基于我之前的内容,ns3-gym就是起到如下的作用:
ns3可执行程序预埋待触发函数,python触发C++对应状态获取、奖励获取函数、环境获取函数,RL迭代后触发对应的action函数,完成完整的控制,如下图所示:
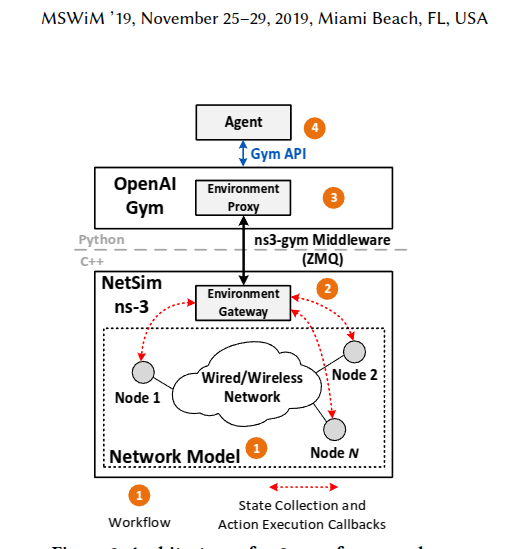
那么具体的流程是咋做的?最基本的预埋操作需要哪些函数?操作opengym的流程是啥?所以我们本文主要看两个例子,一个是最简单的结构与控制,一个是稍微复杂的wifi控制
linear-mesh例子
ns-3.40/contrib/opengym/examples/linear-mesh
遇到了奇怪的情况,直接编译不过:11p、自定义速率数据表、spectrumChannel、spectrumPhy、AdhocWifiMac这些东西在ns3.40里面似乎不兼容------我的研究方向不是11p、不是窄带宽、不是低速率,调了2个小时,不值得调通,替换成标准11n、11ax或者11be。
等效分析
现在的训练本质是: 在一个共享无线信道上, 观察单条 UDP 流(node0 → node4)在 DCF 下的时延/丢包/吞吐, 并让 agent 学速率 / 参数选择。
关键特征只有 3 个:
-
单一竞争域(single collision domain)
-
没有真正的中继转发(逻辑上是一跳)
-
MAC 行为由 DCF 主导,而非路由/调度
计划修改的结构
Node0 : AP + UdpServer
Node1 : STA
Node2 : STA
Node3 : STA
Node4 : STA + UdpClient
保证:5 个节点在同一 WiFi channel、距离足够近(互相可感知)、无 RTS/CTS(或一致开启)
那么:
AP + 4 STA 在 DCF 下 ≈ 5 个 Adhoc 节点竞争
MAC 层统计特性是等价的,对 Gym 观测量(delay / throughput)是等价的
训练 agent 的反馈是:
-
包是否成功
-
接收时延
-
吞吐变化
计划修改的结构中:
-
AP 不做调度
-
没有 EDCA 优先级差异
-
没有 beacon/association 影响业务帧
因此 agent 看到的 因果结构不变。
编译通过的新cc分析
完整源码
cpp
/*
* SPDX-License-Identifier: GPL-2.0-only
*/
#include "ns3/applications-module.h"
#include "ns3/core-module.h"
#include "ns3/internet-module.h"
#include "ns3/mobility-module.h"
#include "ns3/network-module.h"
#include "ns3/point-to-point-module.h"
#include "ns3/ssid.h"
#include "ns3/yans-wifi-helper.h"
#include "ns3/gtk-config-store.h"
#include "ns3/ap-wifi-mac.h"
#include "ns3/txop.h"
#include "ns3/qos-txop.h"
#include "ns3/opengym-module.h"
#include "ns3/wifi-module.h"
#include "ns3/spectrum-module.h"
#include "ns3/stats-module.h"
#include "ns3/flow-monitor-module.h"
#include "ns3/traffic-control-module.h"
#include "ns3/node-list.h"
#include "ns3/csma-module.h"
#include <unordered_map>
#include <vector>
#include "ns3/netanim-module.h"
using namespace ns3;
NS_LOG_COMPONENT_DEFINE("TestModule");
void SetCW(NodeContainer wifiApNodes)
{
Ptr<NetDevice> dev = wifiApNodes.Get(0)->GetDevice(0);
Ptr<WifiNetDevice> wifi_dev = DynamicCast<WifiNetDevice>(dev);
Ptr<WifiMac> mac = wifi_dev->GetMac();
PointerValue ptr;
Ptr<Txop> txop;
if (!mac->GetQosSupported())
{
mac->GetAttribute("Txop", ptr);
txop = ptr.Get<Txop>();
if (txop)
{
uint32_t currentMinCw = txop->GetMinCw();
uint32_t currentMaxCw = txop->GetMaxCw();
std::cout << "Current CWmin: " << currentMinCw << ", CWmax: " << currentMaxCw << std::endl;
uint32_t newMinCw = 2;
uint32_t newMaxCw = 2;
txop->SetMinCw(newMinCw);
txop->SetMaxCw(newMaxCw);
std::cout << "Set CWmin to: " << newMinCw << ", CWmax to: " << newMaxCw << std::endl;
}
}
else
{
mac->GetAttribute("VO_Txop", ptr);
Ptr<QosTxop> vo_txop = ptr.Get<QosTxop>();
mac->GetAttribute("VI_Txop", ptr);
Ptr<QosTxop> vi_txop = ptr.Get<QosTxop>();
mac->GetAttribute("BE_Txop", ptr);
Ptr<QosTxop> be_txop = ptr.Get<QosTxop>();
mac->GetAttribute("BK_Txop", ptr);
Ptr<QosTxop> bk_txop = ptr.Get<QosTxop>();
uint32_t newMinCw = 2;
uint32_t newMaxCw = 2;
be_txop->SetMinCw(newMinCw);
be_txop->SetMaxCw(newMaxCw);
vo_txop->SetMinCw(newMinCw);
vo_txop->SetMaxCw(newMaxCw);
vi_txop->SetMinCw(newMinCw);
vi_txop->SetMaxCw(newMaxCw);
bk_txop->SetMinCw(newMinCw);
bk_txop->SetMaxCw(newMaxCw);
}
}
/*
Define observation space
*/
Ptr<OpenGymSpace> MyGetObservationSpace(void)
{
uint32_t nodeNum = NodeList::GetNNodes();
float low = 0.0;
float high = 888888.0;
std::vector<uint32_t> shape = {
nodeNum,
};
std::string dtype = TypeNameGet<uint32_t>();
Ptr<OpenGymBoxSpace> space = CreateObject<OpenGymBoxSpace>(low, high, shape, dtype);
NS_LOG_UNCOND("MyGetObservationSpace: " << space);
return space;
}
/*
Define action space
*/
Ptr<OpenGymSpace> MyGetActionSpace(void)
{
uint32_t nodeNum = NodeList::GetNNodes();
float low = 0.0;
float high = 666666.0;
std::vector<uint32_t> shape = {
nodeNum,
};
std::string dtype = TypeNameGet<uint32_t>();
Ptr<OpenGymBoxSpace> space = CreateObject<OpenGymBoxSpace>(low, high, shape, dtype);
NS_LOG_UNCOND("MyGetActionSpace: " << space);
return space;
}
/*
Define game over condition
*/
bool MyGetGameOver(void)
{
bool isGameOver = false;
NS_LOG_UNCOND("MyGetGameOver: " << isGameOver);
return isGameOver;
}
Ptr<WifiMacQueue> GetQueue(Ptr<Node> node)
{
Ptr<NetDevice> dev = node->GetDevice(0);
Ptr<WifiNetDevice> wifi_dev = DynamicCast<WifiNetDevice>(dev);
Ptr<WifiMac> wifi_mac = wifi_dev->GetMac();
PointerValue ptr;
wifi_mac->GetAttribute("Txop", ptr);
Ptr<Txop> txop = ptr.Get<Txop>();
Ptr<WifiMacQueue> queue;
if (txop)
{
queue = txop->GetWifiMacQueue();
std::cout << "queue" << queue << std::endl;
}
else
{
wifi_mac->GetAttribute("BE_Txop", ptr);
queue = ptr.Get<QosTxop>()->GetWifiMacQueue();
std::cout << "QosTxop queue" << queue << std::endl;
}
return queue;
}
/*
Collect observations
*/
Ptr<OpenGymDataContainer> MyGetObservation(void)
{
uint32_t nodeNum = NodeList::GetNNodes();
std::vector<uint32_t> shape = {
nodeNum,
};
Ptr<OpenGymBoxContainer<uint32_t>> box = CreateObject<OpenGymBoxContainer<uint32_t>>(shape);
for (NodeList::Iterator i = NodeList::Begin(); i != NodeList::End(); ++i)
{
Ptr<Node> node = *i;
Ptr<WifiMacQueue> queue = GetQueue(node);
uint32_t value = queue->GetNPackets();
box->AddValue(value);
}
NS_LOG_UNCOND("MyGetObservation: " << box);
return box;
}
uint64_t g_rxPktNum = 0;
void DestRxPkt(std::string context, Ptr<const Packet> packet)
{
// NS_LOG_UNCOND ("Client received a packet of " << packet->GetSize () << " bytes"<<"No. "<<g_rxPktNum);
g_rxPktNum++;
}
/*
Define reward function
*/
float MyGetReward(void)
{
static float lastValue = 0.0;
float reward = g_rxPktNum - lastValue;
lastValue = g_rxPktNum;
NS_LOG_UNCOND("reward: " << reward);
return reward;
}
/*
Define extra info. Optional
*/
std::string MyGetExtraInfo(void)
{
std::string myInfo = "linear-wireless-mesh";
myInfo += "|123";
NS_LOG_UNCOND("MyGetExtraInfo: " << myInfo);
return myInfo;
}
bool SetCw(Ptr<Node> node, uint32_t cwMinValue = 0, uint32_t cwMaxValue = 0)
{
Ptr<NetDevice> dev = node->GetDevice(0);
Ptr<WifiNetDevice> wifi_dev = DynamicCast<WifiNetDevice>(dev);
Ptr<WifiMac> wifi_mac = wifi_dev->GetMac();
PointerValue ptr;
wifi_mac->GetAttribute("Txop", ptr);
Ptr<Txop> txop = ptr.Get<Txop>();
NS_LOG_UNCOND("!!!!!!!!!!!txop: " << txop);
if (txop)
{
uint32_t currentMinCw = txop->GetMinCw();
uint32_t currentMaxCw = txop->GetMaxCw();
std::cout << "Current CWmin: " << currentMinCw << ", CWmax: " << currentMaxCw << std::endl;
txop->SetMinCw(cwMinValue);
txop->SetMaxCw(cwMaxValue);
std::cout << "Set CWmin to: " << cwMinValue << ", CWmax to: " << cwMaxValue << std::endl;
}
else
{
wifi_mac->GetAttribute("VO_Txop", ptr);
Ptr<QosTxop> vo_txop = ptr.Get<QosTxop>();
wifi_mac->GetAttribute("VI_Txop", ptr);
Ptr<QosTxop> vi_txop = ptr.Get<QosTxop>();
wifi_mac->GetAttribute("BE_Txop", ptr);
Ptr<QosTxop> be_txop = ptr.Get<QosTxop>();
wifi_mac->GetAttribute("BK_Txop", ptr);
Ptr<QosTxop> bk_txop = ptr.Get<QosTxop>();
uint32_t currentMinCw = be_txop->GetMinCw(0);
uint32_t currentMaxCw = be_txop->GetMaxCw(0);
std::cout << "be_txopCurrent CWmin: " << currentMinCw << ", CWmax: " << currentMaxCw << std::endl;
be_txop->SetMinCw(cwMinValue);
be_txop->SetMaxCw(cwMaxValue);
vo_txop->SetMinCw(cwMinValue);
vo_txop->SetMaxCw(cwMaxValue);
vi_txop->SetMinCw(cwMinValue);
vi_txop->SetMaxCw(cwMaxValue);
bk_txop->SetMinCw(cwMinValue);
bk_txop->SetMaxCw(cwMaxValue);
std::cout << "Set CWmin to: " << cwMinValue << ", CWmax to: " << cwMaxValue << std::endl;
}
return true;
}
/*
Execute received actions
*/
bool MyExecuteActions(Ptr<OpenGymDataContainer> action)
{
NS_LOG_UNCOND("MyExecuteActions: " << action);
Ptr<OpenGymBoxContainer<uint32_t>> box = DynamicCast<OpenGymBoxContainer<uint32_t>>(action);
std::vector<uint32_t> actionVector = box->GetData();
uint32_t nodeNum = NodeList::GetNNodes();
for (uint32_t i = 0; i < nodeNum; i++)
{
Ptr<Node> node = NodeList::GetNode(i);
uint32_t cwSize = actionVector.at(i);
NS_LOG_UNCOND("i=" << i << " ;cwSize: " << cwSize);
SetCw(node, cwSize, cwSize);
}
return true;
}
void ScheduleNextStateRead(double envStepTime, Ptr<OpenGymInterface> openGymInterface)
{
Simulator::Schedule(Seconds(envStepTime), &ScheduleNextStateRead, envStepTime, openGymInterface);
openGymInterface->NotifyCurrentState();
}
int main(int argc, char *argv[])
{
bool verbose = true;
uint32_t nWifi = 4;
bool tracing = false;
uint32_t runNumber = 1;
uint32_t simSeed = 1;
double simulationTime = 3;
double envStepTime = 0.1;
uint32_t openGymPort = 5555;
uint32_t testArg = 0;
CommandLine cmd(__FILE__);
cmd.AddValue("nWifi", "Number of wifi STA devices", nWifi);
cmd.AddValue("verbose", "Tell echo applications to log if true", verbose);
cmd.AddValue("tracing", "Enable pcap tracing", tracing);
cmd.AddValue("runNumber", "Random runNumber", runNumber);
cmd.AddValue("openGymPort", "Port number for OpenGym env. Default: 5555", openGymPort);
cmd.AddValue("simSeed", "Seed for random generator. Default: 1", simSeed);
cmd.AddValue("simTime", "Simulation time in seconds. Default: 10s", simulationTime);
cmd.AddValue("testArg", "Extra simulation argument. Default: 0", testArg);
cmd.Parse(argc, argv);
RngSeedManager::SetSeed(22);
RngSeedManager::SetRun(simSeed);
NS_LOG_UNCOND("Ns3Env parameters:");
NS_LOG_UNCOND("--simulationTime: " << simulationTime);
NS_LOG_UNCOND("--openGymPort: " << openGymPort);
NS_LOG_UNCOND("--envStepTime: " << envStepTime);
NS_LOG_UNCOND("--seed: " << simSeed);
NS_LOG_UNCOND("--testArg: " << testArg);
NS_LOG_UNCOND("--runNumber: " << runNumber);
NodeContainer wifiApNode;
wifiApNode.Create(1);
NodeContainer wifiStaNodes;
wifiStaNodes.Create(nWifi);
YansWifiChannelHelper channel = YansWifiChannelHelper::Default();
YansWifiPhyHelper phy;
phy.SetChannel(channel.Create());
phy.SetPcapDataLinkType(WifiPhyHelper::DLT_IEEE802_11_RADIO);
phy.Set("ChannelSettings", StringValue("{36, 20, BAND_5GHZ, 0}"));
WifiMacHelper mac;
Ssid ssid = Ssid("ns-3-ssid");
WifiHelper wifi;
wifi.SetStandard(WIFI_STANDARD_80211ax);
wifi.SetRemoteStationManager("ns3::ConstantRateWifiManager",
"DataMode", StringValue("HeMcs0"),
"ControlMode", StringValue("HeMcs0"));
wifi.ConfigHeOptions("GuardInterval", TimeValue(NanoSeconds(1600)));
NetDeviceContainer staDevices;
mac.SetType("ns3::StaWifiMac", "Ssid", SsidValue(ssid), "ActiveProbing", BooleanValue(false), "BE_MaxAmsduSize",
UintegerValue(0),
"BE_MaxAmpduSize",
UintegerValue(0));
staDevices = wifi.Install(phy, mac, wifiStaNodes);
NetDeviceContainer apDevices;
mac.SetType(
"ns3::ApWifiMac",
"Ssid",
SsidValue(ssid),
"BeaconInterval",
TimeValue(MicroSeconds(102400)), "BE_MaxAmsduSize",
UintegerValue(0),
"BE_MaxAmpduSize",
UintegerValue(0));
apDevices = wifi.Install(phy, mac, wifiApNode);
MobilityHelper mobility;
mobility.SetPositionAllocator("ns3::GridPositionAllocator",
"MinX",
DoubleValue(0.0),
"MinY",
DoubleValue(1.0),
"DeltaX",
DoubleValue(1.0),
"DeltaY",
DoubleValue(1.0),
"GridWidth",
UintegerValue(7),
"LayoutType",
StringValue("RowFirst"));
mobility.SetMobilityModel("ns3::RandomWalk2dMobilityModel",
"Mode",
StringValue("Time"),
"Time",
StringValue("0.2s"),
"Speed",
StringValue("ns3::ConstantRandomVariable[Constant=1.0]"),
"Bounds",
RectangleValue(Rectangle(-500, 500, -500, 500)));
mobility.Install(wifiStaNodes);
mobility.SetMobilityModel("ns3::ConstantPositionMobilityModel");
mobility.Install(wifiApNode);
InternetStackHelper stack;
stack.Install(wifiApNode);
stack.Install(wifiStaNodes);
Ipv4AddressHelper address;
address.SetBase("10.1.1.0", "255.255.255.0");
Ipv4InterfaceContainer apInterfaces;
apInterfaces = address.Assign(apDevices);
Ipv4InterfaceContainer staInterfaces;
staInterfaces = address.Assign(staDevices);
UdpServerHelper echoServer(9);
ApplicationContainer serverApps = echoServer.Install(wifiApNode.Get(0));
serverApps.Start(Seconds(0));
serverApps.Stop(Seconds(simulationTime));
UdpClientHelper Client_node1(apInterfaces.GetAddress(0), 9);
Client_node1.SetAttribute("MaxPackets", UintegerValue(1000000000));
Client_node1.SetAttribute("Interval", TimeValue(Seconds(0.0002)));
Client_node1.SetAttribute("PacketSize", UintegerValue(1000));
UdpClientHelper Client_other(apInterfaces.GetAddress(0), 9);
Client_other.SetAttribute("MaxPackets", UintegerValue(1000000000));
Client_other.SetAttribute("Interval", TimeValue(Seconds(0.0002)));
Client_other.SetAttribute("PacketSize", UintegerValue(1000));
ApplicationContainer clientApps;
clientApps.Add(Client_node1.Install(wifiStaNodes.Get(0)));
for (uint32_t i = 1; i < wifiStaNodes.GetN(); i++)
{
clientApps.Add(Client_other.Install(wifiStaNodes.Get(i)));
}
clientApps.Start(Seconds(0));
clientApps.Stop(Seconds(simulationTime));
Ipv4GlobalRoutingHelper::PopulateRoutingTables();
SetCW(wifiApNode);
for (uint32_t i = 0; i < nWifi; i++)
SetCW(wifiStaNodes.Get(i));
Config::Connect("/NodeList/0/ApplicationList/*/$ns3::UdpServer/Rx", MakeCallback(&DestRxPkt));
if (tracing)
{
phy.EnablePcap("third", apDevices.Get(0));
}
Ptr<OpenGymInterface> openGymInterface = CreateObject<OpenGymInterface>(openGymPort);
openGymInterface->SetGetActionSpaceCb(MakeCallback(&MyGetActionSpace));
openGymInterface->SetGetObservationSpaceCb(MakeCallback(&MyGetObservationSpace));
openGymInterface->SetGetGameOverCb(MakeCallback(&MyGetGameOver));
openGymInterface->SetGetObservationCb(MakeCallback(&MyGetObservation));
openGymInterface->SetGetRewardCb(MakeCallback(&MyGetReward));
openGymInterface->SetGetExtraInfoCb(MakeCallback(&MyGetExtraInfo));
openGymInterface->SetExecuteActionsCb(MakeCallback(&MyExecuteActions));
Simulator::Schedule(Seconds(0.0), &ScheduleNextStateRead, envStepTime, openGymInterface);
NS_LOG_UNCOND("Simulation start");
AnimationInterface anim("complex-bridge.xml");
for (uint32_t i = 1; i < wifiStaNodes.GetN(); i++) {
anim.UpdateNodeDescription(wifiStaNodes.Get(i), "STA");
anim.UpdateNodeColor(wifiStaNodes.Get(i), 255, 0, 0);
}
anim.UpdateNodeDescription(wifiStaNodes.Get(0), "TargetSTA");
anim.UpdateNodeColor(wifiStaNodes.Get(0), 255, 255, 0);
anim.UpdateNodeDescription(wifiApNode.Get(0), "AP");
anim.UpdateNodeColor(wifiApNode.Get(0), 0, 255, 0);
Simulator::Stop(Seconds(simulationTime));
Simulator::Run();
NS_LOG_UNCOND("Simulation stop");
openGymInterface->NotifySimulationEnd();
return 0;
}Cmakelists文件修改
注意,这里仅仅与NetAnim有关,如果不需要看看STA的随机移动路径,注释掉也没有任何影响。
${libnetanim}是新加入的,ns3中编译可执行程序需要链接对应库,scratch里面在Cmakelists.txt里面已经做了广泛的引用
但对于contrib这里面的可执行文件,需要手动链接一下。
cpp
build_lib_example(
NAME linear-mesh
SOURCE_FILES linear-mesh/sim.cc
LIBRARIES_TO_LINK
${libapplications}
${libcore}
${libinternet}
${libopengym}
${libwifi}
${libnetanim}
)头文件引用与函数声明
cpp
#include "ns3/applications-module.h"
#include "ns3/core-module.h"
#include "ns3/internet-module.h"
#include "ns3/mobility-module.h"
#include "ns3/network-module.h"
#include "ns3/point-to-point-module.h"
#include "ns3/ssid.h"
#include "ns3/yans-wifi-helper.h"
#include "ns3/ap-wifi-mac.h"
#include "ns3/txop.h"
#include "ns3/qos-txop.h"
#include "ns3/opengym-module.h"
#include "ns3/wifi-module.h"
#include "ns3/spectrum-module.h"
#include "ns3/stats-module.h"
#include "ns3/flow-monitor-module.h"
#include "ns3/traffic-control-module.h"
#include "ns3/node-list.h"
#include "ns3/csma-module.h"
#include <unordered_map>
#include <vector>
#include "ns3/netanim-module.h"
using namespace ns3;
NS_LOG_COMPONENT_DEFINE("TestModule");
void SetCW(NodeContainer wifiApNodes)
{
Ptr<NetDevice> dev = wifiApNodes.Get(0)->GetDevice(0);
Ptr<WifiNetDevice> wifi_dev = DynamicCast<WifiNetDevice>(dev);
Ptr<WifiMac> mac = wifi_dev->GetMac();
PointerValue ptr;
Ptr<Txop> txop;
if (!mac->GetQosSupported())
{
mac->GetAttribute("Txop", ptr);
txop = ptr.Get<Txop>();
if (txop)
{
uint32_t currentMinCw = txop->GetMinCw();
uint32_t currentMaxCw = txop->GetMaxCw();
std::cout << "Current CWmin: " << currentMinCw << ", CWmax: " << currentMaxCw << std::endl;
uint32_t newMinCw = 2;
uint32_t newMaxCw = 2;
txop->SetMinCw(newMinCw);
txop->SetMaxCw(newMaxCw);
std::cout << "Set CWmin to: " << newMinCw << ", CWmax to: " << newMaxCw << std::endl;
}
}
else
{
mac->GetAttribute("VO_Txop", ptr);
Ptr<QosTxop> vo_txop = ptr.Get<QosTxop>();
mac->GetAttribute("VI_Txop", ptr);
Ptr<QosTxop> vi_txop = ptr.Get<QosTxop>();
mac->GetAttribute("BE_Txop", ptr);
Ptr<QosTxop> be_txop = ptr.Get<QosTxop>();
mac->GetAttribute("BK_Txop", ptr);
Ptr<QosTxop> bk_txop = ptr.Get<QosTxop>();
uint32_t newMinCw = 2;
uint32_t newMaxCw = 2;
be_txop->SetMinCw(newMinCw);
be_txop->SetMaxCw(newMaxCw);
vo_txop->SetMinCw(newMinCw);
vo_txop->SetMaxCw(newMaxCw);
vi_txop->SetMinCw(newMinCw);
vi_txop->SetMaxCw(newMaxCw);
bk_txop->SetMinCw(newMinCw);
bk_txop->SetMaxCw(newMaxCw);
}
}
/*
Define observation space
*/
Ptr<OpenGymSpace> MyGetObservationSpace(void)
{
uint32_t nodeNum = NodeList::GetNNodes();
float low = 0.0;
float high = 888888.0;
std::vector<uint32_t> shape = {
nodeNum,
};
std::string dtype = TypeNameGet<uint32_t>();
Ptr<OpenGymBoxSpace> space = CreateObject<OpenGymBoxSpace>(low, high, shape, dtype);
NS_LOG_UNCOND("MyGetObservationSpace: " << space);
return space;
}
/*
Define action space
*/
Ptr<OpenGymSpace> MyGetActionSpace(void)
{
uint32_t nodeNum = NodeList::GetNNodes();
float low = 0.0;
float high = 666666.0;
std::vector<uint32_t> shape = {
nodeNum,
};
std::string dtype = TypeNameGet<uint32_t>();
Ptr<OpenGymBoxSpace> space = CreateObject<OpenGymBoxSpace>(low, high, shape, dtype);
NS_LOG_UNCOND("MyGetActionSpace: " << space);
return space;
}
/*
Define game over condition
*/
bool MyGetGameOver(void)
{
bool isGameOver = false;
NS_LOG_UNCOND("MyGetGameOver: " << isGameOver);
return isGameOver;
}
Ptr<WifiMacQueue> GetQueue(Ptr<Node> node)
{
Ptr<NetDevice> dev = node->GetDevice(0);
Ptr<WifiNetDevice> wifi_dev = DynamicCast<WifiNetDevice>(dev);
Ptr<WifiMac> wifi_mac = wifi_dev->GetMac();
PointerValue ptr;
wifi_mac->GetAttribute("Txop", ptr);
Ptr<Txop> txop = ptr.Get<Txop>();
Ptr<WifiMacQueue> queue;
if (txop)
{
queue = txop->GetWifiMacQueue();
std::cout << "queue" << queue << std::endl;
}
else
{
wifi_mac->GetAttribute("BE_Txop", ptr);
queue = ptr.Get<QosTxop>()->GetWifiMacQueue();
std::cout << "QosTxop queue" << queue << std::endl;
}
return queue;
}
/*
Collect observations
*/
Ptr<OpenGymDataContainer> MyGetObservation(void)
{
uint32_t nodeNum = NodeList::GetNNodes();
std::vector<uint32_t> shape = {
nodeNum,
};
Ptr<OpenGymBoxContainer<uint32_t>> box = CreateObject<OpenGymBoxContainer<uint32_t>>(shape);
for (NodeList::Iterator i = NodeList::Begin(); i != NodeList::End(); ++i)
{
Ptr<Node> node = *i;
Ptr<WifiMacQueue> queue = GetQueue(node);
uint32_t value = queue->GetNPackets();
box->AddValue(value);
}
NS_LOG_UNCOND("MyGetObservation: " << box);
return box;
}
uint64_t g_rxPktNum = 0;
void DestRxPkt(std::string context, Ptr<const Packet> packet)
{
// NS_LOG_UNCOND ("Client received a packet of " << packet->GetSize () << " bytes"<<"No. "<<g_rxPktNum);
g_rxPktNum++;
}
/*
Define reward function
*/
float MyGetReward(void)
{
static float lastValue = 0.0;
float reward = g_rxPktNum - lastValue;
lastValue = g_rxPktNum;
NS_LOG_UNCOND("reward: " << reward);
return reward;
}
/*
Define extra info. Optional
*/
std::string MyGetExtraInfo(void)
{
std::string myInfo = "linear-wireless-mesh";
myInfo += "|123";
NS_LOG_UNCOND("MyGetExtraInfo: " << myInfo);
return myInfo;
}
bool SetCw(Ptr<Node> node, uint32_t cwMinValue = 0, uint32_t cwMaxValue = 0)
{
Ptr<NetDevice> dev = node->GetDevice(0);
Ptr<WifiNetDevice> wifi_dev = DynamicCast<WifiNetDevice>(dev);
Ptr<WifiMac> wifi_mac = wifi_dev->GetMac();
PointerValue ptr;
wifi_mac->GetAttribute("Txop", ptr);
Ptr<Txop> txop = ptr.Get<Txop>();
NS_LOG_UNCOND("!!!!!!!!!!!txop: " << txop);
if (txop)
{
uint32_t currentMinCw = txop->GetMinCw();
uint32_t currentMaxCw = txop->GetMaxCw();
std::cout << "Current CWmin: " << currentMinCw << ", CWmax: " << currentMaxCw << std::endl;
txop->SetMinCw(cwMinValue);
txop->SetMaxCw(cwMaxValue);
std::cout << "Set CWmin to: " << cwMinValue << ", CWmax to: " << cwMaxValue << std::endl;
}
else
{
wifi_mac->GetAttribute("VO_Txop", ptr);
Ptr<QosTxop> vo_txop = ptr.Get<QosTxop>();
wifi_mac->GetAttribute("VI_Txop", ptr);
Ptr<QosTxop> vi_txop = ptr.Get<QosTxop>();
wifi_mac->GetAttribute("BE_Txop", ptr);
Ptr<QosTxop> be_txop = ptr.Get<QosTxop>();
wifi_mac->GetAttribute("BK_Txop", ptr);
Ptr<QosTxop> bk_txop = ptr.Get<QosTxop>();
uint32_t currentMinCw = be_txop->GetMinCw(0);
uint32_t currentMaxCw = be_txop->GetMaxCw(0);
std::cout << "be_txopCurrent CWmin: " << currentMinCw << ", CWmax: " << currentMaxCw << std::endl;
be_txop->SetMinCw(cwMinValue);
be_txop->SetMaxCw(cwMaxValue);
vo_txop->SetMinCw(cwMinValue);
vo_txop->SetMaxCw(cwMaxValue);
vi_txop->SetMinCw(cwMinValue);
vi_txop->SetMaxCw(cwMaxValue);
bk_txop->SetMinCw(cwMinValue);
bk_txop->SetMaxCw(cwMaxValue);
std::cout << "Set CWmin to: " << cwMinValue << ", CWmax to: " << cwMaxValue << std::endl;
}
return true;
}
/*
Execute received actions
*/
bool MyExecuteActions(Ptr<OpenGymDataContainer> action)
{
NS_LOG_UNCOND("MyExecuteActions: " << action);
Ptr<OpenGymBoxContainer<uint32_t>> box = DynamicCast<OpenGymBoxContainer<uint32_t>>(action);
std::vector<uint32_t> actionVector = box->GetData();
uint32_t nodeNum = NodeList::GetNNodes();
for (uint32_t i = 0; i < nodeNum; i++)
{
Ptr<Node> node = NodeList::GetNode(i);
uint32_t cwSize = actionVector.at(i);
NS_LOG_UNCOND("i=" << i << " ;cwSize: " << cwSize);
SetCw(node, cwSize, cwSize);
}
return true;
}
void ScheduleNextStateRead(double envStepTime, Ptr<OpenGymInterface> openGymInterface)
{
Simulator::Schedule(Seconds(envStepTime), &ScheduleNextStateRead, envStepTime, openGymInterface);
openGymInterface->NotifyCurrentState();
}头文件
头文件包含基础h和udp、ipv4、移动性、点对点device、ssid、WiFiphy、WIfiMac、opengym、netanim
全局CW初始化(似乎没啥必要,但保留了)
void SetCW(NodeContainer wifiApNodes),后续调用时初始化为了2,函数目的是使得最开始的动作是2,这样起始的reward更低,现象更明显(但似乎效果一般,因为每个episode有30step,大约两个step,action就把CW改到远大于2的值了)
设置观察空间和动作空间
Ptr<OpenGymSpace> MyGetObservationSpace(void)观察对象是
Ptr<OpenGymSpace> MyGetActionSpace(void)
结束状态配置
bool MyGetGameOver(void)一直返回false,因为本实验没有所谓"游戏失败",因为不管怎么选action,都不会导致传输完全不能进行。
当然可以设置延时太大、吞吐太小、丢包太多作为结束状态,但是我们的例子只是想看到映射关系和训练过程,所以这个还是false,直到一轮ns3仿真结束接口会自动产生true通知python。
状态环境获取
Ptr<OpenGymDataContainer> MyGetObservation(void)调用Ptr<WifiMacQueue> GetQueue(Ptr<Node> node)
MyGetObservation遍历NodeList,拿到每个Node的WiFiMac的queue当前包数目,包越多越说明阻塞,需要响应的减小CW,可以加强竞争、获得更多的接入机会,消耗掉过多的包
GetQueue函数通过DynamicCast获得每一个Node的WiFiMac的queue指针并返回。
奖励获取
DestRxPkt会在UDP收到数据包的时候触发、收到一个包就触发一次,g_rxPktNum就增加一个
MyGetReward通过static float lastValue保存前一个step的收到包数目,每个step的reward就是此step中AP新收到的包数目,通过调节CW,也就是action,最终目的是最大化每个step的收到包数目,也就是奖励,更加细节地,每个step,agent都会根据看到的各个Node的队列长度,尝试调节各个Node的CW,使得AP收到的包最多。
其他信息
此处没有有用的内容,打印类似helloworld的信息"linear-wireless-mesh|123"。
执行动作
MyExecuteActions调用SetCw,MyExecuteActions把动作向量一一实现,比如我有50个STA,action返回的就是一个长度50的类似数组的动作集合,根据各个Node的编号,设置这些Node 的CW值,SetCw通过Node找到WifiMac的指针、获取txop指针、设置对应CW,实现了Action到CW设置的映射。
节拍控制
cpp
void ScheduleNextStateRead(double envStepTime, Ptr<OpenGymInterface> openGym)
{
Simulator::Schedule (Seconds(envStepTime), &ScheduleNextStateRead, envStepTime, openGym);
openGym->NotifyCurrentState();
}这部分是最重要的,main函数0.0s触发此函数,此函数每envStepTime时间自我触发一次,被触发时调用的是NotifyCurrentState
cpp
void
OpenGymInterface::NotifyCurrentState()
{
NS_LOG_FUNCTION (this);
if (!m_initSimMsgSent) {
Init();
}
if (m_stopEnvRequested) {
return;
}
// collect current env state
Ptr<OpenGymDataContainer> obsDataContainer = GetObservation();
float reward = GetReward();
bool isGameOver = IsGameOver();
std::string extraInfo = GetExtraInfo();
ns3opengym::EnvStateMsg envStateMsg;
// observation
ns3opengym::DataContainer obsDataContainerPbMsg;
if (obsDataContainer) {
obsDataContainerPbMsg = obsDataContainer->GetDataContainerPbMsg();
envStateMsg.mutable_obsdata()->CopyFrom(obsDataContainerPbMsg);
}
// reward
envStateMsg.set_reward(reward);
// game over
envStateMsg.set_isgameover(false);
if (isGameOver)
{
envStateMsg.set_isgameover(true);
if (m_simEnd) {
envStateMsg.set_reason(ns3opengym::EnvStateMsg::SimulationEnd);
} else {
envStateMsg.set_reason(ns3opengym::EnvStateMsg::GameOver);
}
}
// extra info
envStateMsg.set_info(extraInfo);
// send env state msg to python
zmq::message_t request(envStateMsg.ByteSizeLong());;
envStateMsg.SerializeToArray(request.data(), envStateMsg.ByteSizeLong());
m_zmq_socket.send (request, zmq::send_flags::none);
// receive act msg form python
ns3opengym::EnvActMsg envActMsg;
zmq::message_t reply;
(void) m_zmq_socket.recv (reply, zmq::recv_flags::none);
envActMsg.ParseFromArray(reply.data(), reply.size());
if (m_simEnd) {
// if sim end only rx ms and quit
return;
}
bool stopSim = envActMsg.stopsimreq();
if (stopSim) {
NS_LOG_DEBUG("---Stop requested: " << stopSim);
m_stopEnvRequested = true;
Simulator::Stop();
Simulator::Destroy ();
std::exit(0);
}
// first step after reset is called without actions, just to get current state
ns3opengym::DataContainer actDataContainerPbMsg = envActMsg.actdata();
Ptr<OpenGymDataContainer> actDataContainer = OpenGymDataContainer::CreateFromDataContainerPbMsg(actDataContainerPbMsg);
ExecuteActions(actDataContainer);
}其中m_zmq_socket.recv函数是阻塞的,也就是0.0s时,ns3就开始等python的socket消息了,等不到就不往下走了------每次python step就会发一次python的socket消息,也就是python step一次这边ns3就往前走envStepTime,然后再重新开始等socket消息。
主函数与Wifi环境配置
cpp
int main(int argc, char *argv[])
{
bool verbose = true;
uint32_t nWifi = 4;
bool tracing = false;
uint32_t runNumber = 1;
uint32_t simSeed = 1;
double simulationTime = 3;
double envStepTime = 0.1;
uint32_t openGymPort = 5555;
uint32_t testArg = 0;
CommandLine cmd(__FILE__);
cmd.AddValue("nWifi", "Number of wifi STA devices", nWifi);
cmd.AddValue("verbose", "Tell echo applications to log if true", verbose);
cmd.AddValue("tracing", "Enable pcap tracing", tracing);
cmd.AddValue("runNumber", "Random runNumber", runNumber);
cmd.AddValue("openGymPort", "Port number for OpenGym env. Default: 5555", openGymPort);
cmd.AddValue("simSeed", "Seed for random generator. Default: 1", simSeed);
cmd.AddValue("simTime", "Simulation time in seconds. Default: 10s", simulationTime);
cmd.AddValue("testArg", "Extra simulation argument. Default: 0", testArg);
cmd.Parse(argc, argv);
RngSeedManager::SetSeed(22);
RngSeedManager::SetRun(simSeed);
NS_LOG_UNCOND("Ns3Env parameters:");
NS_LOG_UNCOND("--simulationTime: " << simulationTime);
NS_LOG_UNCOND("--openGymPort: " << openGymPort);
NS_LOG_UNCOND("--envStepTime: " << envStepTime);
NS_LOG_UNCOND("--seed: " << simSeed);
NS_LOG_UNCOND("--testArg: " << testArg);
NS_LOG_UNCOND("--runNumber: " << runNumber);
NodeContainer wifiApNode;
wifiApNode.Create(1);
NodeContainer wifiStaNodes;
wifiStaNodes.Create(nWifi);
YansWifiChannelHelper channel = YansWifiChannelHelper::Default();
YansWifiPhyHelper phy;
phy.SetChannel(channel.Create());
phy.SetPcapDataLinkType(WifiPhyHelper::DLT_IEEE802_11_RADIO);
phy.Set("ChannelSettings", StringValue("{36, 20, BAND_5GHZ, 0}"));
WifiMacHelper mac;
Ssid ssid = Ssid("ns-3-ssid");
WifiHelper wifi;
wifi.SetStandard(WIFI_STANDARD_80211ax);
wifi.SetRemoteStationManager("ns3::ConstantRateWifiManager",
"DataMode", StringValue("HeMcs0"),
"ControlMode", StringValue("HeMcs0"));
wifi.ConfigHeOptions("GuardInterval", TimeValue(NanoSeconds(1600)));
NetDeviceContainer staDevices;
mac.SetType("ns3::StaWifiMac", "Ssid", SsidValue(ssid), "ActiveProbing", BooleanValue(false), "BE_MaxAmsduSize",
UintegerValue(0),
"BE_MaxAmpduSize",
UintegerValue(0));
staDevices = wifi.Install(phy, mac, wifiStaNodes);
NetDeviceContainer apDevices;
mac.SetType(
"ns3::ApWifiMac",
"Ssid",
SsidValue(ssid),
"BeaconInterval",
TimeValue(MicroSeconds(102400)), "BE_MaxAmsduSize",
UintegerValue(0),
"BE_MaxAmpduSize",
UintegerValue(0));
apDevices = wifi.Install(phy, mac, wifiApNode);
MobilityHelper mobility;
mobility.SetPositionAllocator("ns3::GridPositionAllocator",
"MinX",
DoubleValue(0.0),
"MinY",
DoubleValue(1.0),
"DeltaX",
DoubleValue(1.0),
"DeltaY",
DoubleValue(1.0),
"GridWidth",
UintegerValue(7),
"LayoutType",
StringValue("RowFirst"));
mobility.SetMobilityModel("ns3::RandomWalk2dMobilityModel",
"Mode",
StringValue("Time"),
"Time",
StringValue("0.2s"),
"Speed",
StringValue("ns3::ConstantRandomVariable[Constant=1.0]"),
"Bounds",
RectangleValue(Rectangle(-500, 500, -500, 500)));
mobility.Install(wifiStaNodes);
mobility.SetMobilityModel("ns3::ConstantPositionMobilityModel");
mobility.Install(wifiApNode);
InternetStackHelper stack;
stack.Install(wifiApNode);
stack.Install(wifiStaNodes);
Ipv4AddressHelper address;
address.SetBase("10.1.1.0", "255.255.255.0");
Ipv4InterfaceContainer apInterfaces;
apInterfaces = address.Assign(apDevices);
Ipv4InterfaceContainer staInterfaces;
staInterfaces = address.Assign(staDevices);
UdpServerHelper echoServer(9);
ApplicationContainer serverApps = echoServer.Install(wifiApNode.Get(0));
serverApps.Start(Seconds(0));
serverApps.Stop(Seconds(simulationTime));
UdpClientHelper Client_node1(apInterfaces.GetAddress(0), 9);
Client_node1.SetAttribute("MaxPackets", UintegerValue(1000000000));
Client_node1.SetAttribute("Interval", TimeValue(Seconds(0.0002)));
Client_node1.SetAttribute("PacketSize", UintegerValue(1000));
UdpClientHelper Client_other(apInterfaces.GetAddress(0), 9);
Client_other.SetAttribute("MaxPackets", UintegerValue(1000000000));
Client_other.SetAttribute("Interval", TimeValue(Seconds(0.0002)));
Client_other.SetAttribute("PacketSize", UintegerValue(1000));
ApplicationContainer clientApps;
clientApps.Add(Client_node1.Install(wifiStaNodes.Get(0)));
for (uint32_t i = 1; i < wifiStaNodes.GetN(); i++)
{
clientApps.Add(Client_other.Install(wifiStaNodes.Get(i)));
}
clientApps.Start(Seconds(0));
clientApps.Stop(Seconds(simulationTime));
Ipv4GlobalRoutingHelper::PopulateRoutingTables();
SetCW(wifiApNode);
for (uint32_t i = 0; i < nWifi; i++)
SetCW(wifiStaNodes.Get(i));
Config::Connect("/NodeList/0/ApplicationList/*/$ns3::UdpServer/Rx", MakeCallback(&DestRxPkt));
if (tracing)
{
phy.EnablePcap("third", apDevices.Get(0));
}
Ptr<OpenGymInterface> openGymInterface = CreateObject<OpenGymInterface>(openGymPort);
openGymInterface->SetGetActionSpaceCb(MakeCallback(&MyGetActionSpace));
openGymInterface->SetGetObservationSpaceCb(MakeCallback(&MyGetObservationSpace));
openGymInterface->SetGetGameOverCb(MakeCallback(&MyGetGameOver));
openGymInterface->SetGetObservationCb(MakeCallback(&MyGetObservation));
openGymInterface->SetGetRewardCb(MakeCallback(&MyGetReward));
openGymInterface->SetGetExtraInfoCb(MakeCallback(&MyGetExtraInfo));
openGymInterface->SetExecuteActionsCb(MakeCallback(&MyExecuteActions));
Simulator::Schedule(Seconds(0.0), &ScheduleNextStateRead, envStepTime, openGymInterface);
NS_LOG_UNCOND("Simulation start");
AnimationInterface anim("complex-bridge.xml");
for (uint32_t i = 1; i < wifiStaNodes.GetN(); i++) {
anim.UpdateNodeDescription(wifiStaNodes.Get(i), "STA");
anim.UpdateNodeColor(wifiStaNodes.Get(i), 255, 0, 0);
}
anim.UpdateNodeDescription(wifiStaNodes.Get(0), "TargetSTA");
anim.UpdateNodeColor(wifiStaNodes.Get(0), 255, 255, 0);
anim.UpdateNodeDescription(wifiApNode.Get(0), "AP");
anim.UpdateNodeColor(wifiApNode.Get(0), 0, 255, 0);
Simulator::Stop(Seconds(simulationTime));
Simulator::Run();
NS_LOG_UNCOND("Simulation stop");
openGymInterface->NotifySimulationEnd();
return 0;
}ns3全局变量与外部控制接口设置
全局变量包括STA数目nWifi、是否存pcap tracing、当前随机数种子基础上计算随机数的键值simSeed、仿真持续时间simulationTime、单step时间envStepTime(simulationTime/envStepTime就是一个episode对应的step数目)、受python控的zmp的tcp端口openGymPort。
其中nWifi、verbose、tracing、runNumber、openGymPort、simSeed、simTime、testArg是可以ns3 run "linear-mesh --xxxxxx=yyyyy"传递进来的。
然后NS_LOG_UNCOND打印对应值信息。
注意envStepTime写死了,python那边也写死了,没有改而已。
cpp
int main(int argc, char *argv[])
{
bool verbose = true;
uint32_t nWifi = 4;
bool tracing = false;
uint32_t runNumber = 1;
uint32_t simSeed = 1;
double simulationTime = 3;
double envStepTime = 0.1;
uint32_t openGymPort = 5555;
uint32_t testArg = 0;
CommandLine cmd(__FILE__);
cmd.AddValue("nWifi", "Number of wifi STA devices", nWifi);
cmd.AddValue("verbose", "Tell echo applications to log if true", verbose);
cmd.AddValue("tracing", "Enable pcap tracing", tracing);
cmd.AddValue("runNumber", "Random runNumber", runNumber);
cmd.AddValue("openGymPort", "Port number for OpenGym env. Default: 5555", openGymPort);
cmd.AddValue("simSeed", "Seed for random generator. Default: 1", simSeed);
cmd.AddValue("simTime", "Simulation time in seconds. Default: 10s", simulationTime);
cmd.AddValue("testArg", "Extra simulation argument. Default: 0", testArg);
cmd.Parse(argc, argv);
RngSeedManager::SetSeed(22);
RngSeedManager::SetRun(simSeed);
NS_LOG_UNCOND("Ns3Env parameters:");
NS_LOG_UNCOND("--simulationTime: " << simulationTime);
NS_LOG_UNCOND("--openGymPort: " << openGymPort);
NS_LOG_UNCOND("--envStepTime: " << envStepTime);
NS_LOG_UNCOND("--seed: " << simSeed);
NS_LOG_UNCOND("--testArg: " << testArg);
NS_LOG_UNCOND("--runNumber: " << runNumber);测试环境设置
创建了1个ApNode和nWifi个StaNodes,
信道选用YansWifiChannel,
phy选择的是"{36, 20, BAND_5GHZ, 0}"配置,
ssid设置为"ns-3-ssid",
协议是80211ax,
数据速率是HeMcs0控制帧是HeMcs0(目的是使得信道占用最严重,多竞争,更容易导致错误的CW选择导致坏的状态,此时RL对于CW的优化看起来效果更好),
gi选择1600ns,
关闭聚合(事实上开聚合碰撞更严重,前提是关掉RTS CTS,但是当我开了聚合之后,50STA碰撞太严重,几乎聚不起来,frame全miss了,所以我们看关闭聚合),
移动性采取了一行7个,间隔1的分布,后续在正负500的范围内,速度1m/s,每0.2s变方向动一下,AP不动,STA随机动
AP STA都是10.1.1.X网段
wifiApNode是UDP接收,所有的StaNodes都会UDP发送,端口9,包长1000byte,0.0002s一个包(也就是相当饱和)
UDP应用0s开始,simulationTime时结束,也就是一直跑
初始化全局CW为2,函数目的是使得最开始的动作是2,这样起始的reward更低,现象更明显(但似乎效果一般,因为每个episode有30step,大约两个step,action就把CW改到远大于2的值了)
保存pcap为third
cpp
NodeContainer wifiApNode;
wifiApNode.Create(1);
NodeContainer wifiStaNodes;
wifiStaNodes.Create(nWifi);
YansWifiChannelHelper channel = YansWifiChannelHelper::Default();
YansWifiPhyHelper phy;
phy.SetChannel(channel.Create());
phy.SetPcapDataLinkType(WifiPhyHelper::DLT_IEEE802_11_RADIO);
phy.Set("ChannelSettings", StringValue("{36, 20, BAND_5GHZ, 0}"));
WifiMacHelper mac;
Ssid ssid = Ssid("ns-3-ssid");
WifiHelper wifi;
wifi.SetStandard(WIFI_STANDARD_80211ax);
wifi.SetRemoteStationManager("ns3::ConstantRateWifiManager",
"DataMode", StringValue("HeMcs0"),
"ControlMode", StringValue("HeMcs0"));
wifi.ConfigHeOptions("GuardInterval", TimeValue(NanoSeconds(1600)));
NetDeviceContainer staDevices;
mac.SetType("ns3::StaWifiMac", "Ssid", SsidValue(ssid), "ActiveProbing", BooleanValue(false), "BE_MaxAmsduSize",
UintegerValue(0),
"BE_MaxAmpduSize",
UintegerValue(0));
staDevices = wifi.Install(phy, mac, wifiStaNodes);
NetDeviceContainer apDevices;
mac.SetType(
"ns3::ApWifiMac",
"Ssid",
SsidValue(ssid),
"BeaconInterval",
TimeValue(MicroSeconds(102400)), "BE_MaxAmsduSize",
UintegerValue(0),
"BE_MaxAmpduSize",
UintegerValue(0));
apDevices = wifi.Install(phy, mac, wifiApNode);
MobilityHelper mobility;
mobility.SetPositionAllocator("ns3::GridPositionAllocator",
"MinX",
DoubleValue(0.0),
"MinY",
DoubleValue(1.0),
"DeltaX",
DoubleValue(1.0),
"DeltaY",
DoubleValue(1.0),
"GridWidth",
UintegerValue(7),
"LayoutType",
StringValue("RowFirst"));
mobility.SetMobilityModel("ns3::RandomWalk2dMobilityModel",
"Mode",
StringValue("Time"),
"Time",
StringValue("0.2s"),
"Speed",
StringValue("ns3::ConstantRandomVariable[Constant=1.0]"),
"Bounds",
RectangleValue(Rectangle(-500, 500, -500, 500)));
mobility.Install(wifiStaNodes);
mobility.SetMobilityModel("ns3::ConstantPositionMobilityModel");
mobility.Install(wifiApNode);
InternetStackHelper stack;
stack.Install(wifiApNode);
stack.Install(wifiStaNodes);
Ipv4AddressHelper address;
address.SetBase("10.1.1.0", "255.255.255.0");
Ipv4InterfaceContainer apInterfaces;
apInterfaces = address.Assign(apDevices);
Ipv4InterfaceContainer staInterfaces;
staInterfaces = address.Assign(staDevices);
UdpServerHelper echoServer(9);
ApplicationContainer serverApps = echoServer.Install(wifiApNode.Get(0));
serverApps.Start(Seconds(0));
serverApps.Stop(Seconds(simulationTime));
UdpClientHelper Client_node1(apInterfaces.GetAddress(0), 9);
Client_node1.SetAttribute("MaxPackets", UintegerValue(1000000000));
Client_node1.SetAttribute("Interval", TimeValue(Seconds(0.0002)));
Client_node1.SetAttribute("PacketSize", UintegerValue(1000));
UdpClientHelper Client_other(apInterfaces.GetAddress(0), 9);
Client_other.SetAttribute("MaxPackets", UintegerValue(1000000000));
Client_other.SetAttribute("Interval", TimeValue(Seconds(0.0002)));
Client_other.SetAttribute("PacketSize", UintegerValue(1000));
ApplicationContainer clientApps;
clientApps.Add(Client_node1.Install(wifiStaNodes.Get(0)));
for (uint32_t i = 1; i < wifiStaNodes.GetN(); i++)
{
clientApps.Add(Client_other.Install(wifiStaNodes.Get(i)));
}
clientApps.Start(Seconds(0));
clientApps.Stop(Seconds(simulationTime));
Ipv4GlobalRoutingHelper::PopulateRoutingTables();
SetCW(wifiApNode);
for (uint32_t i = 0; i < nWifi; i++)
SetCW(wifiStaNodes.Get(i));
if (tracing)
{
phy.EnablePcap("third", apDevices.Get(0));
}ns3-gym函数映射
APNode收到Udp后会触发DestRxPkt,记录到全局变量g_rxPktNum,作为reward传递到python侧
MyGetActionSpace提供python和ActionSpace的绑定
MyGetObservationSpace提供python和ObservationSpace的绑定
MyGetGameOver提供python和结束条件的绑定
MyGetObservation提供python和Observation结果的绑定
MyGetReward提供python和奖励的绑定
MyGetExtraInfo提供python和其他信息的绑定
MyExecuteActions提供python和Action到CW控制的绑定
ScheduleNextStateRead是节拍器,Simulator::Schedule(Seconds(0.0)负责启动节拍器。
cpp
Config::Connect("/NodeList/0/ApplicationList/*/$ns3::UdpServer/Rx", MakeCallback(&DestRxPkt));
Ptr<OpenGymInterface> openGymInterface = CreateObject<OpenGymInterface>(openGymPort);
openGymInterface->SetGetActionSpaceCb(MakeCallback(&MyGetActionSpace));
openGymInterface->SetGetObservationSpaceCb(MakeCallback(&MyGetObservationSpace));
openGymInterface->SetGetGameOverCb(MakeCallback(&MyGetGameOver));
openGymInterface->SetGetObservationCb(MakeCallback(&MyGetObservation));
openGymInterface->SetGetRewardCb(MakeCallback(&MyGetReward));
openGymInterface->SetGetExtraInfoCb(MakeCallback(&MyGetExtraInfo));
openGymInterface->SetExecuteActionsCb(MakeCallback(&MyExecuteActions));
Simulator::Schedule(Seconds(0.0), &ScheduleNextStateRead, envStepTime, openGymInterface);
NS_LOG_UNCOND("Simulation start");路径记录与结束通知
使用NetAnim记录所有Node的路径,标记了STA和AP,Target是后期其他训练需要单独针对某一个STA的时候单独拎出来的时候的一个预留。
NotifySimulationEnd就是在ns3 simulation stop的时候主动gameover的动作,后面具体看下。
cpp
AnimationInterface anim("complex-bridge.xml");
for (uint32_t i = 1; i < wifiStaNodes.GetN(); i++) {
anim.UpdateNodeDescription(wifiStaNodes.Get(i), "STA");
anim.UpdateNodeColor(wifiStaNodes.Get(i), 255, 0, 0);
}
anim.UpdateNodeDescription(wifiStaNodes.Get(0), "TargetSTA");
anim.UpdateNodeColor(wifiStaNodes.Get(0), 255, 255, 0);
anim.UpdateNodeDescription(wifiApNode.Get(0), "AP");
anim.UpdateNodeColor(wifiApNode.Get(0), 0, 255, 0);
Simulator::Stop(Seconds(simulationTime));
Simulator::Run();
NS_LOG_UNCOND("Simulation stop");
openGymInterface->NotifySimulationEnd();
return 0;
}NotifySimulationEnd先把全局变量m_simEnd配置成true,然后调用WaitForStop,然后调用NotifyCurrentState,然后调用IsGameOver,得到返回值"return (gameOver || m_simEnd);"后面告诉python的message就是需要over了。
cpp
bool
OpenGymInterface::IsGameOver()
{
NS_LOG_FUNCTION (this);
bool gameOver = false;
if (!m_gameOverCb.IsNull())
{
gameOver = m_gameOverCb();
}
return (gameOver || m_simEnd);
}
void
OpenGymInterface::NotifyCurrentState()
{
NS_LOG_FUNCTION (this);
if (!m_initSimMsgSent) {
Init();
}
if (m_stopEnvRequested) {
return;
}
// collect current env state
Ptr<OpenGymDataContainer> obsDataContainer = GetObservation();
float reward = GetReward();
bool isGameOver = IsGameOver();
std::string extraInfo = GetExtraInfo();
ns3opengym::EnvStateMsg envStateMsg;
// observation
ns3opengym::DataContainer obsDataContainerPbMsg;
if (obsDataContainer) {
obsDataContainerPbMsg = obsDataContainer->GetDataContainerPbMsg();
envStateMsg.mutable_obsdata()->CopyFrom(obsDataContainerPbMsg);
}
// reward
envStateMsg.set_reward(reward);
// game over
envStateMsg.set_isgameover(false);
if (isGameOver)
{
envStateMsg.set_isgameover(true);
if (m_simEnd) {
envStateMsg.set_reason(ns3opengym::EnvStateMsg::SimulationEnd);
} else {
envStateMsg.set_reason(ns3opengym::EnvStateMsg::GameOver);
}
}
// extra info
envStateMsg.set_info(extraInfo);
// send env state msg to python
zmq::message_t request(envStateMsg.ByteSizeLong());;
envStateMsg.SerializeToArray(request.data(), envStateMsg.ByteSizeLong());
m_zmq_socket.send (request, zmq::send_flags::none);
// receive act msg form python
ns3opengym::EnvActMsg envActMsg;
zmq::message_t reply;
(void) m_zmq_socket.recv (reply, zmq::recv_flags::none);
envActMsg.ParseFromArray(reply.data(), reply.size());
if (m_simEnd) {
// if sim end only rx ms and quit
return;
}
bool stopSim = envActMsg.stopsimreq();
if (stopSim) {
NS_LOG_DEBUG("---Stop requested: " << stopSim);
m_stopEnvRequested = true;
Simulator::Stop();
Simulator::Destroy ();
std::exit(0);
}
// first step after reset is called without actions, just to get current state
ns3opengym::DataContainer actDataContainerPbMsg = envActMsg.actdata();
Ptr<OpenGymDataContainer> actDataContainer = OpenGymDataContainer::CreateFromDataContainerPbMsg(actDataContainerPbMsg);
ExecuteActions(actDataContainer);
}
void
OpenGymInterface::WaitForStop()
{
NS_LOG_FUNCTION (this);
NS_LOG_UNCOND("Wait for stop message");
NotifyCurrentState();
}
void
OpenGymInterface::NotifySimulationEnd()
{
NS_LOG_FUNCTION (this);
m_simEnd = true;
if (m_initSimMsgSent) {
WaitForStop();
}
}对应python分析
文件夹内每个py都是一种操作,我们这里只看简单一些的qlearn.py(因为对于dqn-agent-v1来说,需要tensorflow,由于我是Ubuntu24,apt-get的时候只能获得tensorflow2以后的版本,现在的ns3-gym用了proto-buf,版本3.20.3,tensorflow2需要6以上的proto-buf,会弄坏现有的proto-buf环境,也就是说兼容性需要调整------真的需要当然需要处理,但作为入门和环境熟悉,为了这些去折腾环境不太友好,所以这里看qlearn.py)。
由于cc以及修改成了上面的形式,python也需要做一定的调整。
修改后的源码
cpp
#!/usr/bin/env python3
import time
import gym
import os
import numpy as np
from ns3gym import ns3env
import matplotlib.pyplot as plt
port = 5555
simTime = 1
startSim = 0
stepTime = 0.1
seed = 122
nWifi=50
simArgs = {"--simTime": simTime,
"--nWifi": nWifi}
debug = False
env = ns3env.Ns3Env(port=port, stepTime=stepTime, startSim=startSim, simSeed=seed, simArgs=simArgs, debug=debug)
Q = np.zeros(shape=(nWifi+1, 200, 100), dtype=float)
action = np.zeros(shape=(nWifi+1), dtype=np.uint)
rewards = []
iterations = []
alpha = 0.3
discount = 0.05
episodes = 50
for episode in range(episodes):
state = env.reset()
state = np.uint(np.array(state, dtype=np.uint32) / 10)
done = False
t_reward = 0
i = 0
while True:
if done:
break
i += 1
current = state
epsilon0 = 0.8
epsilon_min = 0.1
epsilon = max(epsilon0 / np.sqrt(episode + 1), epsilon_min)
for n in range(nWifi + 1):
if np.random.rand() < epsilon:
action[n] = np.random.randint(0, 100)
else:
action[n] = np.argmax(Q[n, current[n], :])
saction = np.uint(action * 5) + 1
print("action", saction)
state, reward, done, info = env.step(saction)
print('state:', state, reward, done)
state = np.uint(np.array(state) / 10 )
t_reward += reward
for n in range(nWifi+1):
Q[n, current[n], action[n]] += alpha * (reward + discount * np.max(Q[n, state[n], :]) - Q[n, current[n], action[n]])
print("Total reward:", t_reward)
rewards.append(t_reward)
iterations.append(i)
env.close()
def chunks_func(l, n):
n = max(1, n)
return (l[i:i+n] for i in xrange(0, len(l), n))
size = episodes
rewards = np.array(rewards)
chunks = np.array_split(rewards, size)
averages = [sum(chunk) / len(chunk) for chunk in chunks]
plt.plot(averages)
plt.xlabel('Episode')
plt.ylabel('Average Reward')
plt.show()环境搭建
一些画图和数据处理的库需要安装
cpp
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -U matplotlib
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -U scipy初始化
与opengym例子类似,不过多了time库------因为训练时间太长我在开始和结束时间加了打印时间log来统计时间
STA数量增加到50,增加碰撞,保证Q表有的学习,必须经过一定的学习才能达到总数据包最多
然后就是常规建立和ns3的链接了
python
import time
import gym
import os
import numpy as np
from ns3gym import ns3env
import matplotlib.pyplot as plt
port = 5555
simTime = 1
startSim = 0
stepTime = 0.1
seed = 122
nWifi=50
simArgs = {"--simTime": simTime,
"--nWifi": nWifi}
debug = False
env = ns3env.Ns3Env(port=port, stepTime=stepTime, startSim=startSim, simSeed=seed, simArgs=simArgs, debug=debug)Qlearning基础知识
标准 Q-learning 更新公式:
Q(s,a) \leftarrow Q(s,a) + \alpha \Bigl r + \\gamma \\max_{a'} Q(s', a') - Q(s,a) \\Bigr
- 状态和动作
s是状态,a是动作,状态s是agent看到的信息,a是根据状态s,agent选的动作
s'是下一个step的状态,a'是遍历s'下的所有动作,用来使得Q(s,a)也考虑后面的状态,保证长期奖励
- Q表
Q(s,a) 就是我们要反复更新、积累经验的多维数组,里面存储着每一个agent针对每一个状态s作出的每一个动作a的长期回报估计值,数值越大说明当前agent遇到s使用a越有利
Q(s', a')代表了下一个step评价,越大说明,下一个step到达了s'选取动作a'越合适,max的意思是本step要看下一step最好能是啥样的Q
\max_{a'} Q(s', a')越大,越说明当前状态s如果选了a(那么下一步到了s'选取动作a'取得的Q越大),也就是说下一步获得的长期奖励更好(Q-learning 正是通过这种只向后看一步的 TD 更新,将长期回报信息逐步向前传导,从而逼近全局最优策略。)
- 学习率
\alpha就是学习率,0~1,越大Q的变化越剧烈,导致振荡更大,最开始的学习可能很快也可能很快的选了不合适的action获得小reward
- 奖励
r就是奖励,每个step都会有一个奖励,本轮次step选择动作a的奖励
- 折扣率
\gamma是折扣率,0~1,越大越重视下一轮的Q,越强调下一轮Q重要,越小,比如取0,此时Q= \alpha*r,也就是只考虑本step的奖励
Q-learning标准流程
- 创建Q表,确定state范围,比如1-10,一维,确定action范围,比如1-5,一维,确定agent数目,比如5个,那么Q表就是一个3维表,可以理解为5张表,每个表10*5大小,比如123,就是1号agent,在状态2下,选择动作3的Q值
- 选择学习率、折扣率,使得符合对训练效率&波动幅度、近期优势&长期优势的权衡
- 映射动作、状态、奖励,使他们与现实情况一一对应
- 开始循环,分为多个episode,每个episode对应的都应该是完全一样的环境(不要求环境每次变化都稳定,有随机变化的环境也可以,Q稳定之后就说明对于训练这种随机变换环境当前Q以经取得了最好结果了),每个episode里面对应多step
- 每个step,对于ε-贪婪策略,在探索阶段,动作更多选择为随机值(就比如1-5的随机值),在稳定阶段,就选择Q表推荐的最优action,选择了action就会导致一个新的reward的获得、新的状态state的获得、是否gameover
- 新的reward和新的state可以用来算r + \gamma \max_{a'} Q(s', a') - Q(s,a),新的reward就是本step选action的结果,新的state就是s',我们遍历a'就可以获得下一个状态的最好的期待(也就是off policy),也就完成了本step的Q更新
- 反复迭代step,完成一个episode,(也就是说一个episode只是一条线,并没有看到每一个step的所有的s的可能性,所以才需要多episode取得最优,也就是说明了Qlearning属于TD时序差分方法),迭代多个episode,稳定获得最优值
- 衡量效果好不好的方法是看每个episode的总reward是不是较快的收敛到了最大值,收敛的越快越好、收敛后的总reward越高越好。
Qlearning初始化
- 我选了50个STA的场景,所以加上AP51个,状态1-200,动作1-100,Q值为浮点的
- 动作于是也就是一个51长度的向量,int型的
- 学习率0.3,希望稳一点,折扣率0.05,不太考虑长远好处,50轮
python
Q = np.zeros(shape=(nWifi+1, 200, 100), dtype=float)
action = np.zeros(shape=(nWifi+1), dtype=np.uint)
rewards = []
iterations = []
alpha = 0.3
discount = 0.05
episodes = 50循环训练
- 循环50次,每次都跑完所有step,终止条件是ns3跑完。
- 初始化状态,缩小十倍,也就是说状态获取的范围支持到10-2000,缩小十倍后就是1-200,不会超限制
- 使用 ε-贪婪策略进行action选择,衰减策略是开始比较大幅度的探索,episode增加后稳定下来更多看Q:
- 初始 ε=0.8,随回合数增加按 1/√episode 衰减
- 最小保持 0.1,确保始终有一定探索,
- 对action进行缩放,放大5倍,也就是1-100 -> 5-500,也就是取得一个范围够大的、颗粒粗一点的action,也就是设置的CW的大小是5-500
- 开始step,根据选择的action操作ns3,获得新的状态奖励和是否gameover
- state缩放,除以10,使得处于1-200之间,由于sate是各个node的mac队列长度,最大500,所以结果是0-50,不会超出状态空间
- 累积总reward用于看一次训练的效率
- 更新Q表
- 每个episode结束了保存本episode总奖励,记录又多了一次iterations,可以作为episode数目的记录
- 所有的episode结束后释放Q空间action空间和state空间
python
for episode in range(episodes):
state = env.reset()
state = np.uint(np.array(state, dtype=np.uint32) / 10)
done = False
t_reward = 0
i = 0
while True:
if done:
break
i += 1
current = state
epsilon0 = 0.8
epsilon_min = 0.1
epsilon = max(epsilon0 / np.sqrt(episode + 1), epsilon_min)
for n in range(nWifi + 1):
if np.random.rand() < epsilon:
action[n] = np.random.randint(0, 100)
else:
action[n] = np.argmax(Q[n, current[n], :])
saction = np.uint(action * 5) + 1
print("action", saction)
state, reward, done, info = env.step(saction)
print('state:', state, reward, done)
state = np.uint(np.array(state) / 10 )
t_reward += reward
for n in range(nWifi+1):
Q[n, current[n], action[n]] += alpha * (reward + discount * np.max(Q[n, state[n], :]) - Q[n, current[n], action[n]])
print("Total reward:", t_reward)
rewards.append(t_reward)
iterations.append(i)
env.close()注意
由于以上内容仅仅作为学习,不需要最优,我们这里忽略了以下问题并取工程近似
reward 是全局的,但 agent 是独立的
所有 agent 用同一个reward,这意味着agent 无法区分 "是我这个 CW 选得好", 还是"别人帮我了",这是 **credit assignment problem,**不是 bug,但会导致:学习慢,振荡,对 agent 数敏感
环境对单 agent 来说是非平稳的
因为,其他 agent 的 policy 在变,对某一个 agent 来说:P(s'|s,a) 在变,这在理论上 破坏 Q-learning 收敛条件, 工程上依然常用,但这是 近似
reward没有归一化
一次ns3总包数目最多9000,30个step,所以reward是0-300,偶尔会出现某次Q过大后锁死,传导还污染,不过由于当前**α、γ 与 reward 尺度是匹配的,**暂时不需要改。
没有归一化影响影响
reward 范围大 → 影响的是 Q 的数值尺度 ,大的reward 带来的影响只是 Q 值会偏大,只要 α、γ 与 reward 尺度是匹配的,就不会出问题
当前参数
-
reward ≈ 0--300
-
α = 0.3
-
γ = 0.05
单步更新量上界大约是:
这意味着:
-
Q 初期会 快速涨到 O(10^2 -- 10^3)
-
但 不会发散
-
因为 γ 很小,未来回报被强烈压制
数值上是安全的
不稳定情况
只有在下面情况之一成立时才危险:
- 情况 1:γ 接近 1 + reward 很大
r = 300, γ = 0.99 ⇒ Q ≈ r / (1 - γ) ≈ 30000
-
Q 爆炸
-
更新震荡
-
argmax 不稳定
- 情况 2:α 太大(接近 1)
-
单次 reward 噪声直接写进 Q
-
多智能体下尤为严重
尺度判断准则
经验法则:
结果处于可接受范围内
例如:
-
几十 / 几百:安全
-
上万:开始危险
-
上百万:基本不可用
state空间浪费
state留下的空间是1-200,事实上缩放完了是1-50,浪费了,不过不会引入数值不稳定、不会影响更新公式正确性,只会影响 **表大小、收敛速度、样本效率,**作为学习,先这样吧,不做优化
结果
以下是800episode、2000episode的仿真结果,可以看到先试探再增加再稳定
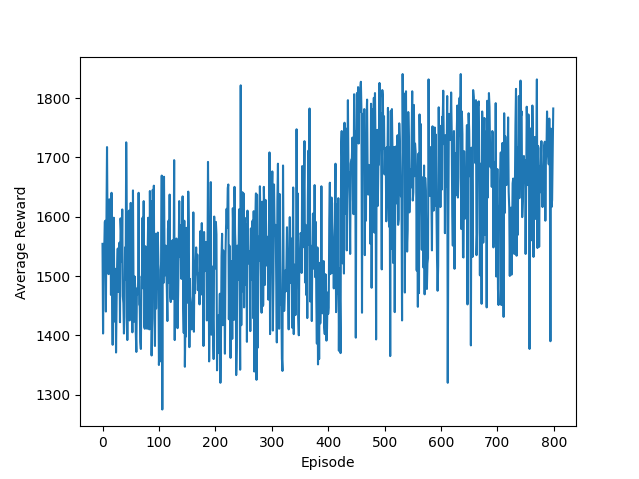
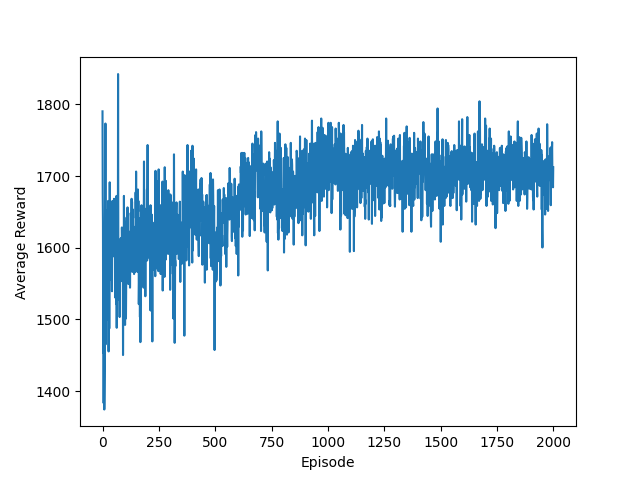
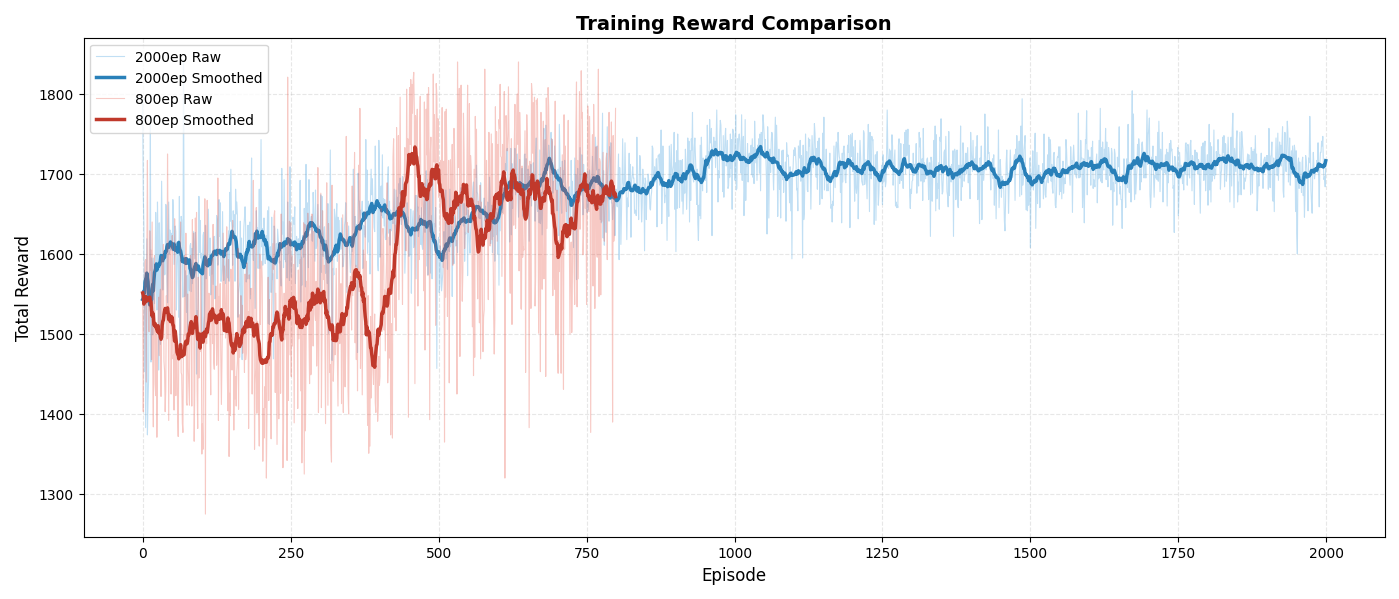
以下是800和200 episode对比,可以看到,二者没有重合,也就是说训练的路径有随机性,但是最后都收敛到类似的情况(800轮与2000轮的在第800轮的总reward几乎一致,2000轮训练更多,后面又有所优化),
引用(一个是公开一个是acm,其实是同一篇):
Gawłowicz P, Zubow A. Ns-3 meets openai gym: The playground for machine learning in networking researchC//Proceedings of the 22nd International ACM Conference on Modeling, Analysis and Simulation of Wireless and Mobile Systems. 2019: 113-120.
Zubow A. ns3-gym: Extending openai gym for networking researchJ. arXiv preprint arXiv:1810.03943, 2018.