
🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
[4.4.1Visual Transformer (ViT)](#4.4.1Visual Transformer (ViT))
[4.4.2ResNet50 Pre-trained](#4.4.2ResNet50 Pre-trained)
[4.4.4Swin Transformer](#4.4.4Swin Transformer)
[4.4.5CNN 5-layer](#4.4.5CNN 5-layer)
1.项目背景
随着人工智能生成艺术技术的快速发展,AI创作的绘画、图像作品在视觉质量上已接近甚至在某些方面超越了人类艺术家的作品。这种技术进步引发了艺术界、学术界和社会公众对艺术本质、创造力来源以及人机关系的新一轮思考。如何有效区分人工智能生成艺术与人类创作艺术,不仅是一个有趣的技术挑战,更成为数字艺术认证、版权保护和教育研究中的实际问题。传统的人工鉴别方法依赖专家的主观经验,难以应对海量数字艺术作品的分类需求,且缺乏客观统一的评判标准。本项目旨在探索深度学习技术在艺术风格自动鉴别中的应用,通过对比卷积神经网络与Transformer等先进架构的性能表现,构建能够准确识别AI艺术与人类艺术的计算模型,为数字艺术分析提供科学化的技术工具,同时促进对人工智能创造力边界的深入理解。
2.数据集介绍
本实验数据集来源于Kaggle,数据集描述:人工智能与人类艺术
该数据集呈现了一系列精心挑选的视觉艺术作品,分为两个截然不同的类别:
- 利用先进生成模型创作的人工智能生成艺术
- 艺术家创作的艺术品
该数据集包含来自传统艺术家和数字艺术家的创作作品。每幅图像都标注了来源(AI 或人类),并包含风格、媒介和分辨率等元数据(如有)。该数据集旨在用于比较分析艺术特征、进行风格分类,以及对人工智能和人类表达的创造力进行基准测试。
应用案例:
- 训练图像分类器以区分人工智能艺术与人类艺术
- 研究机器和人类创造力中的风格模式
- 构建可解释的艺术作品归属模型
- 支持计算创造力和视觉美学领域的学术研究
📁 结构:
- /AI/ --- contains AI-generated artworks
- /Human/ --- contains human-created artworks

3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验过程
4.1导入数据
数据导入是项目实施的起点,需要配置完整的深度学习环境并设置基础参数。艺术图像分类任务对视觉特征提取有较高要求,合理的工具选择和参数配置直接影响后续模型性能和实验复现性。
python
# ====================== 1. 标准库导入 ======================
import os # 操作系统接口,用于文件路径操作和目录管理
import math # 数学函数库,提供数学运算支持
import copy # 对象复制库,用于深度复制数据结构和模型
import random # 随机数生成库,用于数据采样和初始化
# ====================== 2. 数据处理与可视化库 ======================
import numpy as np # 数值计算库,提供高效的数组操作和数学函数
import pandas as pd # 数据处理库,用于表格数据的操作和分析
import matplotlib.pyplot as plt # 数据可视化库,用于绘制图表和图像显示
import seaborn as sns # 统计可视化库,基于matplotlib提供更美观的图表样式
from PIL import Image # Python图像处理库,支持多种图像格式的读取和操作
# ====================== 3. 实用工具与进度显示 ======================
from tqdm.auto import tqdm # 进度条库,提供训练和数据处理过程的可视化进度显示
# ====================== 4. 机器学习库(Scikit-Learn) ======================
from sklearn.model_selection import train_test_split # 数据集划分函数,用于训练集/验证集/测试集分割
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score # 模型评估指标
# ====================== 5. 深度学习库(PyTorch核心) ======================
import torch # PyTorch深度学习框架核心库
import torch.nn as nn # 神经网络模块,包含各种层和损失函数
import torch.optim as optim # 优化算法模块,包含SGD、Adam等优化器
from torch.utils.data import Dataset, DataLoader, random_split # 数据加载和处理工具
from torch.cuda.amp import GradScaler, autocast # 混合精度训练工具,提升训练速度并减少内存占用
# ====================== 6. 计算机视觉库(Torchvision & Timm) ======================
from torchvision import datasets, transforms # PyTorch视觉工具库,提供数据集和图像变换
import timm # PyTorch图像模型库,包含大量预训练的计算机视觉模型
# ====================== 配置参数 ======================
# 设备配置:优先使用GPU(CUDA),如果不可用则回退到CPU
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 数据目录:艺术图像数据集存储路径
DATA_DIR = "./ai-art-vs-human-art/Art"
# 随机种子:确保实验可重复性
SEED = 42
# 工作进程数:根据CPU核心数自动设置,最大化数据加载效率
NUM_WORKERS = max(1, os.cpu_count() - 1) # 保留1个CPU核心给系统,其余用于数据加载
# 图像尺寸:统一调整到224×224像素,这是ImageNet标准尺寸
IMG_SIZE = 224
# 批次大小:每个训练批次包含的图像数量
BATCH_SIZE = 32 # 平衡内存使用和训练效率的常用大小
# ImageNet标准化参数:使用预训练模型的默认均值和标准差
IMAGENET_DEFAULT_MEAN = [0.485, 0.456, 0.406] # RGB三通道的均值
IMAGENET_DEFAULT_STD = [0.229, 0.224, 0.225] # RGB三通道的标准差
# ====================== 设置随机种子确保可重复性 ======================
random.seed(SEED) # Python内置随机模块种子
np.random.seed(SEED) # NumPy随机种子
torch.manual_seed(SEED) # PyTorch CPU随机种子
torch.cuda.manual_seed(SEED) # PyTorch GPU随机种子艺术图像识别任务需要细致的数据组织策略和专门的数据增强方法,以捕捉AI艺术与人类艺术间的细微风格差异。这里定义了数据发现、变换增强和数据集类三个核心组件。
python
# ====================== 数据发现与组织函数 ======================
def find_classes_and_samples(root_dir):
"""
扫描数据目录,发现所有图像文件并组织为结构化样本列表。
参数:
root_dir: 数据集根目录,应包含以类别命名的子目录(如'AiArtData', 'RealArt')
返回:
final_samples: 列表,每个元素为(图像路径, 类别索引)的元组
class_names: 排序后的类别名称列表
"""
samples = [] # 存储所有发现的图像样本
classes = set() # 使用集合存储发现的唯一类别
valid_extensions = ('.jpg', '.jpeg', '.png', '.bmp', '.webp', '.tiff') # 支持的图像格式
# 检查数据目录是否存在
if not os.path.exists(root_dir):
print(f"Error: Directory {root_dir} not found.")
return [], []
# 遍历根目录下的所有项目(应为类别目录)
for class_name in sorted(os.listdir(root_dir)):
class_path = os.path.join(root_dir, class_name)
# 确认是目录而非文件
if os.path.isdir(class_path):
classes.add(class_name) # 添加到类别集合
# 遍历该类别目录下的所有文件
for img_name in os.listdir(class_path):
# 检查文件扩展名是否为支持的图像格式(不区分大小写)
if img_name.lower().endswith(valid_extensions):
img_path = os.path.join(class_path, img_name) # 构建完整路径
samples.append((img_path, class_name)) # 记录样本路径和类别名称
# 类别排序与索引映射:确保一致的类别顺序(AiArtData=0, RealArt=1)
class_names = sorted(list(classes))
class_to_idx = {cls_name: i for i, cls_name in enumerate(class_names)}
# 将类别名称转换为数字索引,形成最终样本列表
final_samples = [(path, class_to_idx[name]) for path, name in samples]
return final_samples, class_names
# ====================== 数据增强变换定义 ======================
def train_transforms(image_size=IMG_SIZE):
"""
训练集数据增强变换流水线。
参数:
image_size: 目标图像尺寸
返回:
组合的图像变换操作序列
"""
return transforms.Compose([
# 随机裁剪并调整尺寸:模拟不同构图和距离
transforms.RandomResizedCrop(image_size, scale=(0.8, 1.2)),
# 随机水平翻转:50%概率,增加数据多样性
transforms.RandomHorizontalFlip(p=0.5),
# TrivialAugmentWide:自动化数据增强策略,组合多种简单变换
transforms.TrivialAugmentWide(),
# 转换为Tensor:将PIL图像转换为PyTorch张量,并自动归一化到[0,1]
transforms.ToTensor(),
# ImageNet标准化:使用预训练模型的均值和标准差
transforms.Normalize(mean=IMAGENET_DEFAULT_MEAN, std=IMAGENET_DEFAULT_STD)
])
def val_transforms(image_size=IMG_SIZE):
"""
验证/测试集数据变换流水线(不包含随机增强)。
参数:
image_size: 目标图像尺寸
返回:
组合的图像变换操作序列
"""
# 计算调整尺寸:先稍微放大再中心裁剪,保留更多原始信息
resize_dim = int(image_size * 1.14) # 放大14%
return transforms.Compose([
# 双三次插值调整尺寸:保持图像质量
transforms.Resize(resize_dim, interpolation=transforms.InterpolationMode.BICUBIC),
# 中心裁剪:确保输入尺寸一致
transforms.CenterCrop(image_size),
# 转换为Tensor
transforms.ToTensor(),
# ImageNet标准化
transforms.Normalize(mean=IMAGENET_DEFAULT_MEAN, std=IMAGENET_DEFAULT_STD)
])
# ====================== 自定义数据集类 ======================
class Dataset(Dataset):
"""
自定义PyTorch数据集类,用于高效加载和处理图像数据。
继承自torch.utils.data.Dataset,必须实现__len__和__getitem__方法。
"""
def __init__(self, samples, transform=None):
"""
初始化数据集。
参数:
samples: 样本列表,每个元素为(图像路径, 类别索引)
transform: 图像变换流水线
"""
self.samples = samples # 存储样本数据
self.transform = transform # 图像变换函数
def __len__(self):
"""返回数据集中样本的总数。"""
return len(self.samples)
def __getitem__(self, idx):
"""
获取指定索引的样本。
参数:
idx: 样本索引
返回:
image: 处理后的图像张量
target: 对应的类别标签(整数索引)
"""
path, target = self.samples[idx] # 提取路径和标签
try:
# 加载图像并统一转换为RGB格式(确保3通道)
image = Image.open(path).convert('RGB')
except Exception as e:
# 图像加载失败时的容错处理:创建空白图像占位
print(f"Error loading image {path}: {e}")
image = Image.new('RGB', (IMG_SIZE, IMG_SIZE))
# 应用指定的图像变换(训练集增强或验证集标准化)
if self.transform:
image = self.transform(image)
return image, target下面将已发现的艺术图像样本划分为训练集和验证集,创建高效的数据加载管道,并输出关键统计数据。分层抽样策略确保了两个艺术类别(AI艺术和人类艺术)在划分后的分布平衡。
python
# ====================== 加载所有样本数据 ======================
# 调用数据发现函数,获取所有图像样本和类别名称
all_samples, class_names = find_classes_and_samples(DATA_DIR)
# 提取所有样本的类别标签,用于分层抽样
all_targets = [s[1] for s in all_samples]
# 数据完整性检查:确保至少找到一些图像文件
if len(all_samples) == 0:
raise Exception("Error: No image found. recheck DATA_DIR path:", DATA_DIR)
# ====================== 分层划分数据集 ======================
# 将全部样本按80%训练集、20%验证集的比例进行分层划分
# stratify=all_targets: 确保训练集和验证集中AI艺术与人类艺术的比例与原始数据集相同
train_samples, val_samples = train_test_split(
all_samples, # 所有样本数据
test_size=0.2, # 验证集比例20%
random_state=SEED, # 固定随机种子确保可重复划分
stratify=all_targets # 按类别标签分层抽样,保持分布平衡
)
# ====================== 创建训练和验证数据集实例 ======================
# 训练数据集:应用包含数据增强的变换流水线
train_dataset = Dataset(train_samples, transform=train_transforms(IMG_SIZE))
# 验证数据集:应用仅标准化的变换流水线(无随机增强)
val_dataset = Dataset(val_samples, transform=val_transforms(IMG_SIZE))
# ====================== 创建训练数据加载器 ======================
train_loader = DataLoader(
train_dataset, # 训练数据集实例
batch_size=BATCH_SIZE, # 每批加载32个样本
shuffle=True, # 每个epoch开始时打乱数据顺序
num_workers=NUM_WORKERS, # 使用多进程并行加载数据
persistent_workers=True, # 保持工作进程活动状态,减少进程创建开销
pin_memory=True # 将数据固定在页锁定内存,加速GPU数据传输
)
# ====================== 创建验证数据加载器 ======================
val_loader = DataLoader(
val_dataset, # 验证数据集实例
batch_size=BATCH_SIZE, # 每批32个样本
shuffle=False, # 验证集不进行打乱,保持评估一致性
num_workers=NUM_WORKERS, # 同样使用多进程加载
persistent_workers=True, # 保持工作进程
pin_memory=True # 固定内存加速传输
)
# ====================== 输出数据集统计信息 ======================
print(f"Training Set : {len(train_dataset)} images") # 训练集图像数量
print(f"Validation Set: {len(val_dataset)} images") # 验证集图像数量
print(f"Total Classes : {len(class_names)}") # 总类别数(应为2:AI艺术和人类艺术)
4.2数据可视化

数据可视化是理解数据集特征、检查数据平衡性的关键步骤。艺术图像分类任务中,AI生成艺术与人类创作艺术的数据分布可能天然不平衡,这会直接影响模型的学习重点和评估策略。本节通过类别分布条形图直观展示数据集的组成结构。
python
# ====================== 准备可视化数据 ======================
# 从所有样本中提取类别索引(0表示AI艺术,1表示人类艺术)
all_targets_indices = [s[1] for s in all_samples]
# 创建DataFrame存储标签数据,便于统计和分析
df_counts = pd.DataFrame({'label_idx': all_targets_indices})
# 将数字索引映射回可读的类别名称(如'AiArtData', 'RealArt')
df_counts['class_name'] = df_counts['label_idx'].map(lambda x: class_names[x])
# 统计每个类别的图像数量,并按类别名称排序确保一致显示顺序
class_counts = df_counts['class_name'].value_counts().sort_index()
# ====================== 创建类别分布条形图 ======================
# 创建图形窗口,尺寸为8×5英寸,适合展示两个类别的分布
plt.figure(figsize=(8, 5))
# 使用seaborn绘制条形图,magma配色方案提供良好的视觉对比
sns.barplot(x=class_counts.index, y=class_counts.values, palette='magma')
# 设置图表标题和坐标轴标签
plt.title('Distribution: AI Art vs Real Art', fontsize=14) # 标题,明确展示对比关系
plt.xlabel('Class', fontsize=12) # x轴标签:类别
plt.ylabel('Number of Images', fontsize=12) # y轴标签:图像数量
# 在每个条形上方添加精确的数值标注
for i, v in enumerate(class_counts.values):
# 在条形顶部上方20像素处显示数值,居中对齐
plt.text(i, v + 20, str(v), ha='center', va='bottom')
# 显示完整图表
plt.show()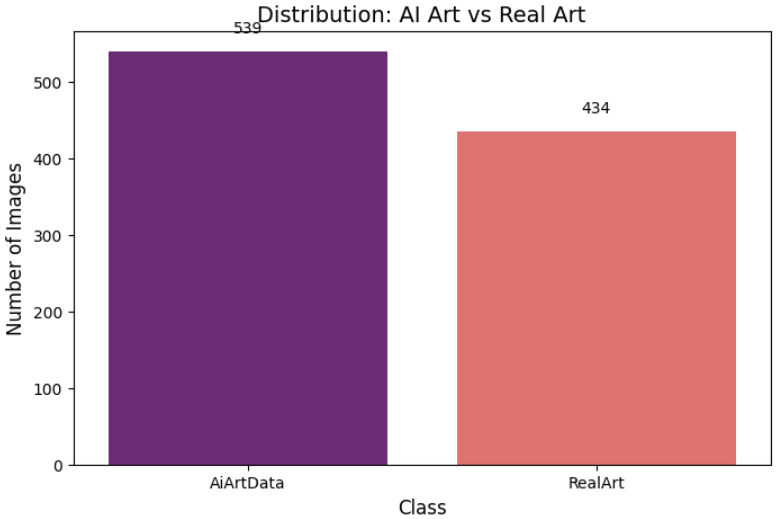
接下来我们通过随机样本展示来直观比较AI生成艺术与人类创作艺术的视觉特征。对于艺术鉴别任务,仅仅了解数据分布还不够,需要实际观察图像内容来理解两类艺术在风格、纹理、构图等方面的差异,这对后续模型设计和特征提取策略有重要指导意义。
python
# ====================== 设置可视化参数 ======================
num_samples_per_class = 4 # 每个类别显示4个样本,平衡信息量和显示空间
# 创建子图网格:行数=类别数(2),列数=4,总8个子图,尺寸15×8英寸
fig, axes = plt.subplots(len(class_names), num_samples_per_class, figsize=(15, 8))
# 设置图形总标题,突出对比主题
fig.suptitle('Random Samples: AI vs Real Art', fontsize=16)
# ====================== 遍历每个类别显示样本 ======================
for i, cls_name in enumerate(class_names): # i: 类别索引(0,1); cls_name: 类别名称
# 筛选属于当前类别的所有样本路径
# all_samples中每个元素为(图像路径, 类别索引)
# 通过class_names[s[1]]获取样本的类别名称,与当前cls_name比较
cls_samples = [s[0] for s in all_samples if class_names[s[1]] == cls_name]
# 随机选择指定数量的样本,如果该类样本不足则取全部
# random.sample(): 无放回随机抽样,确保样本不重复
# min(len(cls_samples), num_samples_per_class): 防止样本不足时的索引错误
selected_samples = random.sample(cls_samples, min(len(cls_samples), num_samples_per_class))
# ================== 显示当前类别的随机样本 ==================
for j, img_path in enumerate(selected_samples):
try:
# 尝试加载并显示图像
img = Image.open(img_path) # 打开图像文件
axes[i, j].imshow(img) # 在对应子图位置显示图像
axes[i, j].set_title(cls_name) # 设置子图标题为类别名称
axes[i, j].axis('off') # 关闭坐标轴,使图像显示更清晰
except Exception as e:
# 图像加载失败时的错误处理:显示错误提示文本
axes[i, j].text(0.5, 0.5, "Error", ha='center') # 在子图中心显示"Error"
# ====================== 调整布局并显示 ======================
# 自动调整子图间距,避免标题和图像重叠
plt.tight_layout()
# 显示完整的可视化图形
plt.show()
4.3特征工程
这里我们定义了一组核心功能函数,为后续的模型构建、训练和评估提供标准化的工具。这些函数封装了数据准备、模型训练、结果可视化和性能评估的完整流程,体现了模块化编程思想,提高了代码复用性和实验效率。
python
# ====================== 数据准备函数 ======================
def get_data_setup(batch_size=32, test_size=0.2, image_size=224):
"""
一站式数据准备函数:加载数据、划分数据集、创建数据加载器。
参数:
batch_size: 批次大小,默认32
test_size: 验证集比例,默认20%
image_size: 输入图像尺寸,默认224×224
返回:
train_loader: 训练数据加载器
val_loader: 验证数据加载器
class_names: 类别名称列表
"""
# 加载所有样本数据和类别名称
all_samples, class_names = find_classes_and_samples(DATA_DIR)
all_targets = [s[1] for s in all_samples] # 提取所有标签用于分层抽样
# 分层划分训练集和验证集
train_samples, val_samples = train_test_split(
all_samples, test_size=test_size, random_state=SEED, stratify=all_targets
)
# 创建数据集实例,分别应用训练和验证的变换
train_ds = Dataset(train_samples, transform=train_transforms(image_size))
val_ds = Dataset(val_samples, transform=val_transforms(image_size))
# 创建数据加载器,优化配置以加速训练
train_loader = DataLoader(train_ds, batch_size=batch_size, shuffle=True,
num_workers=NUM_WORKERS, persistent_workers=True, pin_memory=True)
val_loader = DataLoader(val_ds, batch_size=batch_size, shuffle=False,
num_workers=NUM_WORKERS, persistent_workers=True, pin_memory=True)
return train_loader, val_loader, class_names
# ====================== 模型训练函数 ======================
def train_model(model, train_loader, val_loader, criterion, optimizer,
scheduler=None, epochs=16, device=DEVICE, model_name="Model"):
"""
通用模型训练函数,支持混合精度训练、学习率调度和最佳模型保存。
参数:
model: 待训练的模型
train_loader: 训练数据加载器
val_loader: 验证数据加载器
criterion: 损失函数
optimizer: 优化器
scheduler: 学习率调度器(可选)
epochs: 训练轮数,默认16
device: 训练设备(CPU/GPU)
model_name: 模型名称,用于保存文件
返回:
model: 训练后的模型(加载了最佳权重)
history: 训练历史记录字典
"""
print(f"\n[Training] Starting: {model_name} | Epochs: {epochs}")
save_filename = f"{model_name}.pth" # 最佳模型保存文件名
# 模型和设备准备
model = model.to(device)
scaler = torch.amp.GradScaler('cuda') # 梯度缩放器,支持混合精度训练
best_model_wts = copy.deepcopy(model.state_dict()) # 深拷贝当前最佳权重
best_acc = 0.0 # 跟踪最佳验证准确率
# 初始化训练历史记录
history = {'train_loss': [], 'train_acc': [], 'val_loss': [], 'val_acc': []}
# 开始训练循环
for epoch in range(epochs):
# ---------- 训练阶段 ----------
train_loss = 0.0
train_correct = 0
train_total = 0
model.train() # 设置为训练模式
pbar = tqdm(train_loader, desc=f"{model_name} Ep {epoch+1}/{epochs}", leave=False)
for inputs, labels in pbar:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad() # 清空梯度
# 混合精度训练前向传播
with torch.amp.autocast('cuda'):
outputs = model(inputs)
loss = criterion(outputs, labels)
# 混合精度反向传播和优化
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
# 统计训练结果
_, preds = torch.max(outputs, 1)
train_loss += loss.item() * inputs.size(0)
train_correct += torch.sum(preds == labels.data)
train_total += labels.size(0)
pbar.set_postfix(loss=loss.item()) # 在进度条中显示当前损失
epoch_train_loss = train_loss / train_total
epoch_train_acc = train_correct.double() / train_total
# ---------- 验证阶段 ----------
model.eval() # 设置为评估模式
val_loss = 0.0
val_correct = 0
val_total = 0
with torch.no_grad(): # 禁用梯度计算,节省内存
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
val_loss += loss.item() * inputs.size(0)
val_correct += torch.sum(preds == labels.data)
val_total += labels.size(0)
epoch_val_loss = val_loss / val_total
epoch_val_acc = val_correct.double() / val_total
# 获取当前学习率用于显示
current_lr = optimizer.param_groups[0]['lr']
# 学习率调度器步进(如果提供)
if scheduler:
if isinstance(scheduler, torch.optim.lr_scheduler.ReduceLROnPlateau):
scheduler.step(epoch_val_loss) # 基于验证损失调整学习率
else:
scheduler.step() # 标准调度器步进
# 保存历史记录
history['train_loss'].append(epoch_train_loss)
history['train_acc'].append(epoch_train_acc.item())
history['val_loss'].append(epoch_val_loss)
history['val_acc'].append(epoch_val_acc.item())
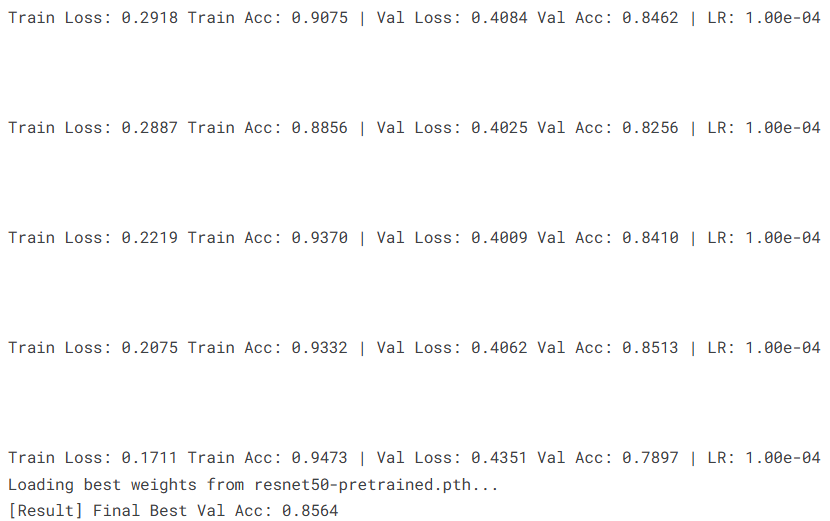
# 输出当前epoch结果
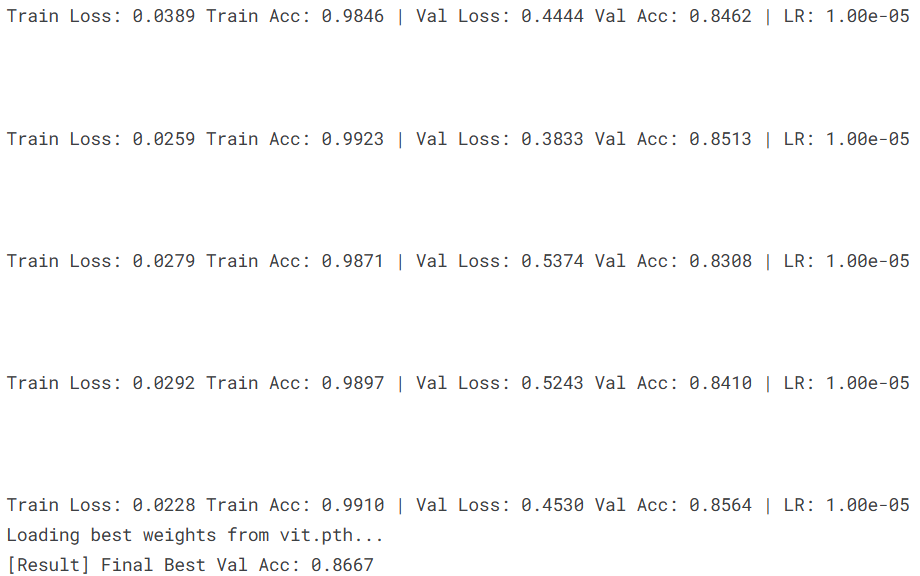
print(f"Train Loss: {epoch_train_loss:.4f} Train Acc: {epoch_train_acc:.4f} | "
f"Val Loss: {epoch_val_loss:.4f} Val Acc: {epoch_val_acc:.4f} | "
f"LR: {current_lr:.2e}")
# 检查点:保存最佳模型
if epoch_val_acc > best_acc:
best_acc = epoch_val_acc
torch.save(model.state_dict(), save_filename)
print(f"Best {model_name} saved as {save_filename}")
# 训练结束,加载最佳模型权重
if os.path.exists(save_filename):
print(f"Loading best weights from {save_filename}...")
model.load_state_dict(torch.load(save_filename))
else:
print(f"[Warning] No model file saved. Check file {save_filename}")
print(f"[Result] Final Best Val Acc: {best_acc:.4f}")
return model, history
# ====================== 结果可视化函数 ======================
def plot_results(history, title="Model Performance"):
"""
绘制训练过程中的损失和准确率曲线。
参数:
history: 训练历史记录字典
title: 图表标题
"""
fig, ax = plt.subplots(1, 2, figsize=(12, 5))
# 损失曲线
ax[0].plot(history['train_loss'], label='Train Loss')
ax[0].plot(history['val_loss'], label='Val Loss')
ax[0].set_title(f'{title} - Loss')
ax[0].legend()
ax[0].grid(True)
# 准确率曲线
ax[1].plot(history['train_acc'], label='Train Acc')
ax[1].plot(history['val_acc'], label='Val Acc')
ax[1].set_title(f'{title} - Accuracy')
ax[1].legend()
ax[1].grid(True)
plt.tight_layout()
plt.show()
# ====================== 模型评估函数 ======================
def evaluate_model(model, loader, class_names, device=DEVICE):
"""
全面评估模型性能,生成分类报告和混淆矩阵。
参数:
model: 待评估的模型
loader: 数据加载器
class_names: 类别名称列表
device: 计算设备
"""
model.eval() # 设置为评估模式
y_true, y_pred = [], [] # 存储真实标签和预测标签
# 在数据加载器上运行推理
with torch.no_grad():
for inputs, labels in tqdm(loader, desc="Evaluating"):
inputs = inputs.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1) # 获取预测类别
y_true.extend(labels.cpu().numpy()) # 收集真实标签
y_pred.extend(preds.cpu().numpy()) # 收集预测标签
# 打印详细分类报告
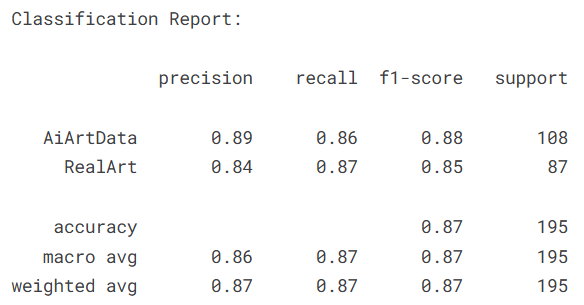
print("\nClassification Report:\n")
print(classification_report(y_true, y_pred, target_names=class_names))
# 计算混淆矩阵
cm = confusion_matrix(y_true, y_pred)
# 绘图1:标准混淆矩阵(原始计数)
plt.figure(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=class_names, yticklabels=class_names)
plt.title("Confusion Matrix (Counts)")
plt.ylabel('True Label')
plt.xlabel('Predicted Label')
plt.xticks(rotation=45, ha='right')
plt.show()
# 绘图2:归一化混淆矩阵(百分比)
# 按行归一化(基于真实类别计数)
cm_normalized = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
plt.figure(figsize=(10, 8))
sns.heatmap(cm_normalized, annot=True, fmt='.2f', cmap='Blues',
xticklabels=class_names, yticklabels=class_names)
plt.title("Normalized Confusion Matrix")
plt.ylabel('True Label')
plt.xlabel('Predicted Label')
plt.xticks(rotation=45, ha='right')
plt.show()4.4训练并评估模型
本节开始执行具体的模型训练。
4.4.1Visual Transformer (ViT)
首先训练基于Vision Transformer (ViT)的预训练模型,这是当前计算机视觉领域的前沿架构。Transformer模型通过自注意力机制捕获全局上下文信息,特别适合捕捉艺术图像中的风格特征和构图关系。我们将利用在ImageNet上预训练的ViT模型进行迁移学习,适应AI艺术与人类艺术的分类任务。
python
# ====================== ViT模型训练配置 ======================
BATCH_SIZE = 32 # 批次大小:平衡内存使用和梯度估计稳定性
EPOCHS = 16 # 训练轮数:预训练模型通常需要较少的fine-tuning轮次
LR = 1e-5 # 学习率:较小的学习率适合预训练模型的微调,避免破坏已学特征
# ====================== 准备数据加载器 ======================
# 调用数据准备函数,获取训练和验证数据加载器以及类别名称
train_loader, val_loader, class_names = get_data_setup(
batch_size=BATCH_SIZE, # 指定批次大小
test_size=0.2, # 验证集比例为20%
image_size=224 # 输入图像尺寸为224×224
)
# ====================== 创建ViT模型实例 ======================
# 使用timm库创建预训练的Vision Transformer模型
# 'vit_base_patch16_224': ViT-Base架构,16×16的patch大小,224输入尺寸
# pretrained=True: 加载在ImageNet-21k上预训练的权重
# num_classes=len(class_names): 将输出层调整为二分类(AI艺术 vs 人类艺术)
model = timm.create_model('vit_base_patch16_224',
pretrained=True,
num_classes=len(class_names))
# ====================== 配置优化器和损失函数 ======================
# AdamW优化器:Adam的改进版本,将权重衰减与梯度更新解耦
# lr=LR: 使用1e-5的学习率,较小的学习率适合预训练模型微调
# weight_decay=1e-2: L2正则化系数,防止过拟合
optimizer = optim.AdamW(model.parameters(), lr=LR, weight_decay=1e-2)
# 交叉熵损失函数:多分类任务的标准损失函数
criterion = nn.CrossEntropyLoss()
# ====================== 执行ViT模型训练 ======================
# 调用通用训练函数,开始ViT模型的训练过程
trained_model, history_vit = train_model(
model=model, # 待训练的ViT模型
train_loader=train_loader, # 训练数据加载器
val_loader=val_loader, # 验证数据加载器
criterion=criterion, # 损失函数
optimizer=optimizer, # 优化器
epochs=EPOCHS, # 训练轮数16
device=DEVICE, # 训练设备(GPU)
model_name="vit" # 模型名称,用于保存文件
)
接着进行模型评估
python
plot_results(history_vit, title="vit")
evaluate_model(trained_model, val_loader, class_names, device=DEVICE)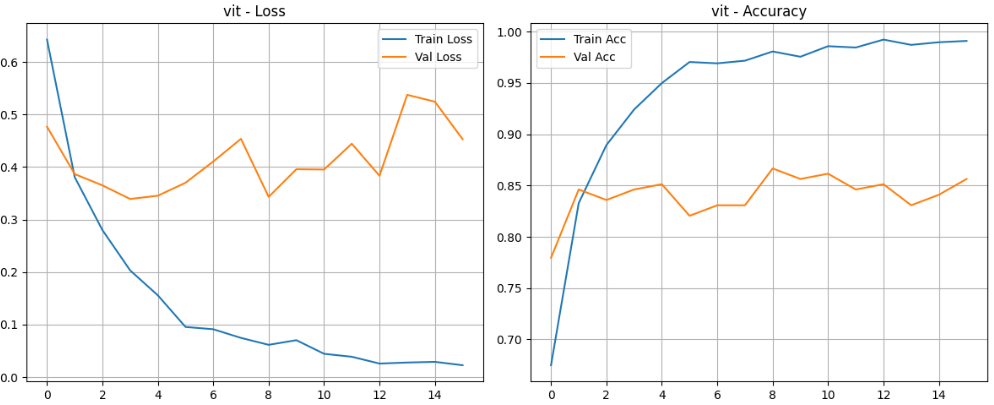
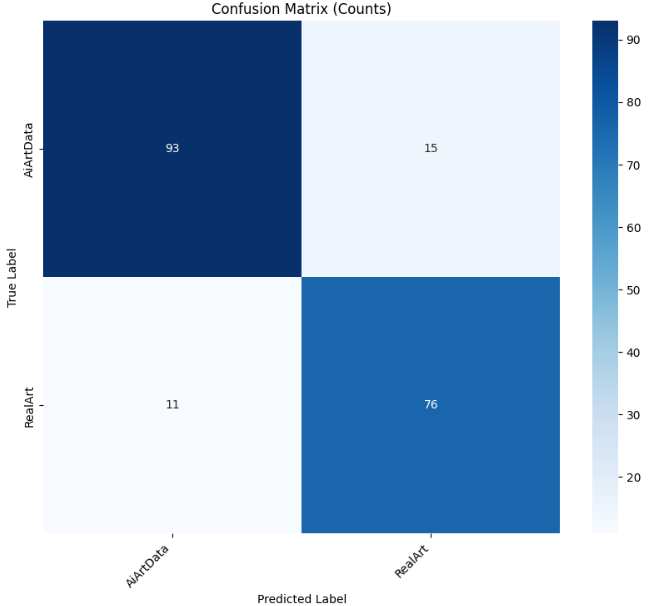
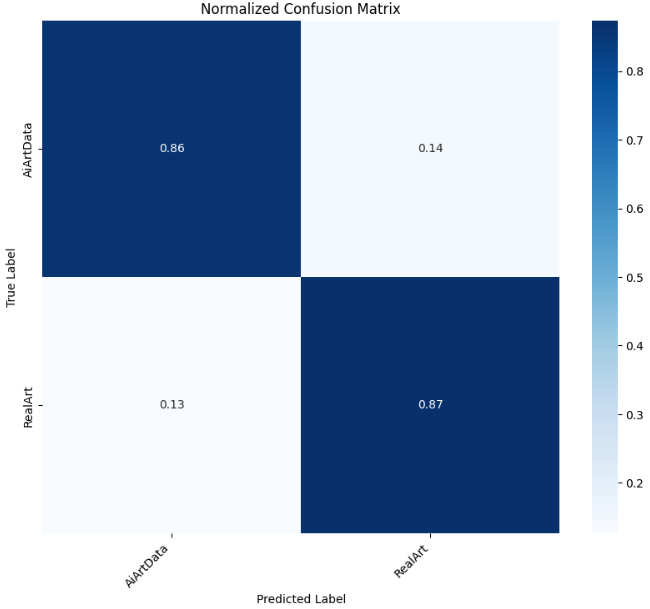
4.4.2ResNet50 Pre-trained
继续训练第二个模型------预训练的ResNet50。作为卷积神经网络(CNN)的代表性架构,ResNet50通过残差连接解决了深层网络梯度消失问题,在计算机视觉任务中表现出优异的性能和稳定性。通过对比ViT和ResNet50在艺术分类任务上的表现,我们可以深入了解不同架构在风格特征提取方面的优势和局限。
python
# ====================== ResNet50模型训练配置 ======================
BATCH_SIZE = 32 # 保持与ViT相同的批次大小,确保公平比较
EPOCHS = 16 # 相同训练轮数,便于架构间性能对比
LR = 1e-4 # 学习率设为1e-4,比ViT的1e-5大一个数量级,反映CNN的不同优化特性
# ====================== 准备数据加载器 ======================
# 重新调用数据准备函数,获取独立的数据加载器实例
# 虽然使用相同参数,但重新调用确保数据加载的独立性
train_loader, val_loader, class_names = get_data_setup(
batch_size=BATCH_SIZE, # 批次大小32
test_size=0.2, # 20%验证集
image_size=224 # 224×224输入尺寸
)
# ====================== 创建ResNet50模型实例 ======================
# 使用timm库创建预训练的ResNet50模型
# 'resnet50': 标准的50层残差网络架构
# pretrained=True: 加载在ImageNet上预训练的权重
# num_classes=len(class_names): 将1000类的ImageNet分类头替换为二分类头
model = timm.create_model('resnet50',
pretrained=True,
num_classes=len(class_names))
# ====================== 配置优化器和损失函数 ======================
# AdamW优化器:同样使用AdamW,保持与ViT实验的一致性
# lr=LR: 学习率设为1e-4,适合CNN模型的微调
# weight_decay=1e-2: 相同的权重衰减系数,控制模型复杂度
optimizer = optim.AdamW(model.parameters(), lr=LR, weight_decay=1e-2)
# 交叉熵损失函数:与ViT使用相同的损失函数,确保可比性
criterion = nn.CrossEntropyLoss()
# ====================== 执行ResNet50模型训练 ======================
# 调用通用训练函数,开始ResNet50模型的训练
trained_model, history_resnet_pretrained = train_model(
model=model, # 待训练的ResNet50模型
train_loader=train_loader, # 训练数据加载器
val_loader=val_loader, # 验证数据加载器
criterion=criterion, # 损失函数
optimizer=optimizer, # 优化器
epochs=EPOCHS, # 训练16个epoch
device=DEVICE, # GPU设备
model_name="resnet50-pretrained" # 模型名称,便于区分保存文件
)
接着进行模型评估
python
plot_results(history_resnet_pretrained, title="resnet50-pretrained")
evaluate_model(trained_model, val_loader, class_names, device=DEVICE)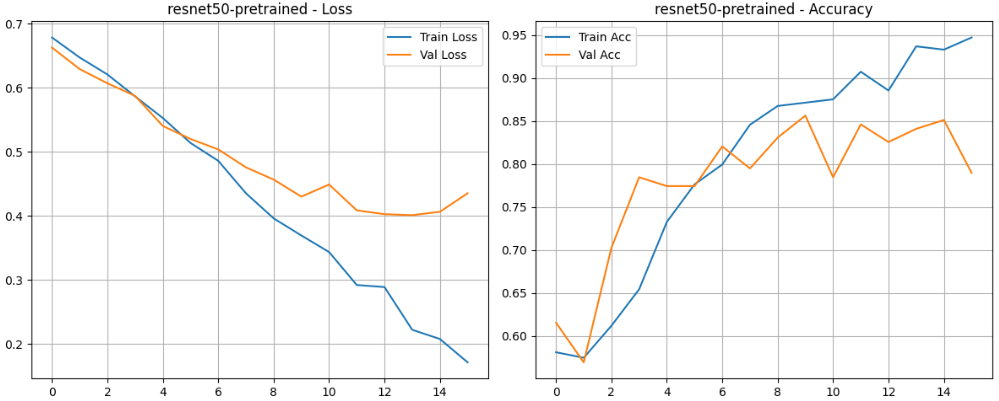
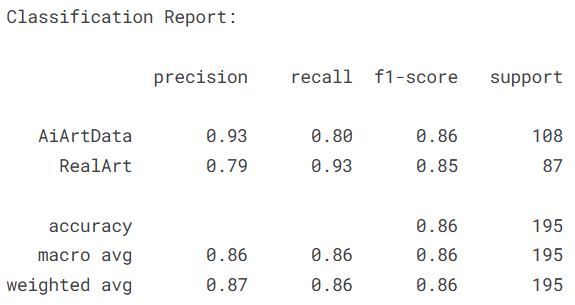
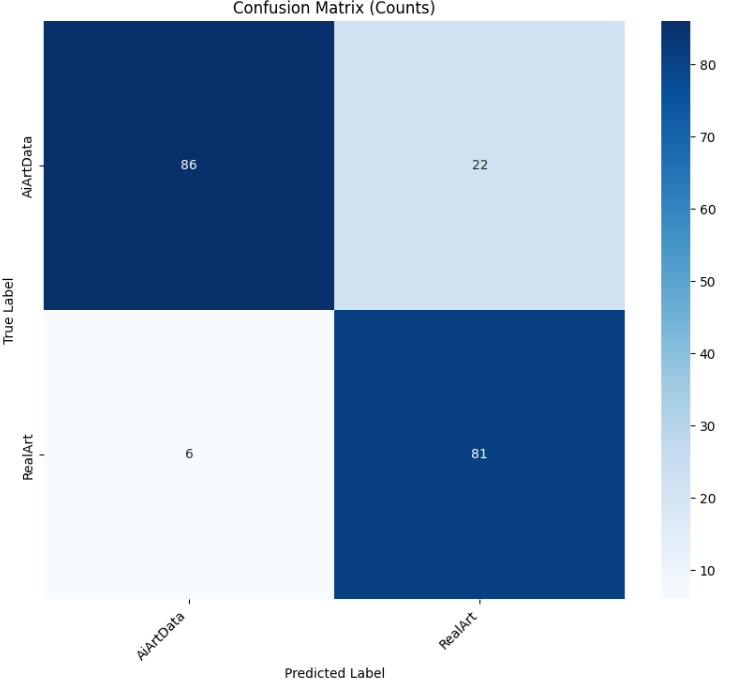
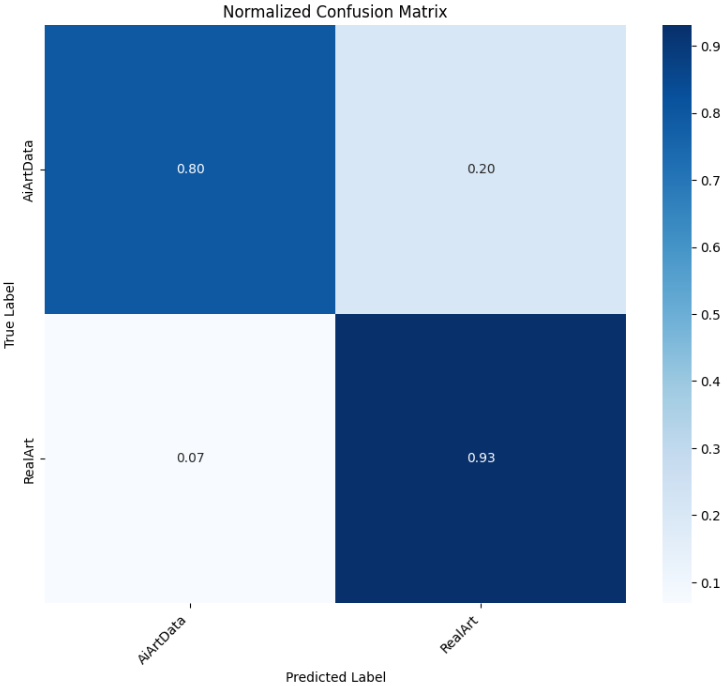
4.4.3ResNet50
接下来训练第三个模型------从头开始训练的ResNet50(非预训练版本)。这个实验设计用于对比迁移学习与从头训练的差异,评估预训练权重在艺术分类任务中的实际价值。从头训练模型完全依赖当前艺术数据集学习特征,可以揭示艺术图像的固有模式与自然图像的异同。
python
# ====================== ResNet50从头训练配置 ======================
BATCH_SIZE = 32 # 保持一致批次大小,确保实验条件可比
EPOCHS = 16 # 相同训练轮数,观察不同初始化下的收敛速度
LR = 1e-3 # 学习率设为1e-3,从头训练需要更大学习率加速收敛
# ====================== 准备数据加载器 ======================
# 重新获取数据加载器,虽然参数相同但确保数据独立性
train_loader, val_loader, class_names = get_data_setup(
batch_size=BATCH_SIZE, # 32个样本每批次
test_size=0.2, # 20%验证集
image_size=224 # 标准224×224输入
)
# ====================== 创建ResNet50模型实例(无预训练) ======================
# 创建未加载预训练权重的ResNet50模型
# pretrained=False: 不加载ImageNet预训练权重,使用随机初始化
# num_classes=len(class_names): 直接构建二分类输出层
model = timm.create_model('resnet50',
pretrained=False, # 关键区别:从头开始训练
num_classes=len(class_names))
# ====================== 配置优化器和损失函数 ======================
# AdamW优化器:保持与前两个实验相同的优化算法
# lr=LR: 学习率1e-3,比预训练版本大10倍,适应随机初始化的较大梯度
# weight_decay=1e-2: 相同的权重衰减,控制过拟合
optimizer = optim.AdamW(model.parameters(), lr=LR, weight_decay=1e-2)
# 交叉熵损失函数:统一损失函数,保持实验一致性
criterion = nn.CrossEntropyLoss()
# ====================== 执行ResNet50从头训练 ======================
# 调用训练函数,开始从头训练过程
trained_model, history_resnet = train_model(
model=model, # 随机初始化的ResNet50模型
train_loader=train_loader, # 训练数据
val_loader=val_loader, # 验证数据
criterion=criterion, # 损失函数
optimizer=optimizer, # 优化器
epochs=EPOCHS, # 16个epoch
device=DEVICE, # GPU设备
model_name="resnet50" # 模型名称,无pretrained后缀以示区别
)
接下来进行模型评估
python
plot_results(history_resnet, title="resnet50")
evaluate_model(trained_model, val_loader, class_names, device=DEVICE)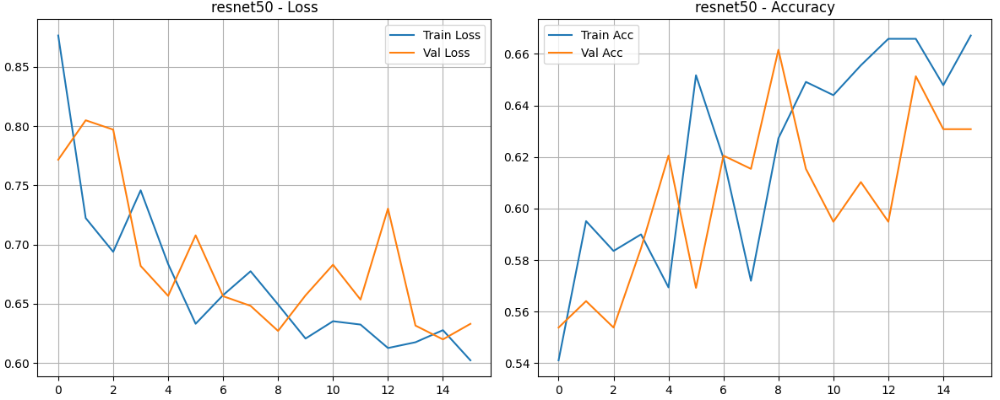
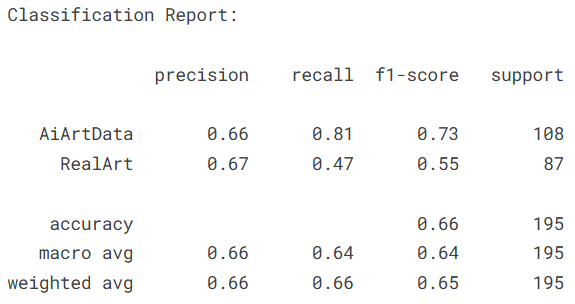
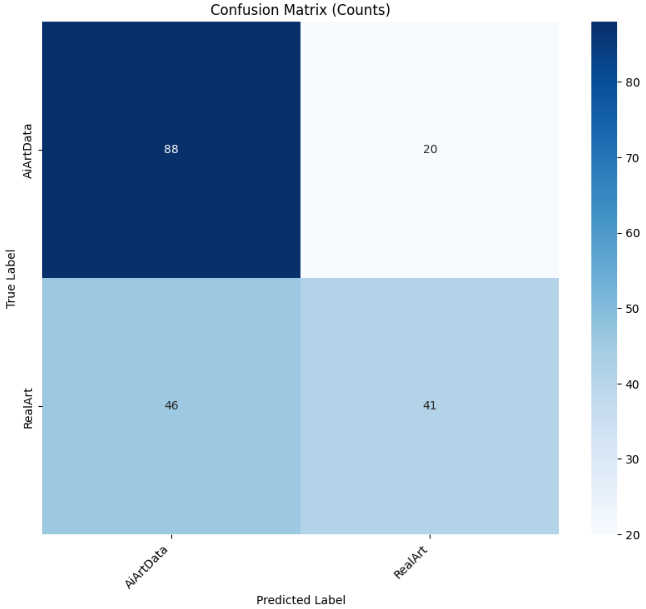
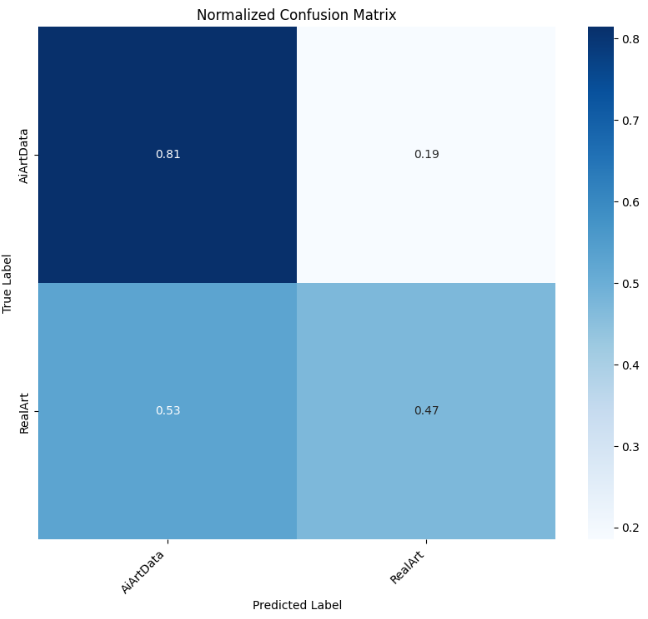
4.4.4Swin Transformer
接下来训练第四个模型------预训练的Swin Transformer。Swin Transformer(Shifted Window Transformer)是一种层次化的Transformer变体,通过局部窗口注意力机制在保持全局建模能力的同时显著降低计算复杂度。相比标准ViT的全局自注意力,Swin Transformer的移位窗口设计更适合捕捉艺术图像中的多尺度特征和局部细节。
python
# ====================== Swin Transformer模型训练配置 ======================
BATCH_SIZE = 32 # 保持统一的批次大小,确保实验条件一致
EPOCHS = 16 # 相同训练轮数,便于架构间横向比较
LR = 1e-4 # 学习率设为1e-4,介于ViT(1e-5)和ResNet(1e-4)之间
# ====================== 准备数据加载器 ======================
# 重新获取数据加载器,确保每次实验数据加载独立
train_loader, val_loader, class_names = get_data_setup(
batch_size=BATCH_SIZE, # 32批次
test_size=0.2, # 20%验证集
image_size=224 # 224输入尺寸
)
# ====================== 创建Swin Transformer模型实例 ======================
# 使用timm库创建预训练的Swin Transformer模型
# 'swin_base_patch4_window7_224': Swin-Base架构,4×4的patch划分,7×7的窗口大小
# pretrained=True: 加载在ImageNet-22k上预训练的权重
# num_classes=len(class_names): 调整为艺术二分类任务
model = timm.create_model('swin_base_patch4_window7_224',
pretrained=True,
num_classes=len(class_names))
# ====================== 配置优化器和损失函数 ======================
# AdamW优化器:统一使用AdamW,保持优化算法一致性
# lr=LR: 1e-4学习率,适合Swin Transformer的微调
# weight_decay=1e-2: 相同权重衰减系数
optimizer = optim.AdamW(model.parameters(), lr=LR, weight_decay=1e-2)
# 交叉熵损失函数:统一损失函数
criterion = nn.CrossEntropyLoss()
# ====================== 执行Swin Transformer模型训练 ======================
# 调用训练函数,开始Swin Transformer的训练
trained_model, history_swin = train_model(
model=model, # Swin Transformer模型
train_loader=train_loader, # 训练数据
val_loader=val_loader, # 验证数据
criterion=criterion, # 损失函数
optimizer=optimizer, # 优化器
epochs=EPOCHS, # 16个epoch
device=DEVICE, # GPU设备
model_name="swin" # 模型名称,简洁标识
)
接下来进行模型评估
python
plot_results(history_swin, title="swin")
evaluate_model(trained_model, val_loader, class_names, device=DEVICE)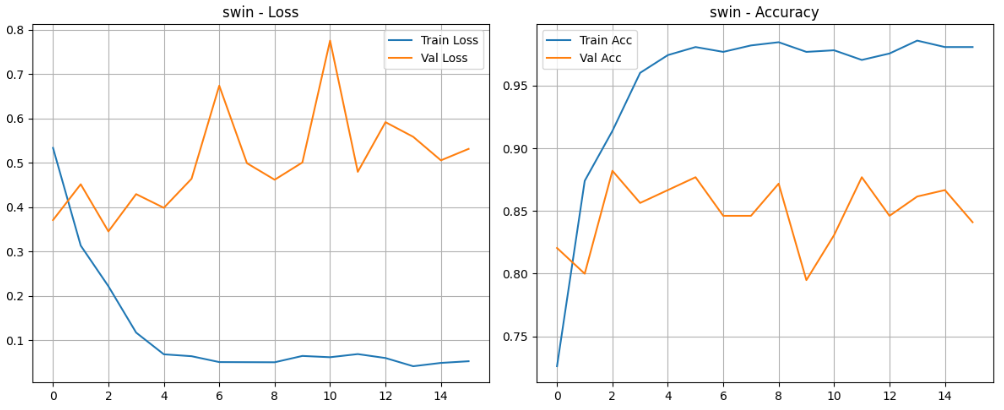
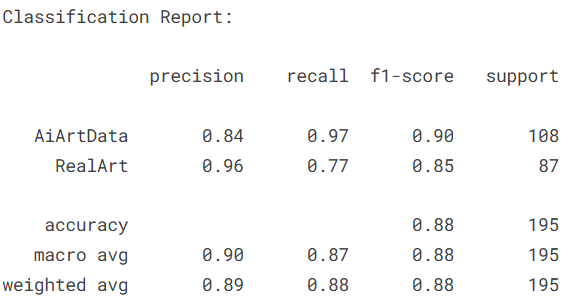
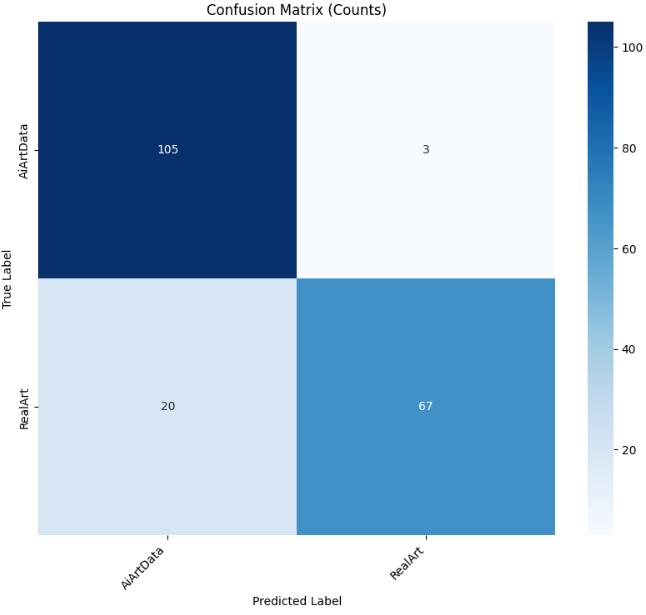
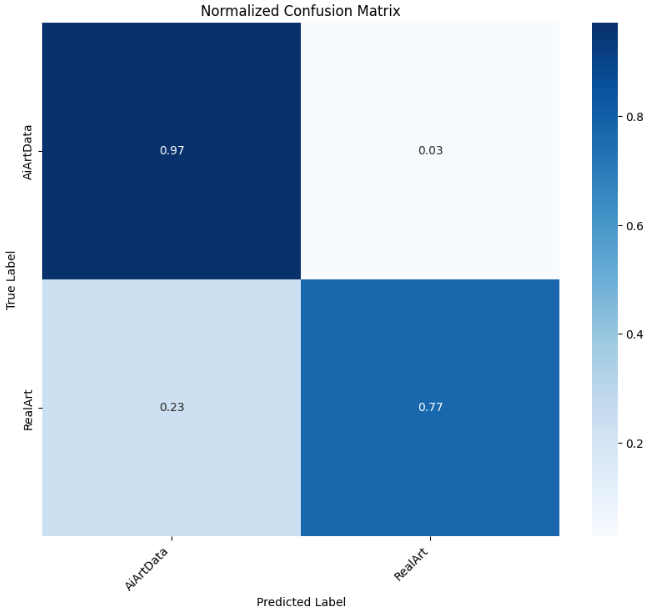
4.4.5CNN 5-layer
接下来训练第五个模型------自定义的5层纯CNN模型。这是一个完全从头设计和训练的轻量级卷积神经网络,不依赖任何预训练权重。相比复杂的ResNet50和Transformer架构,这个简洁的CNN模型提供了基准性能参考,帮助我们理解在有限数据下,简单模型能否有效捕捉AI艺术与人类艺术的本质差异。
python
# ====================== 自定义5层CNN模型定义 ======================
class PureCNN5Layer(nn.Module):
"""
自定义5层卷积神经网络,专为艺术图像分类设计。
简洁的CNN架构提供基准性能,便于与复杂模型对比。
"""
def __init__(self, num_classes):
super(PureCNN5Layer, self).__init__()
# 特征提取层:5个卷积块,逐步增加通道数,减少空间维度
self.features = nn.Sequential(
# 第一卷积块:3→32通道,保持224×224尺寸,然后池化到112×112
nn.Conv2d(3, 32, kernel_size=3, padding=1), # 3×3卷积,保持尺寸不变
nn.BatchNorm2d(32), # 批量归一化,加速训练并稳定学习过程
nn.ReLU(), # ReLU激活函数,引入非线性
nn.MaxPool2d(2), # 2×2最大池化,空间维度减半
# 第二卷积块:32→64通道,112×112→56×56
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2),
# 第三卷积块:64→128通道,56×56→28×28
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2),
# 第四卷积块:128→256通道,28×28→14×14
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2),
# 第五卷积块:256→512通道,14×14→7×7
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2),
)
# 分类器层:将特征图转换为类别预测
self.classifier = nn.Sequential(
nn.Flatten(), # 将7×7×512特征图展平为25088维向量
nn.Linear(512 * 4 * 4, 1024), # 全连接层:25088→1024(注意:此处应为7×7=49,但代码中4×4可能有误)
nn.ReLU(), # 非线性激活
nn.Dropout(0.5), # 50% Dropout,防止过拟合
nn.Linear(1024, num_classes) # 输出层:1024→类别数(2)
)
def forward(self, x):
"""前向传播:特征提取 → 分类决策"""
x = self.features(x) # 通过卷积层提取特征
x = self.classifier(x) # 通过全连接层分类
return x
# ====================== 自定义CNN训练配置 ======================
BATCH_SIZE = 32 # 保持一致批次大小
EPOCHS = 16 # 相同训练轮数
LR = 1e-3 # 学习率1e-3,从头训练需要较大学习率
IMAGE_SIZE = 128 # 图像尺寸缩小为128×128,降低计算负担
# ====================== 准备数据加载器 ======================
# 使用128×128图像尺寸,减轻轻量级模型的计算压力
train_loader, val_loader, class_names = get_data_setup(
batch_size=BATCH_SIZE, # 32批次
test_size=0.2, # 20%验证集
image_size=IMAGE_SIZE # 128×128输入尺寸
)
# ====================== 创建自定义CNN模型实例 ======================
# 实例化自定义的5层CNN模型,随机初始化所有参数
model = PureCNN5Layer(num_classes=len(class_names))
# ====================== 配置优化器和损失函数 ======================
# AdamW优化器:统一优化算法
# lr=LR: 1e-3学习率,适合随机初始化模型的快速收敛
# weight_decay=1e-2: 相同权重衰减
optimizer = optim.AdamW(model.parameters(), lr=LR, weight_decay=1e-2)
# 交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# ====================== 执行自定义CNN模型训练 ======================
# 开始训练轻量级CNN模型
trained_model, history_pure_cnn_5layer = train_model(
model=model, # 自定义5层CNN
train_loader=train_loader, # 训练数据
val_loader=val_loader, # 验证数据
criterion=criterion, # 损失函数
optimizer=optimizer, # 优化器
epochs=EPOCHS, # 16个epoch
device=DEVICE, # GPU设备
model_name="pure_cnn_5layer" # 模型名称,明确标识
)
接下来进行模型评估
python
plot_results(history_pure_cnn_5layer, title="Pure CNN 5-Layer")
evaluate_model(trained_model, val_loader, class_names, device=DEVICE)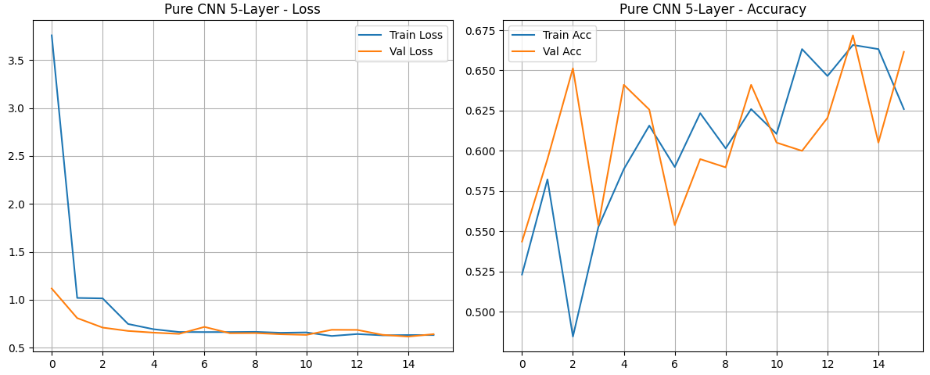
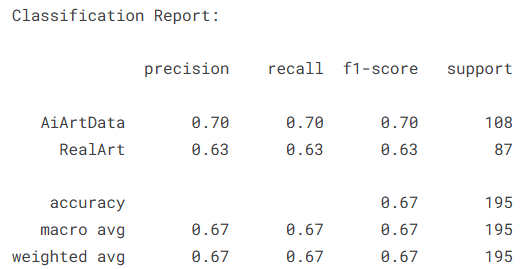
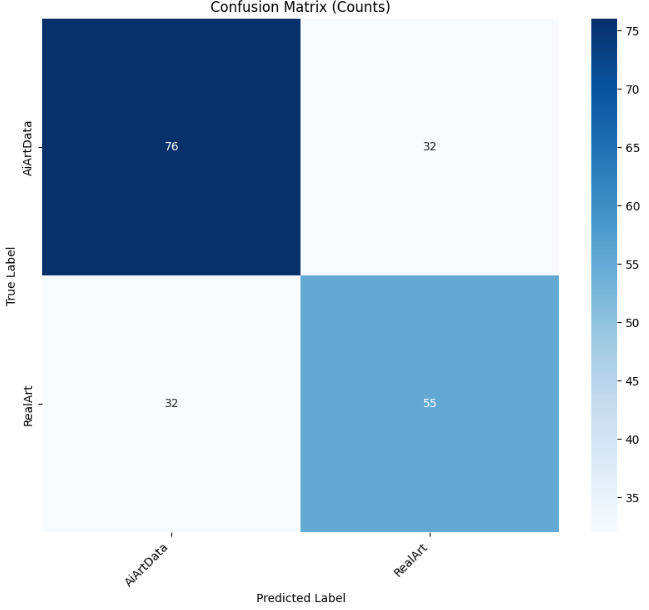
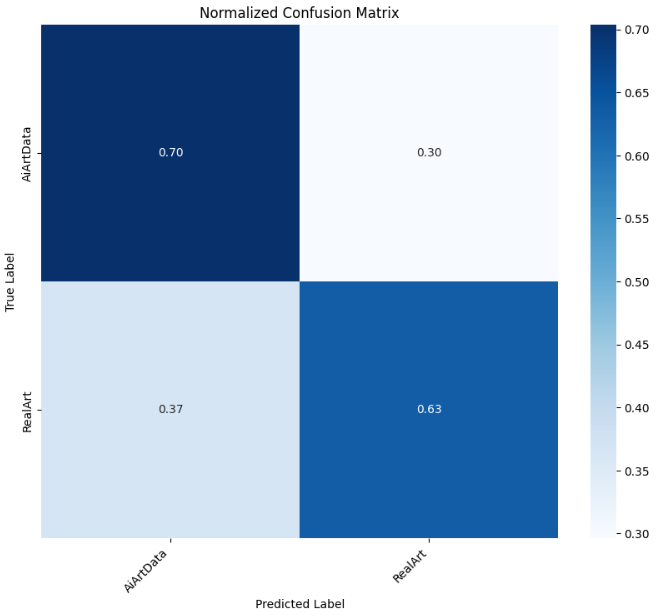
4.5模型总结
接下来对训练完成的多个模型进行系统性的性能对比和总结。通过动态收集各模型的训练历史数据,计算最佳验证准确率,并可视化展示模型间的性能差异,为最终模型选择和后续改进提供数据支持。
python
# ====================== 导入必要的库 ======================
import pandas as pd # 数据处理库,用于创建和管理数据表格
import matplotlib.pyplot as plt # 数据可视化库
import seaborn as sns # 统计可视化库,提供更美观的图表样式
# ====================== 1. 定义模型名称与变量名的映射关系 ======================
# 建立模型显示名称与全局变量名的对应关系,便于动态获取训练历史
potential_vars = {
'ViT Base': 'history_vit', # Vision Transformer模型历史
'ResNet50 (Pretrained)': 'history_resnet_pretrained', # 预训练ResNet50历史
'ResNet50 (Scratch)': 'history_resnet', # 从头训练ResNet50历史
'Swin Transformer': 'history_swin', # Swin Transformer模型历史
'Pure CNN (5-Layer)': 'history_pure_cnn_5layer', # 自定义5层CNN历史
'Current Model': 'history' # 备用变量名(如果其他名称不存在)
}
# ====================== 2. 动态从全局变量中获取存在的训练历史数据 ======================
models_data = {} # 初始化字典,存储模型名称与对应历史数据
for label, var_name in potential_vars.items():
if var_name in globals(): # 检查该变量名是否存在于全局命名空间中
models_data[label] = globals()[var_name] # 将模型历史数据添加到字典
# ====================== 3. 数据处理与性能分析 ======================
if not models_data:
# 如果没有找到任何训练历史数据,输出警告信息
print("⚠️ No training history found in memory.")
else:
benchmark_results = [] # 初始化列表,存储各模型的性能结果
# 遍历每个模型的历史数据,提取最佳验证准确率
for name, hist in models_data.items():
# 确保历史数据是字典类型且包含验证准确率信息
if isinstance(hist, dict) and 'val_acc' in hist:
best_acc = max(hist['val_acc']) # 计算验证集上的最佳准确率
benchmark_results.append({
'Model': name, # 模型名称
'Best Accuracy': best_acc # 最佳验证准确率
})
# 创建DataFrame并按准确率降序排序
df = pd.DataFrame(benchmark_results).sort_values(by='Best Accuracy', ascending=False)
# 去除准确率重复的记录(保留第一个出现的模型)
df = df.drop_duplicates(subset=['Best Accuracy'], keep='first')
if df.empty:
# 如果DataFrame为空,说明没有有效的验证准确率数据
print("⚠️ History found, but no validation accuracy data available.")
else:
# --- 输出1:控制台表格展示 ---
print("\n" + "="*40)
print(f"{'FINAL BENCHMARK LEADERBOARD':^40}") # 居中显示标题
print("="*40)
print(df.to_string(index=False)) # 打印不包含索引的DataFrame
print("-" * 40)
# --- 输出2:可视化柱状图 ---
plt.figure(figsize=(10, 6)) # 创建10×6英寸的图形
# 创建柱状图,使用viridis配色方案
ax = sns.barplot(
data=df, # 使用处理后的数据
x='Model', # x轴:模型架构名称
y='Best Accuracy', # y轴:最佳验证准确率
hue='Model', # 按模型着色(虽然会生成图例)
palette='viridis', # 使用viridis颜色映射
dodge=False # 防止柱状图偏移(单数据组时保持居中)
)
# 在每个柱状图顶部添加准确率数值标签
ax.bar_label(ax.containers[0], fmt='%.4f', padding=3, fontsize=10, fontweight='bold')
# 安全地移除图例(因为hue参数会生成不必要的图例)
if ax.get_legend() is not None:
ax.get_legend().remove()
# 图表样式设置
plt.title('Model Accuracy Comparison', fontsize=14, pad=15) # 标题
plt.ylabel('Best Validation Accuracy', fontsize=12) # y轴标签
plt.xlabel('Model Architecture', fontsize=12) # x轴标签
plt.ylim(0, 1.15) # y轴范围0-115%
plt.xticks(rotation=15) # x轴标签旋转15度
plt.grid(axis='y', linestyle='--', alpha=0.3) # y轴网格线
# 调整布局并显示图形
plt.tight_layout()
plt.show()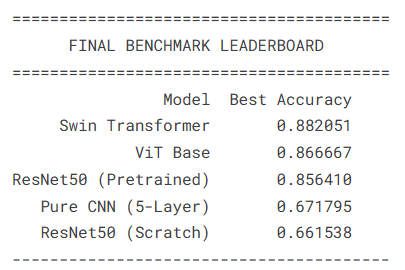
5.总结
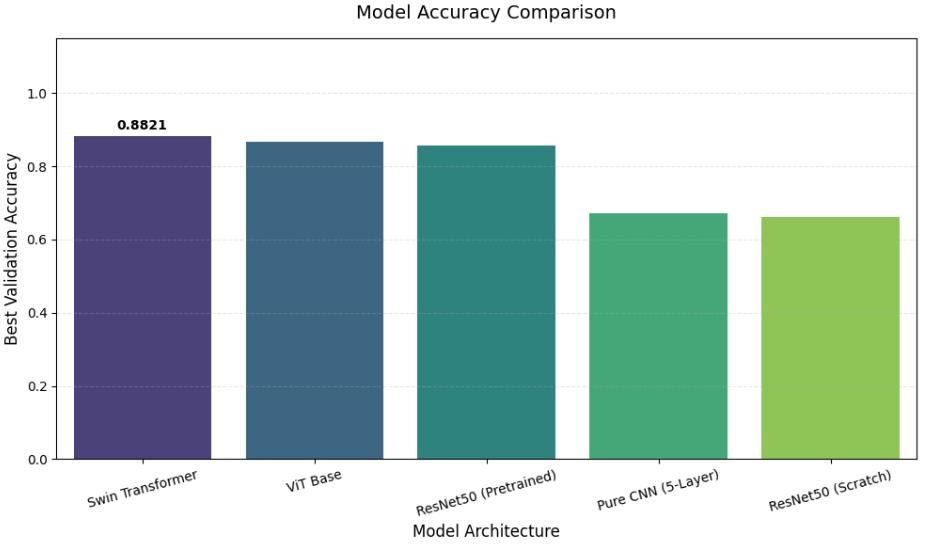
本项目通过对比多种深度学习架构在人工智能艺术与人类艺术分类任务上的表现,系统评估了不同模型在艺术风格识别中的能力。实验结果显示,Swin Transformer模型以88.21%的最佳验证准确率位居榜首,展现了层次化注意力机制在捕捉艺术多尺度特征方面的优势。Vision Transformer以86.67%的准确率紧随其后,验证了全局注意力机制在艺术风格分析中的有效性。预训练的ResNet50模型(85.64%)显著优于从头训练的ResNet50(66.15%),这突显了在大规模自然图像上预训练对艺术分类任务的迁移价值。自定义的5层CNN模型(67.18%)作为轻量级基准,提供了简洁架构在有限数据下的性能参考。
综合分析表明,基于Transformer的架构在处理艺术图像分类任务时具有明显优势,特别是其全局和层次化注意力机制更适合捕捉艺术作品的构图风格和整体一致性。本研究的实验结果为艺术风格自动鉴别系统的构建提供了重要的技术参考和模型选择依据。
源代码
python
# 1. Standard Library
import os
import math
import copy
import random
# 2. Data Manipulation & Visualization
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from PIL import Image
# 3. Utility & Progress
from tqdm.auto import tqdm
# 4. Machine Learning (Scikit-Learn)
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
# 5. Deep Learning (PyTorch Core)
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader, random_split
from torch.cuda.amp import GradScaler, autocast
# 6. Computer Vision (Torchvision & Timm)
from torchvision import datasets, transforms
import timm
# CONFIGURATION
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
DATA_DIR = "/kaggle/input/ai-art-vs-human-art/Art"
SEED = 42
NUM_WORKERS = max(1, os.cpu_count() - 1)
IMG_SIZE = 224
BATCH_SIZE = 32
IMAGENET_DEFAULT_MEAN = [0.485, 0.456, 0.406]
IMAGENET_DEFAULT_STD = [0.229, 0.224, 0.225]
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
def find_classes_and_samples(root_dir):
samples = []
classes = set()
valid_extensions = ('.jpg', '.jpeg', '.png', '.bmp', '.webp', '.tiff')
if not os.path.exists(root_dir):
print(f"Error: Directory {root_dir} not found.")
return [], []
for class_name in sorted(os.listdir(root_dir)):
class_path = os.path.join(root_dir, class_name)
if os.path.isdir(class_path):
classes.add(class_name)
for img_name in os.listdir(class_path):
if img_name.lower().endswith(valid_extensions):
img_path = os.path.join(class_path, img_name)
samples.append((img_path, class_name))
# Sorting class order (AiArtData=0, RealArt=1)
class_names = sorted(list(classes))
class_to_idx = {cls_name: i for i, cls_name in enumerate(class_names)}
final_samples = [(path, class_to_idx[name]) for path, name in samples]
return final_samples, class_names
def train_transforms(image_size=IMG_SIZE):
return transforms.Compose([
transforms.RandomResizedCrop(image_size, scale=(0.8, 1.2)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.TrivialAugmentWide(),
transforms.ToTensor(),
transforms.Normalize(mean=IMAGENET_DEFAULT_MEAN, std=IMAGENET_DEFAULT_STD)
])
def val_transforms(image_size=IMG_SIZE):
resize_dim = int(image_size * 1.14)
return transforms.Compose([
transforms.Resize(resize_dim, interpolation=transforms.InterpolationMode.BICUBIC),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize(mean=IMAGENET_DEFAULT_MEAN, std=IMAGENET_DEFAULT_STD)
])
class Dataset(Dataset):
def __init__(self, samples, transform=None):
self.samples = samples
self.transform = transform
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
path, target = self.samples[idx]
try:
image = Image.open(path).convert('RGB')
except Exception as e:
print(f"Error loading image {path}: {e}")
image = Image.new('RGB', (IMG_SIZE, IMG_SIZE))
if self.transform:
image = self.transform(image)
return image, target
all_samples, class_names = find_classes_and_samples(DATA_DIR)
all_targets = [s[1] for s in all_samples]
if len(all_samples) == 0:
raise Exception("Error: No image found. recheck DATA_DIR path:", DATA_DIR)
# Stratified Split 80:20
train_samples, val_samples = train_test_split(
all_samples,
test_size=0.2,
random_state=SEED,
stratify=all_targets
)
train_dataset = Dataset(train_samples, transform=train_transforms(IMG_SIZE))
val_dataset = Dataset(val_samples, transform=val_transforms(IMG_SIZE))
train_loader = DataLoader(
train_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=NUM_WORKERS,
persistent_workers=True,
pin_memory=True
)
val_loader = DataLoader(
val_dataset,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=NUM_WORKERS,
persistent_workers=True,
pin_memory=True
)
print(f"Training Set : {len(train_dataset)} images")
print(f"Validation Set: {len(val_dataset)} images")
print(f"Total Classes : {len(class_names)}")
all_targets_indices = [s[1] for s in all_samples]
df_counts = pd.DataFrame({'label_idx': all_targets_indices})
df_counts['class_name'] = df_counts['label_idx'].map(lambda x: class_names[x])
class_counts = df_counts['class_name'].value_counts().sort_index()
plt.figure(figsize=(8, 5))
sns.barplot(x=class_counts.index, y=class_counts.values, palette='magma')
plt.title('Distribution: AI Art vs Real Art', fontsize=14)
plt.xlabel('Class', fontsize=12)
plt.ylabel('Number of Images', fontsize=12)
for i, v in enumerate(class_counts.values):
plt.text(i, v + 20, str(v), ha='center', va='bottom')
plt.show()
num_samples_per_class = 4
fig, axes = plt.subplots(len(class_names), num_samples_per_class, figsize=(15, 8))
fig.suptitle('Random Samples: AI vs Real Art', fontsize=16)
for i, cls_name in enumerate(class_names):
# Filter samples yang sesuai kelas ini
cls_samples = [s[0] for s in all_samples if class_names[s[1]] == cls_name]
# Ambil random samples (jika cukup)
selected_samples = random.sample(cls_samples, min(len(cls_samples), num_samples_per_class))
for j, img_path in enumerate(selected_samples):
try:
img = Image.open(img_path)
axes[i, j].imshow(img)
axes[i, j].set_title(cls_name)
axes[i, j].axis('off')
except Exception as e:
axes[i, j].text(0.5, 0.5, "Error", ha='center')
plt.tight_layout()
plt.show()
def get_data_setup(batch_size=32, test_size=0.2, image_size=224):
all_samples, class_names = find_classes_and_samples(DATA_DIR)
all_targets = [s[1] for s in all_samples]
train_samples, val_samples = train_test_split(
all_samples, test_size=test_size, random_state=SEED, stratify=all_targets
)
train_ds = Dataset(train_samples, transform=train_transforms(image_size))
val_ds = Dataset(val_samples, transform=val_transforms(image_size))
train_loader = DataLoader(train_ds, batch_size=batch_size, shuffle=True,
num_workers=NUM_WORKERS, persistent_workers=True, pin_memory=True)
val_loader = DataLoader(val_ds, batch_size=batch_size, shuffle=False,
num_workers=NUM_WORKERS, persistent_workers=True, pin_memory=True)
return train_loader, val_loader, class_names
def train_model(model, train_loader, val_loader, criterion, optimizer,
scheduler=None, epochs=16, device=DEVICE, model_name="Model"):
print(f"\n[Training] Starting: {model_name} | Epochs: {epochs}")
save_filename = f"{model_name}.pth"
model = model.to(device)
scaler = torch.amp.GradScaler('cuda')
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
history = {'train_loss': [],
'train_acc': [],
'val_loss': [],
'val_acc': []}
for epoch in range(epochs):
# Training
train_loss = 0.0
train_correct = 0
train_total = 0
model.train()
pbar = tqdm(train_loader, desc=f"{model_name} Ep {epoch+1}/{epochs}", leave=False)
for inputs, labels in pbar:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
with torch.amp.autocast('cuda'):
outputs = model(inputs)
loss = criterion(outputs, labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
_, preds = torch.max(outputs, 1)
train_loss += loss.item() * inputs.size(0)
train_correct += torch.sum(preds == labels.data)
train_total += labels.size(0)
pbar.set_postfix(loss=loss.item())
epoch_train_loss = train_loss / train_total
epoch_train_acc = train_correct.double() / train_total
# Validation
model.eval()
val_loss = 0.0
val_correct = 0
val_total = 0
with torch.no_grad():
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
val_loss += loss.item() * inputs.size(0)
val_correct += torch.sum(preds == labels.data)
val_total += labels.size(0)
epoch_val_loss = val_loss / val_total
epoch_val_acc = val_correct.double() / val_total
# Get Current Learning Rate to display
current_lr = optimizer.param_groups[0]['lr']
# Scheduler Step
if scheduler:
if isinstance(scheduler, torch.optim.lr_scheduler.ReduceLROnPlateau):
scheduler.step(epoch_val_loss)
else:
scheduler.step()
# Save history
history['train_loss'].append(epoch_train_loss)
history['train_acc'].append(epoch_train_acc.item())
history['val_loss'].append(epoch_val_loss)
history['val_acc'].append(epoch_val_acc.item())
print(f"Train Loss: {epoch_train_loss:.4f} Train Acc: {epoch_train_acc:.4f} | "
f"Val Loss: {epoch_val_loss:.4f} Val Acc: {epoch_val_acc:.4f} | "
f"LR: {current_lr:.2e}")
# Checkpoint
if epoch_val_acc > best_acc:
best_acc = epoch_val_acc
torch.save(model.state_dict(), save_filename)
print(f"Best {model_name} saved as {save_filename}")
if os.path.exists(save_filename):
print(f"Loading best weights from {save_filename}...")
model.load_state_dict(torch.load(save_filename))
else:
print(f"[Warning] No model file saved. Check file {save_filename}")
print(f"[Result] Final Best Val Acc: {best_acc:.4f}")
return model, history
def plot_results(history, title="Model Performance"):
fig, ax = plt.subplots(1, 2, figsize=(12, 5))
# Loss
ax[0].plot(history['train_loss'], label='Train Loss')
ax[0].plot(history['val_loss'], label='Val Loss')
ax[0].set_title(f'{title} - Loss')
ax[0].legend()
ax[0].grid(True)
# Accuracy
ax[1].plot(history['train_acc'], label='Train Acc')
ax[1].plot(history['val_acc'], label='Val Acc')
ax[1].set_title(f'{title} - Accuracy')
ax[1].legend()
ax[1].grid(True)
plt.tight_layout()
plt.show()
def evaluate_model(model, loader, class_names, device=DEVICE):
model.eval()
y_true, y_pred = [], []
with torch.no_grad():
for inputs, labels in tqdm(loader, desc="Evaluating"):
inputs = inputs.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
y_true.extend(labels.cpu().numpy())
y_pred.extend(preds.cpu().numpy())
print("\nClassification Report:\n")
print(classification_report(y_true, y_pred, target_names=class_names))
cm = confusion_matrix(y_true, y_pred)
# Plot 1: Standard Confusion Matrix (Counts)
plt.figure(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=class_names, yticklabels=class_names)
plt.title("Confusion Matrix (Counts)")
plt.ylabel('True Label')
plt.xlabel('Predicted Label')
plt.xticks(rotation=45, ha='right')
plt.show()
# Plot 2: Normalized Confusion Matrix (Percentages)
# Normalize by row (true class counts)
cm_normalized = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
plt.figure(figsize=(10, 8))
sns.heatmap(cm_normalized, annot=True, fmt='.2f', cmap='Blues',
xticklabels=class_names, yticklabels=class_names)
plt.title("Normalized Confusion Matrix")
plt.ylabel('True Label')
plt.xlabel('Predicted Label')
plt.xticks(rotation=45, ha='right')
plt.show()
BATCH_SIZE = 32
EPOCHS = 16
LR = 1e-5
train_loader, val_loader, class_names = get_data_setup(batch_size=BATCH_SIZE, test_size=0.2, image_size=224)
model = timm.create_model('vit_base_patch16_224', pretrained=True, num_classes=len(class_names))
optimizer = optim.AdamW(model.parameters(), lr=LR, weight_decay=1e-2)
criterion = nn.CrossEntropyLoss()
trained_model, history_vit = train_model(
model=model,
train_loader=train_loader,
val_loader=val_loader,
criterion=criterion,
optimizer=optimizer,
epochs=EPOCHS,
device=DEVICE,
model_name="vit"
)
plot_results(history_vit, title="vit")
evaluate_model(trained_model, val_loader, class_names, device=DEVICE)
BATCH_SIZE = 32
EPOCHS = 16
LR = 1e-4
train_loader, val_loader, class_names = get_data_setup(batch_size=BATCH_SIZE, test_size=0.2, image_size=224)
model = timm.create_model('resnet50', pretrained=True, num_classes=len(class_names))
optimizer = optim.AdamW(model.parameters(), lr=LR, weight_decay=1e-2)
criterion = nn.CrossEntropyLoss()
trained_model, history_resnet_pretrained = train_model(
model=model,
train_loader=train_loader,
val_loader=val_loader,
criterion=criterion,
optimizer=optimizer,
epochs=EPOCHS,
device=DEVICE,
model_name="resnet50-pretrained"
)
plot_results(history_resnet_pretrained, title="resnet50-pretrained")
evaluate_model(trained_model, val_loader, class_names, device=DEVICE)
BATCH_SIZE = 32
EPOCHS = 16
LR = 1e-3
train_loader, val_loader, class_names = get_data_setup(batch_size=BATCH_SIZE, test_size=0.2, image_size=224)
model = timm.create_model('resnet50', pretrained=False, num_classes=len(class_names))
optimizer = optim.AdamW(model.parameters(), lr=LR, weight_decay=1e-2)
criterion = nn.CrossEntropyLoss()
trained_model, history_resnet = train_model(
model=model,
train_loader=train_loader,
val_loader=val_loader,
criterion=criterion,
optimizer=optimizer,
epochs=EPOCHS,
device=DEVICE,
model_name="resnet50"
)
plot_results(history_resnet, title="resnet50")
evaluate_model(trained_model, val_loader, class_names, device=DEVICE)
BATCH_SIZE = 32
EPOCHS = 16
LR = 1e-4
train_loader, val_loader, class_names = get_data_setup(batch_size=BATCH_SIZE, test_size=0.2, image_size=224)
model = timm.create_model('swin_base_patch4_window7_224', pretrained=True, num_classes=len(class_names))
optimizer = optim.AdamW(model.parameters(), lr=LR, weight_decay=1e-2)
criterion = nn.CrossEntropyLoss()
trained_model, history_swin = train_model(
model=model,
train_loader=train_loader,
val_loader=val_loader,
criterion=criterion,
optimizer=optimizer,
epochs=EPOCHS,
device=DEVICE,
model_name="swin"
)
plot_results(history_swin, title="swin")
evaluate_model(trained_model, val_loader, class_names, device=DEVICE)
class PureCNN5Layer(nn.Module):
def __init__(self, num_classes):
super(PureCNN5Layer, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2),
)
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(512 * 4 * 4, 1024),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(1024, num_classes)
)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
return x
BATCH_SIZE = 32
EPOCHS = 16
LR = 1e-3
IMAGE_SIZE = 128
train_loader, val_loader, class_names = get_data_setup(
batch_size=BATCH_SIZE,
test_size=0.2,
image_size=IMAGE_SIZE
)
model = PureCNN5Layer(num_classes=len(class_names))
optimizer = optim.AdamW(model.parameters(), lr=LR, weight_decay=1e-2)
criterion = nn.CrossEntropyLoss()
trained_model, history_pure_cnn_5layer = train_model(
model=model,
train_loader=train_loader,
val_loader=val_loader,
criterion=criterion,
optimizer=optimizer,
epochs=EPOCHS,
device=DEVICE,
model_name="pure_cnn_5layer"
)
plot_results(history_pure_cnn_5layer, title="Pure CNN 5-Layer")
evaluate_model(trained_model, val_loader, class_names, device=DEVICE)
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 1. Define potential variable names map (Label: Variable Name)
potential_vars = {
'ViT Base': 'history_vit',
'ResNet50 (Pretrained)': 'history_resnet_pretrained',
'ResNet50 (Scratch)': 'history_resnet',
'Swin Transformer': 'history_swin',
'Pure CNN (5-Layer)': 'history_pure_cnn_5layer',
'Current Model': 'history' # Fallback
}
# 2. Dynamically fetch existing history data from globals
models_data = {}
for label, var_name in potential_vars.items():
if var_name in globals():
models_data[label] = globals()[var_name]
# 3. Process data
if not models_data:
print("⚠️ No training history found in memory.")
else:
benchmark_results = []
for name, hist in models_data.items():
# Ensure it is a valid history dict with validation accuracy
if isinstance(hist, dict) and 'val_acc' in hist:
best_acc = max(hist['val_acc'])
benchmark_results.append({
'Model': name,
'Best Accuracy': best_acc
})
# Create DataFrame and remove duplicates
df = pd.DataFrame(benchmark_results).sort_values(by='Best Accuracy', ascending=False)
df = df.drop_duplicates(subset=['Best Accuracy'], keep='first')
if df.empty:
print("⚠️ History found, but no validation accuracy data available.")
else:
# --- OUTPUT 1: Console Table ---
print("\n" + "="*40)
print(f"{'FINAL BENCHMARK LEADERBOARD':^40}")
print("="*40)
print(df.to_string(index=False))
print("-" * 40)
# --- OUTPUT 2: Visualization ---
plt.figure(figsize=(10, 6))
# Create Bar Plot (Removed 'legend=False' to fix AttributeError)
ax = sns.barplot(
data=df,
x='Model',
y='Best Accuracy',
hue='Model',
palette='viridis',
dodge=False # Prevent bars from shifting
)
# Add values on top of bars
ax.bar_label(ax.containers[0], fmt='%.4f', padding=3, fontsize=10, fontweight='bold')
# Manually remove legend if it exists (Safe method)
if ax.get_legend() is not None:
ax.get_legend().remove()
# Styling
plt.title('Model Accuracy Comparison', fontsize=14, pad=15)
plt.ylabel('Best Validation Accuracy', fontsize=12)
plt.xlabel('Model Architecture', fontsize=12)
plt.ylim(0, 1.15)
plt.xticks(rotation=15)
plt.grid(axis='y', linestyle='--', alpha=0.3)
plt.tight_layout()
plt.show()资料获取,更多粉丝福利,关注下方公众号获取
