前言:本文将简单介绍一下UDP协议在传输层的地位,UDP的报文结构以及实际运用
一、 为什么需要 UDP?
在当下的互联网流量时代中,网络通信传输数据的准确性以及可靠性是一个不可忽视的因素。TCP凭借着这两点成为流量时代的"领头者"。既然如此,为什么还需要UDP呢?UDP在当下仍然有其生态位,说明自然有其独特之处
-
TCP的代价 :TCP三次握手、拥塞控制、重传机制 虽然保障了其数据传输的可靠性以及准确性,但是传输延迟却远大于UDP
-
UDP的定位 :极致的性能,最小的开销
-
应用场景:流媒体、在线游戏、IoT 设备、域名解析 (DNS),服务器间通信(同一房间)
二、 UDP 报文结构
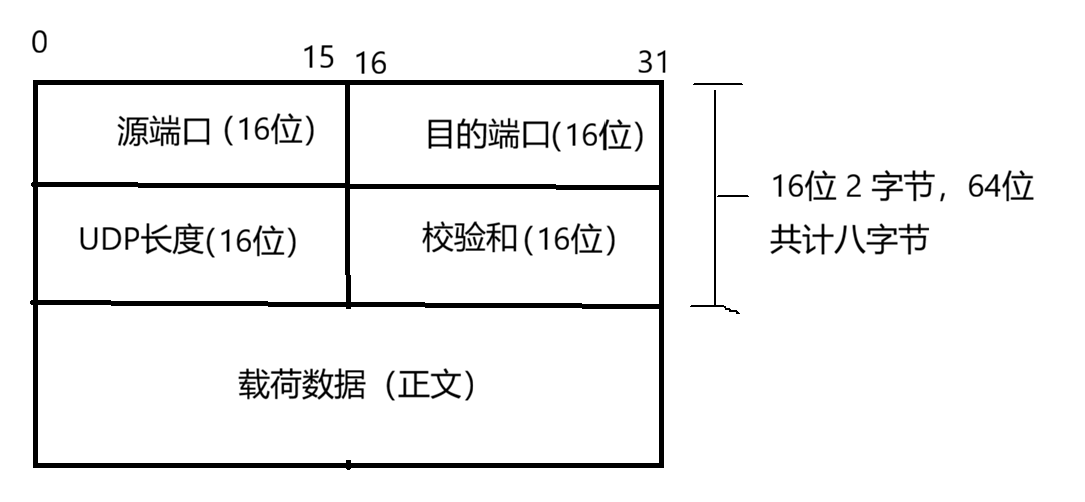
要想了解为什么UDP快,就得从其报文结构入手,下面是一个UDP的报文结构简图:
-
源端口: 位于报头,占据2个字节16位。可以为0,但是不能为空,意味着此数据一经发出无需接收方返回,但是源端口为0的UDP比较少见。
-
目的端口: 2个字节,标识数据该发送到一台主机的哪一个应用程序,即流量该发往何处?
-
UDP长度: 2个字节,UDP长度 = 报头长度 + 载荷长度
范围为:0 - 2^16 - 1 ,最大长度为65535字节,最小长度为65535 - 8 = 65527(无载荷)
虽然UDP最大可以表示64KB的数据,但是一次性传输这么大的数据可以说是会百分百丢包,实际使用UDP传输数据会限制载荷的长度
-
校验和: 校验和是一个用于检测 UDP 报文在传输过程中是否发生了比特错误
UDP数据报在传输的过程中,会"借"来一部分 IP 层的字段,组成一个 12 字节的伪首部
伪首部+报头+载荷共同组成了一个16位的整数。当接收方拿到数据时,会二进制反码求和,当计算的结果为1时,说明数据传输无误。否则直接丢弃(不是我想要的包裹,直接丢弃)
三、 UDP的三大特性
无连接
无连接代表UDP传输数据无需和对方建立连接。就好比发送短信,不需要先和发送对象建立连接才能发送,而是想发就发(只需要知道对方的手机号就行)。
使用UDP传输数据时只需要知道对方的IP和端口号就能发送数据,不像TCP正式传输业务数据前还得经历三次握手,四次挥手等复杂的确认机制,这也是导致UDP传输快的一大原因之一。
不可靠传输
不可靠传输是UDP不提供数据可靠性的保障机制,而不是数据传输一定会出问题。
也就是说UDP只管发送数据,数据有没有到达服务器,数据传输出错,UDP概不负责。
这也是UDP为了实现低延迟,高吞吐,轻量级传输的保证,其无连接的特性具体可以提现在以下几点:
1.无确认连接
UDP 无需三次握手,发送方直接发数据报,不知道接收方是否存在、是否在线、是否能接收,属于 "一发了之";
2.无确认应答(ACK)
接收方收到 UDP 数据报后,不会向发送方返回任何确认包,发送方永远不知道数据是否被成功接收;
3.无丢包重传
若数据报在 IP 层丢包(如网络拥塞、MTU 分片丢失、路由故障),UDP 不会检测丢包,也不会触发重传;
4.无重复去重
因 IP 层的重传或路由异常,UDP 数据报可能重复到达,UDP 不会检测重复,会直接将重复数据报交付应用层;
5.无数据报排序
UDP 数据报是独立的,底层 IP 网络可能因路由不同导致乱序到达 ,UDP 不会记录序列号,接收方会按收到的顺序直接交付应用层,不会重新排序;
6.无流量 / 拥塞控制
UDP 发送方会以自己的速率持续发送数据 ,不管接收方的处理能力(是否忙、缓冲区是否满),也不管网络拥塞程度,容易导致接收方缓冲区溢出丢包,或加剧网络拥塞。
面向数据报
面向数据报表示UDP传输数据的基本单位是数据报,而不是字节流那样的以流水形式接受,其体现可以分为以下几点
1.一次 send 对应一次 recv
如果把TCP面向字节流传输数据比作流水,发送方可以合并读取,也可以随机选择read的字节数目,那么UDP就是对流水严格封装为一个矿泉水瓶
假如发送方三次分别发送了100,200,300字节的数据报。接收方也只能限制三次去接受,不能合并接受(太少了我多拿点吧~),也不能分批接收(太多了我把一份数据报分几次接收)
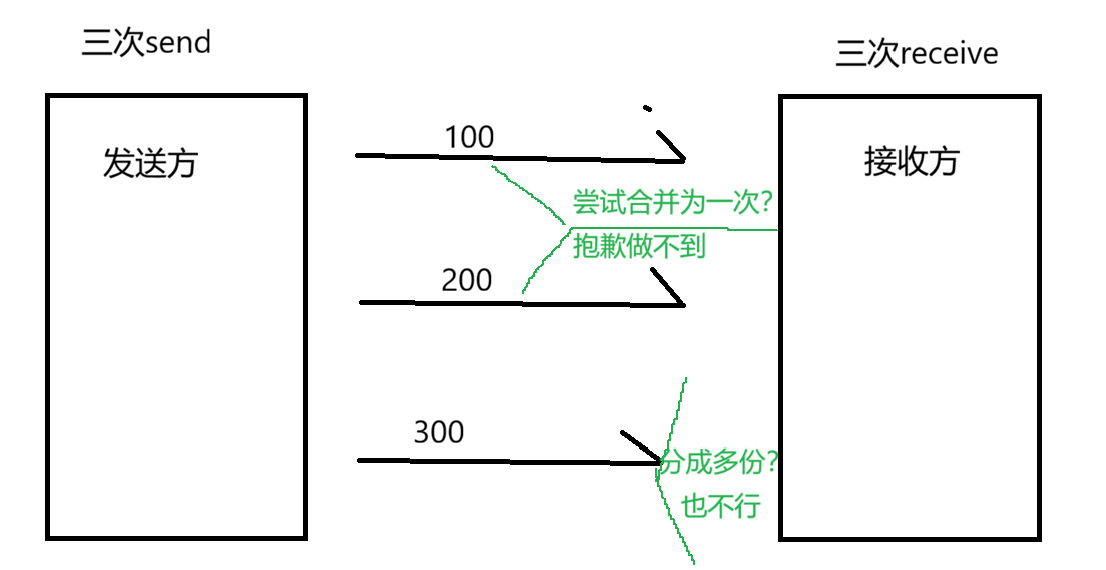
2.数据报间独立,无粘包,拆包
每个数据报又有着对应的receive操作,数据报之间相互独立保证了接收方从缓冲区读取数据时不会出现多读(粘包),拆包(少读)问题的出现,一定程度上保证的读取数据的完整性
3.缺点:容易溢出
由于UCP限制数据报一发一读,当发送的数据报大小超过了缓冲区的容量,或者缓冲区的剩余容量不足以容纳发送过来的数据报时,会出现丢包
四、避坑:UDP 开发的注意事项
MTU 与分片陷阱
核心前提 :MTU(最大传输单元)
- MTU是数据链路层规定的单个帧能承载的最大 IP 数据包大小 ,也就是数据链路层的最大IP数据包的大小。这个数值最大为1500
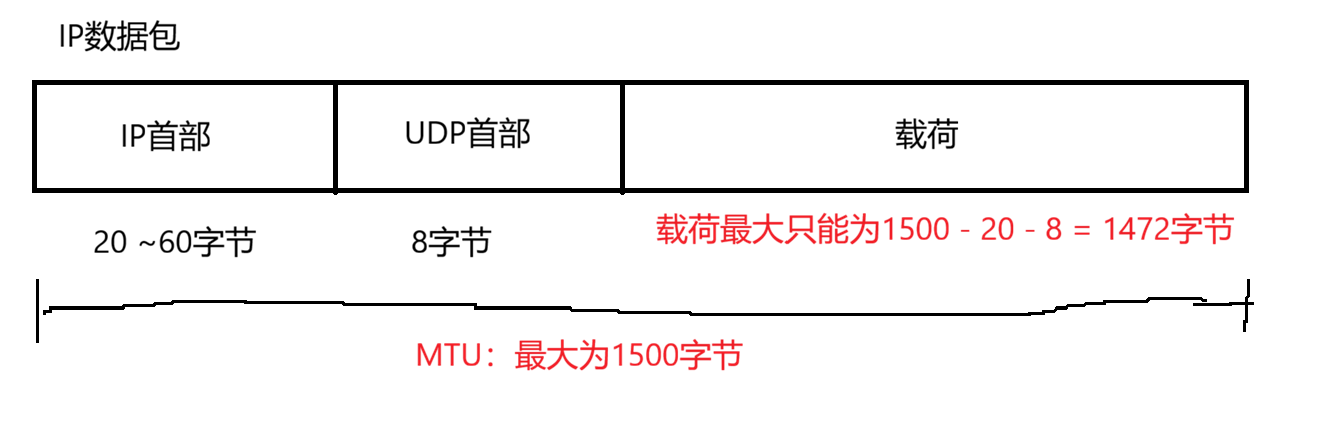
为什么要MTU限制IP数据包在1500字节以内?以下是几点原因:
IP分片处理
假设传输的IP数据包超过了数据链路层MTU的,装不下,路由器或发送方的主机就必须把这个大包切成若干个小碎片发送,这就是 IP 分片 。
小碎片可没有转转帮忙回收,并且UDP以数据报为基本传输单元,IP分片破坏了UDP数据报的完整性,导致接收方收到的数据缺失
丢包处理
UDP的不可靠传输使得它不会处理丢包问题,但是这只是站在传输层的视角来看待的。从应用层来看也是能够处理丢包的,处理方法以下列出
1. 确认与重传 (ARQ)
这是最直接的方法,手动实现 TCP 的功能:
-
ACK 机制: 接收方收到包后,给发送方发一个"收到了"的小包。
-
超时重传: 发送方如果 200ms 没收到 ACK,就重新发一遍。
-
代表协议: KCP 、QUIC。
2. 前向纠错 (FEC, Forward Error Correction)
这是实时通信(RTC)中的绝招,用空间换时间。
-
逻辑: 发送方在发 A 和 B 的时候,顺便发一个 A+B 的校验包 C。
-
效果: 如果 A 丢了,接收方可以通过 B 和 C 把 A 算出来。
-
优点: 无需等待重传,延迟极低。
3. 冗余传输 (Redundancy)
-
做法: 重要的数据包直接连发两遍或三遍。
-
场景: 游戏中的"开火"指令或"位移"指令,宁可浪费带宽也要保证到达。
接收缓冲区溢出
当数据包到达的速度超过了你程序处理(recv)的速度,内核的缓冲区就会被填满。一旦满了,后续到达的包会被系统直接丢弃,且不会通知发送方和接收方。
为什么会溢出?
你可以把接收缓冲区想象成一个"漏斗":
-
进水快: 网络层源源不断地把 UDP 数据报塞进内核缓冲区。
-
出水慢: 你的应用程序(比如 Java 的
DatagramSocket.receive())因为业务逻辑复杂(要写数据库、解析 JSON 等)处理得太慢,导致漏斗满了。
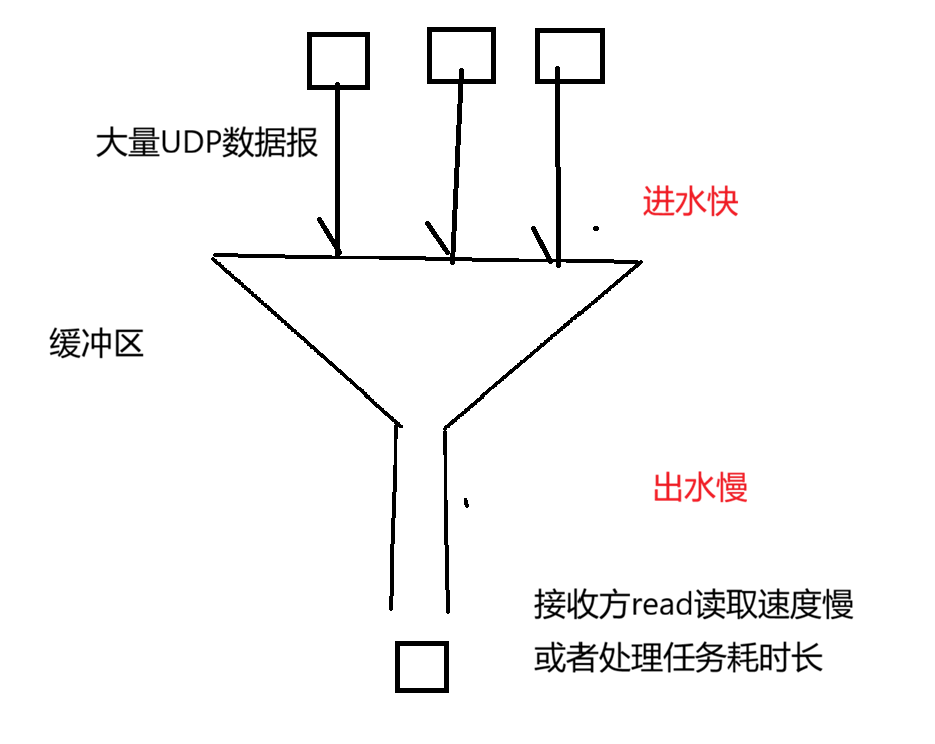
溢出的后果
-
静默丢包: UDP 不会像 TCP 那样通过"流量控制"让发送方慢一点,它只会默默地把包扔掉。
-
应用层逻辑断裂: 如果你在做视频流传输,你会发现画面开始频繁花屏;如果是传感器数据,你会发现数据出现了明显的断层。
如何处理缓冲区溢出?
要注意,该缓冲区溢出涉及到对操作系统内核的操作,而PrintWriter冲刷的缓冲区只是应用层的缓冲区。处理方法如下,这里不做详细介绍:
- 增大内核缓冲区 (最快的方法) :
通过代码或者系统命令修改缓冲区大小 - 优化接收端逻辑 (治本的方法) :
使用生产者-消费者模型 - 使用批量接收 (Recv-mmsg) :
通过系统调用,一次性从内核中取出多个UDP数据包
安全隐患
UDP 反射攻击(UDP Reflection Attack)
UDP反射攻击利用了UDP无连接(无需握手)和源端口可伪造的性质,其核心原理可以说是借刀杀人
UDP 反射攻击并不是攻击者直接发包给受害者,而是找一个中间人(反射服务器),让中间人去"轰炸"受害者。
-
第一步:伪造地址。 攻击者把自己的 IP 地址伪造成受害者的 IP。
-
第二步:发起请求。 攻击者向公网上成千上万个开放的 UDP 服务(如 DNS、NTP、SNMP、Memcached)发送一个很小的请求包。
-
第三步:反射。 这些服务器收到请求后,会按照协议规定回复一个响应包。由于请求包里的"源 IP"是伪造的,这些服务器会整齐划一地把庞大的响应包发给真正的受害者 。
并且由于DNS和NTP等协议导致的放大效应存在,使得只需要少量的数据包就能使得服务器返回放大后的几十到几百倍的数据包。
关于本文对于UDP的介绍就到这里了,如有纰漏还请指出~~