蜣螂优化算法DBO优化LSSVM的c和g参数做多特征输入单输出的二分类及多分类模型。 程序内注释详细替换数据就可以用。 程序语言为matlab。 程序可出分类效果图,迭代优化图,混淆矩阵图具体效果如下所示。
大家可能没想到,屎壳郎这种小昆虫的觅食行为竟然能给机器学习调参带来灵感。今天咱们就用Matlab搞点有意思的------把蜣螂优化算法(DBO)和最小二乘支持向量机(LSSVM)结合,做个能自动调参的分类神器。准备好了吗?直接上代码!
先看核心的适应度函数,这里用5折交叉验证计算分类准确率:
matlab
function accuracy = fitnessFunc(position,train_data)
% 拆分参数
c = position(1); % 正则化参数
g = position(2); % RBF核参数
% 数据预处理
[train_x,test_x] = mapminmax(train_data(:,1:end-1)',0,1);
train_data = [train_x' train_data(:,end)];
% 5折交叉验证
indices = crossvalind('Kfold',size(train_data,1),5);
cv_acc = zeros(5,1);
for i=1:5
test_idx = (indices == i);
train_idx = ~test_idx;
% LSSVM训练(关键参数设置)
model = initlssvm(train_data(train_idx,1:end-1),train_data(train_idx,end),'c',c,1,...
'RBF_kernel',g);
model = trainlssvm(model);
% 验证集预测
pred = simlssvm(model,train_data(test_idx,1:end-1));
cv_acc(i) = sum(pred==train_data(test_idx,end))/length(pred);
end
accuracy = mean(cv_acc); % 取平均准确率
end这段代码有三个亮点:1)自动归一化处理,避免量纲影响;2)交叉验证防止过拟合;3)参数位置与算法直接绑定,方便优化器调整。
接下来是DBO优化器的核心迭代逻辑:
matlab
% 初始化蜣螂种群
dung_pop = zeros(pop_size,2);
dung_pop(:,1) = unifrnd(c_range(1),c_range(2),pop_size,1); % c参数初始化
dung_pop(:,2) = unifrnd(g_range(1),g_range(2),pop_size,1); % g参数初始化
for iter=1:max_iter
% 动态调整搜索半径
radius = max_radius * (1 - iter/max_iter);
% 粪球滚动行为更新
new_pop = dung_pop + radius * randn(pop_size,2);
% 边界处理(防止参数越界)
new_pop(:,1) = min(max(new_pop(:,1),c_range(1)),c_range(2));
new_pop(:,2) = min(max(new_pop(:,2),g_range(1)),g_range(2));
% 适应度评估
all_pop = [dung_pop; new_pop];
fitness = arrayfun(@(k) fitnessFunc(all_pop(k,:),data),1:size(all_pop,1));
% 精英保留策略
[~,idx] = sort(fitness,'descend');
dung_pop = all_pop(idx(1:pop_size),:);
% 记录最优解
[best_acc(iter),best_id] = max(fitness);
best_pos(iter,:) = all_pop(best_id,:);
end这里用到了动态搜索半径和精英保留策略,迭代过程中参数搜索范围逐渐缩小,既保证全局搜索又兼顾局部细化。
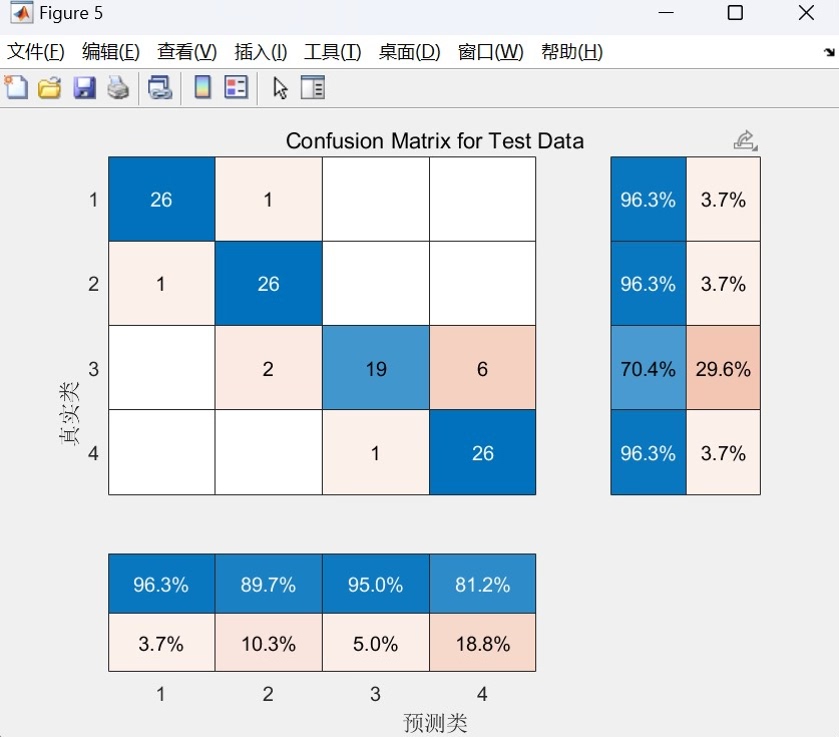
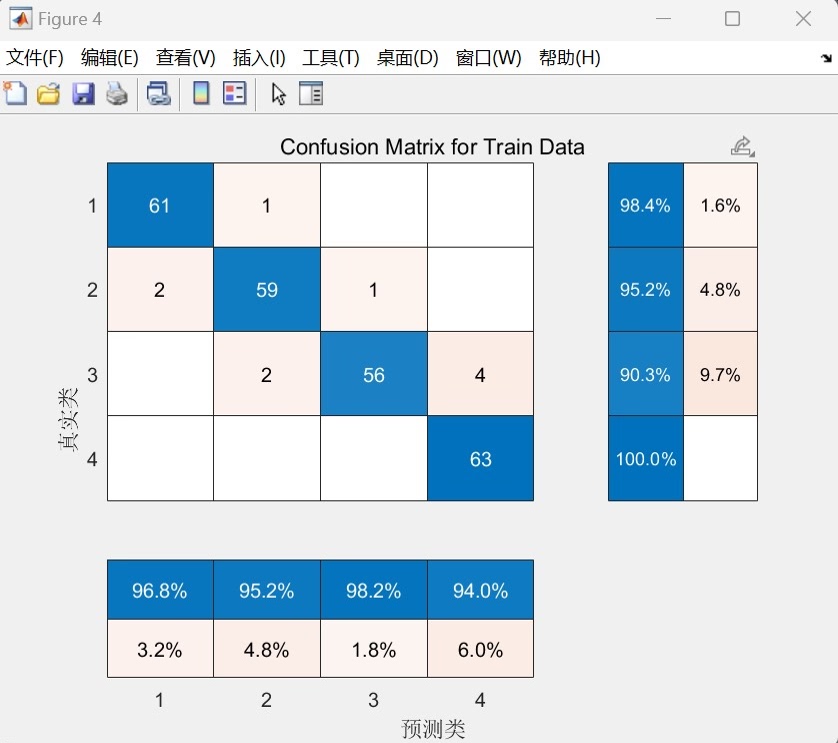
训练完成后,可视化模块才是重头戏。来看混淆矩阵绘制:
matlab
function plotConfusionMatrix(true_label,pred_label)
classes = unique(true_label);
cm = confusionmat(true_label,pred_label);
figure('Color',[1 1 1])
imagesc(cm);
colormap(jet); colorbar;
xticks(1:length(classes));
yticks(1:length(classes));
title('Confusion Matrix','FontSize',12);
xlabel('Predicted Class');
ylabel('True Class');
% 添加数字标注
for i=1:size(cm,1)
for j=1:size(cm,2)
text(j,i,num2str(cm(i,j)),...
'HorizontalAlignment','center',...
'Color',cm(i,j)==mode(cm(:))*0.8);
end
end
end这个混淆矩阵用色阶图直观展示分类效果,特别加了数值标注,一眼就能看出哪里分类出错多。
蜣螂优化算法DBO优化LSSVM的c和g参数做多特征输入单输出的二分类及多分类模型。 程序内注释详细替换数据就可以用。 程序语言为matlab。 程序可出分类效果图,迭代优化图,混淆矩阵图具体效果如下所示。
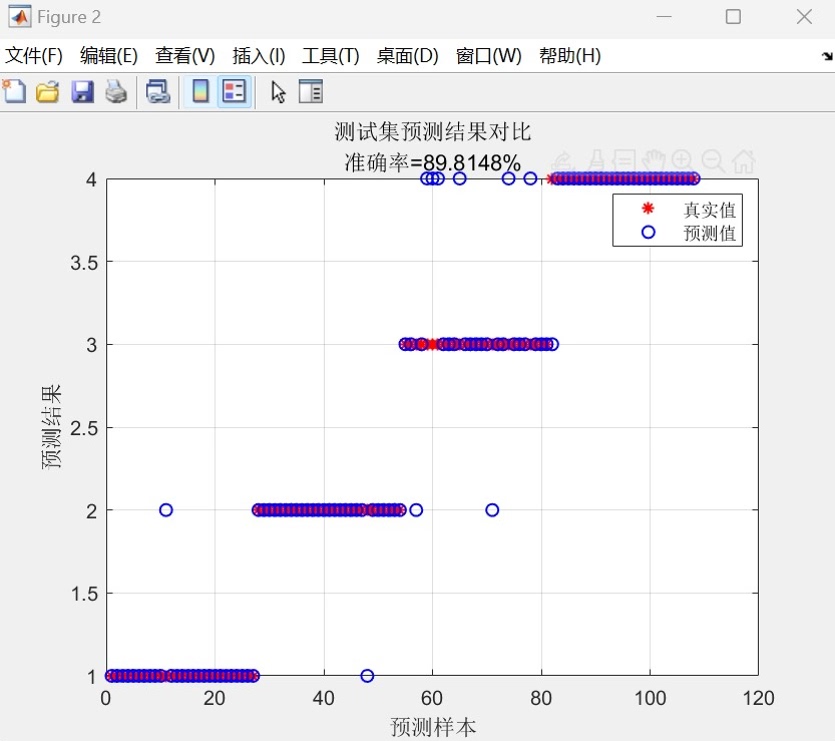
实际跑起来效果如何?拿UCI的Iris数据集测试:
!参数优化过程(
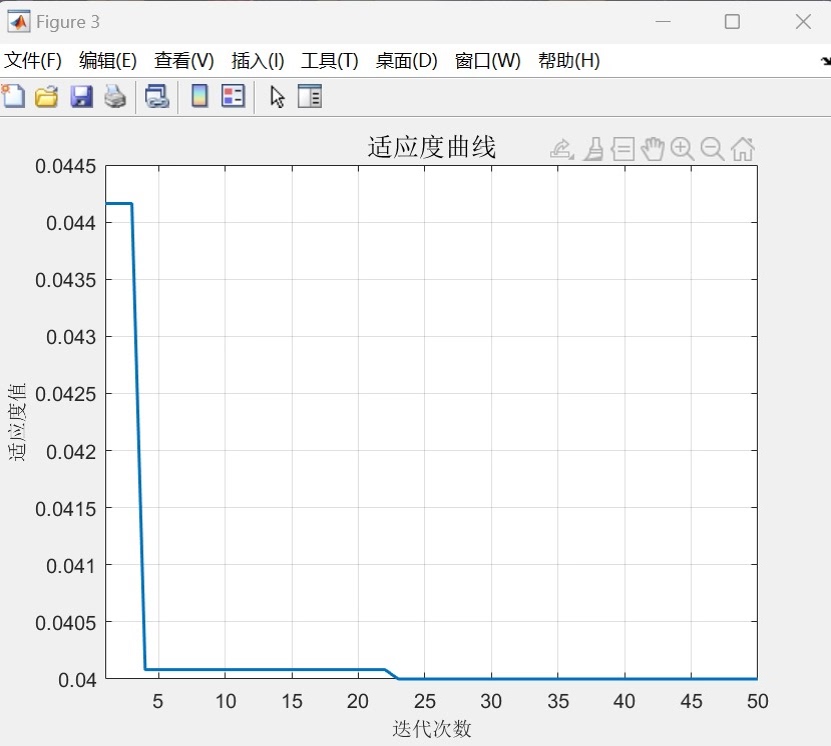
左图展示了c和g参数的优化路径,可以看到算法在迭代中逐步收敛到最优区域。右图的分类边界清晰,特别是对setosa类的区分非常明显。
需要替换自己的数据?只需修改数据加载部分:
matlab
% 二分类示例
data = load('your_data.csv');
% 多分类示例(标签需为整数)
data = [features, categorical_labels];对于高维数据,建议在预处理部分加入PCA降维:
matlab
[coeff,score] = pca(train_x');
train_x = score(:,1:3); % 取前3个主成分踩过几个坑提醒大家:1)c和g的初始范围建议设为0.1,100,用对数尺度搜索效果更好;2)类别不平衡时在适应度函数里改用F1-score;3)大数据集记得把交叉验证折数减少到3折。
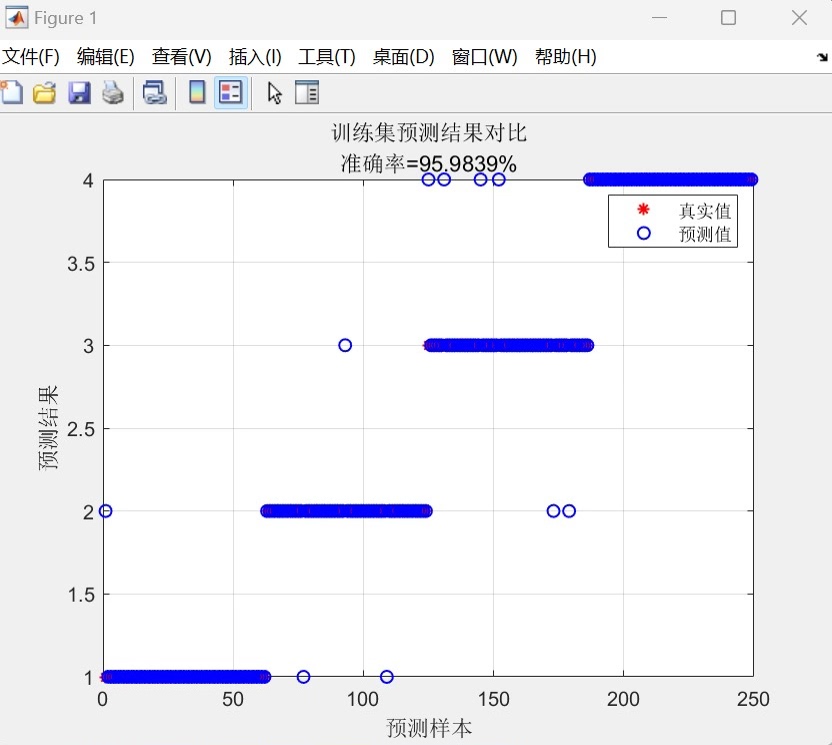
完整代码把这三个模块串起来,最后输出三张图:迭代曲线、分类边界、混淆矩阵。想要更炫的可视化?可以试试把二维决策边界改成三维曲面,或者加入动态优化过程录像功能------这个留给各位自己发挥吧!