(时间 = 特征工程)
时间序列模型发展历程(第一讲:AR/MA/ARMA)-CSDN博客
时间序列模型发展历程(第二讲:平稳性危机与ARIMA诞生、SARIMA)-CSDN博客
时间序列模型发展历程(第三讲:指数平滑法 / Holt / Holt-Winters)-CSDN博客
时间序列模型发展历程(第四讲:State Space Models)-CSDN博客
目录
[1️⃣ SVR 在干什么?](#1️⃣ SVR 在干什么?)
[2️⃣ SVR 的优势与局限](#2️⃣ SVR 的优势与局限)
[五、Random Forest / XGBoost:树的时代](#五、Random Forest / XGBoost:树的时代)
[1️⃣ 树模型怎么看时间?](#1️⃣ 树模型怎么看时间?)
[2️⃣ 为什么树模型在时序上反而很强?](#2️⃣ 为什么树模型在时序上反而很强?)
[六、浅层 ANN:连接主义的早期尝试](#六、浅层 ANN:连接主义的早期尝试)
[1️⃣ 它们本质是什么?](#1️⃣ 它们本质是什么?)
[2️⃣ 为什么它们没成为"终极解"?](#2️⃣ 为什么它们没成为“终极解”?)
[🔥 历史的必然:RNN 的登场](#🔥 历史的必然:RNN 的登场)
一、历史背景:人们开始"厌倦数学假设"
到现在你已经看到,第一代模型有一个共同特点:
-
强假设(线性、平稳、高斯)
-
模型结构固定
-
对异常、非线性非常敏感
现实世界给了统计模型当头一棒:
数据越来越多,世界越来越不干净。
于是一个非常"工程师式"的问题被提出来:
我能不能不理解时间,
只要预测准就行?
这正是第二代模型的精神。
二、这一代模型的核心转变(非常关键)
在这一代里,发生了一件本质性改变:
时间,不再被当作"结构",
而是被压扁成"特征"。
数学上你可以理解为:
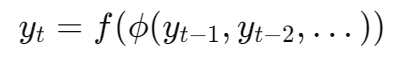
其中:
-
ϕ(⋅):特征工程
-
f(⋅):通用回归器
三、时间是如何被"特征化"的?
这是理解这一代模型的钥匙。
常见时间特征
-
滞后值:yt−1,yt−7
-
滚动统计:mean, std, max
-
差分
-
时间编码(hour, weekday)
📌 关键点:
模型本身不"知道"时间,
时间是你手动塞进去的。
四、SVR:第一个"非线性救星"
SVR全称是support vector regression(支持向量回归),是SVM(支持向量机support vector machine)对回归问题的一种运用。SVR通过在数据两侧创建一个"间隔带",对落入间隔带内的样本不计算损失,只对间隔带外的样本计算损失,从而优化模型。
1️⃣ SVR 在干什么?
Support Vector Regression 的核心是:
在高维空间中拟合一个"平坦但容忍误差"的函数
数学形式(概念层面):
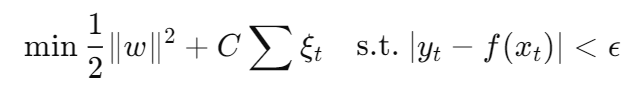
📌 时间在哪里?
-
在输入特征 xt
-
不在模型结构里
2️⃣ SVR 的优势与局限
优势
-
强非线性(核技巧)
-
小样本表现好
局限
-
对特征极度敏感
-
不可扩展到大规模
-
无时间结构感知
五、Random Forest / XGBoost:树的时代
树模型不是时间模型,
它们是"静态函数逼近器"。
时间只是输入的一部分。
1️⃣ 数学定义:树模型到底在学什么?
所有树模型(RF / XGBoost)都在学一个函数:
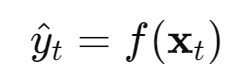
其中:
-
:特征向量
-
📌 关键点:
f 本身 不依赖时间索引 t
只依赖你"喂进去"的数值。
2️⃣ 时间是怎么进入模型的?(非常关键)
时间只能通过 特征工程 进入:
(1)滞后特征(lag features)
👉 你人为规定一个窗口长度 k
(2)滚动统计量
(3)时间戳特征
📌 注意:
时间不是"连续演化的对象",
而是被打碎成了一堆数。
树模型只会问问题:
"某个特征是否大于一个阈值?"
于是:
-
时间被离散切分
-
顺序信息消失
📌 一个非常重要的事实:
树模型对"顺序"不敏感,
只对"数值关系"敏感。
3️⃣ 树模型为什么对"顺序"不敏感?(数学原因)
单棵树在做的事情是:
其中:
-
定义的超矩形区域
-
📌 重要结论:
树只关心:
"某一维大不大"而不关心:
"这一维来自哪一时刻"
所以:
-
yt−1,yt−2\]=\[3,1
-
yt−1,yt−2\]=\[1,3
在树眼里只是"不同点",
没有"先后"的概念。
4️⃣ 那为什么它们在时序任务上反而很强?
因为现实世界的很多时序问题,本质并不是"动力系统"。
从数学角度看:
树模型擅长拟合:
其中:
-
f:高度非线性
-
存在阈值效应
-
条件异方差(variance depends on state)
📌 典型场景:
-
金融风控(不同区间完全不同机制)
-
推荐系统(规则 + 非线性交互)
-
运维告警(if-then 逻辑)
👉 在这些问题中:
"时间顺序"反而不如"状态位置"重要
现实中的很多时序问题:
-
非线性
-
异方差
-
有交互项
树模型:
-
不怕异常值
-
不怕尺度变化
-
自动建交互
👉 在工业界(金融、推荐、运维)
至今仍是主力。
5️⃣ 它们在时间建模谱系中的位置
你可以非常明确地说:
RF / XGBoost
并不建模时间演化,
而是对时间窗口内的状态做条件回归。
这也是为什么:
-
外推能力弱
-
长期预测容易崩
六、浅层 ANN(MLP):连接主义的早期尝试
1️⃣ 数学定义:MLP 到底是什么?
一个标准 MLP 学的是:
其中:
-
-
-
📌 关键事实:
无记忆(memoryless)映射
2️⃣ 时间是怎么被处理的?
完全和树一样:靠窗口。
👉 不同点只在于:
-
MLP 是连续函数
-
树是分段常数函数
3️⃣ 为什么它们学不到"真正的时间"?
从数学上看:
-
输入维度固定
-
没有状态 ht
-
没有递归关系
所以:
它学的是
的映射,
而不是
4️⃣ 长期依赖为什么难?(一句到位)
因为:
所有时间信息都被压缩进了一个静态向量,
而模型不知道哪个维度"更早"。
即便你告诉它:
-
这是
-
这是
它也只能通过参数硬记。
5️⃣ 它们失败的"历史必然性"
你现在可以这样总结:
浅层 ANN 在时序建模中失败,
不是因为表达能力不够,
而是因为它们没有"状态"和"时间递归"。
这正是为什么:
👉 RNN 是一次"结构革命",不是调参革命
七、这一代模型的哲学总结(非常重要)
这一代模型,本质是:
第二代机器学习方法将时间序列问题
转化为静态回归问题,
从而牺牲了对系统动态结构的建模能力。
代价是:
-
时间结构完全外包给工程
-
无法端到端学习依赖
📌 你现在应该自然地问一句:
有没有一种模型,
既不靠手工特征,
又能自己学时间结构?
🔥 历史的必然:RNN 的登场
这不是巧合,而是逻辑必然。
-
State Space 已经告诉我们:
时间 = 状态演化
-
ML 已经告诉我们:
非线性很重要
于是下一代模型只做了一件事:
把状态转移函数变成神经网络。