基于 Ollama + FastAPI + React 的全栈实战,揭秘如何打造零数据外泄的智能合同审查工具
一、引言:法务数字化的"最后一公里"
在企业法务工作中,合同审查是一项高频但耗时的工作。传统方式面临三大痛点:
隐私泄露风险 是首要考量。将包含核心商业秘密合同上传到云端SaaS服务,敏感商业信息可能被第三方获取,这对于追求极致安全的企业来说无异于"裸奔"。审查视角单一 是第二个难题------人工审查往往只从己方立场出发,容易遗漏对方视角下的潜在风险。响应效率低下则是第三个困境,外包给律所审查需要等待数日,难以满足业务快速推进的需求。
面对这些挑战,我们开始思考:能否构建一个完全本地运行、支持双视角分析、实时响应的AI合同审查工具?这个需求催生了本文的核心主题------基于 Ollama 的本地 AI 合同审查系统。我们不仅要实现"能用",更要通过 SSE 流式交互、双视角 Prompt 注入和多级容错解析,打造出媲美商业软件的丝滑体验。
原型系统界面展示
初始界面
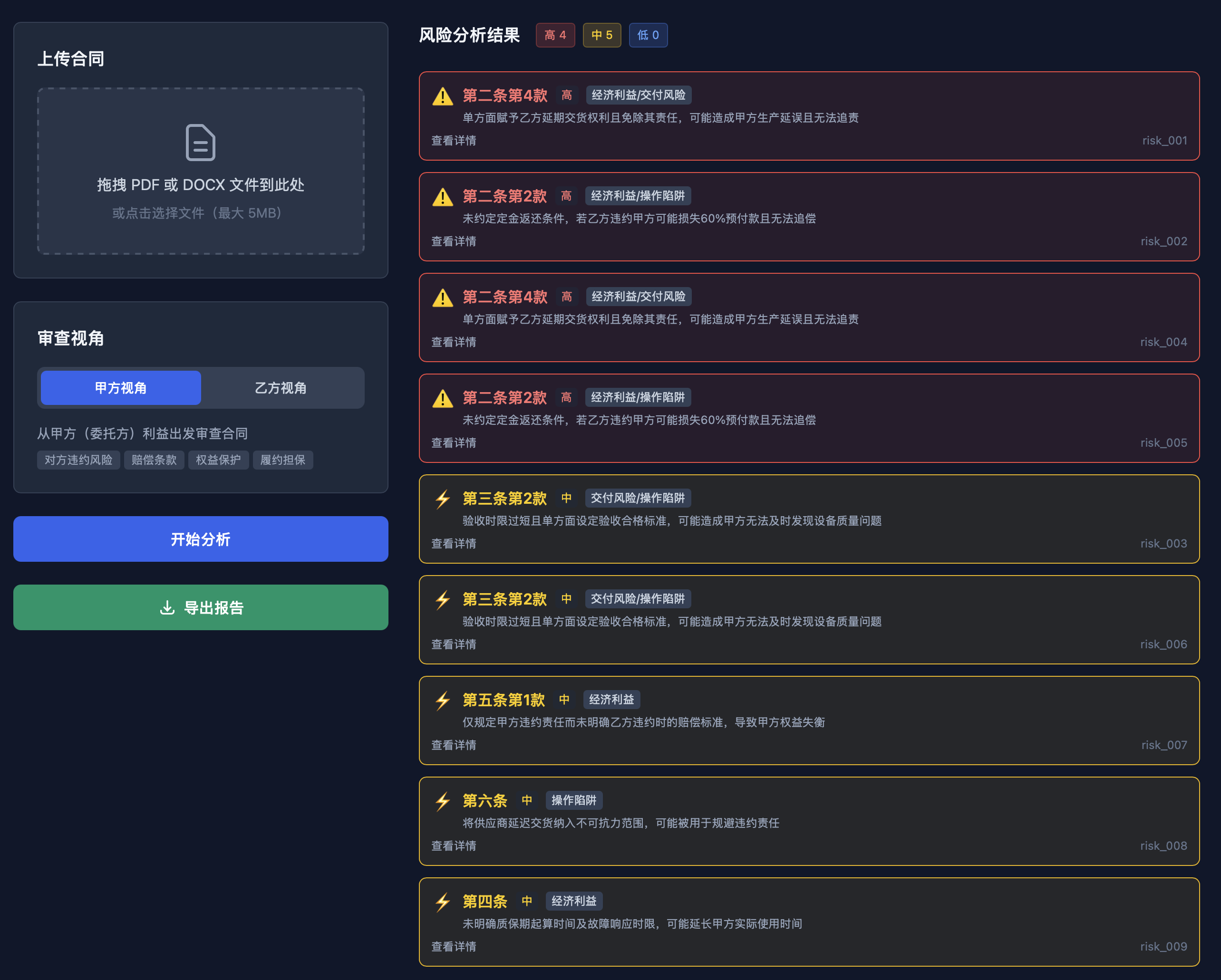
甲方视角风险分析
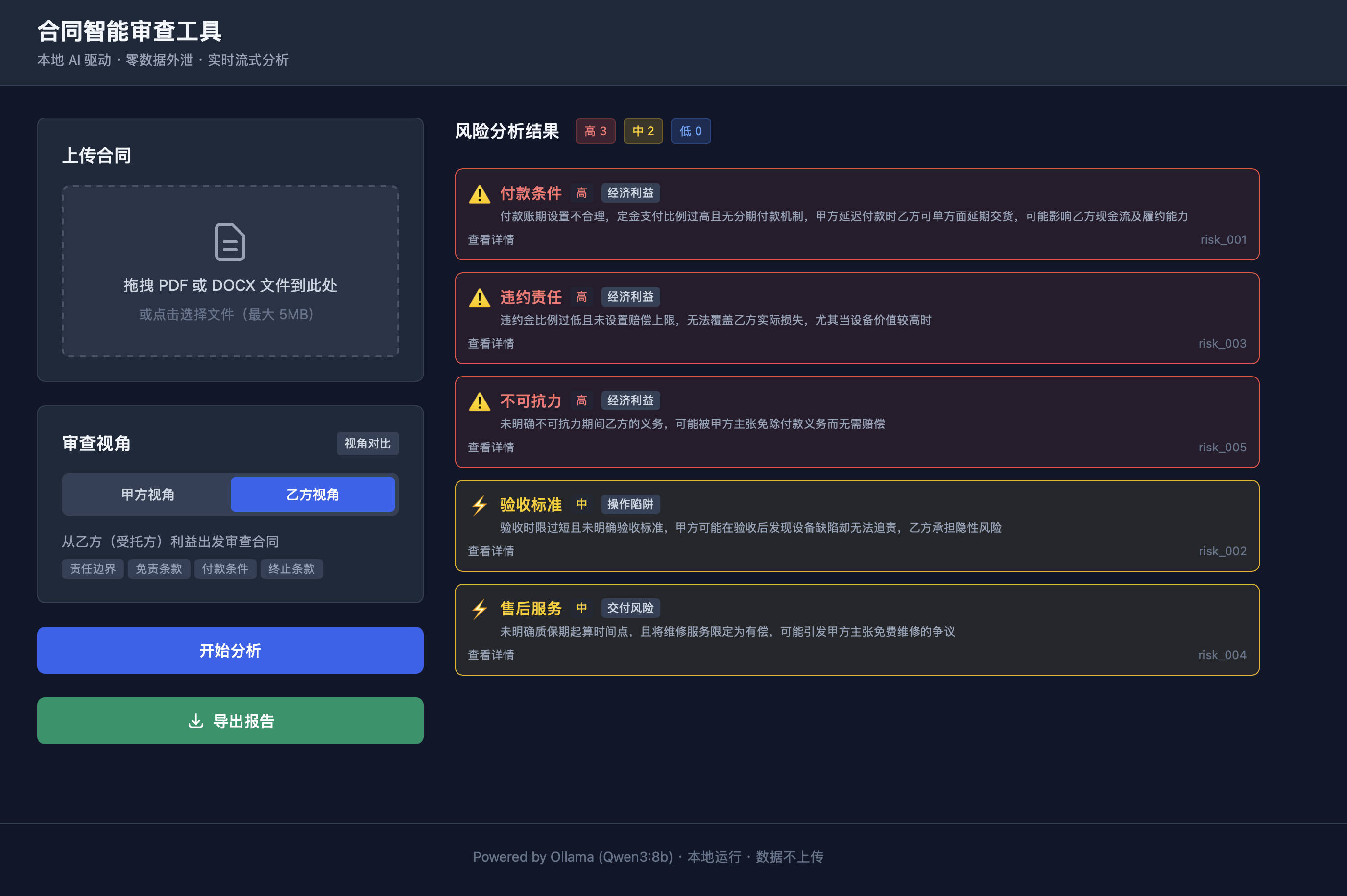
乙方视角风险分析
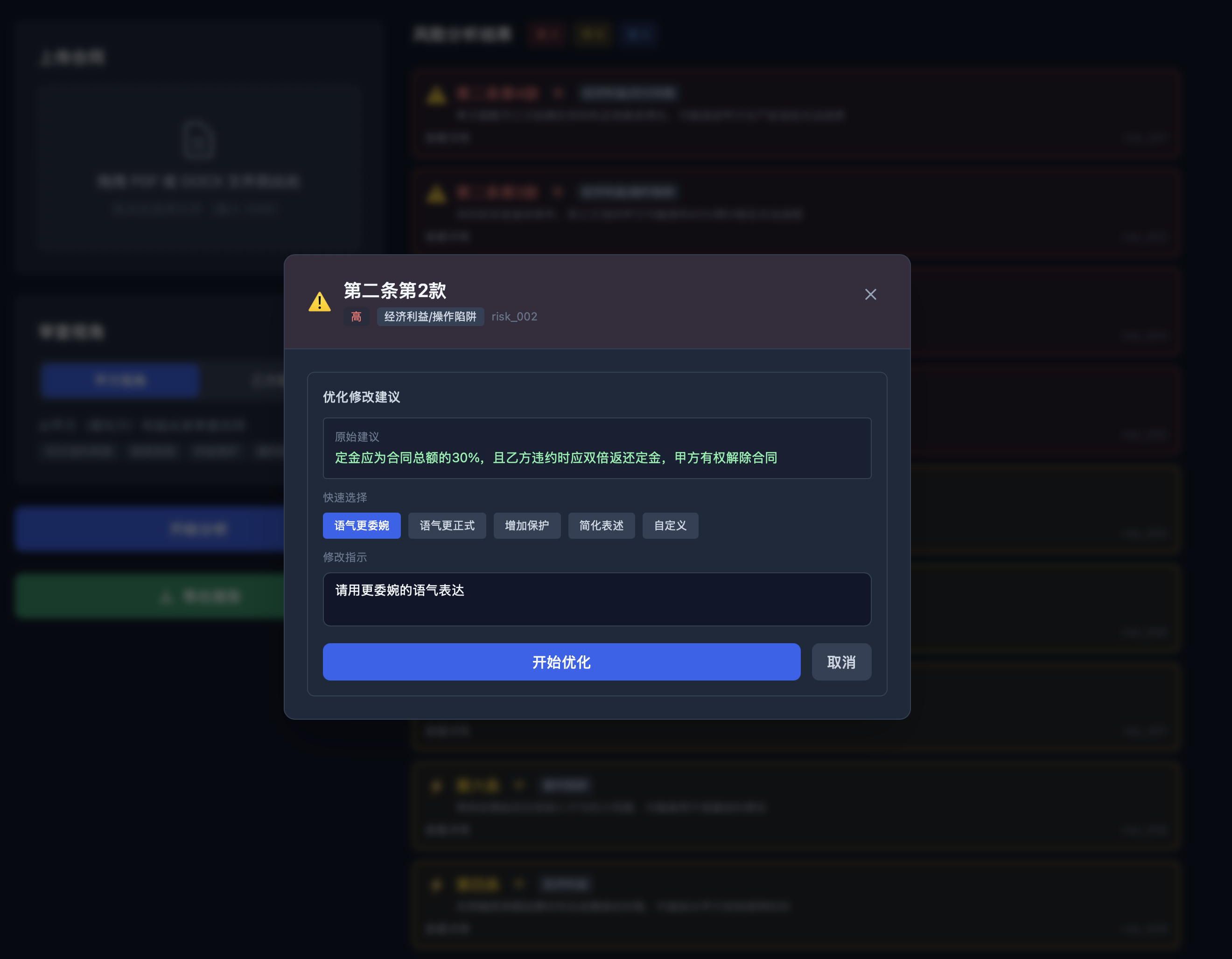
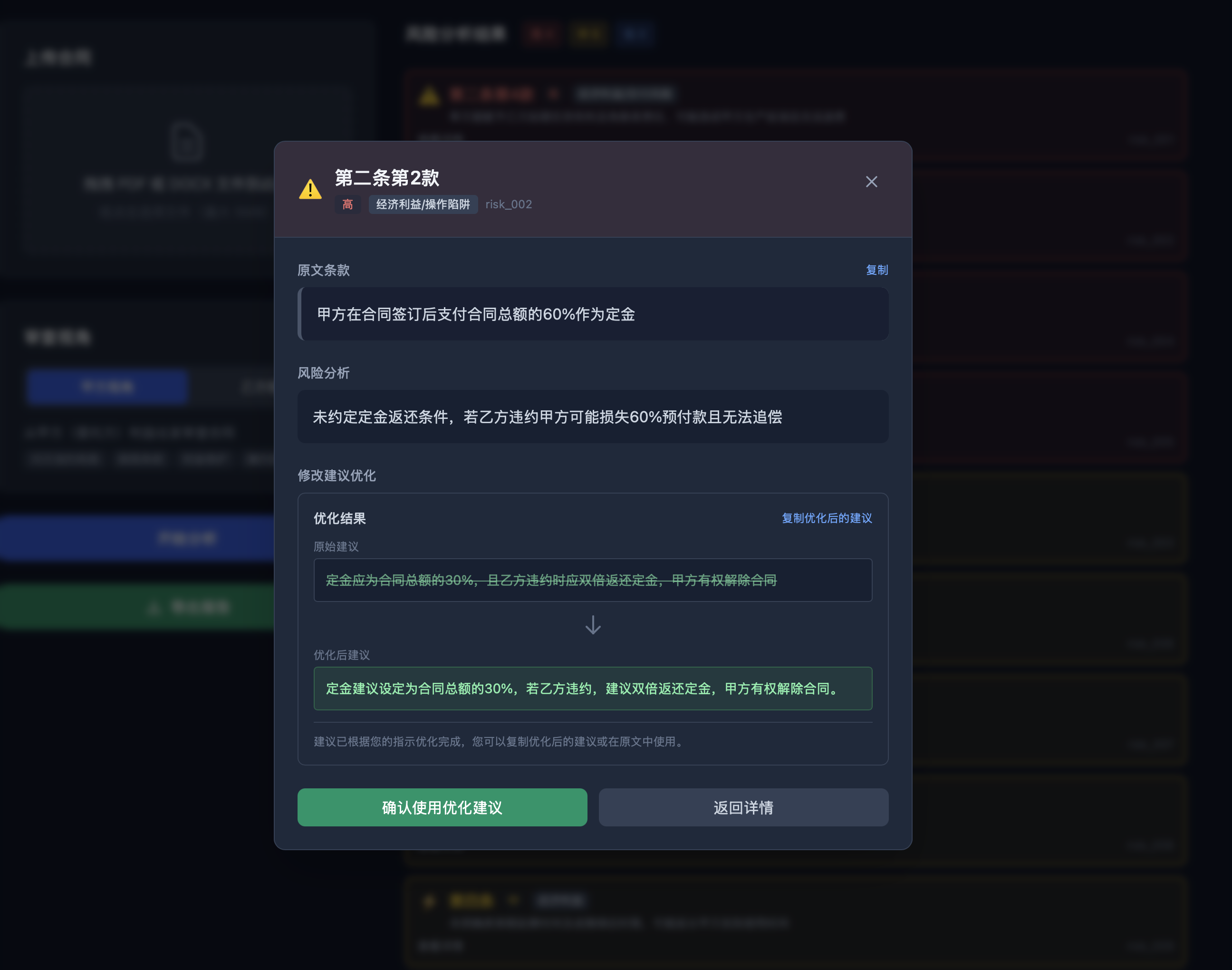
风险详情和建议
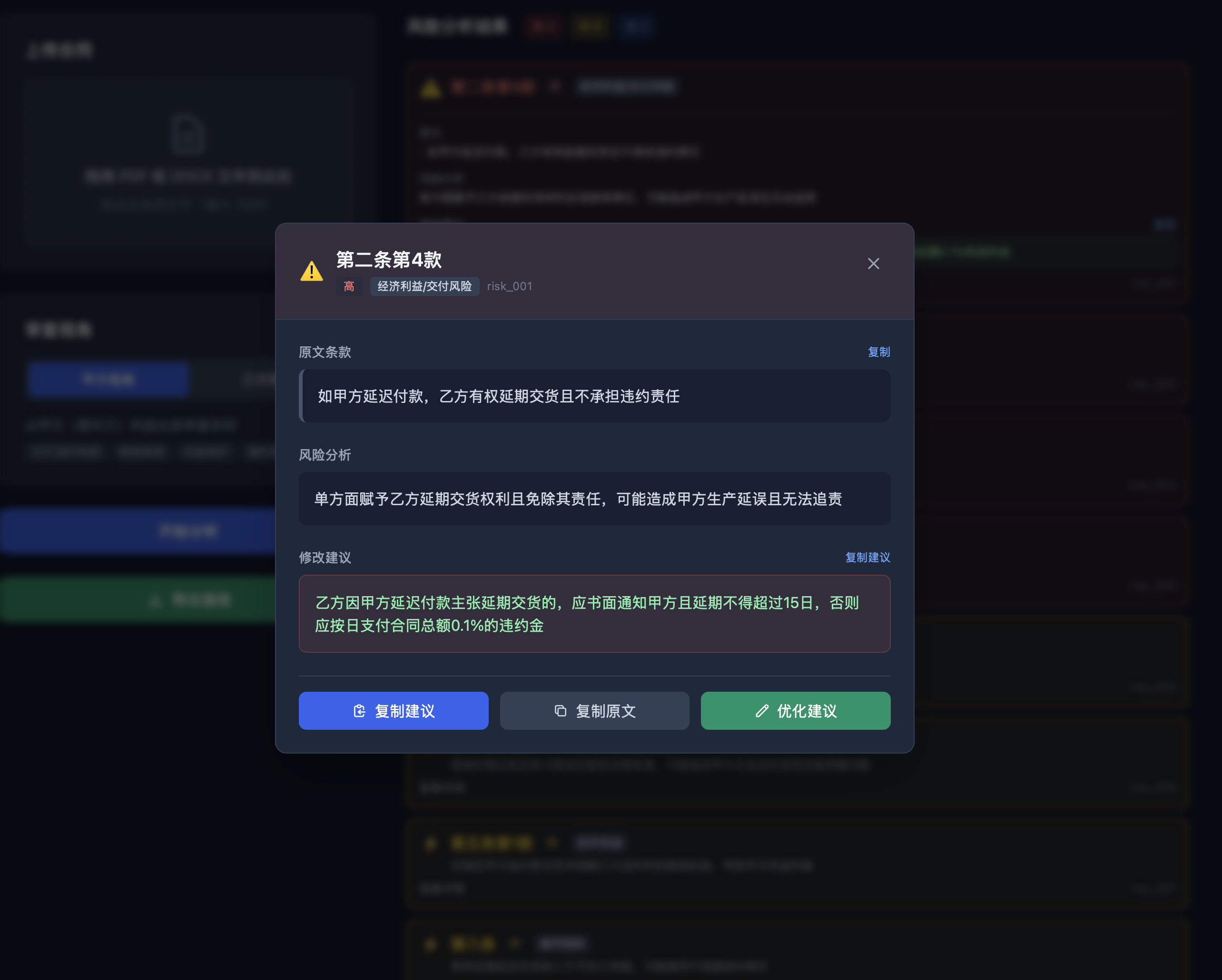
人工建议优化
二、架构设计:零信任本地优先方案
2.1 为什么这样选型
在构建本地 AI 系统时,性能与隐私的平衡是核心考量。我们选择 Ollama (Qwen3:8b) 是基于多重技术验证:首先,Qwen3 在中文法律术语理解上表现卓越,这对于合同审查这种高度依赖专业术语的场景很重要;其次,8b 版本对硬件要求低,普通配置即可流畅运行,兼顾了推理速度与逻辑深度,部署门槛大幅降低;最后,Ollama 原生支持流式输出,为实时交互体验奠定了技术基础。
FastAPI + SSE 的组合则解决了长文本分析的响应问题。传统的 RESTful 请求在处理合同分析时会产生严重的"转圈等待"------用户上传一份30页的合同,可能需要等待30秒甚至更长时间才能看到结果,期间界面一片空白,用户体验极差。采用 Server-Sent Events (SSE),可以让 AI 像人类思考一样,每识别出一个风险点就立即推送给前端,极大地缓解了用户的焦虑感。FastAPI 原生支持异步和 SSE,天然适合这种场景。
无状态设计则是出于安全考量。本项目采用内存存储,确保合同处理完即销毁,从物理层面杜绝了泄密风险。这种"零信任"架构对于处理敏感商业文档的企业来说尤为重要。
2.2 整体架构
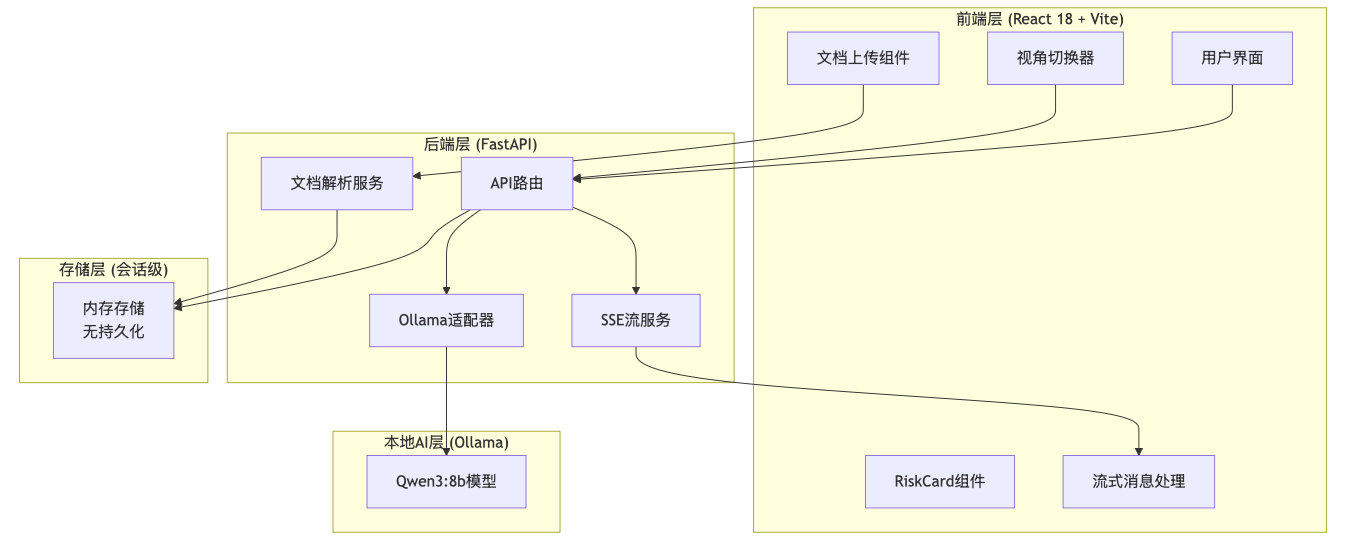
2.3 关键技术选型
| 层级 | 技术 | 选型理由 |
|---|---|---|
| AI推理 | Ollama (Qwen3:8b) | 本地部署,无需联网,中文理解能力强 |
| 后端框架 | FastAPI | 原生支持异步,自动生成OpenAPI文档 |
| 前端框架 | React 18 + TypeScript | 组件化开发,类型安全 |
| 实时通信 | SSE (Server-Sent Events) | 比WebSocket轻量,适合单向流式推送 |
| 文档解析 | PyMuPDF + python-docx | 支持PDF/DOCX双格式 |
| 动画效果 | Framer Motion | 声明式动画,流式卡片入场效果流畅 |
三、核心流程:从上传到风险展示
3.1 完整业务流程
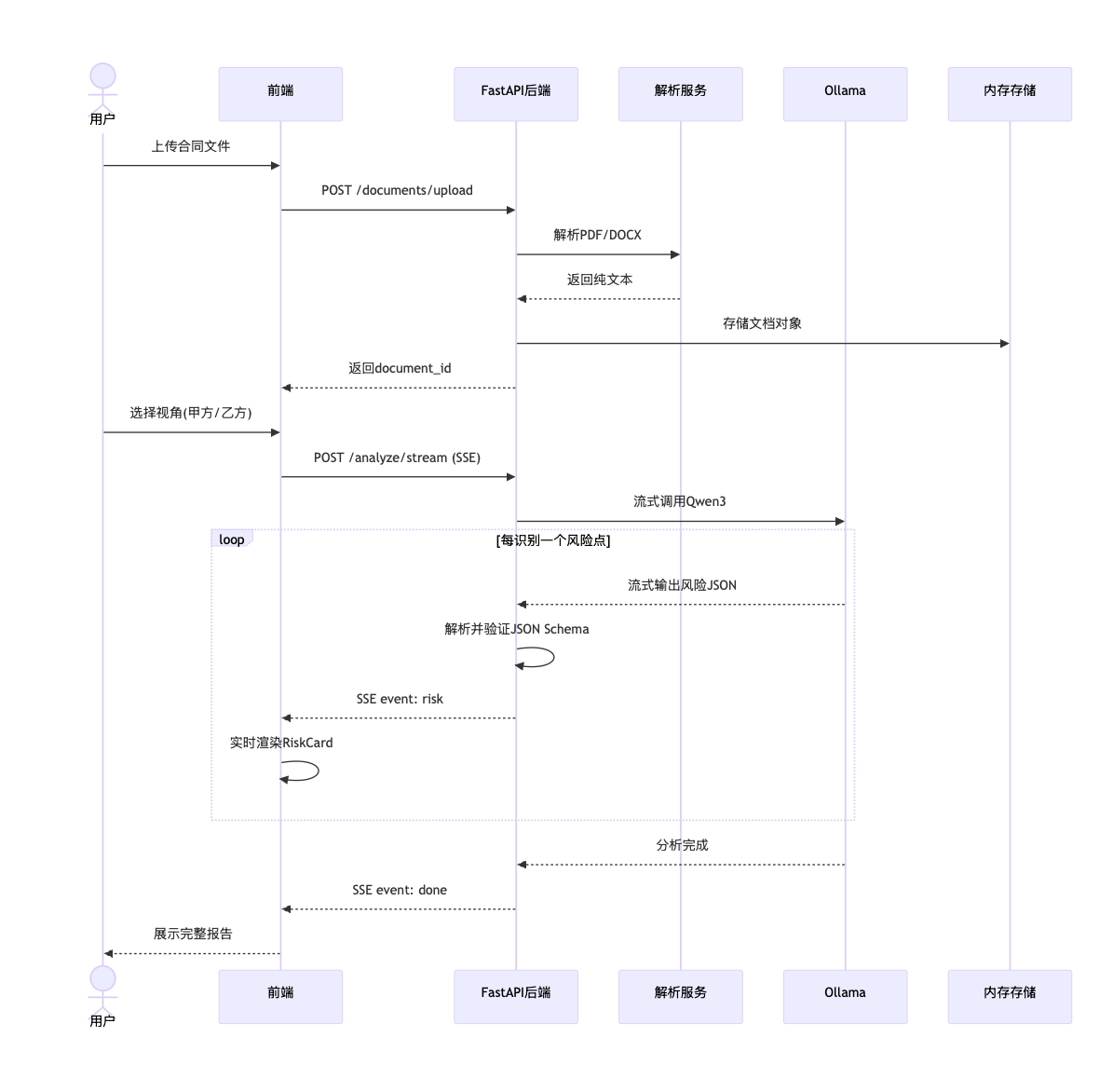
整个流程从用户上传合同开始,经过文档解析、AI分析,到最终的风险卡片展示。其中最核心的创新在于流式交互------用户不需要等待全部分析完成,而是能够实时看到每一个风险点被识别和展示的过程。
3.2 双视角Prompt设计:差异化竞争力的来源
大多数 AI 审查系统只是单纯列出风险,但法律的本质是立场。甲方眼中的"保障",可能是乙方眼中的"陷阱"。同一个合同条款,从不同视角审视,往往会得出截然不同的风险评估。
我们在后端预设了视角切换逻辑,通过动态注入 PERSPECTIVE_PROMPTS,系统会根据用户的身份(甲方/乙方)改变其思维模型。甲方模式 侧重于"交付标准"与"追责便利",关注经济利益受损风险、交付风险和操作陷阱;乙方模式则侧重于"责任上限"与"回款保障",关注责任边界不清、付款风险和续约陷阱。
这种设计让 AI 不再是一个搬运说明书的机器人,而是一个真正的"法律顾问"------它能够理解立场的差异,并据此提供差异化的风险分析。
python
# services/prompt_service.py
PERSPECTIVE_PROMPTS = {
"party_a": """作为甲方(委托方)法律顾问,审查以下合同。
重点关注:
1. 经济利益受损风险 - 违约金过高、付款条件不利、隐性费用
2. 交付风险 - 验收标准模糊、延期责任不清
3. 操作陷阱 - 自动续约、单方终止权、知识产权归属
请从保护甲方利益角度,识别所有潜在风险点。""",
"party_b": """作为乙方(服务方)法律顾问,审查以下合同。
重点关注:
1. 责任边界不清 - 无限连带责任、免责条款缺失
2. 付款风险 - 账期过长、验收后付款比例过低
3. 续约陷阱 - 自动续约条款、优先续约权限制
请从保护乙方利益角度,识别所有潜在风险点。"""
}四、核心技术深度拆解
4.1 SSE流式服务实现
为什么选择 SSE 而不是 WebSocket?这是很多开发者会面临的技术选型问题。WebSocket 是全双工通信,适用于需要客户端和服务端双向实时交换数据的场景,比如聊天应用、实时游戏。而 SSE 是单向通信,服务端可以主动向客户端推送数据,但客户端无法通过 SSE 向服务端发送消息(只能通过额外的 HTTP 请求)。
对于合同审查场景,我们的需求是单向的:服务端推送分析进度和风险卡片,客户端负责展示。这种场景下,SSE 相比 WebSocket 有几个优势:协议更简单(基于 HTTP,不需要握手升级);自动重连(浏览器原生支持,断线后自动重试);对防火墙更友好(443 端口的标准 HTTPS 请求)。
python
# services/stream_service.py
async def event_generator(
request: AnalysisRequest,
document: Document,
) -> AsyncGenerator[str, None]:
"""生成SSE事件流"""
# 发送初始状态
yield format_sse_event("status", {
"message": "开始分析合同...",
"progress": 0,
})
# 调用Ollama流式API
async for chunk in ollama.chat(
model='qwen3:8b',
messages=[...],
stream=True
):
content = chunk['message']['content']
# 实时解析JSON并推送
if risk := parse_risk_json(content):
yield format_sse_event("risk", risk.model_dump())
# 发送完成事件
yield format_sse_event("done", {
"summary": analysis.summary,
"total_risks": len(analysis.risks),
})
def format_sse_event(event_type: str, data: dict) -> str:
"""格式化为SSE事件格式"""
return f"event: {event_type}\ndata: {json.dumps(data)}\n\n"SSE 协议对格式极其敏感。每一行必须以 data: 开头,且必须以两个换行符 \n\n 结尾。漏掉一个换行符,前端的 reader 就会一直挂起等待,这是开发中常见的"隐形坑"。
4.2 前端流式消费与渲染
前端使用 fetch API 原生支持 SSE,配合 React 状态管理实现卡片动画入场。这里的 buffer 处理逻辑是关键:由于 SSE 传输是分片的,数据包可能会在中间断开。我们的前端实现通过一个 buffer 缓存未读完的字符,只有当遇到 \n\n(SSE 标准分隔符)时才尝试解析。
typescript
// services/api.ts
async analyzeStream(
request: AnalysisRequest,
onEvent: (eventType: string, data: unknown) => void
): Promise<void> {
const response = await fetch('/api/analyze/stream', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify(request),
});
const reader = response.body!.getReader();
const decoder = new TextDecoder();
let buffer = '';
while (true) {
const { done, value } = await reader.read();
if (done) break;
buffer += decoder.decode(value, { stream: true });
const parts = buffer.split('\n\n');
buffer = parts.pop() || '';
for (const part of parts) {
// 解析SSE事件
const eventType = part.split('\n')[0].slice(7).trim();
const dataLine = part.split('\n').find(l => l.startsWith('data: '));
if (dataLine) {
const data = JSON.parse(dataLine.slice(6));
onEvent(eventType, data);
}
}
}
}这种处理方式保证了即使在网络抖动或高负载下,前端渲染也不会崩溃。配合 Framer Motion 的 layout 动画,每个新发现的风险卡片会像抽屉一样滑入界面,视觉上的实时反馈能显著提升系统的"高级感"。
4.3 流式卡片动画效果
tsx
// components/RiskCard.tsx
import { motion } from 'framer-motion';
export default function RiskCard({ risk, index }) {
return (
<motion.div
initial={{ x: 50, opacity: 0 }}
animate={{ x: 0, opacity: 1 }}
transition={{
delay: index * 0.1, // 级联动画
duration: 0.3,
ease: "easeOut"
}}
className={`risk-card severity-${risk.severity}`}
>
<div className="severity-indicator" />
<h3>{risk.clause_title}</h3>
<p className="risk-description">{risk.risk_description}</p>
<div className="suggested-revision">
{risk.suggested_revision}
</div>
</motion.div>
);
}4.4 攻克LLM的不确定性:三层JSON容错解析
这是本项目最具技术含量的地方。LLM 输出的结构化数据往往是"半成品" ------多一个逗号、少一个引号、Markdown 代码块包装、甚至直接混入说明文字。传统的 json.loads() 一报错,整个分析流程就中断了。
正如代码所示,我们设计了三道防线应对这种不确定性:
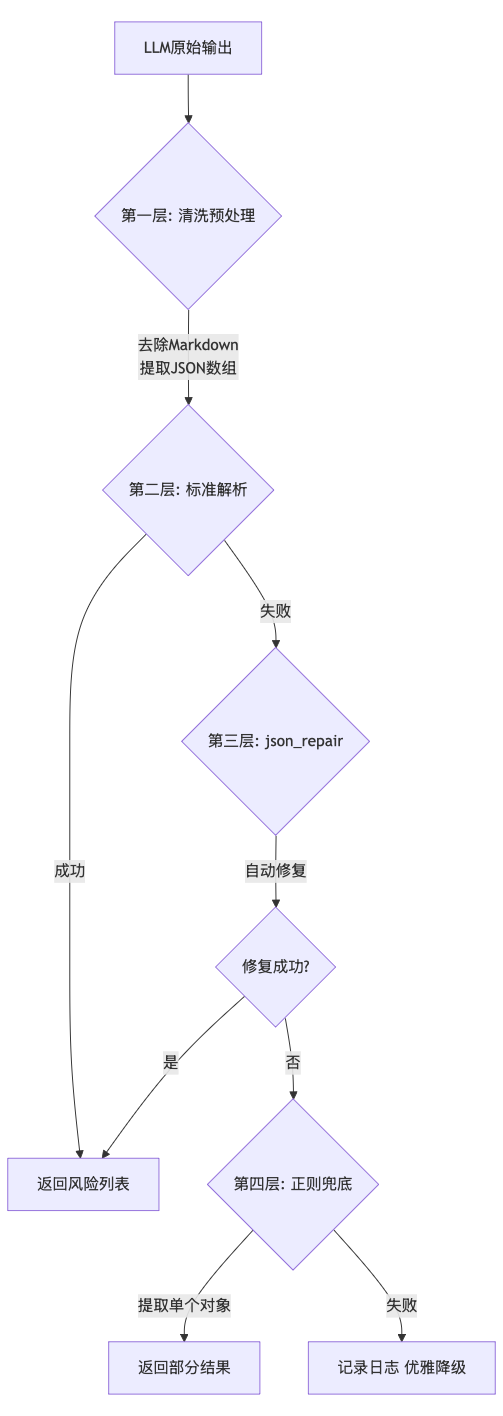
第一层:内容清洗------去除包装噪音,提取核心JSON。模型偶尔会"话多",在 JSON 后面加一句"希望这个分析对你有帮助"。这就是为什么第一层清洗至关重要。
python
def _clean_json_content(content: str) -> str:
"""清洗JSON内容,去除Markdown包装和无关文本。"""
cleaned = content.strip()
# 去除Markdown代码块包装
cleaned = cleaned.replace("```json", "").replace("```", "").strip()
# 智能提取:找到第一个'['和配对的最后一个']'
# 处理模型在JSON前后添加说明文字的情况
start_idx = cleaned.find("[")
if start_idx != -1:
bracket_count = 0
end_idx = -1
for i in range(start_idx, len(cleaned)):
if cleaned[i] == "[":
bracket_count += 1
elif cleaned[i] == "]":
bracket_count -= 1
if bracket_count == 0:
end_idx = i + 1
break
if end_idx > start_idx:
cleaned = cleaned[start_idx:end_idx]
return cleaned第二层:标准解析------对于格式规范的输出,走最快的路径。90%以上的情况在这一层就能成功解析。
第三层:自动修复 ------使用 json_repair 库进行智能修复。它能自动补全缺失的引号、删除多余的逗号,这是处理 LLM 输出的"杀手锏"。
python
from json_repair import repair_json
def parse_risk_json(content: str) -> list[dict]:
"""解析风险JSON,带三层容错修复。"""
# 清洗内容
cleaned = _clean_json_content(content)
# 第一层:标准解析
try:
return json.loads(cleaned)
except json.JSONDecodeError:
pass
# 第二层:json_repair自动修复
try:
repaired = repair_json(cleaned, ensure_ascii=False)
if isinstance(repaired, str):
data = json.loads(repaired)
else:
data = repaired
return data if isinstance(data, list) else [data]
except Exception as e:
logger.error(f"json_repair失败: {e}")
# 第三层:正则兜底,提取单个风险对象
pattern = r'\{[^{}]*(?:\{[^{}]*\}[^{}]*)*\}'
matches = re.findall(pattern, content, re.DOTALL)
risks = []
for match in matches:
try:
risk = json.loads(match)
if "clause_title" in risk and "severity" in risk:
risks.append(risk)
except:
continue
return risks第四层:正则兜底 ------如果 JSON 彻底碎裂,我们利用正则表达式强行提取符合结构的 id 和 clause_title 字段,确保系统"优雅降级"而非直接报错。
实践经验 :这套三层修复策略在实际运行中表现优异------90%以上通过第一层标准解析快速返回,8%左右的"小瑕疵"被 json_repair 自动修复,不到2%的极端情况通过正则兜底提取。
4.5 结构化JSON输出控制
LLM 的输出需要严格结构化,我们采用系统 Prompt 约束 + Pydantic 校验双重保障:
python
# models/risk.py
from pydantic import BaseModel, Field
class RiskCard(BaseModel):
"""风险卡片模型"""
id: str = Field(pattern=r"risk_\d{3}")
clause_title: str = Field(description="条款标题")
risk_category: RiskCategory = Field(description="风险类别")
original_text: str = Field(description="原文片段")
risk_description: str = Field(description="风险分析")
suggested_revision: str = Field(description="修改建议")
severity: Severity = Field(description="严重程度")
# analyzer_service.py
SYSTEM_PROMPT = """你是一个专业的合同审查助手。
输出格式要求:
1. 每个风险点必须是一个JSON对象
2. 所有字段必须使用中文
3. severity只能是:"高"、"中"、"低"
4. risk_category只能是:"经济利益"、"交付风险"、"操作陷阱"
5. 输出必须是合法的JSON数组格式
JSON Schema:
{
"id": "risk_001",
"clause_title": "条款标题",
"risk_category": "经济利益",
"original_text": "原文片段",
"risk_description": "风险分析",
"suggested_revision": "修改建议",
"severity": "高"
}"""
def parse_risk_json(text: str) -> Optional[RiskCard]:
"""从LLM输出中解析风险卡片"""
try:
# 尝试解析JSON
data = json.loads(text)
return RiskCard.model_validate(data)
except ValidationError as e:
logger.warning(f"JSON解析失败: {e}")
return None五、项目实战中的避坑指南
在开发过程中,我们踩过了几个典型的"坑",分享给大家:
5.1 难点一:SSE事件解析错误
问题:前端解析 SSE 事件时,由于正则处理不当,将整段内容作为 eventType,导致事件匹配失败。
现象:后端日志显示风险已发送,但前端界面不显示。
解决:改为按行分割解析,取第一行作为事件类型:
typescript
// 修复前(错误)
const eventType = part.slice(7).trim(); // 包含整个事件内容
// 修复后(正确)
const eventType = part.split('\n')[0].slice(7).trim(); // 只取第一行5.2 难点二:视角切换后的状态污染
问题:用户查看某条风险后,切换到其他风险卡片,弹窗仍显示之前的信息。
原因 :React 状态未在风险切换时重置,导致 modalState 和 refinedSuggestion 残留。
解决 :添加 useEffect 监听风险 ID 变化,自动重置状态:
tsx
// RiskDetailModal.tsx
useEffect(() => {
setModalState('view');
setRefinedSuggestion(null);
}, [risk?.id]); // 风险变化时重置经验 :在切换视角重新分析时,必须清空 React 的 risks 状态数组。否则,新旧风险点会混在一起,造成逻辑混乱。
5.3 难点三:LLM输出格式不稳定
这个问题在上文已经详细讨论,此处不再赘述。核心经验是:只要你的 LLM 返回 JSON,就很值得加一层这样的"自愈能力"。与其反复调试 Prompt 让模型"更乖",不如在代码层面做好容错------毕竟,模型是不可控的,但代码是可控的。
六、项目效果展示
6.1 核心功能一览
| 功能模块 | 实现效果 |
|---|---|
| 文档上传 | 支持PDF/DOCX,自动格式识别 |
| 风险分析 | 30秒内开始展示风险卡片 |
| 视角切换 | 甲方/乙方视角风险列表差异达60%+ |
| 建议优化 | 自然语言指令调整修改建议语气 |
| 报告导出 | Markdown/Word双格式支持 |
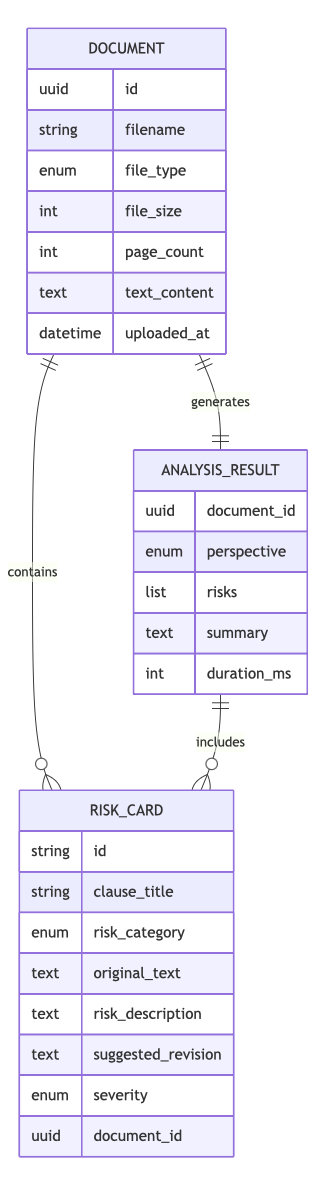
6.2 数据模型关系
七、总结与展望
7.1 技术亮点回顾
- 完全本地运行:Ollama 本地部署,合同数据不出本机,满足敏感信息保护需求
- 流式交互体验:SSE 实时推送 + Framer Motion 动画,打造沉浸式审查体验
- 双视角差异化分析:通过 Prompt 工程实现同一合同的多立场风险识别
- 类型安全:Pydantic + TypeScript 前后端类型对齐,减少运行时错误
- 三层容错解析:优雅应对 LLM 的"不确定性输出"
通过这套架构说明,仅靠开源工具也能打造专业级的法务工具。
7.2 未来路线图
RAG 增强:接入《民法典》和行业案例库,让 AI 的修改建议不仅有逻辑,更有法律依据。
私有化知识库:允许企业上传自己的"标准合同样本",让 AI 学习自有的风控偏好。
持久化存储:当前为会话级存储,可添加 SQLite 本地存储历史记录,方便追溯和管理。
协作功能:支持多人协作审查,添加批注和讨论,提升团队协作效率。
写在最后 :
AI 不是要取代律师,而是要将律师从繁琐的格式审查中解放出来,去处理更有价值的交易架构设计。如果你也对本地化 AI 应用感兴趣,欢迎在评论区交流。
项目源代码
完整的项目代码和更详细的实现,请访问我的知识星球( https://t.zsxq.com/CCi0k ),获取完整系统项目源代码。