本质是系统内存不足,而非栈本身的问题)。
1. 栈溢出(StackOverflowError):核心原因与典型场景
StackOverflowError 的核心原因是:线程的虚拟机栈深度超出了其最大限制 ------也就是说,方法调用的层级过深,导致栈中压入的栈帧过多,超出了 -Xss 配置的栈大小限制,最终引发栈溢出。
典型场景1:无限递归调用(最常见,面试高频)
无限递归是引发 StackOverflowError 的最典型场景,方法自身无限调用自身,导致栈帧不断压入栈中,最终耗尽栈内存。
错误代码示例
java
/**
* 无限递归调用:引发 StackOverflowError
*/
public class StackOverflowDemo {
public static void main(String[] args) {
// 调用递归方法,无终止条件
recursiveMethod();
}
/**
* 无限递归方法:自身调用自身,无终止条件
*/
private static void recursiveMethod() {
System.out.println("执行递归方法...");
// 无限递归:没有终止条件,栈帧不断压入栈中
recursiveMethod();
}
}运行结果(部分)
执行递归方法...
执行递归方法...
...(重复无数次)
Exception in thread "main" java.lang.StackOverflowError
at java.io.PrintStream.println(PrintStream.java:821)
at com.weisian.jvm.StackOverflowDemo.recursiveMethod(StackOverflowDemo.java:15)
at com.weisian.jvm.StackOverflowDemo.recursiveMethod(StackOverflowDemo.java:15)
at com.weisian.jvm.StackOverflowDemo.recursiveMethod(StackOverflowDemo.java:15)
...(后续为重复的方法调用栈信息)代码分析
main()方法调用recursiveMethod(),recursiveMethod()栈帧压入栈中;recursiveMethod()内部又调用自身,新的recursiveMethod()栈帧不断压入栈顶;- 由于没有终止条件,栈帧的数量会持续增长,超出
-Xss配置的栈大小限制; - 最终 JVM 抛出
StackOverflowError,并打印方法调用栈信息(便于排查递归的源头)。
典型场景2:方法调用层级过深(非递归)
除了无限递归,非递归的方法调用层级过深(如调用链达到数万层),也会引发 StackOverflowError,这种场景在实际开发中较为少见,常见于框架源码、复杂业务逻辑中。
模拟代码示例
java
/**
* 方法调用层级过深:引发 StackOverflowError
*/
public class DeepMethodCallDemo {
// 记录方法调用层级
private static int callCount = 0;
public static void main(String[] args) {
// 调用深层方法
deepMethodCall();
}
/**
* 深层方法调用:每次调用自身,层级+1,直到栈溢出
*/
private static void deepMethodCall() {
callCount++;
// 打印调用层级(每 1000 层打印一次)
if (callCount % 1000 == 0) {
System.out.println("当前方法调用层级:" + callCount);
}
// 继续调用自身,模拟深层调用链
deepMethodCall();
}
}运行结果(部分)
当前方法调用层级:1000
当前方法调用层级:2000
当前方法调用层级:3000
...(根据 -Xss 大小不同,层级不同)
Exception in thread "main" java.lang.StackOverflowError
at com.weisian.jvm.DeepMethodCallDemo.deepMethodCall(DeepMethodCallDemo.java:19)
at com.weisian.jvm.DeepMethodCallDemo.deepMethodCall(DeepMethodCallDemo.java:19)
...(后续为方法调用栈信息)2. 栈溢出的排查与解决方案
(1)排查步骤(标准化流程)
- 查看异常堆栈信息 :
StackOverflowError会打印完整的方法调用栈,找到重复出现的方法(通常是递归方法或深层调用链的核心方法),这是排查的关键; - 确认是否为无限递归 :检查该方法是否有明确的终止条件,终止条件是否能够被满足(如递归中的
if判断是否正确); - 检查方法调用链长度:若不是递归,通过堆栈信息梳理方法调用链,确认是否存在不必要的深层调用;
- 验证栈大小配置 :通过
java -XX:+PrintFlagsFinal | grep Xss查看当前栈大小配置,确认是否为默认值或过小。
(2)解决方案
方案1:修复无限递归(核心,针对递归场景)
这是解决 StackOverflowError 的根本方案,给递归方法添加明确的终止条件,确保递归能够正常结束。
修复后的递归代码示例:
java
/**
* 修复无限递归:添加终止条件
*/
public class FixedRecursiveDemo {
public static void main(String[] args) {
// 调用递归方法,传入初始值和终止条件
recursiveMethod(1, 100);
}
/**
* 带终止条件的递归方法
* @param current 当前值
* @param max 最大值(终止条件)
*/
private static void recursiveMethod(int current, int max) {
// 终止条件:当前值大于最大值时,停止递归
if (current > max) {
return;
}
System.out.println("执行递归方法,当前值:" + current);
// 递归调用:当前值+1,向终止条件靠近
recursiveMethod(current + 1, max);
}
}方案2:优化方法调用链(针对非递归场景)
- 简化方法调用链,减少不必要的方法嵌套调用(如将多层嵌套的方法拆分为平级方法);
- 采用「迭代」替代「递归」:对于深层递归场景,可将递归逻辑改写为迭代逻辑(使用
for、while循环),避免栈帧的持续压入,从根本上解决栈溢出问题。
📌 示例:递归转迭代(求阶乘)
递归实现(可能引发栈溢出):
java
public static long factorialRecursive(int n) {
if (n == 1) {
return 1;
}
return n * factorialRecursive(n - 1);
}迭代实现(无栈溢出风险):
java
public static long factorialIterative(int n) {
long result = 1;
for (int i = 2; i <= n; i++) {
result *= i;
}
return result;
}方案3:适当调大栈大小(临时解决方案,不推荐作为首选)
若确认方法调用链是合理的(如框架源码的深层调用),且无法通过优化代码解决,可适当调大 -Xss 参数,增加栈的最大深度。
示例命令:
bash
# 将栈大小调整为 2m
java -Xss2m FixedRecursiveDemo⚠️ 注意事项:
- 调大
-Xss只是临时解决方案,不能从根本上解决方法调用层级过深的问题;- 高并发应用中,调大
-Xss会增加总栈内存开销,可能导致系统物理内存不足,引发其他问题;- 优先选择优化代码,其次才考虑调大
-Xss。
3. 极少出现的 OutOfMemoryError(栈内存区域)
栈内存区域的 OutOfMemoryError 极少出现,其核心原因是:创建了大量线程,导致总栈内存(线程数 × 单个栈大小)超出了系统物理内存限制。
典型场景:创建大量线程
java
/**
* 创建大量线程:引发栈内存区域的 OutOfMemoryError
*/
public class StackOOMDemo {
public static void main(String[] args) {
// 无限创建线程
while (true) {
new Thread(() -> {
// 让线程持续运行,不终止
try {
Thread.sleep(Long.MAX_VALUE);
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
}解决方案
- 减少线程创建数量,采用线程池 复用线程(如
ThreadPoolExecutor),避免无限创建线程; - 适当调小
-Xss参数,减少单个线程的栈内存开销,从而在系统物理内存允许的范围内,创建更多线程(仅适用于必须创建大量线程的场景); - 增加系统物理内存(终极解决方案,成本较高)。
五、栈内存性能优化
1. 栈大小调优策略
(1)默认栈大小
| 平台 | 默认栈大小 | 备注 |
|---|---|---|
| Linux x64 | 1MB | 大多数服务器环境 |
| Windows | 1MB | 视系统配置而定 |
| macOS | 1MB | 同 Linux |
| 32 位系统 | 320KB | 较小以减少内存占用 |
(2)调优建议
bash
# 不同场景的栈大小配置
# 1. 递归深度大的应用(如解析复杂 XML/JSON)
java -Xss2m -Xmx4g DataProcessor
# 2. 高并发微服务(需要大量线程)
java -Xss256k -Xmx2g -XX:MaxMetaspaceSize=256m MicroService
# 3. 桌面应用(中等线程数)
java -Xss512k -Xmx1g DesktopApp
# 4. 大数据处理(避免递归,使用迭代)
java -Xss1m -Xmx8g -XX:+UseG1GC BigDataApp(3)计算最优栈大小
java
public class StackSizeCalculator {
/**
* 估算应用所需栈大小
* @param maxRecursionDepth 最大递归深度
* @param avgFrameSize 平均栈帧大小(字节)
* @param safetyFactor 安全系数(推荐 2.0)
* @return 推荐的栈大小(字节)
*/
public static long calculateOptimalStackSize(
int maxRecursionDepth,
int avgFrameSize,
double safetyFactor) {
long estimated = maxRecursionDepth * avgFrameSize;
return (long)(estimated * safetyFactor);
}
/**
* 获取方法的栈帧信息
*/
public static void analyzeMethodStack(String className, String methodName)
throws Exception {
Class<?> clazz = Class.forName(className);
Method method = clazz.getDeclaredMethod(methodName);
// 通过 Java Agent 或 ASM 获取栈帧大小
System.out.println("分析方法: " + methodName);
System.out.println("建议使用 -Xss 参数调整栈大小");
}
}2. 栈帧复用优化
JVM 在方法调用时有一些优化机制:
(1)栈帧重叠(Stack Frame Overlap)
对于连续的方法调用,JVM 可能复用部分栈帧空间:
java
public class FrameReuseDemo {
public void methodA() {
int a = 1;
methodB();
}
public void methodB() {
int b = 2;
methodC();
}
public void methodC() {
int c = 3;
// 某些 JVM 实现可能复用栈帧空间
}
}(2)逃逸分析优化
如果对象不会逃逸出方法,JVM 可能进行栈上分配:
java
public class EscapeAnalysisDemo {
// 对象不会逃逸出方法 → 可能栈上分配
public int process() {
Point point = new Point(10, 20); // 可能分配在栈上
return point.x + point.y;
}
// 对象逃逸出方法 → 必须在堆上分配
public Point createPoint() {
Point point = new Point(10, 20); // 必须分配在堆上
return point; // 对象逃逸
}
static class Point {
int x, y;
Point(int x, int y) {
this.x = x;
this.y = y;
}
}
}启用逃逸分析:
bash
# 开启逃逸分析(JDK 6u23+ 默认开启)
-XX:+DoEscapeAnalysis
# 开启标量替换(栈上分配的基础)
-XX:+EliminateAllocations
# 打印逃逸分析信息
-XX:+PrintEscapeAnalysis3. 内联优化减少栈帧
方法内联是重要的栈优化技术:
java
public class InliningDemo {
// 小方法:可能被内联
public static int add(int a, int b) {
return a + b;
}
// 热方法:频繁调用,适合内联
public int calculate(int x, int y) {
// 内联后相当于:return x + y;
return add(x, y);
}
// 大方法:不易内联
public void bigMethod() {
// 大量代码...
}
}内联控制参数:
bash
# 内联优化参数
-XX:+Inline # 启用方法内联(默认开启)
-XX:MaxInlineSize=35 # 最大内联字节码大小(默认 35)
-XX:FreqInlineSize=325 # 频繁调用方法的内联大小限制
-XX:+PrintInlining # 打印内联决策4. 栈内存监控工具
(1)jstack 线程栈分析
bash
# 获取线程栈转储
jstack <pid> > thread_dump.txt
# 分析热点线程
jstack <pid> | grep -A 10 "RUNNABLE"
# 定期监控
while true; do jstack <pid> | head -100; sleep 5; done(2)可视化分析工具
- VisualVM:线程监控、栈跟踪
- JProfiler:详细的栈分析、内存分配跟踪
- YourKit:CPU 和内存分析,包括栈使用
(3)自定义监控
java
public class StackMonitor {
// 监控栈深度
public static int getStackDepth() {
return Thread.currentThread().getStackTrace().length;
}
// 预警机制
public static void checkStackDepth(int warningThreshold) {
int depth = getStackDepth();
if (depth > warningThreshold) {
System.err.println("警告:栈深度过大 - " + depth);
// 记录或发送警报
}
}
// 获取栈跟踪(性能敏感,慎用)
public static void printStack() {
StackTraceElement[] stack = Thread.currentThread().getStackTrace();
for (StackTraceElement element : stack) {
System.out.println(element);
}
}
}六、栈内存优化实战建议:高效、安全地使用栈
栈内存虽然无需 GC 介入,且操作高效,但不合理的使用仍会引发栈溢出、性能瓶颈等问题。以下是实战中的核心优化建议,帮助你更好地使用栈内存,提升程序运行效率。
1. 代码层面优化(核心)
(1)避免无限递归,给递归添加明确终止条件
这是预防 StackOverflowError 的最核心措施,无论是自己编写递归代码,还是使用第三方框架的递归功能,都要确保递归有明确的终止条件,且终止条件能够被正常触发。
(2)深层递归优先改为迭代实现
对于阶乘、斐波那契数列等深层递归场景,优先采用迭代实现(for、while 循环),避免栈帧的持续压入,从根本上消除栈溢出的风险,同时迭代的执行效率通常高于递归。
(3)减少局部变量的数量,避免栈帧过大
虽然栈帧的大小在编译期就已确定,但过多的局部变量会增大栈帧的体积,减少单个栈能够容纳的栈帧数量,从而降低栈的最大调用深度。因此,在方法中应尽量减少不必要的局部变量,及时清理无用的局部变量(虽然栈帧销毁时会自动释放,但减少局部变量数量可提升方法执行效率)。
(4)避免在方法中定义过大的局部数组
局部数组的引用存储在栈的局部变量表中,数组实例存储在堆中,但过大的局部数组会占用大量的栈变量槽,同时增加堆内存的压力。因此,应避免在方法中定义过大的局部数组,可采用分段处理、数组池复用等方式优化。
(5)优先使用局部变量,减少全局变量的使用
局部变量存储在线程私有栈中,无线程安全问题,且方法执行完毕后自动释放,无需 GC 介入;而全局变量存储在堆中,存在线程安全问题,且生命周期较长,会增加 GC 压力。因此,在开发中应优先使用局部变量,仅在必要时使用全局变量。
2. JVM 参数优化(辅助)
(1)合理配置 -Xss 参数,避免过大或过小
- 绝大多数应用场景下,保持
-Xss为默认值(JDK8 中约 512k~1m)即可满足需求; - 若遇到合理的深层方法调用引发的
StackOverflowError,可适当调大-Xss(如-Xss2m),但不宜过大; - 高并发应用场景下,建议适当调小
-Xss(如-Xss512k),减少单个线程的栈内存开销,从而支持更多线程的创建。
(2)保持逃逸分析相关优化开启(默认开启)
JVM 的逃逸分析优化(包括局部变量消除、栈上分配等)可以有效减少栈内存的开销,提升方法执行效率,相关参数如下,保持默认开启即可:
-XX:+DoEscapeAnalysis(开启逃逸分析,默认开启);-XX:+EliminateLocalVariables(开启局部变量消除,默认开启);-XX:+EscapeAnalysis(开启栈上分配,默认开启)。
栈相关 JVM 参数
bash
# 基础参数
-Xss1m # 线程栈大小(默认 1MB)
-XX:ThreadStackSize=1024 # 等价于 -Xss1m
# 调试参数
-XX:+PrintFlagsFinal # 打印所有参数值
-XX:+PrintConcurrentLocks # 打印锁信息
-XX:+PrintGC # 打印 GC 信息
# 优化参数
-XX:+DoEscapeAnalysis # 逃逸分析(默认开启)
-XX:+EliminateAllocations # 标量替换(栈上分配)
-XX:+Inline # 方法内联(默认开启)
-XX:MaxInlineSize=35 # 最大内联字节码大小
# 安全参数
-XX:+UseStackBanging # 栈溢出检查(默认开启)
-XX:StackShadowPages=3 # 栈阴影页数
-XX:StackReservePages=1 # 栈保留页(3)监控脚本
bash
#!/bin/bash
# monitor_stack.sh - 栈内存监控脚本
PID=$1
INTERVAL=${2:-5} # 默认 5 秒
echo "监控 JVM 栈使用情况 (PID: $PID, 间隔: ${INTERVAL}s)"
echo "时间戳 | 线程数 | 栈深度警告 | 状态"
echo "----------------------------------------"
while true; do
TIMESTAMP=$(date '+%H:%M:%S')
# 获取线程数
THREAD_COUNT=$(jstack $PID | grep -c "java.lang.Thread.State")
# 检查栈溢出警告
STACK_WARNINGS=$(grep -c "StackOverflowError" /var/log/app/error.log)
# 获取 JVM 栈参数
STACK_SIZE=$(jinfo -flag ThreadStackSize $PID 2>/dev/null | cut -d'=' -f2)
echo "$TIMESTAMP | $THREAD_COUNT | $STACK_WARNINGS | -Xss${STACK_SIZE:-1024}k"
sleep $INTERVAL
done3. 排查工具推荐(问题定位)
(1)栈溢出排查 checklist
1. 现象确认
☐ 是否出现 StackOverflowError?
☐ 错误栈跟踪是否显示递归调用?
☐ 是否在特定操作后出现?
2. 环境检查
☐ 当前 -Xss 设置是多少?
☐ 系统 ulimit 设置?
☐ 应用最近是否有变更?
3. 代码分析
☐ 使用 jstack 获取线程栈
☐ 分析递归调用链
☐ 检查第三方库的递归调用
4. 解决方案
☐ 增大 -Xss 参数(临时)
☐ 修改递归为迭代(根本)
☐ 优化算法减少栈深度(2)线程创建失败排查
bash
#!/bin/bash
# diagnose_thread_oom.sh
PID=$1
echo "=== 线程 OOM 诊断报告 ==="
echo "生成时间: $(date)"
echo "目标 PID: $PID"
echo ""
# 1. 检查当前线程数
echo "1. 当前线程状态:"
jstack $PID | grep "java.lang.Thread.State" | wc -l
echo ""
# 2. 检查栈大小配置
echo "2. 栈配置:"
jinfo -flag ThreadStackSize $PID 2>/dev/null || echo "使用默认值: 1MB"
echo ""
# 3. 检查系统限制
echo "3. 系统限制:"
ulimit -a | grep -E "(stack|processes|user)"
echo ""
# 4. 检查内存使用
echo "4. 内存使用:"
jstat -gc $PID 1000 1
echo ""
# 5. 建议
echo "5. 建议措施:"
echo " - 减小 -Xss 大小(如 256k)"
echo " - 使用线程池控制线程数量"
echo " - 检查代码中的线程泄漏"栈内存问题的排查工具相对简单,核心是通过异常堆栈信息和 JVM 自带工具进行定位,推荐工具如下:
| 工具 | 用途 | 核心使用场景 |
|---|---|---|
jps -l |
查看 Java 进程 ID 与对应的应用名称 | 快速定位目标应用进程 |
jstack <pid> |
打印线程的堆栈信息,包括当前方法调用链、栈帧状态 | 排查栈溢出、线程死锁、方法调用链过深等问题 |
VisualVM |
可视化监控线程状态、方法调用链,支持栈内存分析 | 图形化排查栈内存相关问题,适合初学者 |
📌 实战技巧 :当程序出现
StackOverflowError时,首先查看异常堆栈信息,找到重复出现的方法,确认是否为无限递归,这是最快、最有效的排查方式。
七、常见误区澄清
❌ 误区 1:"基本类型存在栈,对象存在堆"
-
部分正确 :基本类型的局部变量 存在栈,但成员变量(无论基本还是引用)都随对象存在堆中。
javaclass Data { int value; // 在堆中(属于对象实例) } public void method() { int temp = 10; // 在栈中 }
❌ 误区 2:"String 字面量存在栈"
- 错误 :字符串字面量(如
"hello")存储在堆中的字符串常量池(JDK 7+),栈中只存引用。
❌ 误区 3:"增大 -Xss 总是好的"
- 错误 :线程栈总内存 = 线程数 × Xss。若系统内存 8GB,
-Xss=2m,则最多支持约 4000 个线程(未计堆和其他开销),极易导致unable to create new native thread。

结语:栈,是程序跳动的脉搏
JVM 栈虽不如堆那样占据大量内存,也不像方法区那样承载元数据,但它却是程序动态执行的灵魂所在。每一次方法调用,都是栈帧的压入与弹出;每一次局部变量的使用,都是栈内存的读写流转。

理解栈的工作机制,不仅能帮助你写出更健壮的递归与迭代代码,还能在面对 StackOverflowError 时迅速定位根因。更重要的是,它让你明白:Java 的"自动内存管理"并非万能------栈的深度,仍需程序员亲手把控。
"栈无言,却承载了程序的每一次呼吸。"
下一次,当你写下 public static void main(String[] args) 时,不妨想象一下:这个入口方法,正站在主线程栈的顶端,等待着你的代码去填充它的栈帧,开启一段精彩的执行之旅。
互动话题 :
你在项目中是否遇到过 StackOverflowError?是如何将递归重构为迭代的?欢迎在评论区分享你的"栈溢出"救援故事!