背景
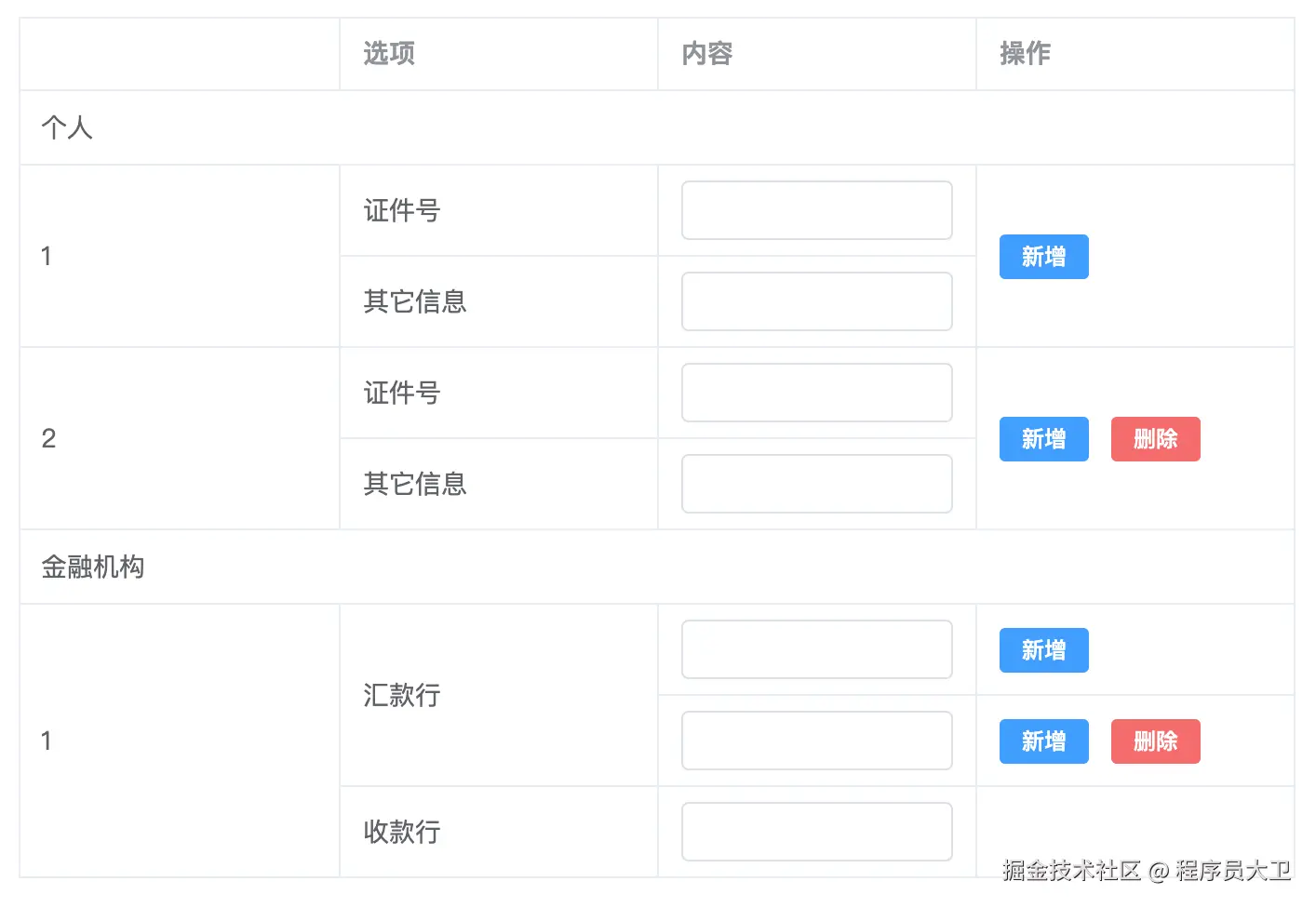
在做后台系统时,表格 合并单元格 几乎是高频需求:
- 相同
type的数据要合并 - 相同
group连续行要合并 - 中间还夹着标题行
- 某些列需要条件合并
很多人一上来就写一堆嵌套循环 + if 判断,最后逻辑混乱、难维护。
今天我给你一个可配置、可复用、强类型、支持特殊行的通用合并方案。
一、只需定义规则
js
const mergeRules: MergedRules<TableItem> = [
{
col: 0,
keys: ['type', 'group'],
getSpan: (row: TableItem) => {
if (row.title) {
return [1, 4];
}
},
},
{
col: 1,
keys: ['type', 'subType'],
getSpan: (row: TableItem) => {
if (row.title) {
return [0, 0];
}
},
},
{
col: 2,
getSpan: (row: TableItem) => {
if (row.title) {
return [0, 0];
}
},
},
{
col: 3,
keys: ['type', 'group'],
getSpan: (row: TableItem) => {
if (row.title) {
return [0, 0];
}
},
filter: (row) => row._canAddGroup,
},
];规则说明
每条规则控制一列:
| 字段 | 作用 |
|---|---|
col |
第几列 |
keys |
哪些字段相同才合并 |
getSpan |
自定义特殊合并规则 |
filter |
条件合并 |
二、规则类型设计
先看类型定义。
ts
type BaseRule<T> = {
col: number;
keys?: (keyof T)[];
getSpan?: (row: T) => [number, number] | void;
filter?: (row: T) => boolean | void;
};
export type MergedRules<T> = BaseRule<T>[];设计亮点
keys使用(keyof T)[]------ 强类型字段校验getSpan返回[rowspan, colspan]filter支持条件合并- 泛型 T 保证数据结构安全
三、数据结构
yaml
export default [
// 个人
{
title: '个人',
type: 'Individual',
},
{
type: 'Individual',
subType: 'ID',
name: '证件号',
_addBtn: true,
_canAddGroup: true,
group: '1',
},
{
type: 'Individual',
subType: 'OtherInfo',
name: '其它信息',
_addBtn: true,
_canAddGroup: true,
group: '1',
},
{
type: 'Individual',
subType: 'ID',
name: '证件号',
_addBtn: true,
_delBtn: true,
_canAddGroup: true,
group: '2',
},
{
type: 'Individual',
subType: 'OtherInfo',
name: '其它信息',
_addBtn: true,
_delBtn: true,
_canAddGroup: true,
group: '2',
},
// 金融机构
{
title: '金融机构',
type: 'FinOrg',
},
{
type: 'FinOrg',
subType: 'FinRemitter',
name: '汇款行',
_addBtn: true,
group: '1',
},
{
type: 'FinOrg',
subType: 'FinRemitter',
name: '汇款行',
_addBtn: true,
_delBtn: true,
group: '1',
},
{
type: 'FinOrg',
subType: 'FinRecevier',
name: '收款行',
group: '1',
},
];四、核心算法实现
ts
export default function computeMergedRows<T extends object>(
data: T[],
rules: MergedRules<T>
) {
const rowSpanObj: Record<number, Record<number, [number, number]>> = {};
// 初始化每列状态
const state: State<T> = rules.map((rule) => ({
...rule,
count: 0,
start: null,
prevRow: null,
}));
// 初始化 rowSpanObj
rules.forEach((rule) => {
rowSpanObj[rule.col] = {};
});
data.forEach((currRow, i) => {
state.forEach((s) => {
const colStore = rowSpanObj[s.col];
if (!colStore) return;
// 1️⃣ 特殊合并规则优先
const customSpan = s.getSpan?.(currRow);
if (customSpan) {
if (s.count > 0 && s.start !== null) {
colStore[s.start] = [s.count, 1];
}
colStore[i] = customSpan;
// 重置状态
s.count = 0;
s.start = null;
s.prevRow = null;
return;
}
// 2️⃣ 常规合并逻辑
if (!s.prevRow) {
s.start = i;
s.count = 1;
} else {
const isSame =
s.keys && s.keys.length > 0
? s.keys.every((k) => currRow[k] === (s.prevRow as T)[k])
: false;
const filterPassed = s.filter ? s.filter(currRow) : true;
if (isSame && filterPassed) {
colStore[i] = [0, 0];
s.count++;
} else {
if (s.start !== null) {
colStore[s.start] = [s.count, 1];
}
s.start = i;
s.count = 1;
}
}
s.prevRow = currRow;
});
});
// 3️⃣ 处理最后遗留分组
state.forEach((s) => {
if (s.count > 0 && s.start !== null) {
rowSpanObj[s.col]![s.start] = [s.count, 1];
}
});
return rowSpanObj;
}五、算法设计思路解析
整个算法核心是:
为每一列维护一个状态机
1️⃣ 每列独立维护状态
ts
type State<T> = Array<
BaseRule<T> & {
count: number;
start: number | null;
prevRow: T | null;
}
>;每一列都会维护:
| 状态 | 含义 |
|---|---|
start |
当前合并组起始行 |
count |
当前组行数 |
prevRow |
上一行数据 |
这使得:
- 每列逻辑互不影响
- 可以自由扩展规则
- 支持不同列不同合并逻辑
2️⃣ 优先处理特殊行
ts
const customSpan = s.getSpan?.(currRow);为什么要优先处理?
因为像"标题行"这种情况:
- 它不参与普通比较
- 它会打断前一组合并
- 它会强制占据固定 span
所以:
- 先结算上一组
- 记录当前特殊 span
- 重置状态
这就是关键。
3️⃣ 常规合并逻辑
核心判断:
ts
const isSame = s.keys?.every(...)只要:
- keys 全部相等
- filter 条件满足
就:
ts
colStore[i] = [0, 0];否则:
- 结算上一组
- 开始新组
4️⃣ 为什么返回 rowSpanObj 结构?
ts
{
colIndex: {
rowIndex: [rowspan, colspan]
}
}这种结构刚好可以用于 Element Plus:
ts
const arraySpanMethod = ({ rowIndex, columnIndex }) => {
return rowSpanObj[columnIndex]?.[rowIndex] ?? [1, 1];
};六、总结
核心思想其实只有一句话:
用"状态机"去驱动每一列的合并行为。
你不需要在模板里写一堆 if。 也不需要在 span-method 里疯狂判断。
只要定义规则。
源码地址: