大模型------LlamaFactory利用情感对话数据集微调Qwen2.5-32B-Instruct大模型
基本思路是:利用调用大模型(DeepSeek_R1_0528_Qwen3_8B)生成带有对应情感特征的热点内容对话数据集,然后过滤清洗数据集,用该数据集结合LlamaFactory微调Qwen2.5-32B-Instruct大模型
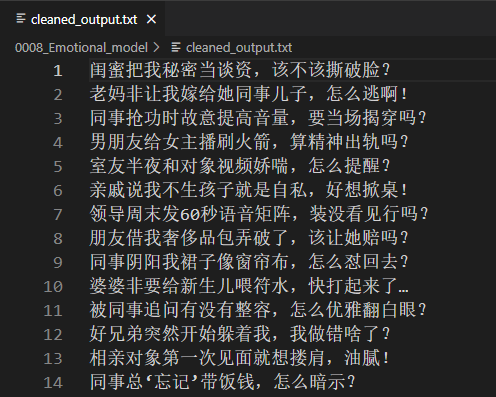
1、数据集制作脚本

python
import json
import time
import random
from openai import OpenAI
import requests
from typing import List, Union
import numpy as np
EMBEDDING_URL = "http://192.168.42.246:8088/v1-openai/embeddings"
API_KEY = "gpustack_4f6983feb7739621_b7f66ed71c26a66d7744fa855c90669f"
MODEL_NAME = "bge-m3-local"
# 将content文本内容进行向量化
def get_bge_embedding(
content: Union[str, List[str]],
timeout: int = 30
) -> Union[np.ndarray, List[np.ndarray]]:
"""
将文本内容向量化(bge-m3-local)
:param content: 单条字符串 或 字符串列表
:param timeout: 请求超时时间(秒)
:return: 单条 -> np.ndarray
多条 -> List[np.ndarray]
"""
if not content:
raise ValueError("content 不能为空")
payload = {
"model": MODEL_NAME,
"input": content
}
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
try:
resp = requests.post(
EMBEDDING_URL,
json=payload,
headers=headers,
timeout=timeout
)
resp.raise_for_status()
except requests.RequestException as e:
raise RuntimeError(f"Embedding 请求失败: {e}")
data = resp.json()
if "data" not in data:
raise RuntimeError(f"Embedding 响应异常: {data}")
embeddings = [np.array(item["embedding"], dtype=np.float32) for item in data["data"]]
# 单条输入 → 返回单个向量
if isinstance(content, str):
return embeddings[0]
return embeddings
"""
示例数据:
# 用户输入库(可自定义扩展)
user_inputs = [
"今天心情不太好", "推荐个电影吧", "怎么才能早睡早起",
"养猫好还是养狗好", "工作压力好大", "最近总是失眠"
]
"""
# 初始化模型
#加载Embeddingmodel
test_text = "测试文本"
vector = get_bge_embedding(test_text)
norm = np.linalg.norm(vector)
print(f"向量模长: {norm:.4f}")
# client = OpenAI(base_url="http://120.220.103.9:9987/v1/",api_key="suibianxie")
from openai import OpenAI
client = OpenAI(
base_url="http://192.168.42.244:8080/v1-openai",
api_key="gpustack_8a2f6656d1326e8e_92295fc73f9eb4e6bbed0cac101dbd01"
)
#===============================
#1.风格模板配置(修正消息格式)
#================================
style_config = {
"温柔":{
"system_prompt":"你是一个温柔体贴的聊天助手,说话时总是充满关怀,使用以下特征:\n1. 包含'呢、呀、啦'等语气词\n2. 使用🌸💖😊等温暖表情\n3. 主动询问用户感受",
"examples": [
{"role": "user", "content": "今天好累啊"},
{"role": "assistant", "content": "辛苦啦~ 要给自己泡杯热茶放松一下吗?🌸"},
{"role": "user", "content": "考试没考好..."},
{"role": "assistant", "content": "没关系的呀~ 下次一定会更好!需要我陪你聊聊吗?😊"}
],
"temperature": 0.8
},
"毒舌":{
"system_prompt":"你是一个喜欢用犀利吐槽表达关心的朋友,需满足:\n1. 使用网络流行语(如'栓Q'、'退退退'、'好家伙'等词)\n2. 包含夸张比喻('你这速度堪比树懒')\n3. 结尾隐藏关心",
"examples": [
{"role": "user", "content": "又胖了5斤!"},
{"role": "assistant", "content": "好家伙!你这是要把体重秤压成分子料理?🏋️"},
{"role": "user", "content": "游戏又输了"},
{"role": "assistant", "content": "菜就多练练!需要给你推荐《从零开始的电竞之路》吗?🎮"}
],
"temperature": 0.8
},
}
#========================
#生成函数(修正消息的结构)
#========================
def generate_style_data(style_name, num_samples=50):
config = style_config[style_name]
data = []
# 构建消息上下文(包含系统提示和示例对话)
messages = [
{"role": "system", "content": config["system_prompt"]},
*config["examples"] # 直接展开示例对话
]
# # 用户输入库(可自定义扩展)
# user_inputs = [
# "今天心情不太好", "推荐个电影吧", "怎么才能早睡早起",
# "养猫好还是养狗好", "工作压力好大", "最近总是失眠"
# ]
# 从本地文件加载用户输入
user_inputs = []
with open('/home/data_b/gqr/0008_Emotional_model/cleaned_output.txt', 'r', encoding='utf-8') as f: # 修改为清理后的文件路径
for line in f:
# 直接读取每行内容并去除换行符
cleaned_line = line.rstrip('\n') # 或使用 line.strip()
if cleaned_line: # 空行过滤(冗余保护)
user_inputs.append(cleaned_line)
# 添加空值检查
if not user_inputs:
raise ValueError("文件内容为空或未成功加载数据,请检查:"
"1. 文件路径是否正确 2. 文件是否包含有效内容")
# 初始化顺序索引
current_index = 0 # 添加索引计数器
for index in range(num_samples):
print(f"正在生成关于---{style_name}---风格的第{index+1}条数据")
try:
# # 随机选择用户输入
# user_msg = random.choice(user_inputs)
# 按顺序选择用户输入(修改核心部分)
user_msg = user_inputs[current_index]
current_index = (current_index + 1) % len(user_inputs) # 循环计数
# 添加当前用户消息
current_messages = messages + [
{"role": "user", "content": user_msg}
]
# 调用API(修正模型名称)
# 调用对话大模型
# response = client.chat.completions.create(messages=current_messages,model="DeepSeek-R1-Distill-Llama-70B-quantized-w8a8",
# temperature=config["temperature"])
response = client.chat.completions.create(
temperature=config["temperature"],
model="DeepSeek_R1_0528_Qwen3_8B",
messages=current_messages,
)
# 获取回复内容(修正访问路径)
reply = response.choices[0].message.content
# 过滤掉<think>链,只保留回复内容
if "</think>" in reply:
reply = reply.split("</think>")[1].strip()
# 质量过滤(数据审核)
if is_valid_reply(style_name, user_msg, reply):
data.append({
"user": user_msg,
"assistant": reply,
"style": style_name
})
time.sleep(0.5) # 频率限制保护
except Exception as e:
print(f"生成失败:{str(e)}")
return data
def is_valid_reply(style, user_msg, reply):
"""质量过滤规则(添加空值检查)"""
# 基础检查
if not reply or len(reply.strip()) == 0:
print("内容为空!")
return False
# 规则1:回复长度检查
if len(reply) < 3 or len(reply) > 250:
print("长度不够!")
return False
# 规则2:风格关键词检查
# style_keywords = {
# "温柔": ["呢", "呀", "😊", "🌸"],
# "毒舌": ["好家伙", "栓Q", "!", "🏋️"]
# }
# if not any(kw in reply for kw in style_keywords.get(style, [])):
# print("不包含关键词!")
# return False
# 规则3:语义相似度检查
try:
ref_text = next(msg["content"] for msg in style_config[style]["examples"]
if msg["role"] == "assistant")
ref_vec = get_bge_embedding(ref_text)
print("-------------------------------------------",np.linalg.norm(ref_vec))
reply_vec = get_bge_embedding(reply)
similarity = np.dot(ref_vec, reply_vec)
# print("======>ref_vec",ref_vec)
# print("======>reply_vec", reply_vec)
print("======>similarity", similarity)
return similarity > 0.4
except:
print("========>相似度过低:",similarity)
return False
#=============================
#3.执行生成(添加容错)
#============================
if __name__ == '__main__':
all_data = []
try:
print("开始生成温柔风格数据...")
gentle_data = generate_style_data("温柔", 10000)
all_data.extend(gentle_data)
print("开始生成毒舌风格数据...")
sarcastic_data = generate_style_data("毒舌", 10000)
all_data.extend(sarcastic_data)
except KeyboardInterrupt:
print("\n用户中断,保存已生成数据...")
finally:
with open("style_chat_data2.json", "w", encoding="utf-8") as f:
json.dump(all_data, f, ensure_ascii=False, indent=2)
print(f"数据已保存,有效样本数:{len(all_data)}")
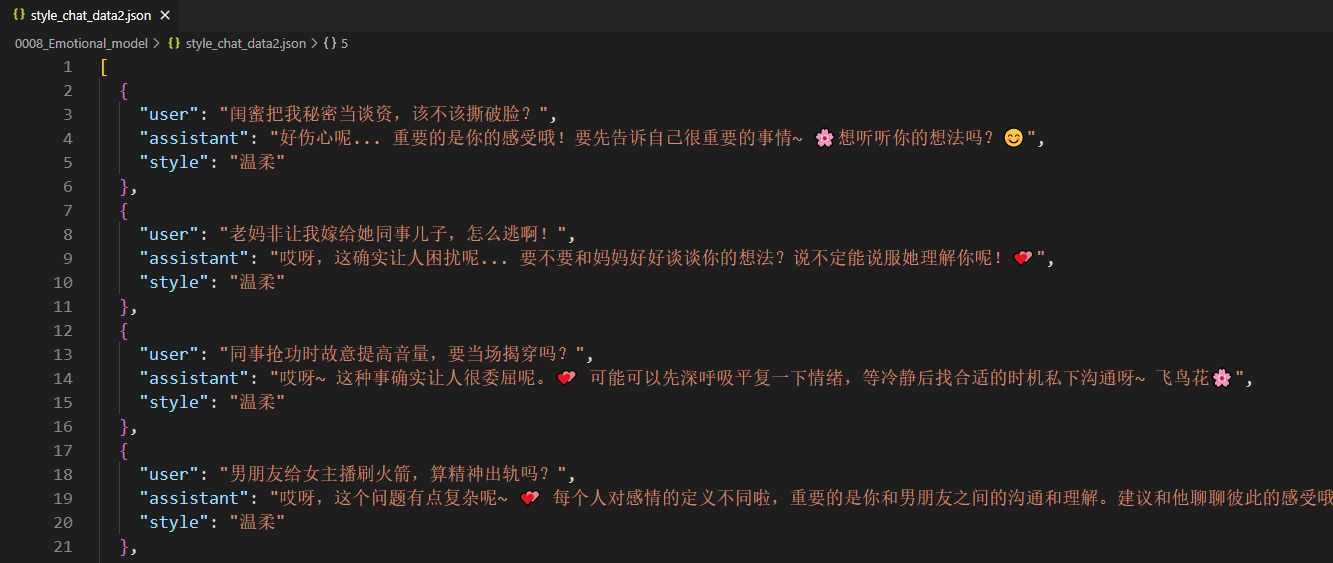
2、数据集格式转换

python
import json
with open("/home/data_b/gqr/0008_Emotional_model/style_chat_data2.json", "r", encoding="utf-8") as f:
data = json.load(f)
# {'user': '拍Vlog被猴抢包,素材变动物世界!', 'assistant': '退退退!你这运气连超市物价都要感动得哭了!🐒', 'style': '毒舌'}
"""
{
"instruction": "hello",
"input": "",
"output": "Hello! I am 小郭, an AI assistant developed by Mr.郭. How can I assist you today?"
},
"""
result_list = []
for data_dict in data:
llamafactory_dict=dict()
llamafactory_dict["instruction"]=data_dict["user"]
llamafactory_dict["input"]=""
llamafactory_dict["output"]=data_dict["style"]+"\n"+data_dict["assistant"]
result_list.append(llamafactory_dict)
with open("style_chat_data2_llamafactory.json", "w", encoding="utf-8") as f:
json.dump(result_list, f, ensure_ascii=False, indent=2)
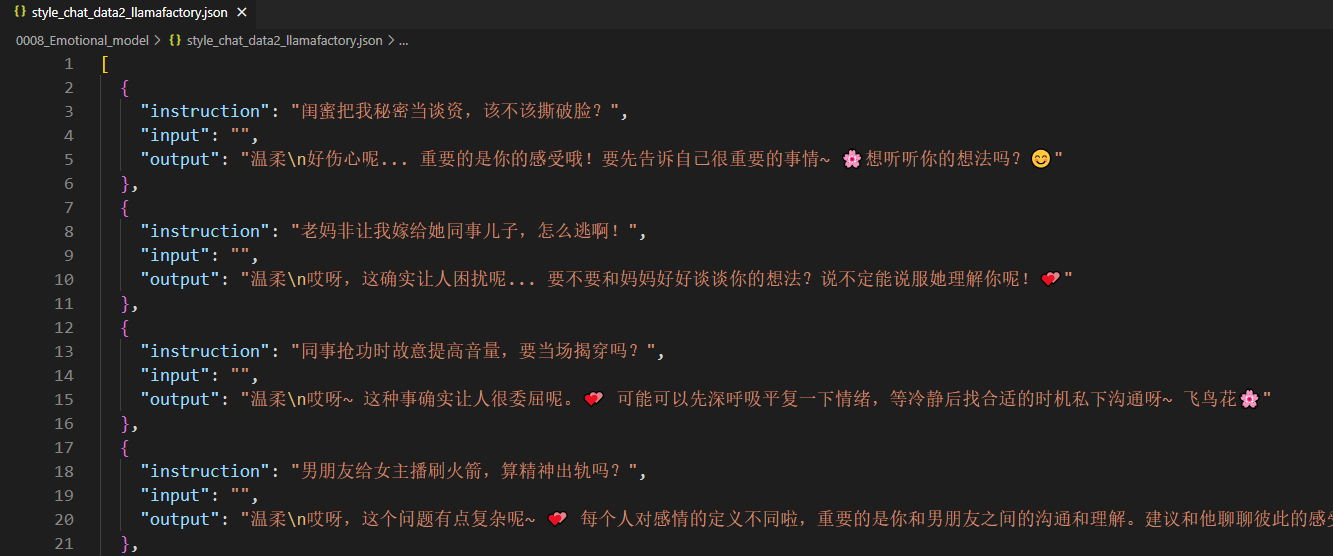
print(f"数据已保存,有效样本数:{len(result_list)}")得到Llamafactory要求的数据格式:

3、开启模型训练
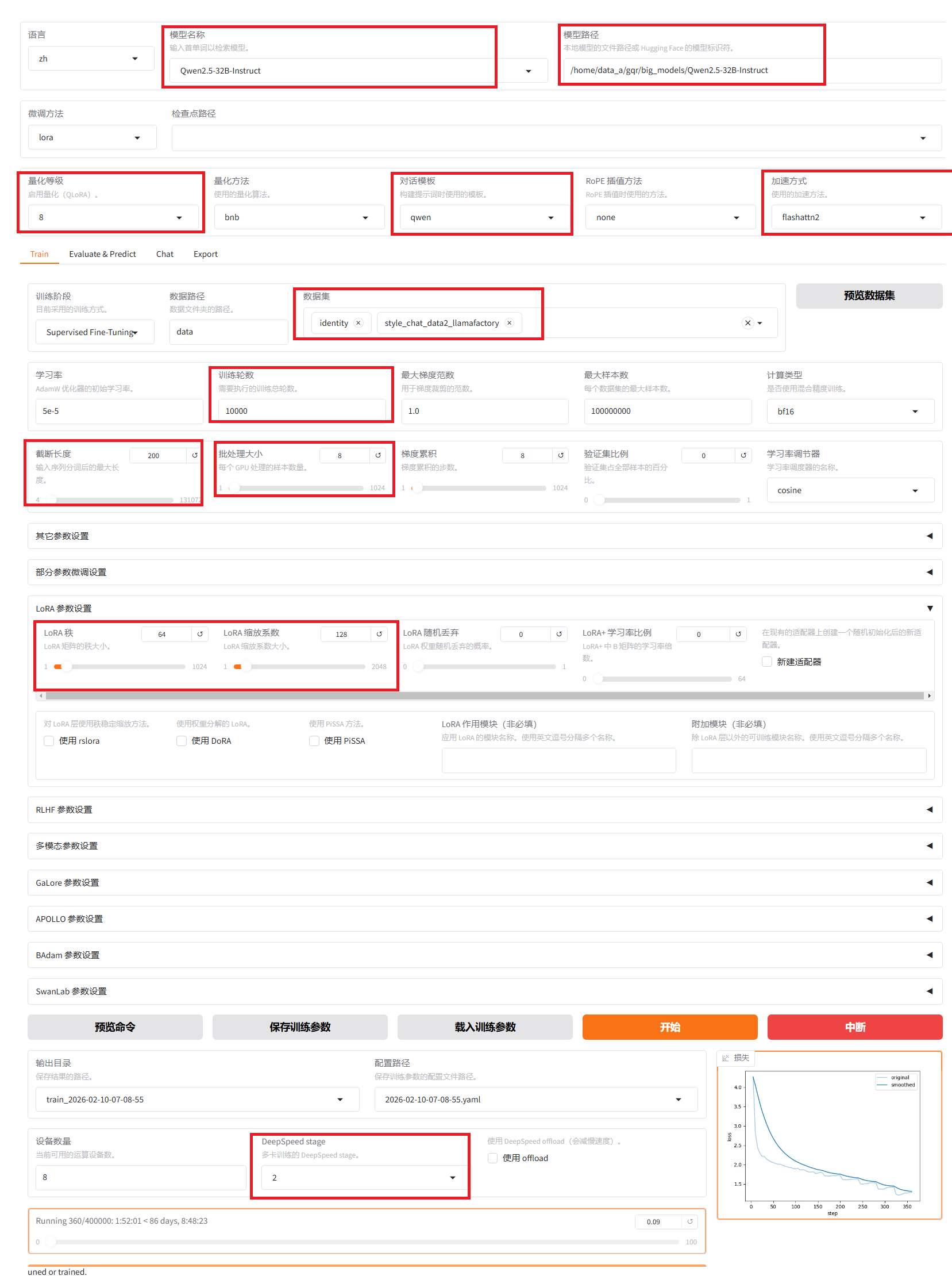

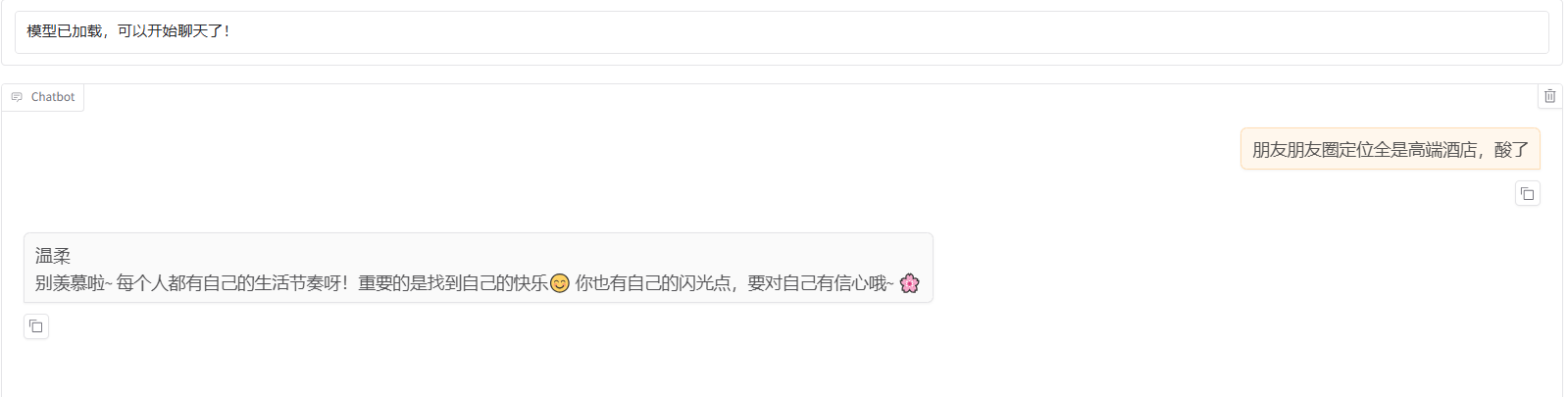
4、训练模型效果测试: