🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
📝个人主页-Sonhhxg_柒的博客_CSDN博客📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋

一、前言
在大模型时代,拥有一个个人专属的AI助手已经不再是遥不可及的梦想。今天,我将为大家带来一份详尽的实战教程,教你如何使用Nanobot构建一个基于vLLM部署的智能QQ聊天机器人。
Nanobot是由香港大学数据科学研究所开发的一款超轻量级AI智能体,灵感来自OpenClaw。它的设计理念是"让AI触手可及",通过极简的代码实现强大的功能。Nanobot的关键特性包括:
- 🪶 超轻量级:仅约4,000行核心代理代码,比Clawdbot小99%,实时代码行数仅为3,510行
- 🔬 研究就绪:代码干净易读,易于理解、修改和扩展以用于研究
- ⚡️ 闪电般快速:最小的占用空间意味着更快的启动、更低的资源使用和更快的迭代
- 💎 易于使用:一键部署即可使用
- 🐅 扩展性强:支持多种聊天平台接入,包括QQ、飞书、邮箱等
- 🦁 高度定制:可以根据个人需求自由配置模型和功能
而vLLM则是一款专为大模型部署优化的工具,它通过实现PagedAttention等技术,大幅提升了大模型的推理速度和并发处理能力。
结合Nanobot和vLLM,我们可以构建一个响应迅速、功能强大的智能QQ聊天机器人,让AI助手真正融入我们的日常沟通。
二、环境准备
在开始部署之前,我们需要准备一个合适的运行环境。以下是推荐的配置:
2.1、 硬件要求
CPU:至少4核以上
内存:至少16GB(推荐32GB以上)
GPU:如果要使用vLLM进行本地推理,建议使用NVIDIA GPU,显存至少16GB(推荐24GB以上)
存储空间:至少100GB可用空间(用于存储模型和依赖)
2.2、 软件要求
操作系统:Linux(推荐Ubuntu 20.04+)或Windows 10/11
Python:3.11+(推荐3.12)
Git:用于克隆代码仓库
CUDA:如果使用GPU,需要安装CUDA 11.7+(推荐11.8或12.4)
三、使用星图AI部署的vLLM模型(Qwen3-4B-Instruct-2507)
3.1、登录星图AI网址搜索(Qwen3-4B-Instruct-2507)
3.2、点击立即部署,等待服务启动成功。
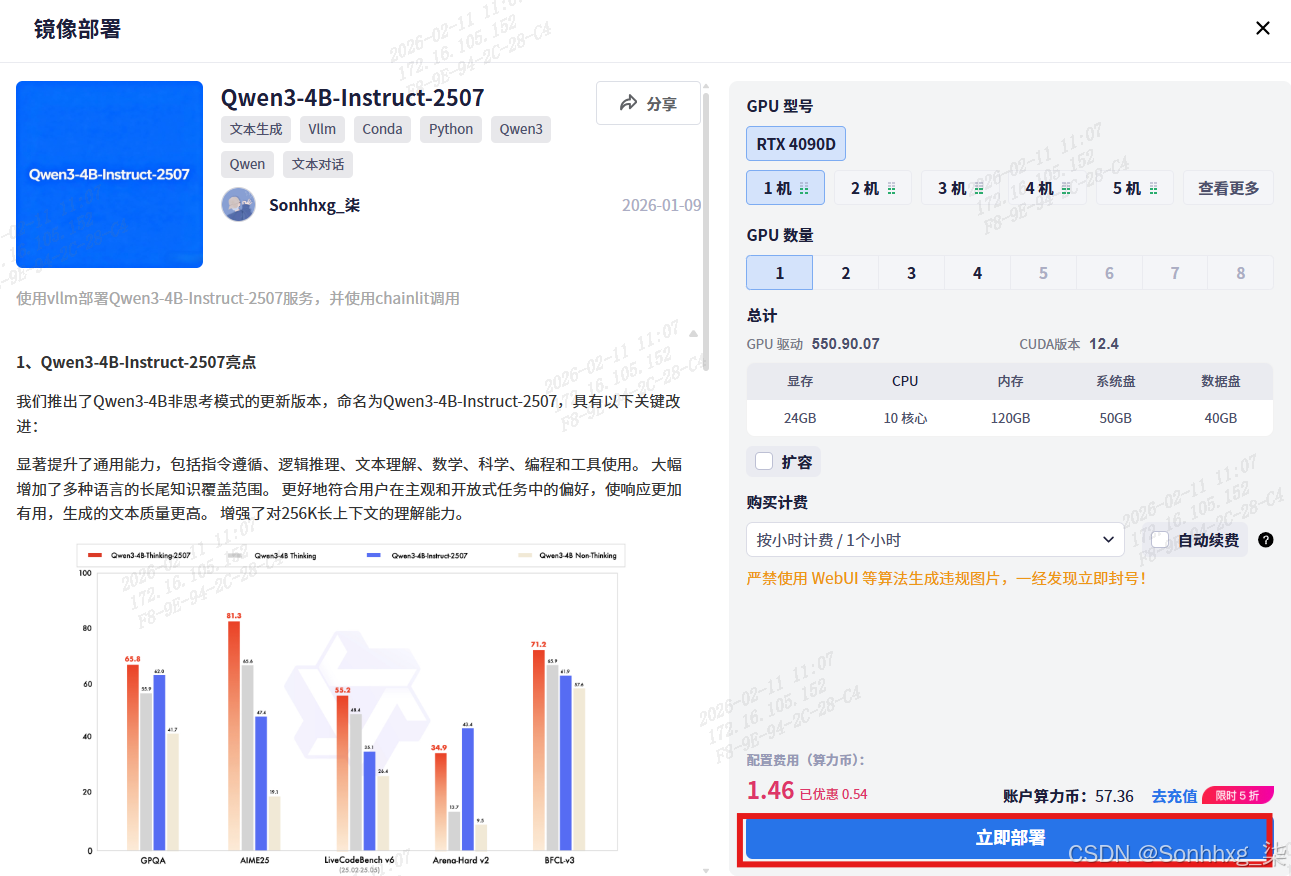
注意:需要工具调度需要,改变镜像内supervisor启动模型的配置文件命令及修改脚本如下:
vim /etc/supervisor/conf.d/tencent_hy.conf修改后的配置如下
[program:llm]
command=/opt/miniconda3/bin/vllm serve --served-model-name Qwen3-4B-Instruct-2507 --max-model-len 25000 --gpu_memory_utilization 0.90 --model /usr/local/bin/Qwen3-4B-Instruct-2507 --port 8000 --host 0.0.0.0 --enable-auto-tool-choice --tool-call-parser hermes
environment=HOME="/root",USER="root",LOGNAME="root",SHELL="/bin/bash"
user=root
autostart=true
autorestart=true
redirect_stderr=true
stdout_logfile = /root/workspace/llm.log部署成功的vllm的模型服务的地址为jupyter链接的端口号替换为8000.
例如:
https://gpu-pod698bf28e9681f1044bf1640b-8000.web.gpu.csdn.net/v13.3、验证vLLM服务
测试vllm服务启动是否成功curl命令如下:
curl --request POST \
--url https://gpu-pod698bf28e9681f1044bf1640b-8000.web.gpu.csdn.net/v1/chat/completions \
--header 'Authorization: Bearer 6741df536d06447abb6db60f0dfa4e21' \
--header 'content-type: application/json' \
--data '{
"model": "Qwen3-4B-Instruct-2507",
"messages": [
{
"role": "user",
"content": "你是谁"
}
],
"stream": false
}
'成功返回如下:

四、QQ开放平台新建机器人,并获取配置
4.1、访问QQ开放平台,注册个人或企业开发者。
4.2、创建机器人。

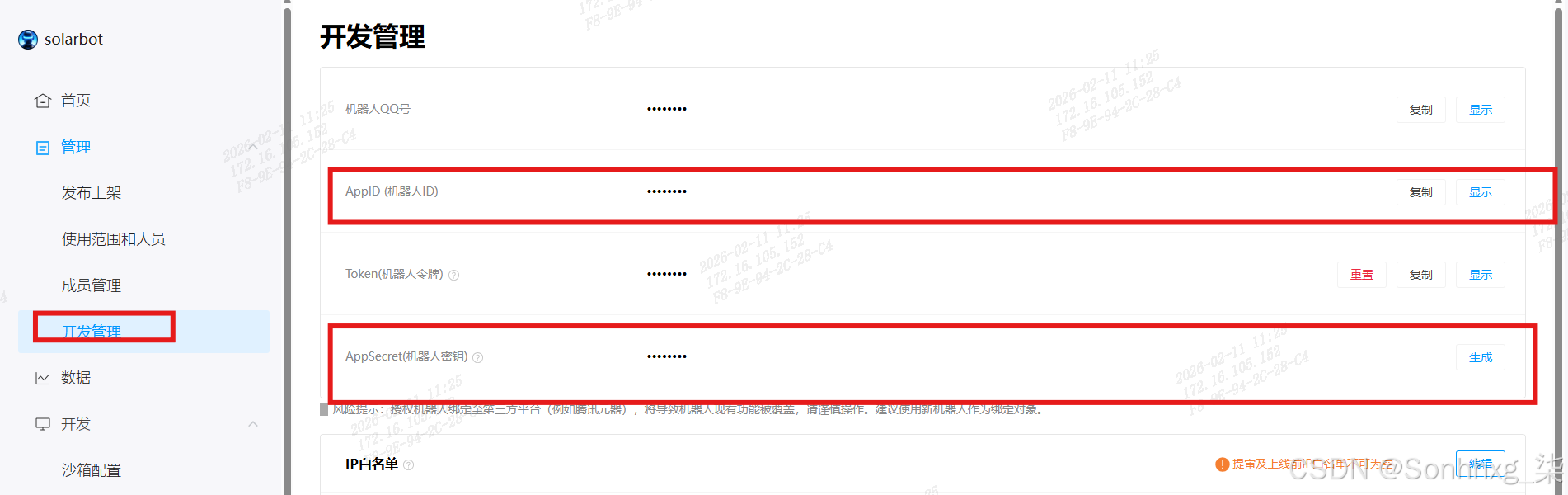
4.3、开发管理,复制AppID和AppSecret。
五、安装Nanobot
5.1、 方式一:通过pip安装(推荐)
使用pip安装
pip install nanobot-ai或使用uv工具安装(推荐,速度更快)
uv tool install nanobot-ai5.2、 方式二:通过源码安装
克隆仓库
git clone https://github.com/HKUDS/nanobot.git进入目录
cd nanobot安装依赖
pip install -e .5.3、 验证安装
安装完成后,我们可以通过以下命令验证Nanobot是否安装成功:
nanobot --version如果看到版本信息,则表示安装成功。
六、启动nanobot服务
6.1、初始化nanobot。
nanobot onboard6.2、修改配置文件
修改模型配置如下:
注意本地部署的模型:
apiBase : http://localhost:8000/v1
{
"providers": {
"vllm": {
"apiKey": "dummy",
"apiBase": "https://gpu-pod698bf28e9681f1044bf1640b-8000.web.gpu.csdn.net/v1"
}
},
"agents": {
"defaults": {
"model": "Qwen3-4B-Instruct-2507",
"maxTokens":4096,
}
}
}修改的qq相关配置如下:
{
"channels": {
"qq": {
"enabled": true,
"appId": "YOUR_APP_ID",
"secret": "YOUR_APP_SECRET",
"allowFrom": []
}
}
}6.4、启动nanobot的gateway服务
nanobot gateway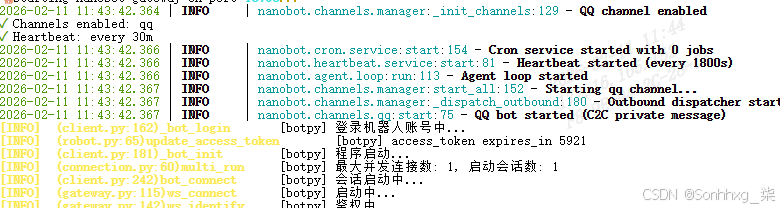
6.4、向qq机器人提问

七、总结
通过本教程,我们成功构建了一个基于Nanobot和vLLM的智能QQ聊天机器人。这个机器人具有以下特点:
- 本地部署:所有计算都在本地完成,保护隐私
- 高性能:使用vLLM优化推理速度,响应迅速
- 功能强大:支持上下文理解、多轮对话、知识库集成等高级功能
- 易于扩展:可以根据需要添加新功能和工具
Nanobot作为一款轻量级的AI智能体,为我们提供了一种简单、高效的方式来部署和使用大模型。结合vLLM的高性能推理能力和QQ的广泛使用,我们可以打造一个真正实用的个人AI助手。
未来,随着大模型技术的不断发展,Nanobot也将不断进化,为我们带来更多惊喜。如果你对Nanobot感兴趣,欢迎加入社区,一起探索AI的无限可能!
附录:相关资源
Nanobot GitHub:https://github.com/HKUDS/nanobot
vLLM GitHub:https://github.com/vllm-project/vllm
Hugging Face模型库:https://huggingface.co/models
希望本教程能够帮助你成功部署自己的Nanobot智能QQ机器人。如果你在部署过程中遇到任何问题,欢迎在评论区留言,我会尽力帮助你解决。