大模型学习笔记------数据清洗(质量过滤)
-
- 1、轻量级分类模型(大规模初筛)
- [2、 中量级预训练模型(精细过滤)](#2、 中量级预训练模型(精细过滤))
- [3、 生成式大模型作为"裁判"(高质量筛选)](#3、 生成式大模型作为“裁判”(高质量筛选))
- [4、 针对指令数据的专用指标](#4、 针对指令数据的专用指标)
- [5、 总结](#5、 总结)
在 LLM(大语言模型)的开发迭代中,有一句金科玉律:"数据质量决定了模型的上限。"实际操作中,大模型训练最无法绕开的环节就是数据清洗。我们必须通过精细的质量过滤(Quality Filtering),将原始的"语料矿石"打磨成"数据黄金"。然而,面对 TB 甚至 PB 级的海量数据,单纯依赖人工逐条核对显然是天方夜谭。那么,质量过滤能否实现自动化批量处理?答案不仅是肯定的,而且"以模治模"已成为工业界的标准做法。
在大型语言模型(LLM)的开发中,质量过滤(Quality Filtering)通常不是单一模型的任务,而是一个多阶段、由易到难的流水线。根据数据规模和质量要求,常用的模型和方法可以归纳为以下几类:
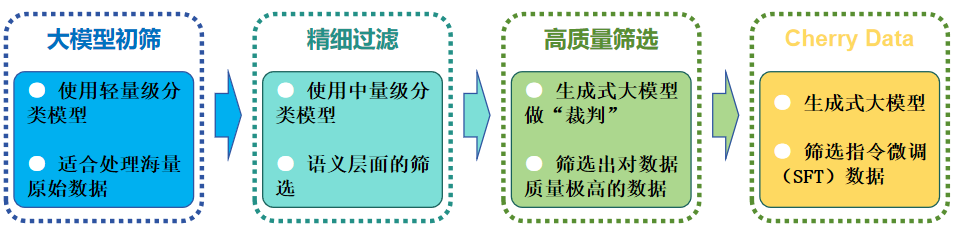
1、轻量级分类模型(大规模初筛)
这类模型适用于处理海量原始数据(如 Common Crawl),其核心优势是速度极快、计算成本低。
-
fastText (Facebook)
用途 :最主流的质量过滤模型。常用于识别语种、过滤低质量文本(如广告、乱码)。
案例 :FineWeb、Ultra-FineWeb 等知名数据集均使用 fastText 训练质量分类器。
原理:基于简单的 n-gram 和线性分类,能够以每秒处理数十万文档的速度运行。 -
启发式规则 (Heuristics)
虽然不是"模型",但它是第一道防线。包括:字数/句长统计、符号比例、重复 n-gram 检测(Gopher 过滤规则)、困惑度(Perplexity)检测。
2、 中量级预训练模型(精细过滤)
当数据量被初步缩减后,可以使用更强的模型进行语义层面的筛选。
- BERT / RoBERTa 系列
用途 :用于判断文本的"教科书感"(Textbook Quality)或专业性。
原理 :相比 fastText,BERT 能够理解上下文。研究表明,使用 BERT 筛选出的数据训练模型,效果通常优于 fastText。
案例:Li (2023) 等人在 phi-1 训练中强调了"教科书级别"数据的价值,通常使用微调后的 BERT 类模型进行此类标记。
3、 生成式大模型作为"裁判"(高质量筛选)
在指令微调(SFT)或偏好对齐(RLHF)阶段,对数据质量要求极高,通常直接使用更强的大模型(LLM-as-a-Judge)。
- LLM 评分模型(如 GPT-4, Llama-3, Qwen)
用途 :对指令-回复对进行打分(0-5分),筛选出逻辑严密、无害且信息丰富的样本。
工具:distilabel 或 Argilla,这些框架可以自动化调用大模型对数据进行"洗涤"。 - Reward Model (奖励模型)
用途:在 RLHF 阶段,奖励模型专门用于评估输出的质量和偏好。
一般情况下,使用LLM 评分模型即可,国内使用QWen是非常好用的。
4、 针对指令数据的专用指标
如果是为了筛选指令微调(SFT)数据,目前最前沿的方法是:
- IFD Score (Instruction-Following Difficulty)
原理 :计算模型在"有指令"和"无指令"下生成相同回复的困惑度比值。
作用:筛选出对模型最有挑战性、提升能力最明显的"樱桃数据"(Cherry Data),剔除简单重复的废话。
5、 总结
根据以上情况总结成如下表格以供参考:
| 阶段 | 数据规模 | 推荐模型/方法 | 核心诉求 |
|---|---|---|---|
| 大规模预训练 | TB / PB 级 | fastText + 启发式规则 | 过滤垃圾、乱码、广告 |
| 领域专业化 | GB 级 | BERT / RoBERTa 微调 | 提升知识密度(如教科书化) |
| 指令微调 (SFT) | MB / GB 级 | LLM-as-a-Judge (GPT-4/Qwen) | 确保逻辑、格式、对齐度 |
| 偏好对齐 | 万条级别 | Reward Model | 符合人类偏好 |
根据不同的项目采用不同的质量过滤方法,不一定按照流程进行。比如医学领域可以直接使用指令微调(SFT)等,进行条件下可以直接使用偏好对齐的方式。