文章目录
一、基本介绍
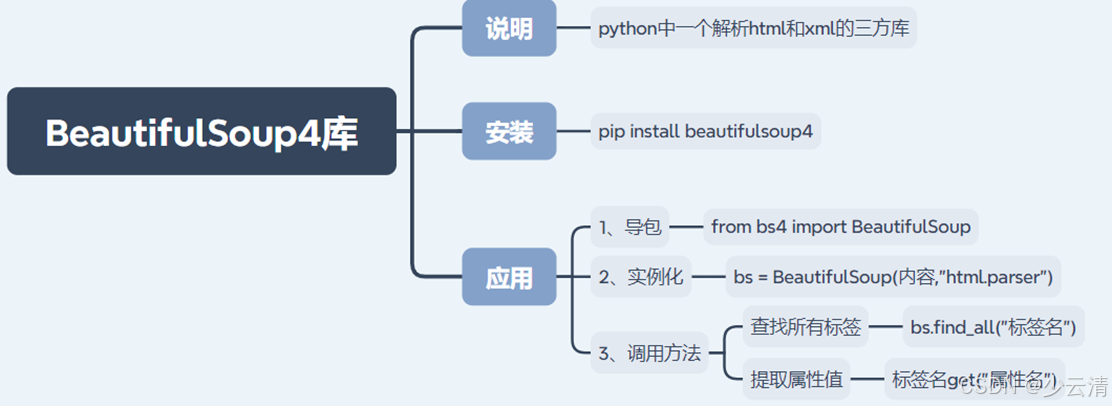
- Beautiful Soup是一个可以从HTML或XMIL文计中提取数据的Python库.
- 它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.
- Beautiful Soup会帮你节省数小时甚至数天的工作时间.
- Beautiful Soup 3目前已经停止开发,推荐在项目中使用Beautiful Soup 4,简称BS4.
yacas
一个python解析HTML\xml的三方库二、使用步骤
2.1 安装
shell
pip install beautifulsoup4注意:包的名称为beautifulsoup4而不是BeautifulSoup,BeautifulSoup是Beautiful Soup3的发布版。
2.2 如何使用
python
# 导入类
from bs4 import BeautifulSoup
# 实例化
soup = BeautifulSoup(open("index.html"), "html.parser") # 方法1
soup = BeautifulSoup(内容, "html.parser") # 方法2
ele = soup.标签名 #根据标签名获取标签对象,如果匹配多个元素,则返回第一个
ele_list = soup.find_all(标签名) # 根据标签名获取所有匹配的标签
attr_value = ele.get(属性名) # 根据标签的属性名获取对应的属性值
text = ele.get_text() # 获取标签的文本内容
yacas
说明:
- 将一段文档传入BeautifulSoup的构造方法,就能得到一个文档的对象
- "html.parser": Python标准库中的HTML解析器。BeautifulSoup还支持一些第三方的解析器,如:lxml、html5lib等,这些第三方解析器需要额外安装三、示例
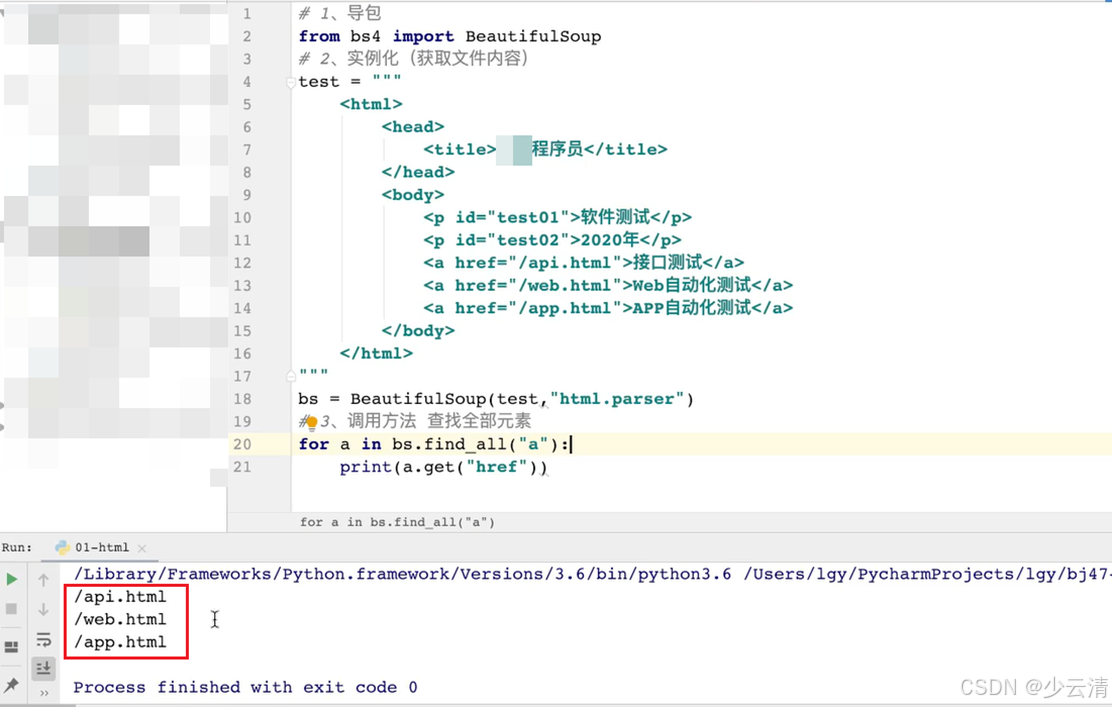
应用步骤:
1、导包
2、实例化(获取文件内容)
3、调用方法
python
# 1、导包
from bs4 import BeautifulSoup
test = """
<html>
<head>
<title>程序员</title>
</head>
<body>
<p id="test01">软件测试</p>
<p id="test02">2020年</p>
<a href="/api.html">接口测试</a>
<a href="/web.html">web自动化测试</a>
<a href="/app.html">APP自动化测试</a>
</body>
</html>
"""
#2、获取bs对象 告诉BeautifulSoup类,你要解析的是hmtl格式
bs = BeautifulSoup(test,"html.parser")
#3、调用方法
"""
重点:
1、查找所有标签 bs.find_all("标签名") == 元素的集合 == ["元素1", "元素2"]
2、提取属性值 标签名.get("属性名")
"""
for a in bs.find_all("a"):
print(a.get("href"))
# 4、其它方法
print(bs.p.string) # 获取P标签的文本
# 5、获取标签名
print(bs.p.name)