
让我们谈谈数字。
大多数现代开源模型在70-80亿参数范围内(如LLaMA 3、Mistral或Qwen3)现在可以在配备12-24GB显存的GPU上使用4-bit量化适配器(QLoRA)进行微调。
一个80亿参数的模型通常只需要5-6GB的内存,使其在RTX 3060或更新版本上运行可行。
对于内存效率,动态量化缩小了精度差距,使得使用4-bit几乎没有缺点。
QLoRA与LoRA现在的损失可以忽略不计,意味着你可以放心使用4-bit来节省内存。你应该以你计划部署的精度进行训练(所以如果你想要一个4-bit运行时模型,就在4-bit下训练)。
关于速度,使用FlashAttention、LoRA和序列打包等优化,你可以在A100(40GB)上几小时内微调80亿参数模型的10万个样本,而在消费级RTX 4090(约24GB,内存和计算稍少)上可能需要10-12小时,在3090上则需要20小时以上。如果没有这些框架提供的优化,可能需要2-3倍的时间。
如果你有多个GPU(例如两个3090),你可以几乎线性地分担负载。在2个GPU上微调130亿参数的模型可能比1个GPU快近2倍。
如果你有Apple Silicon,据我所知,70亿和130亿参数的微调在技术上可行,但由于缺乏Metal优化的底层内核,训练速度慢5-10倍。如果你在配备M1或更高版本的MacBook上,请坚持使用30亿-70亿参数的模型并限制训练轮次,或将训练转移到云GPU(如RunPod或Lambda)。话虽如此,我不是这方面的专家,所以我很乐意在评论中听取你关于Mac/M系列的经验。
在集成方面,所有框架都允许以Hugging Face格式保存模型,因此你可以轻松推送到Hub或使用AutoModel加载。
在本指南中,我将带你了解四个领先的解决方案:
- Unsloth:低显存、2倍快速训练、适合初学者的笔记本
- LLaMA-Factory:全栈CLI + Web UI、100+模型、多模态
- DeepSpeed:经过实战检验的大规模模型和多GPU扩展
- Axolotl :YAML优先、可重现、研究级调优工作流程
我们将探讨每个工具包的功能和实用示例(代码、CLI、YAML)。
0、微调框架概述
为奠定基础,以下是四个框架的高级比较:

每个工具针对稍微不同的受众和用例:
- Unsloth 专注于速度和最小显存,使在适度硬件上进行微调成为可能。它简化了典型的训练流程(提供Colab笔记本、简单的API)并实现巨大的效率提升(例如打包序列,不浪费GPU时间在填充上)。
- LLaMA-Factory 是一个全栈微调工具包,强调通过精致的Web UI和快速支持最新模型和研究技巧来提供易用性。对于想要一站式解决方案且几乎不需要编码的人来说,这是理想选择。
- DeepSpeed 是一个强大的优化库,而不是端到端解决方案。当你需要训练非常大的模型或在多GPU设置上最大化性能时,它会发光,但它有更陡峭的学习曲线(它经常被用在Hugging Face Accelerate等库的后台)。
- Axolotl 击中了一个中间地带:它是开源且可脚本化的 ,带有简单的YAML配置,非常适合想要精细控制和运行自定义训练例程(包括前沿技术)能力的开发人员,而无需从头编写训练循环。它是一个社区驱动的项目,平衡了可用性和灵活性。
下面,我们详细深入研究每个工具,包括示例和最新更新。
1、Unsloth:使用低显存进行轻量级微调
Unsloth 因其能够超高效地微调大语言模型而迅速流行起来。
它宣传训练 "比标准方法快2倍,显存使用减少约70%",这得益于4-bit量化和智能数据处理等技术。
事实上,Unsloth的方法非常节省内存,以至于可以在仅3GB GPU显存上微调40亿参数的模型(例如Qwen3-4B),有效地将大语言模型微调带到消费级笔记本电脑。

Unsloth作为Python包提供(pip install unsloth)和一套现成的Jupyter笔记本。
初学者可以通过运行Colab笔记本来快速入门,该笔记本指导完成整个微调过程。
例如,使用单个笔记本,你可以在Colab或Kaggle上"免费"进行微调或RLHF,只需要几GB的GPU内存。
这显著降低了入门门槛。
高级用户可以在自己的脚本中使用Unsloth的Python API。
没有专门的GUI,但文档完善的笔记本和简单的函数调用使过程变得简单。
1.1 微调方法
Unsloth支持标准监督微调(SFT)以及强化学习微调(用于使用奖励模型的RLHF风格训练)。
它兼容参数高效技术,特别是LoRA 和QLoRA。
在底层,Unsloth可以对基础模型权重应用4-bit量化(使用bitsandbytes),以便你可以在4-bit模式下进行微调。
这就是Unsloth能够在小型GPU上处理更大模型的原因。
例如,QLoRA 将内存减少4倍,而Unsloth通过其动态4-bit量化进一步完善这一点。
"动态"部分指的是Unsloth的自定义4-bit权重量化,它比标准4-bit方法保留更多精度(缩小QLoRA和完整16-bit微调之间的差距)。
如果你愿意,你也可以进行完整的16-bit微调或8-bit模式,Unsloth暴露了load_in_4bit=True/False或full_finetuning=True等标志来切换这些模式(一次只能激活一种模式)。
对于大多数情况,你最好从LoRA/QLoRA开始,因为它以计算成本的一小部分实现了与完整微调几乎相同的结果。
它还支持扩展上下文训练:通过正确的配置,你可以将模型微调到比正常长4倍的上下文长度 (例如,通过调整max_seq_length为LLaMA启用8192-token上下文,这要归功于FlashAttention支持)。
除了文本大语言模型,Unsloth还可以微调其他模型类型:例如,它有用于视觉模型、文本到语音模型、嵌入等的模块,使其成为一个广泛能力的训练库。
1.2 性能
最近的更新引入了序列打包,它将多个短训练样本合并到一个带有适当掩码的序列中,消除了填充token的开销。
在有许多短提示的数据集中,这理论上可以带来高达5倍的训练加速。
即使没有打包的默认模式下,自定义融合内核和优化也能产生比早期实现快约1.1-2倍的训练步骤时间。
与朴素微调相比,Unsloth的显存使用 可以降低30-90%,例如,在单个48GB GPU上微调700亿参数模型,而以前需要多个GPU或根本无法容纳。
所有这些都伴随着"训练损失曲线0%变化",即没有精度下降。这些声明也得到了库基准测试和社区测试的支持。
在实践中,使用Unsloth的一个权衡是它为你抽象了很多东西,这对于易用性很好,但意味着与Axolotl等框架相比,对训练循环的手动控制较少。
此外,由于它依赖于PyTorch和NVIDIA工具(如bitsandbytes),在Apple Silicon或AMD GPU上的完整支持不是它的重点(在这些设备上运行可能会回退到较慢的方法或无法工作)。
但在NVIDIA GPU上,Unsloth是获得微调大语言模型的最快方式之一。
1.3 使用Unsloth进行微调示例
使用Unsloth时,你通常会编写一个简短的Python脚本或使用他们的笔记本。
例如,使用Unsloth的高级API,你可以这样做:
from unsloth import SFTTrainer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("unsloth/llama-3.1-8b-unsloth-bnb-4bit")
trainer = SFTTrainer(
model=model,
train_dataset=my_dataset,
lora_rank=8, # 使用LoRA秩8
load_in_4bit=True,
output_dir="output-model"
)
trainer.train()关键思想是你加载Unsloth准备的4-bit版本的模型(这里是LLaMA 3 8B),指定LoRA或完整微调,然后调用train()。
2、LLaMA-Factory:通过CLI和Web UI统一微调
LLaMA-Factory是一个用于微调大语言模型的一站式平台,结合了易于使用的WebUI、CLI工具和各种高级功能。
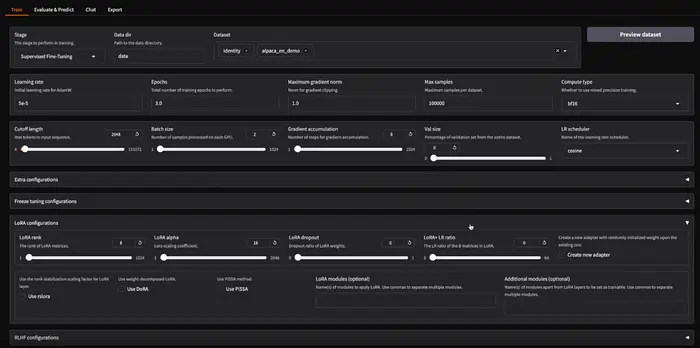
它的使命是让微调*"像...点击开始一样简单"*,同时仍然允许专家利用前沿研究。
该项目以非常活跃的维护而著称(通常在几天内添加对新模型或技术的支持,他们开玩笑地强调对Qwen3、Llama 4等模型的"Day-0"或"Day-1"支持)。
2.1 易用性
使用LLaMA-Factory有两种主要方式:
-
**Web UI(LLaMA Board):**安装后,通过
llamafactory-cli webui启动它,这会打开一个基于Gradio的本地Web界面。这个UI显著降低了门槛,也就是说,你可以完全不编写任何代码就微调模型。训练完成后,评估/聊天标签让你在浏览器中测试模型的性能,导出标签让你打包结果模型(可以选择合并LoRA权重、将模型量化为GGUF/AWQ等,并推送到Hub或本地保存)。
-
**CLI和YAML:**或者,一切都可以通过命令行实现自动化。LLaMA-Factory使用YAML配置文件来指定训练运行(类似于Axolotl)。例如,要使用LoRA微调Qwen-3模型,可以运行:
llamafactory-cli train examples/train_lora/qwen3_lora_sft.yaml
这个命令将根据YAML配置启动训练(包含所有设置)。
同样,有用于聊天/推理的子命令和用于合并适配器的子命令。
例如,训练后,你可以运行llamafactory-cli chat <config.yaml>启动与微调模型的交互式聊天,或llamafactory-cli export <config.yaml>将LoRA权重合并到基础模型。
CLI在某种意义上是零代码的,你只需要准备配置文件;它适合那些喜欢脚本交互或想要将微调集成到管道中的人。
安装比Unsloth或Axolotl更复杂,因为LLaMA-Factory有许多可选组件(用于各种硬件和功能)。
它支持NVIDIA GPU (使用CUDA)、AMD GPU (ROCm)甚至华为昇腾NPU,这很少见。
根据你的硬件,你可能需要安装额外的包(例如,对于Windows,手动安装bitsandbytes,对于AMD,编译自定义bitsandbytes分支)。
简而言之,它是跨平台的,但NVIDIA Linux是最流畅的路径。
Factory支持一个微调方法流水线:
- 它涵盖标准微调 (更新所有模型权重)、冻结微调(冻结某些层,只训练特定部分)和各种基于适配器的调优。
- 它原生支持LoRA 和QLoRA ;事实上,它实现了多种量化方法(你可以从4-bit后端选择,如
bitsandbytesNF4,或其他实验性的3-bit/2-bit方法,如AWQ或AQLM)。你可以进行2/3/4/6/8-bit量化微调,这是尖端的,甚至是2-bit LoRA(尽管可能有一些权衡)。 - 多模态: LLaMA-Factory可以微调视觉语言模型(如LLaVA-1.5,它为LLaMA添加了视觉理解)以及音频模型。这意味着如果你有图像+文本数据集(例如用于VQA任务),WebUI将呈现附加图像特征提取的字段等。它非常全面。
- 强化和指令调优: 它支持奖励建模和RL微调方法,如PPO(用于RLHF的近端策略优化)、DPO(直接偏好优化)以及其他如ORPO/KTO。
- 高级优化器和技巧: 该工具包集成了许多研究优化:例如Apollo 和Lion 优化器、LongLoRA (更好的长序列训练)、DoRA (可能是LoRA的变体)、LoftQ 、GaLORE 和PiSSA(可能与结构化稀疏适配器相关)。
- 监控和部署: 训练期间,你可以使用内置监视器:它支持记录到TensorBoard 、Weights & Biases 、MLflow等,以及其原生的LlamaBoard。
- 对于部署,LLaMA-Factory甚至可以服务模型:它为微调模型提供OpenAI风格的API服务器 ,并与vLLM集成进行优化推理。
- 因此,微调后,你可以启动一个服务模型的本地API(带有加速以进行快速多线程生成)。
- 性能: LLaMA-Factory的效率很高,尽管可能稍...
2.2 LLaMA-Factory使用示例
对于基于代码的方法,LLaMA-Factory还暴露了Python API(以防你想要在没有YAML的情况下编写脚本)。
但通常,你会编辑一个YAML,例如,这是LoRA微调配置的片段:
# qwen3_lora_sft.yaml(节选)
model_name_or_path: Qwen/Qwen-3-4B
finetuning_type: lora
lora_rank: 8
dataset: path/to/dataset.json
template: llama2
per_device_train_batch_size: 2
gradient_accumulation_steps: 4
num_train_epochs: 3
output_dir: output/qwen3-4B-lora在此配置上运行llamafactory-cli train将使用LoRA秩8在数据集上微调Qwen-3 40亿参数模型。
训练后,你可以在WebUI中打开聊天标签,加载基础模型和LoRA权重(它提供用于选择适配器文件的UI元素),并与微调模型进行对话以评估其响应。
3、DeepSpeed:为大规模微调提供动力
DeepSpeed 是这一系列中的另一头野兽,它不是一个全能训练应用程序,而是一个深度学习优化库。
由Microsoft开发,DeepSpeed因通过克服硬件限制高效训练十亿参数模型而著称。
它是许多研究项目的引擎,并补充了Hugging Face的Trainer或PyTorch Lightning等工具。
3.1 易用性
就其本身而言,你通常通过编写Python训练脚本并添加DeepSpeed初始化来使用DeepSpeed。
然而对于大多数用户,利用它的最简单方式是通过Hugging Face Accelerate/Trainer集成。
例如,你可以采用标准的Transformers Trainer并简单地提供一个DeepSpeed配置文件(JSON),Trainer将使用DeepSpeed在后台进行优化。
或者,Accelerate库可以通过简单的配置启动使用DeepSpeed的分布式训练。
以下是用于多节点微调的accelerate配置片段示例:
distributed_type: DEEPSPEED
num_machines: 2
mixed_precision: fp8
deepspeed_config:
zero_stage: 3在此配置(用于微调LLaMA-700亿)中,zero_stage: 3打开DeepSpeed的ZeRO-3分片,而mixed_precision: fp8在支持的GPU上使用8-bit浮点精度以获得更大的内存节省。
只需这个设置,你就可以在训练脚本上调用accelerate launch,它将自动在2台机器(每台可能有4个GPU)上分片模型,大大简化编排。
对于单机使用,你可以使用deepspeed启动器脚本:例如,deepspeed --num_gpus=2 train.py --deepspeed ds_config.json。
这将使用DeepSpeed包装你的PyTorch模型运行你的train.py(假设你的脚本是DeepSpeed兼容的)。简而言之,*DeepSpeed需要一些编码或集成,*对于完整训练(HF生态系统外)没有GUI或简单的YAML。
但设置完成后,它在很大程度上是*"设置并忘记"*,你让DeepSpeed处理并行性和内存。
DeepSpeed的旗舰功能是ZeRO(零冗余优化器)。ZeRO允许将模型状态(优化器时刻、梯度甚至参数)跨GPU分割,以便没有单个GPU需要完整副本。
这就是人们如何在几个GPU上微调300亿、650亿或更大模型的方式。例如,使用ZeRO-3,如果你有4个GPU,每个可能只在内存中保存1/4的模型参数。
DeepSpeed还支持ZeRO-Offload,其中一些数据块(如优化器状态)可以卸载到CPU内存甚至NVMe SSD,进一步扩展了在有限GPU内存上训练巨大模型的能力(以速度为代价)。
另一个核心能力是跨多个节点的分布式训练(不仅仅是一台服务器中的多个GPU,而是跨服务器)。
DeepSpeed与通信后端集成以高效同步梯度。它以扩展到数千个GPU进行大规模模型训练而著称。
DeepSpeed还引入了专门的优化:
- 高效优化器: 如1-bit Adam和1-bit LAMB,通过量化梯度交换来减少多GPU训练期间的通信开销(对分布式微调有用)。
- 混合精度训练: 它无缝处理FP16和BF16(自动进行损失缩放等)。现在,它支持FP8(在H100等硬件上使用accelerate时,如上所示)。
- 内存高效注意力和长序列支持: DeepSpeed有一个名为Sparse Attention的模块和用于非常长序列训练的实验性功能(它引入了长序列的"Arctic"优化),这与你微调超过2048个token上下文的模型相关。
- MoE(专家混合): 如果你微调带有MoE层的模型(对大多数人不常见,但一些研究模型使用MoE),DeepSpeed有内置支持通过为每个token激活哪个专家来高效训练。
然而,请注意,DeepSpeed本身不实现LoRA或QLoRA,但它与它们配合工作。例如,你可以使用Hugging Face PEFT为模型添加LoRA层,并仍然使用DeepSpeed ZeRO来处理基础模型分布和训练。
这是一个常见的设置:DeepSpeed + QLoRA + HF Trainer。
这种组合可以在2x H100(80GB)节点设置上微调LLaMA-700亿,使用ZeRO-3、4-bit量化和LoRA适配器。
结果是生产就绪的管道,即使如此大的模型也可以在合理时间内进行微调。
没有DeepSpeed,在内存中纯粹处理模型几乎是不可能的。
3.2 性能
DeepSpeed已被证明可以显著提高大模型微调的吞吐量和降低成本。
DeepSpeed可以在某些RLHF微调阶段实现15倍加速(与朴素方法相比)。对于大多数在单个GPU上微调中等模型(60亿-130亿)的用户,DeepSpeed的主要好处在于内存节省(ZeRO-Offload),这可能允许你使用更大的批次大小或更长的序列而不会内存不足。
在多个GPU上,它通过实现接近线性的扩展而发光,随着你添加更多GPU。
也就是说,如果你只是在单个GPU上微调70亿参数模型,DeepSpeed可能有些过度,像Unsloth或Axolotl(使用bitsandbytes)更简单。
DeepSpeed出现在突破极限的场景中:例如在24GB GPU上微调400亿参数模型 ,通过将一半卸载到CPU,或在8x 16GB GPU 上通过分片训练700亿参数模型。
对于多节点集群,编写自定义分布式代码会很复杂,DeepSpeed在内部处理它。
使用DeepSpeed进行微调示例(通过HF Trainer):
为了说明,以下是如何在Transformers训练脚本中使用DeepSpeed:
from transformers import Trainer, TrainingArguments, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-70b-chat-hf")
#(如果需要,在这里使用PEFT包装模型与LoRA)
training_args = TrainingArguments(
output_dir="out-model",
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
fp16=True,
deepspeed="ds_config_zero2.json" # DeepSpeed配置文件路径
)
trainer = Trainer(model=model, args=training_args, train_dataset=my_data)
trainer.train()使用deepspeed参数,当调用trainer.train()时,它将初始化DeepSpeed。一个简单的DeepSpeed配置(ds_config_zero2.json)可能包含:
{
"zero_optimization": {
"stage": 2,
"offload_optimizer": { "device": "cpu" }
},
"fp16": {
"enabled": true
}
}这将使用ZeRO阶段2(在GPU上分片优化器状态和梯度)并将优化器卸载到CPU(节省GPU内存)。
结果:你的700亿参数模型的梯度和优化器部分存在于CPU内存中,允许训练在例如2个GPU上进行,每个GPU保存权重的分片。DeepSpeed在后台处理所有同步和交换。
4、Axolotl:让配置驱动的微调变得有趣
Axolotl是一个专注于简单性和灵活性的开源框架。
它经常被描述为*"使用单个YAML配置进行微调"*。
其理念是让你在配置文件中指定什么 你想微调以及如何(哪个模型、数据、方法、超参数),Axolotl的CLI将处理其余一切,从预处理到训练再到保存模型。
4.1 易用性
开始使用Axolotl通常涉及通过pip或Docker安装它,然后使用示例配置文件之一作为你任务的模板。
例如,安装后你可以运行:
axolotl fetch examples
axolotl train examples/llama-3/lora-1b.yml这将下载一堆示例YAML(涵盖不同的模型和方法)。你可以修改YAML以指向你的数据集或更改超参数。
YAML配置方法意味着你不为每次微调编写代码,你只需编辑字段。
配置文件通常包括以下部分:模型(预训练模型名称/路径)、数据(数据集路径或HuggingFace数据集名称)、训练参数(批次大小、轮次、学习率)、LoRA参数(如果适用)(秩、alpha)以及任何特殊设置(例如启用FlashAttention、梯度检查点等)。
这种设计使其**非常可重现,**你可以与其他人共享配置,他们可以准确地重新运行微调。
Axolotl缺乏GUI,但其控制台输出清晰,它会定期打印训练损失等。
如果配置,它还支持记录到WandB。
因为它是配置驱动的,Axolotl非常适合在云实例或无头服务器上运行(不需要笔记本或GUI)。
4.2 功能
尽管占用空间小,Axolotl是功能丰富的:
- 模型支持: 它可以微调几乎任何Hugging Face模型。它提到GPT-OSS、LLaMA、Mistral、Pythia等。它还支持新模型如Kimi、Plano、InternVL 3.5、Olmo-3、Trinity等。
- 多模态和超越大语言模型: Axolotl不限于聊天大语言模型。它支持视觉语言模型 (如LLaMA-Vision、Qwen-VL)和音频模型 (如语音识别或TTS)带有图像/视频/音频输入。它甚至有用于扩散模型微调的扩展(文本到图像)。
- 训练方法: 你可以进行完整微调 或各种参数高效方法。它支持LoRA和QLoRA,有一些独特的优化。
- Axolotl支持GPTQ训练(GPTQ通常是推理量化,但在这里它可能意味着你可以加载GPTQ量化模型,也许可以微调或至少将LoRA合并到其中)。
- Axolotl还支持**量化感知训练(QAT)**以允许使用量化模拟进行int4/int8训练,以提高最终量化精度。
- 在偏好优化方面,它支持如DPO、IPO、ORPO 等方法(这些是不使用RL的偏好对齐微调方法)。对于RL ,它集成了GRPO(引导正则化策略优化,一种较新的RLHF变体)支持。对于奖励模型,它也可以进行奖励模型微调。
4.3 优化
在底层,Axolotl捆绑了许多技巧:
- FlashAttention 和xFormers以加快注意力
- Liger内核(高效融合内核),
- 序列打包(他们称之为"Multipack")以充分利用上下文空间,
- 序列并行性
- 全分片数据并行(FSDP)
- 多GPU的DeepSpeed集成。
本质上,Axolotl试图为你提供DeepSpeed/Accelerate的好处,而无需你编写这些代码,你可以在配置中翻转一个开关来打开DeepSpeed ZeRO阶段2或3,例如。
它就像一个元框架,根据YAML编排PyTorch、Transformers、PEFT、DeepSpeed等。
4.4 集成
它可以从本地文件、HF Hub甚至云存储桶(S3、GCS)加载数据集。训练完成后,你可以轻松地将模型推送到Hugging Face Hub(通过huggingface_hub库,通过提供你的token)。
Axolotl还提供Docker镜像来封装环境,这对于确保跨设置的一致性很方便。
其他功能:
- 支持FP8微调 (通过PyTorch的原型FP8,使用
torch.ao后端启用),使其成为首批允许FP8的开源工具之一,这对新GPU所有者很棒。 - N-D并行性,在一个中结合张量、管道和数据并行策略(用于极端多GPU扩展)。
- 支持大量新研究模型如Magistral (Mistral变体)、Granite 4 、HunYuan等。
- 它还实现了用于长上下文训练的序列并行性(通过跨GPU分割序列实现超出单个GPU容纳范围的上下文长度)。
- 你还可以在Axolotl中使用Unsloth的打包数据加载器。
4.5 Axolotl YAML示例(LoRA微调)
假设我们想使用QLoRA在自定义指令数据集上微调Mistral 70亿参数模型。
我们可以创建mistral_qlora.yml:
base_model: lmsys/mistral-7b-v0.1
datasets:
- path: data/my_instructions.json
type: alpaca # 数据格式(Alpaca风格)
training:
num_epochs: 2
batch_size: 16
lr: 2e-4
peft:
method: qlora
lora_r: 16
lora_alpha: 32
target_modules:
- q_proj
- v_proj
#(要在模型的哪些部分附加LoRA)
hardware:
mixed_precision: bf16
deepspeed: "zero2" # 启用DeepSpeed ZeRO阶段2然后运行axolotl train mistral_qlora.yml将根据这些设置开始微调。
Axolotl将处理转换数据集、加载模型、应用LoRA、使用BF16的DeepSpeed等。
LoRA配置中的target_modules让我们指定我们只希望在某些层上使用LoRA(对于Mistral和LLaMA,通常针对Q和V线性层)。
这种细节级别是可配置的,而其他工具可能会硬编码默认值。
5、结束语
每个框架和工具都带有真实的社区和广泛的文档,帮助你实现为你的产品或研究定制大语言模型的最佳结果。
微调愉快!
原文链接:4个领先的大模型微调工具 - 汇智网