目前盘下来,我比较花时间的事(但我觉得不应该花,也不想花):
- 1 部署与运维。系统软件安装,以及基于容器的微服务部署。
- 2 ETL。这里做一些泛化,除了传统的ETL,凡是具有高确定处理逻辑的程序和服务,我都归为ETL。
- 3 复杂数据处理。当数据处理中遇到比较复杂的功能(比如要加一步实体识别),或者是要联系其他数据进行比对(复杂的比对逻辑),而不是单条无依赖的处理。
ETL方面,之前通过JWT开发 的这篇文章已经比较明确的证明了:基于图结构的处理方式 + 规范文档,可以在大模型辅助的情况下,几乎不需要写代码就能完成。所以只要围绕着更好的抽象,以及整体流程设计(特别是测试环节),那么类ETL流程类的问题就可以解决了。短期来看,效率已经能够翻倍 ;长期往后做,因为会累积更多的设计和规范,我认为效率最终可以达到4-5倍。
复杂数据处理这块,之前的一些实验已经证明了大模型辅助尚不能完成,我觉得是逻辑复杂度太高了。之后我会尝试一些新的方法,原则上将大模型的数据处理将为单条(单对象),然后采用线程并发的方式。将处理将为单条,以对象为中心,我觉得这是一种逻辑的简化,大模型应该能明白。对于这块的效率提升我不会那么乐观,但要是能翻一倍也是极好的,特别是后期的维护可以很轻松。
然后我觉得部署与运维是相当大的一块可改进点。因为本质上,运维部署属于类ETL的方式,都是高度确定的操作,而且因为与服务器交互的过程中,用vim编辑,输入命令行都是重复性很高的事。更别提在服务器上看配置,改配置,加装软件这样的操作。这件事应该在最近也变得比较可行了,以前的麻烦是有些工具(比如 cursor)会比较容易的作出损毁性操作,而有些工具则干脆不提供这样的操作。
在GLM4.7这一波之后,涌现出了一大批在编程方面能力较强的模型;同步的,很多编程工具也做了改进,我觉得现在看起来问题不大了;当然,我觉得还是要区分环境,在一些非生产的机器上做实验,到了生产机的时候,尽量采取只执行开发好的固定流程或者是在容器内让大模型操作。物理机沙箱优先,容器沙箱次之,但千万不要完全让大模型控制服务器的直接安装,否则搞出幺蛾子损失就大了。
因为我本身主要用的是腾讯的云服务器,我发现code buddy是最适合我的。主要是都是腾讯系,这个工具可以调用的工具容易和腾讯云打通,然后操作起来非常方便。
例如,里面集成了【Lighthouse 工具】,机器人会把浏览器调出,让你扫码登录,然后大模型就可以看到你的服务器了。但有两个小坑可以吐槽下:有时候大模型不会意识到调用这个工具,需要再引导;另外就是大模型通过工具不会获得到期时间,还是需要在浏览器里看。

本次我想借助一个实际操作,让完成部署这块的规范化操作。类似ETL的st规范那样,建立一套类似的规范,一方面方便归档,另一方面可以精确的指导大模型操作。
实例:部署JWT服务,并使用nginx生成5年自签ssl证书来进行https连接访问
背景:上次已经完成了JWT相关的函数开发,并启动了本地gradio服务来进行验证,未来这个应用是重要但低频的。现在我可以把项目放到公网可访问的位置,然后使用 https进行秘钥验证访问。未来需要的话甚至还可以开启IP白名单来确保安全。
1 改造JWT服务
- 修改JWT_KEY为一个复杂字符串
- 增加gradio的启动密码限制
- 启动时放开所有ip
- 在配置文件中指定端口
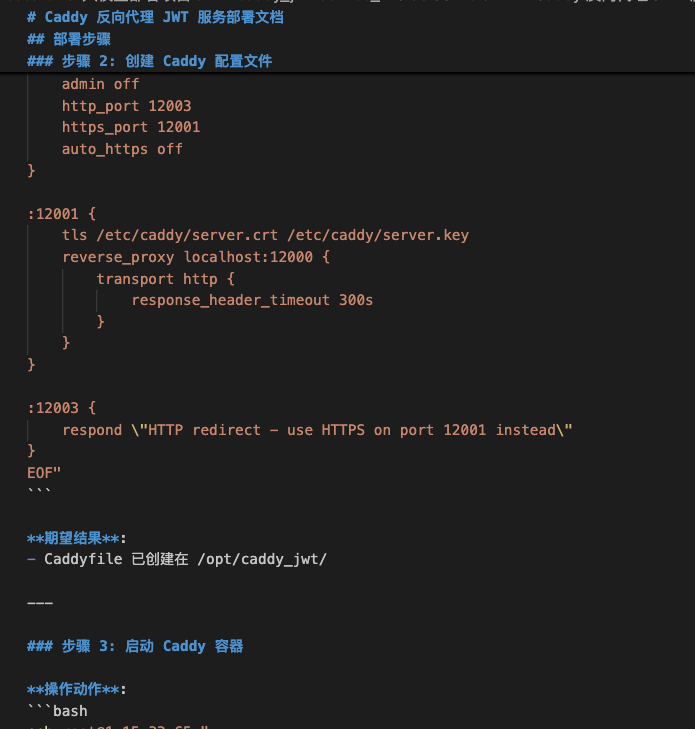
2 配置nginx反向代理
在目标主机(YOUR IP) ,按规范it-0001完成安装
- 1 使用docker方式安装nginx,准备进行反向代理(使用镜像 ccr.ccs.tencentyun.com/YOUR REPOSITORY/nginx:v100)
- 2 如果端口有冲突,使用 10080和10443
- 3 生成5年的自签证书,进行https反向代理
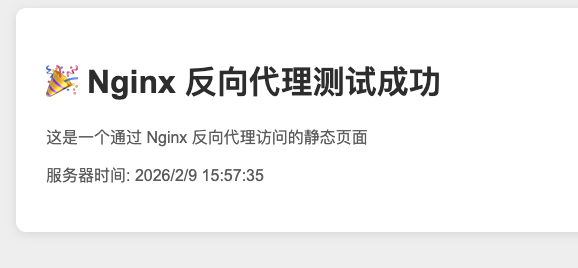
- 4 在目标主机上搭建一个极简的web服务(使用python3 -m http.server方式),测试nginx的反向代理能力
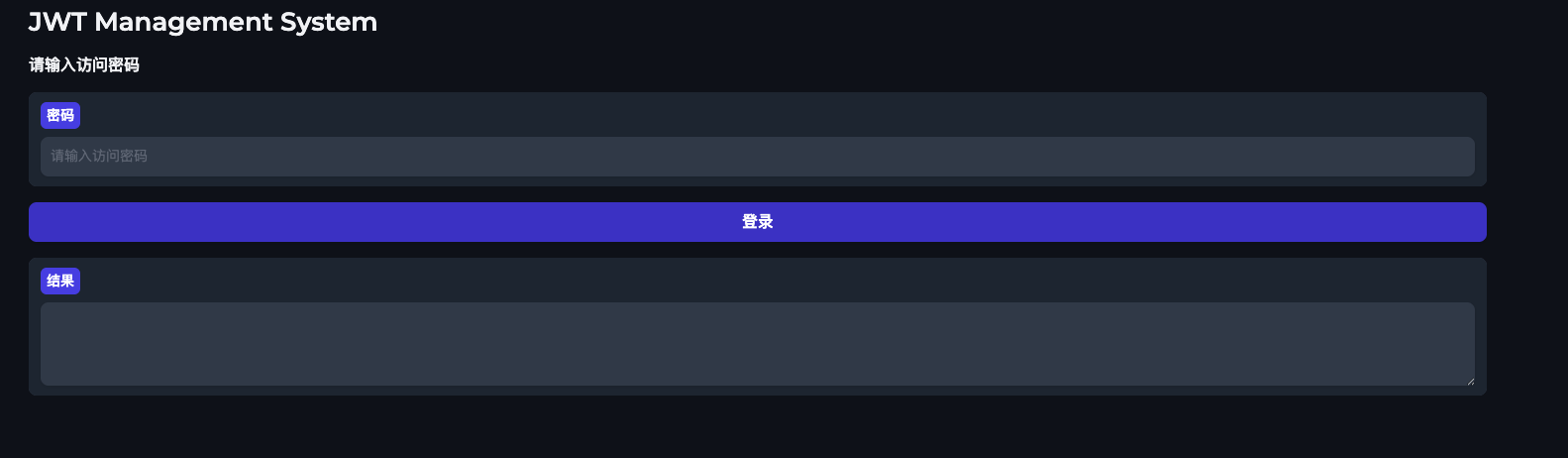
3 配置 jwt_token服务
整体过程还算正常,没有一把梭,但主要的问题是因为我没有把我的环境和习惯说清楚,大模型在这点上也有缺陷,有些基本问题没说清楚会绕不过去。
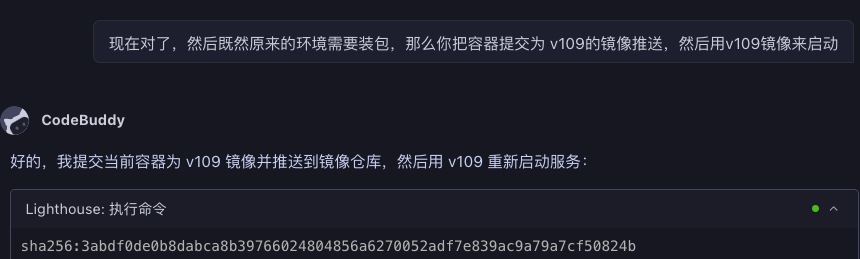
4 使用nginx对 jwt_token进行https转发
这里大模型犯了一些常识性错误,我本来以为这一块大模型挺擅长的,看来也不全是。当然如果是人去做,在这里也会比较烦,我记得以前我也翻过错,而且这些配置的确让人不想再看,比较烦。
其实这块的经验我是有的,我知道大概在哪里出了问题,但是现在我自己都懒得去找(这也是大模型的价值)
好吧,这个错误比较无语,不过毕竟是免费的。

现在我切到opencode,用minimax2.1继续:
测试ssh连接没有问题

我让他继续:
参考当前的部署文件,我在目标主机上部署了服务 jwt-service , 这台机器上还有一个nginx(配置了5年的自签证书),需要用这个nginx 给jwt-service进行https转发,请完成。执行时请参考
it-0001(未完待续)
说明:用于非生产机的部署操作,给到目标主机ip地址,部署需求,以及必要的登录信息(默认root ssh)
1 规范名称:it-0001
2 默认情况下,使用root用户登录目标主机
3 登录后先收集目标主机的操作系统、docker和docker compose版本
4 在安装过程中,如果需要冲突需要修改任务之外的服务或程序,需要和用户确认。(这属于危险操作)
需要给到部署说明文档需要包含每步采取的动作,期望的可验证结果
整体安装测试完成后,需要在implement_list.md 下应在l增加一行,给出部署服务名,简述其作用。
项目生成的文档放置于:/Users/yukai/pre_research/大模型部署项目下面
很可惜,我不知道是不是gradio的问题,虽然被转发了,但是页面上的样式不能修复。
这么看来,nginx的配置可能也算"负责逻辑"了,后续我可能还是得花时间总结一下经验,然后给到样例教会他。
然后我正好有caddy镜像,我让大模型又试了一下,竟然成功了,有趣。(下次如果再做,就可以让大模型直接学习这个例子了)
完成需求。然后等一会code buddy额度恢复后,我会让它关掉我的12000 不加密端口。
总结
从效果上比较符合预期,大模型在部署这块应该可以起到类似 ETL一样的作用。
难点:在复杂配置上,大模型的能力看来是比较有限的(所以我觉得烦也很正常)
以nginx配置为例,可以分为简单后端接口转发、前端转发和流式转发三类应用。这里的经验要总结出来,写成层次分明,结构清晰的文档。然后再给两个样例,锁定好环境、镜像版本,那么以后再指挥大模型干活时就比较简单。
不过话说回来,看起来caddy的确是简单的多,新工具的确是做了改进,绕开了老工具的很多问题,易用性增强了。
Next:
- 做一个部署gallery, 按照结构文档和样例的方式,展示若干种任务的配置方法
- 部署detail, 按大模型当前实际的部署留下详细文档。
最后还是要赞一下,大模型做文档太六了