本推文对2026年人工智能领域的顶会《International Conference on Learning Representations》进行了分析。对已被录用的5000余篇论文进行了深入分析,总结了其研究热点,给出了部分精选论文的标题与研究主题,希望能为相关领域的研究人员提供有价值的参考。
本文作者邓镝,审校韩煦。
一、会议介绍
ICLR(International Conference on Learning Representations)作为机器学习领域顶会,2026年吸引全球近19000篇论文投稿,创历史新高。如图1所示,最终录用率仅28.18%,平均得分5.39,最高分8.5,均为近三年最低水平,反映出投稿竞争加剧与评审标准趋严。会议将于2026年4月23日-27日在巴西举办,议题覆盖大语言模型、扩散生成、强化学习、多模态融合等前沿方向,同时还关注AI安全、垂直领域应用等研究主题。
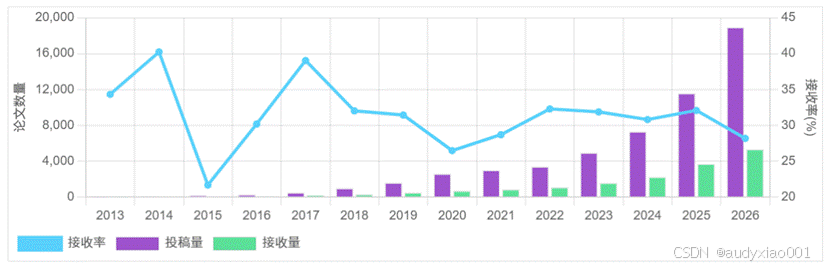
图 1 ICLR论文统计分析
会议官网: https://iclr.cc/Conferences/2026
二、热点分析
本文对2026年该会议所接收的5000余篇论文进行了归纳和热点分析。图2为基于已接收论文的研究热点生成的词云图。表1精选了部分论文,给出了标题及研究内容,旨在为人工智能相关领域的研究人员提供研究参考。

图 2 ICLR 2026录用论文词云图
表 1 ICLR 2026录用论文精选
|--------|-------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------|
| 序号 | 标题 | 研究内容 |
| 1 | A Descriptor-Based Multi-Cluster Memory for Test-Time Adaptation | 该论文提出了一种基于描述符的多簇记忆框架,用于在测试时适应中更有效地捕获目标分布的多样性并实现持续鲁棒性。 |
| 2 | Accelerated Learning with Linear Temporal Logic Using Differentiable Simulation | 该论文提出了一种将线性时序逻辑与可微分模拟器相结合的首个端到端框架,在保证目标正确性的同时,显著加速了复杂连续控制任务中的强化学习训练。 |
| 3 | Achieve Latency-Efficient Temporal-Coding Spiking LLMs via Discretization-Aware Conversion | 该论文提出了一种量化一致的ANN到SNN转换框架,通过将低比特量化与离散时间兼容的TTFS神经元相结合,显著降低了时域编码脉冲大语言模型的推理延迟,同时保持了模型性能。 |
| 4 | Adaptive Test-Time Compute Allocation via Training-Free Difficulty Proxies | 该论文提出了一种无需训练的自适应测试时计算分配框架,在固定总计算预算下动态分配更多计算资源给困难问题实例,从而在数学、编码和问答基准测试中显著提高了解题数量。 |
| 5 | Advancing Equitable AI: A Comprehensive Framework for Individual Fairness Assessment | 该研究提出了四个新的个体公平性评估指标,并与群体公平性指标在多个数据集上进行了实证比较,强调了在现实应用中综合评估个体公平性的必要性。 |
| 6 | AEGIS: Automated Error Generation and Attribution for Multi-Agent Systems | 该研究提出了一个名为AEGIS的自动化框架,用于基于大语言模型的多智能体系统生成大规模、多样化的错误轨迹数据集并进行错误归因,以解决现有数据稀缺和调试困难的问题。 |
| 7 | AGENTRL: Scaling Agentic Reinforcement Learning with a Multi-Turn, Multi-Task Framework | 该研究提出了一个名为AGENTRL的可扩展框架,用于在多轮、多任务场景下训练基于大语言模型的智能体,其通过创新的异步生成-训练流水线、统一API接口以及跨策略采样和任务优势归一化等算法,显著提升了智能体在多个任务上的性能。 |
| 8 | Algorithmic Guarantees for Distilling Supervised and Offline RL Datasets | 该论文提出了一种高效的监督学习和离线强化学习数据集蒸馏算法,无需模型训练即可生成合成数据集,并证明了该算法在理论保证上的紧致性及其实验有效性。 |
| 9 | AlphaSAGE: Structure-Aware Alpha Mining via GFlowNets for Robust Exploration | 该文献提出了一种名为AlphaSAGE的新型框架,通过结合关系图卷积网络、生成流网络和密集多维度奖励结构,以解决现有强化学习方法在自动化挖掘金融预测信号时面临的奖励稀疏、语义表示不足和策略多样性缺乏等核心问题。 |
| 10 | Anatomy of a Hybrid Mind: Deconstructing Hybrid Reasoning in Large Language Models | 该文献对大型语言模型的混合推理机制进行了详细的机理分析,揭示了其快速直觉模式与慢速思考模式如何共存与交互。 |
| 11 | Approximate Multi-Matrix Multiplication for Streaming Power Iteration Clustering | 该文献提出了一种基于近似多矩阵乘法的流式幂迭代聚类方法,用于在随机块模型下高效、可更新地检测大规模图中的最大社区,并提供了单通流式和多通变体算法的理论分析与实验验证。 |
| 12 | ARCMEMO: Abstract Reasoning Composition with Lifelong LLM Memory | 该研究提出了一种为大语言模型设计的抽象概念级记忆框架,通过从推理轨迹中提炼可重用、模块化的自然语言抽象概念并选择性检索,以支持组合推理和测试时持续学习,无需权重更新。 |
| 13 | AtomWorld: A Benchmark for Evaluating Spatial Reasoning in Large Language Models on Crystalline Materials | 该文献提出了AtomWorld基准,用于系统评估大语言模型在晶体材料领域处理CIF文件时的空间推理与结构操作能力,揭示了当前模型在原子级结构理解和编辑任务上的核心局限。 |
| 14 | Attention Is All You Need for KV Cache in Diffusion LLMs | 该研究提出了一种名为Elastic-Cache的训练无关、架构无关策略,用于自适应地决定何时及在何处刷新扩散大语言模型的键值缓存,以减少冗余计算并加速解码,同时保持生成质量。 |
| 15 | Beyond Scattered Acceptance: Fast and Coherent Inference for DLMs via Longest Stable Prefixes | 该论文提出了一种名为最长稳定前缀的训练无关推理调度器,通过识别并原子化提交稳定、对齐的前缀块,解决了扩散语言模型因分散接受策略导致的KV缓存碎片化和重复局部修复问题,从而在保持生成质量的同时显著降低了端到端延迟和去噪调用次数。 |
| 16 | Bi-LoRA: Efficient Sharpness-Aware Minimization for Fine-Tuning Large-Scale Models | 该论文提出了一种名为Bi-LoRA的方法,通过引入一个辅助对抗性LoRA模块,将锐度优化与任务适应解耦,从而在保持LoRA参数高效性的同时,以并行化方式实现了锐度感知最小化,有效提升了大型模型在有限数据下微调的泛化能力并显著降低了计算开销。 |
| 17 | Biasing the Future: Gaussian Attention for Sequential Decision-Making | 该文献提出了一种结合高斯偏置掩码因果注意力机制的改进型决策变换器,用于离线强化学习,以更好地捕捉序列决策任务中的局部依赖和马尔可夫动态,并在基准测试中取得了优于标准决策变换器的性能。 |
| 18 | CapNav: Towards Robust Indoor Navigation with Description-First Maps | 该文献提出了CapNav框架,通过构建以物体实例为中心的3D地图,并利用自然语言描述作为目标选择的主要接口,来实现基于自由形式描述的鲁棒室内导航。 |
| 19 | CLARE: Scalable Class-Incremental Continual Learning via a Sparsity-Based Framework | 该论文提出了一种名为CLARE的基于稀疏性的可扩展类增量持续学习框架,通过识别任务关键参数掩码进行约束微调并结合渐进遗忘机制,以解决长任务序列下的性能下降问题,并在新构建的ImageNet-CIL-1K数据集上取得了最先进的结果。 |
| 20 | CLPO: Curriculum Learning Meets Policy Optimization for LLM Reasoning | 提出了一种名为CLPO的新算法,通过基于模型自身表现实时评估问题难度并构建在线课程,引导模型自适应地重构问题,从而将静态训练转变为与模型能力协同进化的动态过程,以提升大语言模型的推理能力。 |
| 21 | Captain Cinema: Towards Short Movie Generation | 提出Captain Cinema框架,通过自上而下的关键帧规划和自下而上的视频合成,结合交错训练的多模态扩散Transformer,实现基于文本故事线的多场景长叙事短片生成。 |
| 22 | CharacterShot: Controllable and Consistent 4D Character Animation | 提出CharacterShot框架,从单张角色图像和2D姿态序列生成可控且时空一致的4D角色动画,通过预训练2D动画模型、双注意力模块提升至多视角视频,并采用邻域约束4D高斯溅射优化得到4D表征。 |
| 23 | Circuits, Features, and Heuristics in Molecular Transformers | 该文献对自回归分子Transformer进行了机制分析,揭示了其在分子生成过程中维持语法和化学有效性的计算结构与特征,并验证了稀疏自编码器提取的化学相关特征在下游任务中的实用性。 |
| 24 | Clustering by Denoising: Latent Plug-and-Play Diffusion for Single-Cell Data | 该论文提出了一种用于单细胞RNA测序数据的潜在空间即插即用扩散框架,通过分离观测空间与去噪空间并引入输入空间引导的吉布斯采样,以处理噪声并提升细胞聚类的准确性和生物学一致性。 |
| 25 | Compressed Map Priors for 3D Perception | 该研究提出了一种名为压缩地图先验的框架,通过从历史遍历数据中学习空间先验,并以极低存储开销的量化哈希图形式集成到现有3D感知系统中,从而显著提升3D目标检测性能。 |
| 26 | Conformal Prediction with Corrupted Labels: Uncertain Imputation and Robust Re-weighting | 该论文提出了一种在训练数据标签存在噪声或缺失的损坏情况下进行鲁棒不确定性量化的框架,通过分析特权共形预测对权重估计误差的鲁棒性,并引入一种不依赖权重估计、通过不确定性插值处理损坏标签的新方法,最终整合成一个三重鲁棒框架以确保预测的有效性。 |
| 27 | CycleIE: Robust Document Information Extraction Through Iterative Verification and Refinement | 提出了一种名为CycleIE的迭代式信息抽取框架,该框架通过结合ReAct与蒙特卡洛树搜索,以多智能体工作流实现检索、结构化、抽取和验证的循环,旨在解决单次抽取方法在处理长文档或多文档时的不完整和不一致问题,从而提升结构化数据抽取的质量。 |
| 28 | Dancing in Chains: Strategic Persuasion in Academic Rebuttal via Theory of Mind | 该研究提出了首个基于心智理论的学术反驳框架RebuttalAgent,通过建模审稿人心理状态、制定说服策略并生成针对性回应,以解决信息不对称下的学术反驳难题。 |
| 29 | Data Diversity for Compositional Generalization | 该论文通过理论分析和实证验证,探讨了数据多样性的多面性及其对模型组合泛化能力的影响,提出了构建训练数据集以促进高效学习和更好泛化的指导原则。 |
| 30 | Debugging Concept Bottleneck Models Through Removal and Retraining | 该论文提出了一种用于调试概念瓶颈模型的可解释框架,通过"移除"和"重训练"两步流程,利用专家反馈识别并减少模型对不良概念的依赖,以解决模型与专家推理之间的系统性错位问题。 |
| 31 | Deep Reflection Hinting: Leveraging Offline Knowledge for Improving Web Agents Adaptation | 提出Deep Reflection Hinter系统,通过从离线轨迹中提取紧凑、上下文感知的提示来提升LLM智能体在陌生领域的适应能力,无需在线交互或微调。 |
| 32 | DiTraj: Training-Free Trajectory Control for Video Diffusion Transformer | 提出一种无需训练的框架DiTraj,通过前景-背景分离引导和时空解耦3D旋转位置编码,实现对基于扩散Transformer的视频生成模型进行轨迹控制。 |
| 33 | Does the Data Processing Inequality Reflect Practice? On the Utility of Low-Level Tasks | 该文献通过理论和实证研究,探讨了在有限训练样本下,先进行低层任务处理再执行分类,为何可能违反数据处理不等式而提升分类性能。 |
| 34 | DyGB: Dynamic Gradient Boosting Decision Trees with In-Place Updates for Efficient Data Addition and Deletion | 该论文提出了一种名为DyGB的动态梯度提升决策树框架,通过优化实现了对数据高效增删的增量与减量学习。 |
| 35 | Dynamic Multi-Sample Mixup with Gradient Exploration for Open-Set Graph Anomaly Detection | 该论文提出了一种名为DEMO的新方法,通过动态多样本混合与梯度探索来解决开放集图异常检测问题,旨在利用少量已知正常和异常节点训练的图神经网络来检测推理过程中未见过的异常。 |
| 36 | E3-Pruner: Towards Efficient, Economical, and Effective Layer Pruning for Large Language Models | 该论文提出了一种名为E3-PRUNER的层剪枝框架,通过可微分掩码优化和熵感知自适应知识蒸馏策略,旨在同时解决大语言模型剪枝中的性能下降、高训练成本和有限加速等挑战。 |
| 37 | EllipWeather: Gaussian Ellipsoid Representation for Weather Modeling | 提出一种名为EllipWeather的新方法,利用高斯椭球体表示天气模式,并开发等变图神经网络进行天气预报,以解决传统像素表示的数据冗余和连续动态捕捉不足的问题。 |
| 38 | Emergence of Machine Language in LLM-Based Agent Communication | 本研究探讨了基于大语言模型的智能体能否通过互动自发形成一种人类不可解读的机器语言,并验证了该涌现语言具有组合性、泛化性等人类语言的关键特征。 |
| 39 | Emergent Global OOD Performance in Multi-Modal Mammography Models | 研究发现,在单一架构内仅增加参数规模,无需额外图像数据,即可使基于CLIP训练的多模态乳腺X光模型在多个国际数据集上表现出对分布外数据的涌现鲁棒性。 |
| 40 | Estimation and Clustering in Finite Mixture Models: Bayesian Optimization as an Alternative to EM | 该研究提出使用贝叶斯优化框架作为期望最大化算法的替代方案,用于计算一般椭圆分布混合模型的最大似然估计,并提供了其渐近全局收敛性保证及聚类误差率收敛至最优分类错误率的理论证明。 |
| 41 | Evolution-Aware Positive-Unlabeled Learning for Protein Design | 该研究提出了一种名为Evo-PU的进化感知正例-无标记学习框架,通过引入序列依赖的类别先验来改进蛋白质功能预测和设计,并在流感血凝素蛋白等真实任务中验证了其优于现有方法的性能。 |
| 42 | Explain in Your Own Words: Improving Reasoning via Token-Selective Dual Knowledge Distillation | 该文献提出了一种名为TSD-KD的Token选择性双重知识蒸馏框架,通过结合间接反馈和选择性直接蒸馏,使能力有限的学生模型能够专注于推理关键Token并以自己的话语进行解释,从而在复杂推理任务上实现高效的知识迁移和性能提升。 |
| 43 | Extremum Seeking with Surrogate Gradients: Scalable Derivative-Free Optimization for High-Dimensional Black-Box Functions | 该文献提出了一种结合极值搜索与代理梯度的混合框架,通过高斯过程代理模型预测局部梯度并利用极值搜索进行扰动探索,以实现高维黑盒函数的高效、低开销的无导数优化。 |
| 44 | FAKER: Generating Frequency-based Artificial Attributes via Random Walks for Non-attributed Graph Representation Learning | 该研究提出了一种名为FAKER的模型无关框架,通过分析随机游走的频域偏差并自适应采样,从纯拓扑结构合成人工节点属性,以解决无属性图表示学习中随机游走采样偏差导致嵌入失真的问题,从而提升图神经网络的性能。 |
| 45 | A Descriptor-Based Multi-Cluster Memory for Test-Time Adaptation | 该论文提出了一种基于描述符的多簇记忆框架,用于在测试时适应中更有效地捕获目标分布的多样性并实现持续鲁棒性。 |
本文还对已接收的论文中出现的高频关键词(前10名)进行归类整理和统计,结果如表2所示。
表 2 ICLR 2026录用论文的标题高频词
|-----------------------------------------|----------|
| 高频词 | 出现次数 |
| LLM (Large Language Model ) | 1115 |
| Learning | 648 |
| Diffusion | 381 |
| Generation | 332 |
| Agent | 313 |
| Reinforcement Learning | 249 |
| Optimization | 241 |
| Benchmark | 238 |
| Image | 219 |
| Video | 217 |
三、总结
根据对ICLR 2026论文标题和高频词汇的分析,本届会议热点包括大模型与生成模型、多模态理解、强化学习等方向。例如,小米团队的入选论文涵盖了多模态推理、强化学习、自动驾驶、音频生成等领域,说明大型语言模型、扩散式生成模型和视觉-语言模型等仍是研究热点。同时,多智能体和RL算法、图神经网络及知识图谱学习也备受关注。
在方法上,ICLR 2026中的一些研究集中在模型的高效性与鲁棒性上。很多工作聚焦模型压缩(如量化、剪枝、蒸馏)、稀疏与高效架构设计,以及测试时的优化技术以提升模型性能。此外,自监督学习、偏好学习和人类反馈对齐等也具有一定热度,以增强模型的泛化性。有关对抗训练与不确定性估计等研究继续强化AI系统的安全性和稳定性。
在应用场景方面,医疗、自动驾驶、图数据和时间序列等领域研究同样活跃。例如,医学影像分析与药物发现利用深度学习提高诊断与新药筛选效率;自动驾驶系统结合视觉与时序学习优化模型感知与决策;图神经网络被广泛用于生物网络与社交网络分析;还有针对代码生成、商业预测、用户推荐等实际问题的专项研究。
总体来看,ICLR 2026充分体现了大模型与多模态技术的发展趋势,同时兼顾了高效计算、鲁棒安全性以及跨领域应用的研究热点。