从本篇开始,我们正式踏入神经网络与深度学习 的大门,首站就是所有神经网络的入门基石 ------感知器(Perceptron) 算法。
感知器作为最早的人工神经网络模型,是深度学习中多层感知器、CNN、Transformer 等复杂模型的基础,理解它的核心原理,就能打通神经网络从 0 到 1 的任督二脉。
一、什么是感知器?
感知器(Perceptron)是由美国科学家罗森布拉特在 1957 年提出的,是最简单的人工神经网络模型 ,本质是一个线性二分类模型 ,也是我们上一篇提到的 KNN 算法之后,第一个带参数训练过程的经典算法。
从生物学角度,感知器是对生物神经元的极简模拟:生物神经元通过接收多个突触的信号,整合后达到阈值就会产生神经冲动;而人工感知器通过接收多个特征输入,经过加权求和 + 激活判断后,输出分类结果(0 或 1)。
用一句话总结感知器的核心逻辑:对输入特征进行加权求和,再通过激活函数做二分类判断,通过训练不断调整权重参数,让模型能精准划分两类数据。
感知器也是后续多层感知器(MLP) 的基础,多层感知器就是将多个感知器堆叠,加入隐藏层,从而实现非线性分类,这也是深度学习的核心思路。
二、感知器的核心原理
感知器的原理围绕数学公式 和结构模型 展开,没有复杂的推导,核心就 3 步:输入加权求和→加入偏置→激活判断。
2.1 感知器的基本结构
感知器的结构是神经网络的基础,包含三个核心部分,对应生物神经元的输入、整合、输出:
- 输入层 :接收外界的特征输入,记为
x1, x2, ..., xn(n 为特征维度),每个输入对应一个权重(w),权重代表该特征对分类结果的重要性; - 整合层 :对输入特征进行加权求和 ,再加上偏置(b)(偏置的作用是调整模型的分类阈值,让模型更灵活);
- 输出层 :将整合后的结果传入激活函数,得到最终的二分类输出(0 或 1)。
2.2 感知器的核心公式
感知器的计算过程可以用两个核心公式概括
步骤1:线性计算
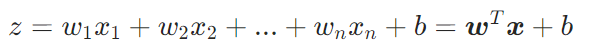
:特征的线性得分(无边界)
步骤 2:二分类输出
感知器的激活函数是符号函数 ,作用是将线性加权和z映射为0 或 1的二分类结果,公式为:
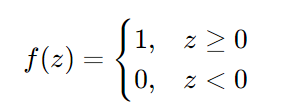
如果线性加权和大于等于 0,感知器输出 1(属于正类);否则输出 0(属于负类)。
2.3 感知器的核心本质
感知器的本质是:在 n 维特征空间中,找到一个线性超平面,将两类数据进行线性划分。
- 二维特征空间中,这个超平面是一条直线;
- 三维特征空间中,这个超平面是一个平面;
- n 维特征空间中,这个超平面是n-1 维的线性界面。
这也是感知器的核心局限性:只能处理线性可分的数据,如果数据是非线性可分的,感知器无法找到合适的划分平面,这也是后续多层感知器出现的原因。
三、感知器的训练过程
和 KNN 算法不同,感知器是有训练过程的模型,核心是通过误差调整权重和偏置,让模型的预测结果越来越接近真实标签。感知器的训练遵循错误驱动的原则,只有当预测结果出错时,才会调整参数,这也是后续反向传播算法的雏形。
3.1 训练的核心目标
找到一组最优的权重参数 W 和偏置 b ,使得感知器能对所有训练样本做出正确的二分类判断,即:对于任意训练样本(Xi, yi)(yi∈{0,1}),感知器的输出f(W·Xi + b) = yi。
3.2 感知器的训练步骤
感知器的训练过程非常简单,总共 5 步,全程只有参数初始化 、前向预测 、误差计算 、参数更新 、循环迭代几个核心步骤。
步骤 1:参数初始化
给权重w1, w2, ..., wn赋随机小值 (或初始化为 0),偏置b初始化为 0(也可以是随机小值)。
步骤 2:前向预测
取一个训练样本(X, y),其中X=(x1,x2,...,xn)是特征,y是真实标签(0 或 1),代入感知器公式计算预测输出:
- 计算线性加权和:
z = w1x1 + w2x2 + ... + wnxn + b - 激活判断得到预测值:
y_hat = f(z)(f 为阶跃函数)
步骤 3:误差计算
计算预测值与真实值的误差:e = y - y_hat
- 如果
e=0:预测正确,不调整参数; - 如果
e≠0:预测错误,需要根据误差调整权重和偏置。
步骤 4:参数更新
这是感知器训练的核心,根据感知器学习规则更新权重和偏置,公式为:
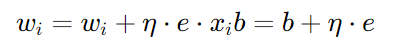
其中:
η:学习率(0<η≤1),控制参数更新的步长,和后续梯度下降的学习率作用一致;e:预测误差y - y_hat;x_i:第 i 个特征值。
学习率的选择技巧:
- η 太小:参数更新太慢,训练耗时久,容易陷入局部最优;
- η 太大:参数更新幅度过大,容易在最优值附近震荡,无法收敛;
- 一般先取 0.1、0.01 尝试,再根据训练结果调整。
步骤 5:循环迭代
重复步骤 2-4,遍历所有训练样本,直到所有样本预测正确 ,或者迭代次数达到预设值,训练结束。
3.3 感知器训练的核心思想
感知器的参数更新规则是梯度下降的极简形式 ,也是后续 BP 神经网络(反向传播)的基础。简单说:预测错了,就根据误差的方向,往能修正错误的方向调整参数,直到模型能正确划分所有线性可分的数据。
四、感知器的优缺点
4.1 优点
- 结构简单:是最简单的人工神经网络,原理易懂,数学推导简单,适合神经网络入门;
- 训练高效:参数更新规则简单,计算量小,对于线性可分的小数据集,训练速度极快;
- 易实现:核心代码只有几十行,无需复杂的库,纯 Python 就能实现;
- 奠定基础:感知器的加权求和、激活函数、参数训练思想,是所有神经网络的核心基石,后续的 MLP、CNN 都基于此。
4.2 缺点
- 只能处理线性可分数据 :这是感知器最大的局限性,也是著名的感知器收敛定理:只有当训练数据线性可分时,感知器才能收敛,否则永远无法训练成功(比如异或 XOR 问题,感知器无法解决);
- 仅支持二分类:原生感知器只能做 0/1 的二分类,无法直接处理多分类问题(需要改进为多类感知器,比如一对多、一对一);
- 对异常值敏感:感知器的参数更新受错误样本驱动,异常值会导致参数向错误方向调整,影响模型效果;
- 无泛化能力优化:原生感知器没有正则化等机制,容易在训练集上过拟合,对测试集的泛化能力较差。
五、实战案例 ------ 感知器实现鸢尾花二分类
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
class Perceptron:
def __init__(self, eta0=0.1, max_iter=100):
self.eta0 = eta0
self.max_iter = max_iter
self.w = None
self.b = 0
def activation(self, z):
return np.where(z >= 0, 1, 0)
def fit(self, X, y):
self.w = np.zeros(X.shape[1])
for _ in range(self.max_iter):
error_count = 0
for xi, yi in zip(X, y):
z = np.dot(xi, self.w) + self.b
y_hat = self.activation(z)
e = yi - y_hat
if e != 0:
self.w += self.eta0 * e * xi
self.b += self.eta0 * e
error_count += 1
if error_count == 0:
print(f"提前收敛,迭代次数:{_+1}")
break
def predict(self, X):
z = np.dot(X, self.w) + self.b
return self.activation(z)
iris = load_iris()
X = iris.data[:100, :]
y = iris.target[:100]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
ppn = Perceptron(eta0=0.1, max_iter=100)
ppn.fit(X_train, y_train)
y_train_pred = ppn.predict(X_train)
y_test_pred = ppn.predict(X_test)
print(f"感知器训练集准确率:{accuracy_score(y_train, y_train_pred):.4f}")
print(f"感知器测试集准确率:{accuracy_score(y_test, y_test_pred):.4f}")
print(f"感知器权重:{ppn.w}")
print(f"感知器偏置:{ppn.b}")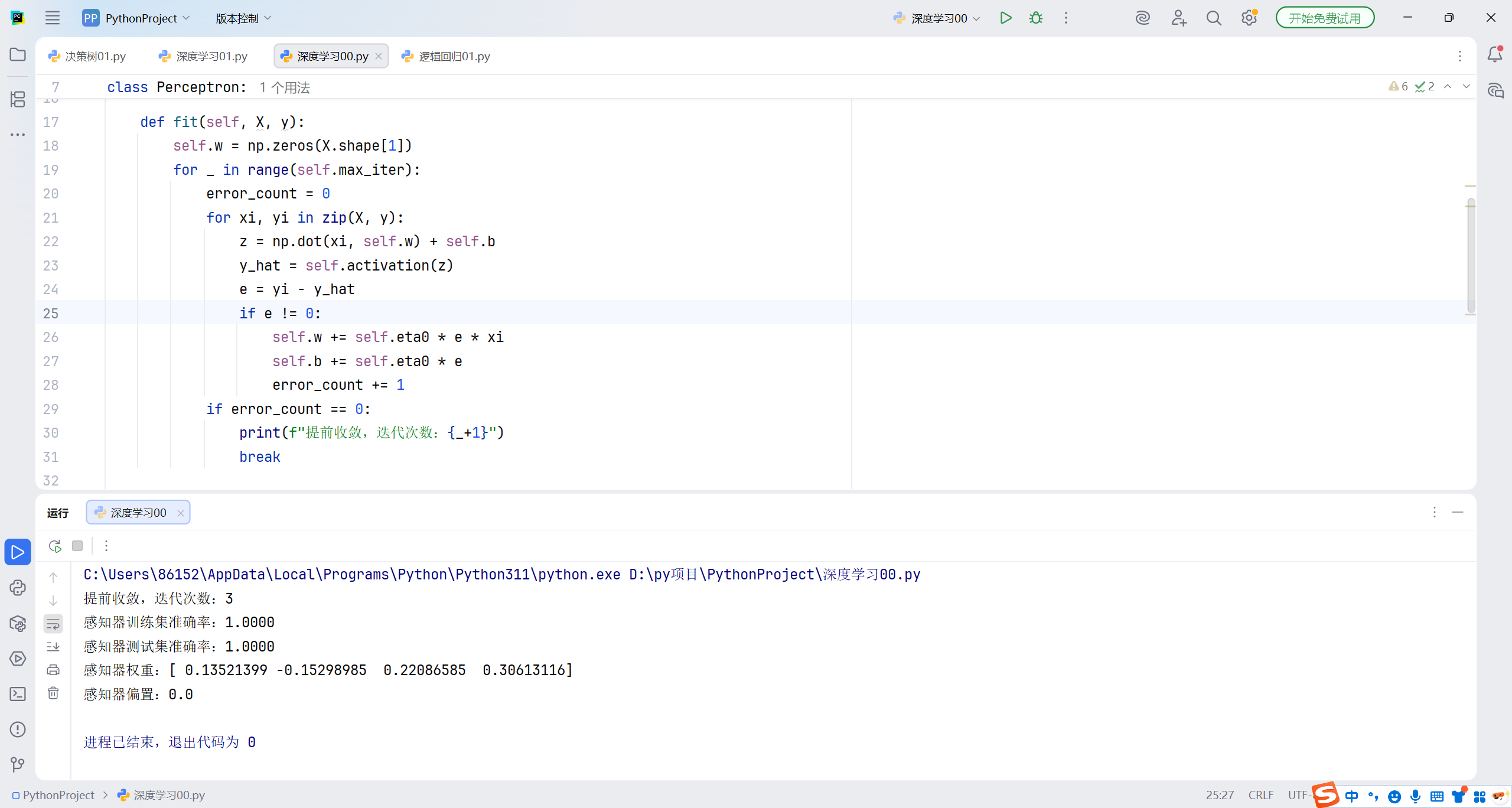
日记
2月8日,星期日
休息的一天
今天单休一天,终于知道之前别人说的放假只吃一顿是什么样的,睡觉睡到下午14:00,然后吃点零食,晚上只吃一顿。