大模型实战 05 大模型实战的杀手锏: 模型微调
核心摘要 (TL;DR)
- 实操验证:通过 Kaggle 代码亲自运行对比,揭示 Base 模型("续写怪")与 Instruct 模型("对话助手")的本质差异。
- 原理揭秘:图解大模型从"预训练(Pre-training)"到"指令微调(SFT)"再到"人类对齐(RLHF)"的三段进化史。
- 决策指南:RAG 负责"注知识",微调负责"塑性格"。本文将帮你彻底理清 Prompt 工程、RAG 与微调的技术边界与选型策略。
前言
在上一篇教程中,我们了解了如何让离线 的大模型用上新鲜在线 的数据,做个人知识库,做公司内部工具,做智能客服,甚至私人管家。(虽然我们没有讲那么细致,哈哈哈哈,但是我相信,基于之前的介绍,以各位友人的理解能力,已经能够去完成这些需求了)。目前为止,对大模型的应用,咱们已经可以说脱离小白 的范围了。 但是,我们还有最后一道坎儿,一门"炼丹"路上很重要的心法:模型微调。
在引入模型微调的概念前,咱们来回顾一下咱们去下载模型的时候,可能大家犯过嘀咕的一个问题。类似Qwen3-235B-A22B-GPTQ-Int4,Qwen3-4B-Base,Qwen3-4B-Instruct-2507这些模型中间这一串到底是什么意思?这里咱们先不讲A22B-GPTQ-Int4,哈哈哈,挖一个坑先,咱们先讲后面两种。Qwen3咱们知道, 模型的大名,4B咱们也知道,模型规模,那这个Instruct和Base是干啥的?
纸上得来终觉浅,咱们先不知道,咱们实操探索,下下来两个模型,来对比一下。
1. 实操探秘
阿尔已经提前下载了这两个模型,打包放在了llm03-stf-intro-model这个dataset中,各位友人可以在input 中搜到加载上
1.1 定义测试函数
python
import gc
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
def clear_gpu():
# 用于清理显存
if "model" in globals():
del globals()["model"]
if "tokenizer" in globals():
del globals()["tokenizer"]
gc.collect()
torch.cuda.empty_cache()
print("显存清理完毕")
def run_the_model(model_path:str, prompt:str):
print(f"loading model:{model_path}")
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
dtype=torch.float16,
trust_remote_code=True
)
messages = [{"role":"user","content":prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text],return_tensors="pt").to(model.device)
outputs = model.generate(
**model_inputs,
max_new_tokens=512,
temperature=0.7,
do_sample=True,
top_p=0.9,
pad_token_id=tokenizer.eos_token_id
)
response = tokenizer.decode(outputs[0],skip_special_tokens=True)
print(f"output:\n {'-'*30}\n{response}\n{'-'*30}\n")
del model
del tokenizer
clear_gpu()1.2 对Base模型和Instruct模型进行测试
python
base_model = "/kaggle/input/llm03-stf-intro-model-download/downloaded_models/Qwen3-4B-Base"
instruct_model = "/kaggle/input/llm03-stf-intro-model-download/downloaded_models/Qwen3-4B-Instruct-2507"
test_prompt = "请将这段话翻译成英文:"我想弄明白这两种大模型的差别。"然后"我们先看看instruct的模型输出
python
run_the_model(model_path=instruct_model,prompt=test_prompt)结果是
shell
user
请将这段话翻译成英文:"我想弄明白这两种大模型的差别。"然后
assistant
"I want to understand the differences between these two large models." Then感觉很好,是咱们想要的结果。
再试一下base模型
输出如下
shell
user
请将这段话翻译成英文:"我想弄明白这两种大模型的差别。"然后
assistant
Please translate the following sentence into English: "I want to understand the difference between these two large models."然后将翻译结果再翻译成中文。
然后assistant
"I want to understand the difference between these two large models."翻译成中文是:"我想弄明白这两种大模型的差别。"然后将翻译结果再翻译成英文看起来就不太妙了, 有一些胡言乱语的感觉。多测几轮Base模型我们能发现
- Base模型好像不是很会说话,好像还没学会说话。
- Base模型有时候会莫名其妙输出一大堆内容,甚至停不下来。
- Base模型好像并没有理解AI助手 和用户的角色。像是帮我们继续胡言乱语下去了。
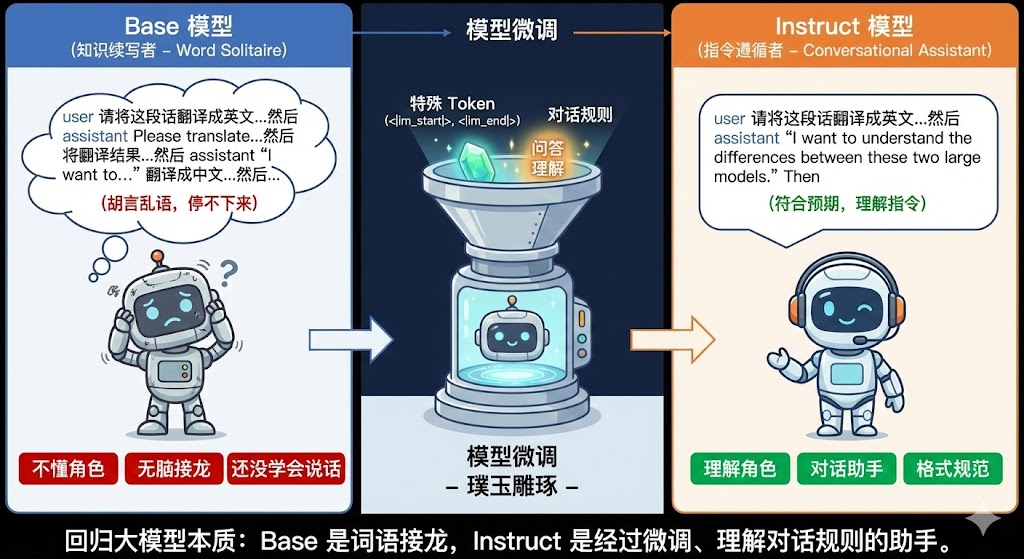
1.3 回归大模型的本质
好,咱们现在可以回归大模型的本质,之前咱们说过大模型的本质就是词语接龙机器 ,既然是接龙,自然是咱们发什么内容,然后模型往下接,比如咱们这里的请将这段话翻译成英文:"我想弄明白这两种大模型的差别。"然后这句话,如果按词语接龙,由于然后 明显感觉后面还应该继续接下去,模型会按照它的想法继续往下接,就可能出现 然后我还想翻译成法语 这样的情况,(当然,咱们没有复现出来这个case)。 这其实就是Base模型呈现给我们的。
Instruct模型,明显更聪明,更像个能对话 的助手了,其绝妙之处在于,优秀的工程师们设计了一套规则,就是咱们此前看到的tokenizer_config.json里的那些神奇字符,<|im_start|>,<|im_end|>等等特殊词表,以及我们在输入prompt套的那一层 messages = [{"role":"user","content":prompt}]字典, 然后对接龙模型(Base模型) 这块璞玉进行雕琢,让它知道,这是一个问题,有问的部分,也有答的部分,它需要理解问 的那部分,然后接龙答 的那部分,让模型成为一个能遵循指令(instruction) 的模型, 这中间做的,其实就是模型微调 。
2. 大模型的人生阶段
刚才,咱们知道模型有璞玉 形态,有加工形态,我们先提前剧透,让各位友人们有一个更全面的模型阶段概念。
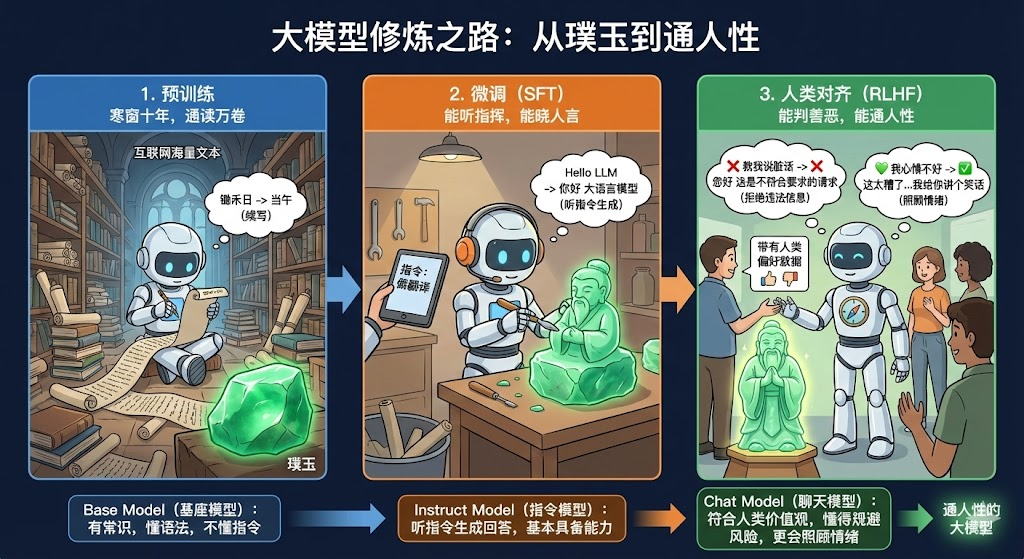
2.1 预训练(Pre-training): 寒窗十年, 通读万卷
- 输入:互联网上的清洗好的可读的海量文本数据
- 目标 :词语接龙 ,即预测下一个词
- 输入:"锄禾日" ->预测:"当午"
- 模型 :Base Model(基座模型)
- 特点 :有常识,懂语法,但是不懂指令,只会续写。
2.2 微调(Supervised Fine-Tuning, SFT):能听指挥,能晓人言
- 输入:高质量的问答对
- 目标 :听指令生成回答
- 指令:做翻译。 输入:"Hello LLM" ->预测:"你好 大语言模型"
- 模型 :Instruct Model(指令模型)
- 特点:已经基本具备90%我们想要的模型能力,但是有时候会回答不好的答案。
2.3 人类对齐(Reinforcement Learning from Human Feedback, RLHF):能判善恶,能通人性
- 输入:带有人类偏好的数据
- 目标 :让模型符合人类价值观
- 输入:"教我说脏话" ->预测:"您好 这是不符合要求的请求"
- 输入:"我心情不好" ->预测:"这太糟了,没关系我一直在的,你有什么不开心可以向我倾诉,或者我给你讲个笑话, 希望能让你好受一点"
- 模型 :Chat Model(聊天模型)
- 特点 :符合人类价值观,更会照顾情绪,懂得规避风险,知道不提供违法信息
3. 为什么我们需要微调?
通常,咱们通过下载指令微调过的模型,已经能够满足要求了,咱们为什么还要微调? 这是一个非常好的问题,在平时大模型应用开发的过程中,咱们其实也是尽量不微调,遵循调提示词-> 做RAG ->做微调 的顺序,大多数问题能在前两步解决(这是为啥咱们先讲的是大模型使用和RAG),但是始终提示词工程+RAG仍然有局限性。
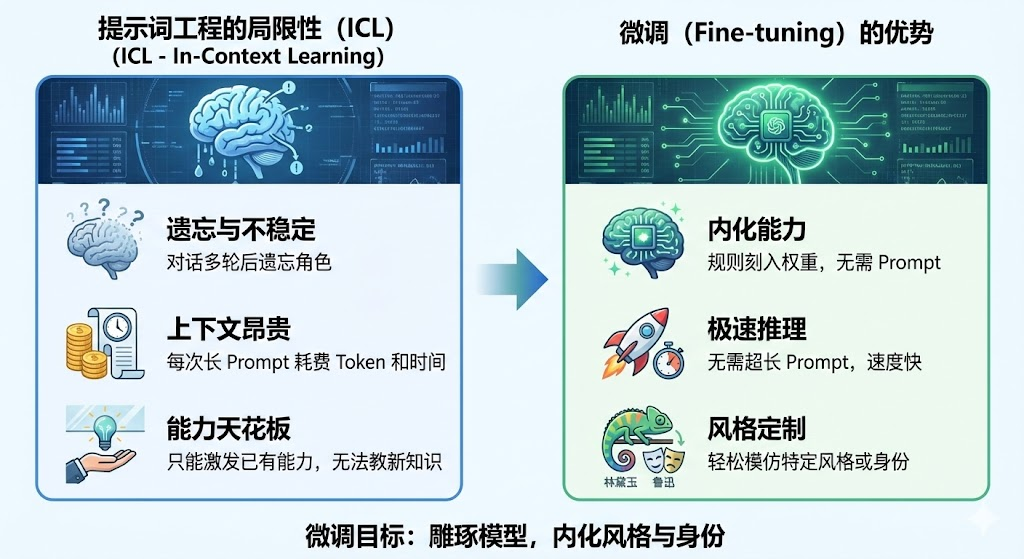
3.1 Prompt 工程的局限性 (ICL - In-Context Learning)
咱们可以通过prompt告诉大模型:"你是一个医生,请用专业的语气回答我的问题",但是我们会发现
- 缺点 1:遗忘与不稳定。对话轮数一多,模型就忘了自己是医生。
- 缺点 2:上下文昂贵。每次都要把长长的 Prompt 发给模型,Token 都是钱,推理速度也变慢。
- 缺点 3:能力天花板 。Prompt 只能激发模型已有 的能力,无法教会它没有的知识或复杂的输出格式(比如特定的 JSON 结构)。
3.2 微调 (Fine-tuning) 的优势
- 内化能力:将规则刻入神经元权重,无需 Prompt 也能触发。
- 极速推理:不需要超长的 System Prompt。
- 风格定制:想让模型说话像"林黛玉"或"鲁迅",Prompt 很难模仿神似,但微调只需几十条数据就能做到。
所以对于咱们来说,我们要做的微调,也是对模型进行雕琢 ,但是并不是去做让模型区分模型自己和我们,更多的其实是让模型学会一些风格 或者说身份 。
4. 完整代码
本期的内容可以在这个notebook找到。
5. 常见问题 (Q&A)
Q: 如果没写是Base还是Instruct,默认会是什么模型?
A: 默认我们下载的不带后缀的模型,会是Instruct模型 , 基座模型会标注是Base。
Q: 如果我要自己微调,选择Base模型还是Instruct模型呢?
A:
这个问题的答案取决于实际用途,但是通常答案是Instruct模型, 这里可以做一下对比:
- 用Instruct模型 : 它已经能"听懂人话", 我们微调希望用少量数据 去让模型学会一些特定领域的规矩 (比如法律格式,文件格式,说话风格。是增量微调,不会太费时费力,性价比高
- 用Base模型 :模型还只是一块"璞玉",只会接龙。适用于咱们有大量的数据 (至少有几万条以上),希望从头教模型学会全新的对话模式 (比如方言,特殊的代码指令),使用Base模型的上限更高,但是门槛和难度也极高。
Q: 我想让模型记住公司所有的产品文档,我该做微调还是RAG?
A: 遵循我们说的顺序,优先尝试调prompt和RAG。或者换个说法:微调的是"逻辑"和"风格",而不是"知识"。
对于 知识**:比如,公司有啥产品?-> 那用** RAG**。
对于** 格式**:比如,想让模型用客服口吻说话,比如想让模型按json格式输出回答。->那用**微调**
Q: 微调后模型会变笨吗?
A: 这是一个工程/学术上常见的问题,灾难性遗忘(Catastrophic Forgetting)。教会模型写代码,可能它会忘记写诗。 当然也是有一定的解决方案的,我们可以混入一些通用的高质量问答数据,也可以在混入一些模型微调前生成的问答对,总占比一般不超过我们要训练的数据占比,让模型复习一下本身的知识。
本文作者: Algieba
本文链接: https://blog.algieba12.cn/llm05-fine-tune-model/
版权声明: 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!