代码由ai生成,本地调试通过。
llamafactory会自动将模型下载到cache路径下,例如:/home/work/.cache/modelscope/hub/models/Qwen/Qwen3-VL-4B-Instruct
python本地调用Qwen
python基础环境
Python 3.13.0
torch 2.8.0
torchaudio 2.8.0
torchdata 0.11.0
torchvision 0.23.0
vllm 0.11.0
transformers 4.57.1
qwen-vl-utils 0.0.141 python调用Qwen3-4B-Base
- 代码:
python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
def load_llamafactory_model(model_path, device="auto"):
"""
加载 LLaMA Factory 导出的本地模型
:param model_path: 模型本地文件夹路径(如 ./output/qwen3-7b-finetuned)
:param device: 运行设备,auto=自动选GPU/CPU,cpu/gpu/cuda
:return: tokenizer, model
"""
# 1. 设置设备
if device == "auto":
device = "cuda" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.bfloat16 if device == "cuda" else torch.float32
# 2. 加载分词器(trust_remote_code=True 适配自定义模型)
tokenizer = AutoTokenizer.from_pretrained(
model_path,
trust_remote_code=True,
use_fast=False # 部分中文模型需要关闭 fast tokenizer
)
# 确保 pad_token 存在(避免推理报错)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# 3. 加载模型
model = AutoModelForCausalLM.from_pretrained(
model_path,
trust_remote_code=True,
torch_dtype=torch_dtype,
device_map=device, # auto 自动分配,单卡写 0,CPU 写 cpu
low_cpu_mem_usage=True # 减少 CPU 内存占用
)
# 模型设为评估模式(关闭 dropout)
model.eval()
return tokenizer, model
def generate_response(tokenizer, model, prompt, max_new_tokens=1024, temperature=0.7):
"""
基于加载的模型生成回答
:param tokenizer: 分词器
:param model: 加载好的模型
:param prompt: 用户提问
:param max_new_tokens: 最大生成长度
:param temperature: 随机性(0-1,越小越稳定)
:return: 模型回答
"""
# 1. 构建对话模板(关键:不同模型的对话模板不同)
# --- 适配 Qwen3 模型的模板 ---
messages = [{"role": "user", "content": prompt}]
input_text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# 2. 编码输入
inputs = tokenizer(
input_text,
return_tensors="pt",
padding=True,
truncation=True
).to(model.device)
# 3. 推理生成
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
temperature=temperature,
top_p=0.8,
repetition_penalty=1.1,
do_sample=True, # 采样生成(temperature>0 时开启)
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id
)
# 4. 解码并提取回答
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 过滤掉输入部分,只保留模型回答(不同模型模板需微调此处)
if "assistant\n" in response:
response = response.split("assistant\n")[-1].strip()
return response
# ------------------- 测试使用 -------------------
if __name__ == "__main__":
# 替换为你的 LLaMA Factory 导出模型的本地路径
MODEL_PATH = "/home/work/.cache/modelscope/hub/models/Qwen/Qwen3-0___6B-Base" # 示例路径,需修改
MODEL_PATH = "/home/work/.cache/modelscope/hub/models/Qwen/Qwen3-4B-Base" #
# 1. 加载模型(首次加载较慢,后续复用即可)
print("正在加载模型...")
tokenizer, model = load_llamafactory_model(MODEL_PATH)
print("模型加载完成!")
# 2. 提问并生成回答
user_prompt = "介绍嵩山和少林寺"
response = generate_response(tokenizer, model, user_prompt)
# 3. 输出结果
print("\n===== 模型回答 =====")
print(response)
- 输出:
python
正在加载模型...
`torch_dtype` is deprecated! Use `dtype` instead!
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:01<00:00, 2.83it/s]
模型加载完成!
===== 模型回答 =====
嵩山位于中国河南省登封市,是中国著名的五岳之一。它以其壮丽的自然风光、丰富的历史文化遗迹而闻名于世。
少林寺是嵩山上的一座古老寺庙,也是中国佛教禅宗的重要发源地之一。以下是关于嵩山和少林寺的一些详细介绍:
1. 嵩山简介:嵩山海拔约1500米,由多座山脉组成,其中包括了太室山、少室山等著名景点。这里拥有壮观的瀑布、幽深的峡谷以及众多的文化古迹。其中最著名的当属中岳庙、天地之中历史建筑群(包括少林寺)被列入世界文化遗产名录。
2. 少林寺的历史与文化意义:少林寺创建于公元495年左右,距今已有超过一千四百年的历史。它是禅宗祖师达摩创立的第一个汉传佛教寺院,在中国乃至亚洲都享有极高的声誉。除了其深厚的宗教内涵外,还因为武术的发展而在民间广为流传,并且成为了功夫电影中的经典场景之一。
3. 参观指南:
- 中岳庙:作为祭祀活动场所及重要文物保存单位之一对外开放;
- 天地之中历史建筑群:涵盖多个不同年代建造风格各异但又相互关联连贯起来展示古代文明成就的地方;
- 少林寺本身则提供给游客一个深入了解禅修生活的机会并欣赏到精美的佛像雕塑作品。
这些信息希望能够帮助你更好地了解嵩山及其代表性景点------少林寺!如果还有其他问题或者需要更详细的信息,请随时告诉我。2 python调用Qwen3-VL-4B-Instruct
- 代码
python
import torch
from transformers import Qwen3VLForConditionalGeneration,AutoProcessor
from qwen_vl_utils import process_vision_info
from PIL import Image
# ================= 配置路径 =================
# 替换为你下载好的本地模型路径
model_dir = "/home/work/.cache/modelscope/hub/models/Qwen/Qwen3-VL-4B-Instruct"
# 替换为你想要测试的本地图片路径
image_path = "demo.jpg"
# ================= 加载模型 =================
print("正在加载模型...")
# 自动检测设备 (GPU/CPU)
device = "cuda" if torch.cuda.is_available() else "cpu"
# 加载模型
# device_map="auto": 自动分配显存
# torch_dtype="auto": 自动选择精度 (通常是 bfloat16 或 float16)
model = Qwen3VLForConditionalGeneration.from_pretrained(
model_dir,
torch_dtype="auto",
device_map="auto"
)
# 加载处理器 (用于处理文本和图像)
processor = AutoProcessor.from_pretrained(model_dir)
print("模型加载完成,开始处理图片...")
# ================= 准备输入 =================
# Qwen2-VL 支持本地路径、URL 或 base64
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": image_path,
},
{"type": "text", "text": "请详细描述这张图片的内容。"},
],
}
]
# 准备推理所需的输入格式
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
# 处理视觉信息 (提取图片/视频特征)
image_inputs, video_inputs = process_vision_info(messages)
# 将数据转换为模型输入张量
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
# 将输入移动到模型所在的设备 (GPU)
inputs = inputs.to(model.device)
# ================= 模型推理 =================
print("正在生成回答...")
# 生成回复
generated_ids= model.generate(**inputs, max_new_tokens=512)
# 仅解码新生成的 token (跳过输入的 prompt)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
# ================= 输出结果 =================
print("-" * 20)
print(f"图片路径: {image_path}")
print(f"模型回答: \
{output_text[0]}")
print("-" * 20)
- 输出
python
正在加载模型...
`torch_dtype` is deprecated! Use `dtype` instead!
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:01<00:00, 1.88it/s]
模型加载完成,开始处理图片...
正在生成回答...
--------------------
图片路径: 02.jpg
模型回答: 这张图片展示了......。
- **款式**:......。
- **材质与纹理**:......。
- **剪裁**:......。
- **颜色**:......。
- **构图**:......。
整张图片风格简洁、专业,常用于......。
--------------------三 LLaMA Factory
参考github安装,运行llamafactory-cli webui,然后在页面打开
1 数据准备
主要有alpaca和sharegpt两种格式,这里使用已经提供的alpaca_zh_demo进行测试,直接选中即可。自己的数据集,首先要遵照格式书写,其次要在dataset_info.json中添加说明
如果是按照alapca的形式,包含多个key-value值,可以在dataset_info.json添加数据说明,如下:
默认的格式就是alpaca,可以不写。columns是做了key名称映射,原始数据中的key分别为A,B,C,D,E......,通过此处的映射,将此三处key值映射为instruction,input,output

sharegpt数据格式更复杂一些
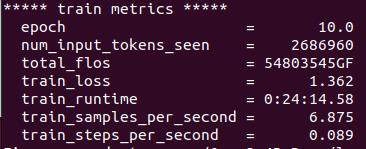
2 开启训练
选择Qwen3-4B-Base模型,通过modelscope下载比较快,会保存到根目录的".cache"路径下
点击Train,数据集选择alpaca_zh_demo,点击预览数据集可以看到数据,一共1000条。
这里选择了10轮,batchsize=10,模型保存到"saves/Qwen3-4B-Base/lora/train***"路径下
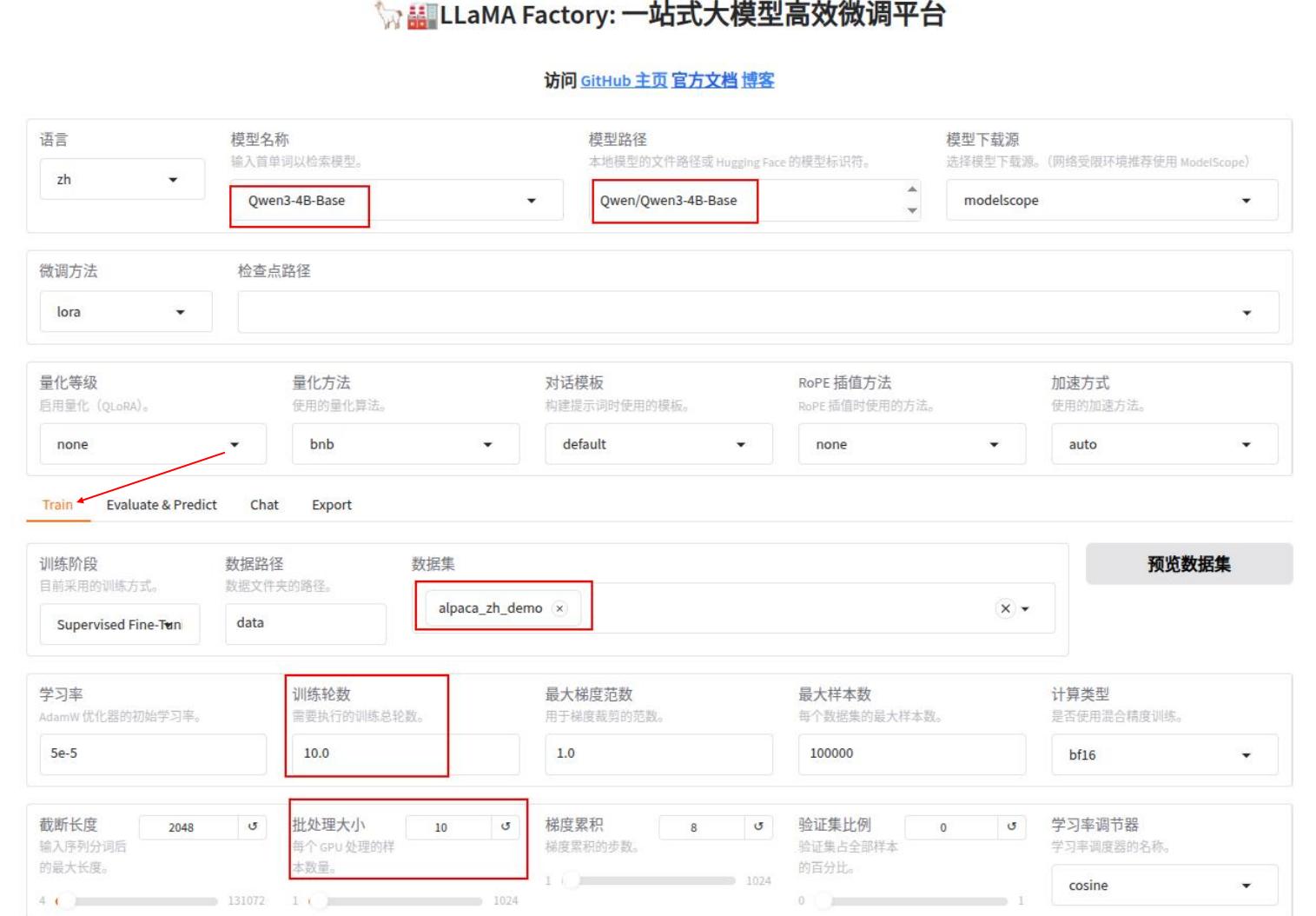
占用显卡约30G,最终loss约1.3,耗时约24min
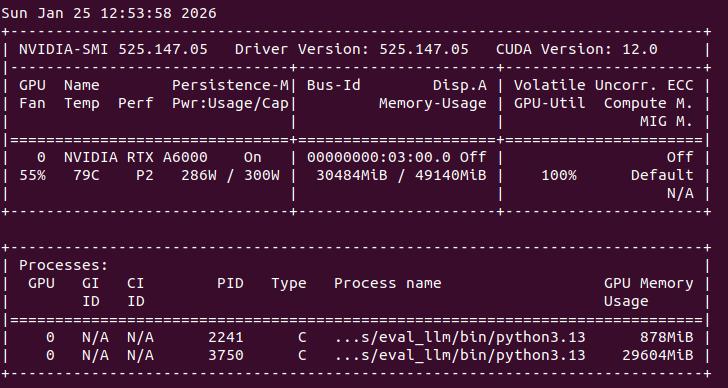
页面的loss曲线
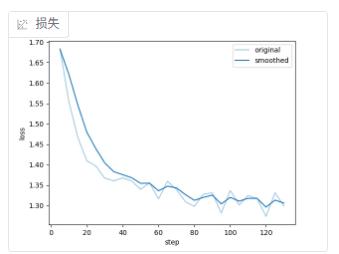
日志最后的输出:
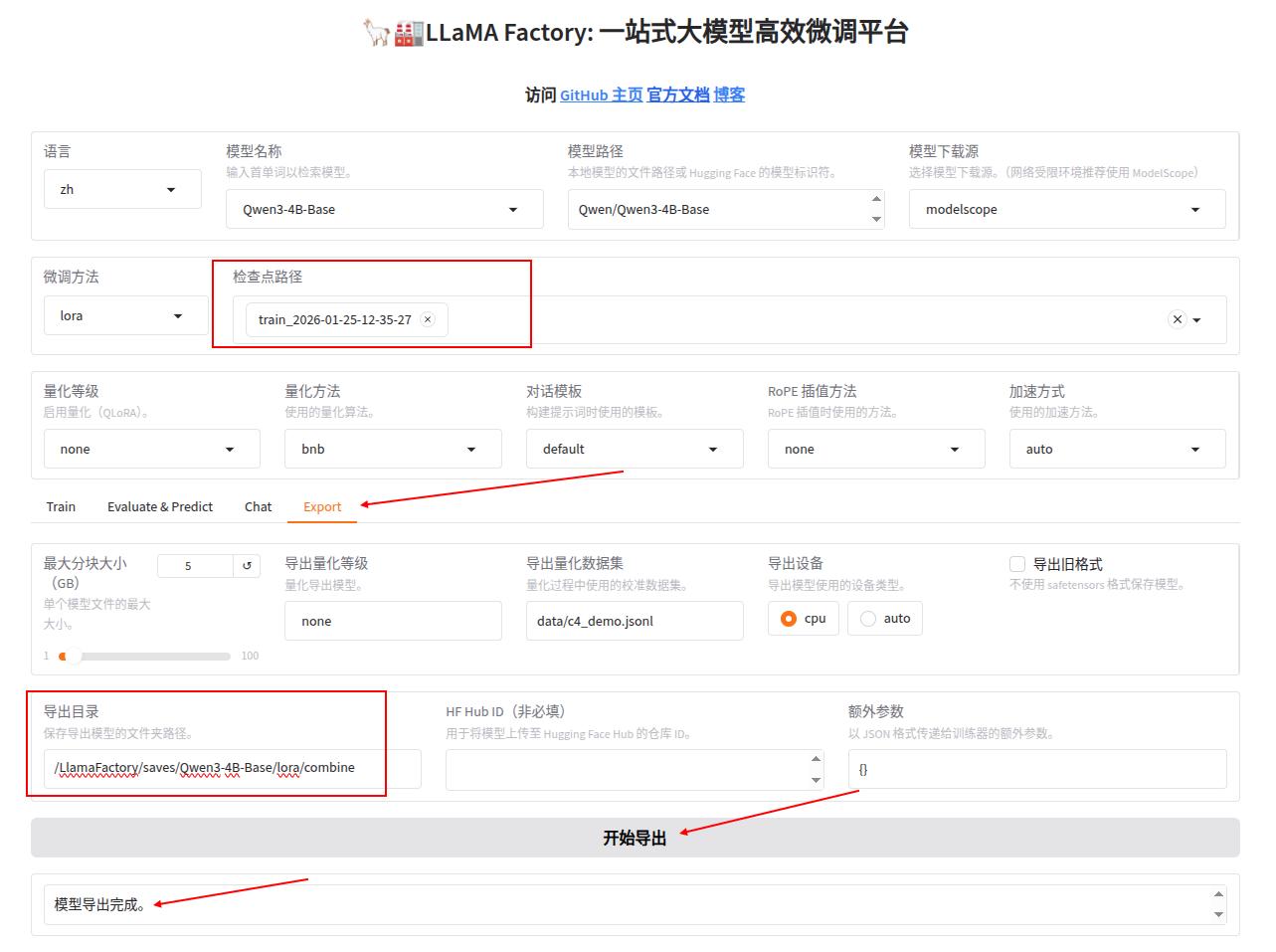
3 模型导出
如图,点击选择Export,选择保存的lora模型的路径,要手动输入导出目录,点击开始导出,就把基座模型和lora模型融合导出了。如果想要量化,则把最上面的模型路径替换为融合后的模型路径,重新到处一份量化模型。
可以使用上面python调用本地模型的代码加载模型测试效果。
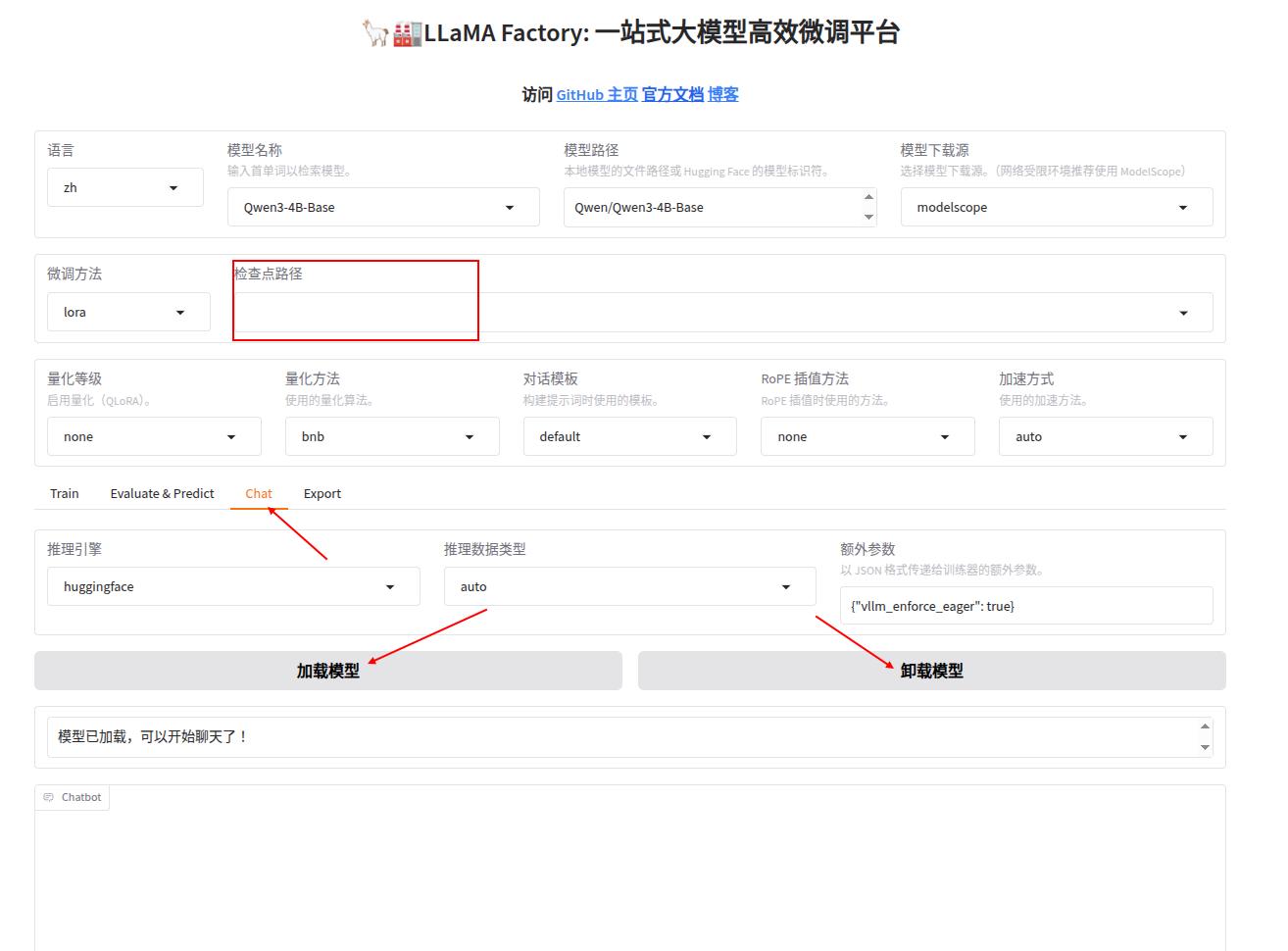
4 聊天对话框
页面支持聊天,选择Chat,点击加载模型,如果切换模型更改模型的话,需要先卸载模型,如果有量化模型的话,可以在检查点路径里面进行添加。
在下面输入框内可以输入提示词进行对话
效果总结
微调的效果不太好,将训练集的instruction作为prompt,输出的数据与output相差较大。不知道是训练配置问题、还是基座模型的问题,还是样例数据质量问题?