01. 什么是 HAProxy?(通俗理解)
HAProxy (High Availability Proxy) 是一款开源的、高性能的负载均衡器 和反向代理软件。
通俗比喻:
-
LVS : 像是一个高速路收费站。它只看你的车牌号(IP)和要去哪(端口),然后迅速抬杆让你通过。它不关心你车里拉的是什么货。
-
HAProxy : 像是一个高级酒店礼宾部。
-
它不仅能看车牌(TCP 模式,层级4)。
-
更厉害的是,它能打开你的车窗,听你的需求(HTTP 模式,层级7)。
-
比如:"我要去中餐厅" -> 带你去 Server A;"我要去西餐厅" -> 带你去 Server B;"我是 VIP 客户" -> 带你去专座。
-
02. 为什么要用它?(核心优势)
-
七层智能路由 (Layer 7 Switching): 这是 LVS 做不到的。HAProxy 可以根据 URL 路径 (比如
/img走图片服务器,/api走业务服务器)、Cookie 、User-Agent(手机端/PC端)来转发请求。 -
极高的性能: 虽然它运行在用户空间(User Space),不如 LVS(内核空间)快,但在现代硬件上,它依然能轻松处理 数万并发 (C10k/C100k problem)。很多互联网大厂(GitHub, StackOverflow, 淘宝)都在用。
-
自带"体检医生" (Advanced Health Check): LVS 只能简单探测端口。HAProxy 可以模拟发一个 HTTP 请求,检查后端返回是不是
200 OK。如果后端数据库挂了,返回500,HAProxy 能立刻把它踢出集群。
03. 核心概念与术语 (配置文件必懂)
HAProxy 的配置文件 (haproxy.cfg) 结构非常清晰,主要由四个部分组成:
-
Frontend (前台):
-
定义监听的 IP 和端口(比如
*:80)。 -
作用: 接待用户,处理 HTTPS 证书,制定"分流规则"(ACL)。
-
-
Backend (后厨):
-
定义一组真实的服务器(Real Servers)。
-
作用: 真正处理业务的地方。可以定义负载均衡算法(轮询、最少连接等)。
-
-
Global (全局配置):
- 定义进程数量、日志路径、最大连接数等底层参数。
-
Defaults (默认配置):
- 为 Frontend 和 Backend 设置默认值(比如连接超时时间),避免重复写代码。
04. 两种核心工作模式
1. TCP 模式 (四层)
-
原理: 和 LVS 类似,只转发 TCP 数据流。客户端和后端服务器建立长连接。
-
场景: 数据库负载均衡 (MySQL, Redis)、SSH、或是非 HTTP 协议的服务。
-
特点: 速度快,但不处理 HTTP 头部。
2. HTTP 模式 (七层)
-
原理: HAProxy 代理了请求。客户端先连上 HAProxy,HAProxy 解析 HTTP 请求头,根据规则再向后端服务器发起新连接。
-
场景: 网站、API 接口、微服务网关。
-
特点: 极其灵活,可以利用 ACL 搞定各种复杂流量控制。
05. 调度算法
除了大家熟悉的 Round Robin (轮询) 和 Least Conn (最少连接),HAProxy 还有针对 Web 场景的特殊算法:
-
Source (源地址哈希):
- 也就是 LVS 的持久化。保证同一个 IP 的用户总是访问同一台服务器。
-
URI (URI 哈希):
-
重点: 根据请求的 URL 进行哈希。
-
场景: 缓存服务器 。保证访问
a.jpg的请求永远找 Server 1,这样 Server 1 的缓存利用率最高。
-
-
HDR (Header 哈希):
- 根据 HTTP 头部的某个字段(比如
Host)来分配。
- 根据 HTTP 头部的某个字段(比如
06. 灵魂功能:ACL (访问控制列表)
逻辑: 如果 (条件) 那么 (动作)
-
例子 1 (动静分离):
-
acl is_image path_end .jpg .png -
use_backend static_server if is_image -
(如果是图片,去静态服务器组)
-
-
例子 2 (封禁 IP):
-
acl bad_guy src 192.168.1.100 -
http-request deny if bad_guy -
(如果是坏人 IP,直接拒绝)
-
07.实验
一、基础环境配置和HAProxy 基础负载均衡实现
利用现有的 LVS-DR 环境 (都在同一个 172.25.254.0/24 网段)(详细配置可参考上一篇LVS文章)来快速改造为 HAProxy 环境。
重要提示(环境清理): 在开始 HAProxy 之前,必须把 LVS-DR 的配置清理干净,否则会有冲突!
-
调度器 (172.25.254.200): 清空 IPVS 规则 (
ipvsadm -C),停止 ipvsadm 服务。 -
真实服务器 RS (Server1 & Server2): 必须删除绑定在
lo(回环接口) 上的 VIP (172.25.254.250),并恢复ARP响应。如果不删,HAProxy 转发请求过去时,RS 可能会因为 IP 冲突或路由混乱导致连接失败。
1.实验拓扑 (基于现有环境)
-
HAProxy 服务器:
-
IP:
172.25.254.200 -
角色: 流量入口,七层代理。
-
-
后端服务器 RS1 (Server1):
-
IP:
172.25.254.10 -
服务: Httpd (Web)
-
-
后端服务器 RS2 (Server2):
-
IP:
172.25.254.20 -
服务: Httpd (Web)
-
-
客户端 (Foundation):
172.25.254.100
2. 分步实施步骤
第一步:安装 HAProxy (在 172.25.254.200 上)
bash
# 安装软件包
dnf install haproxy -y
# 查看版本
haproxy -v预期效果:

第二步:配置 HAProxy 核心文件
HAProxy 的配置文件在 /etc/haproxy/haproxy.cfg。我们需要修改它来实现负载均衡。
建议备份原文件: cp /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.bak
编辑配置文件 (vim /etc/haproxy/haproxy.cfg),修改为以下内容:
注:
global和defaults部分通常保持默认即可,我们重点关注frontend和backend。
bash
# ---------------------------------------------------------------------
# Global settings (全局配置 - 保持默认即可)
# ---------------------------------------------------------------------
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
# 开启多线程处理 (根据 CPU 核心数调整,实验环境设为 1 或 2)
nbproc 1
# ---------------------------------------------------------------------
# Defaults settings (默认配置 - 作用于所有后续配置)
# ---------------------------------------------------------------------
defaults
mode http # 默认工作在 7 层模式 (http)
log global
option httplog # 开启详细的 http 日志
option dontlognull # 不记录空连接
option http-server-close # 每次请求完毕后主动关闭连接
option forwardfor # 关键!透传客户端真实 IP 给后端
retries 3 # 请求失败重试次数
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
# ---------------------------------------------------------------------
# 监控页面配置 (强烈建议开启,是 HAProxy 的一大亮点)
# ---------------------------------------------------------------------
listen stats
bind :9090 # 监听 9090 端口
stats enable
stats uri /status # 访问路径为 /status
stats auth admin:123456 # 设置账号 admin,密码 123456
stats refresh 5s # 每 5 秒自动刷新一次
# ---------------------------------------------------------------------
# Frontend (前台 - 接收用户请求)
# ---------------------------------------------------------------------
frontend my_web_front
bind *:80 # 监听所有网卡的 80 端口
default_backend my_web_back # 将所有流量转发给后端组
# ---------------------------------------------------------------------
# Backend (后厨 - 真实服务器组)
# ---------------------------------------------------------------------
backend my_web_back
balance roundrobin # 负载均衡算法:轮询 (rr)
# 定义真实服务器
# check: 开启健康检查
# inter 2000: 每 2000ms 检查一次
# rise 3: 连续成功 3 次才算上线
# fall 3: 连续失败 3 次就算下线
server web1 172.25.254.10:80 check inter 2000 rise 3 fall 3
server web2 172.25.254.20:80 check inter 2000 rise 3 fall 3第三步:启动服务与验证
检查配置文件语法是否正确:
bash
haproxy -c -f /etc/haproxy/haproxy.cfg
# 输出 Configuration file is valid 说明没问题预期结果:

启动服务:
bash
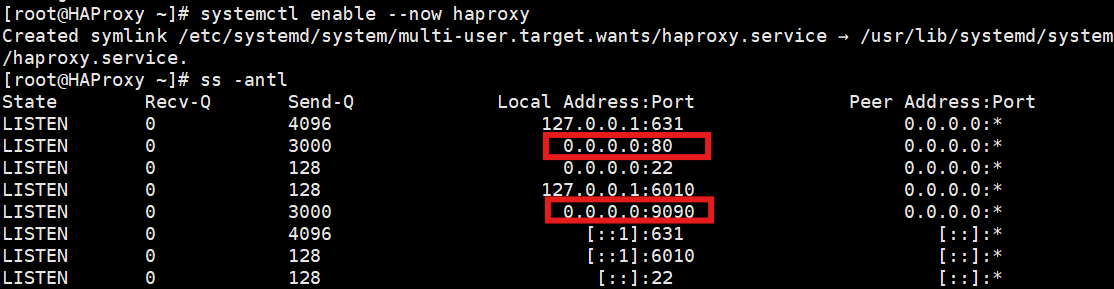
systemctl enable --now haproxy查看端口状态:
bash
ss -antl
# 应该能看到 80 (业务端口) 和 9090 (监控端口)预期结果:
3. 实验效果验证
回到你的母机 (172.25.254.100) 进行测试。
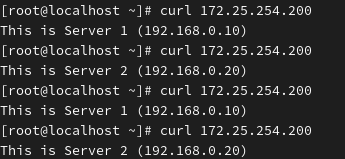
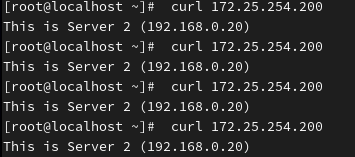
测试 1:负载均衡效果 (命令行)
bash
# 连续请求 4 次
curl 172.25.254.200
curl 172.25.254.200
curl 172.25.254.200
curl 172.25.254.200预期结果:
应该看到 Server 1 和 Server 2 的页面交替出现(因为配置了
roundrobin)
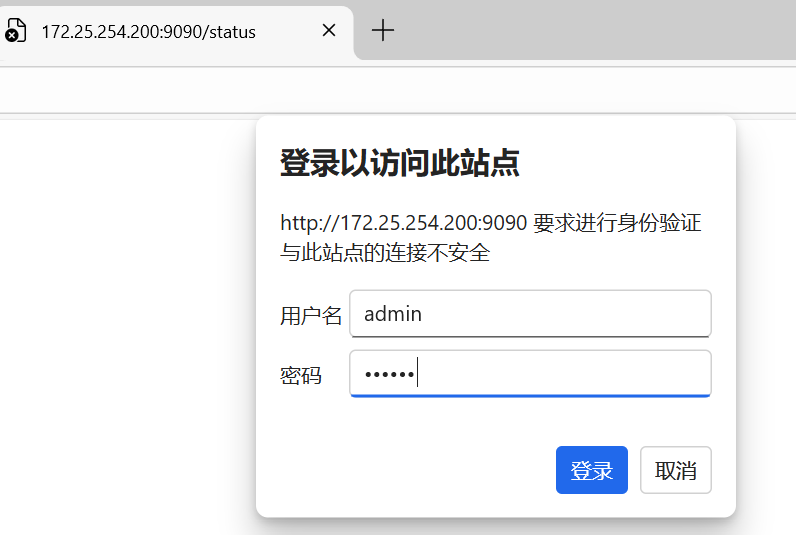
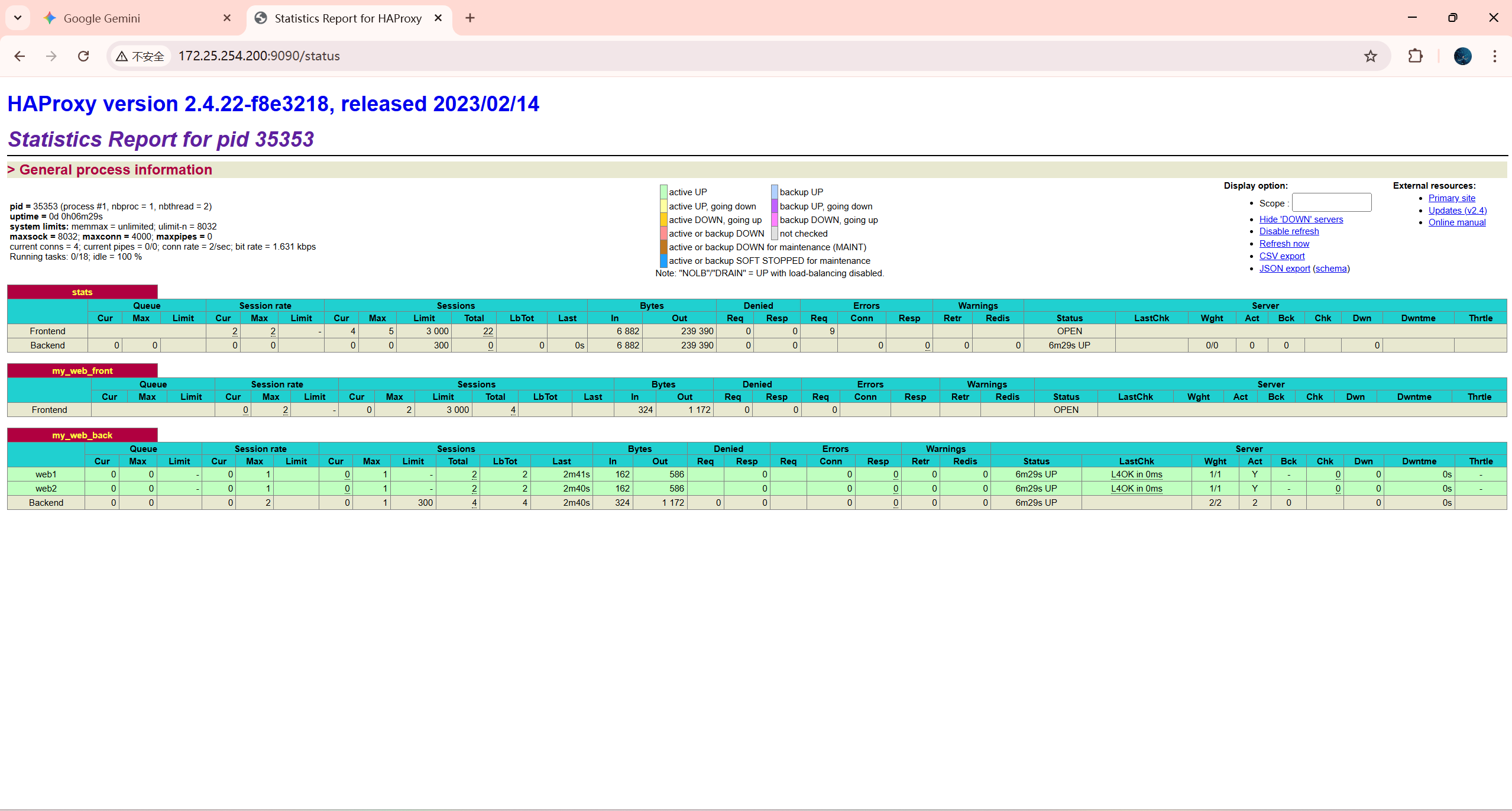
测试 2:可视化监控页面 (浏览器)
-
打开浏览器,访问
http://172.25.254.200:9090/status -
输入账号:
admin,密码:123456 -
观察页面:
-
你会看到一个表格,列出了
web1和web2。 -
颜色应该是绿色 (UP)。
-
-
动态演示:
-
手动停止 Server1 的 httpd (
systemctl stop httpd)。 -
刷新监控页面,你会发现
web1变成了红色 (DOWN)。 -
再次
curl 172.25.254.200,你会发现所有流量自动全部去了 Server2,不会报错。 -
这就是 HAProxy 强大的自动健康检查与故障切换功能。
-

二、全局配置讲解和Socat 热更新配置
(1)HAProxy 全局配置 (global) 深度解析
在 haproxy.cfg 中,global 段落定义了进程级别的安全、性能和日志参数。虽然平时改动不多,但作为 RHCSE,每一行都得懂。
bash
global
# 1. 日志记录
# local2 是日志设备设施,需要在 rsyslog 中配置
log 127.0.0.1 local2
# 2. 运行目录与安全
# 锁定运行目录,提高安全性,防止被骇客跳出目录
chroot /var/lib/haproxy
# 记录进程 ID 的文件,用于 reload 或 stop
pidfile /var/run/haproxy.pid
# 3. 性能调优 (核心)
# 单个进程的最大并发连接数
# 生产环境建议设置为 4000-50000,取决于内存和 CPU
maxconn 4000
# 4. 身份权限
# 也就是 drop privileges,启动后降级为普通用户运行
user haproxy
group haproxy
# 5. 运行模式
# 以守护进程方式在后台运行
daemon
# 6. 多线程/多进程 (性能关键)
# 在旧版本常用 nbproc (多进程),新版本推荐 nbthread (多线程)
# 默认 auto 即可,指定 2 个线程处理
# nbthread 2
# 7. Runtime API (热更新的关键!重点!)
# 开启一个 UNIX Socket 文件,允许管理员通过命令行与运行中的 HAProxy 对话
# mode 600: 只有拥有者可读写
# level admin: 赋予管理员权限 (必加!否则只能看不能改)
stats socket /var/lib/haproxy/stats mode 600 level admin(2)Socat 热更新:
在生产环境中,重启 HAProxy 可能会导致瞬间的连接抖动。如果我们只是想修改某个后端服务器的权重 (比如服务器性能变强了),或者临时下线一台机器修 bug,完全没必要重启。
我们要用到 Socat 工具和 Runtime API。
第一步:环境准备
-
修改配置文件: 确保你的
global段落里已经有了上面提到的stats socket配置。 -
重启服务: 让配置生效(这是最后一次重启)。
-
安装 Socat 工具:
bash
systemctl restart haproxy
dnf install socat -y第二步:常用热更新操作 (博客核心实操)
我们可以通过 echo "命令" | socat stdio /var/lib/haproxy/stats 的方式发送指令。
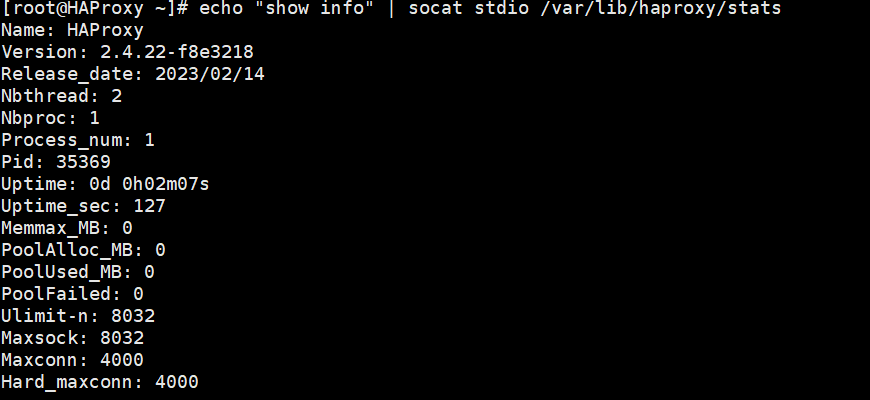
1. 查看 HAProxy 状态 (体检)
不登录 Web 页面,直接看内核信息。
bash
echo "show info" | socat stdio /var/lib/haproxy/stats注: 你会看到 Uptime(运行时间)、Maxconn(最大连接)等关键指标。
2. 查看后端服务器状态 (查岗)
bash
echo "show servers state" | socat stdio /var/lib/haproxy/stats注: 这会列出所有 RS 的 IP、权重、状态(是 UP 还是 DOWN)。

3. 动态修改权重 (热更新 - 核心技能)
假设 web1 性能太强,你想让它多干点活,把权重从 1 改为 2。
语法: set weight <后端组名>/<服务器名> <权重值>
bash
# 1. 先查看当前权重
echo "get weight my_web_back/web1" | socat stdio /var/lib/haproxy/stats
# 2. 修改权重为 2 (立即生效,无需重启)
echo "set weight my_web_back/web1 2" | socat stdio /var/lib/haproxy/stats
# 3. 验证
# 再次 curl 访问 VIP,你会发现去 web1 的次数明显变多了。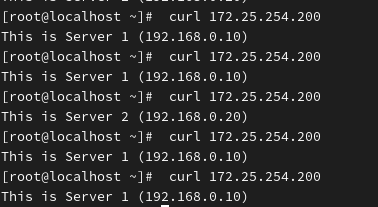
4. 临时下线/上线服务器 (维护模式)
假设 web1 需要更新代码,不能让用户访问它了,但不能停 HAProxy。
下线 (Disable):
bash
echo "disable server my_web_back/web1" | socat stdio /var/lib/haproxy/stats现象: 此时再去监控页面看,
web1会变成棕色 (MAINT),流量会自动全部切到web2

上线 (Enable):
bash
echo "enable server my_web_back/web1" | socat stdio /var/lib/haproxy/stats现象:
web1恢复绿色,流量重新回来

总结:
在传统的运维中,修改配置意味着 systemctl reload 或 restart。但在高并发场景下,哪怕是 1 秒的抖动都可能丢失订单。
通过配置 stats socket 并配合 socat 工具,我们拥有了与 HAProxy 内核直接对话的能力。这不仅让我们能实时监控,更能在业务无感知的情况下,动态调整流量分配(权重)或进行灰度发布(上下线服务器)。这就是初级运维与高级运维的分水岭。
三、HAProxy 调度算法全解析:从'公平轮询'到'智能定向'
1. 静态算法 (Static Algorithms)
特点:
-
权重固定: 在服务启动时读取
haproxy.cfg中的weight值。 -
不可热更新: 即使你用
socat修改权重,它也会提示成功,但实际上没有任何变化。 -
优势: 对 CPU 消耗极低(虽然现在的 CPU 都不差这点性能),且流量分配绝对平均。
代表算法:static-rr (静态轮询)
这是最纯粹的轮询。
配置示例:
bash
backend my_web_back
mode http
# 设置为静态轮询
balance static-rr
# weight 为 1,即便你在运行时想改,它也永远是 1
server web1 172.25.254.10:80 check weight 1
server web2 172.25.254.20:80 check weight 1
bash
systemctl restart haproxy测试得到轮询结果,使用Socat中的方法更改权重
得到如上提示,证明静态轮询算法已经成功实现,且仅支持0(关闭)和1(打开)的权重配置

2. 动态算法 (Dynamic Algorithms) ------ 企业最常用
特点:
-
权重可变: 支持通过 Runtime API (Socat) 动态调整权重。
-
慢启动 (Slow Start): 当服务器从 DOWN 变成 UP 时,它不会立刻承担全部流量,而是逐渐增加,给服务器"预热"的时间。
代表算法 A:roundrobin (动态轮询)
这是 HAProxy 的默认算法。它不仅轮询,还支持权重。
配置示例:
bash
backend my_web_back
mode http
# 设置为动态轮询 (默认就是这个,不写也行,但建议写上)
balance roundrobin
# web1 权重为 1,web2 权重为 2 (web2 处理请求是 web1 的两倍)
server web1 172.25.254.10:80 check weight 1
server web2 172.25.254.20:80 check weight 2
bash
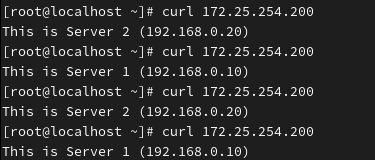
systemctl restart haproxy使用Socat修改权重,web1为2,web2为1
得到相反的结果,同时可知动态算法支持热更新
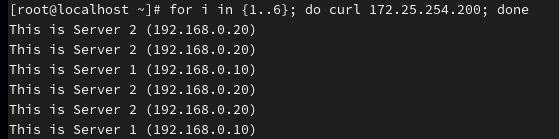
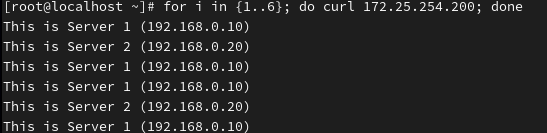
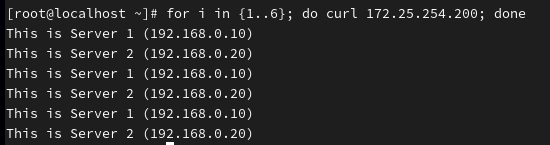
代表算法 B:leastconn (最少连接数)
场景: 数据库 (MySQL)、长连接服务 (WebSocket)、邮件服务。 原理: 谁身上的连接少,就把新请求给谁。
配置示例:
bash
backend my_web_back
mode http
balance leastconn
server web1 172.25.254.10:80 check inter 2000 rise 3 fall 3
server web2 172.25.254.20:80 check inter 2000 rise 3 fall 3由于我此时两台服务器占用是相同的,所以呈1:1轮询
3. 混合/哈希算法 (Source/URI Hashing)
这类算法主要用于"会话保持 "或"缓存命中 "。它们根据请求的特征(IP 或 URL)进行哈希运算,算出来是谁就是谁。哈希算法默认是"静态"的,但可以通过 hash-type 参数变成"动态一致性哈希"。
代表算法 A:source (源地址哈希)
原理: Client IP % 服务器总数 = 目标服务器。
场景: 只要用户 IP 不变,他就永远访问同一台 RS。适用于没有 Cookie 机制的登录会话保持。
配置示例:
bash
backend my_web_back
mode http
balance source
# 强烈建议加上 consistent (一致性哈希)
# 作用:当 backend 中增加或减少服务器时,只会影响一小部分用户,不会导致所有人的会话都丢失。
hash-type consistent
server web1 172.25.254.10:80 check
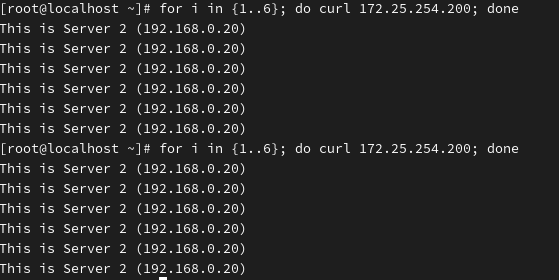
server web2 172.25.254.20:80 check访问的服务器一直是RS2
代表算法 B:uri (URI 哈希)
原理: 对 URL (如 /logo.png) 进行哈希。
场景: 缓存服务器 (Varnish/Squid) 。 确保所有用户访问 /logo.png 时,请求都发往同一台后端服务器,这样这台服务器只需要缓存一次,命中率极高。
配置示例:
bash
backend my_web_back
mode http
balance uri
# 同样建议开启一致性哈希
hash-type consistent
# 模拟后端是缓存服务器
server web1 172.25.254.10:80 check
server web2 172.25.254.20:80 check测试:
在 Server 1 (172.25.254.10) 上执行:
bash
cd /var/www/html/
# 创建三个不同的测试文件
echo "I am Server 1 - File A" > a.html
echo "I am Server 1 - File B" > b.html
echo "I am Server 1 - File C" > c.html在 Server 2 (172.25.254.20) 上执行:
bash
cd /var/www/html/
# 文件名必须和 Server 1 一样,但内容要是 Server 2
echo "I am Server 2 - File A" > a.html
echo "I am Server 2 - File B" > b.html
echo "I am Server 2 - File C" > c.html回到你的 测试机 (172.25.254.100) ,使用 curl 进行测试。
测试一: 我们多次访问同一个文件(比如 a.html)。
预期结果: 你应该看到 全部是 Server 1 (或者全部是 Server 2)。 只要 URL 不变,请求绝对不会跳到另一台机器去。

测试二: 我们分别访问不同的文件(a.html, b.html, c.html)。
bash
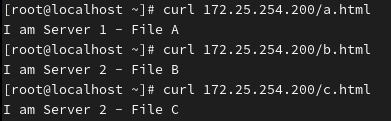
curl 172.25.254.200/a.html
curl 172.25.254.200/b.html
curl 172.25.254.200/c.html预期结果: 你可能会发现:
访问
a.html-> 去了 Server 1访问
b.html-> 去了 Server 2 (因为对 "b.html" 哈希算出来的结果指向 Server 2)访问
c.html-> 去了 Server 2可再次测试,看看结果是否相同
代表算法 C:url_param(根据 URL 参数哈希)
原理: HAProxy 依然会对请求进行哈希,但这次它只盯着 URL 中 ? 后面的特定参数。
场景: 无 Cookie 的用户追踪 / 推广链接分流 。 比如你的 URL 是 http://example.com/buy?userid=1001。
你希望 userid=1001 的用户永远访问 Server 1(因为 Server 1 内存里可能有他的购物车缓存)。
即便他在不同的电脑、不同的 IP 上登录,只要 URL 里的 userid=1001 不变,他就永远去 Server 1。
配置实战:
bash
backend my_web_back
mode http # 必须是 http 模式,否则无法解析 URL
# 语法:balance url_param <参数名>
# 这里我们根据 URL 中名为 "userid" 的参数进行哈希
balance url_param userid
# 同样建议开启一致性哈希
hash-type consistent
server web1 172.25.254.10:80 check
server web2 172.25.254.20:80 check验证方法:
重启 HAProxy 后,使用 curl 模拟带有不同参数的请求。
测试 1:参数不变,服务器不变
预期结果: 全部去同一台机器(例如 Server 2)。

测试 2:参数变化,服务器变化
bash
# 模拟用户 ID 为 200
curl "172.25.254.200/index.html?userid=200"预期结果: 可能会跳到 Server 1(取决于哈希结果)。
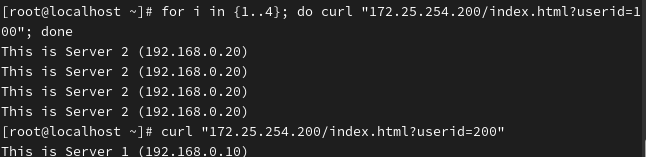
测试 3:不带参数(缺省行为)
bash
curl "172.25.254.200/index.html"预期结果: 如果 URL 里没有
userid参数,HAProxy 通常会退化为 Round Robin (轮询) 模式。

代表算法D:hdr(根据 HTTP 请求头哈希)
原理: HAProxy 读取 HTTP 请求头部(Header)中的某个特定字段(如 User-Agent, Host 等),根据这个字段的值进行哈希。
场景:
hdr(User-Agent): 区分浏览器。让所有用 Chrome 的人去 Server 1,用 Firefox 的人去 Server 2(虽然通常用 ACL 做这个更好,但哈希也是一种手段)。
hdr(Host): 虚拟主机(Virtual Hosting)分流 。如果你的后端是多租户系统,www.a.com 和 www.b.com 指向同一个 VIP,你可以让访问 a.com 的请求总是去同一台机器。
配置实战:
bash
backend my_web_back
mode http
# 语法:balance hdr(<HTTP头部名称>)
# 这里我们根据 User-Agent (浏览器标识) 进行哈希
balance hdr(User-Agent)
hash-type consistent
server web1 172.25.254.10:80 check
server web2 172.25.254.20:80 check验证方法
重启 HAProxy 后,使用 curl -A (User-Agent) 或 curl -H (自定义头) 来测试。
测试 1:模拟 Chrome 浏览器
bash
# -A 指定 User-Agent
for i in {1..4}; do curl -A "Chrome" 172.25.254.200; done预期: 全部去同一台机器(因为头信息没变)。

测试 2:模拟百度浏览器
bash
curl -A "baidu" 172.25.254.200预期: 可能会切到另一台机器,如未切换,可自行更换名称模仿其他浏览器或设备。

四、七层透传 (HTTP) 和 四层透传 (TCP)
1. 理论核心:为什么 IP 会丢失?
-
直连模式: 客户端直接访问服务器,服务器看到的源 IP 就是客户端 IP。
-
代理模式 (HAProxy):
-
客户端 (
172.25.254.100) 找 HAProxy (.200)。 -
HAProxy (
.200) 转身去连后端 RS (.10)。 -
后端 RS 看到的源 IP 是 HAProxy 的
.200,而不是客户端的.100。
-
2. 七层透传 (Layer 7 / HTTP 模式) ------ 最常用
原理: HAProxy 在转发 HTTP 请求时,会在 HTTP 头部(Header)里偷偷塞一张"小纸条",上面写着客户端的真实 IP。这张小纸条的标准名字叫 X-Forwarded-For。
实验步骤
第一步:配置 HAProxy (发送方)
确保你的 haproxy.cfg 是 HTTP 模式 ,并且开启了 forwardfor 选项。
bash
defaults
mode http # 必须是 http 模式
option forwardfor # 关键指令:插入 X-Forwarded-For 头部
# ... 其他配置 ...
backend my_web_back
mode http
balance roundrobin
server web1 172.25.254.10:80 check
server web2 172.25.254.20:80 check重启 HAProxy:systemctl restart haproxy
第二步:配置后端 Apache (接收方)
虽然 HAProxy 发送了 IP,但后端 Apache 默认的日志格式只记录"直接连接者"的 IP。我们需要修改 Apache 的日志格式,让它去读那张"小纸条"。
在 Server 1 (172.25.254.10) 上操作:
1.编辑 Apache 配置文件: vim /etc/httpd/conf/httpd.conf
2.找到 LogFormat 配置段(通常在第 201 行左右)。默认是这样的:
bash
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"" combined %h: 代表 Remote Host (也就是 HAProxy 的 IP)。
3.修改它: 在 %h 前面加上 %{X-Forwarded-For}i,或者直接替换 %h。
bash
# 修改后的格式:
LogFormat "%{X-Forwarded-For}i %h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"" combined4.重启 Apache : systemctl restart httpd
第三步:验证实验
1.在 Server 1 上实时监控日志:
bash
tail -f /var/log/httpd/access_log2.在客户端 (172.25.254.100) 发起请求:
bash
curl 172.25.254.2003.观察日志输出:
你现在的日志应该长这样:
第一列 (
172.25.254.100): 成功获取到了客户端真实 IP第二列 (
172.25.254.200): 这是 HAProxy 的内网 IP

3. 四层透传 (Layer 4 / TCP 模式) ------ 高级且危险
场景: 数据库负载均衡、HTTPS 流量透传(不解密直接转发)。
原理: 在 TCP 模式下,HAProxy 看不懂 HTTP 协议,所以没法塞 Header。 解决方法是使用 PROXY Protocol。HAProxy 会在 TCP 连接建立之初,发送一串二进制代码告诉后端:"嘿,真实的 IP 是 xxx"。
注意: 这需要后端服务(如 Nginx 或 MySQL)必须支持并配置了 PROXY Protocol,否则后端会因为看不懂这串代码而直接报错。
实验步骤
注意: Apache (httpd) 默认很难直接支持 TCP 层的 PROXY Protocol(需要复杂配置)。为了演示成功,请停止你的httpd服务并启动 Nginx。
第一步:配置 HAProxy (开启 send-proxy)
bash
frontend my_web_front
# 强制指定为 tcp 模式,覆盖默认的 http
mode tcp
bind *:80
default_backend my_web_back
backend my_tcp_back
mode tcp # 四层模式
balance roundrobin
# 关键指令:send-proxy
server web1 172.25.254.10:80 check send-proxy
server web2 172.25.254.20:80 check send-proxy第二步:后端接收 (以 Nginx 为例)
如果你现在的后端是 Apache,这一步千万别做,否则 Apache 会报错 400 Bad Request。
如果后端是 Nginx,需要在监听端口时加上 proxy_protocol:
bash
http {
server {
# 必须加上 proxy_protocol 关键字
listen 80 proxy_protocol;
# 定义日志格式来接收真实 IP
set_real_ip_from 172.25.254.200; # 信任 HAProxy 的 IP
real_ip_header proxy_protocol;
# ...
}
}配置完成后重启nginx:systemctl restart nginx
开始验证
现在我们通过客户端发起请求,并观察后端 Nginx 的日志。
步骤 A: 在后端 RS (Nginx) 上监控日志
在 Server1 (172.25.254.10) 上执行:
bash
# 实时查看访问日志
tail -f /var/log/nginx/access.log步骤 B: 在客户端 (Client) 上发起请求
在 测试机 (172.25.254.100) 上执行:
bash
curl 172.25.254.200步骤 C: 观察日志输出
成功的情况: 你应该在 Nginx 日志里看到 客户端的 IP (172.25.254.100),而不是 HAProxy 的 IP。

4.四层负载均衡:构建高性能数据库集群
四层负载均衡(Layer 4 Load Balancing)不解析内容,只负责转发数据包。它性能最强 ,且兼容所有基于 TCP 的协议(数据库、SSH、Redis、甚至 HTTPS 透传)。
1. 核心应用场景
-
数据库负载均衡 (MySQL, MariaDB, Redis, PostgreSQL)
-
HTTPS 透传 (不解密 SSL,直接把加密流量甩给后端,证书配在后端)
-
非 HTTP 服务 (SSH, SMTP, FTP, RabbitMQ)
2. 配置实例:MariaDB 数据库负载均衡
设我们将 HAProxy 配置为数据库的统一入口(端口 3306),后端有两台 MariaDB 数据库。
编辑配置文件: vim /etc/haproxy/haproxy.cfg
我们需要添加一个新的 listen 块 (listen 是 frontend 和 backend 的合并写法,配置四层时更简洁),或者分开写也可以。
方案 A:标准写法 (Frontend + Backend)
bash
# ---------------------------------------------------------------------
# 数据库负载均衡 (TCP 模式)
# ---------------------------------------------------------------------
frontend my_db_front
bind *:3306
# 必须指定为 tcp 模式,否则默认继承 http 会报错
mode tcp
# 只有 TCP 模式才能用 tcplog,httplog 会报错
option tcplog
default_backend my_db_back
backend my_db_back
mode tcp
# 数据库场景强推 leastconn (最少连接数算法)
# 因为数据库连接通常是长连接,轮询可能会导致某个节点累积过多连接
balance leastconn
# 定义后端 (注意端口是 3306)
# check: 发送 TCP 握手包检测存活
server db1 172.25.254.10:3306 check
server db2 172.25.254.20:3306 check方案 B:HTTPS 透传 (Pass-through)
bash
listen https_proxy
bind *:3306
mode tcp
balance roundrobin
# 只要端口能通就算活
server web1 172.25.254.10:3306 check
server web2 172.25.254.20:3306 check3. 几个关键配置详解
-
mode tcp:-
含义: 告诉 HAProxy:"别试着去读 HTTP 头了,里面全是二进制数据,只管转发 TCP 包就行。"
-
后果: 如果不写这个,HAProxy 会尝试解析 HTTP,结果发现是乱码,直接断开连接。
-
-
balance leastconn:-
含义: 谁身上的连接少,就给谁。
-
为什么选它? HTTP 请求是短连接(处理完就断),轮询很公平。但数据库是长连接 (连上就不挂断)。如果用轮询,可能 Server 1 积压了 100 个在跑大查询的连接,而 Server 2 只有 5 个空闲连接,这时候必须用
leastconn把新任务给 Server 2。
-
-
option tcplog:- 含义: 记录 TCP 相关的日志(源 IP、目标 IP、连接时长等),而不是记录 URL 和 User-Agent。
4. 实验验证步骤
要验证这个实验,你不需要真的安装数据库,我们可以用 nc (Netcat) 来模拟 TCP 服务。
第一步:在 RS 上模拟 TCP 服务
既然我们没有装 MySQL,我们让 RS 监听 3306 端口并返回一句话。
在 Server 1 (172.25.254.10):
bash
# 使用 nc 监听 3306,收到连接就发回 "I am DB1"
nc -l -k 3306 -c 'echo "I am DB1"'
# 如果没有 nc 命令,需 dnf install nc在 Server 2 (172.25.254.20):
bash
nc -l -k 3306 -c 'echo "I am DB2"'第二步:重启 HAProxy
确保配置文件无误 (haproxy -c -f ...) 并重启。
第三步:客户端测试
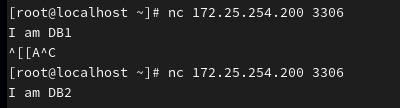
在测试机 (172.25.254.100) 上用 nc 或者 telnet 连接 HAProxy。
bash
nc 172.25.254.200 3306预期结果: 第一次输出:
I am DB1第二次输出:I am DB2
| 透传类型 | 工作模式 | 核心技术 | HAProxy 指令 | 后端配置 | 优点 |
|---|---|---|---|---|---|
| 七层 (HTTP) | mode http |
HTTP Header | option forwardfor |
LogFormat 读取 X-Forwarded-For |
标准通用,配置简单 |
| 四层 (TCP) | mode tcp |
PROXY Protocol | server ... send-proxy |
需开启 proxy_protocol 支持 |
性能高,支持非 HTTP 协议 |
五、自定义错误界面
配置步骤
**第一步:**创建错误页面文件
我们将创建一个专门存放自定义错误的目录,并编写一个 503 错误文件。
bash
# 1. 创建目录
mkdir -p /etc/haproxy/error_page
# 2. 创建 503 错误文件 (注意后缀通常用 .http 以示区别)
vim /etc/haproxy/error_page/503.http将以下内容写入文件:
bash
HTTP/1.0 503 Service Unavailable
Cache-Control: no-cache
Connection: close
Content-Type: text/html;charset=utf-8
<html>
<head>
<title>系统维护中 - 503</title>
<style>
body { font-family: sans-serif; text-align: center; padding: 50px; }
h1 { color: #e74c3c; }
p { color: #7f8c8d; }
</style>
</head>
<body>
<h1>服务暂时不可用</h1>
<p>我们的攻城狮正在紧急抢修中,请稍后再试!</p>
<p>This is a custom HAProxy 503 Error Page.</p>
</body>
</html>**第二步:**修改 HAProxy 配置文件
我们需要告诉 HAProxy:当发生 503 错误时,不要用默认的,而是把刚才那个文件的内容发给用户。建议配置在 defaults 段中,这样对所有的 Frontend/Backend 都生效:
bash
defaults
mode http
log global
option httplog
option dontlognull
timeout connect 5000
timeout client 50000
timeout server 50000
# === 添加这一行 ===
# 语法:errorfile <错误码> <文件绝对路径>
errorfile 503 /etc/haproxy/error_page/503.http
# 你也可以配置其他错误,比如 404
# errorfile 404 /etc/haproxy/error_page/404.http**第三步:**检查并重启
测试验证(记得将HAProxy配置改为七层模式)
要看到 503 错误页面,最简单的方法就是让所有后端服务器都"挂掉"。
停止后端服务: 去 Server1 (172.25.254.10) 和 Server2 (172.25.254.20) 上停止 Web 服务:
bash
systemctl stop nginx # 或者 httpd访问测试: 在浏览器访问 HAProxy 的 IP (http://172.25.254.200),或者使用 curl:
bash
curl -i 172.25.254.200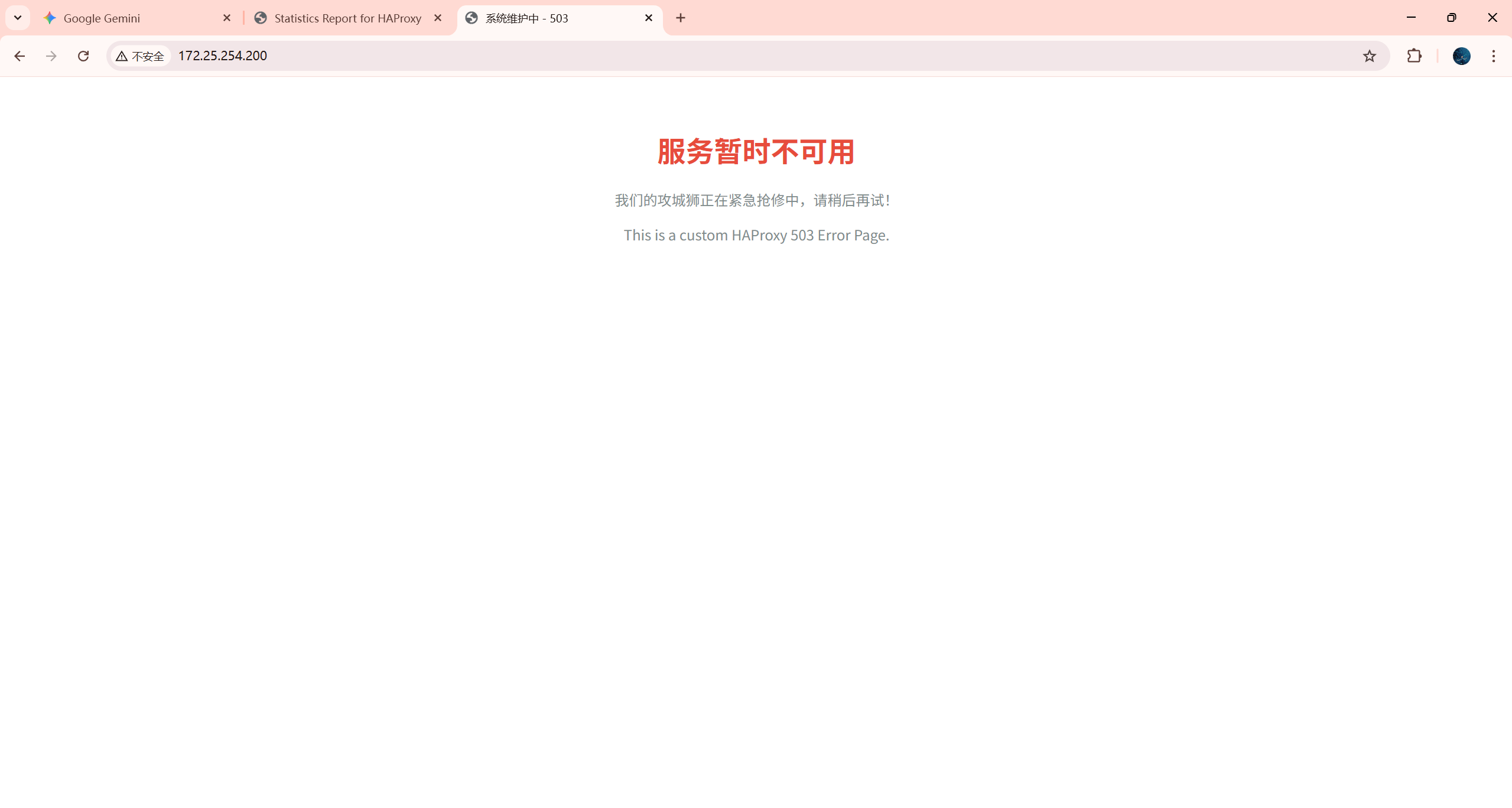
六、ACL访问控制的配置与测试
ACL (Access Control Lists) 是 HAProxy 的大脑。它让 HAProxy 不再只是一个无脑的转发器,而是能根据域名 、路径 、浏览器类型 、IP 来源等条件,进行智能分流和管控。
在开始之前,请务必将你的 Frontend 和 Backend 模式改回 mode http。
- 原因: 大部分 ACL(如域名、URL路径、User-Agent)是基于 HTTP 协议内容的。如果你还在用刚才的 TCP 模式,HAProxy 看不懂这些内容,ACL 就不会生效。
1. 实验目标设计
为了一次性把 ACL 讲透,我们要完成一个**"三合一"**的综合实验:
域名分流 (Virtual Host):
(1)访问 www.timinglee.org -> 走正常流量。
(2)访问 bbs.timinglee.org -> 走另一个后端(模拟论坛)。
动静分离(Path Separation):
访问 *.jpg 或 *.png -> 走图片专用后端。
黑名单 (Access Deny):
如果客户端 IP 是 172.25.254.100 (你的测试机),访问 /admin 目录时直接拒绝 (403 Forbidden)。
2. 配置步骤
第一步:定义 Backend (后厨)
为了演示分流效果,我们定义两个后端:
app_pool: 处理正常业务。
static_pool: 处理图片和论坛业务 (模拟)。
bash
# ---------------------------------------------------------------------
# 后端配置
# ---------------------------------------------------------------------
backend app_pool
mode http
balance roundrobin
server web1 172.25.254.10:80 check
backend static_pool
mode http
balance roundrobin
server web2 172.25.254.20:80 check第二步:配置 Frontend 与 ACL (前台逻辑)
bash
# ---------------------------------------------------------------------
# 前端配置 (ACL 核心)
# ---------------------------------------------------------------------
frontend my_web_front
bind *:80
mode http # 必须是 http
# === 1. 定义 ACL (条件) ===
# 语法: acl <名字> <类型> <值>
# 条件A: 域名匹配 (hdr_dom 匹配 Host 头部)
# -i 表示忽略大小写
acl domain_bbs hdr_dom(host) -i bbs.timinglee.org
# 条件B: 路径结尾匹配 (path_end 匹配 URL 后缀)
acl is_static path_end -i .jpg .png .css .js
# 条件C: 路径开头匹配 (path_beg 匹配目录)
acl is_admin path_beg -i /admin
# 条件D: IP 匹配 (src 匹配源 IP)
acl bad_user src 172.25.254.100
# === 2. 执行动作 (逻辑) ===
# 注意顺序!HAProxy 是从上往下执行的,匹配到就执行。
# 【黑名单】如果 IP 是 bad_user 且访问的是 /admin,直接拒绝 (403)
http-request deny if is_admin bad_user
# 【动静分离】如果是静态文件,扔给 static_pool
use_backend static_pool if is_static
# 【域名分流】如果是 bbs 域名,扔给 static_pool (模拟)
use_backend static_pool if domain_bbs
# 【默认规则】如果上面都没匹配,走默认后端
default_backend app_pool第三步:重启 HAProxy
测试验证(使用httpd)
测试 1:动静分离 (后缀匹配)
在RS2(172.25.254.20)创建一个.jpg 文件。
bash
# httpd默认目录在 /var/www/html
cd /var/www/html/
# 创建一个空的 jpg 文件,或者写点字进去假装是图片
echo "I am a JPG image on Server 2" > a.jpg回到测试机(172.25.254.100)测试
bash
curl 172.25.254.200/a.jpg
预期: 应该由
static_pool(即 Web2: 172.25.254.20) 响应。原理: 触发了
use_backend static_pool if is_static

接下来访问一个普通页面:
bash
curl 172.25.254.200预期: 应该由
app_pool(即 Web1: 172.25.254.10) 响应。

测试 2:域名分流 (Host头匹配)
我们假装自己是从 bbs.timinglee.org 访问的(通过修改 Host 头)。
bash
curl -H "Host: bbs.timinglee.org" 172.25.254.200预期: 应该由
static_pool(Web2) 响应。

我们假装从 www.timinglee.org 访问。
bash
curl -H "Host: www.timinglee.org" 172.25.254.200预期: 应该由
app_pool(Web1) 响应 (因为没匹配到 BBS 规则,走了默认)。

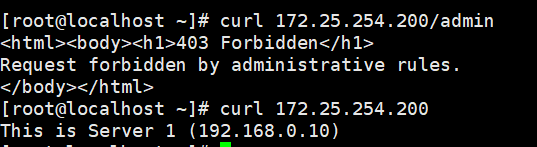
测试 3:黑名单 (IP + 目录 组合匹配)
分别尝试访问管理页面和普通页面:
bash
curl 172.25.254.200/admin
curl 172.25.254.200**预期结果:**进入管理页面被ACL规则拦截。
普通界面正常访问,因为你虽然是
bad_user,但没访问/admin。
ACL 常用匹配符总结
| 匹配方法 | 含义 | 示例 |
|---|---|---|
| hdr(Host) | 精确匹配 HTTP Host 头 | acl is_www hdr(host) -i www.baidu.com |
| hdr_dom(Host) | 域名匹配 (自动处理端口) | acl is_baidu hdr_dom(host) -i baidu.com |
| hdr_beg(User-Agent) | 头部以...开头 | acl is_android hdr_beg(User-Agent) -i Android |
| path_beg | URL 路径以...开头 | acl is_static path_beg /static/ |
| path_end | URL 路径以...结尾 | acl is_php path_end .php |
| src | 源 IP 地址 | acl internal_net src 192.168.0.0/16 |
| dst | 目标 IP 地址 | acl target_db dst 172.25.254.200 |
七、HAProxy全站加密
所谓的**"全站加密"** ,在负载均衡层面通常指的是 SSL Offloading (SSL 卸载/终止)。
-
流程: 客户端 (HTTPS) -> HAProxy (解密) -> 后端服务器 (HTTP)。
-
好处: 后端服务器(Nginx/Tomcat)不需要消耗 CPU 去处理加密解密,只需要处理明文请求,性能极大提升。
-
全站: 意味着我们要强制把所有访问 HTTP (80) 的用户,重定向到 HTTPS (443)。
第一步:准备证书 (核心难点)
HAProxy 对证书格式有一个特殊要求:它需要把 私钥 (Private Key) 和 公钥证书 (Public Certificate) 合并到一个 .pem 文件中。
由于我们是实验环境,我们先用 openssl 生成一个自签名证书。
- 生成密钥和证书:
bash
mkdir -p /etc/haproxy/certs
cd /etc/haproxy/certs
# 生成一个有效期 365 天的自签名证书
# 提示输入信息时,可以直接回车,但在 "Common Name" (CN) 一栏建议填你的域名或 IP (如 172.25.254.200)
openssl req -newkey rsa:2048 -nodes -keyout timinglee.org.key -x509 -days 365 -out timinglee.org.crt2.关键步骤:合并文件 HAProxy 无法分别读取 key 和 crt,必须合体:
bash
cat timinglee.org.crt timinglee.org.key > timinglee.org.pem- 检查文件:
bash
ls -l timinglee.org.pem
# 确保文件存在且大小不为 0第二步:配置 HAProxy
我们需要修改配置文件,做两件事:
-
Frontend 监听 443,并指定证书。
-
Frontend 监听 80,并强制跳转到 443。
bash
# ---------------------------------------------------------------------
# 全站加密前端配置
# ---------------------------------------------------------------------
frontend my_web_front
mode http
# 1. 绑定 80 端口 (用于接收未加密请求并跳转)
bind *:80
# 2. 绑定 443 端口 (SSL)
# 语法: bind *:443 ssl crt <PEM文件绝对路径>
bind *:443 ssl crt /etc/haproxy/certs/timinglee.org.pem
# 3. 【全站加密核心】强制重定向
# 如果用户访问的不是 SSL (即访问的是 80),则返回 301 跳转到 https
redirect scheme https code 301 if !{ ssl_fc }
# 4. 其它 ACL 规则 (之前实验的)
default_backend app_pool
# ---------------------------------------------------------------------
# 后端配置 (保持不变,依然收 HTTP 明文)
# ---------------------------------------------------------------------
backend app_pool
mode http
balance roundrobin
server web1 172.25.254.10:80 check
server web2 172.25.254.20:80 check第三步:检查并重启
第四步:验证全站加密
回到测试机 (172.25.254.100) 进行测试。
测试 1:访问 HTTP (验证自动跳转)
bash
curl -I http://172.25.254.200预期结果: 你应该看到状态码是 301 Moved Permanently ,且
Location指向了https://...

测试 2:访问 HTTPS (验证证书)
由于是自签名证书,curl 默认会报错(因为他不信任你)。我们需要加 -k (insecure) 参数。
bash
curl -k https://172.25.254.200预期结果: 能正常看到网页内容

测试 3:浏览器访问 (最直观)
访问 http://172.25.254.200
-
你会发现地址栏自动变为了
https://...。 -
浏览器会弹出一个巨大的红色警告"连接不安全"(因为证书是自己造的)。
-
点击"高级 -> 继续访问"。
-
你能看到页面,且地址栏有一把锁(虽然可能是红色的)。