《程序员自我修养》读书总结(三)
Author: Once Day Date: 2026年2月5日
一位热衷于Linux学习和开发的菜鸟,试图谱写一场冒险之旅,也许终点只是一场白日梦...
漫漫长路,有人对你微笑过嘛...
全系列文章可参考专栏: 书籍阅读_Once-Day的博客-CSDN博客
参考文章:
文章目录
- 《程序员自我修养》读书总结(三)
-
-
-
- [3. 目标文件](#3. 目标文件)
-
- [3.1 目标文件格式](#3.1 目标文件格式)
- [3.2 ELF文件](#3.2 ELF文件)
- [3.3 ELF文件实例](#3.3 ELF文件实例)
- [3.4 ELF文件组成](#3.4 ELF文件组成)
- [3.5 ELF文件头结构](#3.5 ELF文件头结构)
- [3.6 ELF文件段结构](#3.6 ELF文件段结构)
- [3.7 符号名称](#3.7 符号名称)
- [3.8 符号修饰](#3.8 符号修饰)
- [3.9 强弱符号](#3.9 强弱符号)
- [3.10 调试信息](#3.10 调试信息)
-
-
3. 目标文件
3.1 目标文件格式
从程序构建流程来看,目标文件与可执行文件并非两种截然不同的产物,而是同一套二进制格式在不同阶段的表现形式。Windows 下的 PE 与 Linux 下的 ELF 虽然在细节上存在差异,但本质上都继承自 COFF 的设计思想:以段或节为基本组织单位,描述代码、数据、符号和重定位信息。这种统一的结构使得编译、链接与加载可以围绕同一套抽象模型展开。
在实际实现中,静态链接库、动态链接库以及最终的可执行文件在格式层面高度一致。以 ELF 为例,.o 文件、.a 中的成员、.so 以及最终生成的可执行文件,都遵循相同的 ELF 头和节表机制,区别仅在于是否包含重定位信息、程序头表以及加载属性。从文件语义上看,常见的目标文件可以划分为几类,其核心差异体现在"是否已经完成地址绑定"以及"是否可被加载执行"两个维度上:
| 文件类型 | 说明 | 实例 |
|---|---|---|
| 可重定位文件 | 尚未完成地址分配,包含符号表与重定位信息,需链接器进一步处理 | foo.o |
| 可执行文件 | 地址已确定,可被操作系统加载并直接运行 | a.out、app.exe |
| 共享目标文件 | 供多个进程共享,运行期由动态链接器完成重定位 | libc.so、kernel32.dll |
| 核心转储文件 | 进程异常时的内存快照,用于调试和分析 | coredump |
bash
ubuntu->tool:$ file test.o
test.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped
ubuntu->tool:$ file test.so
test.so: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, BuildID[sha1]=814b12cbcf2967a44cd7c3a6ae65aead93e48260, not stripped
ubuntu->tool:$ file test.out
test.out: ELF 64-bit LSB pie executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=c7b5526705e557396ddc98360fa24077a1705410, for GNU/Linux 3.2.0, not stripped从历史演进角度看,早期的程序格式往往紧耦合于具体硬件与操作系统,缺乏统一规范。随着 Unix 生态的发展,a.out 等早期格式逐渐暴露出扩展性不足的问题,COFF 随之引入,首次系统性地将符号、段和重定位信息纳入统一描述。ELF 在此基础上进一步增强了对动态链接、多架构和调试信息的支持,而 PE 则结合 Windows 的加载机制进行了定制化扩展。
统一的文件结构降低了编译器、链接器和调试器之间的协作成本,也为后续引入动态链接、位置无关代码和地址空间随机化等机制奠定了基础。
3.2 ELF文件
现代目标文件通常需要容纳多种信息,例如机器指令代码、全局与静态数据、符号表、调试信息以及字符串常量。这些内容并不是杂乱无章地堆放,而是通过节(section)或段(segment)进行组织。节更偏向于链接视角,强调逻辑属性;段更偏向于装载视角,强调运行期的内存映射关系。这种分层组织方式,使编译器、链接器与加载器可以各司其职,又能在同一文件结构下协同工作。
代码段与数据段的分离是最典型、也最重要的设计之一。
- 权限保护,代码段通常被标记为只读且可执行,而数据段则是可读写但不可执行,这种权限区分提供了基础的安全保障。
- 缓存友好,指令与数据的访问模式差异明显,分段有利于 CPU 指令缓存与数据缓存各自发挥作用,减少无效缓存行的装入。
- 节约空间,按属性划分内容还能让加载器更精确地映射内存页,避免不必要的空间浪费。
在数据相关的节中,bss 段是一个经常被提及却容易被误解的存在。bss 的全称是 "Block Started by Symbol",这一命名可以追溯到 Dennis Ritchie 所描述的早期历史:它最初是 IBM 704 系列机器上汇编器中的一种伪指令,用于声明一块仅以符号标识的存储区域,而不需要在目标文件中真实地写入这些内容。这种"只记录大小、不存实际数据"的思想,被 Unix 目标文件格式完整继承下来。
参考链接:http://www.faqs.org/faqs/unix-faq/faq/part1/section-3.html
从实现角度看,bss 段的本质是"运行期再分配"。加载器在装载程序时,根据 bss 的大小信息为其分配一段内存,并保证初值为 0,但这些 0 并不会出现在磁盘上的目标文件中。正因如此,bss 段几乎不占用文件空间,却可以在进程虚拟地址空间中占据相当大的比例,这对于包含大量全局数组或缓冲区的程序尤为重要。
编译器还会进一步利用这一机制进行优化。按照 C/C++ 语言规则,未显式初始化的全局或静态变量其初值应为 0,因此即便程序员写下了"初始化为 0"的代码,编译器也往往会将其视为未初始化变量,统一放入 bss 段。例如:
c
int a; // 放入 bss
int b = 0; // 通常也会被优化进 bss
int c = 42; // 放入 data 段这种处理方式在语义上完全等价,却显著减少了目标文件中需要存储的数据量。由此可以看到,节与段的划分不仅是格式设计问题,更深刻地影响着程序的空间占用、加载效率以及运行期行为。
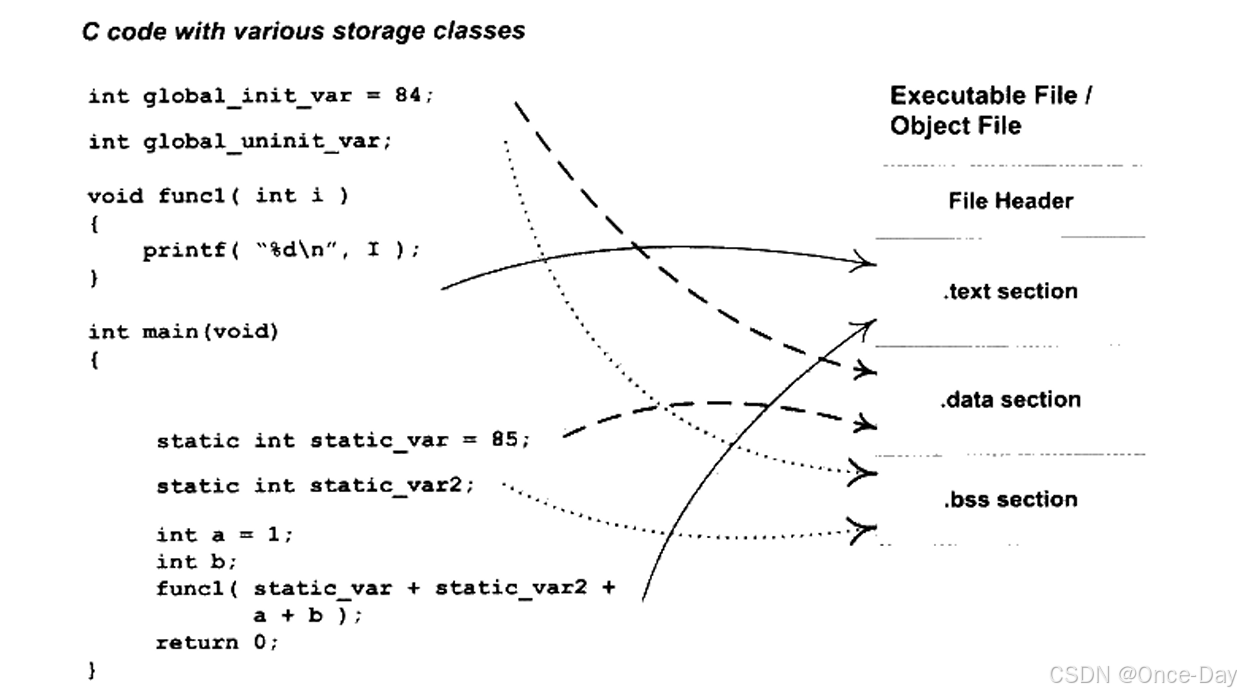
3.3 ELF文件实例
size 与 objdump 是理解目标文件结构最直接的工具,它们从不同抽象层面揭示了 ELF 文件的空间布局与语义划分。size 更关注"程序占用多少空间",而 objdump -h 则展示"这些空间分别由哪些段构成"。
size 的输出反映了目标文件中三类经典段的规模:.text、.data 和 .bss。其中 .text 表示机器指令,占用 222 字节;.data 是已初始化的全局或静态变量,占用 8 字节;.bss 则是未初始化的全局或静态变量,同样占用 8 字节,但它并不实际存储在文件中。dec 是前三者的十进制总和,hex 则是对应的十六进制表示,用于快速评估模块体量。
bash
ubuntu->ProgSelf:$ size simple_section.o
text data bss dec hex filename
222 8 8 238 ee simple_section.o相比之下,objdump -h 揭示了 ELF 段表的完整视图。每一行描述一个 section,其 Size 表示段长度,VMA 与 LMA 在可重定位目标文件中通常为 0,而 File off 则给出了段在文件中的偏移。对齐属性 Algn 直接影响链接与加载时的内存布局,尤其是 .data、.bss 这类对齐敏感的段,往往与硬件访问效率密切相关。
bash
ubuntu->ProgSelf:$ objdump -h simple_section.o
simple_section.o: file format elf64-x86-64
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000062 0000000000000000 0000000000000000 00000040 2**0
CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE
1 .data 00000008 0000000000000000 0000000000000000 000000a4 2**2
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000008 0000000000000000 0000000000000000 000000ac 2**2
ALLOC
3 .rodata 00000004 0000000000000000 0000000000000000 000000ac 2**0
CONTENTS, ALLOC, LOAD, READONLY, DATA
4 .comment 0000002c 0000000000000000 0000000000000000 000000b0 2**0
CONTENTS, READONLY
5 .note.GNU-stack 00000000 0000000000000000 0000000000000000 000000dc 2**0
CONTENTS, READONLY
6 .note.gnu.property 00000020 0000000000000000 0000000000000000 000000e0 2**3
CONTENTS, ALLOC, LOAD, READONLY, DATA
7 .eh_frame 00000058 0000000000000000 0000000000000000 00000100 2**3
CONTENTS, ALLOC, LOAD, RELOC, READONLY, DATA从段类型看,.text、.data、.bss 是最核心的执行相关段,而 .rodata 用于存放只读常量字符串等数据,体现了"数据与权限分离"的设计原则。.comment、.note.* 等段并不参与程序执行,它们更多用于编译器标识、ABI 属性或安全增强信息。.eh_frame 则为异常处理和栈回溯提供元数据,是现代 C++ 程序不可或缺的一部分。
在可重定位目标文件中,重定位表是连接编译与链接阶段的关键纽带。.rel.text 表示 .text 段对应的重定位信息,其中记录了哪些指令中的地址或符号引用需要在链接时修正。类似地,.data、.rodata 等段也可能拥有各自的重定位表。链接器正是依赖这些表项,将符号引用转换为最终的地址,从而生成可执行文件或共享对象。
3.4 ELF文件组成
ELF 文件的整体结构由 ELF 头部、程序头表、段表以及各类 section 共同组成,其中 ELF 头部负责描述文件的基本属性与索引信息,而真正承载代码与数据语义的,则是后续的各类段。
| 段名 | 主要作用 |
|---|---|
.text |
程序机器指令代码段 |
.data |
已初始化的全局/静态数据 |
.rodata |
只读常量数据 |
.bss |
未初始化数据,运行期分配 |
.comment |
编译器与构建信息 |
.debug |
调试符号与调试信息 |
.dynamic |
动态链接元数据 |
.hash |
动态符号哈希表 |
.line |
源码行号映射 |
.note |
ABI 或平台注记 |
.strtab |
字符串表 |
.symtab |
符号表 |
.shstrtab |
段表字符串表 |
.plt |
过程链接表 |
.got |
全局偏移表 |
.init |
程序初始化代码 |
.fini |
程序终止清理代码 |
除了执行必需的段,ELF 还包含大量辅助性 section。例如 .comment 记录编译器信息,.note 用于 ABI、平台或安全相关的注记,.debug、.line 为调试器提供源码映射能力。
与动态链接相关的段同样至关重要。.dynamic 保存动态链接器所需的元数据,.hash 或 .gnu.hash 加速符号查找,.plt 与 .got 共同支撑延迟绑定机制,使函数地址在运行期解析成为可能。.init 与 .fini 则用于程序启动和退出时的初始化与清理逻辑,尤其在 C++ 全局对象管理中不可或缺。
符号与字符串相关的段为链接器提供"名字到地址"的映射基础。.symtab 保存完整符号表,.strtab 存放符号名字符串,.shstrtab 则专门用于段表中各 section 名称的解析。这些段通常不会被加载进内存,但缺失它们将直接影响链接与调试能力。
系统保留段通常以 . 作为前缀,这是 ELF 规范约定的命名空间,用于避免与用户自定义段冲突。编译器与链接器允许通过脚本或属性自定义段名,只要遵循对齐与属性规则即可,这为嵌入式系统或特殊运行时环境提供了高度灵活性。
3.5 ELF文件头结构
ELF 文件头是解析整个 ELF 文件的"总索引",它为加载器和工具链提供了文件类型、体系结构、入口地址以及程序头表和段表的位置等关键信息。
下面是一个ELF文件头部实例信息:
ubuntu->ProgSelf:$ readelf -h simple_section.out
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: DYN (Position-Independent Executable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x1060
Start of program headers: 64 (bytes into file)
Start of section headers: 14184 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 13
Size of section headers: 64 (bytes)
Number of section headers: 31
Section header string table index: 30下面是 ELF 头结构体定义:
c
typedef struct
{
unsigned char e_ident[EI_NIDENT]; /* Magic number and other info */
Elf64_Half e_type; /* Object file type */
Elf64_Half e_machine; /* Architecture */
Elf64_Word e_version; /* Object file version */
Elf64_Addr e_entry; /* Entry point virtual address */
Elf64_Off e_phoff; /* Program header table file offset */
Elf64_Off e_shoff; /* Section header table file offset */
Elf64_Word e_flags; /* Processor-specific flags */
Elf64_Half e_ehsize; /* ELF header size in bytes */
Elf64_Half e_phentsize; /* Program header table entry size */
Elf64_Half e_phnum; /* Program header table entry count */
Elf64_Half e_shentsize; /* Section header table entry size */
Elf64_Half e_shnum; /* Section header table entry count */
Elf64_Half e_shstrndx; /* Section header string table index */
} Elf64_Ehdr;ELF 文件头中各字段的语义、作用及其在链接与加载阶段的含义说明:
| 结构体字段 | readelf 显示项 | 示例值 | 含义与作用说明 |
|---|---|---|---|
e_ident |
Magic / Class / Data / OS/ABI 等 | 7f 45 4c 46 ... |
ELF 文件的身份标识区,前 4 字节是固定魔数 0x7f 'E' 'L' 'F',用于快速识别文件类型;其余字节描述 ELF 是 32/64 位、大小端、ABI 类型等,是解析整个文件的前提 |
e_type |
Type | DYN |
描述 ELF 文件的总体用途,如 REL(可重定位文件)、EXEC(可执行文件)、DYN(共享对象或 PIE);该示例为 PIE,可被加载到任意虚拟地址 |
e_machine |
Machine | X86-64 |
指定目标指令集架构,决定了指令编码、重定位类型和调用约定,是链接器和加载器正确工作的基础 |
e_version |
Version | 0x1 |
ELF 规范版本号,当前固定为 EV_CURRENT,主要用于向后兼容和格式校验 |
e_entry |
Entry point address | 0x1060 |
程序入口虚拟地址,加载完成后控制权最初转移的位置;对于 PIE,该地址是相对基址的偏移 |
e_phoff |
Start of program headers | 64 |
程序头表在文件中的偏移位置,加载器正是通过该表决定哪些内容需要映射到进程地址空间 |
e_shoff |
Start of section headers | 14184 |
节头表在文件中的偏移位置,主要供链接器、调试器和分析工具使用,运行时并非必须 |
e_flags |
Flags | 0x0 |
与具体处理器相关的标志位,在 x86-64 上通常为 0,但在某些架构(如 ARM)中具有实际意义 |
e_ehsize |
Size of this header | 64 |
ELF 文件头自身大小,必须与当前 ELF 类别(32/64 位)对应,常用于一致性检查 |
e_phentsize |
Size of program headers | 56 |
单个程序头表项的大小,加载器通过该值遍历所有 Program Header |
e_phnum |
Number of program headers | 13 |
程序头表项数量,直接决定了可加载段和辅助段的数量 |
e_shentsize |
Size of section headers | 64 |
单个节头表项的大小,供工具按顺序解析各个 Section |
e_shnum |
Number of section headers | 31 |
节的数量,反映了目标文件在链接层面的逻辑拆分情况 |
e_shstrndx |
Section header string table index | 30 |
指向节名字符串表的索引,使每个 Section 能通过名字而非索引被识别 |
ELF 头部并不承载具体代码或数据,而是作为"索引与元信息中心",将文件的物理布局、逻辑结构以及运行时加载方式统一描述出来,使得链接器、加载器和调试工具可以各取所需、协同工作。
3.6 ELF文件段结构
段表主要服务于链接器、调试器等工具,其设计更偏向"逻辑组织",而非直接的加载描述。
下面是一个段表实例信息:
bash
ubuntu->ProgSelf:$ readelf -S simple_section.o
There are 14 section headers, starting at offset 0x418:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .text PROGBITS 0000000000000000 00000040
0000000000000062 0000000000000000 AX 0 0 1
[ 2] .rela.text RELA 0000000000000000 000002f8
0000000000000078 0000000000000018 I 11 1 8
[ 3] .data PROGBITS 0000000000000000 000000a4
0000000000000008 0000000000000000 WA 0 0 4
[ 4] .bss NOBITS 0000000000000000 000000ac
0000000000000008 0000000000000000 WA 0 0 4
[ 5] .rodata PROGBITS 0000000000000000 000000ac
0000000000000004 0000000000000000 A 0 0 1
[ 6] .comment PROGBITS 0000000000000000 000000b0
000000000000002c 0000000000000001 MS 0 0 1
[ 7] .note.GNU-stack PROGBITS 0000000000000000 000000dc
0000000000000000 0000000000000000 0 0 1
[ 8] .note.gnu.pr[...] NOTE 0000000000000000 000000e0
0000000000000020 0000000000000000 A 0 0 8
[ 9] .eh_frame PROGBITS 0000000000000000 00000100
0000000000000058 0000000000000000 A 0 0 8
[10] .rela.eh_frame RELA 0000000000000000 00000370
0000000000000030 0000000000000018 I 11 9 8
[11] .symtab SYMTAB 0000000000000000 00000158
0000000000000138 0000000000000018 12 8 8
[12] .strtab STRTAB 0000000000000000 00000290
0000000000000061 0000000000000000 0 0 1
[13] .shstrtab STRTAB 0000000000000000 000003a0
0000000000000074 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
D (mbind), l (large), p (processor specific)下面是 Section 结构体定义:
c
typedef struct
{
Elf64_Word sh_name; /* Section name (string tbl index) */
Elf64_Word sh_type; /* Section type */
Elf64_Xword sh_flags; /* Section flags */
Elf64_Addr sh_addr; /* Section virtual addr at execution */
Elf64_Off sh_offset; /* Section file offset */
Elf64_Xword sh_size; /* Section size in bytes */
Elf64_Word sh_link; /* Link to another section */
Elf64_Word sh_info; /* Additional section information */
Elf64_Xword sh_addralign; /* Section alignment */
Elf64_Xword sh_entsize; /* Entry size if section holds table */
} Elf64_Shdr;ELF Section Header 中各字段的语义及其在编译、链接和运行期的角色的系统性说明:
| 结构体字段 | readelf 显示列 | 含义说明 |
|---|---|---|
sh_name |
Name | 段名在 .shstrtab 中的字符串偏移索引,真正的名字并不存放在段头里,而是通过该索引间接引用,体现 ELF 去冗余、集中管理字符串的设计 |
sh_type |
Type | 段的内容类型,如 PROGBITS 表示普通数据、NOBITS 表示仅占用内存不占文件空间(如 .bss)、SYMTAB 和 STRTAB 分别表示符号表和字符串表,链接器依据该字段决定处理逻辑 |
sh_flags |
Flags | 描述段在运行期的属性,如 A 表示需要分配到进程地址空间,X 表示可执行,W 表示可写;这些标志会在链接阶段被映射到 Program Header 的权限位 |
sh_addr |
Address | 段在进程虚拟地址空间中的地址,仅在可执行文件或共享对象中有意义;在 .o 可重定位文件中通常为 0,由链接器最终决定 |
sh_offset |
Offset | 段内容在 ELF 文件中的偏移位置,工具通过该值从文件中定位段数据;对于 NOBITS 类型,该值只是逻辑占位 |
sh_size |
Size | 段的字节大小,.bss 等 NOBITS 段虽然文件中无实体数据,但该字段仍描述其运行期所需内存规模 |
sh_link |
Link | 指向另一个 Section 的索引,用于建立段之间的语义关联,例如重定位段指向其符号表,符号表再指向字符串表 |
sh_info |
Info | 补充信息字段,含义依赖于段类型;例如在 RELA 段中,它指明该重定位作用于哪个目标段 |
sh_addralign |
Align | 段在内存中的对齐要求,通常与 CPU 访问效率或 ABI 约束相关,链接器在布局地址时必须满足该对齐 |
sh_entsize |
EntSize | 若段包含定长表项(如符号表、重定位表),该字段给出单个表项大小;普通数据段则为 0 |
Section Header 更像是"编译与链接视角"的索引体系,它强调语义划分和工具协作,而非直接描述加载行为。这种分层使 ELF 能同时满足静态分析、重定位和运行期执行等多种需求。
3.7 符号名称
在 ELF 体系中,函数和变量被统一抽象为符号,符号名本质上是链接器与加载器识别程序实体的"逻辑标识"。编译阶段,源代码中的函数名、全局变量名会被记录为符号;链接阶段,符号成为不同目标文件之间建立引用关系的关键媒介。正是通过符号解析与重定位,离散的目标文件才能被组织成一个逻辑完整、地址连续的程序映像。
符号并不等价于"有名字的代码或数据"。从实现角度看,符号只是描述某个地址区间及其属性的一组元信息,包括位置、大小、绑定方式和可见性。局部变量通常不会进入符号表,而 static 修饰的函数或变量会生成局部符号,仅在当前目标文件内有效。
下面是Elf64_Sym 结构体定义:
c
typedef struct
{
Elf64_Word st_name; /* Symbol name (string tbl index) */
unsigned char st_info; /* Symbol type and binding */
unsigned char st_other; /* Symbol visibility */
Elf64_Section st_shndx; /* Section index */
Elf64_Addr st_value; /* Symbol value */
Elf64_Xword st_size; /* Symbol size */
} Elf64_Sym;Elf64_Sym 结构体字段含义:
| 字段 | readelf 列 | 含义说明 |
|---|---|---|
st_name |
Name | 符号名在字符串表 .strtab 中的偏移索引,本身不直接保存字符串,通过该索引间接取得符号名 |
st_info |
Type / Bind | 高 4 位表示绑定属性(LOCAL、GLOBAL、WEAK),低 4 位表示符号类型(FUNC、OBJECT、SECTION、NOTYPE 等) |
st_other |
Vis | 符号可见性,常见为 DEFAULT,也可限制为 HIDDEN 等,影响动态链接时符号是否可被外部引用 |
st_shndx |
Ndx | 符号所在段的索引,UND 表示未定义符号,ABS 表示绝对符号,其值不随重定位改变 |
st_value |
Value | 符号值,在可重定位文件中通常是相对段起始的偏移,在可执行文件中是最终虚拟地址 |
st_size |
Size | 符号所占字节数,对函数表示指令范围大小,对对象表示变量占用空间 |
readelf -s 输出实例介绍:
bash
ubuntu->ProgSelf:$ readelf -s simple_section.o
Symbol table '.symtab' contains 13 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS simple_section.c
2: 0000000000000000 0 SECTION LOCAL DEFAULT 1 .text
3: 0000000000000000 0 SECTION LOCAL DEFAULT 3 .data
4: 0000000000000000 0 SECTION LOCAL DEFAULT 4 .bss
5: 0000000000000000 0 SECTION LOCAL DEFAULT 5 .rodata
6: 0000000000000004 4 OBJECT LOCAL DEFAULT 3 static_var.1
7: 0000000000000004 4 OBJECT LOCAL DEFAULT 4 static_var2.0
8: 0000000000000000 4 OBJECT GLOBAL DEFAULT 3 global_init_var
9: 0000000000000000 4 OBJECT GLOBAL DEFAULT 4 global_uninit_var
10: 0000000000000000 43 FUNC GLOBAL DEFAULT 1 func1
11: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND printf
12: 000000000000002b 55 FUNC GLOBAL DEFAULT 1 main下面是各列字段含义说明:
| 列名 | 说明 |
|---|---|
| Num | 符号在符号表中的索引,链接器通过索引而非名字直接引用符号 |
| Value | 对应 st_value,需结合 Ndx 理解其是偏移还是绝对地址 |
| Size | 对应 st_size,在调试和优化中可用于边界检查 |
| Type | 符号的语义类别,如函数、变量或段本身 |
| Bind | 符号的链接属性,决定是否可被其他目标文件引用 |
| Vis | 控制动态链接器是否导出该符号 |
| Ndx | 段索引或特殊值(UND、ABS) |
| Name | 实际的符号名字符串 |
在示例中,static_var.1、static_var2.0 为 LOCAL 符号,仅在当前目标文件内可见;printf 标记为 UND,说明该符号需要在链接阶段由外部库解析;而 func1、main 属于 GLOBAL FUNC,是链接与调用的核心入口。
除了由程序员显式定义的符号,ELF 链接过程中还会生成一类特殊符号。这些符号没有对应的源代码实体,却精确刻画了程序在内存中的整体布局。例如 _executable_start 表示可执行文件映像的起始虚拟地址,它通常指向第一个可加载段的起点,为运行时探测程序边界提供了可靠依据。
与之相对,_edata 和 _end 则用于标识数据区域的结束位置。_edata 通常指向已初始化全局变量区域(.data)的末尾,而 _end 指向整个进程映像中最后一个字节之后的位置,覆盖 .bss 等未初始化数据段。这种分界在早期 UNIX 程序中尤为常见,用于实现自定义内存管理或简单的堆起始地址计算。
这些特殊符号的价值在于,它们将"链接结果"显式暴露给程序本身。某些底层代码可以通过声明这些符号为外部变量,直接获取关键内存边界信息,而无需依赖平台私有接口。这种机制体现了 ELF 设计的一致性:链接器既是程序的构建者,也是运行时信息的重要提供者。
3.8 符号修饰
符号修饰的根本目的在于避免不同编译单元之间的符号名冲突,并为链接器提供足够的语义信息 。早期 C 语言并不支持函数重载,也缺乏名称空间机制,因此只能通过约定在符号层面做最小化区分。在一些体系结构和工具链中,编译器会在函数或全局变量的汇编符号名前加上下划线,这正是 -fleading-underscore 所控制的行为。
这种前导下划线并不改变语言层面的语义,而是编译器与汇编器、链接器之间的一种历史兼容约定。例如在早期的 UNIX 或某些 ABI 中,C 函数 main 在目标文件里实际符号名可能是 _main。这样做的好处是将用户符号与工具链内部符号区分开来,但它并不能从根本上解决复杂工程中的命名冲突问题。
C++ 引入名称空间后,从语法层面解决了符号可见性和作用域的问题,但这仍不足以支持函数重载。因为在最终的目标文件和符号表中,链接器只认"名字+地址",并不了解参数类型、返回值等高级语言信息。为了弥补这一鸿沟,C++ 编译器必须将函数的完整类型信息编码进符号名中,这便是符号修饰(Name Decoration 或 Name Mangling)。
C++
// example.cpp
// 修饰名称 => _Z3addii
int add(int a, int b) {
return a + b;
}
// 修饰名称 => _Z3adddd
double add(double a, double b) {
return a + b;
}如上所示,_Z 是 Itanium C++ ABI 规定的前缀,表示这是一个经过 C++ 修饰的符号;3add 表示函数名 add 长度为 3;后缀的 ii 和 dd 分别编码了参数类型 int, int 与 double, double。正是这种类型信息的编码,使得链接器能够区分重载函数并完成正确绑定。
符号修饰的核心思想是将函数名、名称空间、类作用域以及参数类型组合成一个唯一的汇编级符号。例如两个同名但参数不同的函数,在经过修饰后会生成完全不同的符号名,从而在链接阶段能够被准确区分。虽然不同编译器的修饰规则并不完全一致,但在同一 ABI 下,这种规则是稳定且可预测的。
从链接器的角度看,符号修饰并非"花哨的语法技巧",而是一种信息下沉策略:把高级语言的类型系统压缩进字符串形式的符号名中,使得不具备类型系统的链接器仍然能够完成正确的符号匹配。这也解释了为什么 C++ 对外暴露接口时常常需要 extern "C",以关闭修饰机制,回退到 C 风格的简单符号名。
3.9 强弱符号
在链接阶段,符号不仅区分是否已定义,还具有强弱属性。函数定义以及已初始化的全局变量通常被视为强符号,而未初始化的全局变量在传统模型中表现为弱符号语义。强弱符号的引入,使链接器能够在多目标文件同时提供同名符号时做出确定性选择,从而在不破坏模块化设计的前提下支持可覆盖、可裁剪的实现方式。
弱符号可以通过编译器扩展显式声明,例如使用 __attribute__((weak)) 将原本的强符号降级。这种机制常见于系统库和基础框架中,用于提供"默认实现"。当程序中存在同名强符号时,链接器会优先选择强符号;若仅存在弱符号,则该弱符号会被采用,从而实现一种无需条件编译的替换策略。
强弱符号的解析规则是链接行为的核心:
- 不允许多个强符号同名共存,否则会触发重定义错误;
- 强符号与弱符号同名时,强符号胜出;
- 多个弱符号同名时,链接器选择其中占用空间最大的一个。
这种规则在保持链接确定性的同时,也为库设计提供了有限但实用的扩展空间。
c
// lib.c
__attribute__((weak))
int handler(void) {
return 0;
}
// app.c
int handler(void) {
return 42;
}在上述示例中,若同时链接 lib.o 与 app.o,最终可执行文件中的 handler 将指向强符号版本。若应用未提供实现,则弱符号版本自然生效,这一行为完全由链接器完成,运行期不产生额外开销。
与弱符号相关但语义更精细的是弱引用。通过 __attribute__((weakref)) 或链接器支持的弱引用声明,可以使一个符号引用在目标未定义时不产生链接错误。弱引用在解析失败时会被解析为 NULL,这使得程序能够在运行期检测功能是否存在,常用于可选特性或平台差异化支持。
c
extern void optional_feature(void)
__attribute__((weak));
if (optional_feature) {
optional_feature();
}在该模式下,弱引用并不参与强弱符号的覆盖竞争,而是影响"是否必须存在"。因此,强弱符号解决的是"选谁",弱引用解决的是"要不要"。二者结合,使 C/C++ 在保持静态链接模型的同时,具备接近插件化的扩展能力,成为系统级程序设计中不可或缺的工具。
3.10 调试信息
调试信息用于在可执行文件与源代码之间建立映射关系,使调试器能够还原变量、类型与执行路径等高层语义。在现代工具链中,调试信息通常独立于指令语义存在,由编译器生成、链接器整合,调试器按需解析。其中最具代表性的两种格式是 DWARF 与 CodeView,分别主导类 Unix 与 Windows 生态。
DWARF 是一种与目标文件格式松耦合的调试信息规范,常与 ELF 结合使用。编译器在生成目标文件时,会将调试信息放入诸如 .debug_info、.debug_line、.debug_abbrev 等独立节中。这些节以高度结构化的树状表示描述编译单元、作用域、变量和类型关系,支持复杂的 C/C++ 语言特性。
从表达能力上看,DWARF 采用"描述式"模型,而非简单符号表。例如变量的位置可以通过一段位置表达式动态计算,而非固定地址。这使得优化级别较高时,调试器仍能追踪寄存器分配或被重排的变量生命周期,但也显著增加了解析复杂度。
c
int add(int a, int b) {
int c = a + b;
return c;
}在 DWARF 中,函数、形参和局部变量都会被建模为独立条目,并通过抽象树关联,c 的生存区间可能仅覆盖部分指令范围,这一信息对单步调试尤为关键。
与之相比,CodeView 是微软在 Windows 平台长期使用的调试信息格式,主要服务于 MSVC 工具链。其调试信息最终通常被收敛到独立的 PDB 文件中,而非直接嵌入可执行文件。该设计减少了最终产物体积,也便于在不重新分发程序的情况下更新调试信息。
CodeView 更强调与编译器和调试器的紧密配合,数据布局偏向顺序化和索引化,便于 Visual Studio 快速定位符号与类型信息。与 DWARF 相比,其跨平台性较弱,但在 Windows 生态中对 C++ 模板、异常处理和增量链接有更深度的工程化支持。
生成
调试信息
源代码
编译器
目标文件
DWARF 节 / CodeView 数据
链接器
可执行文件 / PDB

Once Day
也信美人终作土,不堪幽梦太匆匆......
如果这篇文章为您带来了帮助或启发,不妨点个赞👍和关注!
(。◕‿◕。)感谢您的阅读与支持~~~