深入 JVM 垃圾回收:从识别到清除的完整闭环
作者 :Weisian
发布时间:2026年2月9日

在前几篇中,我们探索了JVM的各个内存区域。但有一个问题始终悬而未决:
JVM 是如何判断一个对象"已经死亡",可以被安全回收的?
这正是垃圾回收(Garbage Collection, GC) 的核心命题。如果说堆是对象的舞台,那么垃圾回收器就是那位沉默的清道夫------它不声不响地巡视内存,精准识别无用对象,并高效释放空间,确保程序永续运行而不至于被"垃圾"压垮。
本文将围绕「垃圾识别」和「垃圾回收算法」两大核心展开,带你走进 JVM 垃圾回收的底层世界,理解 GC 背后的设计逻辑与实战价值,为后续掌握各类垃圾回收器(G1、ZGC 等)打下坚实基础。
一、前提认知:什么是"垃圾"?为什么需要垃圾回收?
1. 垃圾的定义
在 JVM 中,垃圾 = 不再被任何活跃引用所指向的对象 。
------这类对象无法被程序后续逻辑使用,占据的内存空间若不及时释放,终将导致堆内存溢出(OutOfMemoryError: Java heap space)。
垃圾回收的核心目标有两个:
- 准确识别:不遗漏存活对象(否则会导致程序运行异常、数据丢失),不误判垃圾对象(否则会造成内存浪费,加速 OOM);
- 高效清理:在尽可能短的 STW(Stop-The-World)时间内,释放垃圾对象占用的内存,同时兼顾内存碎片控制和系统吞吐量。
垃圾回收的流程,始终遵循"先识别,后清理"的原则------垃圾识别是前提,垃圾清理是核心,两者共同决定了 GC 的性能表现。

📌 补充说明 :GC 主要针对堆内存(对象实例)和方法区/元空间(常量、无用类),栈内存(局部变量、方法调用栈)随线程生命周期自动入栈/出栈,无需 GC 管理;堆外内存(Direct Memory)也不受 JVM 自动 GC 管控,需手动释放或依赖
Cleaner虚引用回收。

2. 垃圾回收的核心价值
- 消除内存泄漏:自动检测无引用的对象
- 避免野指针:防止访问已释放的内存
- 减少程序员负担:专注于业务逻辑而非内存管理
- 提高开发效率:减少因内存问题导致的bug
java
// C++需要手动管理内存
void cppMemoryManagement() {
Object* obj = new Object(); // 分配内存
// 使用obj...
delete obj; // 必须手动释放
// 忘记delete → 内存泄漏
// 提前delete → 野指针
}
// Java自动管理内存
void javaMemoryManagement() {
Object obj = new Object(); // 分配内存
// 使用obj...
// obj = null; // 可选:帮助GC识别
// JVM自动回收不再使用的内存
}
3. 垃圾回收 vs 手动内存管理
| 对比维度 | 垃圾回收(Java) | 手动内存管理(C/C++) |
|---|---|---|
| 内存安全 | 高(无野指针、双重释放) | 低(依赖程序员) |
| 开发效率 | 高(专注业务逻辑) | 低(需管理内存) |
| 性能开销 | 有(GC暂停、CPU开销) | 无额外开销 |
| 内存泄漏 | 可能(逻辑泄漏) | 常见(忘记释放) |
| 实时性 | 不确定(GC时机不定) | 确定(可精确控制) |
| 内存碎片 | 自动整理(某些GC器) | 可能产生碎片 |
💡 哲学差异:
- 手动管理:相信程序员能做好一切
- 垃圾回收:承认人会犯错,让机器帮忙
4. 垃圾回收的演进历程
垃圾回收技术演进:
┌─────────────────────────────────────────────────────┐
│ 引用计数(1960年代) │
│ 简单但无法解决循环引用问题 │
└─────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────┐
│ 标记-清除算法(Lisp,1960年代) │
│ 首次解决循环引用,但产生碎片 │
└─────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────┐
│ 复制算法(M.L. Minsky,1963年) │
│ 无碎片但浪费一半空间 │
└─────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────┐
│ 分代收集理论(Ungar,1984年) │
│ "弱分代假设":大多数对象朝生夕死 │
└─────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────┐
│ 现代GC器(1990年代至今) │
│ 并行、并发、增量、区域化、低延迟... │
└─────────────────────────────────────────────────────┘5. 垃圾回收的基本流程
无论采用何种算法,垃圾回收都遵循相似的基本流程:
1. 暂停应用线程(STW开始)
↓
2. 识别垃圾对象(标记阶段)
↓
3. 回收垃圾内存(清除/复制/整理)
↓
4. 恢复应用线程(STW结束)
↓
5. 可选:内存整理(压缩阶段)⚠️ STW(Stop-The-World):垃圾回收时暂停所有应用线程,是影响应用响应时间的主要因素。现代GC器的核心目标之一就是减少STW时间。
二、垃圾识别:JVM 如何"分辨"存活与垃圾对象?
判断一个对象是否为垃圾,经历了两个核心阶段的演进:早期的引用计数法 ,以及现在主流的可达性分析算法。其中,可达性分析算法是现代 HotSpot 虚拟机的核心垃圾识别方案。
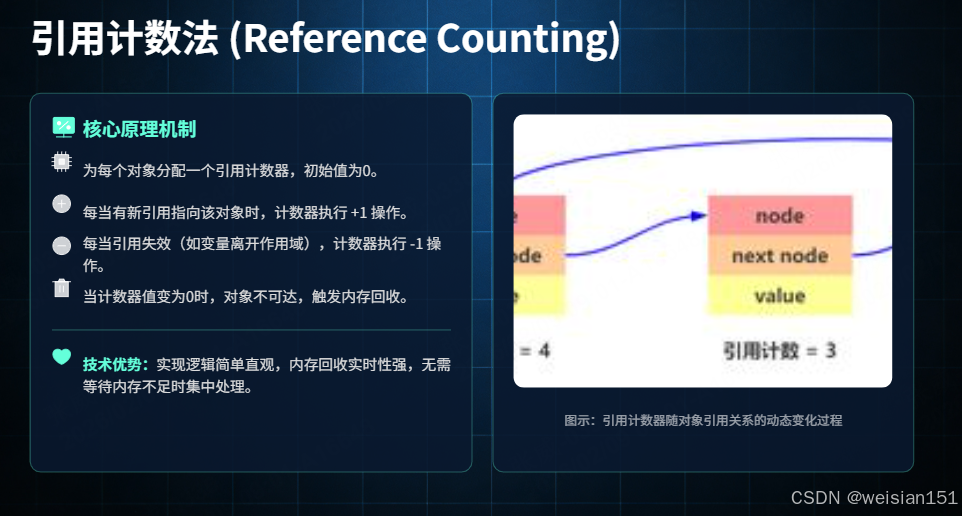
2.1 引用计数法(Reference Counting)------被淘汰的先驱
(1) 原理
- 为每个对象维护一个引用计数器。
- 每当有引用指向该对象,计数器 +1;引用失效(如变量置 null、方法结束),计数器 -1。
- 当计数器为 0,对象可回收。
(2) 代码示例:模拟引用计数法
java
/**
* 模拟引用计数法的核心逻辑(仅用于理解,JVM 实际并不是如下方案)
*/
public class ReferenceCountingDemo {
// 引用计数器
private int refCount = 0;
// 当有新引用指向该对象时,计数器 +1
public void addReference() {
refCount++;
System.out.println("引用计数器 +1,当前值:" + refCount);
}
// 当引用失效时,计数器 -1
public void releaseReference() {
if (refCount > 0) {
refCount--;
System.out.println("引用计数器 -1,当前值:" + refCount);
}
// 计数器为 0 时,标记为可回收
if (refCount == 0) {
System.out.println("对象引用计数器为 0,标记为垃圾,可被回收");
}
}
public static void main(String[] args) {
ReferenceCountingDemo obj = new ReferenceCountingDemo();
// 新引用指向对象,计数器 +1
obj.addReference();
// 新增一个引用变量指向该对象,计数器 +1
ReferenceCountingDemo obj2 = obj;
obj.addReference();
// 引用 obj2 失效,计数器 -1
obj2 = null;
obj.releaseReference();
// 引用 obj 失效,计数器 -1
obj = null;
// 此处注意:obj 已为 null,实际运行会报空指针,仅为演示逻辑
// obj.releaseReference();
}
}(3) 优点与致命缺陷
优点
- 实现简单,无需暂停业务线程(无 STW),垃圾识别实时性高。
- 回收效率高,计数器为 0 时可立即回收对象,无需额外扫描内存。
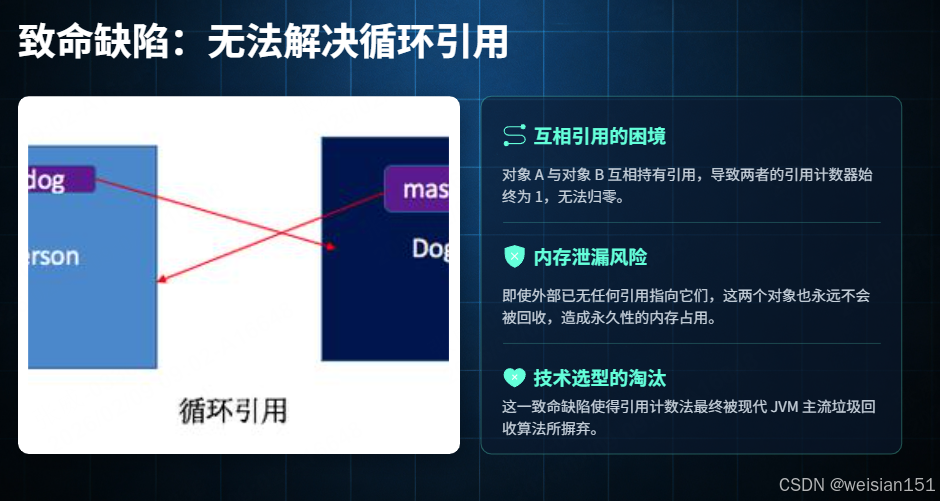
致命缺陷:无法解决循环引用问题
这是引用计数法被淘汰的核心原因------当两个或多个对象互相引用,形成闭环时,它们的引用计数器始终大于 0,即使没有任何外部引用指向这个闭环,这些对象也无法被识别为垃圾,最终导致内存泄漏。
(4) 循环引用场景深度剖析
为了彻底澄清引用计数法在循环引用下的行为,我们通过两个对比案例来说明。
案例一:正常引用(无循环)
java
import java.util.ArrayList;
import java.util.List;
/**
* 正常引用场景:引用计数法可正确识别垃圾(无循环引用)
*/
public class NormalReferenceDemo {
private NormalReferenceDemo partner;
private List<byte[]> data = new ArrayList<>();
public NormalReferenceDemo() {
data.add(new byte[1024 * 1024]); // 占用内存,方便观察回收效果
}
public static void main(String[] args) {
NormalReferenceDemo objA = new NormalReferenceDemo();
NormalReferenceDemo objB = new NormalReferenceDemo();
// objA.partner = objB → objB 计数器 = 2
objA.partner = objB;
// 释放外部栈引用
objA = null; // objA 计数器 = 0
objB = null; // objB 计数器 = 1
// 关键:引用计数法的"联动回收"逻辑
// 1. objA 计数器 = 0 → 被判定为垃圾,JVM执行回收;
// 2. 回收objA时,JVM会遍历objA的所有成员引用,解除其对其他对象的引用:
// - 解除objA.partner对objB的引用 → objB计数器 -1 = 0;
// 3. objB 计数器变为 0 → 也被判定为垃圾,执行回收;
System.gc();
System.out.println("正常引用场景:引用计数法可回收所有垃圾对象");
}
}计数器变化拆解
| 操作步骤 | objA 计数器 | objB 计数器 | 变化原因(核心) |
|---|---|---|---|
| 创建 objA | 1 | 0 | 栈变量 objA 指向 objA → +1 |
| 创建 objB | 1 | 1 | 栈变量 objB 指向 objB → +1 |
| objA.partner = objB | 1 | 2 | objA的成员新增对objB的引用 → objB +1 |
| objA = null | 0 | 2 | 栈变量 objA 失效 → objA -1;objB无变化 |
| objB = null | 0 | 1 | 栈变量 objB 失效 → objB -1;objA无变化 |
| 回收 objA | 0(已回收) | 0 | 解除objA.partner对objB的引用 → objB -1 |
| 回收 objB | - | 0(已回收) | objB计数器归0 → 判定为垃圾回收 |
结论:在非循环场景下,引用计数法通过"回收联动规则"可以正确回收所有垃圾对象。
案例二:循环引用
java
import java.util.ArrayList;
import java.util.List;
/**
* 循环引用:引用计数法无法识别的垃圾场景
*/
public class CircularReferenceDemo {
private CircularReferenceDemo partner;
private List<byte[]> data = new ArrayList<>();
public CircularReferenceDemo() {
data.add(new byte[1024 * 1024]); // 用于占用内存,方便观察内存泄漏
}
public static void main(String[] args) {
CircularReferenceDemo objA = new CircularReferenceDemo();
CircularReferenceDemo objB = new CircularReferenceDemo();
// 设置互相引用(循环引用)
objA.partner = objB; // objB 计数器 = 2
objB.partner = objA; // objA 计数器 = 2
// 释放外部引用
objA = null; // objA 计数器 = 1
objB = null; // objB 计数器 = 1
// 核心:虽然没有外部引用,但两者互相引用,计数器始终不为 0
System.gc();
System.out.println("GC 触发完成,循环引用对象是否被回收?(可达性分析:是;引用计数:否)");
}
}计数器变化全过程
| 操作步骤 | objA 计数器 | objB 计数器 | 计数变化原因 |
|---|---|---|---|
| 创建 objA | 1 | 0 | 变量 objA 指向 objA 对象 → +1 |
| 创建 objB | 1 | 1 | 变量 objB 指向 objB 对象 → +1 |
| objA.partner = objB | 1 | 2 | objA 的成员引用 objB → objB 计数器 +1 |
| objB.partner = objA | 2 | 2 | objB 的成员引用 objA → objA 计数器 +1 |
| objA = null | 1 | 2 | 变量 objA 失效 → objA 计数器 -1 |
| objB = null | 1 | 1 | 变量 objB 失效 → objB 计数器 -1 |
关键原因:循环引用形成"内部闭环"
- 当外部变量
objA和objB置为null后,没有任何外部引用指向这两个对象,但它们内部仍互相引用。 - 引用计数法只关注"引用数量",不关注"引用来源":只要计数器 > 0,无论引用来自外部还是内部,都会判定为"存活"。
- 这个"内部闭环"无法被引用计数法打破,导致计数器永远无法归 0,对象无法被回收。
❌ 结论 :尽管 Python、PHP 等语言仍在使用引用计数(配合周期检测),但 JVM 从未采用此方案,因其无法处理对象图中的环状结构。
2.2 可达性分析算法(Reachability Analysis)------JVM 的标准答案
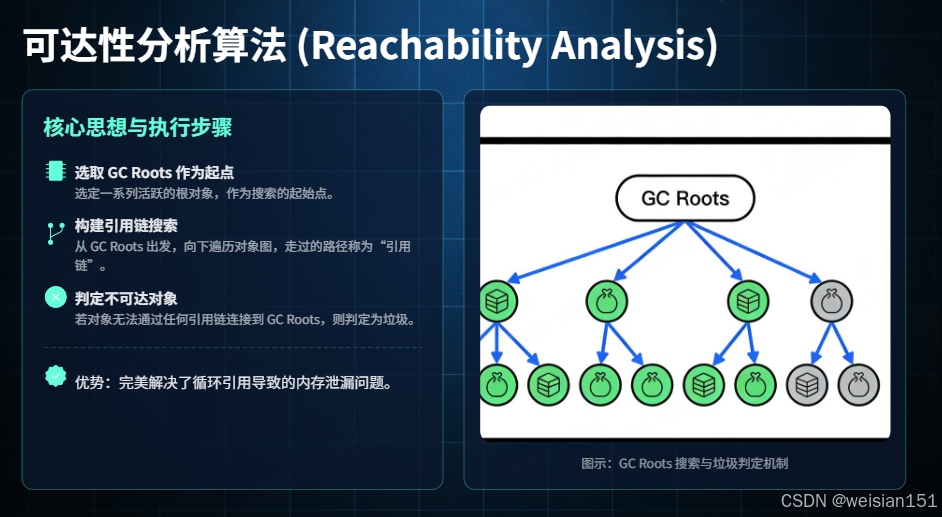
(1) 核心思想
可达性分析算法也被称为"根搜索算法",其核心思想是以"GC 根(GC Roots)"为起点,通过引用链遍历堆内存中的所有对象,能被遍历到的对象即为存活对象,无法被遍历到的对象即为垃圾。
简单来说:对象 → 引用 → ... → GC 根,形成一条完整的引用链,对象就是"可达的"(存活);反之,没有任何引用链连接到 GC 根,对象就是"不可达的"(垃圾)。
🔍 通俗比喻:GC Roots 就像森林中的"活树根",所有从根长出的枝叶(对象)都是活的;断开连接的枯枝落叶(不可达对象),就是待清理的垃圾。
(2) GC Roots 包括哪些?
| 类型 | 说明 | 示例 |
|---|---|---|
| 虚拟机栈(栈帧中的本地变量表) | 方法执行时的局部变量 | Object obj = new Object(); 中的 obj |
| 本地方法栈中的 JNI 引用 | Native 代码持有的 Java 对象引用 | JNI 调用中传入的 Java 对象 |
| 方法区中的静态变量 | 类的 static 字段 | private static List cache; |
| 方法区中的常量引用 | 字符串常量池、基本类型常量 | "hello".intern() 返回的字符串 |
| 活跃线程本身 | Thread 对象及其关联资源 | 正在运行的 Thread 实例 |

java
public class ReachabilityAnalysis {
// GC Roots包括:
// 1. 虚拟机栈中的引用
public void stackReference() {
Object localObj = new Object(); // 局部变量 → GC Root
// 方法结束时,localObj不再可达
}
// 2. 方法区中静态属性引用的对象
private static Object staticObj = new Object(); // 静态变量 → GC Root
// 3. 方法区中常量引用的对象
private static final String CONSTANT = "constant"; // 常量 → GC Root
// 4. 本地方法栈中JNI引用的对象
private native Object nativeMethod(); // JNI引用 → GC Root
// 5. Java虚拟机内部引用
// 如基本类型对应的Class对象,常驻的异常对象等
// 6. 被同步锁持有的对象
public synchronized void synchronizedMethod() {
// 同步锁对象 → GC Root
}
}(3) 执行流程
可达性分析流程:
初始状态:从GC Roots开始标记
[GC Roots]
↓
[对象A] → [对象B] → [对象C]
↓
[对象D] ← [对象E](循环引用)
第一次标记:可达对象标记为存活
[GC Roots*]
↓
[对象A*] → [对象B*] → [对象C*]
↓
[对象D*] ← [对象E*]
第二次标记:处理特殊引用(软、弱、虚引用)
如果只有弱引用指向对象,则标记为可回收
清理阶段:回收未标记的对象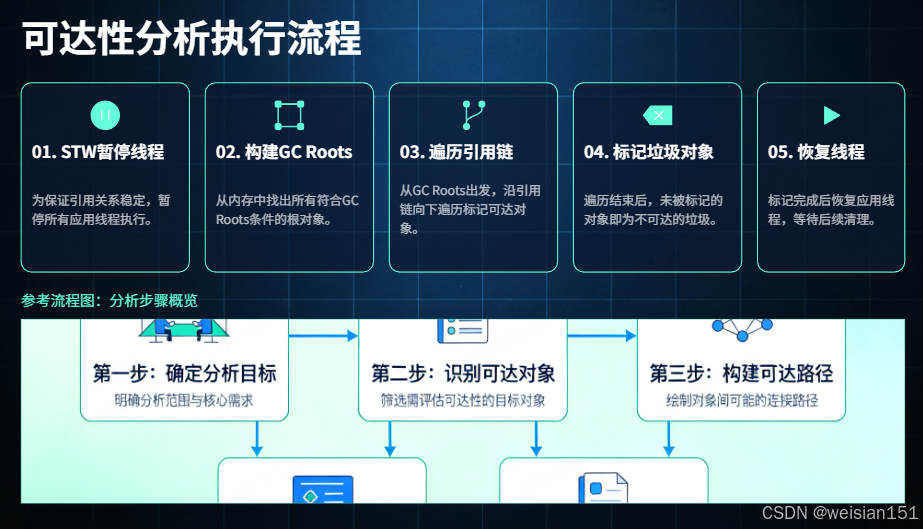
执行流程(简化版)
- 暂停所有业务线程(STW):为了保证引用链的稳定性(避免遍历过程中引用关系发生变化),可达性分析必须在一个"快照"环境中执行,因此会触发短暂的 STW。
- 构建 GC 根集合:从虚拟机栈、方法区、本地方法栈等区域中,收集所有符合条件的 GC 根对象。
- 遍历引用链:从每个 GC 根出发,递归遍历其引用的对象,将所有可达的对象标记为"存活"。
- 标记垃圾对象:遍历完成后,堆内存中未被标记为"存活"的对象,即为不可达的垃圾对象,标记为可回收。
- 恢复业务线程:STW 结束,业务线程继续执行,后续由垃圾回收算法清理标记的垃圾对象。
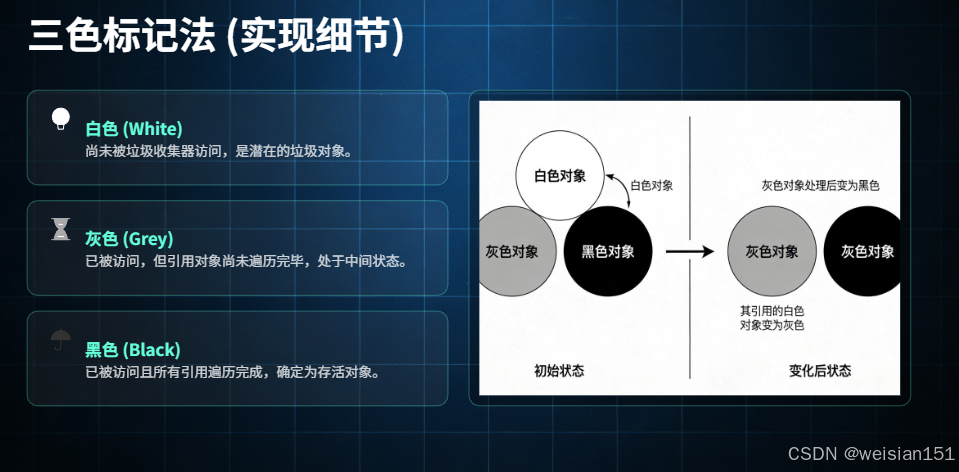
(4) 三色标记算法
可达性分析常用三色标记法实现:
java
public class ThreeColorMarking {
enum Color { WHITE, GRAY, BLACK }
// WHITE: 未访问(可能是垃圾)
// GRAY: 正在访问(可达但未完全处理)
// BLACK: 已访问(确定存活)
static class ObjectNode {
Object data;
Color color = Color.WHITE;
List<ObjectNode> references = new ArrayList<>();
}
public void markFromRoots(List<ObjectNode> roots) {
// 1. 初始所有对象为白色
// 2. 根对象置为灰色
for (ObjectNode root : roots) {
root.color = Color.GRAY;
}
// 3. 处理灰色对象
while (hasGrayObjects()) {
ObjectNode gray = getGrayObject();
// 遍历所有引用
for (ObjectNode ref : gray.references) {
if (ref.color == Color.WHITE) {
ref.color = Color.GRAY; // 白色变灰色
}
}
gray.color = Color.BLACK; // 灰色变黑色
}
// 4. 回收白色对象(垃圾)
reclaimWhiteObjects();
}
}
(5) 解决循环引用问题
对于上文中的循环引用场景,可达性分析算法可以轻松解决:
objA和objB互相引用,但没有任何 GC 根指向它们(外部引用已被置为null)。- 遍历引用链时,无法从任何 GC 根出发找到
objA和objB,因此它们被标记为垃圾。 - 后续 GC 清理时,会释放这两个对象占用的内存,避免内存泄漏。
这也是可达性分析算法成为现代 JVM 垃圾识别核心方案的根本原因------它能解决引用计数法的致命缺陷,且识别准确率更高。
(6) 优点与不足
优点
- 能正确解决循环引用问题,垃圾识别准确率高,是目前最可靠的垃圾识别方案。
- 可灵活适配不同的引用类型(强引用、软引用、弱引用、虚引用),支持精细化的内存管理。
不足
- 执行过程需要触发 STW,暂停所有业务线程,若堆内存过大、对象过多,遍历引用链的时间会变长,导致 STW 时间增加,影响应用响应性能。
- 构建 GC 根集合和遍历引用链需要消耗一定的 CPU 资源,对系统吞吐量有一定影响。
💡 优化方向 :现代垃圾回收器(如 G1、ZGC)通过"并发标记""增量标记"等技术,将可达性分析的大部分工作放在业务线程运行期间执行,仅在关键步骤触发短暂 STW,大幅降低了 GC 卡顿的影响。
🔍 HotSpot实现:HotSpot虚拟机使用可达性分析算法,采用准确式GC(知道哪些位置存放的是引用)。
三、引用的强度:不只是"有"或"无"
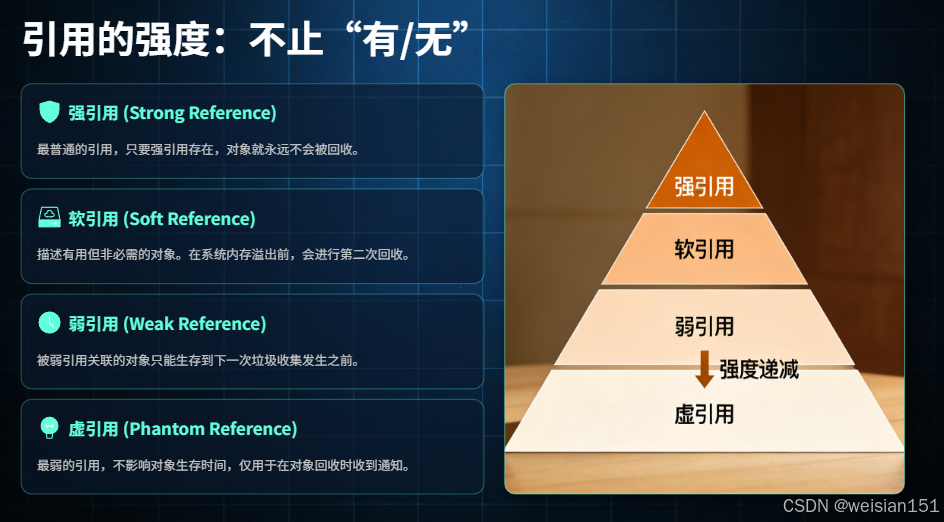
可达性分析算法的核心是"引用链",而 Java 中的引用并非只有"存在"和"不存在"两种状态------JDK 1.2 之后,Java 将引用分为 4 种类型,从强到弱依次为:强引用、软引用、弱引用、虚引用。不同引用类型决定了对象在 GC 时的不同命运,这也是 JVM 实现精细化内存管理的基础。
3.1 强引用(Strong Reference)
这是最常见、最默认的引用类型,也是我们日常开发中使用最多的引用(如 Object obj = new Object())。

核心特性
- 只要强引用存在,对象永远不会被 GC 回收 ,即使堆内存不足,JVM 宁愿抛出
OutOfMemoryError,也不会回收强引用指向的对象。 - 强引用是造成内存泄漏的最主要原因(如静态集合持有大量无用对象的强引用)。
代码示例
java
/**
* 强引用示例:只要强引用存在,对象永不被回收
*/
public class StrongReferenceDemo {
public static void main(String[] args) {
Object obj = new Object(); // 强引用
System.gc();
System.out.println("GC 后,强引用对象是否存在:" + (obj != null)); // 输出:true
obj = null; // 释放强引用
System.gc();
System.out.println("释放强引用后,对象是否存在:" + (obj != null)); // 输出:false
}
}3.2 软引用(Soft Reference)
软引用是一种"弱于强引用"的引用类型,用于描述"有用但非必需"的对象,通过 java.lang.ref.SoftReference 类实现。

核心特性
- 当堆内存充足时,软引用指向的对象不会被 GC 回收,保持存活状态。
- 当堆内存不足时(即将发生 OOM 之前),JVM 会主动回收所有软引用指向的对象,释放内存。
- 软引用非常适合用于实现"内存敏感型缓存"(如图片缓存、数据缓存),既可以提升应用性能,又不会导致 OOM。
代码示例
java
import java.lang.ref.SoftReference;
import java.util.ArrayList;
import java.util.List;
/**
* 软引用示例:堆内存不足时,对象被回收
*/
public class SoftReferenceDemo {
public static void main(String[] args) {
byte[] bigData = new byte[1024 * 1024]; // 创建一个大对象(1MB)
SoftReference<byte[]> softRef = new SoftReference<>(bigData); // 用软引用包装
bigData = null; // 释放强引用
System.gc();
System.out.println("堆内存充足时,软引用对象是否存在:" + (softRef.get() != null)); // true
// 模拟堆内存不足
try {
List<byte[]> list = new ArrayList<>();
for (int i = 0; ; i++) {
list.add(new byte[1024 * 1024]);
if (i % 100 == 0) {
System.out.println("已添加 " + i + " 个1MB对象,软引用对象是否存在:" + (softRef.get() != null));
}
}
} catch (OutOfMemoryError e) {
System.out.println("堆内存不足(OOM 即将发生),软引用对象是否存在:" + (softRef.get() != null)); // false
e.printStackTrace();
}
}
}3.3 弱引用(Weak Reference)
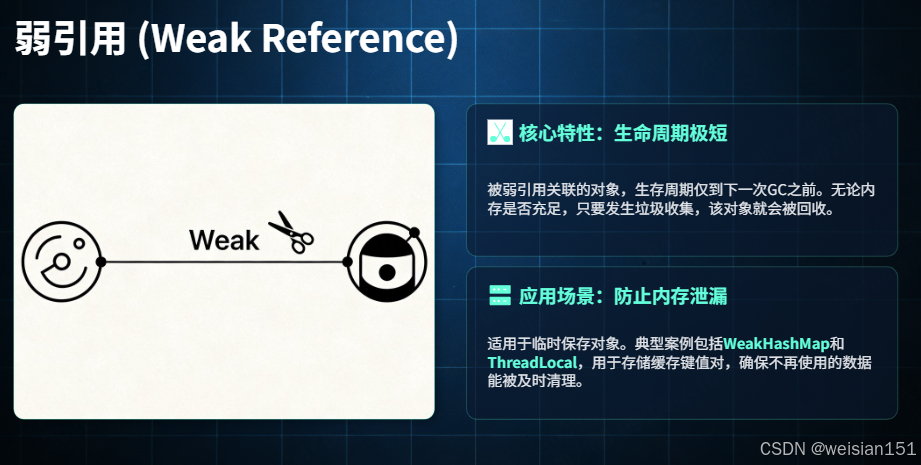
弱引用是一种"弱于软引用"的引用类型,用于描述"非必需"的对象,通过 java.lang.ref.WeakReference 类实现。
核心特性
- 弱引用指向的对象,无论堆内存是否充足,只要触发 GC,就会被回收(相比软引用,生命周期更短)。
- 弱引用的存活时间仅到"下一次 GC 发生之前",适合用于实现"临时缓存"(如
ThreadLocal、WeakHashMap),避免内存泄漏。
代码示例
java
import java.lang.ref.WeakReference;
/**
* 弱引用示例:只要触发 GC,对象就会被回收
*/
public class WeakReferenceDemo {
public static void main(String[] args) {
Object obj = new Object();
WeakReference<Object> weakRef = new WeakReference<>(obj);
obj = null; // 释放强引用
System.out.println("GC 前,弱引用对象是否存在:" + (weakRef.get() != null)); // true
System.gc();
System.out.println("GC 后,弱引用对象是否存在:" + (weakRef.get() != null)); // false
}
}3.4 虚引用(Phantom Reference)
虚引用是最弱的一种引用类型,也被称为"幽灵引用",用于描述"几乎没有任何意义"的对象,通过 java.lang.ref.PhantomReference 类实现。

核心特性
- 虚引用无法通过
get()方法获取对象的引用 (get()方法永远返回null),对对象的生命周期没有任何影响。 - 虚引用的唯一作用是:当对象被 GC 回收时,会收到一个系统通知 (通过
ReferenceQueue队列),用于跟踪对象的回收状态。 - 虚引用主要用于管理堆外内存(
Direct Memory),如ByteBuffer的Cleaner就是通过虚引用实现堆外内存的回收通知。
代码示例
java
import java.lang.ref.PhantomReference;
import java.lang.ref.ReferenceQueue;
/**
* 虚引用示例:跟踪对象的回收状态,无法获取对象引用
*/
public class PhantomReferenceDemo {
public static void main(String[] args) throws InterruptedException {
ReferenceQueue<Object> refQueue = new ReferenceQueue<>(); // 创建引用队列
Object obj = new Object();
PhantomReference<Object> phantomRef = new PhantomReference<>(obj, refQueue); // 关联队列
System.out.println("虚引用 get() 结果:" + phantomRef.get()); // null
obj = null; // 释放强引用
System.out.println("GC 前,引用队列中的通知:" + refQueue.poll()); // null
System.gc();
Thread.sleep(100); // 等待 GC 完成
System.out.println("GC 后,引用队列中的通知:" + refQueue.poll()); // java.lang.ref.PhantomReference@xxx
}
}3.5 四种引用类型对比总结
| 引用类型 | 英文名称 | 核心特性 | 存活时间 | 适用场景 |
|---|---|---|---|---|
| 强引用 | Strong Reference | 堆内存不足时抛出 OOM,永不回收 | 直到强引用被释放 | 日常开发中的普通对象引用(默认) |
| 软引用 | Soft Reference | 堆内存充足时存活,不足时回收 | 到堆内存不足之前 | 内存敏感型缓存(图片、数据缓存) |
| 弱引用 | Weak Reference | 无论内存是否充足,GC 即回收 | 到下一次 GC 发生之前 | 临时缓存(WeakHashMap、ThreadLocal) |
| 虚引用 | Phantom Reference | 无法获取对象引用,仅跟踪回收状态 | 到对象被 GC 回收时 | 堆外内存管理、对象回收通知 |

📌 核心结论 :4 种引用类型的"强度"依次递减:强引用 > 软引用 > 弱引用 > 虚引用,JVM 在进行可达性分析时,会根据引用类型的不同,决定对象是否被回收,这为精细化内存管理提供了支撑。
四、对象的"临终关怀":finalize() 与回收屏障
即使对象被判定为垃圾,JVM 也允许它进行"最后的告别"。
4.1 finalize() 方法 ------ 被废弃的"遗言"
java
@Override
protected void finalize() throws Throwable {
// 清理资源(如关闭文件句柄)
System.out.println("Object is being finalized!");
}问题重重:
- 执行时机不确定:可能永不执行(如程序退出前未触发 GC)。
- 性能极差:拖慢 GC 速度。
- 安全性低:可能 resurrect 对象(在 finalize 中将 this 赋值给静态变量),导致对象"复活",破坏 GC 逻辑。
java
public class ObjectResurrection {
static ObjectResurrection resurrection;
@Override
protected void finalize() throws Throwable {
System.out.println("finalize()被调用");
resurrection = this; // 复活对象!
// 注意:不推荐这样做,有风险
}
public static void main(String[] args) throws InterruptedException {
resurrection = new ObjectResurrection();
resurrection = null;
System.gc();
Thread.sleep(500);
System.out.println("第一次GC后: " + resurrection); // 不为null(已复活)
resurrection = null;
System.gc();
Thread.sleep(500);
System.out.println("第二次GC后: " + resurrection); // 为null(真正死亡)
}
}对象生命周期与finalize()
对象生命周期:
1. 创建 → 2. 使用 → 3. 不可达 → 4. 第一次标记 → 5. 执行finalize()
↑ ↓
8. 真正回收 ← 7. 第二次标记 ← 6. finalize()可能复活对象⚠️ 官方建议 :不要使用
finalize()! 替代方案:try-with-resources、Cleaner(虚引用)、显式 close()。
4.2 回收过程中的"两次标记"
JVM 对可回收对象并非立即删除,而是经过两次标记:
- 第一次标记:可达性分析后,发现无 GC Roots 引用。
- 筛选 :检查是否有必要执行
finalize()(仅当对象覆盖了 finalize 且未被调用过)。- 若无需执行 → 直接回收。
- 若需执行 → 加入 F-Queue 队列,由低优先级 Finalizer 线程执行。
- 第二次标记 :finalize() 执行完毕后,再次检查是否被"复活"。
- 若仍不可达 → 真正回收。
- 若被复活 → 移出回收集合。
💡 启示 :即使覆盖了
finalize(),也不能保证对象一定被"拯救",且代价高昂。

五、垃圾回收算法:JVM 如何"清理"垃圾对象?
当 JVM 通过可达性分析算法标记出垃圾对象后,接下来就需要通过垃圾回收算法清理这些垃圾对象,释放占用的堆内存。现代 JVM 的垃圾回收算法,均基于分代收集理论(绝大多数对象朝生夕死,少数对象长期存活),针对新生代和老年代的不同特性,采用了不同的垃圾回收算法。
核心的垃圾回收算法有 3 种:复制算法、标记-清除算法、标记-整理算法,后续的所有垃圾回收器(G1、ZGC 等),都是这 3 种基础算法的组合与优化。
5.1 标记-清除算法(Mark-Sweep)
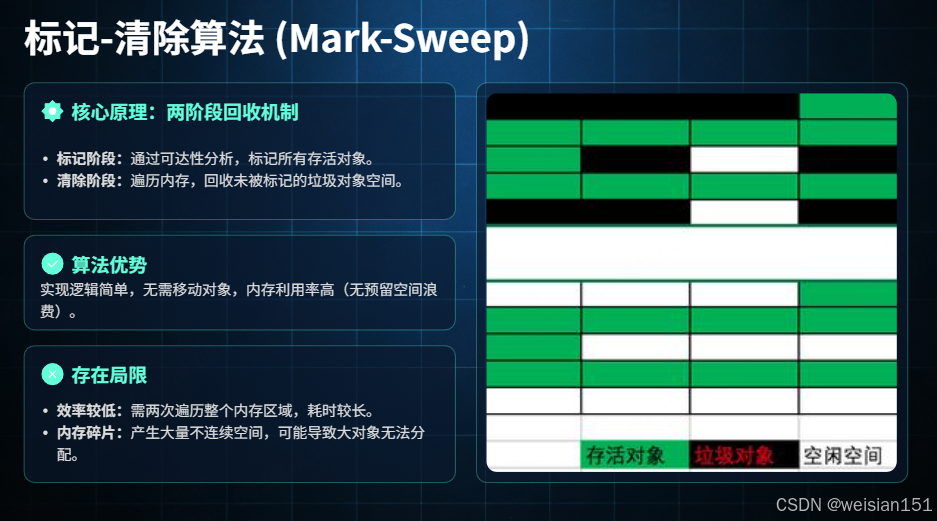
(1) 核心原理
- 标记阶段:通过可达性分析算法,遍历堆内存中的所有对象,标记出存活对象和垃圾对象。
- 清除阶段:遍历堆内存,直接清理(释放)所有未被标记为存活的垃圾对象,回收其占用的内存空间。
- 清理完成后,堆内存中留下存活对象和大量不连续的空闲内存块(内存碎片)。

(2) 代码示例:模拟标记-清除算法
java
import java.util.ArrayList;
import java.util.List;
/**
* 模拟标记-清除算法的核心逻辑(针对老年代,存活率高)
*/
public class MarkSweepAlgorithmDemo {
private static List<Object> heapArea = new ArrayList<>();
private static boolean[] markArray;
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
heapArea.add(new Object());
}
markArray = new boolean[heapArea.size()];
System.out.println("初始状态:堆内存对象数量 = " + heapArea.size());
majorGC(); // 触发 Major GC
System.out.println("GC 后:堆内存对象数量 = " + heapArea.size());
}
private static void majorGC() {
// 步骤 1:标记阶段(假设前 8 个对象存活)
for (int i = 0; i < 8; i++) {
markArray[i] = true;
}
int garbageCount = 0;
for (boolean mark : markArray) {
if (!mark) garbageCount++;
}
System.out.println("标记阶段完成:存活对象 = " + (markArray.length - garbageCount) + " 个,垃圾对象 = " + garbageCount + " 个");
// 步骤 2:清除阶段
for (int i = heapArea.size() - 1; i >= 0; i--) {
if (!markArray[i]) {
heapArea.remove(i);
}
}
System.out.println("清除阶段完成:已清理所有垃圾对象");
// 步骤 3:重置标记数组
markArray = new boolean[heapArea.size()];
}
}(3) 优点与不足
优点
- 内存利用率高:无需预留空闲内存,所有堆内存均可用于分配对象,没有内存浪费。
- 适合老年代:无需复制存活对象,仅清理垃圾对象,对于存活率高的老年代,回收开销相对较小。
- 实现简单,是后续标记-整理算法的基础。
不足
- 回收效率低:需要两次遍历堆内存(标记阶段 + 清除阶段),若堆内存过大、对象过多,遍历时间会很长,导致 STW 时间增加。
- 产生大量内存碎片:清理垃圾对象后,堆内存中会留下大量不连续的空闲内存块,后续分配大对象时,可能没有足够大的连续内存块可供分配,不得不提前触发 Full GC。
- 空闲内存管理复杂:后续分配对象时,需要采用"空闲列表"的方式查找可用内存块,分配效率低于"指针碰撞"。
(4) 适用场景
- 老年代垃圾回收:由于老年代对象存活率高(可达性分析后大部分对象存活),若使用复制算法,需要预留大量空闲内存(如 50%)用于复制,内存浪费严重;而标记-清除算法无需预留空闲内存,仅清理少量垃圾对象,更适合老年代的特性。
- 对内存利用率要求高的场景:当系统内存资源紧张,无法接受复制算法的内存浪费时,可采用标记-清除算法。
💡 优化方向 :为了解决内存碎片问题,后续衍生出标记-整理算法,在清除阶段增加"整理"步骤,将存活对象向一端移动,消除内存碎片。
5.2 复制算法(Copying)
(1) 核心原理
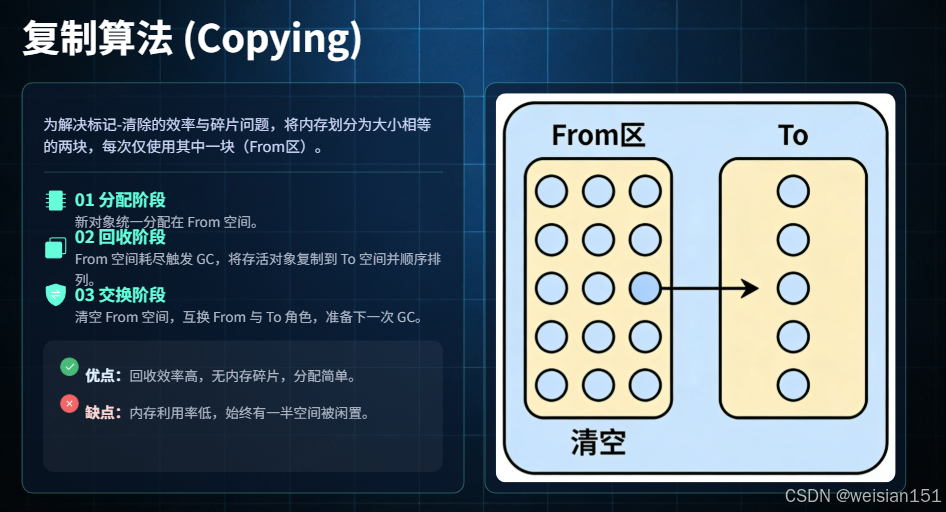
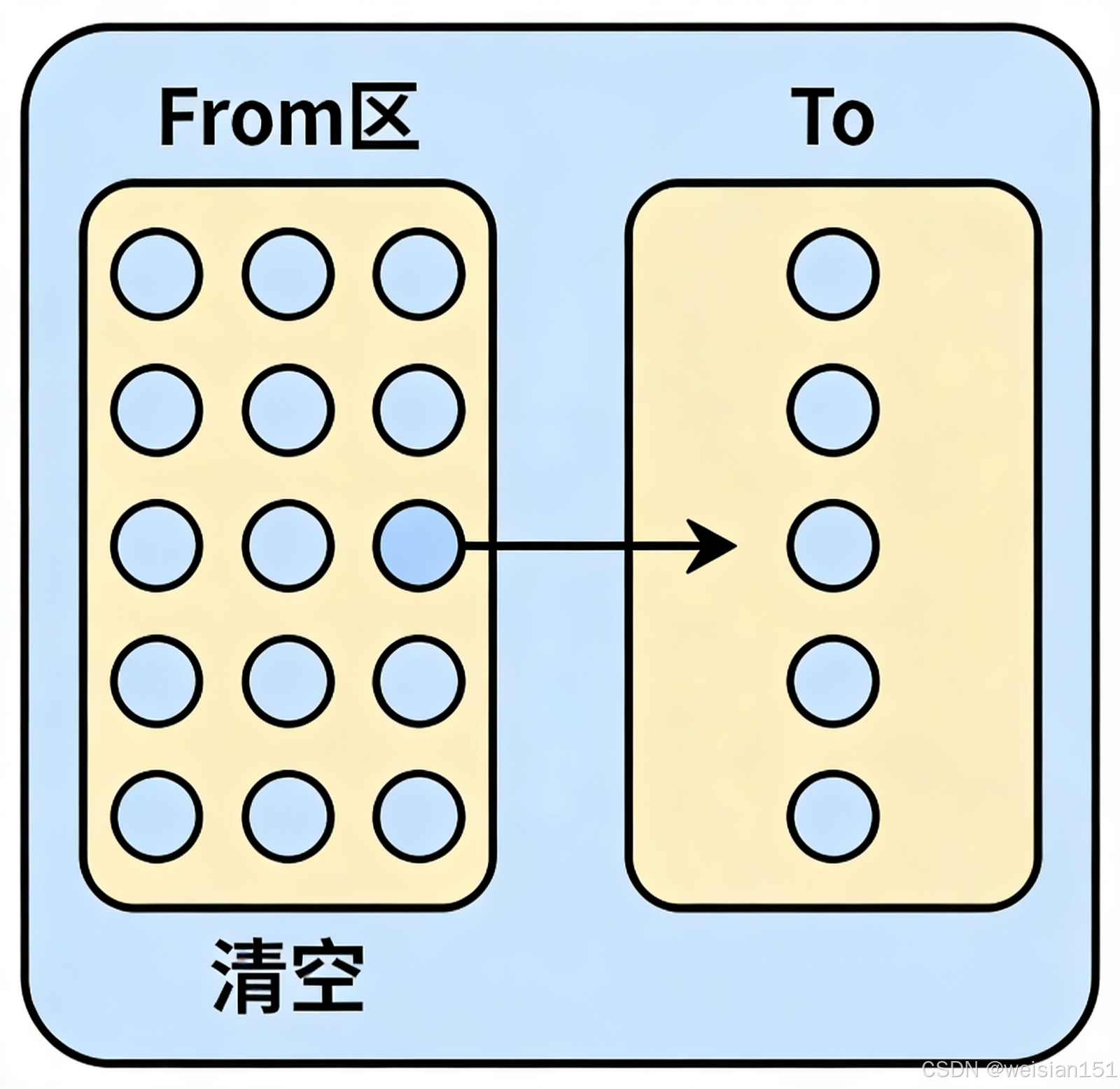
- 分区 :将可用内存按容量划分为两块大小相等的区域,称为 From 空间 和 To 空间(或 Survivor0/Survivor1)。
- 分配:所有新创建的对象都分配在 From 空间。
- 回收 :当 From 空间用尽时,触发 Minor GC:
- 遍历 From 空间中的所有对象,通过可达性分析标记存活对象;
- 将所有存活对象一次性复制到 To 空间;
- 清空 From 空间(直接指针重置,效率极高);
- 交换 From/To 角色(下次 GC 时,原来的 To 变成 From,反之亦然)。
(2) 代码示例:模拟复制算法
java
import java.util.ArrayList;
import java.util.List;
/**
* 模拟复制算法的核心逻辑(针对新生代,朝生夕死)
*/
public class CopyingAlgorithmDemo {
private static List<Object> fromSpace = new ArrayList<>();
private static List<Object> toSpace = new ArrayList<>();
public static void main(String[] args) {
// 初始分配对象到 From 空间
for (int i = 0; i < 100; i++) {
fromSpace.add(new Object());
}
System.out.println("初始状态:From 空间对象数量 = " + fromSpace.size() + ",To 空间对象数量 = " + toSpace.size());
minorGC(); // 触发 Minor GC
System.out.println("GC 后:From 空间对象数量 = " + fromSpace.size() + ",To 空间对象数量 = " + toSpace.size());
}
private static void minorGC() {
// 步骤 1:标记并复制存活对象(假设只有 10% 对象存活)
for (Object obj : fromSpace) {
if (isSurvived(obj)) { // 假设 isSurvived() 判断对象是否存活
toSpace.add(obj);
}
}
int survivedCount = toSpace.size();
System.out.println("复制阶段完成:存活对象 = " + survivedCount + " 个,已复制到 To 空间");
// 步骤 2:清空 From 空间(直接清空列表,模拟指针重置)
fromSpace.clear();
System.out.println("清空 From 空间完成");
// 步骤 3:交换 From/To 角色(简化处理,实际是角色互换)
List<Object> temp = fromSpace;
fromSpace = toSpace;
toSpace = temp;
System.out.println("交换 From/To 角色完成");
}
// 模拟对象存活判断(随机 10% 存活)
private static boolean isSurvived(Object obj) {
return Math.random() < 0.1;
}
}(3) 优点与不足
优点
- 无内存碎片:每次 GC 后,To 空间中的存活对象都是连续存放的,后续分配新对象时,只需移动指针即可(指针碰撞),分配效率极高。
- 实现简单高效:清空 From 空间只需重置指针,无需逐个清理对象,回收速度极快。
- 适合新生代:新生代对象"朝生夕死",存活率极低(通常 < 10%),复制少量存活对象的成本远低于标记-清除/整理大量存活对象的成本。
不足
- 内存浪费严重:任何时候都只有一半的内存空间可用于分配对象(From 空间),另一半(To 空间)作为备用,内存利用率仅为 50%。
- 不适合老年代:老年代对象存活率高(可达性分析后大部分对象存活),若使用复制算法,需要频繁复制大量存活对象,且需要预留大量空闲内存,成本极高。
(4) 适用场景
- 新生代垃圾回收:JVM 的新生代(Young Generation)普遍采用复制算法(如 Serial、ParNew、Parallel Scavenge 回收器),因为新生代对象生命周期短、存活率低,复制少量存活对象的成本很低,且能保证内存连续性,提升分配效率。
- 对内存碎片敏感的场景:当应用需要频繁分配大对象,且对内存连续性要求高时,复制算法能有效避免内存碎片问题。
💡 优化方向 :为了减少内存浪费,现代 JVM 的新生代通常采用 Eden + Survivor 的分区方式(如 8:1:1),而非严格的 1:1 分区,进一步提升内存利用率。
5.3 标记-整理算法(Mark-Compact)
(1) 核心原理
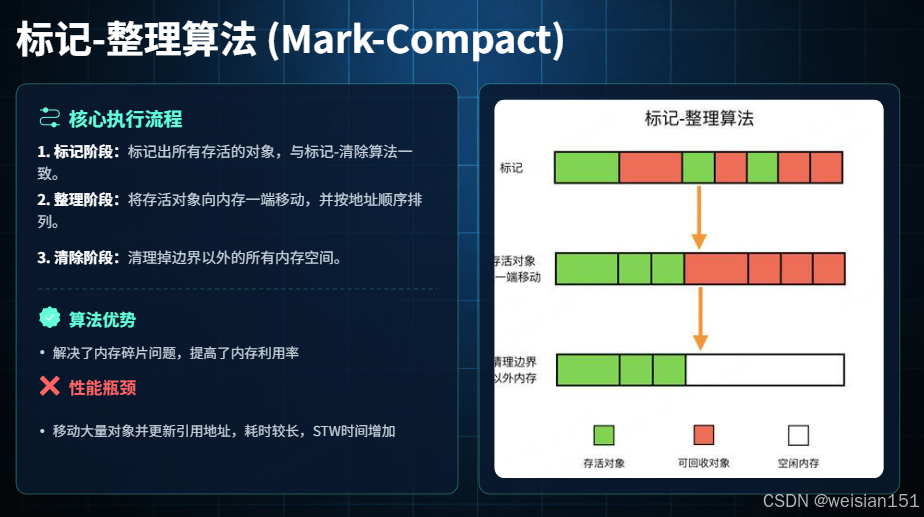
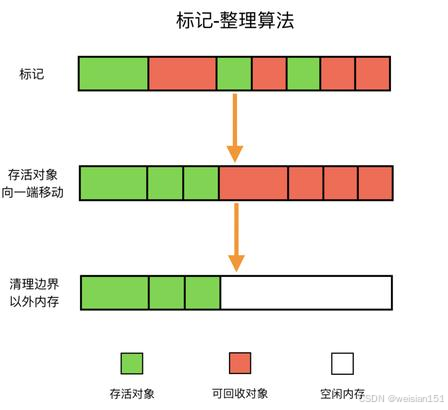
标记-整理算法是标记-清除算法的改进版,核心思想是在标记-清除的基础上,增加一个"整理"步骤,解决内存碎片问题。其流程如下:
- 标记阶段:通过可达性分析算法,遍历堆内存中的所有对象,标记出存活对象和垃圾对象(与标记-清除算法相同)。
- 整理阶段:将所有存活对象向内存的一端(如起始地址)移动,使其连续存放。
- 清理阶段:直接清理边界以外的所有内存空间(即垃圾对象占用的内存),释放为连续的空闲内存块。
(2) 代码示例:模拟标记-整理算法
java
import java.util.ArrayList;
import java.util.List;
/**
* 模拟标记-整理算法的核心逻辑(兼顾内存利用率和碎片问题)
*/
public class MarkCompactAlgorithmDemo {
private static List<Object> heapArea = new ArrayList<>();
private static boolean[] markArray;
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
heapArea.add(new Object());
}
markArray = new boolean[heapArea.size()];
System.out.println("初始状态:堆内存对象数量 = " + heapArea.size());
fullGC(); // 触发 Full GC
System.out.println("GC 后:堆内存对象数量 = " + heapArea.size());
}
private static void fullGC() {
// 步骤 1:标记阶段(假设前 6 个对象存活)
for (int i = 0; i < 6; i++) {
markArray[i] = true;
}
int garbageCount = 0;
for (boolean mark : markArray) {
if (!mark) garbageCount++;
}
System.out.println("标记阶段完成:存活对象 = " + (markArray.length - garbageCount) + " 个,垃圾对象 = " + garbageCount + " 个");
// 步骤 2:整理阶段(将存活对象移动到堆内存起始位置)
List<Object> compactedHeap = new ArrayList<>();
for (int i = 0; i < heapArea.size(); i++) {
if (markArray[i]) {
compactedHeap.add(heapArea.get(i));
}
}
heapArea = compactedHeap;
System.out.println("整理阶段完成:存活对象已连续存放");
// 步骤 3:清理阶段(直接释放边界外的内存,此处通过替换列表模拟)
markArray = new boolean[heapArea.size()];
System.out.println("清理阶段完成:已释放所有垃圾内存,形成连续空闲块");
}
}(3) 优点与不足
优点
- 无内存碎片:整理阶段将存活对象连续存放,后续分配大对象时,无需担心内存碎片问题,可直接分配连续内存块。
- 内存利用率高:无需预留空闲内存(如复制算法的 To 空间),所有堆内存均可用于分配对象,内存利用率接近 100%。
- 适合老年代:对于存活率高的老年代,既能避免复制算法的高成本,又能解决标记-清除算法的内存碎片问题。
不足
- 整理开销大:需要移动所有存活对象,并更新其引用地址(涉及指针修正),整理阶段的耗时与存活对象数量成正比,若老年代存活对象多,STW 时间会很长。
- 实现复杂:相比标记-清除和复制算法,标记-整理算法需要额外的整理逻辑和指针修正机制,实现更复杂。
(4) 适用场景
- 老年代垃圾回收:当老年代内存碎片严重,且无法接受 Full GC 的频繁触发时,可采用标记-整理算法(如 Serial Old、Parallel Old 回收器),兼顾内存利用率和碎片问题。
- 对内存连续性要求高的场景:当应用需要频繁分配大对象(如大数组、大缓存),且对内存连续性要求高时,标记-整理算法能有效避免因内存碎片导致的分配失败。
💡 优化方向:现代垃圾回收器(如 G1、ZGC)通过"区域化"(Region)和"并发整理"技术,将标记-整理的整理开销分散到多次 GC 中,或在业务线程运行期间并发执行,大幅降低 STW 时间。
5.4 三种核心垃圾回收算法对比总结
| 算法名称 | 核心步骤 | 优点 | 不足 | 适用场景 |
|---|---|---|---|---|
| 复制算法 | 标记 → 复制 → 交换角色 | 回收效率高、无内存碎片、实现简单 | 内存利用率低、不适合高存活率场景 | 新生代(Minor GC) |
| 标记-清除算法 | 标记 → 清除 | 内存利用率高、实现简单、适合高存活率场景 | 回收效率低、产生大量内存碎片 | 老年代(Major GC,CMS GC) |
| 标记-整理算法 | 标记 → 整理 → 清除 | 内存利用率高、无内存碎片、适合高存活率场景 | 回收效率低、STW 时间长、实现复杂 | 老年代(Major GC,Serial/Parallel GC) |
📌 核心结论:
- 新生代优先采用复制算法,兼顾回收效率和无碎片需求;
- 老年代优先采用标记-整理算法(或标记-清除算法+碎片整理),兼顾内存利用率和无碎片需求;
- 现代垃圾回收器(如 G1、ZGC)均是这 3 种基础算法的组合与优化,通过"并发""增量""区域化"等技术,平衡回收效率、STW 时间和内存碎片。

六、分代收集理论:工程实践的智慧结晶
现代 JVM(如 HotSpot)不单独使用某一种算法,而是结合分代思想,针对不同区域采用最适合的策略:
| 区域 | 对象特征 | 选用算法 | 原因 |
|---|---|---|---|
| 新生代 | 朝生夕死,存活率低 | 复制算法 | 高效、无碎片 |
| 老年代 | 长期存活,存活率高 | 标记-清除 / 标记-整理 | 避免频繁复制大对象 |
分代收集的工作流程
- 新生代收集(Minor GC/Young GC):采用复制算法,回收 Eden 区和 Survivor 区
- 老年代收集(Major GC/Full GC):采用标记-清除或标记-整理算法
- 混合收集(Mixed GC):G1 特有,同时回收新生代和部分老年代
🌐 G1 的创新 :
G1 打破分代界限,将堆划分为 Region,每个 Region 可独立回收,采用混合回收策略(Young GC + Mixed GC),兼顾吞吐与停顿。

七、方法区/元空间的垃圾回收
方法区(JDK 8 及以后为元空间)也需要进行垃圾回收,只是回收频率较低、回收难度较大。
1. 回收内容
- 无用常量:如字符串常量池中的字符串,若没有任何引用指向该常量,且该常量不再被使用,可被回收;
- 无用类 :满足以下 3 个条件的类,可被判定为"无用类",可被回收:
- 该类的所有实例对象均已被回收(堆中没有该类的任何对象);
- 加载该类的类加载器已被回收;
- 该类的
java.lang.Class对象没有被任何引用指向(如没有通过反射引用该类)。
2. 回收意义
方法区/元空间的回收,主要是为了释放内存,避免元空间溢出(OutOfMemoryError: Metaspace),尤其是在动态生成大量类的场景(如 CGLIB 动态代理、热部署),无用类的回收至关重要。
3. 注意事项
- 方法区/元空间的回收效率较低,且回收条件严格,尤其是无用类的回收,需要满足多个条件;
- JVM 默认开启常量回收,但无用类的回收需要通过
-XX:+AllowUnsafeClassDefinition(JDK 8 及以前)或-XX:+ClassUnloadingEnabled(JDK 9+)参数开启; - 元空间使用本地内存,不受 JVM 堆内存限制,但其大小可通过
-XX:MaxMetaspaceSize参数限制,避免耗尽系统内存。
八、垃圾回收的核心优化方向
理解了垃圾识别算法和垃圾回收算法后,在实际项目中,针对 GC 的优化可围绕以下几个核心方向展开:
1. 减少垃圾对象的创建
- 避免循环中频繁创建临时对象(如
String拼接使用StringBuilder,而非+运算符); - 复用高频对象(如数据库连接、线程池、通用工具对象),采用对象池技术(如
Apache Commons Pool); - 避免创建过大的对象,拆分大对象为多个小对象,减少内存占用。
2. 优化引用类型的使用
- 避免静态集合、全局变量持有大量无用对象的强引用,用完及时释放引用(置为
null); - 对于缓存场景,根据需求选择合适的引用类型(如内存敏感型缓存使用软引用,临时缓存使用弱引用);
- 避免不必要的反射引用,减少无用类的产生,降低元空间压力。
3. 合理配置 JVM 参数
- 调整堆内存大小(
-Xms、-Xmx),避免堆内存不足导致频繁 GC 或 OOM; - 优化新生代与老年代的比例(
-Xmn),增大新生代内存,减少 Minor GC 频率; - 选择合适的垃圾回收器(如大堆场景使用 G1 GC,延迟敏感场景使用 ZGC),并配置合理的 GC 参数(如
MaxGCPauseMillis)。
4. 监控与排查 GC 问题
- 开启 GC 日志(
-XX:+PrintGCDetails、-XX:+PrintGCTimeStamps),实时监控 GC 频率和耗时; - 使用
jstat、jmap、MAT 等工具,排查 GC 频繁、内存泄漏、OOM 等问题; - 针对内存泄漏问题,通过堆转储文件(
.hprof)分析对象引用链,定位根因并修复。
九、常见误区澄清
❌ 误区1:"对象没有引用就立刻回收"
✅ 正解:只有 GC 发生时才会回收,且需通过可达性分析确认。
❌ 误区2:"finalize() 是可靠的资源清理方式"
✅ 正解:已被废弃,应使用 try-with-resources 或 Cleaner。
❌ 误区3:"软引用一定能防止 OOM"
✅ 正解:软引用对象在内存压力下会被回收,但若强引用过多,仍会 OOM。
❌ 误区4:"GC 只发生在堆"
✅ 正解:方法区(元空间)也会 GC,回收废弃常量和无用类。
❌ 误区5:"System.gc() 会立即回收所有垃圾"
✅ 正解:System.gc() 只是建议 JVM 进行垃圾回收,不保证立即执行,也不保证回收所有垃圾。

十、总结:从识别到清除的完整闭环
本文系统梳理了 JVM 垃圾回收的核心逻辑,从"垃圾识别"到"垃圾清理",形成了完整的闭环:
- 垃圾识别 :JVM 采用可达性分析算法 (非引用计数法),以 GC Roots 为起点,通过引用链遍历堆内存,准确识别存活对象与垃圾对象,并通过 4 种引用类型(强、软、弱、虚)实现精细化内存管理。
- 垃圾清理 :基于分代收集理论 ,针对新生代(朝生夕死)和老年代(长期存活)的不同特性,采用不同的垃圾回收算法:
- 新生代 :采用复制算法,高效回收大量短期对象,保证内存连续性;
- 老年代 :采用标记-清除 或标记-整理算法,平衡内存利用率与碎片问题。
📌 关键认知:
- GC 是自动的,但不是免费的:它带来了内存安全和开发效率,但也引入了 STW 和 CPU 开销。
- 没有银弹:每种 GC 算法都有其适用场景和 trade-off(权衡),选择合适的 GC 算法和参数调优,是保障应用性能的关键。
- 理解原理,方能驾驭:掌握 GC 背后的设计逻辑,才能在面对 OOM、高延迟等问题时,快速定位根因,制定有效的优化策略。
下一次当你看到GC日志时,不妨想一想:这不仅仅是一次内存清理,这是一场精密的算法舞蹈,是工程与科学的完美结合。