1、PDF文件加载和切片
PDF 中的文本通常通过文本框表示。它们也可能包含图像。PDF 解析器可能会执行以下作的某种组合:
通过启发式或 ML 推理将文本框聚合为行、段落和其他结构;
对图像运行 OCR(https://en.wikipedia.org/wiki/Optical_character_recognition) 以检测其中的文本;
将文本分类为属于段落、列表、表格或其他结构;
将文本构建为表格行和列或键值对。
Python中有许多 PDF 解析器集成。有些是简单且相对较低的;其他 API 将支持 OCR 和图像处理,或执行高级文档布局分析。正确的选择将取决于您的需求。
pypdf
它将返回一个 Document(https://python.langchain.com/api_reference/core/documents/langchain_core.documents.base.Document.html) 对象列表 -- 每页一个 -- 在 Document 的属性中包含页面文本的单个字符串。它不会解析图像或扫描的 PDF 页面中的文本。
python
```
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader(file_path)
pages = []
async for page in loader.alazy_load():
pages.append(page)
```Unstructured
如果您需要对文本进行更精细的分割(例如,分割成不同的段落、标题、表格或其他结构)或需要从图像中提取文本,则以下方法适用。它将返回 Document 对象列表,其中每个对象代表页面上的一个结构。Document 的元数据存储页码和与对象相关的其他信息(例如,如果是 table 对象,它可能会存储 table 行和列)。
`UnstructuredLoader` 是 LangChain 中用于加载非结构化文档(如 PDF、Word、HTML 等)的工具。以下是代码中各个参数的解释:
- **`file_path=pdf_file`**
* 指定要加载的 PDF 文件路径。可以是本地文件路径或 URL。
- **`strategy="hi_res"`**
* 解析策略,决定如何处理文档内容。可选值包括:
* `"fast"`:快速解析,适合简单文档,但可能忽略复杂布局。
* `"hi_res"`:高精度解析,适合复杂布局(如多栏、表格、图片),但速度较慢
* `"auto"`:自动选择策略(默认)。
- **`partition_via_api=True`**
* 是否通过 Unstructured API 进行文档分区(即拆分文档为结构化块)。
* 若为 `True`,需提供 `api_key` 并依赖网络请求;若为 `False`,则使用本地解析逻辑(需安装额外依赖)。
- **`coordinates=True`**
* 是否保留文本在原始文档中的坐标信息(如位置、边界框)。这对需要精确定位文本的应用(如表格提取)很有用。
- **`api_key='IhWKAZRBmZ14c8tmCsOLabqwIKLJ2e'`**
* Unstructured API 的访问密钥,用于通过云端服务处理文档。若无此密钥,需本地运行分区逻辑
**高精度解析** : 策略为文档布局分析和 OCR 提供支持。
**本地构建Unstructured环境**
在本地解析需要安装其他依赖项。
**Poppler** (PDF 分析)
* Linux的:`apt-get install poppler-utils`
* 苹果电脑:`brew install poppler`
* Windows:https://github.com/oschwartz10612/poppler-windows(https://github.com/oschwartz10612/poppler-windows)
**Tesseract** (OCR)
* Linux的:`apt-get install tesseract-ocr`
* 苹果电脑:`brew install tesseract`
* Windows:https://github.com/UB-Mannheim/tesseract/wiki#tesseract-installer-for-windows(https://github.com/UB-Mannheim/tesseract/wiki#tesseract-installer-for-windows)
我们还需要安装 PDF 解析器:`unstructured`
```python
%pip install -qU "unstructuredpdf"
```
```
loader_local = UnstructuredLoader(
file_path=file_path,
strategy="hi_res",
)
docs_local = \[\]
for doc in loader_local.lazy_load():
docs_local.append(doc)
```
安装Langchain的第三方库:
```
pip install langchain langchain-community langchain-unstractured iPython 等等
```
**配置HuggingFace镜像站:**\*\*https://hf-mirror.com/\*\*(https://hf-mirror.com/)
- 安装依赖**
```
pip install -U huggingface_hub
```
- 设置环境变量**
*Linux*
```
export HF_ENDPOINT=https://hf-mirror.com
```
2、Markdown文件加载和切片
需要 Unstructured 包的 UnstructuredMarkdownLoader 对象。首先我们安装它:
```
pip install "unstructuredmd" nltk
```
两种解析md文件的模式:
* `"elements"`:将Markdown解析为结构化元素(标题、段落、列表等),每个元素都带有元数据(如类型、层级关系等)
* `"single"`(默认):将整个Markdown文件作为单个文档加载,不保留结构信息
3、语义切割
在 `SemanticChunker` 中,`breakpoint_threshold_type` 参数用于控制如何确定文本语义分割的阈值,即何时将文本拆分为不同的块。以下是该参数的详细说明:
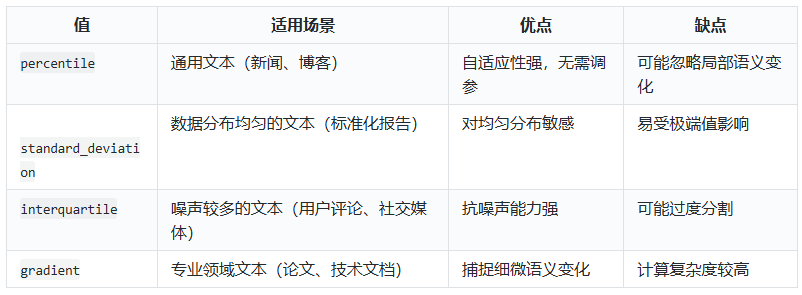
参数值及其区别
- **`percentile`(默认值**
* **原理** :计算所有句子间向量差异的百分位数(如第90百分位),差异大于该百分位数的位置会被拆分。
* **特点** :适用于通用场景,能自适应不同文本的语义分布。
- **`standard_deviation`**
* **原理** :基于句子间差异的标准差设定阈值,差异超过均值加X倍标准差时拆分。
* **特点** :适合数据分布较均匀的文本,对异常值敏感。
- **`interquartile`**
* **原理** :使用四分位距(IQR)确定阈值,差异超过上四分位加一定倍数的IQR时拆分。
* **特点** :对异常值鲁棒,适合长尾分布或噪声较多的文本。
- **`gradient`**
* **原理** :结合百分位数和梯度变化检测语义边界,适用于高度相关或领域特定的文本。
* **特点** :能识别细微的语义变化,适合技术文档或专业领域内容。
应用场景对比