深入 JVM 垃圾回收器:从 Serial 到 ZGC 的演进全景
作者 :Weisian
发布时间:2026年2月9日

在前几篇中,我们系统性地构建了对 JVM 内存管理的认知框架:
- 类被加载后,对象在堆中诞生;
- 堆采用分代设计,新生代"朝生夕死",老年代"历久弥坚";
- 四大基础 GC 算法(标记-清除、复制、标记-整理、分代)构成了回收逻辑的底层基石。
但理论终需落地。真正决定 Java 应用性能表现的,是具体实现这些算法的垃圾回收器(Garbage Collector, GC)。
如果说 GC 算法是"兵法",那么 GC 器就是"军队"------同一套兵法,由不同将领指挥,战果天差地别。
今天,我们将穿越 HotSpot JVM 的 GC 器发展史,从最古老的 Serial 到面向未来的 ZGC ,逐一剖析其架构设计、适用场景、调优参数与实战陷阱,并最终为你提供一份可落地的 GC 选型决策指南。
一、GC 器的核心设计维度
垃圾回收算法是"底层武器",而垃圾回收器(GC器)是"武器的使用者"------它将回收算法落地为可执行的逻辑,同时处理并发、STW、内存分配等一系列复杂问题。
现代HotSpot JVM提供了多种GC器,按发展阶段可分为「经典分代GC器」和「现代区域化GC器」。前者采用严格的分代模型(新生代+老年代),后者则采用Region化模型,打破了传统分代界限。
1.1 核心评价指标(选型的关键)
在介绍具体GC器之前,我们先明确评价一个GC器好坏的核心指标,这也是实际项目中选型的依据:
| 维度 | 说明 | 用户感知 |
|---|---|---|
| 吞吐量(Throughput) | 指「程序运行时间」占「总时间(程序运行时间+GC时间)」的比例。越高越好,适合后台计算型应用(如数据挖掘、批处理任务)。 | 应用整体处理能力 |
| 停顿时间(Pause Time) | 指GC过程中触发的**STW(Stop-The-World)**时间,即业务线程被暂停的时间。越短越好,适合延迟敏感型应用(如Web服务、电商交易系统)。 | 应用响应速度 |
| 内存开销(Memory Overhead) | 指GC器本身运行所需的内存开销(如G1的Remembered Set)。越低越好,说明对应用可用内存的占用越少。 | 可用内存大小 |
| 并发能力 | 指GC器是否支持「并发回收」(即GC线程与业务线程同时运行)。越强越好,能有效减少STW时间。 | 响应性保障 |
| 可扩展性 | 指GC器在大堆内存(>16GB)、多核心CPU环境下的表现。越好越适合大型分布式应用。 | 大规模部署能力 |
📌 关键认知 :吞吐量与停顿时间是一对矛盾体------追求高吞吐量,往往需要牺牲一定的停顿时间;追求低停顿时间,往往需要牺牲一定的吞吐量。没有"完美的GC器",只有"适合场景的GC器"。

1.2 关键概念辨析
📌 关键概念辨析:
- STW(Stop-The-World):GC 过程中暂停所有用户线程;
- 并发(Concurrent)≠ 并行(Parallel) :
- 并发 = GC 与应用交替执行(降低延迟);
- 并行 = 多个 GC 线程同时工作(提升吞吐)。

二、经典 GC 器详解(按演进顺序)
2.1 Serial GC:单线程的"极简清道夫"
Serial GC是最基础、最简单的GC器,也是JDK 1.3之前的默认GC器,采用「单线程」进行垃圾回收,全程触发STW。
架构与工作流程
- 新生代:Serial Young GC(采用3区复制算法)。
- 老年代:Serial Old GC(采用标记-整理算法)。
工作流程:
-
Minor GC:Eden区满 → STW → 单线程复制存活对象到Survivor区 → 清空Eden区。
-
Full GC:老年代满 → STW → 单线程标记-整理整个堆(包括新生代)→ 清除垃圾。
Serial GC工作流程(以Minor GC为例):
-
应用线程运行,分配对象到Eden
┌─────────┐ ┌─────────┐
│ 应用线程 │ → │ Eden区 │
└─────────┘ └─────────┘ -
Eden满,触发Minor GC,暂停所有线程(STW)
┌─────────┐ ┌─────────┐
│ 暂停 │ │ GC线程 │ → 开始回收
└─────────┘ └─────────┘ -
单线程执行复制算法
From空间 → To空间(复制存活对象) -
GC完成,恢复应用线程
┌─────────┐ ┌─────────┐
│ 应用线程 │ ← │ 完成 │
└─────────┘ └─────────┘
-
配置与启用
bash
# 启用串行GC
-XX:+UseSerialGC # 新生代和老年代都使用串行
# 调优参数
-XX:SurvivorRatio=8 # Eden:Survivor比例
-XX:PretenureSizeThreshold=1m # 大对象直接进老年代的阈值
-XX:MaxTenuringThreshold=15 # 晋升年龄阈值
# 适合场景配置示例(客户端应用)
java -Xms64m -Xmx256m -XX:+UseSerialGC -jar MyDesktopApp.jar优缺点总结
| 优势 | 缺点 |
|---|---|
| 实现极简,内存开销极低(无并发线程开销,无额外数据结构) | 单线程回收,效率极低,大堆内存下停顿时间极长 |
| STW时间可预测(无并发干扰,每次GC停顿时间相对固定) | 全程STW,对应用响应性影响极大,无法满足高并发场景 |
| 适合小堆内存(<4GB),回收效率尚可 | 可扩展性差,多核心CPU环境下无法利用多核优势,资源浪费 |
适用场景
- 客户端应用(如桌面软件、嵌入式设备);
- 小堆内存(<1GB)、低并发、对响应性要求不高的后台小应用;
- 开发/测试环境(默认 GC 器)。
💡 冷知识 :即使在现代服务器上,Serial 仍是
-client模式的默认选择。
2.2 Parallel GC:吞吐量优先的"多线程执行者"
Parallel GC(又称Parallel Scavenge GC)是JDK 1.8的默认GC器,是Serial GC的多线程版本,核心目标是追求高吞吐量,适合后台计算型应用。
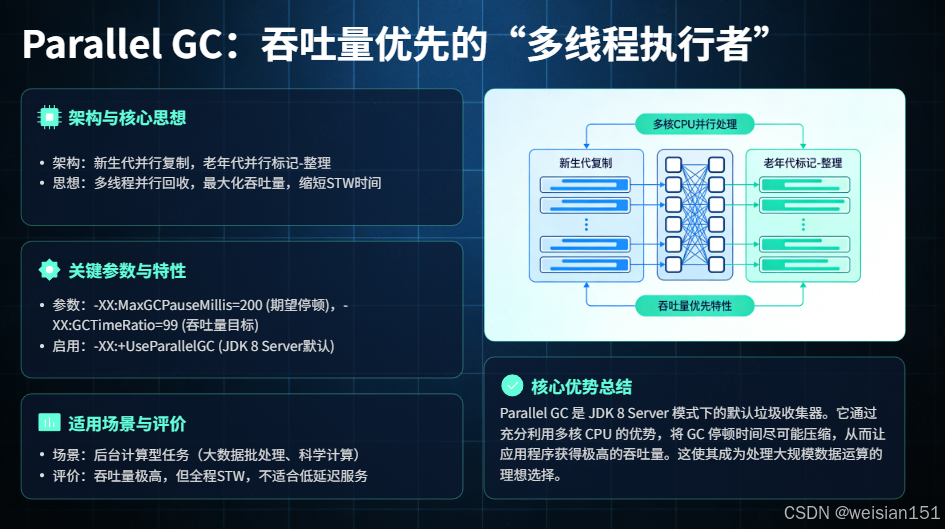
架构与核心思想
- 新生代:Parallel Scavenge(多线程并行复制)。
- 老年代:Parallel Old(多线程并行标记-整理)。
最大化应用程序的吞吐量 ,即:
吞吐量 = 用户代码执行时间 / (用户代码 + GC 时间)
核心特性
- 多线程回收:充分利用多核心CPU优势,提升回收效率,缩短STW时间。
- 吞吐量优先:提供了参数用于控制吞吐量目标。
- 自适应调节策略:可自动调整新生代大小、Survivor区比例等参数,降低使用成本。
- 全程触发STW:虽然多线程执行,但仍会暂停所有业务线程。
关键参数
| 参数 | 作用 |
|---|---|
-XX:MaxGCPauseMillis=200 |
期望最大停顿时间(仅作参考,不保证) |
-XX:GCTimeRatio=99 |
吞吐量目标(99 表示 99% 时间用于用户代码) |
-XX:+UseAdaptiveSizePolicy |
自动调整堆分区(默认开启) |
⚠️ 重要提醒 :
-XX:MaxGCPauseMillis是软目标 !若设得太小,JVM 会频繁 GC 以满足停顿要求,反而降低吞吐量。
配置与启用
bash
# JDK 8 Server 模式默认 GC 器
java -XX:+UseParallelGC MyApp优缺点总结
| 优势 | 缺点 |
|---|---|
| 充分利用多核 CPU,并行回收大幅提升吞吐 | 全程STW,虽然停顿时间比Serial GC短,但仍无法满足低延迟场景 |
| 支持自动调优(AdaptiveSizePolicy),动态调整内存分区 | 不支持并发回收,GC时业务线程完全暂停,对高并发Web应用不友好 |
| 适合大堆内存(4~16GB),回收效率尚可 | 对停顿时间无严格控制,无法保证低延迟 |
适用场景
- 后台计算型任务(如大数据批处理、科学计算);
- 对响应时间不敏感,但要求高吞吐的系统。
📊 生产建议:若你的应用是"离线任务",优先考虑 Parallel GC;若是"在线服务",慎用------它可能因追求吞吐而引发长停顿。
2.3 CMS GC:低延迟的"并发回收者"(已废弃)
CMS GC(Concurrent Mark Sweep GC)是JDK 1.5引入的GC器,核心目标是追求低停顿时间,首次实现了「并发回收」,大幅减少STW时间。
⚠️ 重要提醒:CMS GC在JDK 9中被标记为废弃,JDK 14中被正式移除,目前已被G1 GC替代,但其设计思想对后续GC器有深远影响,仍需掌握。
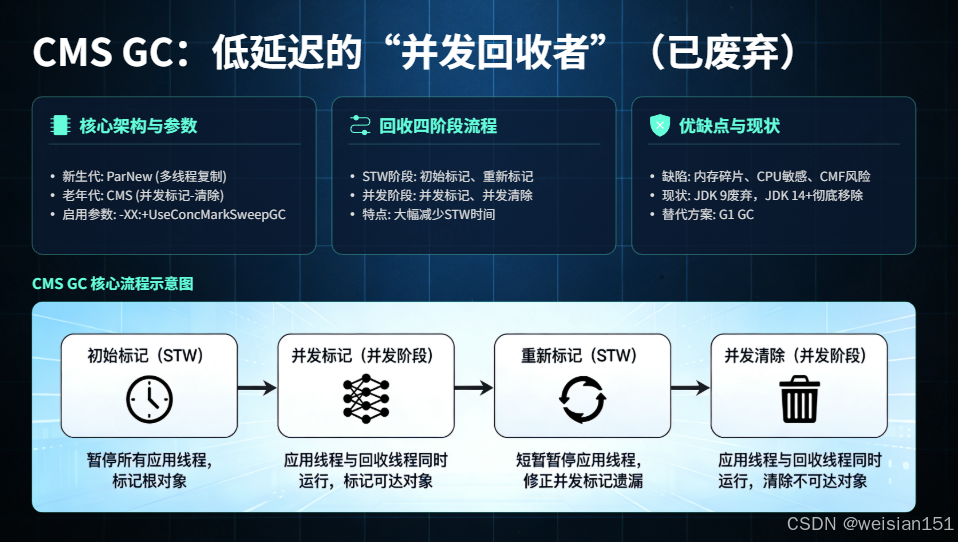
架构与工作流
- 新生代:ParNew(多线程复制)。
- 老年代:CMS(并发标记-清除)。
四阶段工作流:
- Initial Mark(STW) :标记 GC Roots 直接引用的对象。停顿极短(通常 <1ms)。
- Concurrent Mark(并发) :遍历整个对象图。与用户线程并发执行,耗时最长。
- Remark(STW) :修正并发标记期间因用户线程修改引用导致的漏标。停顿较长。
- Concurrent Sweep(并发) :清除未标记对象,释放内存。与用户线程并发执行。
优缺点总结
| 优点 | 致命缺陷 |
|---|---|
| 老年代 GC 几乎无 STW(仅 Initial/Remark 阶段) | 内存碎片:标记-清除不整理内存,大对象分配失败 → 触发 Full GC |
| 适合 Web 应用等低延迟场景 | Concurrent Mode Failure:并发清理期间老年代满 → 退化为 Serial Old(长时间 STW) |
| CPU 敏感:并发阶段占用大量 CPU,影响应用性能 |
废弃状态
- JDK 9:标记为 deprecated;
- JDK 14+:彻底移除。
💡 历史意义:CMS 首次将"并发"理念引入 JVM,为 G1/ZGC 奠定基础,但其碎片问题无法根治。
启用方式(仅限旧版本)
bash
java -XX:+UseConcMarkSweepGC MyApp⚠️ 强烈建议 :新项目不要使用 CMS,直接升级到 G1 或 ZGC。
三、现代 GC 器详解(区域化与超低延迟)
3.1 G1(Garbage-First)------ 可预测停顿的"区域化管理者"
G1 GC(Garbage-First GC)是JDK 9的默认GC器,也是目前生产环境中最主流的GC器,核心目标是在高吞吐量与低延迟之间寻求平衡,同时支持可预测的停顿时间。
核心创新:Region 化堆布局
G1 打破传统分代模型,将堆划分为 约 2048 个固定大小 Region(默认 1~32MB):
- 每个 Region 可动态扮演 Eden、Survivor 或 Old 角色。
- 引入 Remembered Set(RSet) 记录跨 Region 引用,避免全堆扫描。
- Humongous Region:专门存放超大对象(≥ 50% Region 大小)。
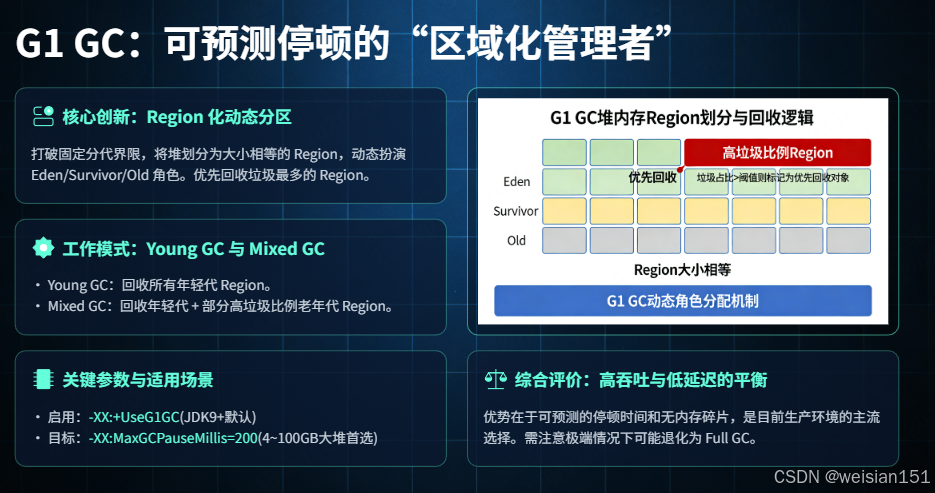
G1工作流程(核心流程)
G1 GC的工作流程包含多个阶段:
G1完整工作流程:
┌─────────────────────────────────────────────────────┐
│ 阶段1:年轻代收集(Young GC) │
│ - STW,复制所有年轻代Region的存活对象 │
│ - 对象年龄增加,检查晋升条件 │
│ - 更新RSet(Remembered Set) │
├─────────────────────────────────────────────────────┤
│ 阶段2:并发标记周期(Concurrent Marking Cycle) │
│ a) 初始标记(STW):伴随Young GC执行 │
│ b) 根区域扫描:扫描Survivor Region引用 │
│ c) 并发标记:标记整个堆的存活对象 │
│ d) 重新标记(STW):完成标记 │
│ e) 清理(STW):统计Region信息,选择回收集 │
├─────────────────────────────────────────────────────┤
│ 阶段3:混合收集(Mixed GC) │
│ - 回收年轻代所有Region + 选择的老年代Region │
│ - 基于Region的垃圾比例选择回收集 │
│ - 重复直到达到目标停顿时间或回收足够内存 │
├─────────────────────────────────────────────────────┤
│ 阶段4:Full GC(fallback) │
│ - 当回收速度跟不上分配速度时触发 │
│ - 使用串行标记-整理算法 │
│ - 停顿时间长,应尽量避免 │
└─────────────────────────────────────────────────────┘工作模式
| 模式 | 触发条件 | 回收范围 | 算法 |
|---|---|---|---|
| Young GC | Eden 区满 | 所有 Young Region(Eden + Survivor) | 复制算法 |
| Mixed GC | 老年代占用 > InitiatingHeapOccupancyPercent(默认 45%) |
Young Region + 部分 Old Region(垃圾最多的) | 复制算法 |
🎯 关键目标 :通过
-XX:MaxGCPauseMillis控制停顿时长(如 200ms),G1 会动态调整每次 Mixed GC 回收的 Old Region 数量以达成目标。
配置与启用
bash
# 启用G1
-XX:+UseG1GC # 启用G1垃圾回收器
# 基本配置
-XX:G1HeapRegionSize=4m # Region大小(1-32MB,2的幂)
-XX:MaxGCPauseMillis=200 # 目标停顿时间(默认200ms)
-XX:G1NewSizePercent=5 # 最小年轻代比例(默认5%)
-XX:G1MaxNewSizePercent=60 # 最大年轻代比例(默认60%)
# 并发标记配置
-XX:InitiatingHeapOccupancyPercent=45 # 触发并发标记的堆占用率
-XX:G1MixedGCLiveThresholdPercent=85 # 混合回收的Region存活阈值
-XX:G1HeapWastePercent=5 # 可容忍的堆浪费比例
-XX:G1MixedGCCountTarget=8 # 混合回收的最大次数
# 并行线程配置
-XX:ParallelGCThreads=8 # 并行GC线程数
-XX:ConcGCThreads=2 # 并发GC线程数
# 调优参数
-XX:G1ReservePercent=10 # 保留空间比例(避免to-space溢出)
-XX:G1ConcRefinementThreads=4 # 并发 refinement 线程数
-XX:+G1UseAdaptiveConcRefinement # 自适应 refinement
# 日志与监控
-Xlog:gc*,gc+heap=debug,gc+ergo=debug,gc+age=trace:file=g1.log
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintTenuringDistribution
# 适合场景配置示例(大堆应用)
java -Xms16g -Xmx16g -XX:+UseG1GC -XX:MaxGCPauseMillis=200 \
-XX:G1HeapRegionSize=8m -XX:InitiatingHeapOccupancyPercent=40 \
-jar BigDataApp.jar日志解读示例
log
[GC pause (G1 Evacuation Pause) (young), 0.045 secs]
[Eden: 2048M(2048M)->0B(2048M)
Survivors: 256M->256M
Heap: 4096M(8192M)->2304M(8192M)]Evacuation Pause:表示复制算法(对象迁移);- Eden 清空,Survivor 保留,堆使用量下降。
优缺点总结
| 优势 | 潜在问题 |
|---|---|
| 可预测停顿:停顿时间与堆大小无关,只与回收 Region 数相关 | Full GC 退化:若 Mixed GC 速度跟不上对象分配速度,仍会触发 Full GC(退化为 Serial Old) |
| 无内存碎片:Mixed GC 使用复制算法整理 Old Region | RSet 开销:跨 Region 引用维护消耗额外内存与 CPU |
| 自动调优:无需手动设置新生代/老年代比例 |
适用场景
- 大堆(>16GB);
- 低延迟要求(停顿 <1s);
- 堆内存不规则增长的应用(如缓存系统)。
💡 生产建议 :G1 是 4~100GB 堆的"甜点区"首选,平衡了吞吐与延迟。
3.2 ZGC(Z Garbage Collector)------ 超低延迟的"革命性回收者"
ZGC(Z Garbage Collector)是JDK 11引入的实验性GC器,JDK 17中被正式转正,核心目标是实现超低延迟(停顿时间<10ms),同时支持超大堆内存(最大支持4TB)。
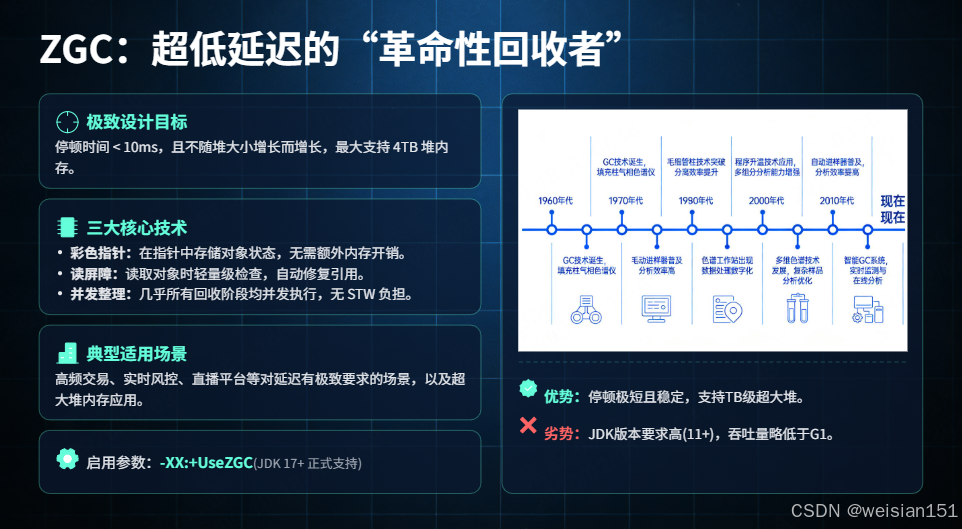
设计目标
停顿时间 < 10ms,且与堆大小无关(支持 TB 级堆)
三大核心技术
- Colored Pointer(着色指针) :利用 64 位指针中的 4 位元数据存储对象状态,无需额外内存。
- Load Barrier(读屏障):在每次对象读取时插入轻量级检查,自动修复旧引用。
- Concurrent Compaction(并发整理) :标记、转移、重映射全程并发,几乎无 STW。
执行流程(三阶段)
- Mark Start(STW <1ms):标记 GC Roots,初始化标记位。
- Concurrent Mark & Remap:并发遍历对象图,同时重映射旧引用。
- Concurrent Relocate:并发移动对象到新位置,更新指针。
✅ 全程 STW 仅发生在 Mark Start 和少量引用处理,通常 <1ms。
配置与启用
bash
-XX:+UseZGC # 启用ZGC(JDK 17+正式支持)
-XX:ZHeapSize=32g # 堆内存大小(最大支持4TB)
-XX:ZCollectionInterval=60 # 主动触发GC的时间间隔(秒)
# 启动示例
java -XX:+UseZGC -Xmx64g
-jar BigDataApp.jar优缺点总结
| 优势 | 代价 |
|---|---|
| 停顿时间恒定(实测 0.5~2ms),不受堆大小影响 | 吞吐量略低于 G1(读屏障增加 CPU 开销) |
| 无内存碎片 | JDK 版本要求高(JDK 11+ 正式可用,JDK 15+ 生产就绪) |
| 支持大堆(TB 级) |
适用场景
- 极致低延迟系统(高频交易、实时音视频、游戏服务器);
- 超大堆应用(>100GB)。
💡 ZGC vs Shenandoah:两者目标相似,但 ZGC 由 Oracle 主导,Shenandoah 由 Red Hat 主导;ZGC 性能略优,Shenandoah 社区更开放(OpenJDK 默认包含)。
3.3 Shenandoah GC:与ZGC比肩的"超低延迟竞争者"
Shenandoah GC是RedHat主导开发的GC器,JDK 12中引入,JDK 17中被正式转正,核心目标与ZGC一致。

核心特性
- 超低延迟:所有回收阶段均为并发执行,STW时间<10ms。
- Region化模型:与G1 GC类似。
- 并发整理:支持并发对象移动与引用更新,无内存碎片。
- SATB(Snapshot At The Beginning):采用快照技术解决并发标记问题。
- 无彩色指针:兼容性更好(支持更多硬件架构)。
与ZGC的核心区别
- 技术实现:ZGC采用彩色指针,Shenandoah GC采用SATB快照技术。
- 生态支持:ZGC由Oracle主导,Shenandoah GC由RedHat主导,在Linux环境下表现更优。
启用方式
bash
-XX:+UseShenandoahGC # 启用Shenandoah GC(JDK 17+正式支持)适用场景
与ZGC基本一致,可根据团队技术栈、操作系统环境选择。
四、GC 器对比全景图
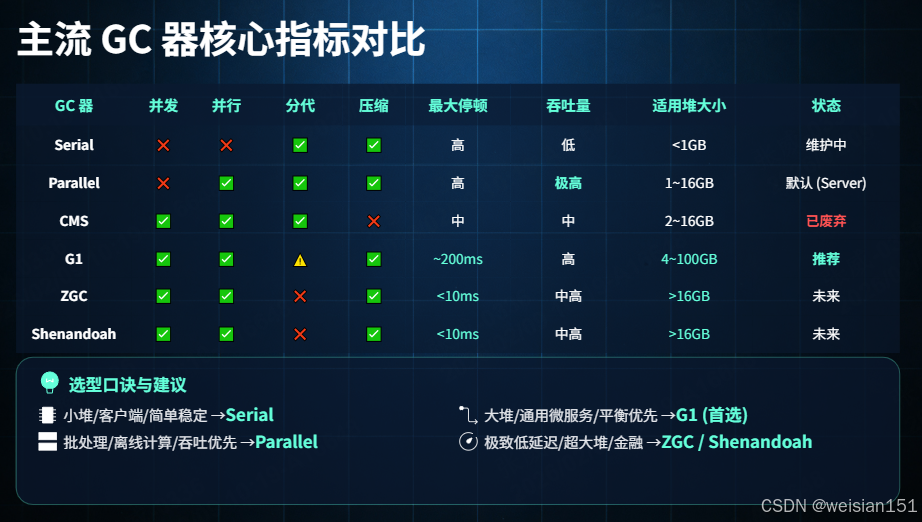
4.1 主流 GC 器核心指标对比
| GC 器 | 并发 | 并行 | 分代 | 压缩 | 最大停顿 | 吞吐量 | 适用堆大小 | 状态 |
|---|---|---|---|---|---|---|---|---|
| Serial | ❌ | ❌ | ✅ | ✅ | 高(随堆增长) | 低 | <1GB | 维护中 |
| Parallel | ❌ | ✅ | ✅ | ✅ | 高 | 极高 | 1~16GB | 默认(Server) |
| CMS | ✅ | ✅ | ✅ | ❌ | 中(Remark 阶段) | 中 | 2~16GB | 已废弃 |
| G1 | ✅ | ✅ | ⚠️(Region 化) | ✅ | 可预测(~200ms) | 高 | 4~100GB | 推荐 |
| ZGC | ✅ | ✅ | ❌ | ✅ | <10ms | 中高 | >16GB(TB 级) | 未来 |
| Shenandoah | ✅ | ✅ | ❌ | ✅ | <10ms | 中高 | >16GB(TB 级) | 未来 |
📌 选型口诀:
- 小堆、客户端、简单稳定 → Serial
- 批处理、离线计算、吞吐优先 → Parallel
- 大堆、通用微服务、平衡优先 → G1(首选)
- 极致低延迟、超大堆、金融/实时 → ZGC / Shenandoah
- 永远不要新上 CMS
4.2 实战选型指南(核心原则:贴合场景,简单优先)
- 小堆内存(<4GB)、客户端应用:优先选择「Serial GC」。
- 中堆内存(4~16GB)、后台计算型应用(吞吐量优先):优先选择「Parallel GC」。
- 大堆内存(>16GB)、大部分生产环境应用(吞吐量+延迟兼顾):优先选择「G1 GC」。
- 超大堆内存(>64GB)、延迟敏感型应用(超低延迟要求):优先选择「ZGC」或「Shenandoah GC」。
- 新项目选型:优先选择「G1 GC」(JDK 17+),若有超低延迟要求,选择「ZGC」。
- 旧项目迁移:JDK 1.8项目可继续使用「Parallel GC」或「G1 GC」,JDK 17+项目建议迁移到「G1 GC」或「ZGC」。
📌 选型黄金法则 :先选择默认GC器,再根据性能监控结果进行调优------不要盲目追求"先进的GC器",适合场景的才是最好的。
决策流程图
选择垃圾回收器的决策流程:
┌─────────────────────────────────┐
│ 开始:分析应用需求 │
├─────────────────────────────────┤
│ 问题1:堆大小? │
│ <4GB → Serial/Parallel │
│ 4-16GB → Parallel/G1 │
│ >16GB → G1/ZGC/Shenandoah │
├─────────────────────────────────┤
│ 问题2:延迟要求? │
│ <10ms → ZGC/Shenandoah │
│ <200ms → G1 │
│ >200ms → Parallel │
├─────────────────────────────────┤
│ 问题3:吞吐量重要? │
│ 是 → Parallel │
│ 否 → 根据延迟选择 │
├─────────────────────────────────┤
│ 问题4:JDK版本? │
│ JDK 8 → Parallel/G1 │
│ JDK 11+ → G1/ZGC │
│ OpenJDK 12+ → Shenandoah │
├─────────────────────────────────┤
│ 输出:推荐的GC器 │
└─────────────────────────────────┘五、垃圾回收器实战调优:从监控到落地
选择合适的GC器后,还需要进行实战调优,才能充分发挥GC器的性能。GC调优的核心逻辑是:先监控,再定位,最后调优------无监控的调优都是"瞎猜"。
1. 第一步:开启GC日志(必备)
GC日志是监控与调优的基础。
JVM参数配置(生产环境推荐)
bash
# 基础GC日志配置
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-XX:+PrintGCDateStamps
-Xloggc:/data/logs/jvm/gc-%t.log
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=10
-XX:GCLogFileSize=100M
# 额外诊断参数
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/data/logs/jvm/heap.hprofGC日志分析工具
- GCViewer:开源免费,适合快速分析。
- GCEasy:在线工具(https://gceasy.io/),自动生成分析报告,推荐生产环境使用。
- VisualVM:JDK自带工具,适合本地调试。


2. 第二步:实时监控GC状态(常用工具)
(1)jstat(JDK自带,命令行工具)
jstat是JDK自带的命令行工具,用于实时监控JVM的GC状态、堆内存使用情况,无需提前开启GC日志,适合快速排查问题。
常用命令
bash
# 实时监控GC状态,每1000毫秒打印一次,共打印10次
jstat -gc <pid> 1000 10
# 实时监控GC详细状态(包括各区域内存使用率、GC次数、耗时)
jstat -gcutil <pid> 1000 10
# 实时监控新生代GC状态
jstat -gcnew <pid> 1000 10
# 实时监控老年代GC状态
jstat -gcold <pid> 1000 10输出结果关键指标解读
YGC:新生代GC(Minor GC)次数YGCT:新生代GC总耗时(秒)FGC:Full GC次数FGCT:Full GC总耗时(秒)GCT:GC总耗时(秒)E:Eden区内存使用率(%)S0/S1:Survivor 0/Survivor 1区内存使用率(%)O:老年代内存使用率(%)
(2)VisualVM(JDK自带,可视化工具)
VisualVM是JDK自带的可视化工具,支持实时监控JVM的GC状态、堆内存使用情况、线程状态等,操作简单,适合本地调试与问题排查。
核心功能
- 实时监控堆内存、非堆内存的使用变化
- 实时监控GC次数、耗时,以及GC器的工作状态
- 生成堆转储文件,分析内存泄漏问题
- 监控线程状态,排查线程死锁、线程阻塞问题
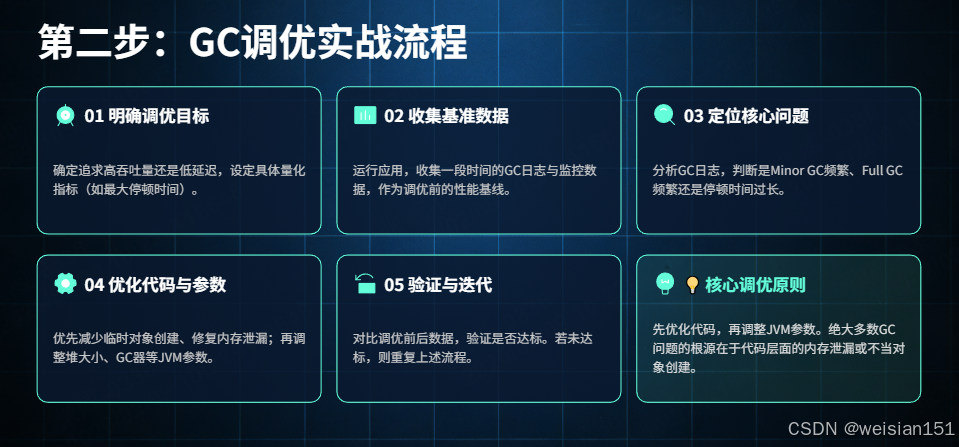
3. 第三步:GC调优实战步骤(核心流程)
GC调优是一个"循序渐进"的过程,核心流程如下:
- 明确调优目标:确定是追求"高吞吐量"还是"低延迟",预设目标指标(如吞吐量≥99%,停顿时间<200ms)
- 开启监控与日志:配置JVM参数,开启GC日志与堆转储功能,使用jstat、VisualVM等工具实时监控
- 收集基准数据:运行应用,收集一段时间内的GC数据(GC次数、耗时、堆内存变化等),作为调优的基准
- 定位核心问题:根据监控数据与GC日志,定位核心问题(如Minor GC频繁、Full GC频繁、停顿时间过长等)
- 调整参数/优化代码 :
- 若Minor GC频繁:增大新生代内存(
-Xmn或-XX:G1NewSizePercent),优化代码减少临时对象创建 - 若Full GC频繁:调整对象晋升策略(
-XX:MaxTenuringThreshold),增大老年代内存,替换GC器(如从Parallel GC迁移到G1 GC) - 若停顿时间过长:降低预设最大停顿时间(
-XX:MaxGCPauseMillis),迁移到G1 GC/ZGC
- 若Minor GC频繁:增大新生代内存(
- 验证调优效果:重新运行应用,收集调优后的GC数据,与基准数据对比,验证是否达到调优目标
- 迭代优化:若未达到目标,重复步骤4~6,直至满足调优目标(注意:调优需适度,不可过度调优)
💡 调优原则 :先优化代码,再调整JVM参数------大部分GC问题都是由不良代码(如内存泄漏、频繁创建临时对象)导致的,优化代码往往能带来更显著的效果。
4. 通用调优原则
- 固定堆大小 :
-Xms = -Xmx,避免扩容开销 - 监控先行 :开启 GC 日志(
-Xloggc)和堆转储(-XX:+HeapDumpOnOutOfMemoryError) - 渐进调整:每次只改一个参数,观察效果
- 压测验证:上线前进行全链路压测,确认 GC 表现符合预期
5. 生产环境常见问题与解决方案
(1)Minor GC 频繁
- 核心症状:jstat监控显示YGC每秒数次,YGCT快速累积,新生代Eden区快速被填满
- 核心原因:新生代内存过小,或代码频繁创建临时对象(如循环中String拼接、频繁创建大对象)
- 解决方案 :
- 增大新生代内存(Parallel GC:
-Xmn;G1 GC:-XX:G1MaxNewSizePercent) - 优化代码,减少临时对象创建(如使用StringBuilder替代String拼接、采用对象池复用高频对象)
- 调整Survivor区比例(
-XX:SurvivorRatio),提升Survivor区容量,减少对象过早晋升
- 增大新生代内存(Parallel GC:
(2)Full GC 频繁
- 核心症状:jstat监控显示FGC频繁(每分钟数次),FGCT单次耗时过长(>100ms)
- 核心原因:老年代内存过小,大量对象过早晋升到老年代,或内存泄漏导致老年代被填满
- 解决方案 :
- 增大老年代内存(Parallel GC:增大
-Xmx,减少-Xmn;G1 GC:调整-XX:G1MaxNewSizePercent) - 调整对象晋升策略(增大
-XX:PretenureSizeThreshold,减少大对象直接进入老年代;降低-XX:MaxTenuringThreshold,让对象尽快晋升) - 排查内存泄漏(生成堆转储文件,使用MAT工具分析,清理无用强引用)
- 替换GC器(从Parallel GC迁移到G1 GC,避免全局Full GC)
- 增大老年代内存(Parallel GC:增大
(3)GC 停顿时间过长
- 核心症状:应用响应缓慢、超时,GC日志显示单次GC停顿时间>500ms
- 核心原因:GC器选择不当(如使用Serial GC/Parallel GC),或堆内存过大,导致全局Full GC耗时过长
- 解决方案 :
- 替换GC器(迁移到G1 GC/ZGC,支持可预测停顿/超低延迟)
- 降低预设最大停顿时间(
-XX:MaxGCPauseMillis) - 拆分大堆内存(若堆内存>64GB,可考虑拆分应用,或使用ZGC/Shenandoah GC)
- 优化代码,减少存活对象数量,降低GC整理开销

六、常见误区与陷阱
❌ 误区1:"G1 不会产生 Full GC"
✅ 正解:当 Mixed GC 无法跟上分配速率时,仍会触发 Full GC(退化为 Serial Old),表现为长时间 STW。
对策 :增大堆、降低分配速率、调高IHOP。
❌ 误区2:"ZGC 完全没有停顿"
✅ 正解:仍有极短 STW(<1ms),用于根标记,但对应用无感知。
❌ 误区3:"Parallel GC 的 MaxGCPauseMillis 能保证停顿"
✅ 正解:该参数仅为软目标,JVM 会尽量满足,但不保证。过度依赖会导致吞吐暴跌。

结语:GC 器的"过去、现在与未来"
JVM垃圾回收器的发展历程,是一部"从单线程到多线程、从分代到区域化、从高吞吐量到超低延迟"的进化史:
- 过去:Serial GC、Parallel GC、CMS GC,解决了"自动回收内存"的核心问题。
- 现在:G1 GC成为生产环境主流;ZGC/Shenandoah GC实现超低延迟。
- 未来:GC器将朝着"更高吞吐量、更低延迟、更大堆支持、更智能调优"的方向发展。
关键点回顾
- 垃圾识别的核心是可达性分析算法,4种引用类型影响GC回收时机。
- 三大核心回收算法各有优劣,现代GC器采用算法组合策略。
- 经典分代GC器基于严格分代模型,现代区域化GC器基于Region化模型。
- GC选型的核心是贴合场景。
- GC调优的核心流程是**"监控-定位-调优-验证"**。
理解JVM垃圾回收器,不仅能帮助你解决实际项目中的性能问题,更能让你深入理解Java虚拟机的运行机制,写出更高效、更稳定的代码。
JVM 的垃圾回收器,如同城市中的清洁工队伍:
- Serial 是独行侠,默默清扫小巷;
- Parallel 是高效团队,专注快速清运;
- CMS 是夜班工人,试图在居民睡觉时工作,却常因垃圾堆积而手忙脚乱;
- G1 是智能调度员,分区清理,承诺准时完成;
- ZGC 则是隐形机器人,悄无声息地维持城市整洁,居民甚至感觉不到它的存在。
"没有最好的 GC 器,只有最适合你业务的 GC 器。"
互动话题 :
你在生产环境中使用过哪种 GC 器?是否通过切换 GC 器显著提升了系统稳定性或响应速度?欢迎在评论区分享你的"GC 器实战"故事!