硬件与成本:显存预算、吞吐、单次训练成本的工程估算
-
- [01|显存到底花在哪?先把 VRAM 账本拆开](#01|显存到底花在哪?先把 VRAM 账本拆开)
-
- [✅ 训练显存(Training VRAM)六件套](#✅ 训练显存(Training VRAM)六件套)
- [02|推理显存最容易被忽略的"吞金兽":KV Cache](#02|推理显存最容易被忽略的“吞金兽”:KV Cache)
-
- [✅ KV Cache 单 token 显存(通用估算)](#✅ KV Cache 单 token 显存(通用估算))
- [✅ vLLM 允许你"手动卡死 KV Cache 显存"](#✅ vLLM 允许你“手动卡死 KV Cache 显存”)
- [03|seq_len / batch / grad_accum:显存与吞吐的三把"杠杆"](#03|seq_len / batch / grad_accum:显存与吞吐的三把“杠杆”)
- [04|交付物 1:显存估算表(公式版,可直接抄到 Notion/Excel)](#04|交付物 1:显存估算表(公式版,可直接抄到 Notion/Excel))
-
- [4.1 基础符号](#4.1 基础符号)
- [4.2 训练 VRAM 估算(简化)](#4.2 训练 VRAM 估算(简化))
- [4.3 推理 VRAM 估算(简化)](#4.3 推理 VRAM 估算(简化))
- 05|云端成本账本:训练/推理/存储/带宽,一行行拆出来
-
- [5.1 训练成本(最核心)](#5.1 训练成本(最核心))
- [5.2 推理成本(两种模式要分开算)](#5.2 推理成本(两种模式要分开算))
- [5.3 存储/带宽(别忽略)](#5.3 存储/带宽(别忽略))
- [06|交付物 2:成本测算模板(表格,直接复制)](#06|交付物 2:成本测算模板(表格,直接复制))
-
- [6.1 成本模板(MVP)](#6.1 成本模板(MVP))
- [6.2 工程化 KPI(建议你在团队内强制)](#6.2 工程化 KPI(建议你在团队内强制))
- [07|本篇小结:你现在就能做的 3 步](#07|本篇小结:你现在就能做的 3 步)
你做私有模型训练,最常见的翻车不是"不会训",而是:
- 训练到一半 OOM
- 推理上线后 并发一上来就卡爆
- 成本算不清,老板/自己都不敢扩大规模
这篇把"硬件与成本"拆成一套可复用估算方法 :
✅ 显存怎么拆(训练 vs 推理)
✅ seq_len / batch / grad_accum 怎么影响显存与速度
✅ 云端成本账本怎么拆(训练/推理/存储/带宽)
✅ 最后交付:显存估算表(公式)+ 成本测算模板(表格)
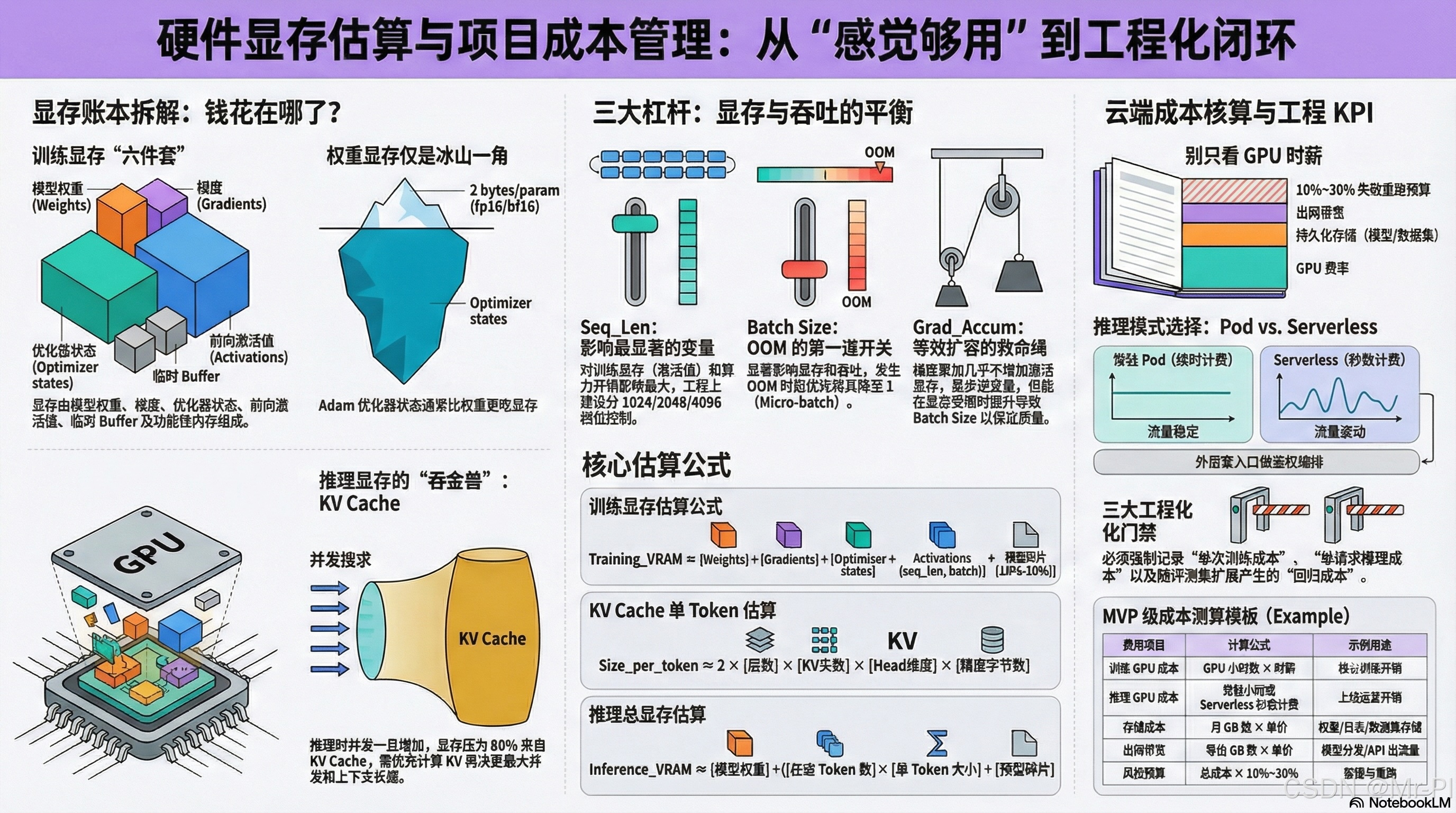
01|显存到底花在哪?先把 VRAM 账本拆开
别再把显存当"一个黑盒"。训练时显存主要由这些部分组成:
权重(weights)/ 优化器状态(optimizer states)/ 梯度(gradients)/ 激活(activations)/ 临时 buffer / 其它功能性内存 。(Hugging Face)
✅ 训练显存(Training VRAM)六件套
- Weights:模型参数本体(fp16/bf16 通常 2 bytes/param)
- Gradients:每个参数的梯度(通常同 weights 精度)
- Optimizer states:Adam 这类优化器会存 m、v 两份状态(通常比 weights 更吃显存)
- Activations :前向激活(反传要用),受 seq_len × batch 影响最大
- Temporary buffers:算子临时内存
- Functionality-specific:比如 checkpointing、特殊算子等
⚡黄金句:
"你以为你在买权重显存,其实你在买激活与优化器显存。"
02|推理显存最容易被忽略的"吞金兽":KV Cache
你上线后突然发现:
模型权重能放下,但并发一上来就爆显存------80% 是 KV Cache。
✅ KV Cache 单 token 显存(通用估算)
在 vLLM 社区讨论中,有一个非常标准的 token 级 KV cache 估算式(以 FP16/BF16 为例):
size_per_token ≈ 2 × layers × kv_heads × head_dim × bytes_per_element (GitHub)
2:K 和 V 两份layers:层数kv_heads:KV heads(GQA 会显著影响)head_dim:每个 head 的维度bytes_per_element:FP16/BF16 = 2 bytes
✅ vLLM 允许你"手动卡死 KV Cache 显存"
vLLM 配置中有 kv_cache_memory_bytes,可精细控制每张 GPU 给 KV cache 的预算;如果设置了它,会忽略 gpu_memory_utilization 的自动推断。(vLLM)
⚡工程建议:
上线时先算 KV 再算权重,再决定最大并发/最大上下文长度。
03|seq_len / batch / grad_accum:显存与吞吐的三把"杠杆"
| 参数 | 对训练显存影响 | 对速度/吞吐影响 | 工程用法 |
|---|---|---|---|
seq_len |
⭐⭐⭐⭐⭐(激活、注意力爆炸) | ⭐⭐⭐⭐(算力开销上升) | 先控它:1024/2048/4096 分档 |
batch_size(micro batch) |
⭐⭐⭐⭐ | ⭐⭐⭐(吞吐↑但更吃显存) | OOM 时先降它到 1 |
grad_accum |
⭐(几乎不增激活) | ⭐⭐(步更慢,但等效 batch↑) | 保吞吐不保显存的救命绳 |
⚡黄金句:
OOM 优先砍 micro-batch;质量不足再用 grad_accum 把等效 batch 拉回来。
04|交付物 1:显存估算表(公式版,可直接抄到 Notion/Excel)
下面给你一套"够用且可解释"的估算公式(不是精确到 MiB,但足够做选卡/选云/定配置)。
4.1 基础符号
P:模型参数量(例如 7B = 7e9)bw:权重字节数(fp16/bf16=2;fp32=4)bg:梯度字节数(通常同bw)bo:优化器状态字节数(Adam 约2 × bw,这是工程近似)A(seq_len, batch):激活显存(强依赖模型结构与 seq_len)M_misc:临时+碎片(建议预留 10%~20%)
4.2 训练 VRAM 估算(简化)
Training_VRAM ≈ P×bw + P×bg + P×bo + A(seq_len,batch) + M_misc
- "权重/梯度/优化器/激活"等拆分思路与训练显存构成一致。(Hugging Face)
✅ QLoRA/LoRA 会把"可训练参数"变少、优化器状态显著下降,显存压力会小很多;QLoRA 论文也强调用 NF4 + double quant + paged optimizer 等组合以控制显存峰值。(arXiv)
4.3 推理 VRAM 估算(简化)
Inference_VRAM ≈ Weights + KV_Cache + M_misc
其中:
Weights ≈ P × bw_inferKV_Cache ≈ tokens_in_flight × size_per_token(见上面 token 公式)(GitHub)
05|云端成本账本:训练/推理/存储/带宽,一行行拆出来
很多项目成本失控的原因就一个:
只算 GPU 时薪,不算存储与带宽,更不算"无效跑"的时间。
5.1 训练成本(最核心)
Train_Cost ≈ GPU_hours × GPU_rate + Storage + Egress
- RunPod 的 GPU 单价以官方 Pricing 为准(不同 GPU 不同)。(Runpod)
5.2 推理成本(两种模式要分开算)
- 常驻 Pods:稳定流量更划算(按小时/秒计费)
- Serverless :流量波动更适合,但要考虑冷启动与单位时间单价(RunPod serverless pricing 有专门说明)。(docs.runpod.io)
⚡工程建议:
训练用 Pods + 持久盘;推理用 vLLM Pods;外层再套 Serverless 入口做鉴权/编排------兼顾成本和上线速度。
5.3 存储/带宽(别忽略)
- 存储:模型权重、checkpoints、数据集、日志、评测产物
- 带宽:拉模型(HF)、上传 checkpoints、对外 API 出流量
06|交付物 2:成本测算模板(表格,直接复制)
你做专栏/项目交付,就把这一张表作为"成本门禁"放进 README。
6.1 成本模板(MVP)
| 项目 | 公式 | 示例/填写 |
|---|---|---|
| 训练 GPU 成本 | GPU_hours × $/hour |
__ × __(查官方价)([Runpod](https://www.runpod.io/pricing?utm_source=chatgpt.com "Pricing |
| 推理 GPU 成本(Pods) | hours × $/hour |
__ × __ |
| 推理 GPU 成本(Serverless) | active_seconds × $/sec |
__ × __ (docs.runpod.io) |
| 存储(数据/权重) | GB_month × $/GB_month |
__ × __ |
| 出网带宽 | GB_egress × $/GB |
__ × __ |
| 失败与重跑预算 | 总成本 × 10%~30% |
__ |
| 总计 | 以上求和 |
__ |
6.2 工程化 KPI(建议你在团队内强制)
- 每次训练都写"单次成本":否则你永远不知道优化值不值
- 每次上线都写"单请求成本":否则你不知道并发上限在哪
- 每次迭代都写"回归成本":评测集扩展会增加推理开销
07|本篇小结:你现在就能做的 3 步
- 按"训练六件套"写出你项目的 Training_VRAM 估算 (先粗略也行)(Hugging Face)
- 用 KV token 公式估算你目标并发下的 KV Cache (推理最易翻车点)(GitHub)
- 把"成本模板表格"贴到 repo,训练前先填一遍------这就是工程闭环的第一道门禁 (Runpod)