Mitigating Long-Tail Bias via Prompt-Controlled Diffusion Augmentation
Authors: Buddhi Wijenayake, Nichula Wasalathilake, Roshan Godaliyadda, Vijitha Herath, Parakrama Ekanayake, Vishal M. Patel
Deep-Dive Summary:
论文摘要:Self-Consistency Improves Chain of Thought Reasoning in Large Language Models
1. 核心概述
本文介绍了一种名为"自一致性"(Self-Consistency)的新型解码策略,旨在显著提升大型语言模型(LLM)在复杂推理任务中的表现。传统的思维链(Chain-of-Thought, CoT)推理通常采用贪婪解码(Greedy Decoding)生成单一的推理路径,而自一致性方法则通过从模型的后验分布中采样多个不同的推理路径,并对最终答案进行"多数投票"(Majority Vote)来确定最终结果。
2. 自一致性方法论

2.1 核心思想
自一致性的设计灵感来源于:一个复杂的推理问题通常有多种不同的思考方式,但正确的推理路径往往会导向同一个正确答案。
2.2 数学定义
在标准的思维链推理中,对于给定的提示(Prompt),模型生成一个包含推理路径 r r r 和答案 a a a 的序列。自一致性的目标是最大化在所有采样推理路径下的边际概率:
p ( a ∣ prompt ) = ∑ r p ( a , r ∣ prompt ) p(a | \text{prompt}) = \sum_{r} p(a, r | \text{prompt}) p(a∣prompt)=r∑p(a,r∣prompt)

2.3 实施步骤
- 采样(Sampling) :给定提示词,使用语言模型通过温度采样(Temperature Sampling)生成 k k k 组不同的推理路径 { r i , a i } i = 1 k \{r_i, a_i\}_{i=1}^k {ri,ai}i=1k。
- 聚合(Aggregation) :对所有生成的答案 a i a_i ai 进行投票,选择出现频率最高的答案作为最终输出。其估算公式为:
arg max a ∑ i = 1 k 1 ( a i = a ) \arg \max_a \sum_{i=1}^k \mathbb{1}(a_i = a) argamaxi=1∑k1(ai=a)
3. 实验对比与效果
如上图所示,传统的思维链推理(Greedy Decode)仅走一条路径,如果中途出错则导致错误答案。而自一致性通过采样多条路径(如三个不同的计算过程),即使其中一条路径出错,通过多数投票仍能锁定正确答案。
3.1 主要性能提升

研究团队在数学推理(GSM8K, MATH)、常识推理(StrategyQA)和符号推理等多个基准测试上进行了实验。结果显示:
- 数学推理:在 GSM8K 数据集上,性能从 17.9% 提升至 57.0%(LaMDA-137B)以及从 56.5% 提升至 74.4%(PaLM-540B)。
- 鲁棒性:该方法对采样策略(如不同温度值)具有很强的鲁棒性。
- 通用性:自一致性是一种无监督的方法,无需额外的训练或人工标注,且能与现有的预训练模型直接配合使用。
4. 结论
自一致性解码策略通过利用推理路径的多样性,有效地解决了大型语言模型在执行复杂多步推理时容易出现局部错误的问题。它不仅刷新了多项推理任务的最优性能(SOTA),还为提升 LLM 的可靠性提供了一种简单而强大的工具。
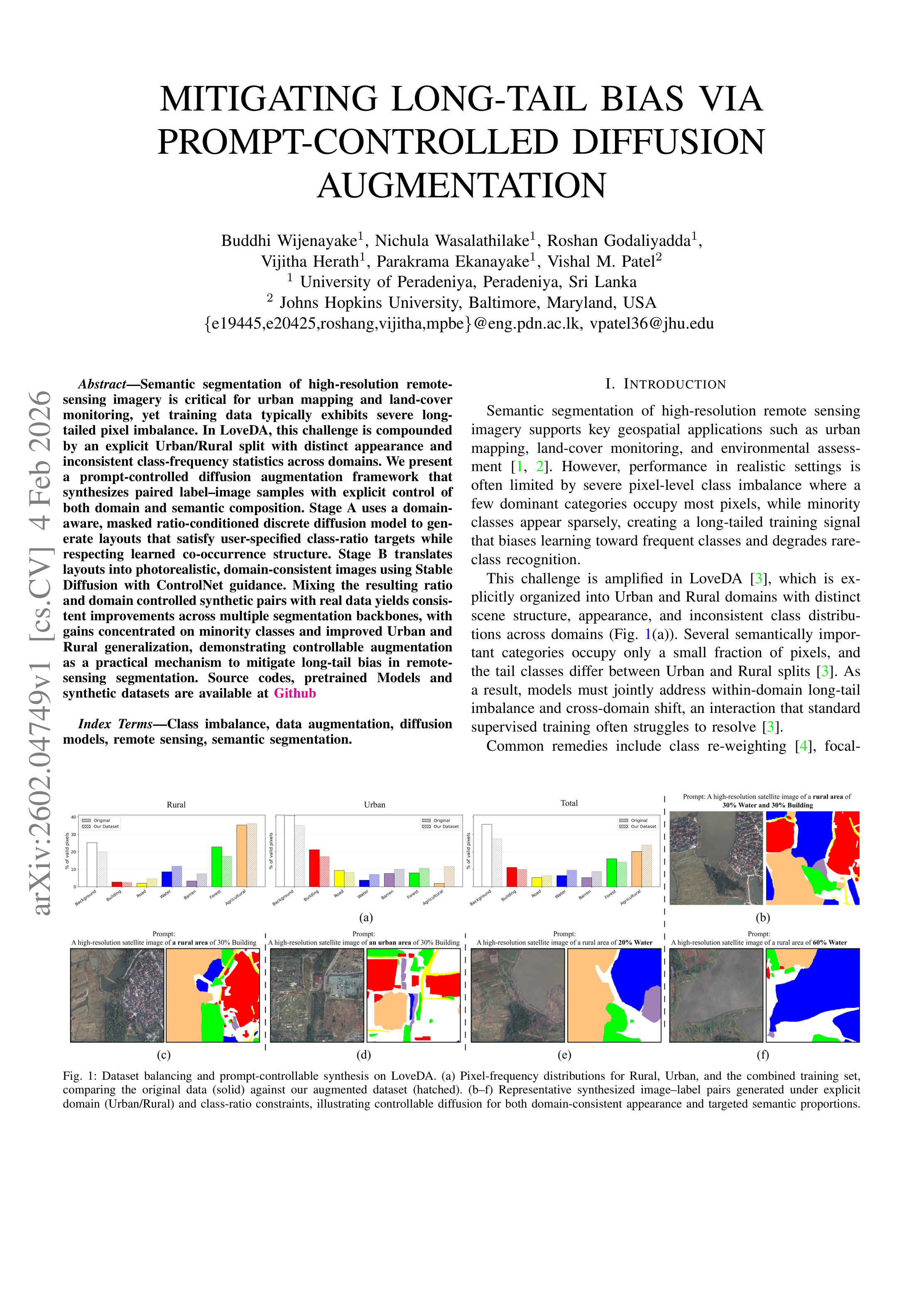
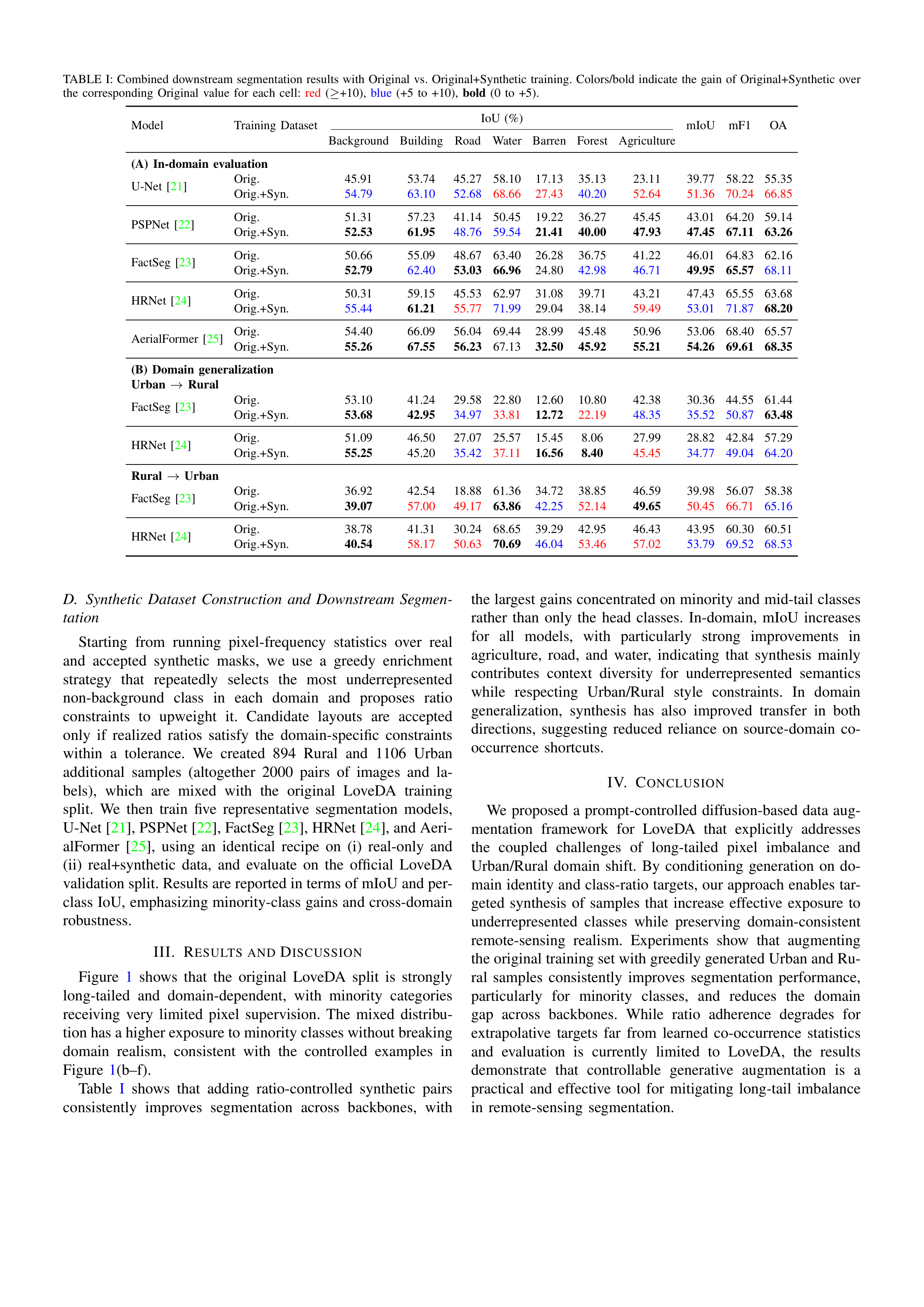
Original Abstract: Semantic segmentation of high-resolution remote-sensing imagery is critical for urban mapping and land-cover monitoring, yet training data typically exhibits severe long-tailed pixel imbalance. In the dataset LoveDA, this challenge is compounded by an explicit Urban/Rural split with distinct appearance and inconsistent class-frequency statistics across domains. We present a prompt-controlled diffusion augmentation framework that synthesizes paired label--image samples with explicit control of both domain and semantic composition. Stage~A uses a domain-aware, masked ratio-conditioned discrete diffusion model to generate layouts that satisfy user-specified class-ratio targets while respecting learned co-occurrence structure. Stage~B translates layouts into photorealistic, domain-consistent images using Stable Diffusion with ControlNet guidance. Mixing the resulting ratio and domain-controlled synthetic pairs with real data yields consistent improvements across multiple segmentation backbones, with gains concentrated on minority classes and improved Urban and Rural generalization, demonstrating controllable augmentation as a practical mechanism to mitigate long-tail bias in remote-sensing segmentation. Source codes, pretrained models, and synthetic datasets are available at \href{https://github.com/Buddhi19/SyntheticGen.git}{Github}
PDF Link: 2602.04749v1
部分平台可能图片显示异常,请以我的博客内容为准
