HDFS框架
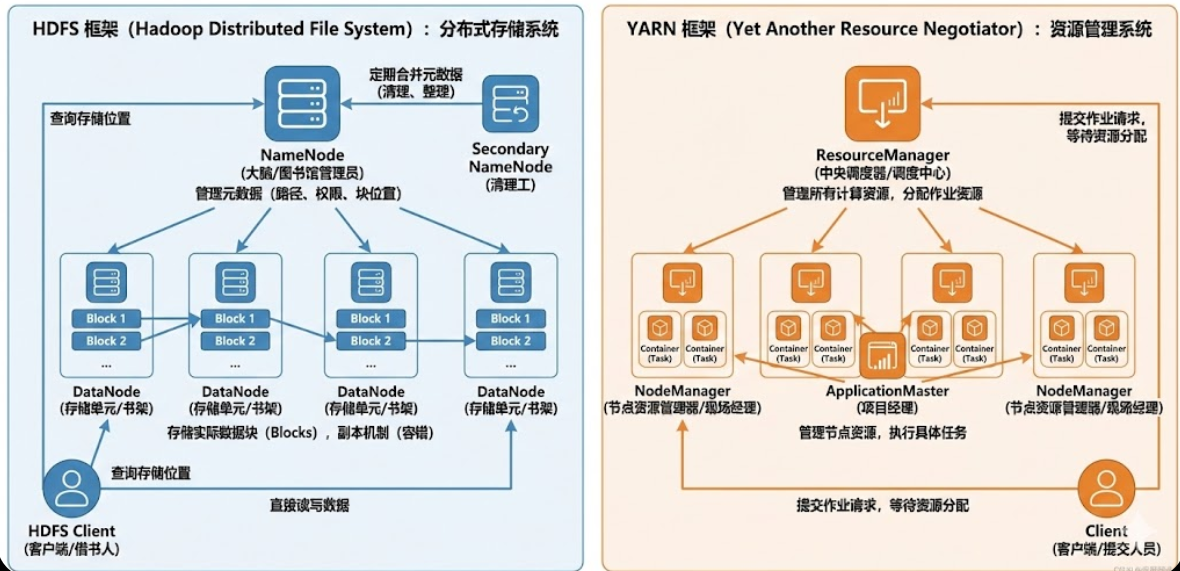
HDFS(Hadoop Distributed File System)是 Hadoop 的分布式存储系统。它的设计目的是能够处理海量数据,确保数据存储的高可靠性和高可用性。这个系统的核心结构主要包括 NameNode、DataNode、Secondary NameNode 和 HDFS Client。我们来逐个了解它们的作用。
-
NameNode 是 HDFS 的大脑,它负责管理文件系统的元数据,包括文件的路径、权限、块的位置等。它不直接存储数据,而是记录每个文件对应的块的位置。它就像一个图书馆管理员,知道每本书放在哪里,但并不储存书籍。没有它,数据是找不到地方的。
-
DataNode 是 HDFS 的存储单元,负责实际的数据存储。HDFS 将文件分成多个块(Block),并把这些块分散存储在不同的 DataNode 上。每个 DataNode 定期向 NameNode 汇报自己存储的块的信息,保证系统的健康。你可以把它看作是图书馆的书架,专门存放书籍。
-
Secondary NameNode 不是 NameNode 的备份,它的作用更像是一个"清理工"。它定期将 NameNode 的元数据进行合并,防止元数据文件变得太大,影响系统性能。可以理解为它是对 NameNode 的"清理"和"整理",确保 NameNode 的运行更加高效。
-
HDFS Client 是与 HDFS 集群交互的客户端,它通过 HDFS 提供的 API 来执行各种文件操作。比如上传、下载文件时,HDFS Client 会先向 NameNode 查询文件的存储位置,再直接与 DataNode 通信完成数据的读写。它就像是你去借书时,先找管理员获取书籍信息,然后到书架上取书。
YARN框架
YARN(Yet Another Resource Negotiator)是 Hadoop 的资源管理系统,主要负责调度和管理集群中的计算资源。它的核心组件包括 ResourceManager、NodeManager、Client 和 ApplicationMaster。让我们逐个了解它们的作用。
-
ResourceManager 是 YARN 的中央调度器,负责管理集群中所有的计算资源。它监控集群中各个节点的资源状况,并根据作业的需求分配资源。可以把它看作是一个调度中心,决定哪些任务能得到哪些计算资源。你想要做一个项目,ResourceManager 就像是分配工作的人,决定你能用多少资源。
-
NodeManager 是集群中每个节点的资源管理器,它负责管理该节点的资源,并执行具体的任务。当 ResourceManager 分配资源后,NodeManager 负责在本节点上启动任务并监控其执行情况。可以理解为它是现场的经理,负责确保任务在本地按时完成。
-
Client 是提交作业的客户端程序。通常是用户的应用程序,它负责向 ResourceManager 提交任务请求,并等待资源分配。Client 可以理解为提交工作的人员,它发起任务请求并等待资源调度。
-
ApplicationMaster 是每个作业的管理者,它负责管理整个作业的生命周期,包括任务的调度、资源申请和执行。它根据 ResourceManager 分配的资源,向 NodeManager 请求执行任务,并跟踪任务的进度。ApplicationMaster 就像是一个项目经理,负责确保每个任务顺利完成。
HDFS和YARN的对比
HDFS 和 YARN 都是 Hadoop 的重要组成部分,但它们的侧重点完全不同,功能也有所区别。
-
数据管理 vs 资源管理:HDFS 专注于数据的存储与管理,确保数据高效、安全地存储在分布式环境中;而 YARN 专注于资源调度与任务管理,确保每个作业能够高效地使用集群资源。
-
核心组件:HDFS 的核心组件是 NameNode、DataNode 和 Secondary NameNode,主要负责文件系统的管理和数据的存储;而 YARN 的核心组件是 ResourceManager、NodeManager、Client 和 ApplicationMaster,主要负责计算资源的分配与作业的执行。
-
容错机制:HDFS 提供副本机制来保证数据的高可靠性,比如一个数据块可以有多个副本存储在不同的 DataNode 上;而 YARN 的容错机制更多体现在任务调度上,它会在节点故障时重新调度任务。
总结
简而言之,HDFS 和 YARN 各自担任不同的角色。HDFS 作为存储系统,负责数据的分布式存储和管理,确保数据的高可用性;而 YARN 作为资源管理系统,负责调度和管理集群资源,确保作业能够高效执行。两者合作,共同构成了大数据处理平台的核心。可以说,HDFS 提供了坚实的数据存储基础,而 YARN 则提供了高效的资源调度和任务执行平台。