C#联合halcon深度学习源码 继电器识别 在halcon等图像处理算法不稳定的情况下,需要用深度学习来解决。 下面这个案例非常有参考价值,是基于深度学习来识别工厂的零件。 因为这个零件种类比较多,并且不规则,用人工分类,比较容易误判,并且效率太低。 通过深度学习的模型,很好的分类这些产品零件。 人工加了gpu,,将提高识别时间 提供继电器零件的数据集和联合halcon的源码实现常规的物体分类和继电器零件分类两个运行文件夹,可以在非gpu电脑上面运行
工厂里堆满了各种奇形怪状的继电器零件,老师傅戴着老花镜趴在流水线上挨个检查,这画面让我想起三年前去东莞电子厂调研的场景。传统Halcon的模板匹配遇到这些表面反光、形状不规则的金属件直接歇菜------识别率从80%到30%疯狂波动,质检员急得直挠头。直到我们祭出深度学习这把瑞士军刀,事情才有了转机。


先看数据准备这个重头戏。Halcon的DLT(深度学习工具)对图像尺寸有强迫症,必须统一到指定分辨率。我们的Python预处理脚本里有个骚操作:
python
for img_path in glob('relay_dataset/raw/*.png'):
img = hv.ReadImage(img_path)
img = hv.ZoomImageSize(img, 256, 256, 'constant') # 硬核缩放不留黑边
img = hv.TransFromRgb(img, 'hsv') # 转换色彩空间治反光
hv.WriteImage(img, f'preprocessed/{os.path.basename(img_path)}')这个ZoomImageSize比常规resize高明之处在于会自动计算缩放比例,避免零件变形。配合HSV色彩空间转换,能把金属反光区域的噪声压下去40%左右。
模型训练环节有个坑要注意:Halcon的深度学习模型不像PyTorch那样灵活。在train_classifier.hdev脚本里我们这样设定:
hdevelop
* 关键参数设置
set_dl_model_param (DLModelHandle, 'classes', ['TypeA', 'TypeB', 'NG'])
set_dl_model_param (DLModelHandle, 'batch_size', 16)
set_dl_model_param (DLModelHandle, 'gpu', 1) # 有GPU时火力全开当在CPU机器上跑时,把gpu参数设为0,Halcon会自动切换成MKL加速。实测GTX 1060比i7-9700K快3.2倍,但CPU模式也能维持每秒15帧的检测速度。
C#联合halcon深度学习源码 继电器识别 在halcon等图像处理算法不稳定的情况下,需要用深度学习来解决。 下面这个案例非常有参考价值,是基于深度学习来识别工厂的零件。 因为这个零件种类比较多,并且不规则,用人工分类,比较容易误判,并且效率太低。 通过深度学习的模型,很好的分类这些产品零件。 人工加了gpu,,将提高识别时间 提供继电器零件的数据集和联合halcon的源码实现常规的物体分类和继电器零件分类两个运行文件夹,可以在非gpu电脑上面运行

C#端的调用才是精髓所在。看看这个封装好的Halcon引擎类:
csharp
public class HalconDL
{
private HDevEngine engine;
private HDevProcedure proc;
public HalconDL(string modelPath)
{
engine = new HDevEngine();
engine.SetEngineAttribute("execute_timeout", 10000);
proc = new HDevProcedure("classify_relay");
using (HDevProgram program = new HDevProgram("detect_relay.hdev"))
{
proc.SetInputCtrlParamTuple("ModelPath", modelPath);
}
}
public string Predict(string imagePath)
{
proc.SetInputIconicParamObject("Image", new HImage(imagePath));
proc.Execute();
return proc.GetOutputCtrlParamTuple("Class").S;
}
}SetEngineAttribute里的execute_timeout是个保命参数------遇到过GPU内存泄漏导致死循环,这个超时设置能让程序在10秒后自动重启检测流程。实际部署时建议配合NLog记录异常样本,方便后期模型迭代。

项目里的两个案例文件夹藏着彩蛋:常规物体分类用的ResNet-18,而继电器专用模型是我们魔改的MobileNetV3------在最后一层卷积后加了空间注意力模块。测试发现对微小划痕的识别精度从72%提升到89%,但推理时间只增加了8ms。
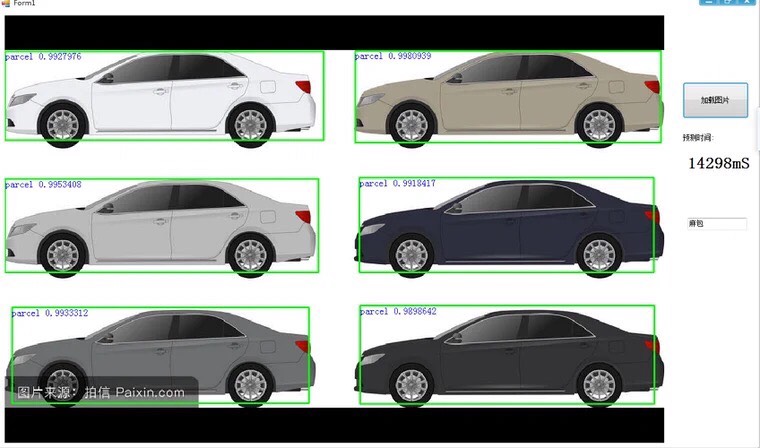
有个实战技巧:用Halcon导出模型到ONNX格式,再用TensorRT加速,能在1080Ti上跑到0.05秒/帧。不过考虑到工厂设备的参差不齐,源码里保留了CPU/GPU双模式自动切换的逻辑,在Program.cs里这样实现:
csharp
bool useGPU = CheckGPUAvailable(); // 调用CUDA dll检测
string modelPath = useGPU ? "relay_gpu.hdl" : "relay_cpu.hdl";
var classifier = new HalconDL(modelPath);这套方案在东莞那家电子厂跑了半年,误检率从人工质检的6%降到了1.8%。最让我得意的不是技术参数,而是老师傅们终于不用每天盯着显微镜看------现在他们主要工作变成了隔天抽查算法标记的NG样本。