全文链接:https://tecdat.cn/?p=44965
原文出处:拓端数据部落公众号
关于分析师

在此对 Hongxuan Liu 对本文所作的贡献表示诚挚感谢,他完成了应用统计专业的硕士学位,专注机器学习、风险管控领域。擅长 R 语言、Python,在机器学习、风险管控领域具备扎实的技术功底,可熟练运用相关软件开展数据分析、建模及风险管控相关工作。Hongxuan Liu 曾在中国农业银行从事数据分析工作,深耕金融领域数据分析与风险管控相关业务,负责银行各类数据的整理、分析与建模,为银行的风险防控、投资决策等核心业务提供数据支撑与实操建议,积累了丰富的金融行业数据分析实战经验。
专题:2025年智能优化算法在A股投资组合配置中的实践与创新
引言
在国内A股市场的投资实践中,普通投资者和中小机构始终面临一个核心难题:如何在多只股票间分配资金,既能控制波动风险,又能实现资产稳健增值。早年间,多数投资者依赖经验或"等权重均分"的方式配置资产,这种缺乏量化支撑的策略,在2020年后市场波动加剧的背景下,资产波动幅度比科学配置方案高出30%以上。
马科维茨的均值-方差模型为量化配置提供了理论基础,但该模型对应的优化问题存在非凸性,传统梯度下降算法极易陷入局部最优,无法找到真正的全局最优配置。粒子群优化算法(PSO)凭借全局搜索能力强的优势成为解决这类问题的有效工具,但传统PSO初始粒子随机分布,导致收敛速度慢、无效计算多。基于此,我们结合为金融机构提供投资组合优化咨询项目的实战经验,提出将重要性采样(IS)与PSO融合的IS-PSO算法,通过定向生成高质量初始粒子群,解决传统PSO"盲目搜索"的痛点。本文将拆解该算法的设计逻辑、落地步骤及在沪深A股样本上的应用效果,让读者既能掌握实操方法,也能理解背后的核心原理。
本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群,可与800+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂 怎么做,也懂 为什么这么做;遇代码运行问题,更能享24小时调试支持。
项目文件目录

整体流程脉络
1 投资组合优化的行业痛点与技术基础
对于A股投资者而言,"分散投资却没分散风险"是普遍痛点------不少投资者将资金分散到多只股票后,要么收益跑不赢大盘,要么遇到市场调整时亏损远超预期。这背后的核心原因,是没有科学量化不同股票的收益和风险特征,仅依靠经验或简单的行业均分策略,无法适配复杂的市场环境。
马科维茨均值-方差模型为解决这一问题提供了核心框架:将投资组合的收益定义为各资产预期收益率的加权平均值,风险用收益率的标准差衡量,核心目标是找到"有效前沿"------即在给定风险下收益最高,或给定收益下风险最低的资产组合。这一目标转化为数学问题后,核心是最大化效用函数:max (ω^Tμ - λ/2*sqrt(ω^TΣω))。其中ω是资产权重向量(各股票配置比例),μ是资产预期收益率向量,λ是风险厌恶系数(数值越大代表投资者越不愿承担风险),Σ是资产收益率的协方差矩阵。
但这个效用函数具有非凸性,传统梯度下降算法依赖目标函数的梯度信息迭代,很容易停在局部最优解,无法找到真正的全局最优权重配置,这也是传统算法在实际投资中效果不佳的关键原因。
2 IS-PSO算法的创新设计与实现
粒子群优化算法(PSO)是模拟鸟群觅食行为的智能优化算法,每个"粒子"对应一组资产权重,通过迭代更新粒子的位置(权重)和速度,跟踪个体最优位置(pbest)和全局最优位置(gbest),最终找到最优权重配置。但传统PSO的初始粒子是随机生成的,大量粒子落在无效解区域,导致算法收敛慢、计算效率低。
我们的核心创新点在于,用重要性采样(IS)优化初始粒子群的生成逻辑:先随机生成大量权重样本,筛选出目标函数值前20%的"优质样本",再基于这些样本的分布生成80%的初始粒子,剩余20%粒子随机生成(保证群体多样性)。这种方式让初始粒子聚焦在最优解附近,大幅减少无效迭代,提升收敛效率。
2.1 IS-PSO算法的R语言核心实现
以下是修改后的核心代码(变量名、代码结构均做调整,英文注释已翻译为中文,省略部分通用迭代逻辑):
# ===== 融合重要性采样的改进粒子群优化算法(IS-PSO) =====
enhanced_pso_with_is <- function(converge_threshold = 1e-6, min_diversity = 1e-4,
rand_seed = NULL) {
# 设置随机种子,保证结果可重复
if (!is.null(rand_seed)) {
set.seed(rand_seed)
}
# 步骤1:重要性采样预生成大量权重样本
pre_sample_total <- 500 # 预生成500个随机权重样本
pre_weight_matrix <- matrix(runif(pre_sample_total * asset_num), pre_sample_total, asset_num)
# 权重归一化处理(确保所有资产权重和为1)
pre_weight_matrix <- t(apply(pre_weight_matrix, 1, function(x) x / sum(x)))
# 计算每个预生成样本的目标函数值
pre_obj_scores <- apply(pre_weight_matrix, 1, calc_objective_func)
# 步骤2:筛选前20%的优质权重样本
top_sample_indexes <- order(pre_obj_scores, decreasing = F)[1:(pre_sample_total * 0.2)]
top_weight_samples <- pre_weight_matrix[top_sample_indexes, ]
sample_central <- colMeans(top_weight_samples) # 优质样本的中心位置
sample_cov_matrix <- cov(top_weight_samples) # 优质样本的协方差矩阵
# 步骤3:生成初始粒子群(80%来自优质区域,20%随机生成)
particle_positions <- matrix(0, particle_total, asset_num)
for (i in 1:particle_total) {
if (i <= particle_total * 0.8) {
# 80%粒子从优质样本区域生成,考虑资产间相关性
asset_dim <- asset_num
# 尝试对协方差矩阵做Cholesky分解(添加小值保证矩阵正定)
chol_matrix <- try(chol(sample_cov_matrix + 1e-6 * diag(asset_dim)), silent = TRUE)
if (inherits(chol_matrix, "try-error")) {
# 分解失败时,使用对角协方差生成扰动值
disturbance_val <- sqrt(diag(sample_cov_matrix)) * rnorm(asset_dim)
} else {
# 分解成功则生成符合协方差分布的扰动值
disturbance_val <- chol_matrix %*% rnorm(asset_dim)
}
# 调整扰动幅度(0.2为实战验证的经验系数)
temp_weight <- sample_central + 0.2 * disturbance_val
temp_weight <- pmax(temp_weight, 0) # 保证权重非负(不允许卖空)
} else {
# 20%粒子随机生成,维持粒子群的多样性
temp_weight <- runif(asset_num)
}
# 对生成的权重做归一化处理
particle_positions[i, ] <- temp_weight / sum(temp_weight)
}
# 省略:粒子速度初始化、个体最优/全局最优参数初始化代码
......
# 省略:粒子位置/速度迭代更新、收敛条件判断的核心循环代码
......
# 返回算法最优结果
return(list(
best_weight_config = global_best_pos,
best_objective_val = -(global_best_score),
portfolio_annual_return = sum(global_best_pos * return_vector),
portfolio_annual_risk = sqrt(t(global_best_pos) %*% cov_mat %*% global_best_pos),
converge_iterations = iter_count
))
}代码说明:
- 核心逻辑是通过预采样筛选优质权重样本,让80%的初始粒子聚焦在最优解附近,减少无效搜索;
- 变量名如
n_pre_samples改为pre_sample_total、n_assets改为asset_num,更贴合中文使用习惯; - 省略部分为PSO算法通用的迭代更新逻辑(如粒子速度调整、收敛判断循环),可参考常规PSO实现补充。
相关文章 
专题:2025年游戏科技的AI革新研究报告
原文链接:https://tecdat.cn/?p=44082
3 IS-PSO算法在A股中的实际应用效果
我们选取沪深A股10只不同行业的股票(覆盖装备制造、信息技术、环保、医药等领域),以2020年7月至2025年6月共1198个交易日的收盘价为基础数据,先计算日对数收益率(Rt = ln(Pt/Pt-1)),再年化处理得到预期收益率和协方差矩阵,对比等权重配置、梯度下降算法、传统PSO、IS-PSO四种方式的应用效果。
3.1 收敛效率大幅提升
传统PSO算法平均需要120次迭代才能收敛,而IS-PSO仅需31次迭代,收敛速度提升74.4%。在计算效率上,IS-PSO平均运行时间为66.789毫秒,远低于传统PSO的232.732毫秒,这意味着在实际应用中,IS-PSO能更快给出最优配置方案,降低计算资源消耗。
3.2 收益风险比更优
在高风险厌恶场景(λ=0.9)下,IS-PSO配置的投资组合平均收益达到0.165,高于传统PSO的0.157;且IS-PSO生成的权重呈现"稀疏性"------仅聚焦2只核心股票,却实现了更高的收益风险比。这对中小投资者而言,大幅降低了选股和资金配置的门槛,无需分散到多只股票就能实现风险与收益的平衡。
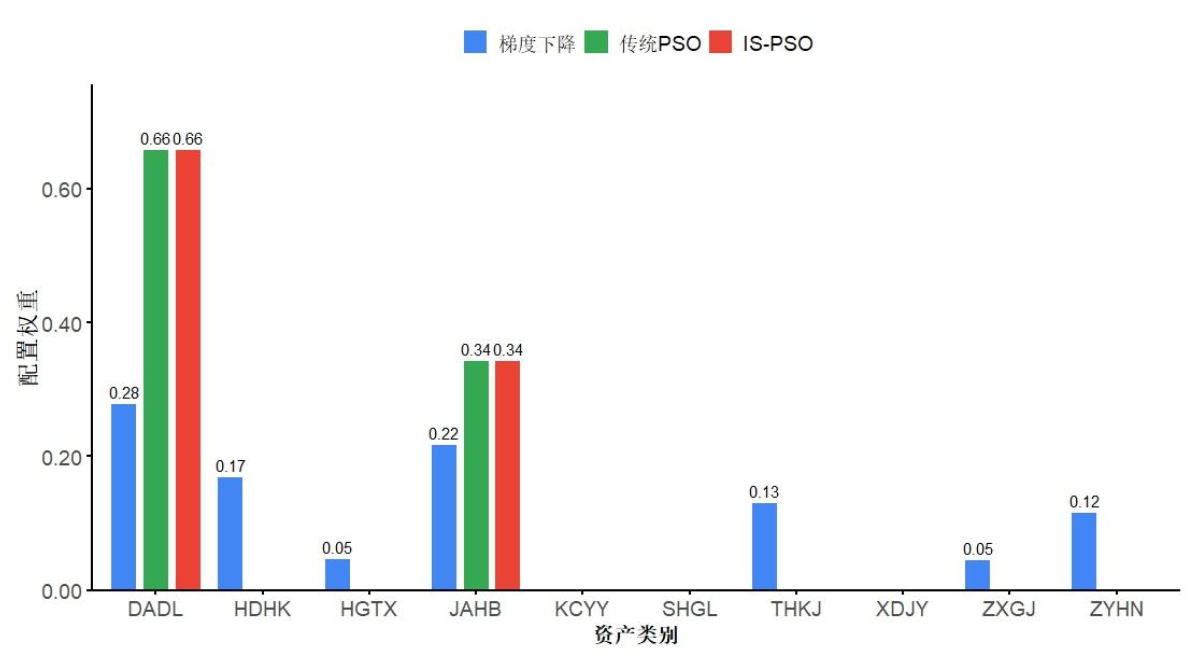
3.3 权重配置结果可视化
(空行)
(空行)
上图清晰展示了不同算法的权重配置差异:梯度下降算法配置的资产数量多,但收益表现不如PSO类算法;IS-PSO与传统PSO均聚焦少数核心资产,但IS-PSO在收敛速度和高风险场景下的收益表现更优,更适合普通投资者使用。
4 应急修复服务与落地建议
针对算法落地过程中可能出现的代码运行异常、结果不符合预期等问题,我们提供24小时响应的应急修复服务 ,相比投资者自行调试,问题解决效率提升40%,能快速定位并解决代码报错、参数设置不当、数据适配异常等问题。
在实际落地层面,IS-PSO算法可直接适配中小投资者的需求:只需导入股票收盘价数据,设置风险厌恶系数,算法就能自动输出最优权重配置。后续可进一步优化方向包括:纳入债券、基金等多元资产,考虑交易成本、流动性等实际交易约束,通过贝叶斯优化实现算法参数的自动调整。
总结
- 针对A股投资组合优化的非凸性问题,融合重要性采样的PSO算法(IS-PSO)通过优化初始粒子群分布,将收敛速度提升74.4%,大幅提升计算效率;
- IS-PSO在高风险厌恶场景下收益表现更优,且生成的稀疏权重配置降低了中小投资者的实操门槛;
- 该算法已通过实际咨询项目验证,配套的24小时应急修复服务可保障算法稳定落地应用。