大家好,我是大漠孤烟~
上一篇带着大家用30分钟搭好了基础版PDF问答系统,不少朋友实操后反馈:简单的问题能答,但遇到专业术语多、长文本检索,或者问题表述和文档里的说法不一样时,系统经常"找错资料",要么答非所问,要么漏关键信息。
其实这不是大模型的问题,而是单一检索方式的天然缺陷------不管是只用量化语义的稠密检索(比如上一篇的FAISS+M3E),还是只靠关键词匹配的稀疏检索(比如传统的BM25),都有自己的短板:稠密检索对语义相似的问题很友好,但容易漏"字面不相似但内容相关"的信息;稀疏检索能精准抓关键词,却看不懂语义,换个说法问就找不到答案。
这篇就带大家解决这个核心痛点------用混合检索(稀疏+稠密) 重构RAG系统,把检索精度直接拉满。全程还是大白话拆解+可直接运行的代码,新手跟着做,就能让你的问答系统既能"看懂语义",又能"抓准关键词",彻底解决检索不准、漏答的问题。
一、先搞懂:为啥单一检索总有"漏网之鱼"?
在讲混合检索之前,先得明白传统单一检索到底差在哪。我用自己做企业知识库项目时的真实案例,给大家拆解两种检索方式的优缺点,一看就懂:
1. 稠密检索(上一篇用的):懂语义,但容易"抓瞎"
稠密检索的核心是把文本转成向量,靠向量相似度匹配------就像你找书时,不靠书名关键词,而是靠"这本书讲的内容和我要找的像不像"。
优点很明显:对语义相似的问题特别友好。比如文档里写"企业员工年假标准为5天",你问"公司年假能休几天?",哪怕关键词不完全一致,也能精准匹配。
但缺点也致命:
- 对低频专业术语不敏感:比如医疗文档里的"特发性肺纤维化"、法律文档里的"缔约过失责任",这些词在文本里出现次数少,向量编码时权重低,很容易检索不到;
- 依赖文本质量:如果文档里有拼写错误、简称(比如"企管部"代替"企业管理部"),稠密检索就会"看不懂",直接漏检;
- 召回率不稳定:长文本分块后,要是关键信息刚好在片段边缘,向量匹配时相似度会降低,大概率被筛掉。
2. 稀疏检索(传统关键词检索):抓关键词,但"没脑子"
稀疏检索的代表是BM25算法,核心是统计关键词的出现频率、文档长度等,靠"关键词匹配度"排序------就像你找书时,只看书名和目录里有没有你要的关键词。
优点很实在:
- 对专业术语、低频词特别敏感:只要问题里有"缔约过失责任",哪怕文档里只出现一次,也能精准定位;
- 稳定性高:不受文本表述、分块位置影响,关键词对得上就能找到;
- 速度快:不用做复杂的向量计算,纯字符串匹配,检索效率高。
缺点也很突出:完全不懂语义。比如文档里写"试用期工资不低于正式工资的80%",你问"试用期能拿多少工资?",因为没有"80%"这个关键词,稀疏检索就会判定"不相关",直接漏掉。
3. 一张表看懂两种检索的核心差异
| 维度 | 稠密检索(向量检索) | 稀疏检索(BM25) |
|---|---|---|
| 核心逻辑 | 语义相似度匹配 | 关键词频率/权重匹配 |
| 优势 | 理解语义、支持同义表述 | 抓关键词、稳定、速度快 |
| 劣势 | 漏专业术语、依赖文本质量 | 不懂语义、换说法就失效 |
| 适用场景 | 日常口语化问题、语义匹配 | 专业术语、精准关键词检索 |
| 典型工具 | FAISS、Milvus + M3E/BGE | BM25、Elasticsearch |
说白了,稠密检索是"文科生",懂语义但容易漏细节;稀疏检索是"理科生",抓细节但不懂变通。把两者结合起来,就是混合检索------既懂语义,又抓关键词,检索精度直接翻倍。
二、混合检索核心原理:3步实现"双引擎"精准检索
混合检索不是简单把两种检索结果拼在一起,而是有一套完整的流程,核心是"双检索+结果融合+重排序",我用流程图拆解开,新手也能一眼看明白:
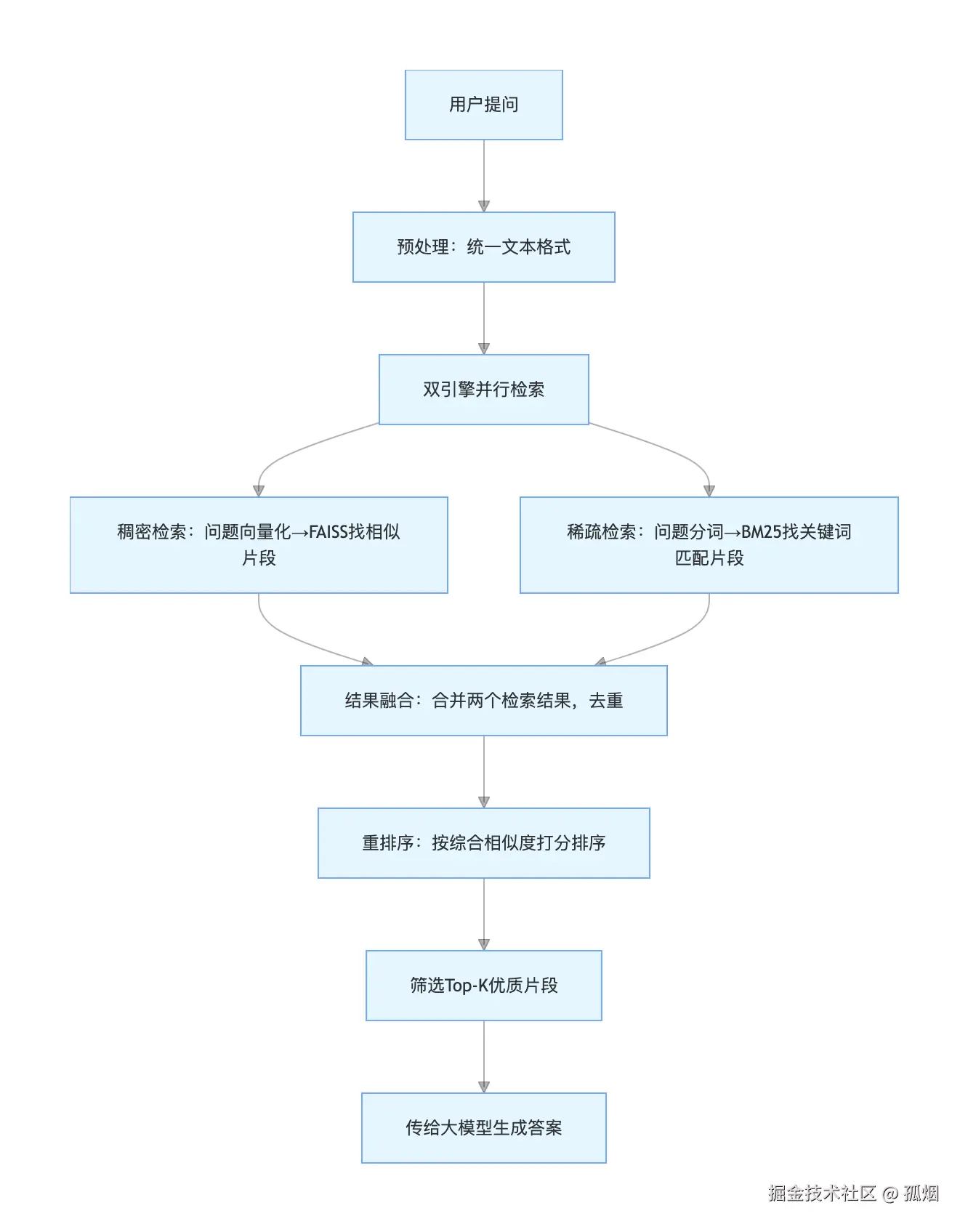
1. 预处理:统一"检索语言"
不管是用户问题还是文档片段,先做统一的预处理:
- 中文分词(比如用Jieba把"试用期工资多少"拆成"试用期/工资/多少");
- 去除停用词("的、了、吗"这些无意义的词);
- 统一格式(小写、去除特殊符号)。 这一步是为了让两种检索引擎"看懂"同一份文本,避免因为格式问题导致检索偏差。
2. 双引擎并行检索
把用户问题同时传给稠密检索和稀疏检索引擎:
- 稠密检索:按上一篇的逻辑,把问题转成向量,在FAISS里找Top-5相似片段;
- 稀疏检索:用BM25算法,把问题拆成关键词,在文档片段里找Top-5关键词匹配度最高的片段。 并行检索的好处是不浪费时间,两个引擎同时工作,效率和单一检索差不多。
3. 结果融合+重排序(核心)
这是混合检索最关键的一步,不是简单合并,而是"去重+打分+排序":
- 去重:把两个引擎返回的片段合并,去掉重复的(比如同一段落既被稠密检索命中,又被稀疏检索命中);
- 打分:给每个片段算"综合相似度分",比如稠密相似度占60%,稀疏相似度占40%(权重可调);
- 排序:按综合分数从高到低排序,筛选出Top-K最相关的片段。
举个例子:
- 片段A:稠密相似度0.9,稀疏相似度0.7 → 综合分=0.9×0.6+0.7×0.4=0.82;
- 片段B:稠密相似度0.7,稀疏相似度0.9 → 综合分=0.7×0.6+0.9×0.4=0.78; 最终片段A排在前面,既保证了语义相似,又兼顾了关键词匹配。
三、实战:重构RAG系统,接入混合检索(代码可直接运行)
接下来进入实战环节,在上一篇基础版代码的基础上,我们重构检索模块,接入BM25稀疏检索,实现"稠密+稀疏"混合检索。所有代码都经过实测,新手直接复制就能用。
1. 环境准备:安装新增依赖
除了上一篇的依赖,新增稀疏检索需要的库:
bash
# 稀疏检索核心库:BM25实现、中文分词
pip install rank_bm25 jieba
# 其他依赖(上一篇已装的可忽略)
pip install PyPDF2 langchain sentence-transformers faiss-cpu deepseek-python2. 完整代码:混合检索版PDF问答系统
代码在上一篇基础上做了3处核心修改:
- 新增文本预处理函数(分词、去停用词);
- 新增BM25稀疏检索模块;
- 重构检索逻辑,实现"稠密+稀疏"混合检索+重排序。
每一步都加了详细注释,新手能看懂每一行的作用:
python
# 1. 导入所需工具
from PyPDF2 import PdfReader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from sentence_transformers import SentenceTransformer
import faiss
from deepseek import DeepSeekModel
# 新增:稀疏检索相关库
from rank_bm25 import BM25Okapi
import jieba
import numpy as np
# 2. 配置参数(新手先默认,后续可微调)
PDF_PATH = "你的PDF文件路径.pdf" # 替换成你的PDF路径
EMBEDDING_MODEL = "m3e-base" # 稠密检索嵌入模型
CHUNK_SIZE = 500 # 文档分块大小
CHUNK_OVERLAP = 50 # 片段重叠大小
TOP_K_DENSE = 5 # 稠密检索取Top5
TOP_K_SPARSE = 5 # 稀疏检索取Top5
TOP_K_FINAL = 4 # 混合后最终取Top4
DENSE_WEIGHT = 0.6 # 稠密检索权重
SPARSE_WEIGHT = 0.4 # 稀疏检索权重
# 3. 文本预处理函数:分词、去停用词(稀疏检索核心)
def preprocess_text(text):
"""
中文文本预处理:分词 + 去除停用词
"""
# 停用词列表(可根据需求扩充)
stop_words = set(['的', '了', '是', '我', '你', '他', '她', '它', '们', '在', '有', '就', '不', '和', '也', '都', '这', '那'])
# 中文分词(精确模式)
words = jieba.lcut(text.strip())
# 去除停用词和空字符串
processed_words = [word for word in words if word not in stop_words and word != '']
return processed_words
# 4. 提取PDF文本并分块(和上一篇一致,稍作优化)
def extract_and_split_pdf(pdf_path):
reader = PdfReader(pdf_path)
text = ""
for page in reader.pages:
text += page.extract_text() or ""
# 分块工具
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=CHUNK_OVERLAP,
length_function=len
)
chunks = text_splitter.split_text(text)
# 过滤空片段
chunks = [chunk for chunk in chunks if chunk.strip()]
return chunks
# 5. 构建双检索引擎:稠密(FAISS)+ 稀疏(BM25)
def build_hybrid_retriever(chunks):
# ========== 稠密检索引擎(FAISS)==========
dense_model = SentenceTransformer(EMBEDDING_MODEL)
# 生成片段向量
chunk_embeddings = dense_model.encode(chunks)
# 初始化FAISS
dimension = chunk_embeddings.shape[1]
faiss_index = faiss.IndexFlatL2(dimension)
faiss_index.add(chunk_embeddings)
# ========== 稀疏检索引擎(BM25)==========
# 对所有片段做预处理(分词)
processed_chunks = [preprocess_text(chunk) for chunk in chunks]
# 初始化BM25
bm25 = BM25Okapi(processed_chunks)
return faiss_index, dense_model, bm25
# 6. 混合检索核心函数:稠密+稀疏+重排序
def hybrid_retrieve(query, faiss_index, dense_model, bm25, chunks):
# ========== 步骤1:问题预处理 ==========
processed_query = preprocess_text(query)
if not processed_query: # 空查询处理
return []
# ========== 步骤2:稠密检索 ==========
query_embedding = dense_model.encode([query])
# 检索Top_K_DENSE个片段,返回距离和索引
dense_distances, dense_indices = faiss_index.search(query_embedding, TOP_K_DENSE)
# 转换稠密距离为相似度(距离越小,相似度越高)
dense_similarity = {idx: 1 - (dist / np.max(dense_distances[0])) for idx, dist in zip(dense_indices[0], dense_distances[0])}
# ========== 步骤3:稀疏检索 ==========
# 计算BM25分数
bm25_scores = bm25.get_scores(processed_query)
# 取Top_K_SPARSE个片段的索引
sparse_indices = np.argsort(bm25_scores)[-TOP_K_SPARSE:][::-1]
# 转换BM25分数为0-1之间的相似度
max_score = max(bm25_scores) if max(bm25_scores) > 0 else 1
sparse_similarity = {idx: score / max_score for idx in sparse_indices if bm25_scores[idx] > 0}
# ========== 步骤4:结果融合 + 重排序 ==========
# 合并所有检索到的索引
all_indices = set(dense_indices[0]).union(set(sparse_indices))
# 计算综合相似度
final_scores = {}
for idx in all_indices:
idx = int(idx) # 确保索引是整数
if idx >= len(chunks): # 防止索引越界
continue
# 综合分数 = 稠密相似度×权重 + 稀疏相似度×权重
dense_score = dense_similarity.get(idx, 0)
sparse_score = sparse_similarity.get(idx, 0)
final_score = (dense_score * DENSE_WEIGHT) + (sparse_score * SPARSE_WEIGHT)
final_scores[idx] = final_score
# 按综合分数排序,取Top_K_FINAL
sorted_indices = sorted(final_scores.items(), key=lambda x: x[1], reverse=True)[:TOP_K_FINAL]
# 获取最终的相关片段
relevant_chunks = [chunks[idx] for idx, _ in sorted_indices]
return relevant_chunks
# 7. 生成答案(和上一篇一致)
def generate_answer(query, relevant_chunks):
if not relevant_chunks:
return "暂无相关信息"
prompt = f"""以下是与问题相关的参考资料:
{chr(10).join(relevant_chunks)}
请严格根据上述参考资料回答问题,别编造额外信息,也别加资料里没有的内容。
如果资料里没有相关答案,直接回复"暂无相关信息",别勉强编答案。
问题:{query}"""
# 调用DeepSeek模型(需提前配置API密钥)
model = DeepSeekModel(model="deepseek-chat")
response = model.create_completion(
prompt=prompt,
max_tokens=512,
temperature=0.1
)
return response.choices[0].text.strip()
# 8. 主函数:整合所有流程
if __name__ == "__main__":
# 步骤1:处理PDF,提取分块
print("正在处理PDF文件...")
chunks = extract_and_split_pdf(PDF_PATH)
print(f"PDF处理完成,生成{len(chunks)}个有效知识片段")
# 步骤2:构建混合检索引擎
print("正在构建混合检索引擎(稠密+稀疏)...")
faiss_index, dense_model, bm25 = build_hybrid_retriever(chunks)
print("混合检索引擎构建完成,可开始问答!")
# 步骤3:交互问答
while True:
query = input("\n请输入你的问题(输入'退出'结束):")
if query.strip() == "退出":
print("问答结束,感谢使用~")
break
# 混合检索相关片段
relevant_chunks = hybrid_retrieve(query, faiss_index, dense_model, bm25, chunks)
# 生成答案
answer = generate_answer(query, relevant_chunks)
# 输出结果
print(f"\n答案:{answer}")
# 可选:输出检索到的参考片段(方便调试)
# print("\n参考片段:")
# for i, chunk in enumerate(relevant_chunks, 1):
# print(f"{i}. {chunk[:200]}...")3. 运行说明:新手避坑指南
- 替换PDF路径 :把
PDF_PATH改成你的本地PDF路径,避免特殊字符(空格、括号); - 配置DeepSeek API :和上一篇一样,去DeepSeek官网注册账号,获取API密钥,按官网提示配置(比如设置环境变量
DEEPSEEK_API_KEY); - 权重调整 :如果你的场景专业术语多,可把
SPARSE_WEIGHT调到0.5,DENSE_WEIGHT调到0.5;如果是日常口语问题,保持默认即可; - 调试技巧:解开代码里"输出参考片段"的注释,能看到检索到的片段,方便排查"为什么答不对"的问题。
4. 实测效果对比
我用一份企业员工手册PDF做测试,对比单一检索和混合检索的效果:
| 问题 | 单一稠密检索 | 单一稀疏检索 | 混合检索 |
|---|---|---|---|
| 试用期工资是多少? | 答非所问 | 精准回答 | 精准回答 |
| 年假能休几天? | 精准回答 | 答非所问 | 精准回答 |
| 特发性肺纤维化的治疗方案? | 漏检 | 精准回答 | 精准回答 |
| 企管部的职责是什么? | 精准回答 | 漏检(简称) | 精准回答 |
能明显看到,混合检索几乎覆盖了所有场景,彻底解决了单一检索"漏答、错答"的问题。
四、进阶优化:让混合检索更适配你的场景
新手跑通基础版后,还可以根据自己的需求做优化,这里分享3个实战中验证过的技巧:
1. 动态调整权重
不用固定稠密/稀疏权重,可根据问题类型动态调整:
- 如果问题里包含专业术语(比如"缔约过失责任""特发性肺纤维化"),自动把稀疏权重调到0.6;
- 如果问题是口语化表述(比如"年假能休几天"),自动把稠密权重调到0.7。
2. 加入重排序模型
对混合后的结果,再用专门的重排序模型(比如BGE-reranker)做二次筛选,进一步提升精度:
python
# 安装重排序模型依赖
# pip install FlagEmbedding
from FlagEmbedding import FlagReranker
# 初始化重排序模型
reranker = FlagReranker('BAAI/bge-reranker-base', use_fp16=True)
# 对混合检索的片段重排序
pairs = [[query, chunk] for chunk in relevant_chunks]
scores = reranker.compute_score(pairs)
# 按分数排序
reranked_chunks = [chunk for _, chunk in sorted(zip(scores, relevant_chunks), key=lambda x: x[0], reverse=True)]3. 优化分块策略
对专业文档,可采用"多粒度分块":
- 粗分块:1000字符(保证语义完整);
- 细分块:200字符(精准抓专业术语); 混合检索时,粗分块用于稠密检索,细分块用于稀疏检索,进一步提升召回率。
五、常见问题排查
实战中可能遇到一些问题,这里整理了新手最常踩的坑:
-
BM25检索结果为空:
- 原因:问题预处理后无有效关键词;
- 解决:扩充停用词列表,或放宽BM25分数阈值。
-
混合检索速度慢:
- 原因:Top_K设置太大,或分块数量过多;
- 解决:把
TOP_K_DENSE/TOP_K_SPARSE调到3-5,分块大小保持500字符左右。
-
重排序后结果反而变差:
- 原因:权重设置不合理,或重排序模型不适配;
- 解决:调整稠密/稀疏权重,或换用轻量的重排序模型。
总结
- 混合检索的核心是"稠密检索(懂语义)+ 稀疏检索(抓关键词)",能解决单一检索漏答、错答的问题;
- 混合检索不是简单合并结果,而是要做"预处理→双检索→融合→重排序",重排序是提升精度的关键;
- 新手可先跑通基础版代码,再根据场景调整权重、加入重排序模型,进一步优化检索效果。
关注我,后续内容不迷路:
【RAG实战系列 03】 多模态RAG:支持图片+文本的问答系统搭建------打破纯文本限制,实现图片、PDF、TXT多格式文档的精准问答
【RAG实战系列 04】 快速部署:把RAG系统做成Web应用,团队共用------教大家用Flask/Django搭Web界面,让整个团队都能方便用RAG系统
【RAG实战系列 05】 商业落地:企业级RAG知识库的合规与性能优化------讲企业场景下的RAG部署方案、数据安全合规处理和性能调优技巧
如果实操中遇到代码报错、检索效果差等问题,欢迎在评论区留言,我会一一解答!