应届生第一门 AI 大模型实战课:RAG、Dify、Milvus 与 Vibe Coding
AI 大模型应用技术全景
前置导入:当前流行大模型速览
目标:先建立行业地图,知道"现在主流模型有哪些、各自擅长什么"。
- 闭源代表模型
- OpenAI GPT 系列(最新旗舰:GPT-5.3,通用能力、推理能力、生态成熟)。
- Anthropic Claude 系列(最新旗舰:Claude Opus 4.6,擅长代码、写作)。
- Google Gemini 系列(最新旗舰:Gemini 3,前端代码、多模态能力强)。
- xAI Grok 系列(最新模型:Grok 4.1 Fast)。
- 开源代表模型
- Qwen(通义千问)系列。
- DeepSeek 系列。
- GLM 系列(最新模型:GLM-4.7 ,即将推出GLM-5)。
- MiniMax 开源模型(最新模型:MiniMax-M2.1)。
- Kimi(Moonshot)系列(最新模型:Kimi-K2.5)。
Vibe Coding 主流配置:
国外配置 :Claude 负责代码生成,GPT 负责代码审查与质量把关。
国内配置:代码场景可优先考虑 MiniMax、GLM、Kimi。
2025-11 2025-11 2025-12 2025-12 2025-12 2025-12 2026-01 2026-01 2026-01 2026-01 2026-02 2026-02 2026-02 Gemini 3 Grok 4.1 Fast DeepSeek-V3.2 GLM-4.7 MiniMax-M2.1 Kimi-K2.5 GPT-5.3-Codex Claude Opus 4.6 GLM-5(预计) 闭源 开源 主流模型发布时间(里程碑)
第一部分:RAG (检索增强生成) ------ 解决幻觉的关键
目标 :这是企业最看重的技术,也是本次培训的重点。
1.1 意义
传统关系型数据库(如 MySQL)主要做结构化查询,通常基于字段进行精确匹配或模糊匹配。
倒排索引检索(如 Elasticsearch)通常是先分词,再通过关键词做匹配。
这两类方案本质上都偏"词匹配",对"语义理解"能力有限。
比如用户搜索"苹果手机",系统不能召回 "iPhone " 相关内容。
1.2 痛点
- LLM 的两大硬伤:知识截止(过时) + 私有数据不可见(企业内部文档)。
- 解决方案对比:微调 (Fine-tuning) 太贵且慢 vs RAG (外挂知识库) 性价比最高。
1.3 核心技术
Embedding (嵌入) 与 向量搜索
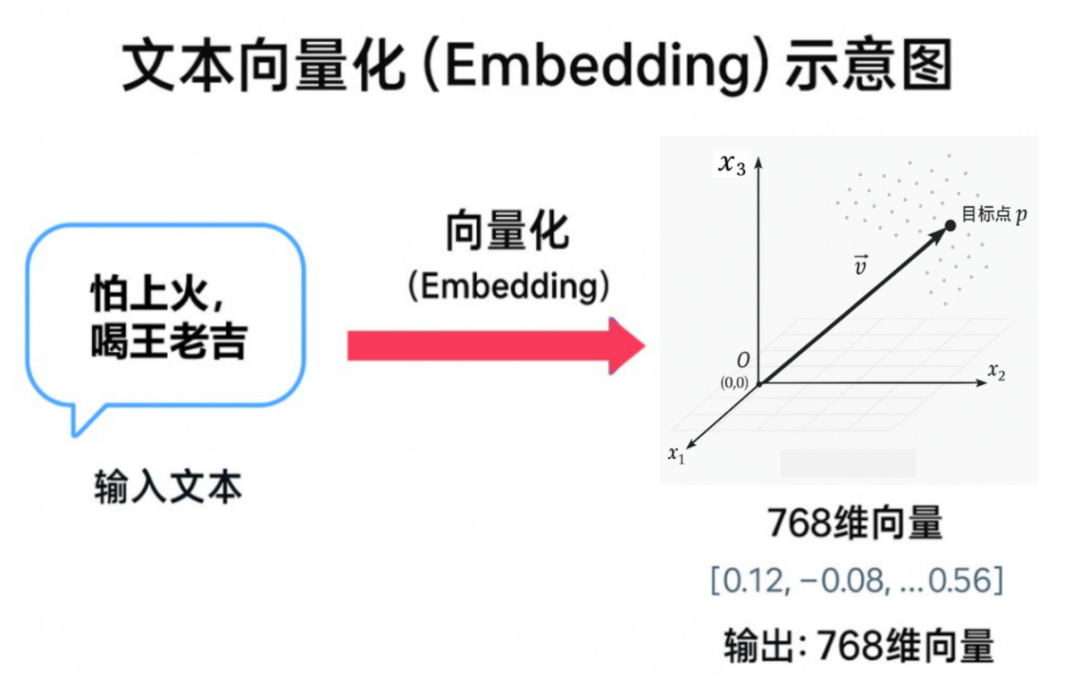
- 什么是向量/向量化?
把文本、图片、音频等非结构化数据,转换成一组可计算的数字(如[0.1, -0.5, 0.8, ...])。
这些数字不是"随机编码",而是模型对语义信息的压缩表达。 - 向量化的关键价值
向量化不只是"把内容变成数字",更重要的是把"语义关系"也编码进去:
语义越接近的内容,在向量空间中通常距离越近;语义差异越大,距离越远。
这就是 RAG 能做"语义检索"的基础。 - 向量维度代表什么?
向量往往是高维的(如768维、1024维、2048维)。
这里的每一维通常都不是人类可直接命名的"具体属性",而是模型学习到的"隐式语义特征"。
可以把它理解为:模型在高维空间里给每段文本打了一个"语义坐标"。
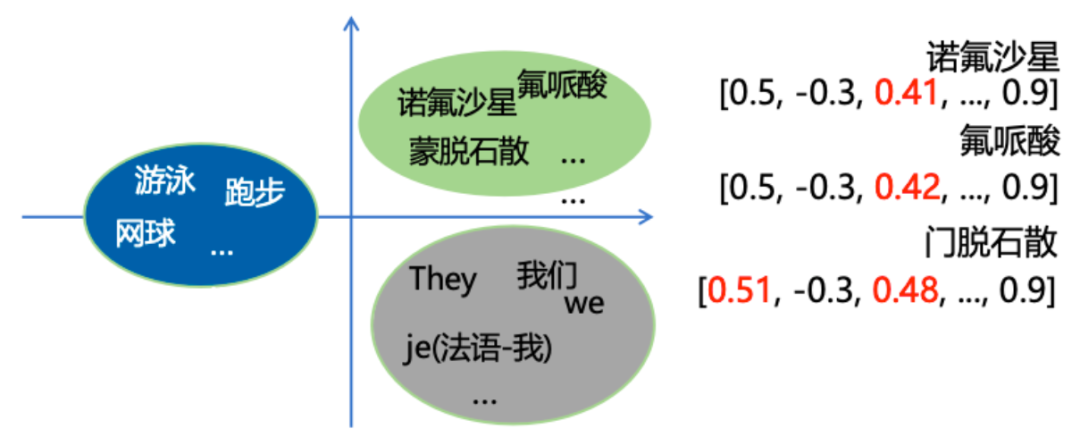
- 如何判断两段文本是否相似?
在向量空间中,通常通过"距离/夹角"来度量相似度,常见方法包括:
Cosine Similarity(余弦相似度)、L2 Distance(欧氏距离)、Inner Product(内积)。
本质上是把"语义相似判断"转化为"向量距离计算"。 - 一个直观例子
当用户搜索"苹果手机",系统会先把这句话向量化,再到向量库中查找"距离最近"的文本块。
即使文档里写的是"iPhone 15 Pro",没有出现"苹果手机"这个原词,也可能被正确召回。
第二部分:RAG架构流程
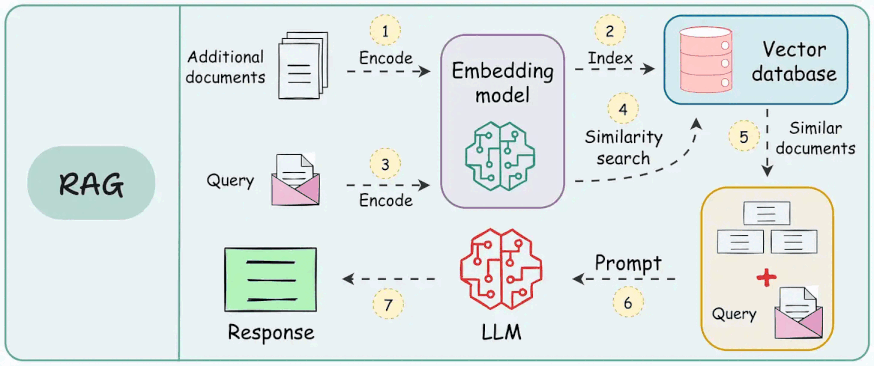
2.1 RAG 标准架构图
- 文档切片 (Chunking) -> 向量化 (Embedding) -> 存入向量库 (Chroma/Milvus) -> 检索 (Retrieval) -> 生成 (Generation)。
2.2 文本切分(Chunk)
常见的切分策略:
在 RAG 中,通常不会把整篇长文一次性向量化后写入向量库。
更常见的做法是先将文档切分为多个 Chunk,再对每个 Chunk 单独向量化,并以独立记录写入向量数据库。
这样做的好处是:检索粒度更细、召回更精准、上下文更可控。
常见切分方式有以下几类:
CharacterTextSplitter 字符分块
使用固定长度字符窗口拆分文本(如每512字符)
RecursivelyCharacterTextSplitter 递归分块
基于字符列表拆分文本。按层次化分隔符(\n\n > \n > , > ? > !)递归拆分至目标长度。
解释:其中如果每个分割的大小较大,则会递归分割,直到分至目标长度。
Document Specific Splitting
基于不同的文件类型使用不同的切分方法(如PDF、Python、Markdown)。
Semantic Splitting 语义分块
基于滑动窗口的语义切分。利用嵌入向量相似性分段。
- 从前几个句子开始,生成一个嵌入。
- 移动到下一组句子,并生成另一个嵌入(例如,使用滑动窗口方法)。
- 比较嵌入以查找重大差异,这表明语义部分之间可能存在"中断点"。
总结:先用某个方式切分,然后做滑动窗口,比如现在的窗口是
1-3块,那么就将1-3和1-4块计算余弦相似度距离。我们会设置一个距离的阈值,如果满足就把
4块加入到1-3中,那么现在就是1-4块为一块,继续做滑动窗口。如果不满足,就从这里切分,
1-3块为一块,下一个窗口是4块,类推用4和4-5比较...
2.3 生成嵌入(Embedding)
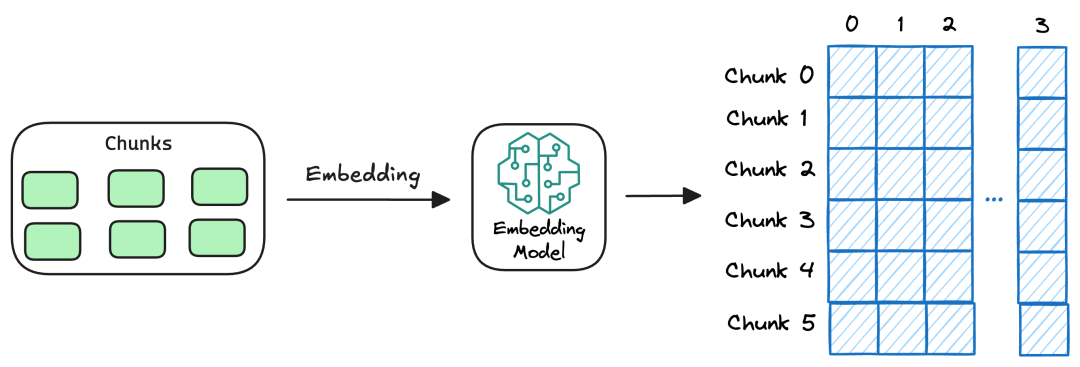
2.4 向量存储(Vector Storage)
| 向量数据库 | 类型 | 优点 | 局限 | 适合场景 |
|---|---|---|---|---|
| Milvus | 专用向量库 | 高性能、可扩展、工程化成熟 | 分布式部署复杂度较高,资源规划要求高 | 大规模生产、亿级向量检索 |
| Milvus Lite | 嵌入式向量库 | 轻量、无服务依赖、上手快 | 单进程、不可分布式服务化 | 本地学习、PoC、Demo |
| Weaviate | 专用向量库 | 功能完整,混合检索能力强 | 内存规划要求较高 | 产品化团队、中大型项目 |
| Qdrant | 专用向量库 | 轻量稳定、资源友好、易运维 | 企业生态普及度不如 ES | 中小规模、资源受限场景 |
| PGVector | PostgreSQL 扩展 | 架构简单、DBA 友好、SQL 统一 | 超大规模下性能与运维通常不如专用向量库 | 不希望引入新组件、已有 Postgres 体系 |
| Chroma | 轻量向量库 | 极简、开发体验好、适合快速验证 | 默认单机形态,高可用与大规模能力有限 | 本地实验、原型验证、教学演示 |
| Elastic / OpenSearch | 搜索引擎扩展 | 企业普及率高,关键词 + 向量融合方便 | 纯向量检索极限性能通常不如专用向量库 | 传统企业、已建设 ES/OS 体系 |
| OceanBase / SeekDB | 国产数据库/AI 检索产品 | 合规、国产化、政企友好 | 与国际主流方案相比,生态与案例沉淀仍在增长 | 政企项目、国产化要求高场景 |
| MyScale / MatrixOne | SQL/分析型数据库(含向量能力) | SQL 分析与向量检索结合好 | 向量检索是能力之一,不以向量为唯一核心 | 数据分析驱动的 AI 场景 |
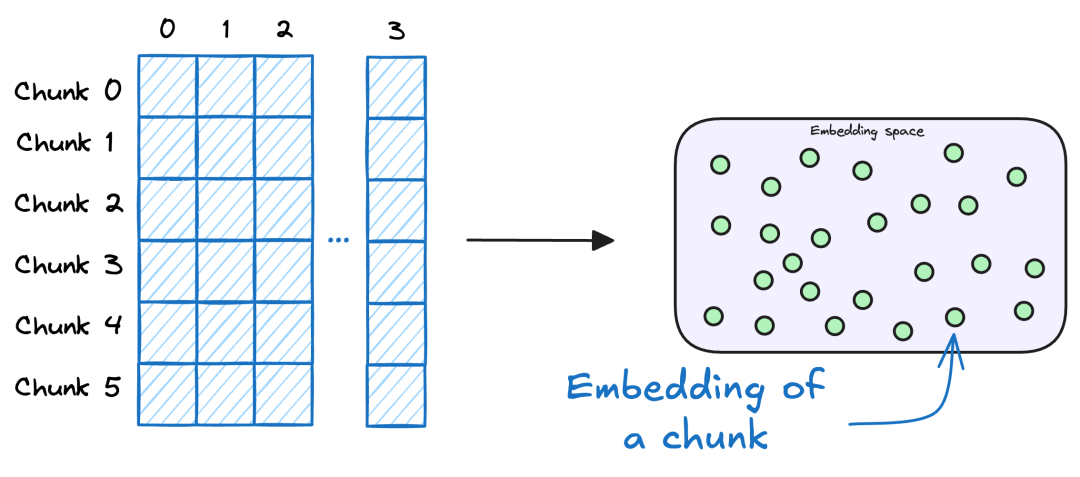
2.5 用户查询嵌入(Query Embedding)
使用与文档入库阶段一致的 Embedding 模型,将用户查询转换为向量表示,以保证检索向量空间一致、相似度计算可比。
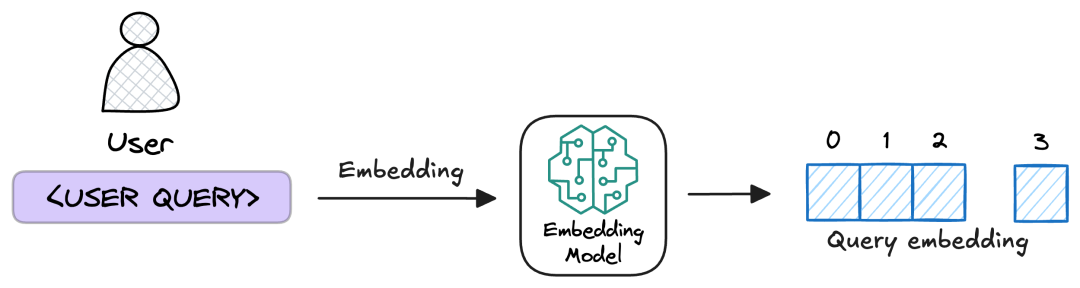
2.6 步骤5:语义检索(Semantic Retrieval)
基于查询向量,在向量数据库中通过近似最近邻(ANN)等检索算法进行高效相似度搜索,召回 Top-K 个最相关的知识块。
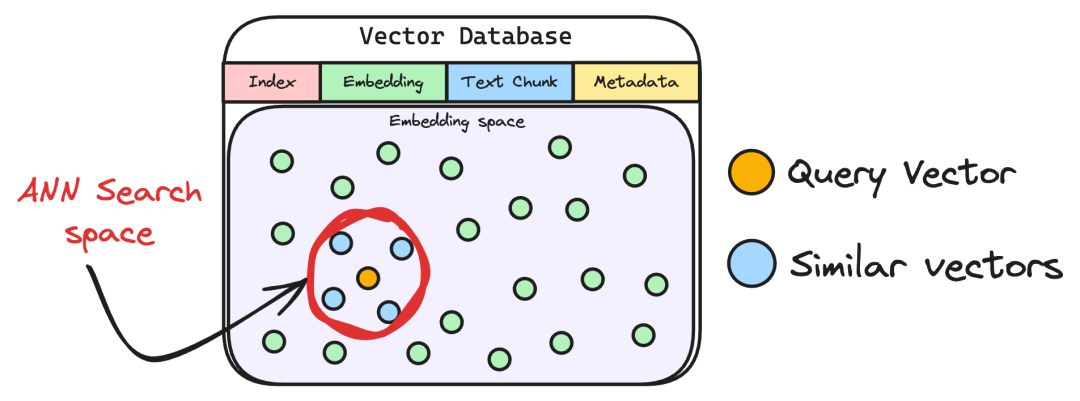
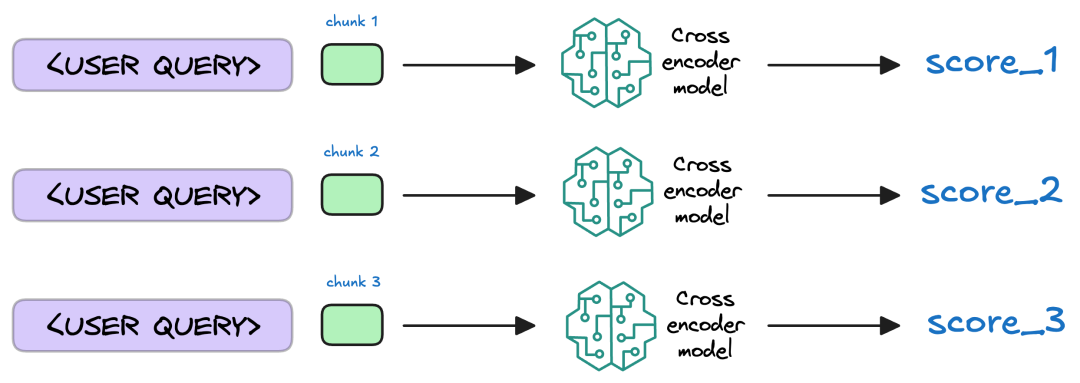
2.7 重排序(Reranking)
初步检索到的Top-K个知识块,可能存在"语义相似但主题偏离"的问题。比如用户问"RAGFlow的多模态支持",检索结果里可能混进了"其他工具的OCR功能",这时候就需要"重排序"环节来校准。
重排序一般采用交叉编码器(Cross-Encoder),将"查询 + 候选片段"成对输入模型,深度建模两者的语义交互,并输出更精细的相关性分数。随后按分数重新排序,保留最契合的问题上下文。这样可以显著减少噪声,提高答案依据的准确性与稳定性。
Embedding 模型与 Rerank 模型对比
| 对比维度 | 向量化模型(Embedding) | 重排序模型(Rerank / Cross-Encoder) |
|---|---|---|
| 输入形式 | 单文本(Query 或 Chunk) | Query + 候选 Chunk 成对输入 |
| 输出结果 | 向量表示(用于相似度检索) | 相关性分数(用于重新排序) |
| 主要目标 | 大范围高召回(Recall) | 小范围高精度(Precision) |
| 所在阶段 | 第一阶段:召回 | 第二阶段:精排 |
| 候选规模(常见) | 召回 Top-K 常设 50-200 |
重排候选 K 常设 20-100,高召回可到 100-200 |
| 性能特点 | 速度快、吞吐高、成本低;适合海量数据检索 | 速度相对慢、吞吐较低、成本更高;通常只处理 Top-K 候选 |
| 精度特点 | 能找到"可能相关"的候选,但排序不够精细 | 对语义匹配更精准,能有效压制噪声、提升 Top-N 结果质量 |
工程实践中通常采用"两阶段检索":先用 Embedding 召回,再用 Rerank 精排,以兼顾性能与精度。
2.8 增强生成(Augmented Generation)
将 Rerank 后的高相关知识片段与用户问题一起组装为新的 Prompt,输入大模型,由模型基于该上下文生成最终答案。
第三部分:Dify 实战
目标:让学生在低代码平台上快速搭建一个可用的 AI 应用,理解从"想法"到"可演示产品"的最短路径。
- Dify 是什么
- 面向 AI 应用开发的低代码平台,支持 Prompt、知识库、工作流、工具调用。
- 与代码开发的关系
- Dify 适合快速验证需求与交互流程(MVP)。
- 复杂场景再迁移到代码框架(LangChain/LlamaIndex/自研服务)做深度定制。
获取免费测试 Token
有两个平台有免费额度,其中阿里百炼比较多。
阿里百炼平台获取 Key:https://bailian.console.aliyun.com/cn-beijing/?tab=model#/api-key
硅基流动平台获取 Key:https://cloud.siliconflow.cn/me/account/ak
硅基流动需完成实名任务,否则可能会有并发限制导致调用Embedding模型出现错误。
配置模型供应商
Dify 官网:https://cloud.dify.ai/apps
Dify 测试网站:http://dify.chongwenz.cn:8085/
ps: Dify 官方网站需要VPS。
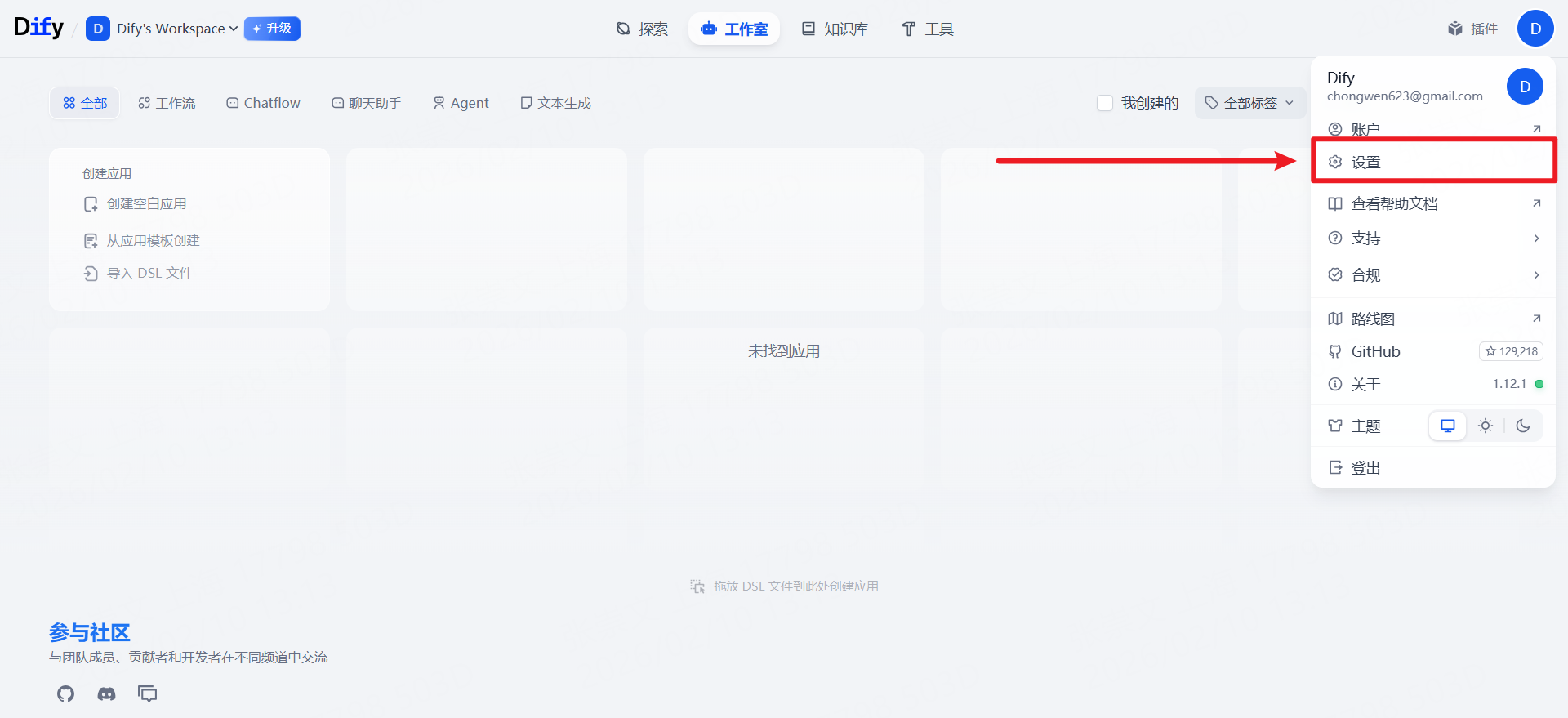
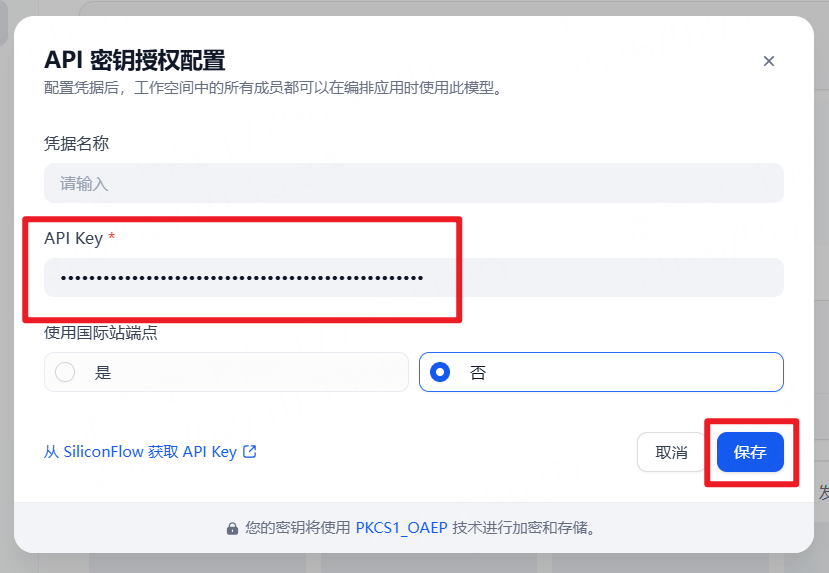
步骤 1 :进入 Dify 工作台首页,点击设置并配置模型。
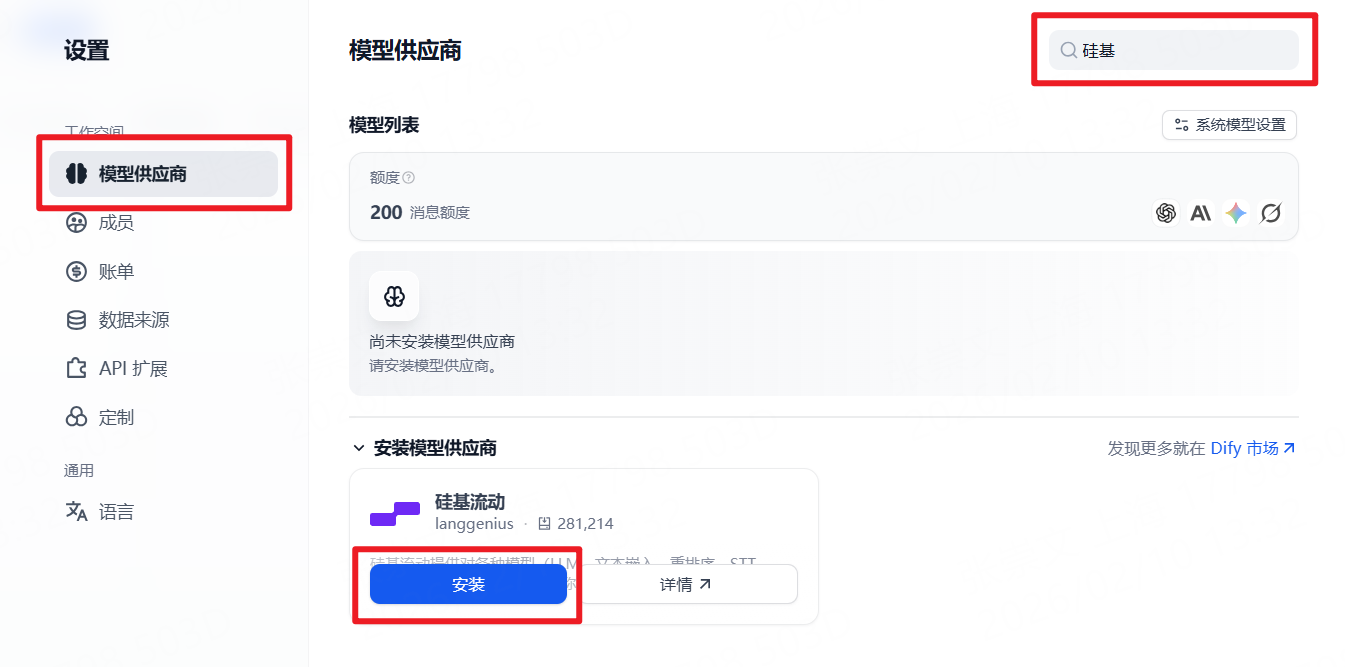
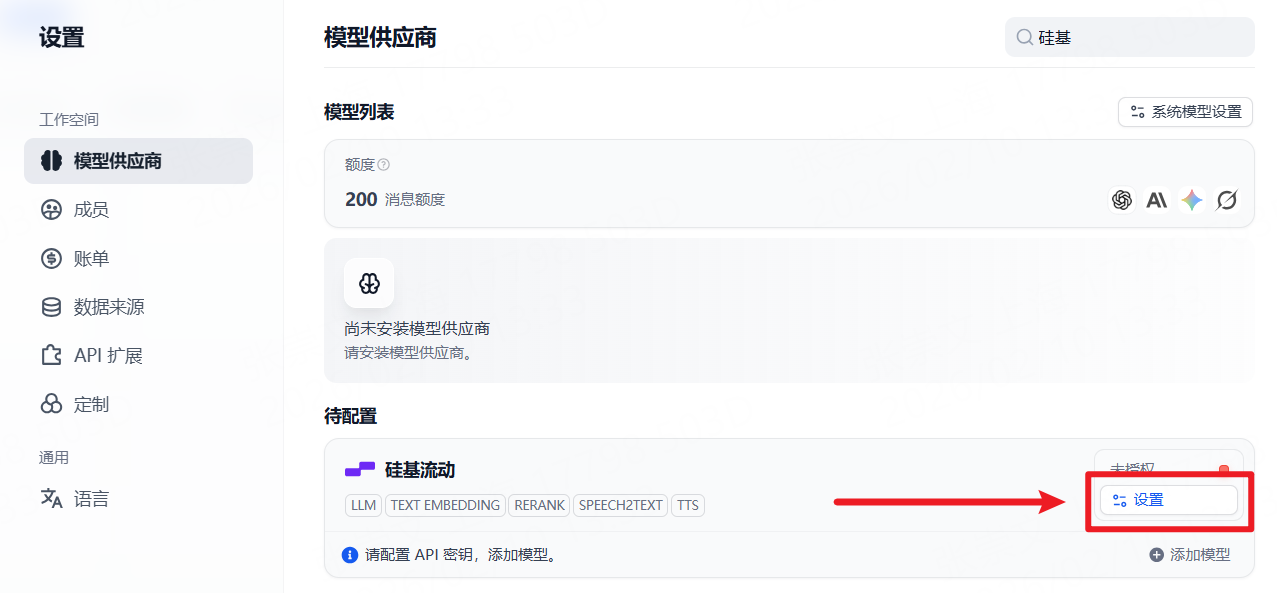
步骤 2 :打开模型供应商配置入口,准备新增可调用的大模型服务。
创建知识库
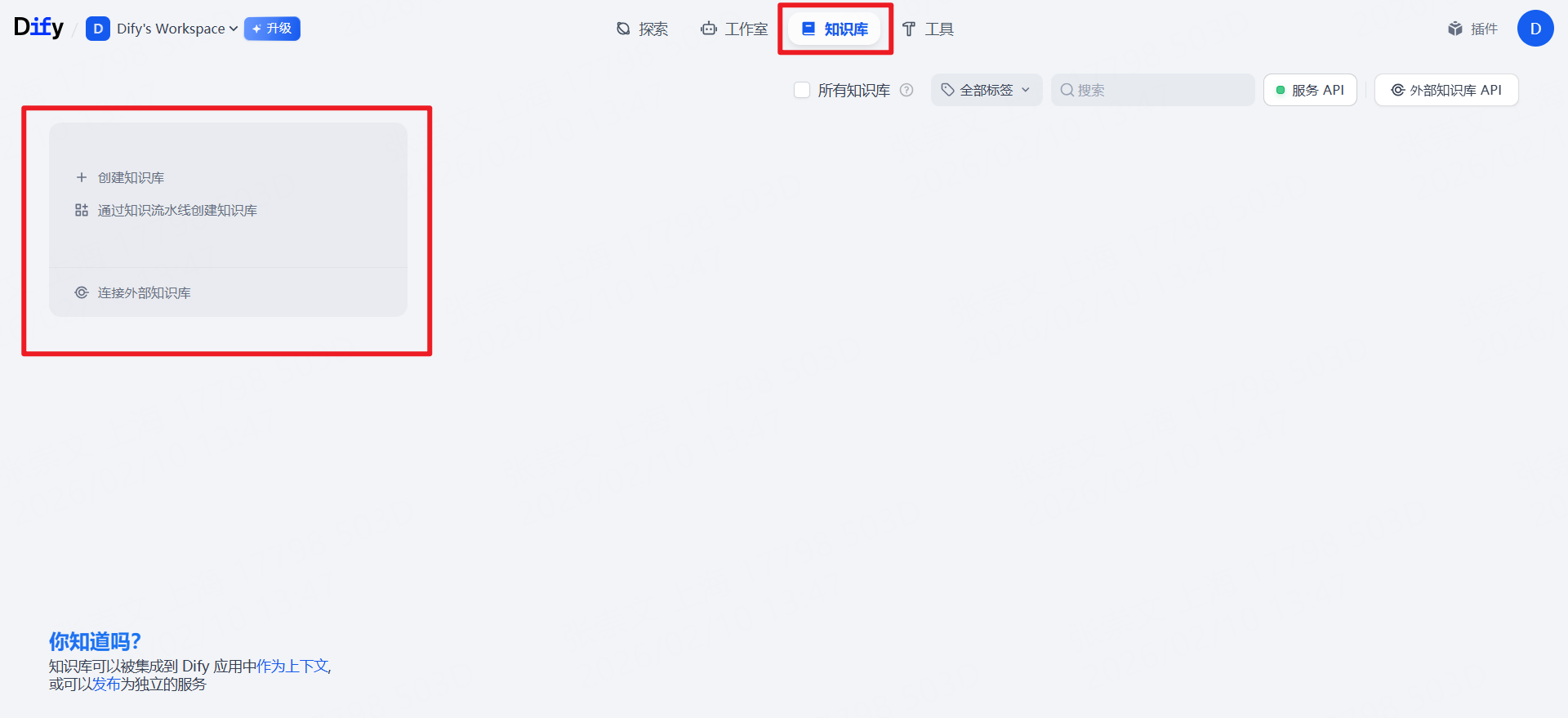
测试文件下载地址:https://www.gov.cn/lianbo/bumen/202406/P020240607272121492270.pdf
步骤 3 :上传测试 PDF 文档,作为后续 RAG 的知识来源。
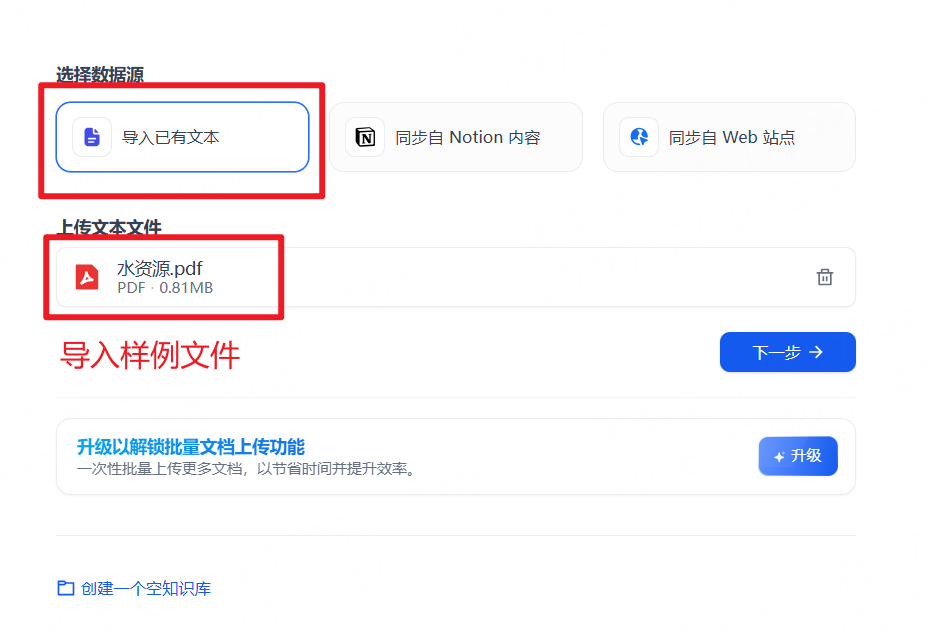
步骤 4 :设置文档解析与切分策略(可先使用默认参数)。

步骤 5 :配置向量化模型、检索参数并启动索引构建。

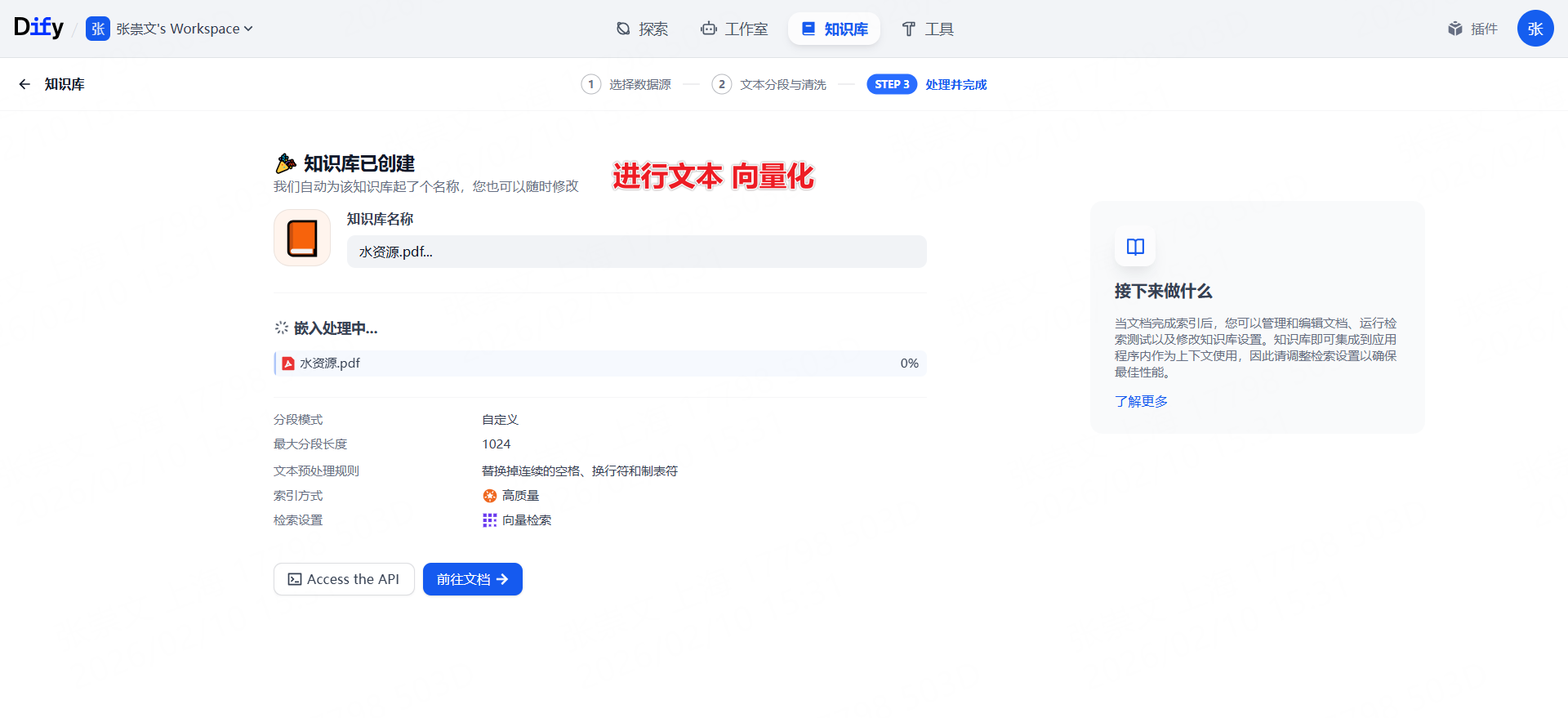
创建RAG聊天助手
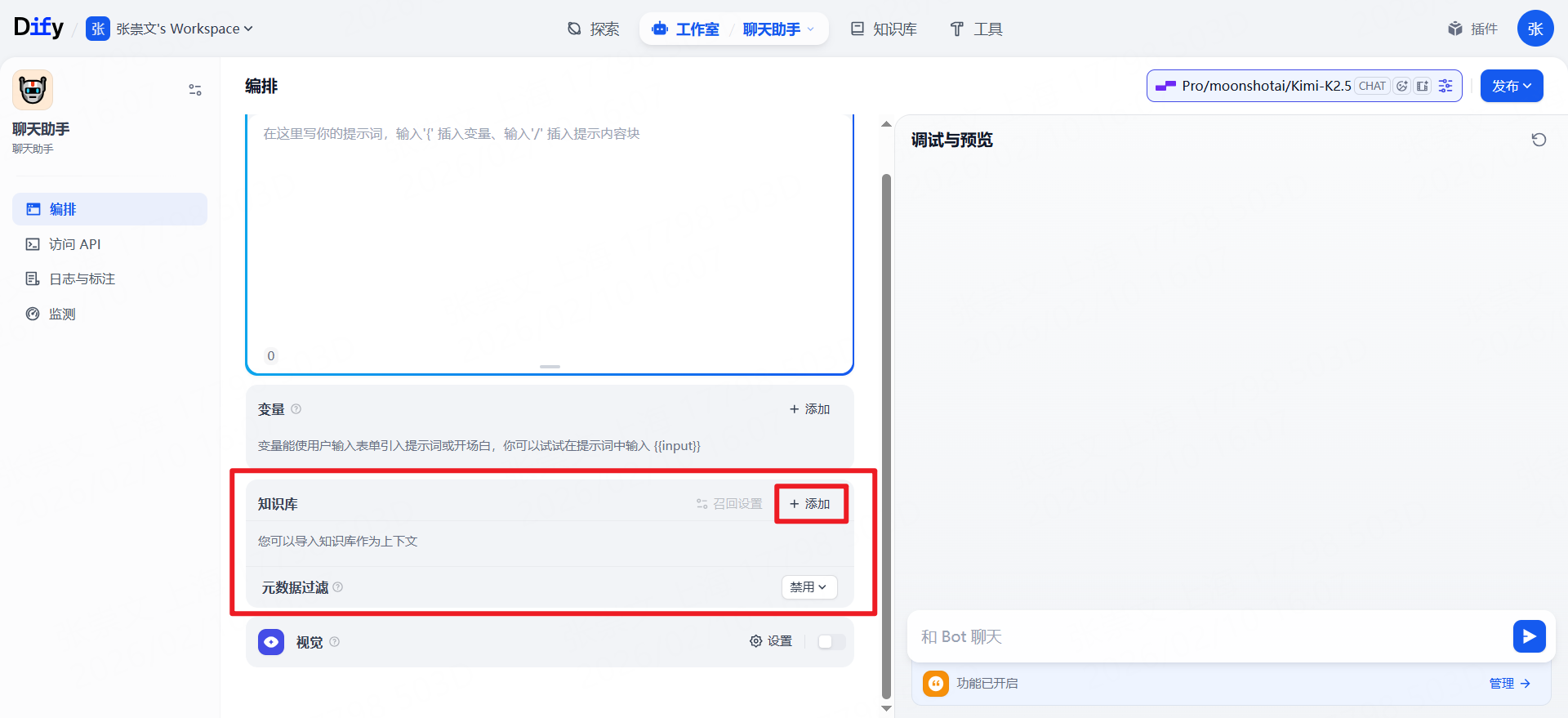
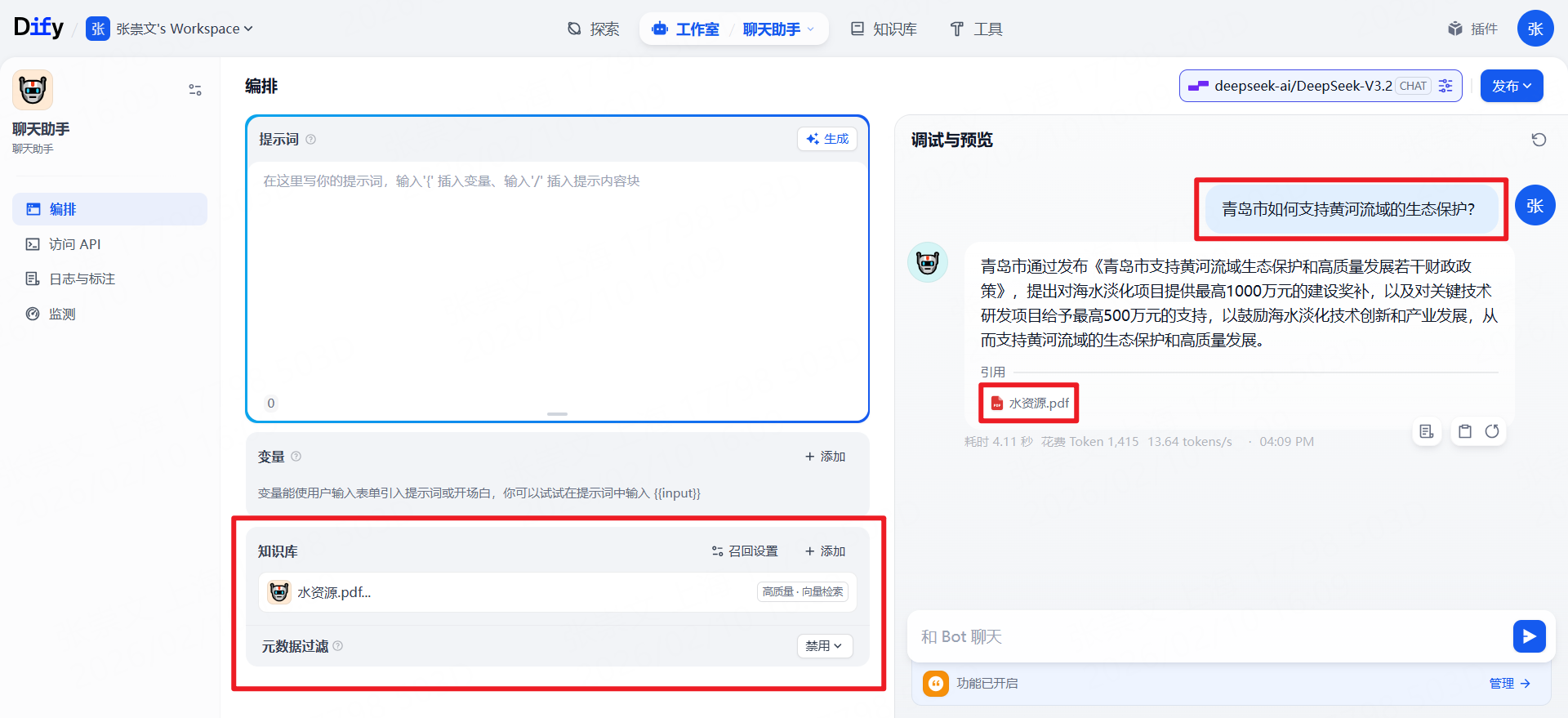
测试效果
原文问题(用于对照回答准确性):

预期结果:回答应基于知识库内容,并尽量给出对应依据。
第四部分:**LlamaIndex + Milvus **实战
测试文件下载地址:https://www.gov.cn/lianbo/bumen/202406/P020240607272121492270.pdf
运行环境说明 :本节示例需在 macOS、Linux 或 Windows + WSL2 环境运行;Milvus Lite 暂不支持原生 Windows。
对输入文档构建向量索引
第一阶段检索
召回候选内容
第二阶段重排
筛出更相关内容
拼接上下文 与 用户问题
组成 Prompt 并生成回答
输出最终答案
依赖安装
bash
pip install requests llama-index-core llama-index-embeddings-openai llama-index-vector-stores-milvus llama-index-llms-openai-like "pymilvus[milvus_lite]" pypdf样例代码
python
#!/usr/bin/env python3
"""
Milvus Lite + LlamaIndex + SiliconFlow(OpenAI 兼容)RAG 示例。
用法:
在代码顶部设置 QUERY / DOC_PATH / TOP_K 等配置后运行:
python rag_milvus_lite_siliconflow.py
"""
import asyncio
import re
from pathlib import Path
from typing import Optional
import requests
from llama_index.core import SimpleDirectoryReader, StorageContext, VectorStoreIndex
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai_like import OpenAILike
from llama_index.vector_stores.milvus import MilvusVectorStore
# =========================
# 基础模型与服务配置(通常不常改)
# =========================
# Milvus Lite 本地数据库文件路径。首次运行会自动创建该文件。
DEFAULT_MILVUS_URI = "./milvus_lite_demo.db"
# 向量集合名称。配合 overwrite=True 使用时,每次运行会重建该集合。
DEFAULT_COLLECTION = "rag_demo"
# 向量化模型:将文本转为向量,供 Milvus 相似度检索。
DEFAULT_EMBED_MODEL = "Qwen/Qwen3-Embedding-0.6B"
# SiliconFlow OpenAI 兼容网关地址。
DEFAULT_BASE_URL = "https://api.siliconflow.cn/v1"
# 最终回答使用的对话模型。
DEFAULT_CHAT_MODEL = "Pro/deepseek-ai/DeepSeek-V3.2"
# 专用重排序模型(与生成模型分离)。
DEFAULT_RERANK_MODEL = "Qwen/Qwen3-Reranker-0.6B"
# 请在此处填写你的 SiliconFlow API Key
SILICONFLOW_API_KEY = "你的_api_key"
# =========================
# 教学样例配置(按需修改)
# =========================
# 教学样例配置:直接修改这里即可运行
# 你要提问的问题(RAG Query)。
QUERY = "如何支持黄河流域的生态保护,有多少资金支持?"
# 本地知识源文件路径(支持 txt/pdf 等被 SimpleDirectoryReader 识别的格式)。
DOC_PATH = Path("./test_doc.pdf")
# Milvus 集合名称(默认沿用上面的 DEFAULT_COLLECTION)。
COLLECTION_NAME = DEFAULT_COLLECTION
# 向量维度。None 表示自动探测模型维度;手动指定可减少一次探测请求。
EMBED_DIM = None
# 第一阶段召回数量:向量检索返回的候选片段数。
TOP_K = 10
# 第二阶段重排数量:rerank 后保留的片段数。
RERANK_TOP_N = 4
def ensure_document(doc_path: Path) -> Path:
"""
确保本地文档存在。
参数:
doc_path (Path):目标文档在本地的保存路径。
返回:
Path:可用的本地文档路径(存在于磁盘中)。
异常:
FileNotFoundError:本地文档不存在时抛出。
"""
if doc_path.exists():
return doc_path
raise FileNotFoundError(f"本地文档不存在:{doc_path}")
def build_index(
doc_path: Path,
milvus_uri: str,
collection_name: str,
embed_model_name: str,
embed_dim: Optional[int],
api_key: str,
api_base: str,
) -> VectorStoreIndex:
"""
构建向量索引并写入 Milvus Lite。
参数:
doc_path (Path):知识源文档路径。
milvus_uri (str):Milvus Lite 数据文件路径。
collection_name (str):Milvus 集合名称。
embed_model_name (str):嵌入模型名称。
embed_dim (Optional[int]):向量维度;若为空则自动推断。
api_key (str):云端嵌入服务的 API Key(OpenAI 兼容)。
api_base (str):云端嵌入服务的基础地址(OpenAI 兼容)。
返回:
VectorStoreIndex:可用于后续检索的 LlamaIndex 向量索引对象。
说明:
当前使用 overwrite=True,每次运行会重建同名集合并重新写入向量。
"""
# Step 1) 读取原始文档,LlamaIndex 会把文档切分成可索引的文本节点。
documents = SimpleDirectoryReader(input_files=[str(doc_path)]).load_data()
# Step 2) 初始化嵌入模型(走 OpenAI 兼容接口,后端由 SiliconFlow 提供服务)。
embed_model = OpenAIEmbedding(
model_name=embed_model_name,
api_key=api_key,
api_base=api_base,
)
# Step 3) 若未指定向量维度,发送一次短文本嵌入请求进行自动探测。
if embed_dim is None:
embed_dim = len(embed_model.get_text_embedding("维度探针"))
# Step 4) 连接/创建 Milvus Lite 集合。overwrite=True 会清空旧集合并重建。
vector_store = MilvusVectorStore(
uri=milvus_uri,
collection_name=collection_name,
dim=embed_dim,
overwrite=True,
)
# Step 5) 把文档节点写入向量库,返回可查询的 VectorStoreIndex。
storage_context = StorageContext.from_defaults(vector_store=vector_store)
return VectorStoreIndex.from_documents(
documents=documents,
storage_context=storage_context,
embed_model=embed_model,
)
def retrieve_nodes(index: VectorStoreIndex, query: str, top_k: int):
"""
根据查询从向量索引中检索相关节点。
参数:
index (VectorStoreIndex):已构建的向量索引。
query (str):用户问题。
top_k (int):返回的相关文本块数量。
返回:
List[NodeWithScore]:检索到的节点列表。
"""
# 向量召回阶段:根据 query embedding 在向量库中检索 TopK 候选片段。
retriever = index.as_retriever(similarity_top_k=top_k)
return retriever.retrieve(query)
def rerank_nodes(query: str, nodes, api_key: str, base_url: str, model: str, top_n: int):
"""
使用云端 rerank 模型对检索结果重新排序。
参数:
query (str):用户问题。
nodes (List[NodeWithScore]):待重排的节点列表。
api_key (str):SiliconFlow API Key。
base_url (str):OpenAI 兼容接口基础地址。
model (str):Rerank 模型名称。
top_n (int):返回前 N 条结果。
返回:
Tuple[List[NodeWithScore], Dict[int, float]]:重排后的节点列表与 rerank 分数。
"""
# 没有候选片段时直接返回空结果,避免无意义请求。
if not nodes:
return [], {}
# rerank 接口需要纯文本列表,这里从节点中提取文本内容。
documents = [node.get_content() for node in nodes]
# 保护 top_n 范围:至少 1,最多不超过候选数量。
top_n = max(1, min(top_n, len(documents)))
# 调用 SiliconFlow 的 /rerank 接口,让专用重排模型基于 query 对 documents 重新排序。
resp = requests.post(
f"{base_url}/rerank",
headers={
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
},
json={
"model": model,
"query": query,
"documents": documents,
"top_n": top_n,
},
timeout=60,
)
# 若 HTTP 状态码非 2xx,直接抛异常,便于在教学时显式看到失败原因。
resp.raise_for_status()
# 典型返回结构里 results 为重排结果列表,每个元素包含 index 与分数。
data = resp.json()
results = data.get("results", [])
# 若重排服务未返回结果,则回退到"向量召回前 top_n 条"。
if not results:
return nodes[:top_n], {}
# ordered: 按重排顺序组织后的节点列表。
ordered = []
# rerank_scores: 记录"原始索引 -> 重排分数",用于后续对比日志。
rerank_scores = {}
for item in results:
# index 指向原始候选列表中的位置。
idx = item.get("index")
if isinstance(idx, int) and 0 <= idx < len(nodes):
ordered.append(nodes[idx])
# 兼容不同字段名:relevance_score / score。
score = item.get("relevance_score", item.get("score"))
if isinstance(score, (int, float)):
rerank_scores[idx] = float(score)
return ordered, rerank_scores
def _node_key(node) -> str:
"""
为节点生成稳定键值,用于跨列表(原始召回 / rerank 结果)对齐同一节点。
"""
raw = getattr(node, "node", node)
# 优先使用节点自带 node_id;无 node_id 时退化为对象 id。
node_id = getattr(raw, "node_id", None)
if node_id is not None:
return str(node_id)
return str(id(node))
def _format_score(value) -> str:
"""
将分数格式化为固定小数位,便于日志阅读。
参数:
value:原始分数值,可能为 None 或非数值。
返回:
str:格式化后的分数字符串;不可用时返回 "-"。
"""
if isinstance(value, (int, float)):
return f"{value:.4f}"
return "-"
def print_retrieval_and_rerank(original_nodes, reranked_nodes, rerank_scores):
"""
输出"向量召回"与"rerank 结果"两段日志,便于教学对比。
参数:
original_nodes (List[NodeWithScore]):原始检索结果。
reranked_nodes (List[NodeWithScore]):rerank 后结果。
rerank_scores (Dict[int, float]):按原始索引保存的 rerank 分数。
"""
# 先把原始召回信息整理成字典,避免后续重复计算预览文本和分数。
orig_info = {}
for i, node in enumerate(original_nodes, start=1):
key = _node_key(node)
# 预览文本:先清理空白再截断,提升日志可读性。
preview_raw = node.get_content()[:60]
preview = re.sub(r"\s+", " ", preview_raw).strip()[:30]
orig_info[key] = {
"orig_rank": i,
"orig_score": getattr(node, "score", None),
"preview": preview,
}
# 第一段日志:展示向量检索 TopK,帮助观察"召回范围"。
print(f"=== 向量召回 Top{len(original_nodes)} ===")
for i, node in enumerate(original_nodes, start=1):
key = _node_key(node)
info = orig_info.get(key, {})
preview = info.get("preview", re.sub(r"\s+", " ", node.get_content()[:60]).strip()[:30])
print(
f"向量排名:{i}; 向量分数:{_format_score(getattr(node, 'score', None))}; "
f"文本预览:{preview}"
)
print("=== 向量召回结束 ===\n")
# 第二段日志:展示 rerank TopN,帮助观察"重排后的保留结果"。
print(f"=== Rerank Top{len(reranked_nodes)} ===")
for j, node in enumerate(reranked_nodes, start=1):
key = _node_key(node)
info = orig_info.get(key, {})
orig_rank = info.get("orig_rank", "-")
orig_score = info.get("orig_score", None)
preview = info.get("preview", re.sub(r"\s+", " ", node.get_content()[:60]).strip()[:30])
# rerank_scores 的 key 是"原始索引(0-based)",所以要 orig_rank - 1。
if isinstance(orig_rank, int):
rerank_score = rerank_scores.get(orig_rank - 1, None)
else:
rerank_score = None
print(
f"重排排名:{j}; 原始排名:{orig_rank}; 原始分数:{_format_score(orig_score)}; "
f"重排分数:{_format_score(rerank_score)}; 文本预览:{preview}"
)
print("=== Rerank 结束 ===\n")
def build_context(nodes) -> str:
"""
将节点内容拼接为上下文文本。
参数:
nodes (List[NodeWithScore]):节点列表。
返回:
str:拼接后的上下文文本。
"""
# 把最终保留的节点按顺序拼接给大模型,顺序即"上下文优先级"。
return "\n\n".join(node.get_content() for node in nodes)
def ask(
api_key: str,
base_url: str,
model: str,
question: str,
context: str,
) -> str:
"""
调用 SiliconFlow 的 OpenAI 兼容接口生成最终回答。
参数:
api_key (str):SiliconFlow API Key。
base_url (str):OpenAI 兼容接口基础地址。
model (str):对话模型名称。
question (str):用户问题。
context (str):检索到的上下文文本。
返回:
str:模型返回的回答文本;若为空则返回空字符串。
"""
# 使用 OpenAILike:适配 OpenAI 兼容网关 + 非官方模型名(如 SiliconFlow 的模型标识)。
llm = OpenAILike(
model=model,
api_key=api_key,
api_base=base_url,
temperature=0.2,
# 对于非 OpenAI 官方模型名,需要显式提供这两个元信息,避免内部模型名校验失败。
context_window=32768,
is_chat_model=True,
)
# 手动拼装提示词:保留"仅基于上下文回答"的约束。
prompt = (
"你是一个严谨的 RAG 助手。\n"
"请仅基于提供的上下文作答。\n"
f"问题:{question}\n\n"
f"上下文:\n{context}\n"
)
print(f"\n======发送给模型的提示词前400字:======\n\n{prompt[:400]}\n\n")
response = llm.complete(prompt)
# LlamaIndex completion 返回对象的文本字段为 text。
return response.text or ""
def main() -> None:
"""
程序入口:串联文档准备、建库检索与生成回答流程。
流程:
1. 检查 API Key。
2. 准备文档(仅支持本地文件)。
3. 构建向量索引并检索上下文。
4. 调用 SiliconFlow 生成并输出答案。
"""
# ===== Stage 0: 基础配置校验 =====
# 从代码常量读取 API Key。
api_key = SILICONFLOW_API_KEY
if not api_key or api_key == "你的_api_key":
raise RuntimeError("请在代码中设置有效的 SILICONFLOW_API_KEY")
# ===== Stage 1: 准备文档与索引 =====
# 确保知识源文档可用。
doc_path = ensure_document(DOC_PATH)
# 构建向量索引(写入 Milvus Lite)。
index = build_index(
doc_path=doc_path,
milvus_uri=DEFAULT_MILVUS_URI,
collection_name=COLLECTION_NAME,
embed_model_name=DEFAULT_EMBED_MODEL,
embed_dim=EMBED_DIM,
api_key=api_key,
api_base=DEFAULT_BASE_URL,
)
# ===== Stage 2: 检索与重排 =====
# 基于用户问题检索上下文并进行 rerank。
nodes = retrieve_nodes(index=index, query=QUERY, top_k=TOP_K)
reranked_nodes, rerank_scores = rerank_nodes(
query=QUERY,
nodes=nodes,
api_key=api_key,
base_url=DEFAULT_BASE_URL,
model=DEFAULT_RERANK_MODEL,
top_n=RERANK_TOP_N,
)
# 输出两段日志:先看向量召回,再看 rerank 结果。
print_retrieval_and_rerank(nodes, reranked_nodes, rerank_scores)
# ===== Stage 3: 组装上下文并生成答案 =====
# 最终上下文只基于 rerank 后结果(通常比纯向量召回更精准)。
context = build_context(reranked_nodes)
# 生成最终答案并输出到标准输出。
answer = ask(
api_key=api_key,
base_url=DEFAULT_BASE_URL,
model=DEFAULT_CHAT_MODEL,
question=QUERY,
context=context,
)
print(f"\n======最终回答:======\n\n{answer}\n\n")
if __name__ == "__main__":
# 这里保留 asyncio 外壳,方便后续演示异步扩展(当前 main 本身为同步流程)。
async def _main_async() -> None:
main()
asyncio.run(_main_async())运行输出(示例)
python
❯ python rag_milvus_lite_siliconflow.py
=== 向量召回 Top10 ===
向量排名:1; 向量分数:0.4383; 文本预览:16 时间 发布主体 文件名称 涉及内容 2023 年 4
向量排名:2; 向量分数:0.4094; 文本预览:12 纳入水资源统一配置体系,对实行两部制电价的海水淡化用
向量排名:3; 向量分数:0.3256; 文本预览:11 六、政策与交流 (一)政策规划 为贯彻落实《国家水网建
向量排名:4; 向量分数:0.3164; 文本预览:13 论坛海洋合作专题论坛在北京举行,主题为"共促蓝色合作
向量排名:5; 向量分数:0.3106; 文本预览:17 时间 发布主体 文件名称 涉及内容 2023 年 5
向量排名:6; 向量分数:0.3020; 文本预览:18 时间 发布主体 文件名称 涉及内容 2023 年 9
向量排名:7; 向量分数:0.3000; 文本预览:6 三、海水直接利用 (一)利用规模 2023 年,沿海电力
向量排名:8; 向量分数:0.2936; 文本预览:14 七、附录 大事纪要 2023 年 2 月 1---4 日,
向量排名:9; 向量分数:0.2751; 文本预览:7 图 5 全国年海水冷却用水量分布图 (三)技术应用 国内
向量排名:10; 向量分数:0.2745; 文本预览:5 2023 年,我国积极推进海水淡化关键装备及材料研发与
=== 向量召回结束 ===
=== Rerank Top4 ===
重排排名:1; 原始排名:2; 原始分数:0.4094; 重排分数:0.9963; 文本预览:12 纳入水资源统一配置体系,对实行两部制电价的海水淡化用
重排排名:2; 原始排名:1; 原始分数:0.4383; 重排分数:0.9938; 文本预览:16 时间 发布主体 文件名称 涉及内容 2023 年 4
重排排名:3; 原始排名:10; 原始分数:0.2745; 重排分数:0.0323; 文本预览:5 2023 年,我国积极推进海水淡化关键装备及材料研发与
重排排名:4; 原始排名:8; 原始分数:0.2936; 重排分数:0.0120; 文本预览:14 七、附录 大事纪要 2023 年 2 月 1---4 日,
=== Rerank 结束 ===
Rerank后上下文前20字:12
纳入水资源统一配置体系,对实行两部
=== 检索到的上下文 ===
12
纳入水资源统一配置体系,对实行两部
=== 上下文结束 ===
2026-02-11 13:14:00,722 - INFO - HTTP Request: POST https://api.siliconflow.cn/v1/chat/completions "HTTP/1.1 200 OK"
根据提供的上下文,关于如何支持黄河流域的生态保护及资金支持,信息如下:
**1. 如何支持:**
上下文指出,通过制定专项财政政策来支持,具体方式是 **鼓励海水淡化项目建设与技术攻关**。这是《青岛市支持黄河流域生态保护和高质量发展若干财政政策》中提出的措施。
**2. 资金支持:**
根据上述政策,资金支持分为两个方面:
* **建设奖补**:对海水淡化项目,根据其产能和综合利用水平,给予 **最高1000万元** 的奖补。
* **研发支持**:对海水淡化及综合利用关键核心技术研发项目,给予 **最高500万元** 的支持。
**结论:**
提供的上下文仅明确了 **青岛市** 通过财政政策,以支持海水淡化产业发展的方式,来服务于黄河流域生态保护和高质量发展。具体的资金支持额度为项目最高1000万元、技术攻关最高500万元。
上下文未提供黄河流域生态保护其他方面(如水土保持、污染防治等)的支持措施或资金情况,也未提及国家层面或流域整体性的资金支持规模。第五部分:Vibe Coding 的流行用法
什么是 Vibe Coding
- 用自然语言描述需求,由 AI 生成代码、测试与文档,人类负责目标、约束和验收。
- 开发者更像建筑师和现场监工,负责"这栋房子要盖成什么结构、哪里承重、先做哪一层";AI 工具像施工队,负责把砖一块块砌起来。你要做的是架构与指挥,AI 负责高频实现,但最终质量和安全仍由人来验收。
一些流行的AI编程工具介绍
Gemini 2.5 和 Gemini 3 都很擅长逻辑判断与事件分析。这个模型的价值在于处理项目中的**"设计"**类工作,往往比 GPT、Claude 更出色。而 Gemini 3 的前端设计能力尤其强,也适合做 UI 设计。
Antigravity 是 Google 推出的 AI-IDE,有免费额度,但门槛较高(主要是容易封号),主要用于生成 HTML 的 UI 原型图。如果没有 Antigravity,用网页版也可以。
Codex 是 OpenAI 的 AI 编程工具(CLI 命令行/插件)。它比 Claude Code 更严谨、更可信,可以把它当成一把精准的外科手术刀,用于代码审核,尤其适合审查其他模型写出的代码。审核的意义在于:我用 AI 越多,越意识到 AI 的不可靠,尤其在复杂逻辑上更明显。所以需要 Codex 根据最初需求与最终代码,检查是否符合业务需求以及代码本身是否存在问题。适合解决疑难 Bug,在大型项目的奠基阶可能不如Claude。
Kiro 是亚马逊推出的 AI-IDE。推荐原因可见:https://mp.weixin.qq.com/s/Js9Pvclobge8dd168zSY4Q。`Kiro` 提出了 Spec 模式,即将一次代码工作拆分为:需求文档 -> 设计文档 -> 任务文档。每个流程都可人工干预。除 Kiro 外,还有两个开源的 Spec 项目,适用于多个 AI 工具(如 Codex、Claude Code 等):1) Spec-kit:适合新项目,从 0 到 1 构建;2) Open-Spec:更轻量,适合旧项目新增功能,我更推荐这个。Kiro 目前仅支持 Claude 模型,且价格性价比很高。
GLM-4.7 / MiniMax M2.1 + Claude Code:GLM-4.7 和 MiniMax M2.1 等模型厂商都有Coding Plan套餐,比如20元一月、30元一月,性价比较高。国内这两个模型的代码能力比较好,Kimi也可以。
Trae: 字节推出的编程IDE,能力一般,但国内网络可用、且容易上手。
总结:
魔法环境 :推荐 Codex 或 Kiro。
国内环境 :推荐 GLM-4.7 / MiniMax M2.1 + Claude Code。
更优协作方式 :使用 Kiro 的 Claude 模型生成代码,使用 Codex 做代码审查和 Bug 分析。