核心问题
读一个 1000 行文件消耗 ~4000 token。处理 30 个文件 + 20 条命令后,token 使用量超过 100,000。大型项目的代码库工作在没有压缩策略的情况下是不可能的。
上下文窗口是 Agent 的**"工作记忆"** ------ 它决定了 Agent 能同时记住多少东西。
上下文压缩的整体流程
1.压缩流程图
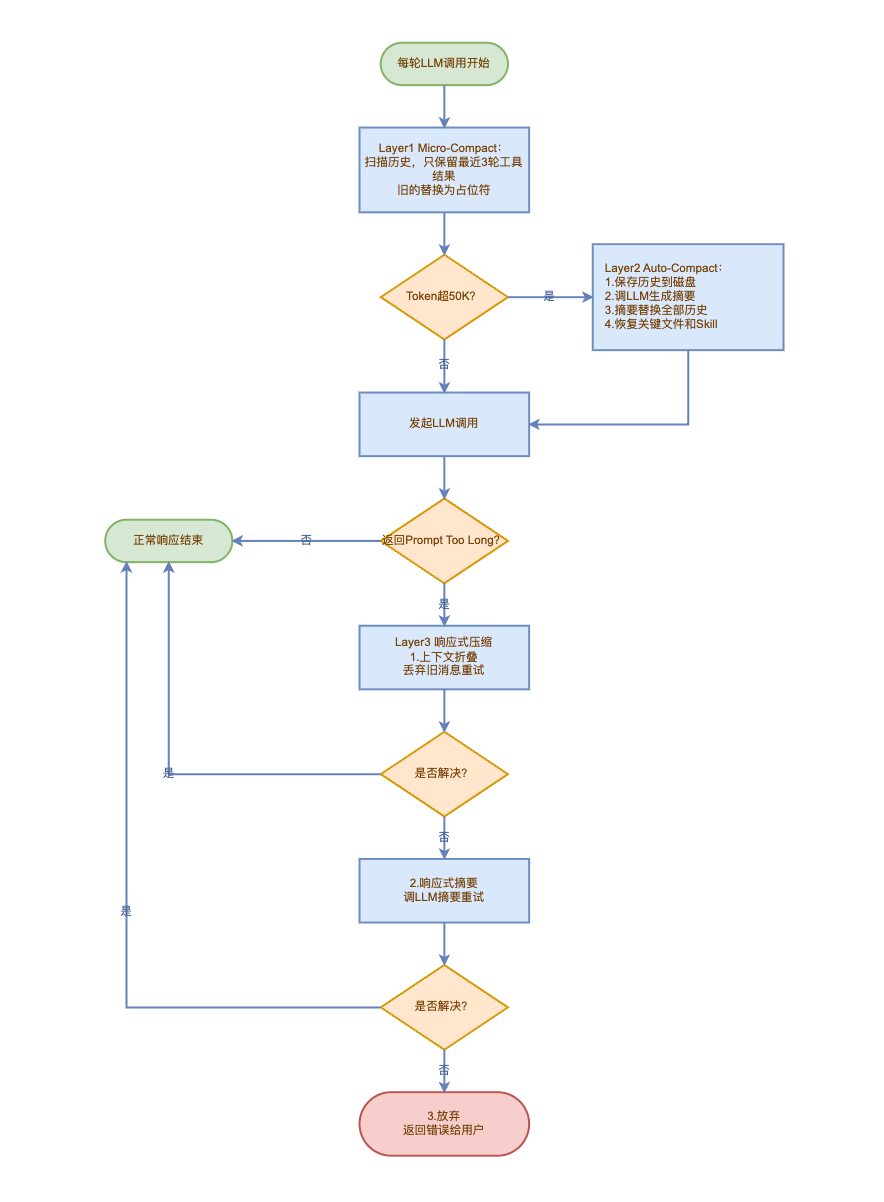
2.三层压缩干了什么
|--------|---------------------------|------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------|--------------------------------------------------|
| 压缩层级 | 名称 | 触发时机 | 核心压缩逻辑 | 配套后置动作 | 成本开销 | 设计目的 |
| Layer1 | Micro-Compact(微压缩) | 每次 LLM 调用前自动执行(必跑) | 从消息末尾向前遍历工具结果消息;仅保留最近 3 轮完整工具返回内容,更早的工具结果替换为简短占位:Previous: used xxx工具名;不修改 assistant 模型推理消息 | 无额外恢复;仅精简历史工具数据 | 无 LLM 调用,纯本地代码遍历,零 API 费用 | 日常持续控 token,避免工具输出无限堆积,高频轻量瘦身 |
| Layer2 | Auto-Compact(阈值自动摘要压缩) | 上下文总 Token > 设定阈值(示例 50K)时触发 | 1. 压缩前全量对话落盘保存到磁盘 (.transcripts); 2. 消息按 API 轮分组、剔除图片等大资源;3. 调用 LLM 生成结构化 9 项规范摘要; 4. 全量历史替换成 1 条摘要消息Previous conversation summary+正文 | postCompactRestore 局部恢复:在摘要尾部追加关键内容,总恢复 token 上限 50000: ①最多 5 个最近读写文件(单文件封顶 5k token); ②剩余额度内恢复自定义技能源码(技能子预算 25K),用<system-reminder>标记恢复内容 | 需要调用 LLM 生成摘要,产生 API 计费 | 重度超限后大幅压缩整体对话,靠摘要保留全量语义,再回填编码必需的文件 / 技能,保证代码编写能力 |
| Layer3 | Reactive Compact(响应式容错压缩) | 调用 LLM 返回Prompt Too Long超长报错时触发,三级兜底递进策略 | 1. 策略 1(低成本):上下文折叠,丢弃最老旧消息、保留近期内容,能释放空间就直接重试; 2. 策略 2(中成本):折叠无效则执行 LLM 全量摘要替换历史; 3. 策略 3(兜底):两次压缩都失败则终止调用、抛出报错 | 压缩成功后同样执行文件 + 技能局部恢复逻辑 | 策略 1 零成本;策略 2 消耗 LLM 计费;策略 3 无消耗 | API 突发超长兜底防护,解决压缩预判失误导致的调用失败,保证 Agent 健壮运行 |
3.Micro-Compact (每轮自动)
Micro-Compact 是三层上下文压缩策略中最轻量的第一层,每轮 LLM 调用前自动执行。
3.1核心逻辑:把旧的工具调用结果替换成占位符
[Previous: used ${工具名}] 替换之后可能是这样的:[Previous: used exec]
原来可能是几千 token 的文件内容,压缩后只剩一行占位符。
只保留最近 3 轮的完整工具结果,更旧的全部替换掉:
第 1 轮 exec: ls -la → [Previous: used exec] ← 被替换
第 2 轮 read: xxx.java → [Previous: used read] ← 被替换
第 3 轮 read: yyy.java → 保留完整内容 ← 保留
第 4 轮 exec: mvn test → 保留完整内容 ← 保留
第 5 轮 read: zzz.java → 保留完整内容 ← 保留(最近3轮)3.2核心代码
javascript
// 简化的 Micro-Compact 逻辑
function microCompact(messages: Message[]): Message[] {
// 只保留最近 3 轮的完整工具结果
const KEEP_RECENT = 3
let toolResultCount = 0
// 从后往前遍历
for (let i = messages.length - 1; i >= 0; i--) {
const msg = messages[i]
if (isToolResult(msg)) {
toolResultCount++
if (toolResultCount > KEEP_RECENT) {
// 替换为占位符
messages[i] = {
role: 'user',
content: `[Previous: used ${msg.toolName}]`,
}
}
}
}
return messages
}3.3为什么 Micro-Compact 只替换工具结果?
Assistant 消息包含模型的推理过程和决策,这些信息比工具结果更有价值。工具结果通常很大(文件内容、命令输出)但价值递减很快。
4.Auto-Compact (Token 阈值触发)
4.1自动压缩的流程
4.2核心代码
javascript
Token 超过 50K
│
▼
┌─────────────────────────────────┐
│ Step 1: 保存完整历史到磁盘 │
│ → ~/.transcripts/xxx.jsonl │
└─────────────────┬───────────────┘
│
▼
┌─────────────────────────────────┐
│ Step 2: 按 API 轮次分组消息 │
└─────────────────┬───────────────┘
│
▼
┌─────────────────────────────────┐
│ Step 3: 去掉图片等大体积内容 │
└─────────────────┬───────────────┘
│
▼
┌─────────────────────────────────┐
│ Step 4: 构建压缩提示词 │
└─────────────────┬───────────────┘
│
▼
┌─────────────────────────────────┐
│ Step 5: 调 LLM 生成结构化摘要 │
│ (包含 9 个固定部分) │
└─────────────────┬───────────────┘
│
▼
┌─────────────────────────────────┐
│ Step 6: 解析摘要 │
│ (提取 <summary> <analysis>) │
└─────────────────┬───────────────┘
│
▼
┌─────────────────────────────────┐
│ Step 7: 摘要替换全部历史 │
│ + 恢复最近编辑的文件(≤5个) │
│ + 恢复已加载的 Skill 文件 │
└─────────────────┬───────────────┘
│
▼
继续发起 LLM 调用4.3构建提示词
构建压缩提示词 就是把「要压缩的内容」和「压缩指令」拼在一起,组成一个完整的 prompt,准备交给 LLM 去生成摘要。
具体来说,这个 prompt 包含两部分:
① 系统指令(告诉 LLM 它的任务)
javascript
你的任务是分析一段对话并生成结构化摘要。
输出格式:
<analysis>
对当前状态的深入分析...
</analysis>
<summary>
1. 初始用户请求和高层目标
2. 已完成的关键步骤
3. 当前工作状态
4. 待完成的任务
5. 重要的技术决策和原因
6. 相关文件路径
7. 遇到的错误和解决方案
8. 环境配置细节
9. 下一步行动建议
</summary>② 历史内容(经过 Step2/3 处理后的对话)
javascript
[User]: 帮我读一下 xxx.java
[Assistant]: 好的,文件内容是...
[Tool Result]: (已在Step3中去掉大图片)
...(所有历史轮次)4.4压缩后恢复
压缩后恢复是 Auto-Compact 的最后一步,目的是防止模型「失忆」------摘要虽然保留了对话脉络,但有些内容光靠摘要是不够的。
为什么需要恢复?
压缩后上下文只剩一条摘要,比如:
javascript
摘要:用户正在修改 UserService.java,已完成了权限校验逻辑,下一步要处理事务回滚...但摘要里不会把 UserService.java 的完整代码都写进去------那样摘要本身就又很大了。
问题来了:模型下一轮要继续改这个文件,却完全不知道文件现在长什么样
恢复两类内容
① 恢复最近编辑的文件(最多 5 个,共 50K token 预算)
扫描历史中被读取/编辑过的文件路径
按最近操作时间排序,取最新的最多 5 个
重新把文件内容注入到上下文
50K token是上限,超了就按优先级截断
javascript
为什么是 5 个、50K?→ 经验值,够覆盖大多数任务场景,又不会让恢复本身消耗太多窗口② 恢复已加载的 Skill 文件
压缩前加载了哪些SKILL.md,压缩后重新注入
避免模型忘记「我现在能用什么工具、有什么规则」
恢复后的上下文结构
javascript
┌─────────────────────────────────┐
│ [摘要] 压缩后的对话历史 │ ← Auto-Compact 生成
├─────────────────────────────────┤
│ [文件] UserService.java 完整内容 │ ← 恢复注入
│ [文件] OrderController.java │ ← 恢复注入
├─────────────────────────────────┤
│ [Skill] SKILL.md 内容 │ ← 恢复注入
├─────────────────────────────────┤
│ [新消息] 用户接下来说的话 │ ← 正常对话继续
└─────────────────────────────────┘5.响应式压缩 (错误恢复)
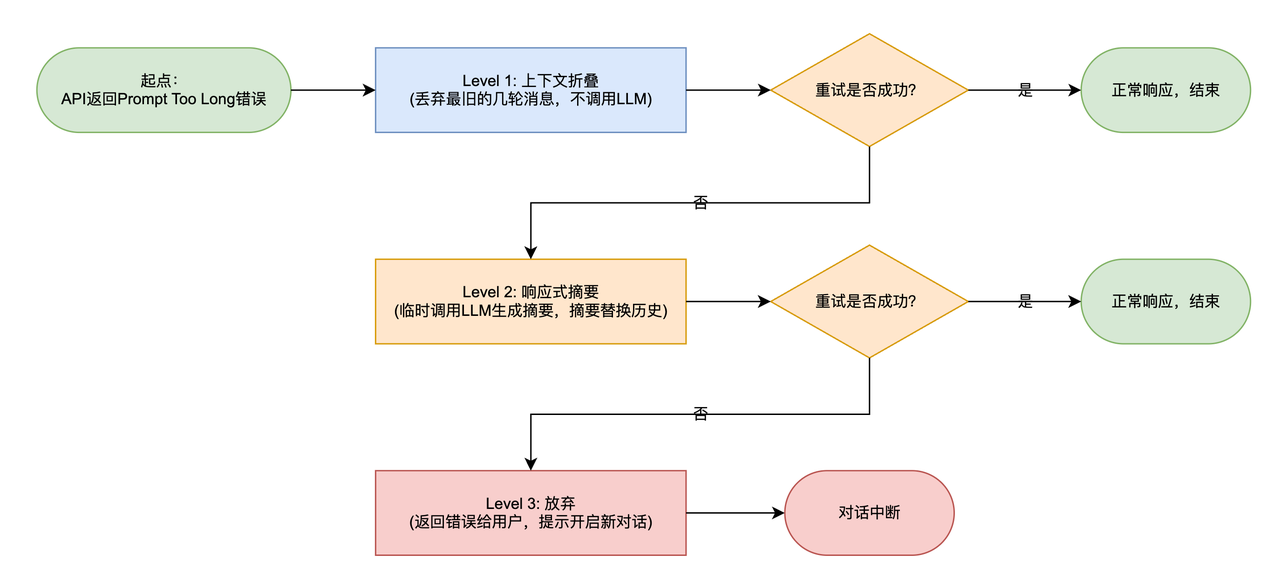
触发条件:发起 LLM 调用后,API 返回 Prompt Too Long 错误------也就是 Micro 和 Auto 都没拦住,上下文真的撑爆了。
这是最后的兜底机制,采用三级递进策略,代价一级比一级高。
5.1三级递进
Level 1:上下文折叠(最便宜)
做法:直接从历史消息中丢弃最旧的几轮,不调用任何 LLM,然后立刻重试。
javascript
原始历史:[轮1][轮2][轮3]...[轮N]
折叠后: [轮3]...[轮N] ← 丢掉最旧的轮1、轮2优点:
零额外 API 调用,速度快、成本低
对于「旧轮次已经不重要」的场景效果很好
缺点:
粗暴,丢掉的内容不可恢复
如果旧轮次里有关键信息,模型会真的忘掉
重试后如果还是 Too Long → 进入 Level 2。
Level 2:响应式摘要(较贵)
做法:临时调用一次 LLM,对当前历史生成摘要,再用摘要替换历史,然后重试。
本质上是在出错时触发了一次「小型 Auto-Compact」,但这次是被动触发的,不是因为 token 超阈值,而是因为 API 已经报错了。
优点:
比 Level 1 更智能,摘要保留了语义
不会粗暴丢弃关键信息
缺点:
多一次 LLM 调用,有延迟和费用
摘要质量依赖模型能力,极端情况下摘要本身也可能很大
重试后如果还是 Too Long → 进入 Level 3。
Level 3:放弃(最后手段)
做法:什么都不做,直接把错误返回给用户。
Error: Context too long, unable to continue.Please start a new conversation.触发场景:极少见,通常是单条消息本身就超限(比如用户粘贴了一个几万行的文件)。
理想情况:Auto-Compact 把 token 控制在合理范围,响应式压缩永远不需要触发。响应式压缩是真正的兜底,不是常规路径。
5.2核心代码
javascript
// src/query.ts - 响应式压缩
if (isPromptTooLongMessage(lastMessage)) {
// 策略 1: 上下文折叠 (低成本)
// 丢弃最旧的消息,保留最近的
const drained = contextCollapse.recoverFromOverflow(messages)
if (drained.committed > 0) {
state.messages = drained.messages
continue // 用折叠后的上下文重试
}
// 策略 2: 响应式压缩 (调用 LLM 生成摘要)
if (!state.hasAttemptedReactiveCompact) {
const compacted = await reactiveCompact(messages)
state.messages = compacted
state.hasAttemptedReactiveCompact = true
continue // 用摘要重试
}
// 策略 3: 放弃 → 返回错误给用户
return { reason: 'prompt_too_long' }
}5.3流程图
转录持久化
一句话: 在Auto-Compact 压缩之前,把完整的对话历史原封不动地存到磁盘,确保有损压缩不会造成信息永久丢失。
javascript
~/.claude/sessions/
└── <session-id>/
├── session.json # 会话元数据(模型、配置等)
├── transcript.jsonl # 完整消息记录
└── .transcripts/ # 压缩前的快照备份JSONL 格式:每行一条消息,独立的 JSON 对象,追加写入。
javascript
{"role":"user","content":"帮我读一下 xxx.java","timestamp":1234567890}
{"role":"assistant","content":"好的,正在读取...","timestamp":1234567891}
{"role":"tool_result","content":"文件内容...","timestamp":1234567892}1.为什么用 JSONL 而不是普通 JSON
|-------|------------|----------|
| | JSONL | 普通 JSON |
| 写入方式 | 追加一行 | 重写整个文件 |
| 崩溃恢复 | 已写的行不丢 | 写到一半整个损坏 |
| 大文件处理 | 按行读,不需要全加载 | 必须全量解析 |
简化实现
javascript
// 三层压缩的简化实现
const TOKEN_THRESHOLD = 50_000
const KEEP_RECENT_RESULTS = 3
async function manageContext(
messages: Message[],
tokenCount: number,
): Promise<Message[]> {
// Layer 1: Micro-compact (每轮)
let result = microCompact(messages, KEEP_RECENT_RESULTS)
// Layer 2: Auto-compact (超过阈值)
if (tokenCount > TOKEN_THRESHOLD) {
await saveTranscript(result)
const summary = await summarize(result)
result = [{ role: 'user', content: summary }]
result = await restoreContext(result) // 恢复关键文件和技能
}
return result
}
// Layer 3: Manual compact (用户触发)
const CompactTool = buildTool({
name: 'compact',
async call(input, context) {
const summary = await summarize(context.messages)
context.messages.splice(0, context.messages.length, {
role: 'user', content: summary,
})
return { data: 'Conversation compacted.' }
},
})感兴趣的宝子可以关注一波,后续会更新更多有用的知识!!!
