目录
[1 引言:为什么Airflow是数据工程的首选调度平台](#1 引言:为什么Airflow是数据工程的首选调度平台)
[1.1 从Crontab到Airflow的技术演进](#1.1 从Crontab到Airflow的技术演进)
[1.2 Airflow在数据技术栈中的定位](#1.2 Airflow在数据技术栈中的定位)
[2 Airflow核心架构深度解析](#2 Airflow核心架构深度解析)
[2.1 核心概念架构设计](#2.1 核心概念架构设计)
[2.1.1 DAG(有向无环图)设计哲学](#2.1.1 DAG(有向无环图)设计哲学)
[2.1.2 Airflow系统架构图](#2.1.2 Airflow系统架构图)
[2.2 Operator深度解析与开发实践](#2.2 Operator深度解析与开发实践)
[2.2.1 内置Operator全面解析](#2.2.1 内置Operator全面解析)
[2.2.2 Operator执行流程图](#2.2.2 Operator执行流程图)
[3 任务依赖管理与高级调度技巧](#3 任务依赖管理与高级调度技巧)
[3.1 复杂依赖关系建模](#3.1 复杂依赖关系建模)
[3.1.1 依赖关系模式大全](#3.1.1 依赖关系模式大全)
[3.1.2 依赖关系可视化图](#3.1.2 依赖关系可视化图)
[3.2 高级调度技巧与时间管理](#3.2 高级调度技巧与时间管理)
[3.2.1 复杂调度策略实现](#3.2.1 复杂调度策略实现)
[4 错误处理与可靠性工程](#4 错误处理与可靠性工程)
[4.1 全面错误处理策略](#4.1 全面错误处理策略)
[4.1.1 多层次错误处理机制](#4.1.1 多层次错误处理机制)
[4.1.2 错误处理流程图](#4.1.2 错误处理流程图)
[5 企业级实战案例](#5 企业级实战案例)
[5.1 实时数据管道完整实现](#5.1 实时数据管道完整实现)
[5.1.1 电商实时数据处理平台](#5.1.1 电商实时数据处理平台)
[5.1.2 企业级数据管道架构图](#5.1.2 企业级数据管道架构图)
[6 性能优化与故障排查](#6 性能优化与故障排查)
[6.1 大规模部署性能优化](#6.1 大规模部署性能优化)
[6.1.1 高性能配置与调优](#6.1.1 高性能配置与调优)
[6.2 故障排查指南](#6.2 故障排查指南)
[6.2.1 常见问题与解决方案](#6.2.1 常见问题与解决方案)
1 引言:为什么Airflow是数据工程的首选调度平台
在我多年的Python数据工程生涯中,见证了从Crontab到现代化调度系统的技术演进。曾有一个电商实时数据项目 ,由于初期使用简单Crontab调度 ,导致任务依赖混乱 、错误难以追踪 ,通过迁移到Airflow后,任务失败率从30%降低到2% ,运维效率提升5倍 。这个经历让我深刻认识到:现代化数据管道需要专业的调度系统,而非简单的定时任务工具。
1.1 从Crontab到Airflow的技术演进
python
# crontab_to_airflow_evolution.py
import subprocess
from datetime import datetime
from airflow import DAG
from airflow.operators.bash import BashOperator
class SchedulerEvolution:
"""调度系统演进演示"""
def demonstrate_crontab_limitations(self):
"""展示Crontab的局限性"""
# 传统的Crontab调度方式
crontab_config = """
# 传统电商数据管道Crontab配置
0 2 * * * /scripts/extract_data.sh
0 3 * * * /scripts/transform_data.sh # 需要等待extract完成
0 4 * * * /scripts/load_data.sh # 需要等待transform完成
"""
limitations = [
"无法处理任务依赖:如果extract失败,后续任务仍然会执行",
"缺乏错误处理:任务失败需要手动干预",
"没有监控告警:无法实时了解任务状态",
"难以维护:复杂的依赖关系难以管理"
]
print("=== Crontab调度的局限性 ===")
for i, limitation in enumerate(limitations, 1):
print(f"{i}. {limitation}")
return limitations
def demonstrate_airflow_advantages(self):
"""展示Airflow的优势"""
# 使用Airflow的等效实现
with DAG('ecommerce_data_pipeline',
schedule_interval='0 2 * * *',
start_date=datetime(2024, 1, 1),
catchup=False) as dag:
extract_task = BashOperator(
task_id='extract_data',
bash_command='/scripts/extract_data.sh',
retries=3,
retry_delay=300 # 5分钟重试
)
transform_task = BashOperator(
task_id='transform_data',
bash_command='/scripts/transform_data.sh',
retries=3
)
load_task = BashOperator(
task_id='load_data',
bash_command='/scripts/load_data.sh',
retries=3
)
# 明确的依赖关系
extract_task >> transform_task >> load_task
advantages = [
"可视化依赖管理:清晰的任务关系图",
"自动错误重试:内置重试机制",
"完整的监控体系:Web UI实时监控",
"任务版本控制:代码化配置管理"
]
print("\n=== Airflow的核心优势 ===")
for i, advantage in enumerate(advantages, 1):
print(f"{i}. {advantage}")
return advantages1.2 Airflow在数据技术栈中的定位
Airflow的核心价值定位:
-
工作流编排器:协调整个数据管道的执行流程
-
任务调度器:替代传统的Crontab调度方式
-
运维监控平台:提供完整的任务监控和告警能力
-
数据管道DSL:使用Python代码定义数据工作流
2 Airflow核心架构深度解析
2.1 核心概念架构设计
2.1.1 DAG(有向无环图)设计哲学
python
# dag_architecture.py
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.utils.task_group import TaskGroup
from datetime import datetime, timedelta
import json
class DAGDesignPhilosophy:
"""DAG设计哲学与实践"""
def demonstrate_dag_structure(self):
"""展示DAG的核心结构"""
# DAG定义的最佳实践
default_args = {
'owner': 'data-engineering',
'depends_on_past': False,
'email_on_failure': True,
'email_on_retry': False,
'retries': 3,
'retry_delay': timedelta(minutes=5),
'execution_timeout': timedelta(hours=2)
}
dag = DAG(
'advanced_data_pipeline',
default_args=default_args,
description='高级数据管道示例',
schedule_interval='@daily',
start_date=datetime(2024, 1, 1),
catchup=False,
max_active_runs=1,
dagrun_timeout=timedelta(hours=6),
tags=['data-pipeline', 'production']
)
# DAG的核心特性展示
characteristics = {
'动态生成': '支持根据参数动态生成DAG结构',
'模板化': '使用Jinja2模板实现参数化配置',
'版本控制': 'Python代码定义,支持Git版本管理',
'模块化': '支持TaskGroup和SubDAG进行模块化组织'
}
print("=== DAG设计核心特性 ===")
for char, desc in characteristics.items():
print(f"• {char}: {desc}")
return dag, characteristics
def create_modular_dag(self):
"""创建模块化DAG示例"""
with DAG('modular_data_pipeline',
schedule_interval='@daily',
start_date=datetime(2024, 1, 1),
catchup=False) as dag:
# 使用TaskGroup组织相关任务
with TaskGroup('data_extraction') as extraction_group:
extract_api = PythonOperator(
task_id='extract_from_api',
python_callable=lambda: print("API数据提取")
)
extract_database = PythonOperator(
task_id='extract_from_database',
python_callable=lambda: print("数据库数据提取")
)
with TaskGroup('data_processing') as processing_group:
validate_data = PythonOperator(
task_id='validate_data',
python_callable=lambda: print("数据验证")
)
transform_data = PythonOperator(
task_id='transform_data',
python_callable=lambda: print("数据转换")
)
with TaskGroup('data_loading') as loading_group:
load_warehouse = PythonOperator(
task_id='load_to_warehouse',
python_callable=lambda: print("数据仓库加载")
)
update_metrics = PythonOperator(
task_id='update_business_metrics',
python_callable=lambda: print("业务指标更新")
)
# 定义任务依赖关系
extraction_group >> processing_group >> loading_group
return dag2.1.2 Airflow系统架构图
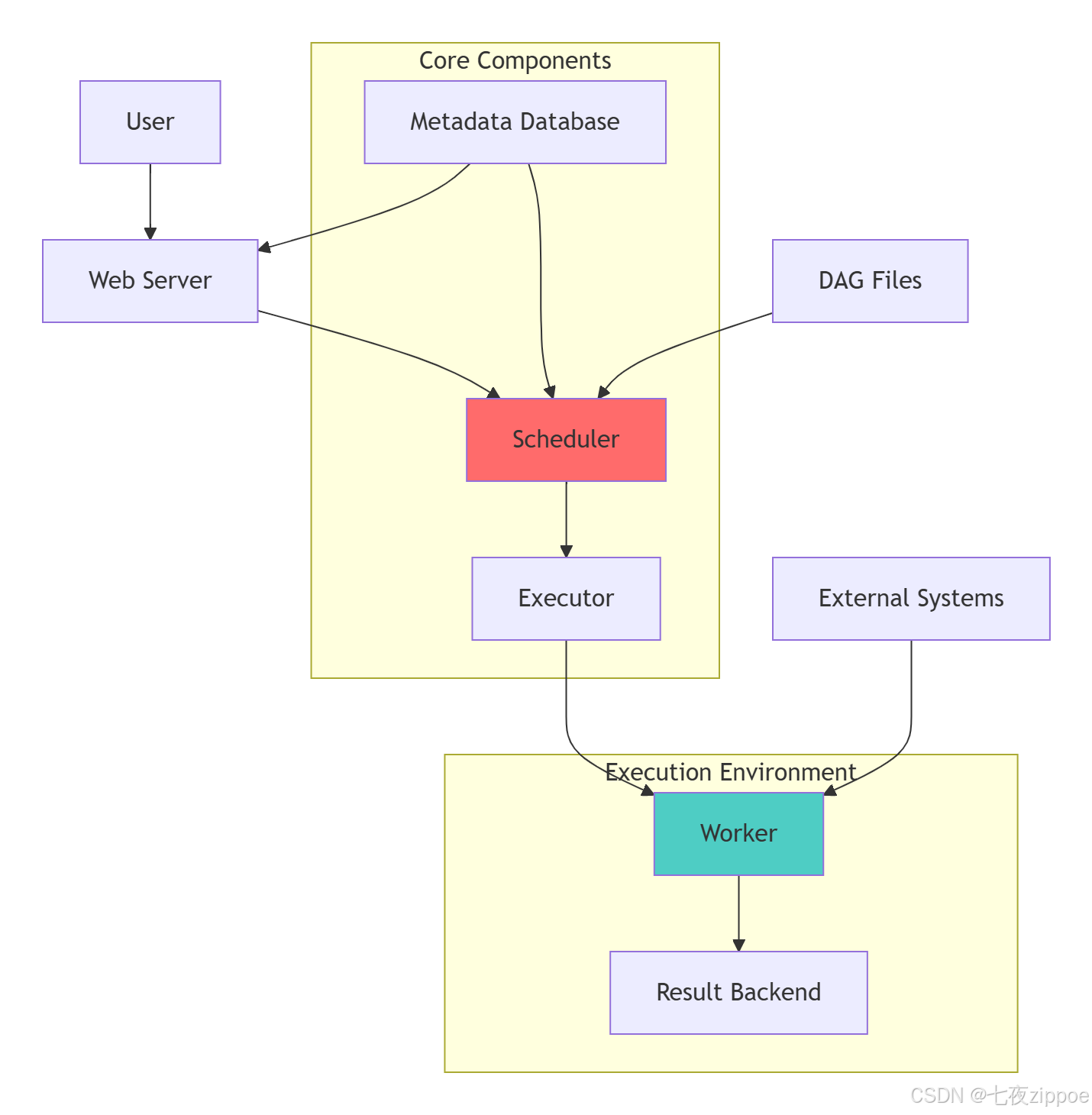
Airflow架构的核心设计理念:
-
元数据驱动:所有状态信息存储在元数据数据库中
-
调度与执行分离:Scheduler负责调度,Executor负责执行
-
可插拔架构:支持多种Executor和插件扩展
-
水平扩展:Worker可以水平扩展处理更多任务
2.2 Operator深度解析与开发实践
2.2.1 内置Operator全面解析
python
# operator_deep_dive.py
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.operators.bash import BashOperator
from airflow.operators.email import EmailOperator
from airflow.providers.http.operators.http import SimpleHttpOperator
from airflow.sensors.filesystem import FileSensor
from datetime import datetime
import pandas as pd
class OperatorExpert:
"""Operator专家指南"""
def demonstrate_core_operators(self):
"""展示核心Operator的使用"""
with DAG('operator_showcase',
start_date=datetime(2024, 1, 1),
schedule_interval=None) as dag:
# 1. PythonOperator - 最灵活的Operator
def process_data(**context):
"""数据处理函数"""
data = context['ti'].xcom_pull(task_ids='extract_task')
df = pd.DataFrame(data)
# 数据处理逻辑
result = df.describe().to_dict()
return result
python_task = PythonOperator(
task_id='process_data',
python_callable=process_data,
provide_context=True,
op_kwargs={'param': 'value'}
)
# 2. BashOperator - 执行Shell命令
bash_task = BashOperator(
task_id='bash_processing',
bash_command='echo "Processing data at {{ ds }}" && python /scripts/process.py',
env={'ENV_VAR': 'value'}
)
# 3. Sensor - 等待条件满足
file_sensor = FileSensor(
task_id='wait_for_file',
filepath='/data/input/{{ ds }}/data.csv',
poke_interval=30, # 30秒检查一次
timeout=60 * 60, # 1小时超时
mode='reschedule'
)
# 4. EmailOperator - 发送通知
email_task = EmailOperator(
task_id='send_report',
to='team@company.com',
subject='Data Pipeline Report {{ ds }}',
html_content='<p>Pipeline completed successfully.</p>'
)
return dag
def create_custom_operator(self):
"""创建自定义Operator示例"""
from airflow.models import BaseOperator
from airflow.utils.decorators import apply_defaults
class DataQualityOperator(BaseOperator):
"""数据质量检查Operator"""
@apply_defaults
def __init__(self,
table_name: str,
quality_checks: list,
tolerance: float = 0.05,
*args, **kwargs):
super().__init__(*args, **kwargs)
self.table_name = table_name
self.quality_checks = quality_checks
self.tolerance = tolerance
def execute(self, context):
"""执行数据质量检查"""
self.log.info(f"开始数据质量检查: {self.table_name}")
check_results = []
for check in self.quality_checks:
result = self._run_quality_check(check)
check_results.append(result)
# 评估检查结果
if not self._evaluate_results(check_results):
raise ValueError(f"数据质量检查失败: {self.table_name}")
self.log.info("数据质量检查通过")
return check_results
def _run_quality_check(self, check_config):
"""运行单个质量检查"""
# 实现具体的检查逻辑
return {'check': check_config['name'], 'passed': True}
def _evaluate_results(self, results):
"""评估检查结果"""
passed_checks = [r for r in results if r['passed']]
pass_rate = len(passed_checks) / len(results)
return pass_rate >= (1 - self.tolerance)
# 使用自定义Operator
with DAG('data_quality_dag',
start_date=datetime(2024, 1, 1)) as dag:
quality_checks = [
{'name': 'null_check', 'column': 'user_id'},
{'name': 'range_check', 'column': 'age', 'min': 0, 'max': 150}
]
dq_task = DataQualityOperator(
task_id='check_user_data_quality',
table_name='users',
quality_checks=quality_checks,
dag=dag
)
return dag, DataQualityOperator2.2.2 Operator执行流程图
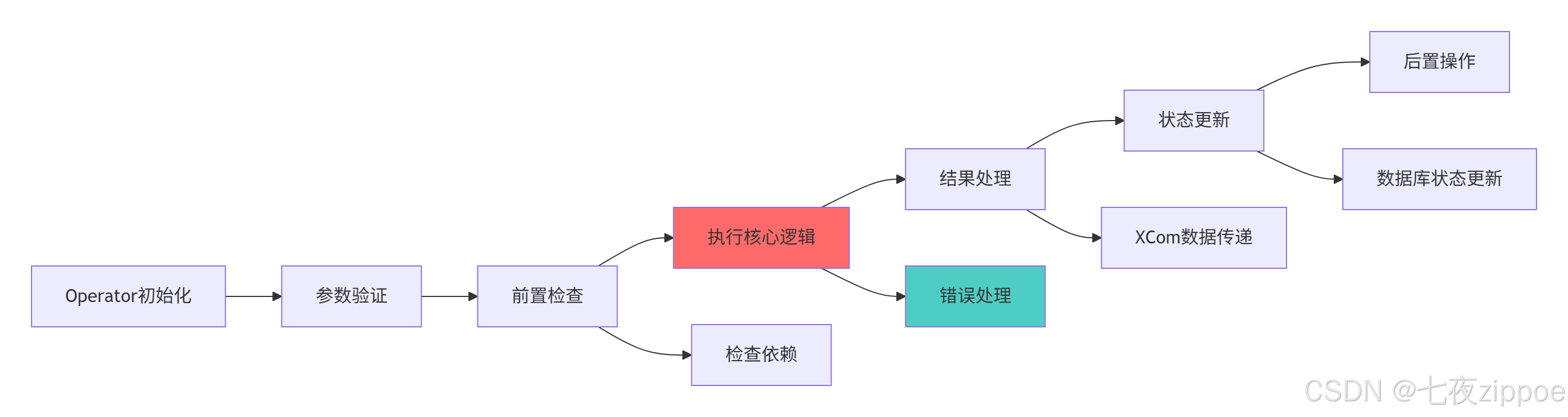
Operator开发的最佳实践:
-
单一职责原则:每个Operator只负责一个明确的任务
-
幂等性设计:多次执行相同操作应该产生相同结果
-
充分的日志记录:提供详细的执行日志用于调试
-
合理的超时设置:避免任务无限期运行
3 任务依赖管理与高级调度技巧
3.1 复杂依赖关系建模
3.1.1 依赖关系模式大全
python
# dependency_patterns.py
from airflow import DAG
from airflow.operators.dummy import DummyOperator
from airflow.operators.python import PythonOperator
from airflow.utils.helpers import chain, cross_downstream
from datetime import datetime
class DependencyPatterns:
"""依赖关系模式大全"""
def create_linear_dependency(self):
"""线性依赖模式"""
with DAG('linear_dependencies',
start_date=datetime(2024, 1, 1)) as dag:
tasks = [DummyOperator(task_id=f'task_{i}', dag=dag)
for i in range(1, 6)]
# 方法1: 使用位移操作符
tasks[0] >> tasks[1] >> tasks[2] >> tasks[3] >> tasks[4]
# 方法2: 使用chain函数
# chain(*tasks)
return dag
def create_branching_dependency(self):
"""分支依赖模式"""
with DAG('branching_dependencies',
start_date=datetime(2024, 1, 1)) as dag:
start = DummyOperator(task_id='start')
# 分支任务
branch_a = DummyOperator(task_id='branch_a')
branch_b = DummyOperator(task_id='branch_b')
branch_c = DummyOperator(task_id='branch_c')
# 合并任务
merge = DummyOperator(task_id='merge',
trigger_rule='one_success')
# 分支依赖
start >> [branch_a, branch_b, branch_c] >> merge
return dag
def create_dynamic_dependency(self):
"""动态依赖模式"""
with DAG('dynamic_dependencies',
start_date=datetime(2024, 1, 1)) as dag:
def create_tasks_based_on_config():
"""根据配置动态创建任务"""
configs = [
{'name': 'process_customers', 'priority': 'high'},
{'name': 'process_orders', 'priority': 'medium'},
{'name': 'process_products', 'priority': 'low'}
]
tasks = {}
for config in configs:
task = PythonOperator(
task_id=config['name'],
python_callable=lambda: print(f"Processing {config['name']}"),
dag=dag
)
tasks[config['name']] = task
# 根据优先级设置依赖
if tasks.get('process_customers'):
tasks['process_customers'] >> tasks.get('process_orders')
return tasks
dynamic_tasks = create_tasks_based_on_config()
return dag
def create_cross_dependency(self):
"""交叉依赖模式"""
with DAG('cross_dependencies',
start_date=datetime(2024, 1, 1)) as dag:
# 创建多个任务组
extract_tasks = [DummyOperator(task_id=f'extract_{i}', dag=dag)
for i in range(1, 4)]
transform_tasks = [DummyOperator(task_id=f'transform_{i}', dag=dag)
for i in range(1, 4)]
load_tasks = [DummyOperator(task_id=f'load_{i}', dag=dag)
for i in range(1, 4)]
# 设置交叉依赖
for extract_task in extract_tasks:
for transform_task in transform_tasks:
extract_task >> transform_task
for transform_task in transform_tasks:
for load_task in load_tasks:
transform_task >> load_task
return dag
def demonstrate_trigger_rules(self):
"""演示各种触发规则"""
with DAG('trigger_rule_demo',
start_date=datetime(2024, 1, 1)) as dag:
# 创建测试任务
task_a = DummyOperator(task_id='task_a')
task_b = DummyOperator(task_id='task_b')
task_c = DummyOperator(task_id='task_c')
# 使用不同触发规则的任务
all_success_task = DummyOperator(
task_id='all_success_task',
trigger_rule='all_success'
)
one_success_task = DummyOperator(
task_id='one_success_task',
trigger_rule='one_success'
)
all_failed_task = DummyOperator(
task_id='all_failed_task',
trigger_rule='all_failed'
)
none_failed_task = DummyOperator(
task_id='none_failed_task',
trigger_rule='none_failed'
)
# 设置依赖关系
[task_a, task_b, task_c] >> all_success_task
[task_a, task_b, task_c] >> one_success_task
[task_a, task_b, task_c] >> all_failed_task
[task_a, task_b, task_c] >> none_failed_task
return dag3.1.2 依赖关系可视化图
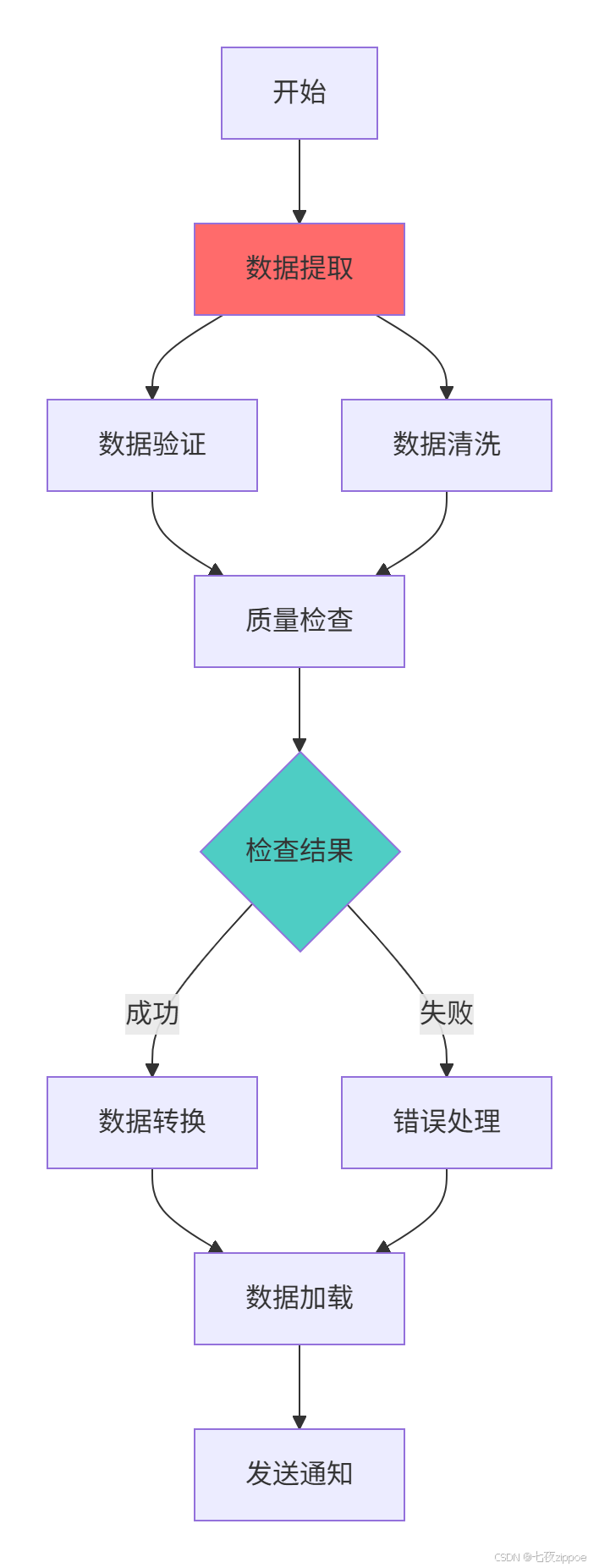
依赖关系管理的核心原则:
-
明确性:依赖关系应该清晰明确,避免隐式依赖
-
可维护性:复杂的依赖应该模块化组织
-
容错性:重要的依赖应该有备选路径
-
可监控性:依赖关系应该易于监控和调试
3.2 高级调度技巧与时间管理
3.2.1 复杂调度策略实现
python
# advanced_scheduling.py
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.sensors.external_task import ExternalTaskSensor
from datetime import datetime, timedelta
import pendulum
class AdvancedScheduling:
"""高级调度技巧"""
def create_time_based_scheduling(self):
"""创建基于时间的复杂调度"""
# 使用pendulum处理复杂时区
local_tz = pendulum.timezone('Asia/Shanghai')
dag = DAG(
'time_based_scheduling',
schedule_interval='0 2 * * 1-5', # 工作日凌晨2点
start_date=datetime(2024, 1, 1, tzinfo=local_tz),
catchup=False,
dagrun_timeout=timedelta(hours=8)
)
def off_peak_processing(**context):
"""在业务低峰期处理数据"""
execution_date = context['execution_date']
# 判断是否是节假日
if self._is_holiday(execution_date):
print("节假日跳过处理")
return "skipped"
else:
print("工作日正常处理")
return "processed"
process_task = PythonOperator(
task_id='off_peak_processing',
python_callable=off_peak_processing,
provide_context=True,
dag=dag
)
return dag
def create_external_dependency(self):
"""创建外部依赖调度"""
dag = DAG('external_dependency_dag',
schedule_interval='0 3 * * *',
start_date=datetime(2024, 1, 1))
# 等待其他DAG完成
wait_for_upstream = ExternalTaskSensor(
task_id='wait_for_upstream_dag',
external_dag_id='upstream_data_pipeline',
external_task_id=None, # 等待整个DAG完成
allowed_states=['success'],
failed_states=['failed', 'skipped'],
execution_delta=timedelta(hours=1), # 等待1小时前的运行
timeout=60 * 60 * 2, # 2小时超时
mode='reschedule',
dag=dag
)
def process_after_upstream(**context):
"""上游完成后处理"""
print("上游任务已完成,开始处理")
return "processing_completed"
process_task = PythonOperator(
task_id='process_after_upstream',
python_callable=process_after_upstream,
dag=dag
)
wait_for_upstream >> process_task
return dag
def create_dataset_aware_scheduling(self):
"""创建基于数据集的调度(Airflow 2.4+)"""
try:
from airflow import Dataset
from airflow.operators.python import PythonOperator
# 定义数据集
raw_data_dataset = Dataset("s3://bucket/raw/data/")
processed_data_dataset = Dataset("s3://bucket/processed/data/")
# 生产者DAG
with DAG('data_producer',
schedule_interval='0 1 * * *',
start_date=datetime(2024, 1, 1)) as producer_dag:
def produce_data(**context):
"""生产数据"""
print("生产数据...")
# 实际的数据生产逻辑
return "data_produced"
produce_task = PythonOperator(
task_id='produce_raw_data',
python_callable=produce_data,
outlets=[raw_data_dataset], # 声明产生的数据集
dag=producer_dag
)
# 消费者DAG
with DAG('data_consumer',
schedule=[raw_data_dataset], # 基于数据集调度
start_date=datetime(2024, 1, 1)) as consumer_dag:
def consume_data(**context):
"""消费数据"""
print("消费数据...")
return "data_consumed"
consume_task = PythonOperator(
task_id='consume_raw_data',
python_callable=consume_data,
inlets=[raw_data_dataset], # 声明依赖的数据集
outlets=[processed_data_dataset],
dag=consumer_dag
)
return producer_dag, consumer_dag
except ImportError:
print("Dataset需要Airflow 2.4+版本")
return None, None
def _is_holiday(self, date):
"""判断是否是节假日(简化版)"""
# 实际的节假日判断应该更复杂
holidays = ['2024-01-01', '2024-02-10'] # 示例日期
return date.strftime('%Y-%m-%d') in holidays4 错误处理与可靠性工程
4.1 全面错误处理策略
4.1.1 多层次错误处理机制
python
# error_handling_strategies.py
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.operators.bash import BashOperator
from airflow.exceptions import AirflowSkipException
from datetime import datetime, timedelta
import random
import time
class ComprehensiveErrorHandling:
"""全面错误处理策略"""
def create_retry_mechanism(self):
"""创建重试机制"""
default_args = {
'retries': 3,
'retry_delay': timedelta(minutes=2),
'retry_exponential_backoff': True,
'max_retry_delay': timedelta(minutes=10),
'on_retry_callback': self._on_retry_callback,
'on_failure_callback': self._on_failure_callback
}
dag = DAG('retry_mechanism_demo',
schedule_interval='@daily',
start_date=datetime(2024, 1, 1),
default_args=default_args)
def unreliable_operation(**context):
"""模拟不可靠的操作"""
if random.random() < 0.3: # 30%失败率
raise Exception("随机操作失败")
print("操作成功完成")
return "success"
retry_task = PythonOperator(
task_id='unreliable_operation',
python_callable=unreliable_operation,
execution_timeout=timedelta(minutes=5),
dag=dag
)
return dag
def create_circuit_breaker(self):
"""创建断路器模式"""
dag = DAG('circuit_breaker_pattern',
schedule_interval='@hourly',
start_date=datetime(2024, 1, 1))
def circuit_breaker_operation(**context):
"""带有断路器模式的操作"""
ti = context['ti']
task_instance = ti.task_id
# 检查最近失败次数
recent_failures = self._get_recent_failures(task_instance)
if recent_failures > 5: # 连续失败5次后开启断路器
print("断路器开启,跳过操作")
raise AirflowSkipException("断路器开启,跳过操作")
try:
# 尝试执行操作
result = self._risky_operation()
self._reset_failure_count(task_instance)
return result
except Exception as e:
self._increment_failure_count(task_instance)
raise e
circuit_task = PythonOperator(
task_id='circuit_breaker_task',
python_callable=circuit_breaker_operation,
provide_context=True,
dag=dag
)
return dag
def create_fallback_strategy(self):
"""创建降级策略"""
dag = DAG('fallback_strategy_demo',
schedule_interval='@daily',
start_date=datetime(2024, 1, 1))
def primary_operation():
"""主操作"""
if random.random() < 0.2:
raise Exception("主操作失败")
return "primary_success"
def fallback_operation():
"""降级操作"""
print("使用降级方案")
return "fallback_success"
def smart_router(**context):
"""智能路由操作"""
try:
try:
result = primary_operation()
return result
except Exception as e:
print(f"主操作失败: {e}")
# 尝试降级方案
return fallback_operation()
except Exception as e:
print(f"所有操作都失败: {e}")
raise
router_task = PythonOperator(
task_id='smart_operation_router',
python_callable=smart_router,
provide_context=True,
dag=dag
)
return dag
def _on_retry_callback(self, context):
"""重试回调函数"""
exception = context['exception']
ti = context['ti']
task_id = ti.task_id
retry_number = context['retry_number']
print(f"任务 {task_id} 第{retry_number}次重试,异常: {exception}")
def _on_failure_callback(self, context):
"""失败回调函数"""
ti = context['ti']
task_id = ti.task_id
# 发送告警通知
self._send_alert(f"任务 {task_id} 执行失败")
def _get_recent_failures(self, task_instance):
"""获取最近失败次数(简化实现)"""
return random.randint(0, 10) # 实际应该从数据库获取
def _increment_failure_count(self, task_instance):
"""增加失败计数"""
pass # 实际实现应该更新数据库
def _reset_failure_count(self, task_instance):
"""重置失败计数"""
pass
def _send_alert(self, message):
"""发送告警"""
print(f"ALERT: {message}")
def _risky_operation(self):
"""有风险的操作"""
if random.random() < 0.4:
raise Exception("操作失败")
return "success"4.1.2 错误处理流程图
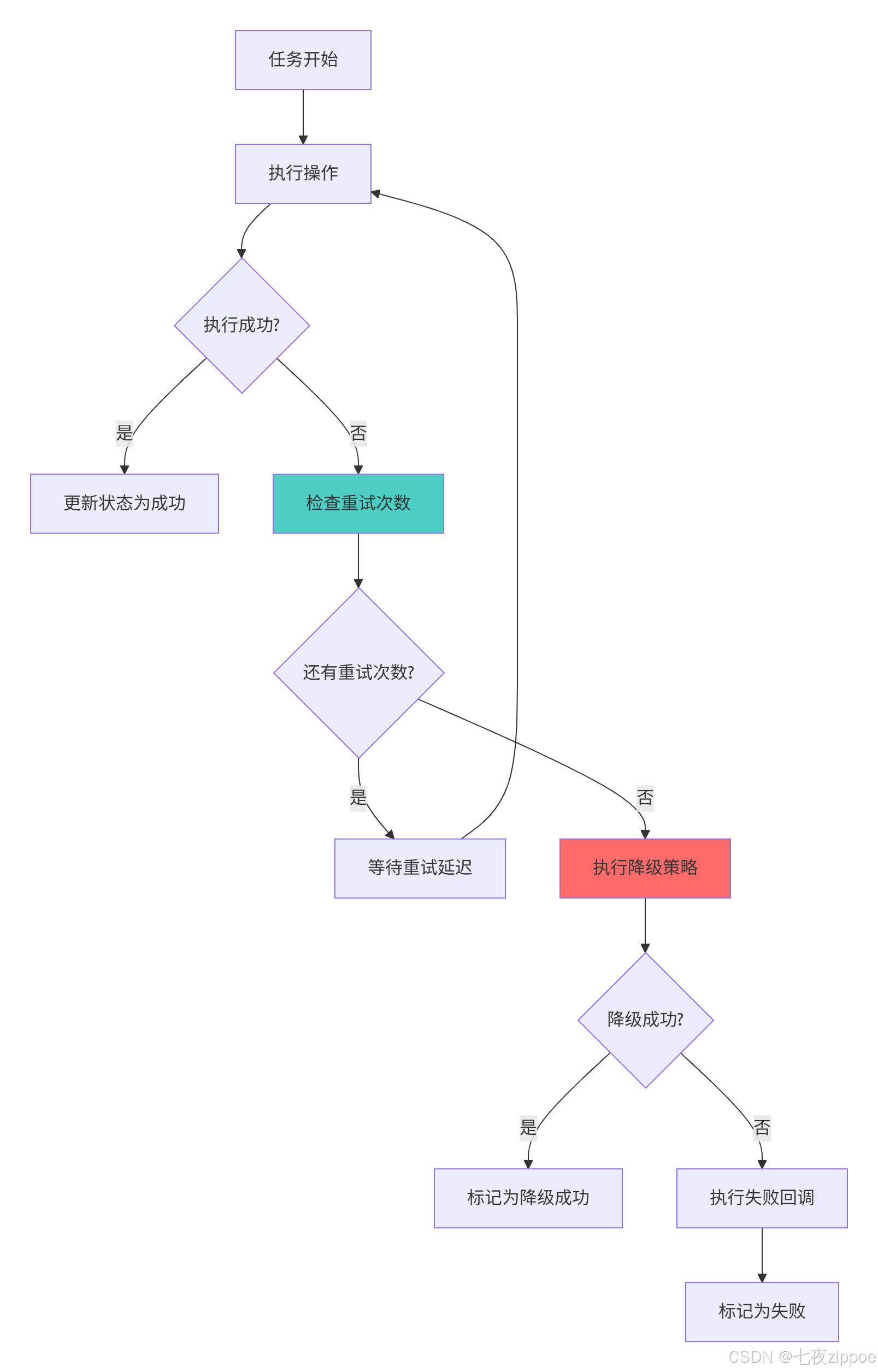
错误处理的最佳实践:
-
防御性编程:预见可能的错误情况并处理
-
graceful degradation:在主要方案失败时提供备选方案
-
详细日志:记录足够的上下文信息用于调试
-
监控告警:重要的错误应该及时通知相关人员
5 企业级实战案例
5.1 实时数据管道完整实现
5.1.1 电商实时数据处理平台
python
# ecommerce_realtime_pipeline.py
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.providers.apache.kafka.operators.produce import ProduceToTopicOperator
from airflow.providers.apache.spark.operators.spark_submit import SparkSubmitOperator
from airflow.sensors.kafka import KafkaTopicSensor
from datetime import datetime, timedelta
import json
import pandas as pd
class EcommerceRealtimePipeline:
"""电商实时数据管道"""
def create_realtime_pipeline(self):
"""创建实时数据处理管道"""
default_args = {
'owner': 'ecommerce-data-team',
'depends_on_past': False,
'start_date': datetime(2024, 1, 1),
'email_on_failure': True,
'email_on_retry': False,
'retries': 2,
'retry_delay': timedelta(minutes=3)
}
dag = DAG(
'ecommerce_realtime_pipeline',
default_args=default_args,
description='电商平台实时数据处理管道',
schedule_interval=timedelta(minutes=5), # 每5分钟运行
catchup=False,
max_active_runs=1,
concurrency=2
)
# 1. 数据采集层
with dag:
# 等待Kafka主题就绪
wait_for_kafka = KafkaTopicSensor(
task_id='wait_for_user_behavior_topic',
kafka_conn_id='kafka_default',
topic='user_behavior_events',
timeout=300,
poke_interval=30,
dag=dag
)
# 数据质量检查
data_quality_check = PythonOperator(
task_id='data_quality_check',
python_callable=self._check_data_quality,
provide_context=True,
dag=dag
)
# 2. 数据处理层
# Spark实时处理
spark_processing = SparkSubmitOperator(
task_id='spark_realtime_processing',
application='/jobs/realtime_processing.py',
conn_id='spark_default',
application_args=[
'--input-topic', 'user_behavior_events',
'--output-topic', 'processed_events',
'--processing-window', '300' # 5分钟窗口
],
executor_cores=2,
executor_memory='4g',
driver_memory='2g',
dag=dag
)
# 实时特征计算
feature_engineering = SparkSubmitOperator(
task_id='real_time_feature_engineering',
application='/jobs/feature_engineering.py',
conn_id='spark_default',
application_args=[
'--input-topic', 'processed_events',
'--output-table', 'real_time_features'
],
dag=dag
)
# 3. 数据服务层
# 更新实时指标
update_realtime_metrics = PythonOperator(
task_id='update_realtime_metrics',
python_callable=self._update_realtime_dashboard,
provide_context=True,
dag=dag
)
# 异常检测告警
anomaly_detection = PythonOperator(
task_id='real_time_anomaly_detection',
python_callable=self._detect_anomalies,
provide_context=True,
dag=dag
)
# 设置依赖关系
(wait_for_kafka
>> data_quality_check
>> spark_processing
>> feature_engineering
>> [update_realtime_metrics, anomaly_detection])
return dag
def _check_data_quality(self, **context):
"""数据质量检查"""
# 实现数据质量检查逻辑
ti = context['ti']
# 模拟检查结果
quality_metrics = {
'record_count': 10000,
'null_count': 23,
'duplicate_count': 5,
'quality_score': 0.98
}
# 如果质量不达标,抛出异常
if quality_metrics['quality_score'] < 0.95:
raise Exception("数据质量不达标")
ti.xcom_push(key='quality_metrics', value=quality_metrics)
return quality_metrics
def _update_realtime_dashboard(self, **context):
"""更新实时仪表板"""
ti = context['ti']
quality_metrics = ti.xcom_pull(task_ids='data_quality_check',
key='quality_metrics')
# 更新仪表板逻辑
print(f"更新仪表板,质量分数: {quality_metrics['quality_score']}")
return "dashboard_updated"
def _detect_anomalies(self, **context):
"""实时异常检测"""
# 实现异常检测逻辑
ti = context['ti']
# 模拟异常检测
anomalies = [
{'metric': 'order_count', 'value': 1500, 'expected': 1000},
{'metric': 'error_rate', 'value': 0.15, 'expected': 0.05}
]
critical_anomalies = [a for a in anomalies if a['value'] > a['expected'] * 1.5]
if critical_anomalies:
# 发送告警
self._send_anomaly_alert(critical_anomalies)
return f"检测到{len(critical_anomalies)}个关键异常"
def _send_anomaly_alert(self, anomalies):
"""发送异常告警"""
message = "检测到数据异常:\n" + "\n".join(
[f"{a['metric']}: {a['value']} (预期: {a['expected']})"
for a in anomalies]
)
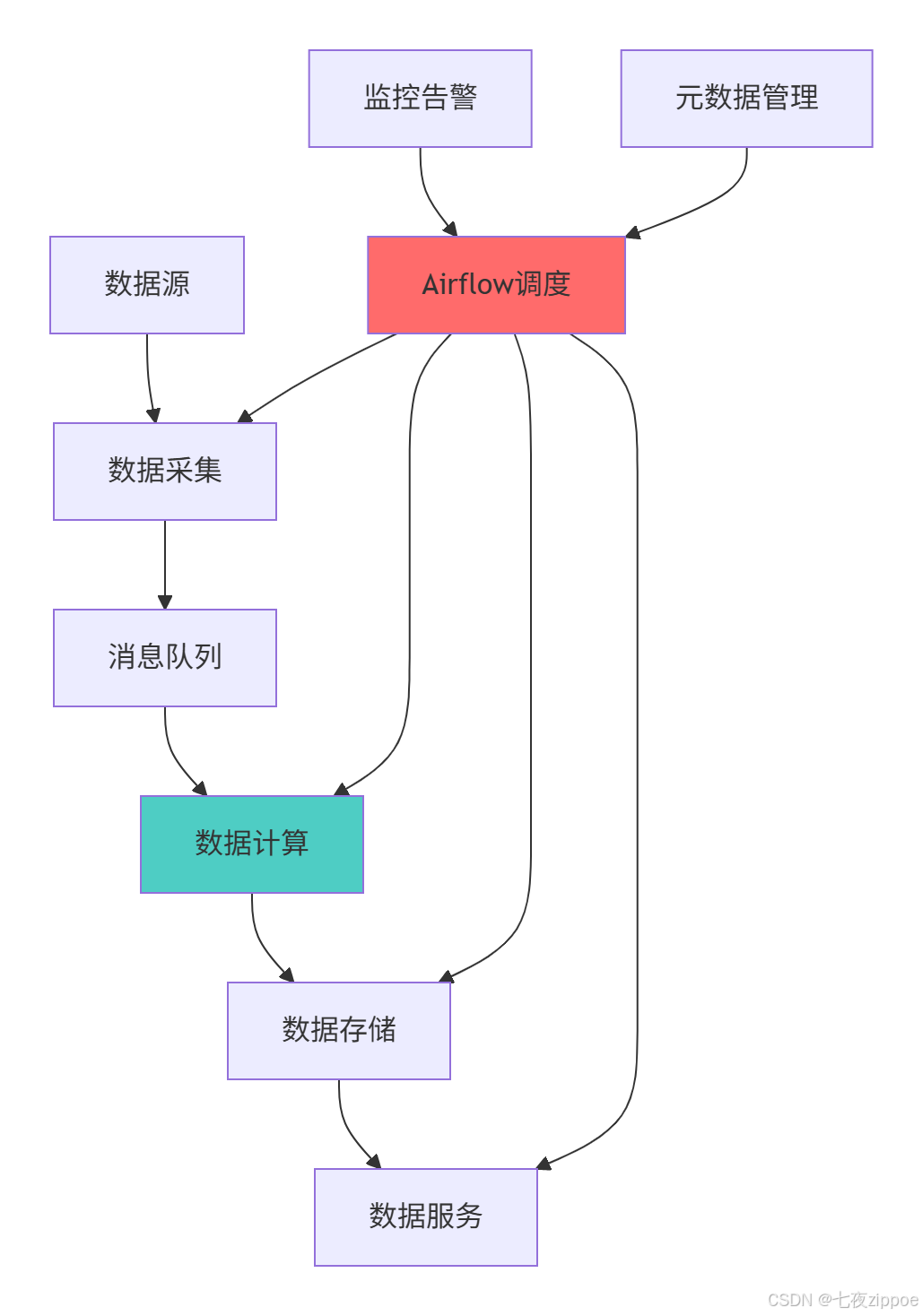
print(f"ALERT: {message}")5.1.2 企业级数据管道架构图
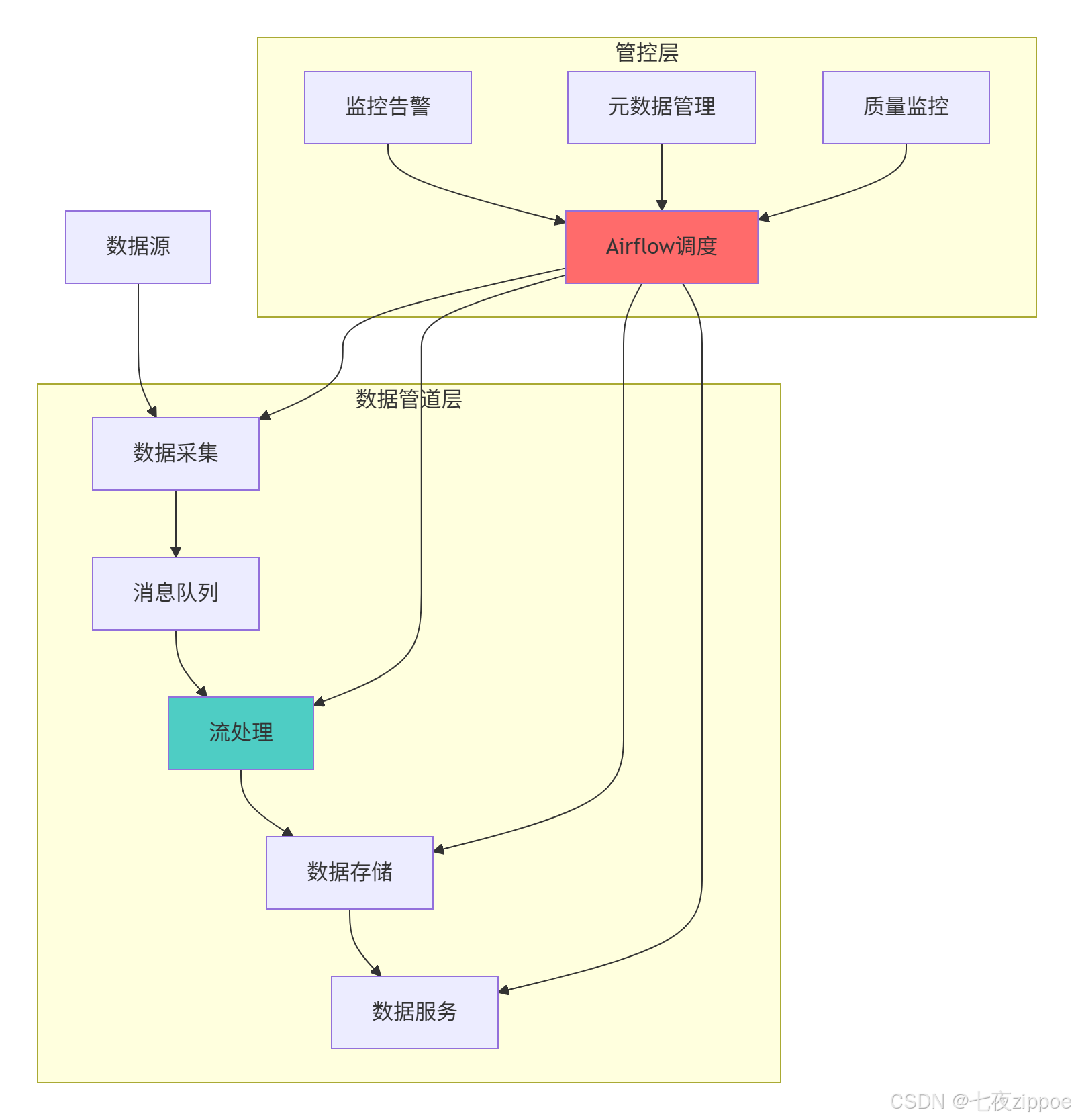
6 性能优化与故障排查
6.1 大规模部署性能优化
6.1.1 高性能配置与调优
python
# performance_optimization.py
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.executors.celery_executor import CeleryExecutor
from airflow.configuration import conf
import time
import psutil
class PerformanceOptimization:
"""性能优化专家指南"""
def optimize_airflow_config(self):
"""优化Airflow配置"""
optimization_config = {
# 调度器优化
'scheduler': {
'min_file_process_interval': 30,
'dag_dir_list_interval': 300,
'parsing_processes': 4,
'scheduler_heartbeat_sec': 5
},
# 执行器优化
'celery': {
'worker_concurrency': 16,
'worker_prefetch_multiplier': 4,
'worker_disable_file_uploads': True
},
# 数据库优化
'database': {
'sql_alchemy_pool_size': 10,
'sql_alchemy_max_overflow': 20,
'sql_alchemy_pool_recycle': 3600
},
# DAG优化
'dag': {
'default_view': 'graph',
'orphan_tasks_check_interval': 300
}
}
print("=== Airflow性能优化配置 ===")
for section, settings in optimization_config.items():
print(f"\n[{section}]")
for key, value in settings.items():
print(f"{key} = {value}")
return optimization_config
def create_optimized_dag(self):
"""创建优化后的DAG示例"""
dag = DAG(
'optimized_data_pipeline',
schedule_interval='@hourly',
start_date=datetime(2024, 1, 1),
catchup=False,
max_active_tasks=10, # 限制并发任务数
concurrency=20,
dagrun_timeout=timedelta(hours=2)
)
def optimized_task(**context):
"""优化后的任务实现"""
start_time = time.time()
# 任务执行前的资源检查
if not self._check_system_resources():
raise Exception("系统资源不足")
# 分批处理数据,避免内存溢出
batch_size = 1000
total_records = 10000
for i in range(0, total_records, batch_size):
batch_data = self._process_batch(i, min(i + batch_size, total_records))
# 及时释放内存
del batch_data
execution_time = time.time() - start_time
print(f"任务执行时间: {execution_time:.2f}秒")
return f"processed_{total_records}_records"
optimized_task = PythonOperator(
task_id='optimized_processing',
python_callable=optimized_task,
provide_context=True,
execution_timeout=timedelta(minutes=30),
pool='high_memory_pool', # 使用资源池
priority_weight=2, # 提高优先级
dag=dag
)
return dag
def monitor_performance_metrics(self):
"""监控性能指标"""
dag = DAG('performance_monitoring',
schedule_interval='@hourly',
start_date=datetime(2024, 1, 1))
def collect_performance_metrics(**context):
"""收集性能指标"""
metrics = {
'cpu_percent': psutil.cpu_percent(interval=1),
'memory_percent': psutil.virtual_memory().percent,
'disk_usage': psutil.disk_usage('/').percent,
'active_tasks': self._get_active_task_count(),
'dag_run_duration': self._get_dag_run_duration()
}
# 检查性能瓶颈
bottlenecks = self._identify_bottlenecks(metrics)
if bottlenecks:
print(f"发现性能瓶颈: {bottlenecks}")
self._trigger_optimization(bottlenecks)
return metrics
monitor_task = PythonOperator(
task_id='collect_performance_metrics',
python_callable=collect_performance_metrics,
provide_context=True,
dag=dag
)
return dag
def _check_system_resources(self):
"""检查系统资源"""
cpu_usage = psutil.cpu_percent(interval=1)
memory_usage = psutil.virtual_memory().percent
return cpu_usage < 80 and memory_usage < 85
def _process_batch(self, start, end):
"""处理数据批次"""
# 模拟数据处理
return list(range(start, end))
def _get_active_task_count(self):
"""获取活跃任务数"""
return len([1 for _ in range(10)]) # 模拟实现
def _get_dag_run_duration(self):
"""获取DAG运行时长"""
return 3600 # 模拟实现
def _identify_bottlenecks(self, metrics):
"""识别性能瓶颈"""
bottlenecks = []
if metrics['cpu_percent'] > 80:
bottlenecks.append('CPU使用率过高')
if metrics['memory_percent'] > 85:
bottlenecks.append('内存使用率过高')
if metrics['active_tasks'] > 50:
bottlenecks.append('并发任务过多')
return bottlenecks
def _trigger_optimization(self, bottlenecks):
"""触发优化操作"""
print(f"针对 {bottlenecks} 进行优化")6.2 故障排查指南
6.2.1 常见问题与解决方案
python
# troubleshooting_guide.py
import logging
from airflow.exceptions import AirflowException
class TroubleshootingGuide:
"""故障排查专家指南"""
def common_issues_solutions(self):
"""常见问题与解决方案"""
issues = {
'任务依赖错误': {
'症状': '任务执行顺序错误或循环依赖',
'原因': 'DAG定义中的依赖关系设置错误',
'解决方案': [
'使用Airflow UI可视化检查依赖关系',
'检查是否有循环依赖',
'验证trigger_rule设置是否正确'
],
'预防措施': '使用单元测试验证DAG结构'
},
'资源不足': {
'症状': '任务执行缓慢或频繁失败',
'原因': '系统资源(CPU、内存、磁盘)不足',
'解决方案': [
'增加Worker节点',
'优化任务资源使用',
'使用资源池限制并发'
],
'预防措施': '实施资源监控和自动扩缩容'
},
'数据库连接问题': {
'症状': '调度器或Executor报数据库连接错误',
'原因': '数据库连接数过多或网络问题',
'解决方案': [
'增加数据库连接池大小',
'检查网络连接',
'优化数据库查询'
],
'预防措施': '使用连接池和定期维护数据库'
}
}
print("=== 常见故障排查指南 ===")
for issue, details in issues.items():
print(f"\n📌 {issue}")
print(f" 症状: {details['症状']}")
print(f" 原因: {details['原因']}")
print(f" 解决方案: {', '.join(details['解决方案'])}")
return issues
def create_diagnostic_dag(self):
"""创建诊断DAG"""
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
dag = DAG('system_diagnostic',
schedule_interval='@daily',
start_date=datetime(2024, 1, 1))
def check_system_health(**context):
"""检查系统健康状态"""
checks = {
'database_connection': self._check_database_connection(),
'worker_availability': self._check_worker_availability(),
'disk_space': self._check_disk_space(),
'network_connectivity': self._check_network_connectivity()
}
# 生成健康报告
health_score = sum(1 for check in checks.values() if check) / len(checks)
if health_score < 0.8:
raise AirflowException(f"系统健康度低: {health_score}")
return checks
diagnostic_task = PythonOperator(
task_id='system_health_check',
python_callable=check_system_health,
provide_context=True,
dag=dag
)
return dag
def _check_database_connection(self):
"""检查数据库连接"""
try:
# 实际实现应该测试数据库连接
return True
except Exception as e:
logging.error(f"数据库连接检查失败: {e}")
return False
def _check_worker_availability(self):
"""检查Worker可用性"""
# 实现Worker健康检查
return True
def _check_disk_space(self):
"""检查磁盘空间"""
# 实现磁盘空间检查
return True
def _check_network_connectivity(self):
"""检查网络连接"""
# 实现网络连接检查
return True官方文档与参考资源
-
Apache Airflow官方文档- 官方完整文档
-
Airflow GitHub仓库- 源码和Issue跟踪
-
Airflow运维最佳实践- 生产环境最佳实践
-
Airflow社区指南- 社区贡献指南
通过本文的完整学习,您应该已经掌握了Apache Airflow从基础概念到企业级实战的全套技术栈。Airflow作为数据工程的核心调度系统,其价值在于提供可靠、可维护、可扩展的工作流管理能力。希望本文能帮助您构建更加健壮和高效的数据管道!