2深度学习基础知识
一、深度学习基础回顾
1. 传统机器学习 vs. 深度学习
| 维度 | 传统机器学习 | 深度学习 |
|---|---|---|
| 特征处理 | 人工设计 | 自动学习 |
| 模型复杂度 | 浅层结构 | 深层非线性架构 |
| 数据需求 | 小规模有效 | 大数据驱动 |
| 计算成本 | 低 | 极高 (依赖GPU) |
| 可解释性 | 高 | 低 (黑盒模型) |
| 适用领域 | 结构化数据/简单模式 | 非结构化数据 (图像、语音、文本) |
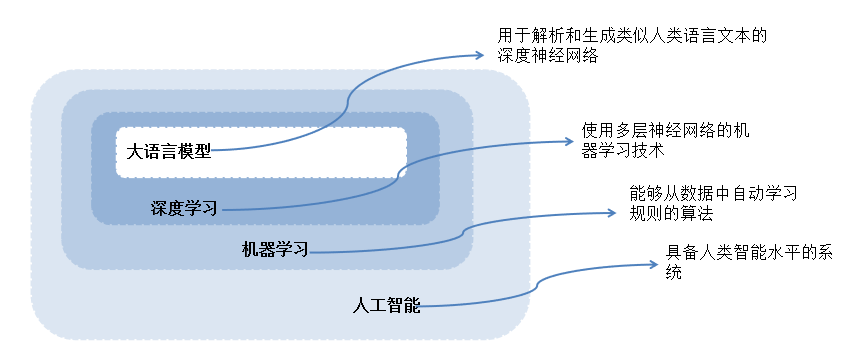
2. 人工智能层次结构
- 人工智能 (AI):具备人类智能水平的系统。
- 机器学习 (ML):能够从数据中自动学习规则的算法。
- 深度学习 (DL):使用多层神经网络的机器学习技术。
- 大语言模型 (LLM):用于解析和生成类似人类语言文本的深度神经网络。
二、PyTorch 与 张量基础
1. PyTorch 框架特点
- 前身是 Torch,使用 Python 重写。
- 核心优势 :灵活、支持动态计算图、支持 GPU 加速、环境优先。
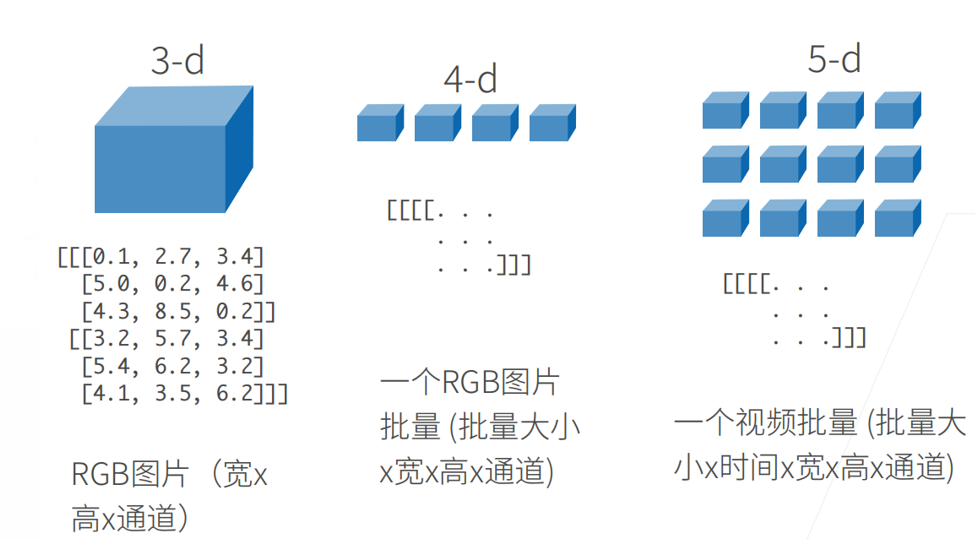
2. 张量的维度
张量是一个多维数组,方向称为模 ,阶数称为维数。
-
0-d (标量) :一个类别(如
1.0)。 -
1-d (向量) :一个特征向量(如
[1.0, 2.7, 3.4])。 -
2-d (矩阵) :一个样本特征矩阵。

-
3-d :RGB图片(宽 ×\times× 高 ×\times× 通道)。
-
4-d :图片批量(批量大小 ×\times× 宽 ×\times× 高 ×\times× 通道)。
-
5-d :视频批量(批量大小 ×\times× 时间 ×\times× 宽 ×\times× 高 ×\times× 通道)。
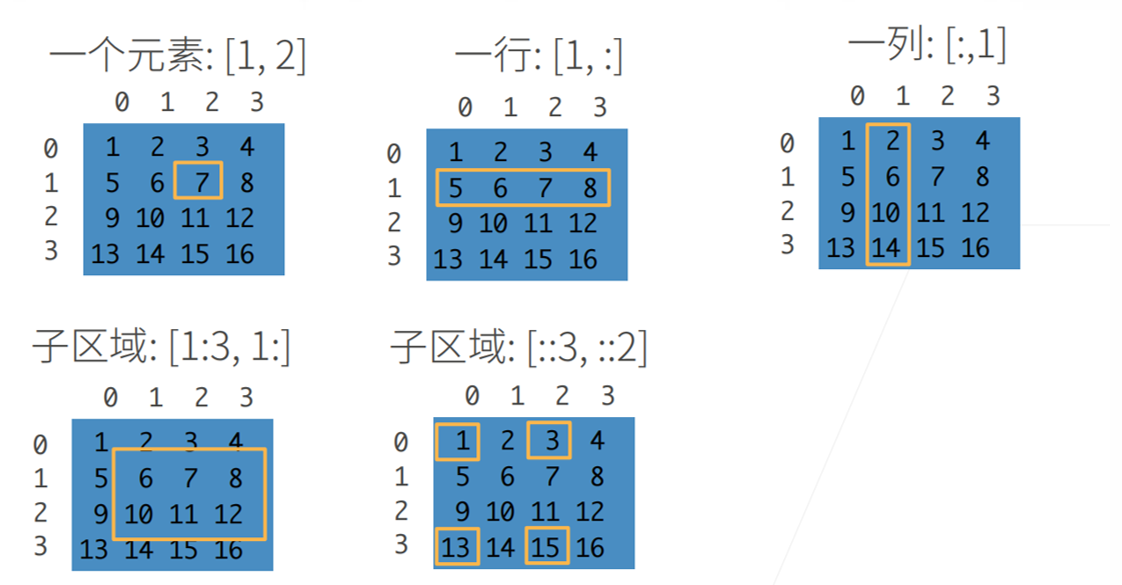
3.访问数组中的元素
创建数组
访问数组中的元素
3. PyTorch 数据操作
- 导入 :
import torch(注意不是import pytorch)。 - 创建 :
torch.arange(12):生成 0-11 的向量。torch.zeros((2, 3, 4))/torch.ones((2, 3, 4)):全 0 或全 1。torch.randn(3, 4):标准正态分布(均值 0,方差 1)。torch.tensor([[...]]):通过 Python 列表显式创建。
- 属性访问 :
x.shape:查看形状。x.numel():查看元素总数。x.reshape(3, 4):改变形状但不改变值和数量。
- 连接 :
torch.cat((X, Y), dim=0):按行拼接。torch.cat((X, Y), dim=1):按列拼接。
4. 广播机制------ 重点
广播机制是PyTorch中的一种自动扩展张量形状的机制,使得两个不同形状的张量可以进行逐元素操作。当两个张量的形状不完全匹配时,PyTorch会自动将较小的张量**"广播"**到与较大张量相同的形状,以便进行逐元素操作。
- 从后向前比较形状:从张量的最后一个维度开始,向前逐个维度比较。
- 维度兼容:如果两个张量在某个维度上的大小相等,或者其中一个张量在该维度上的大小为1,则这两个张量在该维度上是兼容的。
- 扩展维度:如果两个张量在某个维度上不兼容,则PyTorch会自动将大小为1的维度扩展为与另一个张量相同的大小。
- 如果两个张量在任何维度上都不兼容(即大小既不相等,也不为1),则无法进行广播,PyTorch会抛出错误。



第三部分:数据预处理
1. 典型流程
- 读取数据 :通常使用 Pandas 库
pd.read_csv()。 - 处理缺失值 (NaN) :
- 插值 :
inputs.fillna(inputs.mean())用均值填充。 - 删除:直接去掉含有缺失值的行或列。
- 插值 :
- 类别值转换 :
- 使用
pd.get_dummies(inputs, dummy_na=True)将类别转为 One-hot 编码。
- 使用
- 转为张量格式 :
torch.tensor(df.values)。- 深度学习惯例 :通常使用
float32提高计算速度。
第四部分:线性代数与计算
1. 矩阵运算
- 按元素运算 :
+,-,*,/,**。 - 哈达玛积 :
A * B,符号为 ⊙\odot⊙,对应元素相乘。 - 点积 :
torch.dot(x, y),对应元素乘积之和。 - 矩阵-向量积 :
torch.mv(A, x)。 - 矩阵-矩阵乘法 :
torch.mm(A, B),即线性代数中的矩阵乘法。 - 转置 :
A.T。 - 对称矩阵 :满足 A=ATA = A^TA=AT。
2. 降维与非降维求和
X.sum():所有元素求和,变为标量。X.sum(axis=0):沿行求和,消除第 0 维。X.sum(axis=1, keepdims=True):保持轴数不变(利于后续广播)。X.mean():平均值。X.cumsum(axis=0):累积总和(不降维)。
3. 范数 ------ 向量/矩阵的"长度"
- L2L_2L2 范数 :元素平方和的平方根 ∥x∥2=∑xi2\|x\|_2 = \sqrt{\sum x_i^2}∥x∥2=∑xi2 。
- L1L_1L1 范数 :元素绝对值之和 ∥x∥1=∑∣xi∣\|x\|_1 = \sum |x_i|∥x∥1=∑∣xi∣。
- 弗罗贝尼乌斯范数 :矩阵元素平方和的平方根 ∥X∥F=∑∑xij2\|X\|F = \sqrt{\sum \sum x{ij}^2}∥X∥F=∑∑xij2 。
第五部分:微积分与自动微分
1. 导数与梯度
- 梯度 :将导数拓展到向量。对于 y=f(x)y = f(\mathbf{x})y=f(x),梯度 ∇xy\nabla_{\mathbf{x}}y∇xy 是一个包含所有偏导数的向量。
- 链式法则 :dydx=dydududx\frac{dy}{dx} = \frac{dy}{du} \frac{du}{dx}dxdy=dudydxdu。
2. 计算图
- 深度学习将代码分解为操作子,并表示为有向无环图。
- 正向传播 (Forward):执行图计算,存储中间结果。
- 反向传播 (Backward):从结果出发,逆向执行图以计算梯度。
3. PyTorch 自动求导步骤
- 设置属性:
x = torch.tensor([...], requires_grad=True)。 - 定义函数:
y = f(x)。 - 反向传播:
y.backward()。 - 获取梯度:
x.grad。
第六部分:线性神经网络
1. 回归vs. 分类
- 回归:输出连续变量(如房价预测、身高预测)。
- 分类:输出离散变量/概率分布(如图像分类、文本分类)。
2. 线性回归模型
- 假设 :自变量与因变量存在线性关系 y=wTx+by = \mathbf{w}^T\mathbf{x} + by=wTx+b。
- 噪声假设:假设噪声遵循正态分布。
- 模型组成 :
- 权重 (Weights) :w1,w2,...w_1, w_2, \dotsw1,w2,...
- 偏差 (Bias) :bbb。
3. 损失函数
用于量化实际值 yyy 与预测值 y^\hat{y}y^ 之间的差距。
-
平方损失:
l(y,y^)=12(y−y^)2l(y, \hat{y}) = \frac{1}{2}(y - \hat{y})^2l(y,y^)=21(y−y^)2
-
训练目标:在整个训练集上最小化损失均值。