最近需要实现遥感卫星影像中的建筑物识别功能,因此选用了 LoveDA 数据集。在模型选择上,我们同时尝试了 PaddleSeg 和 YOLOv8-Seg。其中,PaddleSeg 能够较好地适配 LoveDA 数据集的格式;然而,YOLOv8-Seg 所要求的标注格式与 LoveDA 原始标注(单通道语义分割掩码)存在较大差异,因此需对数据进行格式转换,以便用于 YOLO 系列模型的训练与评估。
LoveDA数据集介绍
该数据集包含来自南京、常州和武汉的 5,987 张高空间分辨率(0.3 米)遥感影像,覆盖城市与乡村等多样化的地理环境,旨在推动语义分割与域自适应任务的研究。数据集具有以下三大挑战:
- 多尺度目标:地物尺度变化显著,建筑物、道路等目标在不同区域呈现较大尺寸差异;
- 复杂背景干扰:场景中存在大量结构相似或纹理复杂的非目标区域,易造成误判;
- 类别分布不均衡:不同地理区域间各类别(如建筑、水体、植被等)的出现频率存在显著差异。
类别标签定义如下:
- 背景(background)--- 1
- 建筑物(building)--- 2
- 道路(road)--- 3
- 水体(water)--- 4
- 贫瘠地(barren)--- 5
- 森林(forest)--- 6
- 农田(agriculture)--- 7
此外,无有效数据区域(no-data regions)被标记为 0,在训练与评估过程中应予以忽略。
如下图所示,LoveDA数据集的mask标注是单通道8位格式。

任务分析
在本任务中,我们仅关注建筑物(building)和水体(water)两类目标,因此需将其他类别(包括背景、道路、贫瘠地、森林、农田以及无数据区域)全部排除。同时,为适配目标模型的标签体系,需将原始类别标签进行映射:
- 原始类别
2(建筑物) → 新类别0 - 原始类别
4(水体) → 新类别1
其余类别均视为无效或忽略区域,不参与训练与推理。
实现代码如下:
python
import os
import cv2
import numpy as np
from pathlib import Path
def loveda_mask_to_yolo_segmentation(mask_path, output_txt_path, ignore_values=None):
"""
将单通道 mask 转换为 YOLO 分割格式 .txt 文件。
仅处理 class_mapping 中定义的类别,并可选跳过 ignore_values。
"""
if ignore_values is None:
ignore_values = set()
# 定义你要保留并转换的类别:原始像素值 -> YOLO class_id
class_mapping = {2: 0, 4: 1}
mask = cv2.imread(mask_path, cv2.IMREAD_GRAYSCALE)
if mask is None:
raise FileNotFoundError(f"Mask not found: {mask_path}")
h, w = mask.shape
lines = []
# 只遍历你关心的原始类别(2 和 4)
for orig_cls in class_mapping:
# 额外安全检查:如果该类别被显式忽略,则跳过
if orig_cls in ignore_values:
continue
binary = (mask == orig_cls).astype(np.uint8) * 255
contours, _ = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for contour in contours:
if len(contour) < 3:
continue
contour = contour.squeeze(axis=1) # (N, 2)
contour_norm = contour / np.array([w, h])
coords_str = " ".join([f"{x:.6f} {y:.6f}" for x, y in contour_norm])
new_class_id = class_mapping[orig_cls]
lines.append(f"{new_class_id} {coords_str}")
with open(output_txt_path, 'w') as f:
f.write("\n".join(lines))
def batch_loveda_to_yolo(image_dir=None, mask_dir=None, label_output_dir=None, ignore_values=None):
"""
批量将 LoveDA mask 转为 YOLO segmentation 格式
Args:
image_dir (str): 图像文件夹路径(可选,用于验证配对)
mask_dir (str): mask 文件夹路径(必须)
label_output_dir (str): 输出 .txt 标签文件夹
ignore_values (set): 要忽略的像素值,默认 {0, 7}
"""
if mask_dir is None:
raise ValueError("mask_dir 必须提供")
mask_dir = Path(mask_dir)
label_output_dir = Path(label_output_dir) if label_output_dir else mask_dir.parent / "labels"
label_output_dir.mkdir(parents=True, exist_ok=True)
# 支持的图像扩展名(用于 image_dir 配对)
IMG_EXTS = {'.jpg', '.jpeg', '.png', '.tif', '.tiff'}
MASK_EXTS = {'.png'} # LoveDA mask 通常是 PNG
# 获取所有 mask 文件(按 stem 建立索引)
mask_files = {}
for f in mask_dir.iterdir():
if f.suffix.lower() in MASK_EXTS:
mask_files[f.stem] = f
if not mask_files:
print(f"在 {mask_dir} 中未找到任何 mask 文件(支持: {MASK_EXTS})")
return
# 如果提供了 image_dir,只处理有对应图像的 mask
if image_dir:
image_stems = set()
image_dir = Path(image_dir)
for f in image_dir.iterdir():
if f.suffix.lower() in IMG_EXTS:
image_stems.add(f.stem)
# 交集:同时存在于 image 和 mask 中的文件
valid_stems = set(mask_files.keys()) & image_stems
print(f"找到 {len(valid_stems)} 个图像-mask 配对")
else:
valid_stems = set(mask_files.keys())
print(f"未提供 image_dir,将处理所有 {len(valid_stems)} 个 mask 文件")
# 批量转换
success = 0
for stem in sorted(valid_stems):
mask_path = mask_files[stem]
output_txt = label_output_dir / f"{stem}.txt"
try:
loveda_mask_to_yolo_segmentation(
str(mask_path),
str(output_txt),
ignore_values=ignore_values
)
success += 1
except Exception as e:
print(f"处理 {mask_path.name} 时出错: {e}")
print(f"完成!成功生成 {success} 个 YOLO 标签文件,保存至: {label_output_dir}")
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description="批量将 LoveDA mask 转换为 YOLO segmentation 格式")
parser.add_argument("--image_dir", default=r"D:\BaiduNetdiskDownload\yaogan\images",type=str, help="原始图像文件夹(可选,用于配对验证)")
parser.add_argument("--mask_dir", default=r"D:\BaiduNetdiskDownload\yaogan\labels",type=str, help="LoveDA mask 文件夹(PNG)")
parser.add_argument("--output_dir", default=r"D:\BaiduNetdiskDownload\yaogan\txt",type=str, help="YOLO 标签输出文件夹(默认: mask_dir 同级 labels/)")
parser.add_argument("--ignore", type=str, default="0,1,3,5,6,7", help="要忽略的像素值,如 '0,7'")
args = parser.parse_args()
ignore_vals = set(int(x.strip()) for x in args.ignore.split(',') if x.strip())
batch_loveda_to_yolo(
image_dir=args.image_dir,
mask_dir=args.mask_dir,
label_output_dir=args.output_dir,
ignore_values=ignore_vals
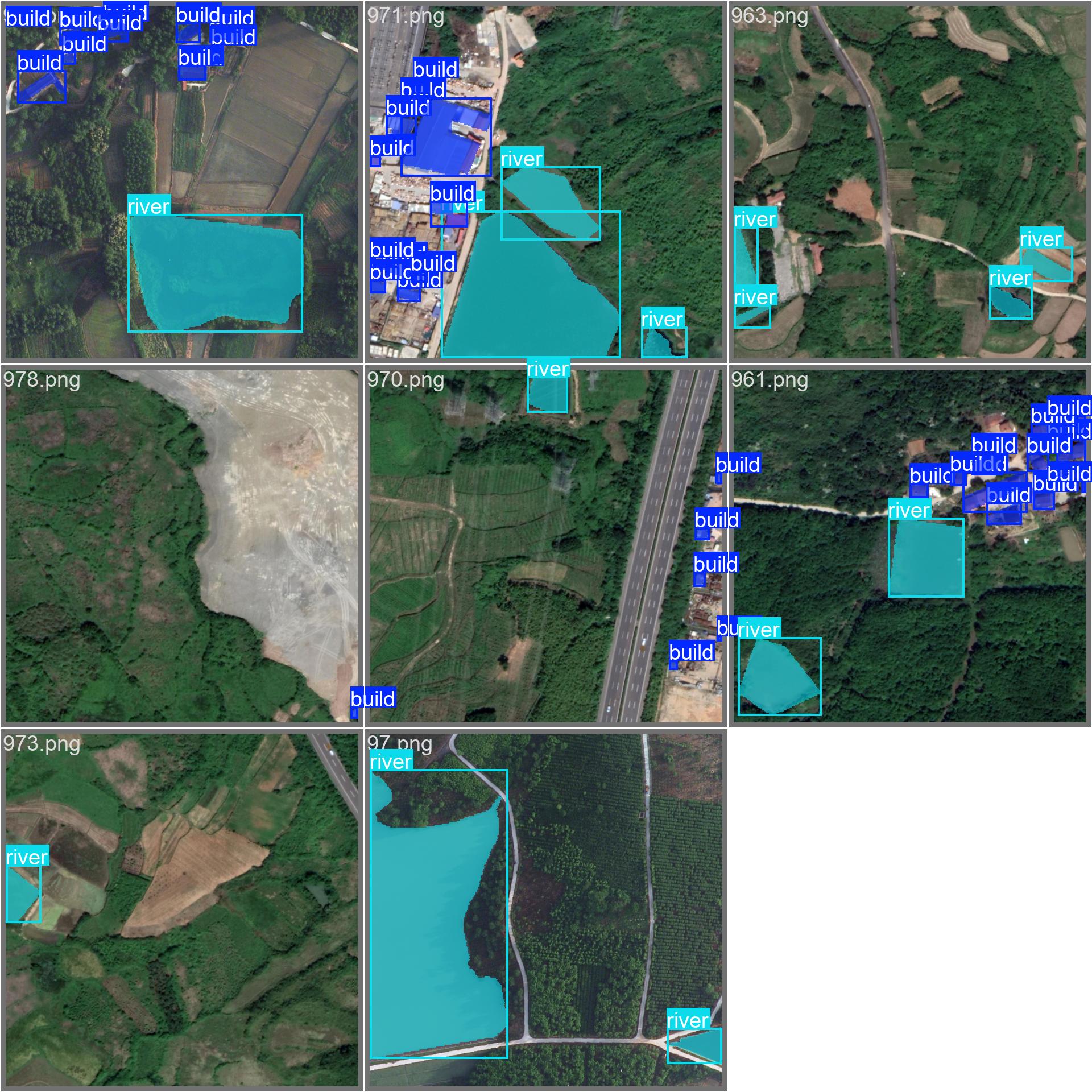
)数据转换后如下:

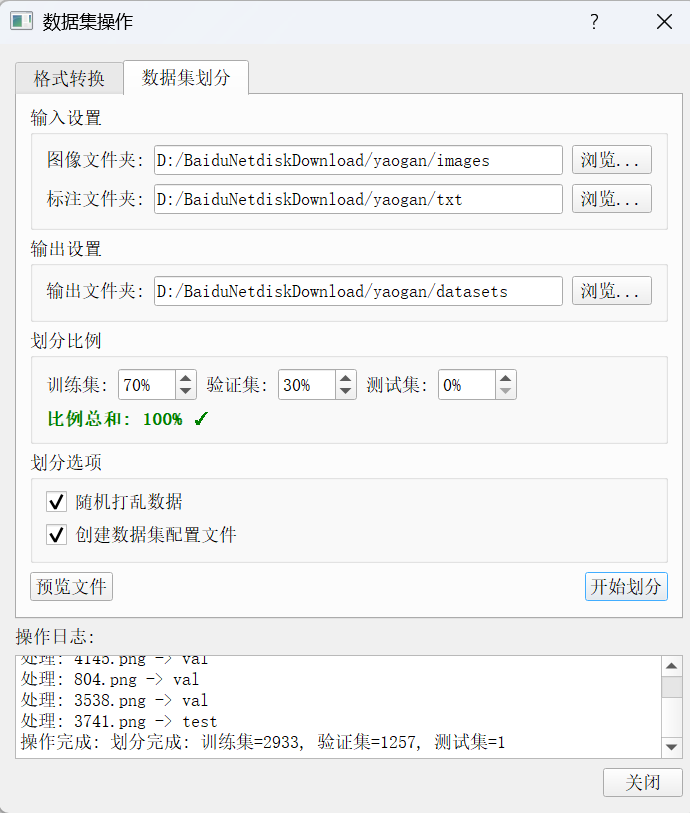
随后,我们使用自己开发的数据集划分工具划分训练集与验证集:
使用ultralytics社区的框架,可以极大的简化训练过程:
python
from ultralytics import YOLO
if __name__ == '__main__':
# Load a model
model = YOLO("yolo26s-seg.yaml") # build a new model from YAML
# Train the model
results = model.train(data="yaogan.yaml", epochs=80, imgsz=960,batch=4)