NAVER 是韩国领先的互联网科技公司,运营着韩国最大的搜索引擎,并在人工智能、自动驾驶等高科技领域积极布局。作者 Nam Kyung-wan 来自 NAVER Infra 团队,自 2023 年参与 JuiceFS 社区代码贡献 (GitHub: kyungwan-nam),为 Hadoop 场景提出了多项改进。本文是作者继" 为 AI 平台引入存储方案 JuiceFS"后的第二篇博客。
NAVER Infra 团队负责运营公共 Hadoop 集群,使用 Spark、Hive、MapReduce 等 Hadoop 应用处理数据,并将数据存储在 HDFS 中。HDFS 在 Hadoop 生态系统中通过数据本地性支持高性能,具备优异的容错性和可扩展性。
随着人工智能服务的普及,数据规模急剧增长,对多样化数据存储的需求也日益增加。同时,如何高效地共享 Hadoop 集群外部 AI 平台(如 Kubernetes)中的数据,成为了一项重要挑战。在这一背景下,NAVER 探讨了对象存储是否可以替代 HDFS,并明确了 JuiceFS 结合对象存储的适用场景。
01 HDFS 的局限
存储成本上升
AI 开发需要以高效且经济的方式存储不断增长的数据,并在某些情况下长期保留原始数据,以便进行模型改进和重新训练。
然而,Hadoop 的计算和存储是紧密耦合的,导致存储扩展难以独立进行。当没有计算需求时,仅为扩展存储空间而增加节点会造成不必要的成本。此外,HDFS 默认保留三重副本,进一步增加了存储成本。
文件数量限制
AI 开发涉及数千万个小文件,如图像、音频和文本等。HDFS 存在著名的小文件问题,因为所有文件和块的元数据都存储在 NameNode 的内存中。例如,管理 1000 万个文件大约需要 3GB 的内存。因此,HDFS 可管理的文件数量受到单个 NameNode 内存容量的限制。
数据中心容灾能力弱
HDFS 通常由单个数据中心的节点组成。为应对数据中心故障或灾难,需使用额外方案将数据复制到其他数据中心,从而产生增加成本。
运营成本增加
NAVER 由专业人员运营公共 Hadoop 集群,负担相对较小,但通常 Hadoop 集群的构建和运营非常复杂且成本高昂。若要单独构建和运营稳定的 Hadoop 环境,需要专业知识和较高的维护成本。
Kubernetes 中的生态兼容性差
NAVER AI 平台基于 Kubernetes 构建,并利用 Kubeflow、KServe 等多种 AI 开源工具及 GPU 支持。但 HDFS 不支持 POSIX API 和 CSI 驱动,无法作为 Kubernetes 常规存储方式(即 PersistentVolume)使用。因此,在 Kubernetes 中使用 HDFS 需在容器中准备 Hadoop 包、配置和认证信息,并编写 HDFS API 代码,非常繁琐且会降低 AI 开发效率。
02 对象存储的优势与劣势
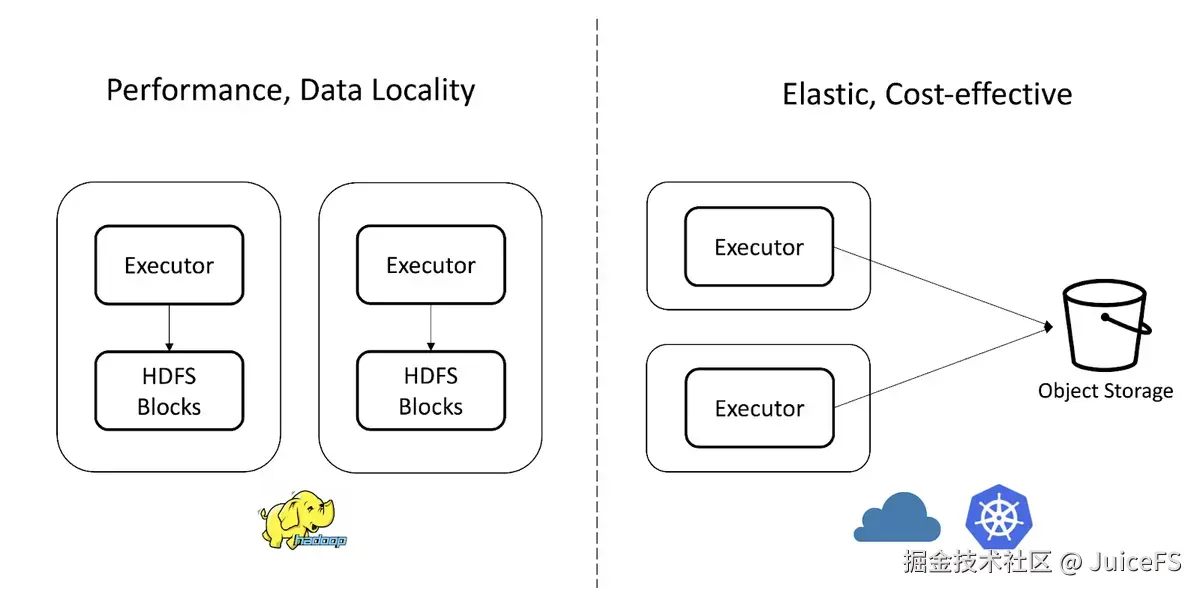
Hadoop 通过数据本地性提供高性能,但由于 HDFS 与计算节点耦合,计算和存储资源难以独立扩展。因此,扩展存储空间时,仍需增加额外的计算节点。
相比之下,云环境支持计算和存储的独立扩展。通常,数据存储在对象存储中而非 HDFS,计算可以通过托管服务(如 AWS EMR、Google Dataproc)或基于 Kubernetes 的数据处理引擎进行,数据则存储在 S3、GCS 等对象存储中。这种架构支持灵活扩展计算和存储资源。
此外,Hadoop 社区和云供应商提供了 S3A、Azure Blob、Aliyun OSS 等 HDFS 兼容文件系统,使得对象存储可以像 HDFS 一样使用。
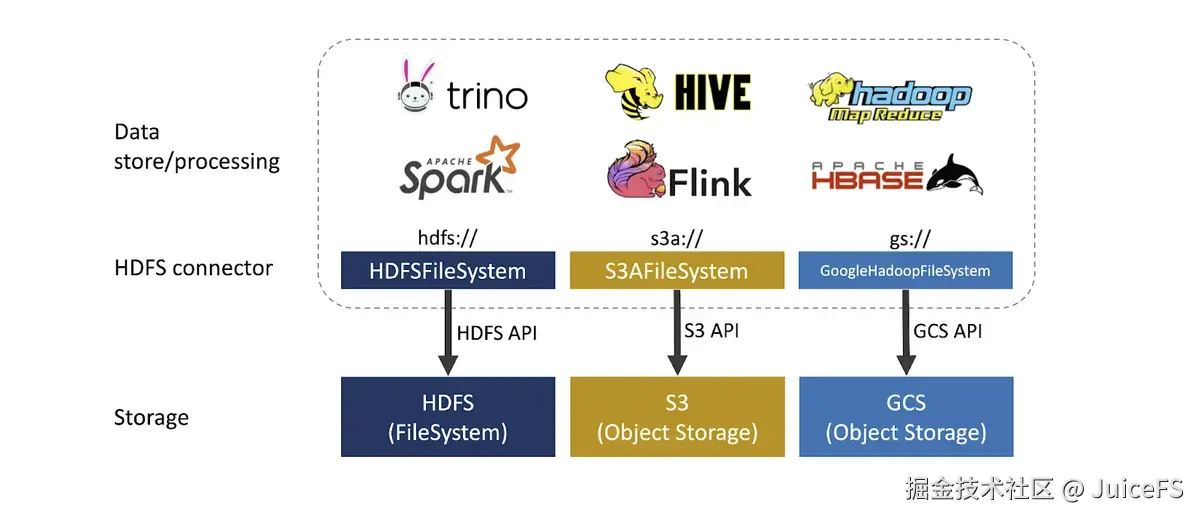
对象存储作为远程存储,虽然难以实现数据本地性,但具有以下优势:
- 存储成本降低:计算和存储分离,可独立扩展。对象存储通常成本较低,并能根据需要选择不同的存储类别。例如,对于访问频率低但需长期保留的数据,可使用低成本存储类别(如 S3 Glacier)。
- 出色的扩展性和弹性:对象存储设计上支持近乎无限的扩展。对象数量和容量无限制,可根据工作负载变化轻松扩展或缩减。
- 数据中心灾难恢复支持:S3 等对象存储提供跨区域复制功能,可防止数据中心故障或灾难导致的数据丢失。
- 运营成本降低:避免 Hadoop 集群的构建和运营负担,从而降低运营成本。
但对象存储替代 HDFS 是好的选择吗?
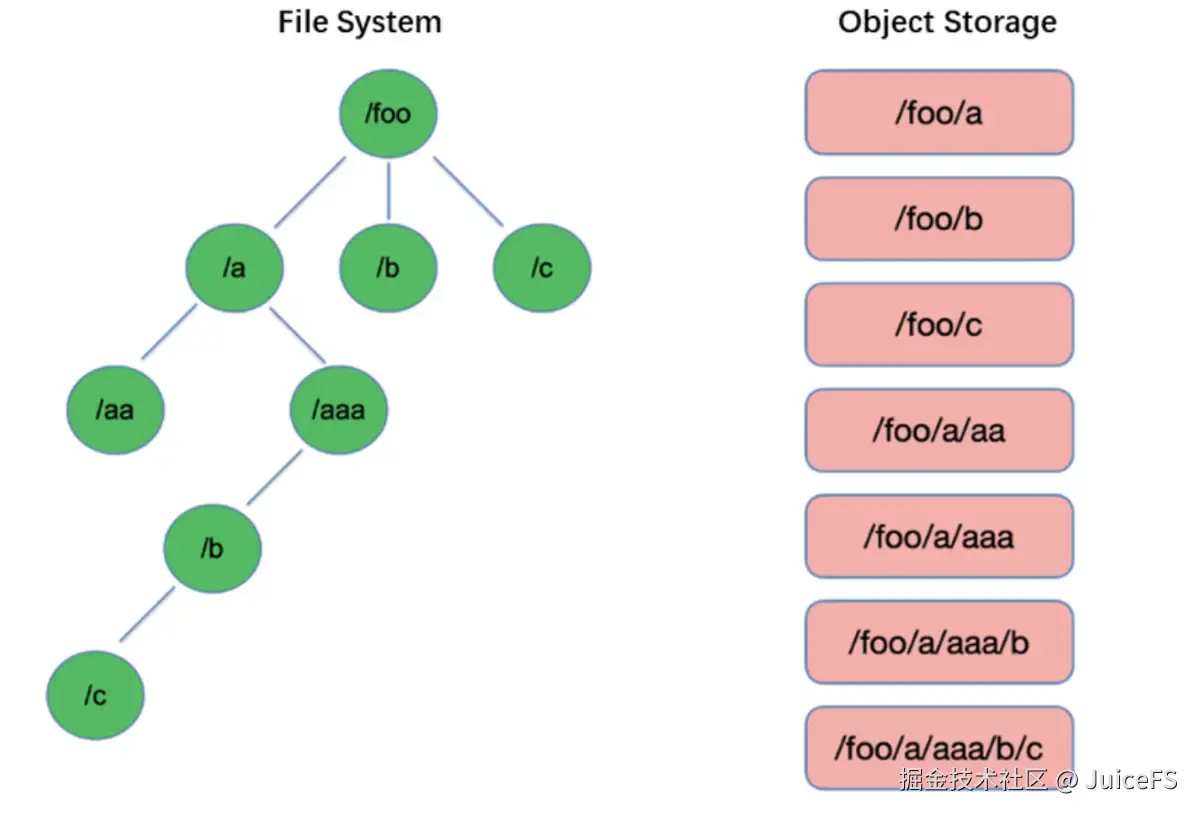
不支持目录 :
在文件系统中,文件通过目录进行组织,列出目录下的文件是一项基本操作,通常速度较快。
而对象存储没有目录的概念,所有对象是独立的扁平结构。列出文件时需要通过对象前缀搜索,速度较慢。此外,为模拟目录结构而临时创建的 Directory Marker 对象也会影响性能。
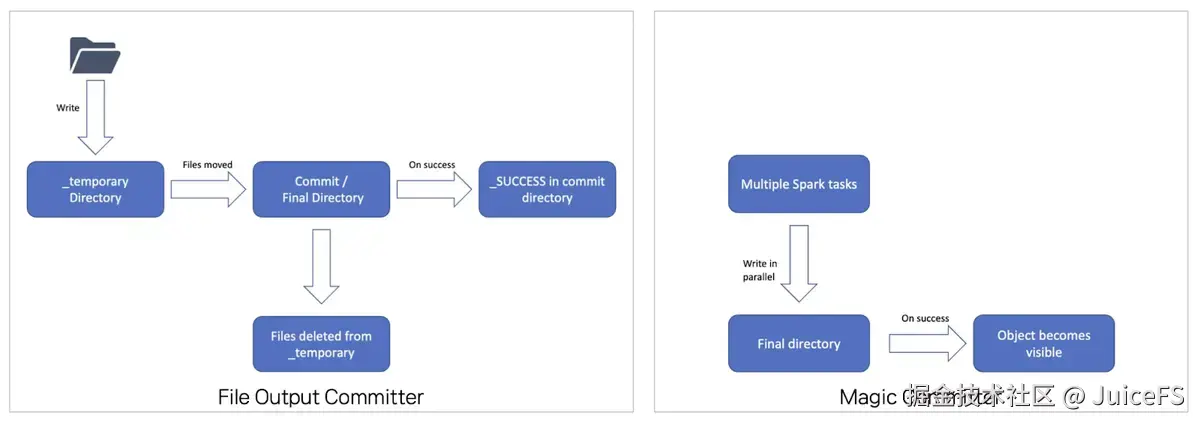
不支持重命名 :
在文件系统中,重命名是基本操作,以 O(1) 级别的原子事务快速执行。但对象存储不支持重命名,需通过复制全部数据再删除原数据的方式处理,导致速度非常慢且可能中途失败。
这一问题对于 MapReduce 和 Spark 等大数据框架影响尤为明显(Apache Hadoop Amazon Web Services support -- Committing work to S3 with the S3A Committers)。文件输出操作通常依赖重命名来保证一致性,FileOutputFormatCommitter 就是基于重命名实现的。因此,在对象存储中直接使用 FileOutputFormatCommitter 会显著降低性能。
为了解决这一问题,可以使用 Magic Committer,它避免了重命名操作,并针对对象存储进行了优化。
-
不支持文件权限 :
HDFS 支持 POSIX 权限体系,可以设置文件和目录的所有者、组以及其他用户的权限。而对象存储不提供此功能,因此文件的所有者和组通常被视为当前用户,所有文件和目录的权限默认为 666 和 777(即文件可读写,目录可读写并可执行)(参考: Object Stores vs. Filesystems).。
-
数据访问速度慢 :
对象存储作为远程存储,无法保证数据本地性,并且每次访问都涉及网络传输,因此相较于 HDFS,其数据访问速度较慢,性能受到网络延迟和带宽限制的影响。
-
Kubernetes 中的低可用性 :
一些工具,如 Mountpoint for Amazon S3 和 s3fs,支持通过 POSIX API 将对象存储挂载为类似本地文件系统的方式。AWS S3 还通过 Mountpoint for Amazon S3 CSI 驱动 支持将对象存储作为 Kubernetes 卷使用。
然而,由于对象存储与传统文件系统存在根本差异,它无法完全兼容 POSIX API,且性能较低。因此,在使用这些工具时,需要充分了解它们的工作原理和局限性。最终,即使在 Kubernetes 环境中使用对象存储,低可用性问题仍然无法解决。
- S3 兼容对象存储的 API 兼容性:
S3 已成为对象存储的事实标准,被多种应用广泛支持。因此,许多云供应商和开源项目提供 S3 兼容对象存储。然而,S3 兼容对象存储并不完全等同于原生 S3 服务。在使用时,需要确认其是否与 S3AFileSystem 或其他应用所使用的 S3 API 兼容。
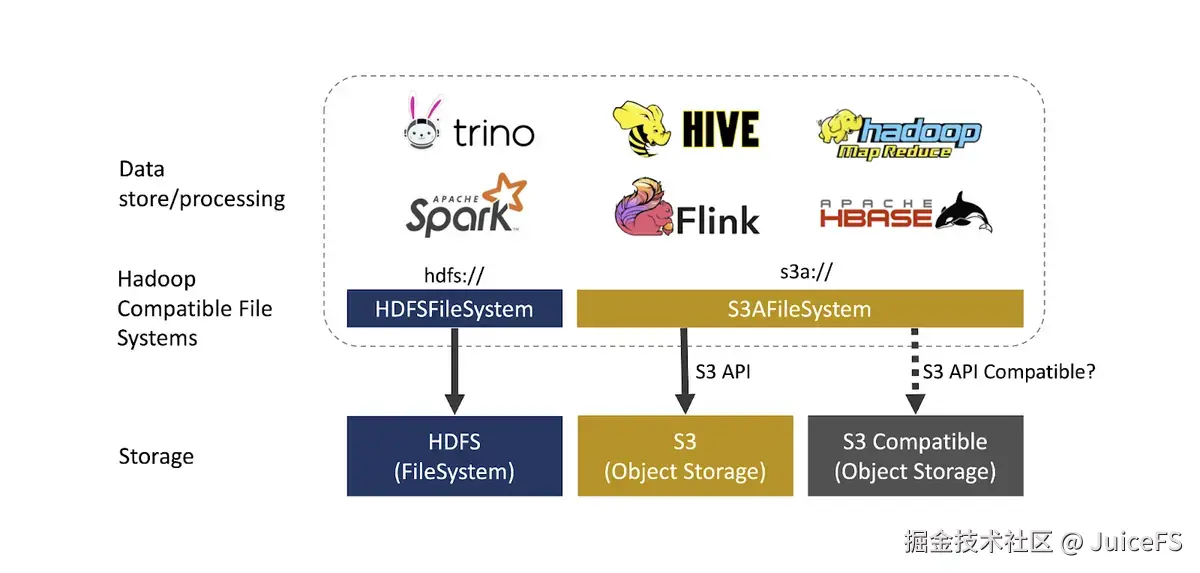
综上,对象存储可以像 HDFS 一样使用,但需要充分理解其局限性。现有 Hadoop 应用难以直接迁移,仍需额外的开发和适配工作。对于直接使用 HDFS API 编写的代码,需要避免重命名操作,并减少文件列表操作,以适应对象存储的特性。为避免现有 Spark 应用性能下降,需考虑使用 Magic Committer,但它并非总是有效,特别是在不支持 Spark 动态分区覆盖的情况下。
此外,虽然 Spark 和 Hadoop 社区持续改进对象存储相关问题,但更新软件包版本和解决问题仍然面临挑战。使用 S3 兼容的对象存储时,还需验证其与 S3 API 的兼容性。
03 在 Hadoop 中使用 JuiceFS
JuiceFS 是一款分布式文件系统,架构由客户端、元数据引擎和数据存储组成。对象存储仅用于存储数据块,而文件系统所需的元数据则由数据库管理。
需注意 JuiceFS 是与 HDFS 类似的分布式文件系统。因此,与直接使用对象存储不同,JuiceFS 能完美支持 HDFS API、POSIX API 和 Kubernetes CSI 驱动。
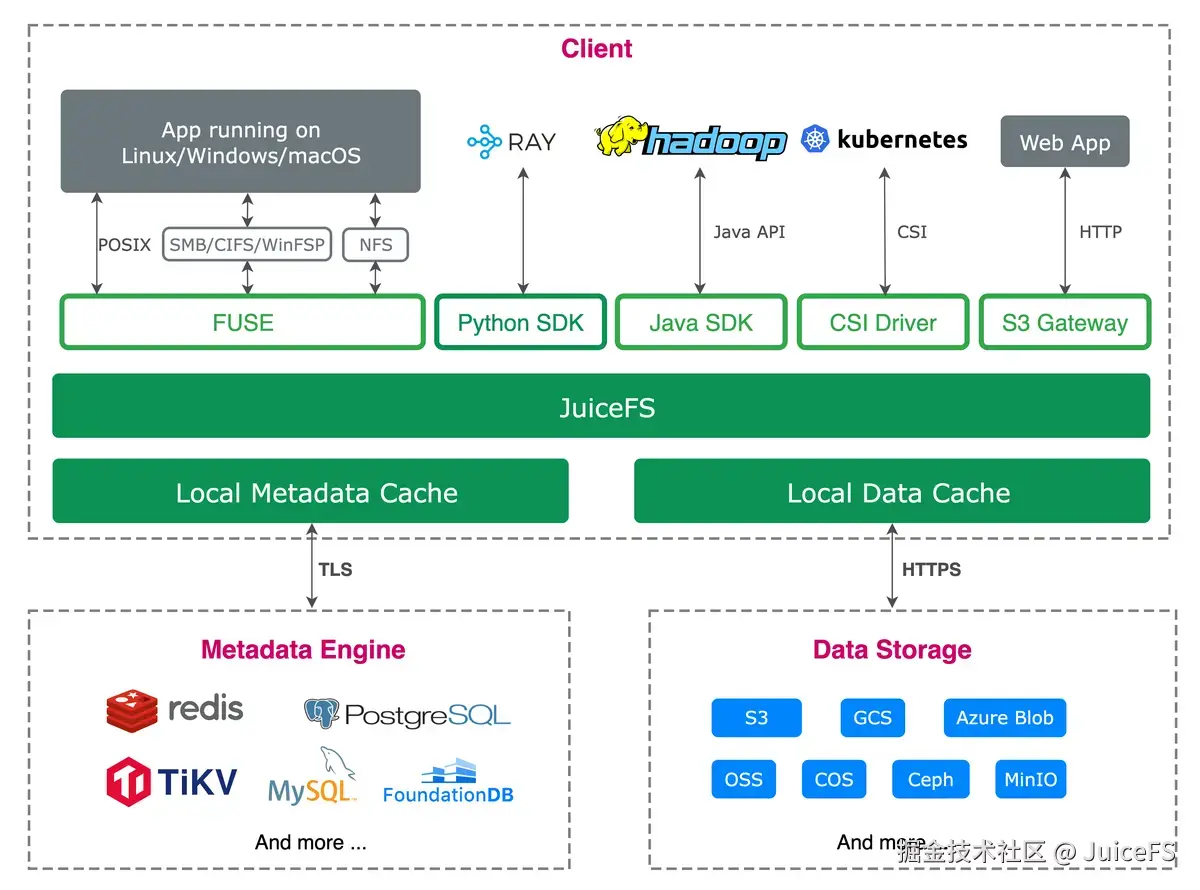
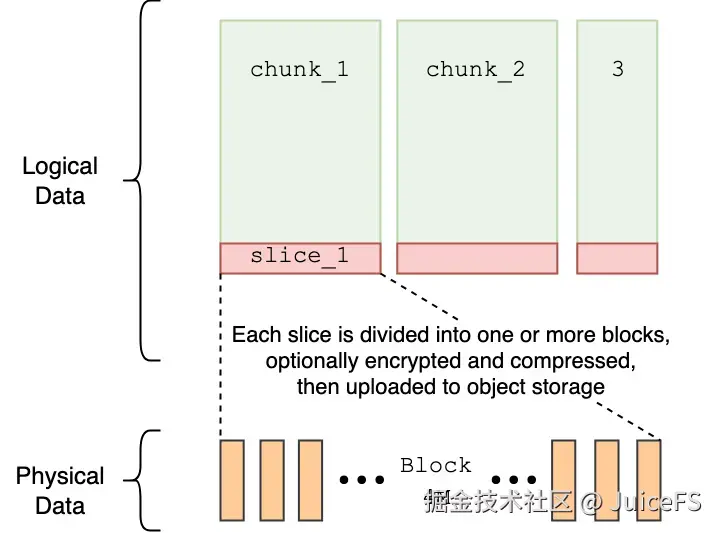
为了在速度慢且修改困难的对象存储上实现分布式文件系统,JuiceFS 引入了 chunk、slice 和 block 概念。
- chunk(64MB):将文件分割为 64MB 单位,支持基于偏移的并行处理。
- slice:chunk 内的修改单位,写入时创建新 slice 并优先使用最新版本。
- block(默认 4MB):实际存储在对象存储中的最小单位,通过并行处理缩短上传时间。
此外,从远程对象存储读取数据较慢,JuiceFS 支持多级缓存,以此弥补此性能不足。
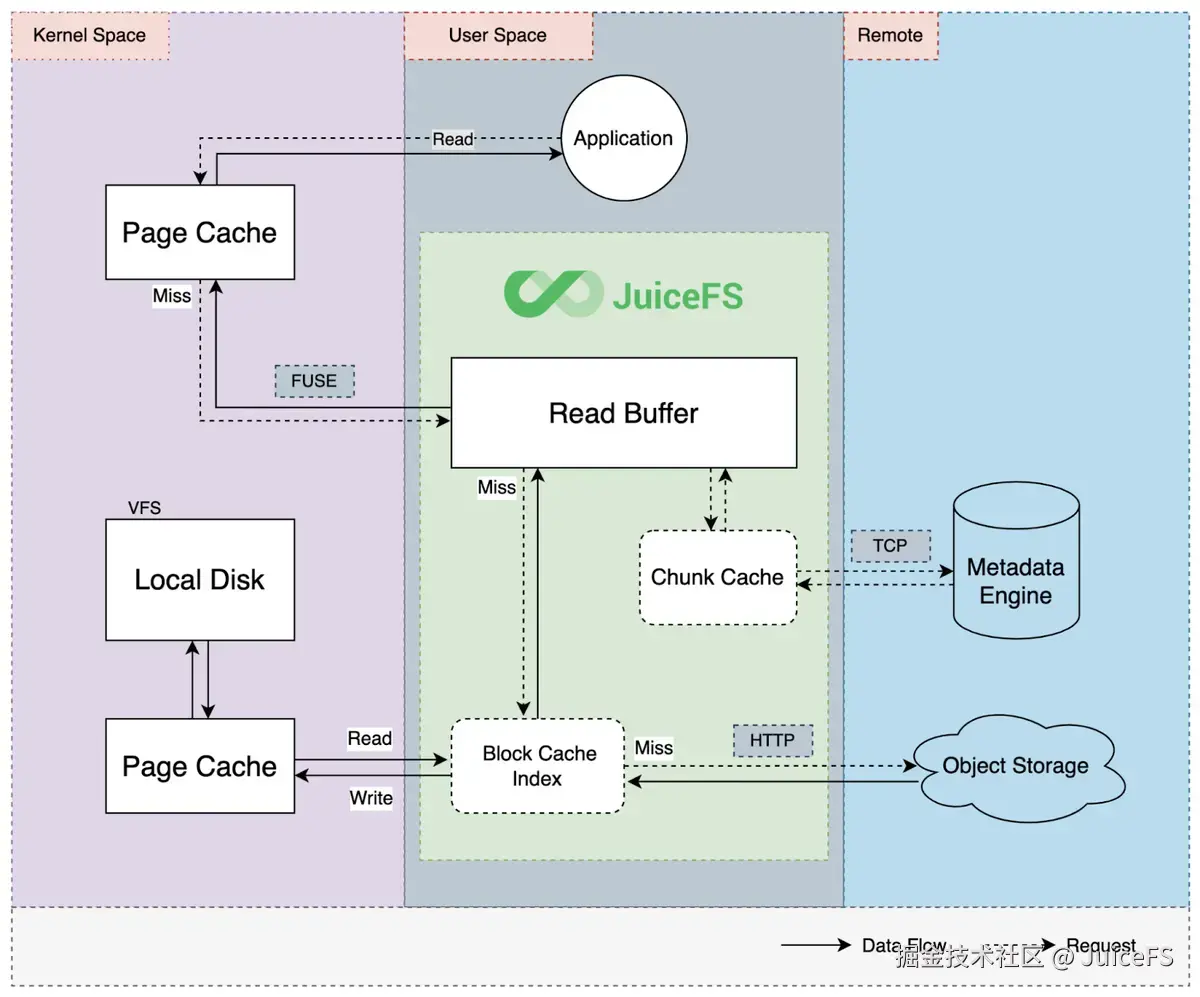
NAVER 内部 AI 平台已使用 JuiceFS。更多关于 JuiceFS 的详细信息及 AI 平台引入过程可参考为 AI 平台引入存储方案 JuiceFS。
JuiceFS 支持 Hadoop SDK,通过配置 JuiceFS 后,用户即可在 Hadoop 环境中使用它。
配置 JuiceFS
为使 Hadoop 识别 JuiceFS 文件系统,需在 core-site.xml 文件中添加以下内容。其中 fs.jfs.impl、fs.AbstractFileSystem.jfs.impl 和 juicefs.meta 是必需的。
xml
<!-- Configure JuiceFS to be available via jfs:// -->
<property>
<name>fs.jfs.impl</name>
<value>io.juicefs.JuiceFileSystem</value>
</property>
<property>
<name>fs.AbstractFileSystem.jfs.impl</name>
<value>io.juicefs.JuiceFS</value>
</property>
<!-- juicefs meta url -->
<property>
<name>juicefs.meta</name>
<value>redis://:password@addr</value>
</property>
<!-- In this example, grant access permissions to all users to avoid permission issues. -->
<property>
<name>juicefs.umask</name>
<value>000</value>
</property>
<!-- Cache up to 100 GiB. -->
<property>
<name>juicefs.cache-size</name>
<value>102400</value>
</property>
<!-- Cache under the temporary path of YARN containers, so the cache is removed when the container terminates.
Since it's a shared Hadoop, caching is temporary only during job execution. -->
<property>
<name>juicefs.cache-dir</name>
<value>${env.PWD}/tmp</value>
</property>
<!-- Prometheus remote write configuration for metrics collection -->
<property>
<name>juicefs.push-remote-write</name>
<value>http://host:port</value>
</property>
<property>
<name>juicefs.push-remote-write-auth</name>
<value>username:password</value>
</property>
<!-- Additionally collect Hadoop user and YARN container ID.
For shared Hadoop to distinguish users and applications. -->
<property>
<name>juicefs.push-labels</name>
<value>user:${env.USER};container_id:${env.CONTAINER_ID}</value>
</property> 以上为单文件系统的默认配置,但也可根据需要配置多个文件系统同时使用。
更多配置选项可参考"客户端配置"。
Hadoop SDK
Hadoop SDK 的 JAR 文件可以通过下载预编译客户端或自行编译源代码获取。为了简化部署,通常可以在所有 Hadoop 节点的 Hadoop 发行版安装路径中预先安装。然而,在大规模 Hadoop 集群中,这种方法操作繁琐,尤其是对于公共 Hadoop 环境,它会限制所有用户使用特定版本。
大多数 Hadoop 应用支持将所需 JAR 文件部署并添加到 classpath 中,用户可根据实际需要选择部署方式。以下是 HDFS CLI、MapReduce 和 Spark 中的具体部署方法。
HDFS CLI
配置完上述 core-site.xml 文件后,需要在 HADOOP_CLASSPATH 环境变量中设置 Hadoop SDK 文件路径。完成此设置后,您可以使用 hdfs 命令操作 hdfs:// 和 jfs:// 文件系统。
bash
$ export HADOOP_CLASSPATH=/home/juicefs/juicefs-hadoop-1.2.3.jar
$ hdfs dfs -ls hdfs://home/foo
Found 6 items
...
drwx------ - foo users 0 2022-10-14 20:55 hdfs://home/foo/.Trash
drwx------ - foo users 0 2022-01-06 10:18 hdfs://home/foo/dfsio
drwx------ - foo users 0 2025-01-22 17:54 hdfs://home/foo/tpcds
$ hdfs dfs -ls jfs://default/
2025-08-25 19:15:43,964 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 60 minutes, Emptier interval = 60 minutes.
Found 8 items
...
drwxrwxrwx - 10000 hadoop-admins 4096 2025-06-10 18:06 jfs://default/nyc
drwxrwxrwx - 10000 hadoop-admins 4096 2025-05-15 19:42 jfs://default/subdir MapReduce
MapReduce 在 Hadoop 的多个节点上并行运行,因此所有分配任务的节点都需要部署 JAR 文件。推荐的方法是通过分布式缓存进行部署。使用此方法时,任务执行时会自动将 mapreduce.application.framework.path 中设置的 MapReduce 框架部署到任务节点。
以下是 mapred-site.xml 文件的示例配置:
mapreduce.application.framework.path:指定包含 Hadoop SDK 的 MapReduce 框架的 HDFS 路径。mapreduce.application.classpath:配置为包含 Hadoop SDK 的路径。
bash
<property>
<name>mapreduce.application.classpath</name>
<value>$PWD/mr-framework/hadoop/share/hadoop/mapreduce/*:$PWD/mr-framework/hadoop/share/hadoop/mapreduce/lib/*:$PWD/mr-framework/hadoop/share/hadoop/common/*:$PWD/mr-framework/hadoop/share/hadoop/common/lib/*:$PWD/mr-framework/hadoop/share/hadoop/yarn/*:$PWD/mr-framework/hadoop/share/hadoop/yarn/lib/*:$PWD/mr-framework/hadoop/share/hadoop/hdfs/*:$PWD/mr-framework/hadoop/share/hadoop/hdfs/lib/*:$PWD/mr-framework/hadoop/share/hadoop/tools/lib/*</value>
</property>
<property>
<name>mapreduce.application.framework.path</name>
<value>hdfs://mapred/framework/hadoop-mapreduce-3.1.2-juicefs-1.2.3.tar.gz#mrframework</value>
</property> Spark
Spark 的基本配置文件是 spark-defaults.conf。在该文件中,可以替代 core-site.xml 进行如下设置:
- 任意 Hadoop 设置可以通过
spark.hadoop.key=value形式添加。 spark.jars:指定要部署到 Spark driver 和 executor,并包含在 classpath 中的 JAR 文件。
arduino
spark.hadoop.fs.jfs.impl io.juicefs.JuiceFileSystem
spark.hadoop.fs.AbstractFileSystem.jfs.impl io.juicefs.JuiceFS
spark.hadoop.juicefs.meta redis://:password@addr
spark.hadoop.juicefs.umask 000
spark.hadoop.juicefs.push-remote-write http://host:port
spark.hadoop.juicefs.push-remote-write-auth username:password
spark.hadoop.juicefs.push-labels user:${env.USER};container_id:${env.CONTAINER_ID}
spark.hadoop.juicefs.cache-size 102400
spark.hadoop.juicefs.cache-dir ${env.PWD}/tmp
spark.jars hdfs://juicefs/juicefs-hadoop/juicefs-hadoop-1.2.3.jar 04 JuiceFS 改进事项
JuiceFS 提供多种接口,支持跨平台的数据共享。例如,在 Hadoop 中使用 MapReduce 或 Spark 处理的数据存储到 JuiceFS 后,可以轻松在 Kubernetes 环境中访问和使用这些数据。
为使 NAVER 公共 Hadoop 和基于 Kubernetes 的 AI 平台顺畅共享数据,需要进行一些改进。(已经全部贡献到社区版。)
支持 all-squash 挂载(#5394)
NAVER 公共 Hadoop 与 LDAP 集成管理用户账户,因此 Hadoop 中创建的数据由相应用户的 LDAP UID 和 GID 所有。然而,在 Kubernetes 中,容器可以使用任意 UID 和 GID 运行,这可能导致访问 Hadoop 创建的数据时产生权限问题。
为了解决这个问题,我们增加了挂载选项 --all-squash。该选项使得访问挂载路径时,操作不会以当前账户的 UID 和 GID 进行,而是使用指定的 UID:GID。因此,设置 Hadoop 用户的 LDAP UID 和 GID 后,Kubernetes 中的容器可以无权限问题地访问数据。
改进 juicefs.users 和 juicefs.group 设置方式(#4723)
如前所述,在 Hadoop 集群中执行任务时,数据归 Hadoop 用户的 LDAP UID 和 GID 所有。但在 Hadoop 集群外部使用 Hadoop SDK 时,数据归任意 UID 和 GID 所有。例如,在 Docker 容器中使用 HDFS 命令存储数据时,所有者为容器内部账户的 UID 和 GID。
为了解决这个问题,用户需要通过 juicefs.users 和 juicefs.groups 设置指定所需的 UID 和 GID。之前,这要求用户编写 <用户名>:<UID> 和 <组名>:<GID> 格式的文件,并设置文件路径,这个过程非常繁琐。现在,我们增加了直接通过配置值来指定 UID 和 GID 的功能,简化了操作。
支持 subdir(#6096)
在基于 Kubernetes 的 AI 平台中,JuiceFS 以动态供应方式使用。创建 PersistentVolumeClaim(PVC)时,会在 JuiceFS 文件系统内生成与该卷对应的子目录。若要在 Hadoop 中共享该 PVC,需仅安全地共享该卷对应的目录。
然而,Hadoop SDK 并不提供类似 --subdir 的挂载选项,无法限制 Hadoop 仅访问 JuiceFS 的特定子路径。为了解决这个问题,我们在 Hadoop SDK 中增加了 juicefs.subdir 设置,使用此设置可以限制仅访问指定路径。
通过 hdfs 命令查看配额(#5937)
JuiceFS 可以为整个文件系统或特定目录设置配额。在 Kubernetes 中,PVC 的 spec.resources.requests.storage 值将设置为该目录的配额。
在 Hadoop 与 PVC 共享时,也需要查看配额信息。然而,原有的 HDFS 命令 hdfs dfs -count -q 无法查看 JuiceFS 的配额。为了解决这个问题,我们对该功能进行了改进,现在可以通过相同的命令查看 JuiceFS 的配额信息。
支持 Prometheus remote_write 协议(#6295)
使用 JuiceFS Hadoop SDK 时,可以将指标发送到 Pushgateway 和 Graphite。但 Pushgateway 需要定期清理指标,且 Graphite 格式独特,使用起来较为困难。
许多系统支持 Prometheus remote_write 协议。为了解决这个问题,我们在 JuiceFS 中增加了通过该协议发送指标的功能。通过 juicefs.push-remote-write 和 juicefs.push-remote-write-auth 设置,用户可以指定 VictoriaMetrics vmagent 或 Prometheus。这一功能不仅整合了跨平台数据,还能整合监控系统。
05 JuiceFS 的优势
优势 1:通过并行处理和缓存克服对象存储的性能瓶颈
JuiceFS 需要通过网络与远程对象存储交换数据块,因此在性能上难以超越具有数据本地性优势的 HDFS。然而,通过将数据分块并行处理以及缓存已读取数据,可以克服这一性能瓶颈。我们通过性能测试验证了 HDFS 和 JuiceFS 在不同场景下的表现。
DFSIO
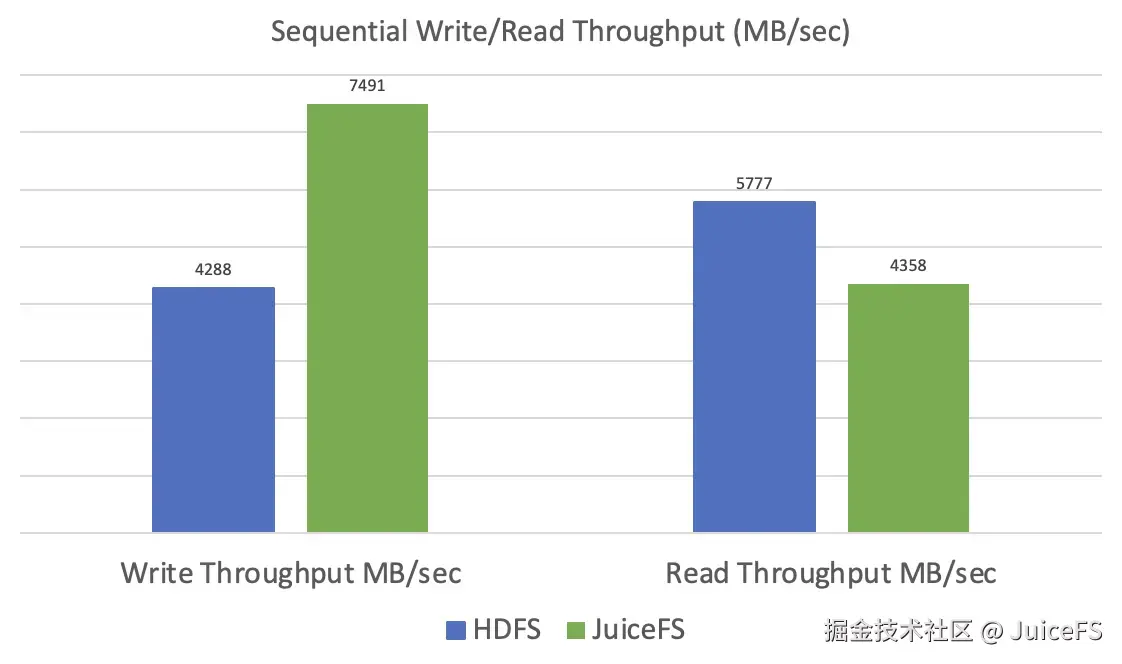
使用 10 个 map task,针对 100GB 文件测量 HDFS 和 JuiceFS 的顺序数据写入和读取的吞吐量。数值越高性能越好。为适应顺序写入/读取,将 JuiceFS 的块大小设为 16MB。
- 写入:JuiceFS 的吞吐量是 HDFS 的 1.7 倍。这是因为数据被分割成小块并行上传。
- 读取:JuiceFS 的吞吐量是 HDFS 的 0.75 倍。但如果数据已缓存,预期性能与 HDFS 相似。
TPC-DS
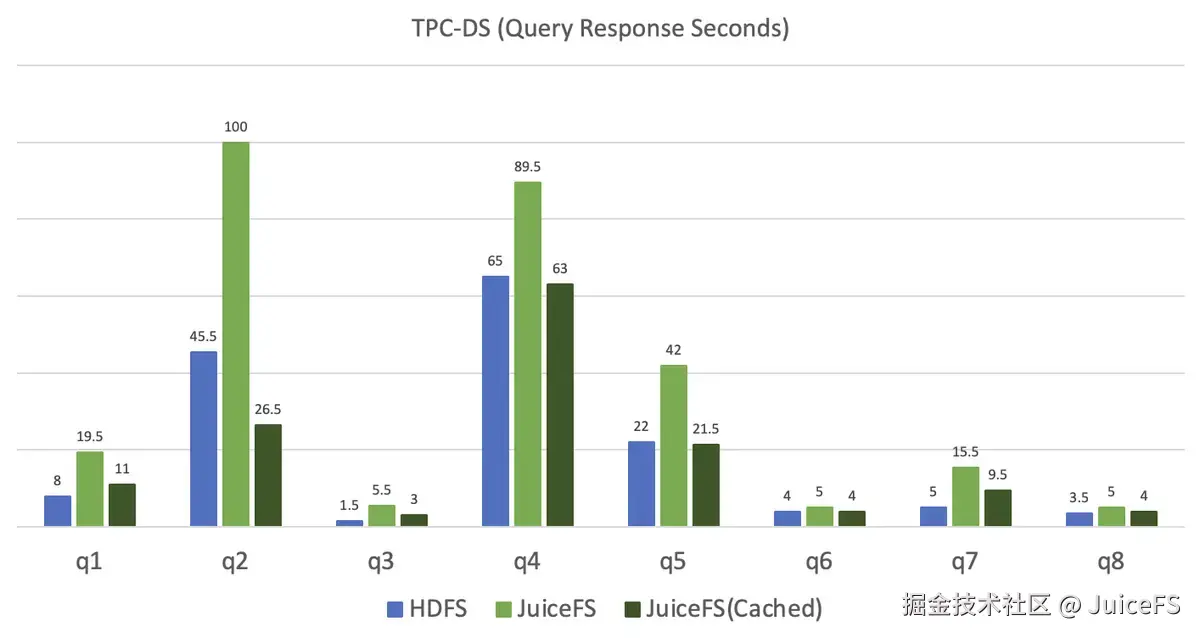
使用 Spark SQL 测量对存储在 HDFS 和 JuiceFS 的 100GB 规模表的查询响应时间。数值越低性能越好。
- JuiceFS 的响应时间是 HDFS 的 1.8 倍,这是由于数据本地性差异所致。
- 已缓存的 JuiceFS 表现出与 HDFS 相似的性能。
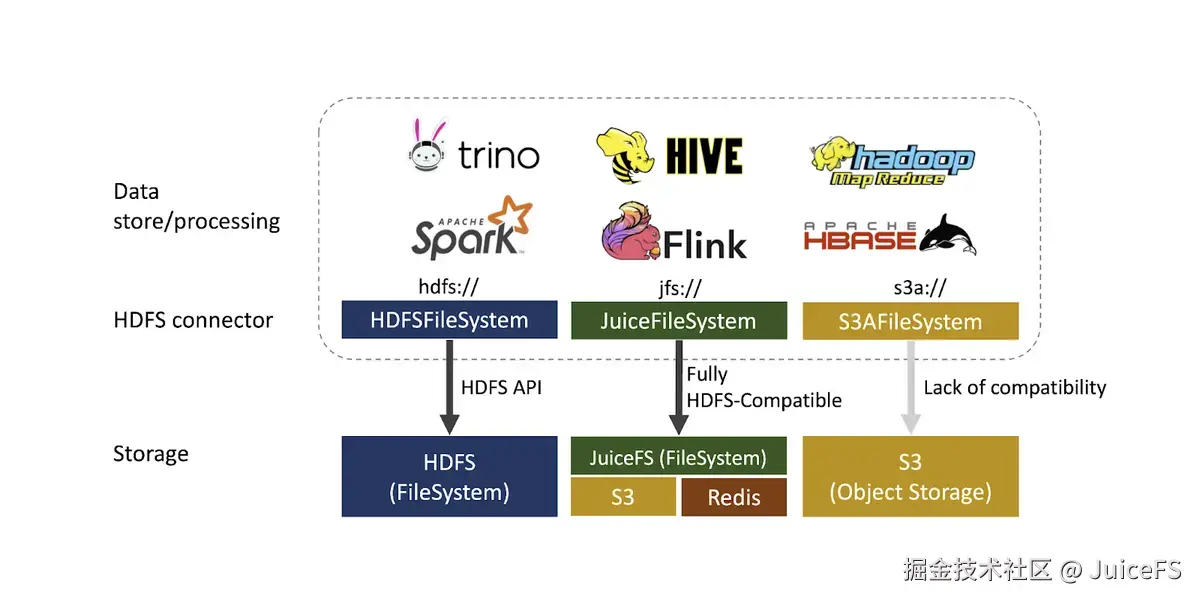
优势 2:与 HDFS 完全兼容,无需修改现有 Hadoop 应用即可使用
NAVER 拥有稳定运营的公共 Hadoop 集群,运行着多种服务的 Hadoop 应用。如果仅将不常用的数据存储在对象存储中以降低存储成本,可能会出现问题。正如前所述,对象存储不是文件系统,无法保证现有 Hadoop 应用的性能和运行。为此,需要重写代码或检查数据处理引擎是否支持对象存储。此外,还需根据存储类型单独运行和管理 Hadoop 应用,增加了管理负担。
与之相反,使用 JuiceFS 可以保持现有 Hadoop 应用不变。用户只需将输入输出路径指定为 hdfs:// 或 jfs://,即可以相同方式运行应用。
HDFS 基于数据本地性保证高性能,而对象存储则在低成本和扩展性方面具有优势。两者各有所长,难以完全替代,需要根据需求选择。使用 JuiceFS 可以在不修改现有 Hadoop 应用的情况下,同时利用 HDFS 和对象存储的优势。
优势 3:支持多种接口,可作为跨平台集成存储
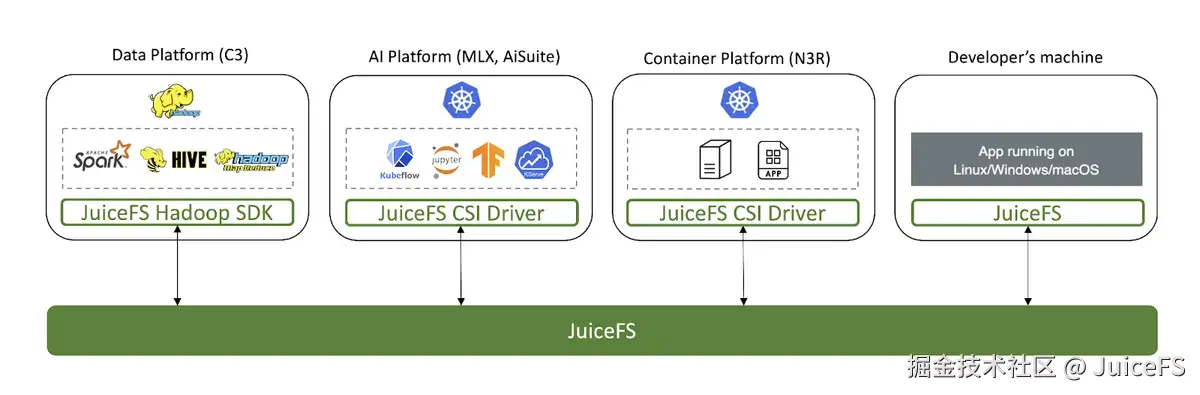
NAVER 使用多种平台进行服务开发和运营。例如,在开发/运营 AI 服务时,需要在数据处理平台中清洗数据,在 AI 平台中训练模型,并通过容器平台提供服务。
在 NAVER,各个平台提供独立的存储,平台内部易于使用,但难以访问其他平台的存储。不同平台的存储隔离导致了数据孤岛现象,并容易造成数据重复和资源浪费。
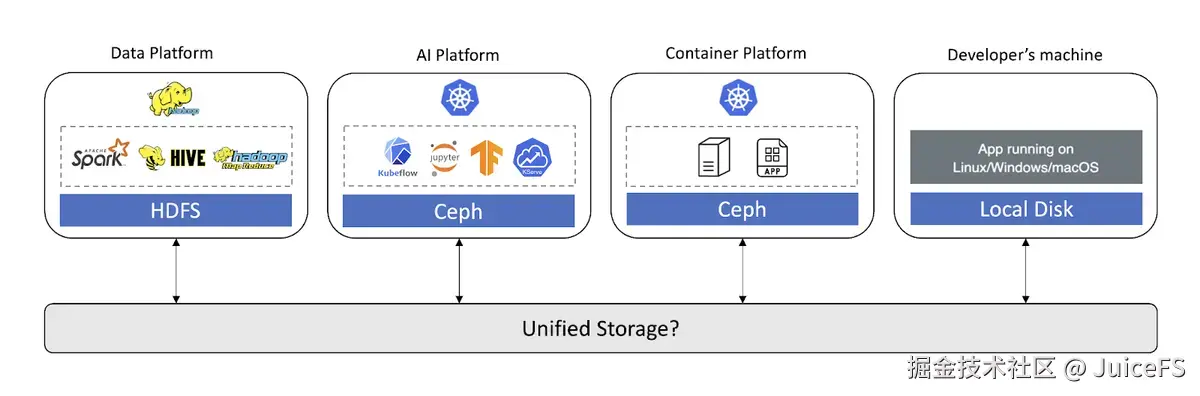
JuiceFS 不仅支持 HDFS,还完美兼容 POSIX 和 Kubernetes CSI 驱动,适合作为跨平台的集成存储。通过在多个平台间顺畅使用 JuiceFS 共享数据,可大幅提升 AI 服务开发效率,实现数据统一管理。
06 结语
本文探讨了 JuiceFS 在 Hadoop 环境中的使用方法及其优势,而在部分业务场景下,直接采用 HDFS 或对象存储会是更适配的选择。例如,当业务需要依托数据本地性实现高效快速处理时,建议将数据存储于 HDFS 中;此外,针对访问频率较低的数据,或采用 Iceberg 等专为对象存储优化的数据格式时,直接使用对象存储则更为简便。
而在以下场景中,JuiceFS 会是更优选择:
- 需在 Kubernetes 与 Hadoop 环境之间实现数据共享时;
- 希望在不修改现有 Hadoop 应用代码的前提下,与 HDFS 并行部署使用时;
- 处理存在重复读取行为、可通过缓存显著提升效率的数据作业时;
- 业务所用 S3 API 无法被底层 S3 兼容存储良好支持时。
本文介绍了在 NAVER 内部本地环境中的应用案例,但在 AWS、Google Cloud 等公有云环境中同样适用。希望对有类似困扰的读者有所帮助。