通过静态分析实现按需加载
根据上文我们知道 App.vue 的模板内容会被编译成:
import { resolveComponent as _resolveComponent, createVNode as _createVNode, openBlock as _openBlock, createElementBlock as _createElementBlock } from "vue"
export function render(_ctx, _cache, $props, $setup, $data, $options) {
const _component_my_button = _resolveComponent("my-button")
return (_openBlock(), _createElementBlock("template", null, [
_createVNode(_component_my_button)
]))
}那么根据上文我们知道需要把 _resolveComponent("my-button") 部分替换成对应的组件对象,内容如下:
+ import MyButton from 'vite-ui/dist/components/button'
+ import 'vite-ui/dist/style.css'
import { resolveComponent as _resolveComponent, createVNode as _createVNode, openBlock as _openBlock, createElementBlock as _createElementBlock } from "vue"
export function render(_ctx, _cache, $props, $setup, $data, $options) {
- const _component_co_button = _resolveComponent("my-button")
+ const _component_co_button = MyButton
return (_openBlock(), _createElementBlock("template", null, [
_createVNode(_component_co_button)
]))
}那么要实现上述功能,我们得通过 Vite 插件来实现,我们在上面安装了一个 @vitejs/plugin-vue 插件,这个 Vite 插件的主要功能就是把 .vue 文件编译成上述的 js 内容。那么我们这样在它的后面继续添加一个插件在编译后的 js 内容中去实现上述替换功能即可。
我们在 ./packages/utils/index.js 文件中实现这个自动加载组件的 Vite 插件,实现如下:
import MagicString from "magic-string";
export default function VitePluginAutoComponents() {
return {
// 插件名称,用于调试和错误信息
name: "vite-plugin-auto-component",
// transform 钩子函数,在转换模块时调用
// code: 文件内容,id: 文件路径
transform(code, id) {
// 使用正则表达式检查文件是否为.vue文件
// 如果不是.vue文件,不进行处理
if (/\.vue$/.test(id)) {
// 创建 MagicString 实例,用于高效地修改字符串并生成 source map
const s = new MagicString(code);
// 初始化结果数组,用于存储匹配到的组件信息
const results = [];
// 使用 matchAll 方法查找所有匹配的 resolveComponent 调用
// 正则表达式解释:
// _?resolveComponent\d* - 匹配可能的函数名变体(可能带下划线或数字后缀)
// \("(.+?)"\) - 匹配括号内的字符串参数
// g - 全局匹配
for (const match of code.matchAll(
/_?resolveComponent\d*\("(.+?)"\)/g,
)) {
// match[1] 是第一个捕获组,即组件名称字符串
const matchedName = match[1];
// 检查匹配是否有效:
// match.index != null - 确保有匹配位置
// matchedName - 确保捕获到组件名
// !matchedName.startsWith('_') - 确保组件名不以_开头(可能是内部组件)
if (
match.index != null &&
matchedName &&
!matchedName.startsWith("_")
) {
// 计算匹配字符串的起始位置
const start = match.index;
// 计算匹配字符串的结束位置
const end = start + match[0].length;
// 将匹配信息存入结果数组
results.push({
rawName: matchedName, // 原始组件名称
// 创建替换函数,使用 MagicString 的 overwrite 方法替换指定范围的文本
replace: (resolved) => s.overwrite(start, end, resolved),
});
}
}
// 遍历所有匹配结果进行处理
for (const { rawName, replace } of results) {
// 定义要替换的变量名(这里暂时编码为 MyButton)
const varName = `MyButton`;
// 在代码开头添加导入语句:
// 1. 导入 MyButton 组件
// 2. 导入样式文件
// 这样写,生成的代码就是干净的两行,没有前导空格
s.prepend(
"\nimport MyButton from 'vite-ui/dist/components/button';\nimport 'vite-ui/dist/style.css';\n",
);
// 执行替换:将 resolveComponent("xxx") 调用替换为组件变量名
replace(varName);
}
// 返回转换后的代码
return {
code: s.toString(), // 转换后的代码字符串
map: null,
};
}
},
};
}我们在上述 Vite 插件中使用到了一个新工具库 magic-string,我们需要安装一下它的依赖:
pnpm add magic-string -D -wmagic-string 是一个专注于字符串操作,主要作用是对源代码可以进行精准的插入、删除、替换等操作。
上述编写的 Vite 的插件主要是实现在.vue 文件中查找所有形如 resolveComponent("xxx") 的函数调用,对于每一个找到的调用,它会在文件顶部添加一个固定的导入语句,例如导入 MyButton 组件和样式。最后把找到的resolveComponent("xxx") 替换成对应的组件,例如 MyButton。
然后我们在根目录重新打包,接着在 play 目录中的 vite.config.js 文件中进行以下修改:
import { defineConfig } from 'vite'
import vue from '@vitejs/plugin-vue'
+ import AutoComponents from 'vite-ui/dist/utils'
// https://vite.dev/config/
export default defineConfig({
- plugins: [vue()],
+ plugins: [vue(), AutoComponents()],
})接着我们再次重启 play 测试项目,我们可以看到即便我们不导入任何我们编写的组件库设置,我们依然可以在 play 项目中成功使用 MyButton 组件。
同时我们在网络窗口可以查看到 App.vue 文件的内容变化如下:
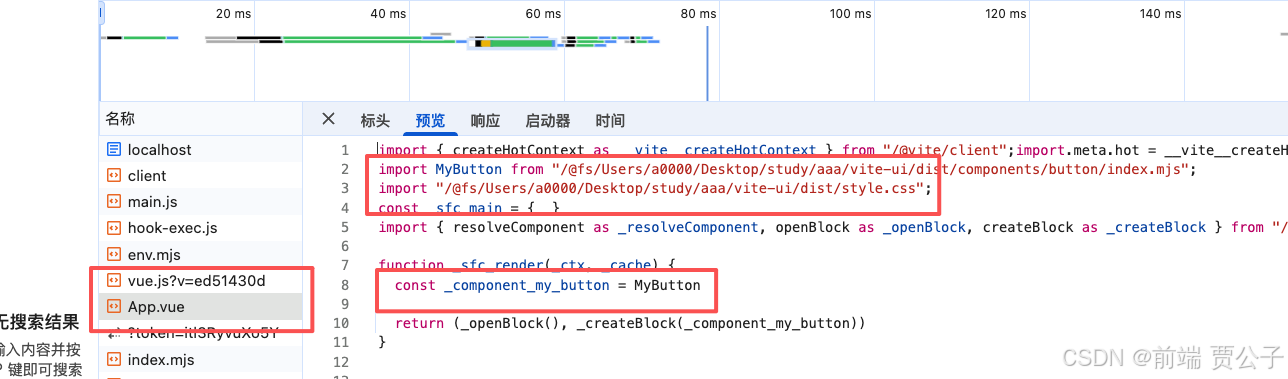
可以看到我们通过静态分析代码,识别并替换 Vue3 的组件解析函数,成功实现了组件的自动导入功能 。但上述实现为了快速验证功能,无论匹配到的组件名是什么,都导入 MyButton 组件,并替换为 MyButton。这显然是不正确的,应该根据匹配到的组件名动态导入对应的组件。
自动化路径解析
因为我们的组件编译后的调用变成 _resolveComponent("my-button"),组件名称变成了 my-button,而我们在导入的语句是这样的 import MyButton from 'vite-ui/dist/components/button',组件名称又需要变成 MyButton,所以我们需要把匹配到的 my-button 变成 MyButton。
// 将字符串转换为帕斯卡命名(即大驼峰,每个单词首字母大写)
export function pascalCase(str) {
return capitalize(camelCase(str));
}
// 将字符串转换为驼峰命名
export function camelCase(str) {
return str.replace(/-(\w)/g, (_, c) => (c ? c.toUpperCase() : ""));
}
// 将字符串的首字母大写,使用 charAt(0) 获取第一个字符并转换为大写,然后加上剩余字符串(从索引1开始)
export function capitalize(str) {
return str.charAt(0).toUpperCase() + str.slice(1);
}
export default function VitePluginAutoComponents() {
return {
// 插件名称,用于调试和错误信息
name: 'vite-plugin-auto-component',
// transform 钩子函数,在转换模块时调用
// code: 文件内容,id: 文件路径
transform(code, id) {
// 使用正则表达式检查文件是否为.vue文件
// 如果不是.vue文件,不进行处理
if(/\.vue$/.test(id)) {
// 省略...
// 遍历所有匹配结果进行处理
for (const { rawName, replace } of results) {
// 将字符串转换为大驼峰
const name = pascalCase(rawName);
// 只处理 My 开头的组件
if (!name.match(/^My[A-Z]/)) return;
// 定义要替换的变量名
const varName = name;
// 在代码开头添加导入语句:
// 1. 导入 MyButton 组件
// 2. 导入样式文件
// 这样写,生成的代码就是干净的两行,没有前导空格
s.prepend(
`\nimport ${varName} from 'vite-ui/dist/components/button';\nimport 'vite-ui/dist/style.css';\n`,
);
// 执行替换:将 resolveComponent("xxx") 调用替换为组件变量名
replace(varName);
}
// 返回转换后的代码
return {
code: s.toString(), // 转换后的代码字符串
map: null,
}
}
},
}
}经过上述实现还是存在以下问题,无论 rawName 是什么,组件都是从 'vite-ui/dist/components/button' 这个固定路径导入。这意味着即使使用了 resolveComponent("MyTable"),插件依然会尝试从 button 文件导入,这显然是不正确的。理想情况下,导入路径应根据组件名动态生成。所以我们继续实现动态组件路径,例如 MyTableColumn 组件映射到 'vite-ui/dist/components/table-column'。
我们上述的组件是 "MyButton",那么转换过程则是:
"MyButton" -> 去掉"My" -> "Button" -> kebabCase -> "button"。
我们通过实现一个 kebabCase 函数进行组件路径转换解析,实现如下:
import MagicString from "magic-string";
// 将字符串转换为帕斯卡命名(即大驼峰,每个单词首字母大写)
export function pascalCase(str) {
return capitalize(camelCase(str));
}
// 将字符串转换为驼峰命名
export function camelCase(str) {
return str.replace(/-(\w)/g, (_, c) => (c ? c.toUpperCase() : ""));
}
// 将字符串的首字母大写,使用 charAt(0) 获取第一个字符并转换为大写,然后加上剩余字符串(从索引1开始)
export function capitalize(str) {
return str.charAt(0).toUpperCase() + str.slice(1);
}
// 将驼峰命名的字符串转换为短横线分隔的字符串(即kebab-case)
export function kebabCase(key) {
const result = key.replace(/([A-Z])/g, " $1").trim();
return result.split(" ").join("-").toLowerCase();
}
export default function VitePluginAutoComponents() {
return {
// 插件名称,用于调试和错误信息
name: "vite-plugin-auto-component",
// transform 钩子函数,在转换模块时调用
// code: 文件内容,id: 文件路径
transform(code, id) {
// 使用正则表达式检查文件是否为.vue文件
// 如果不是.vue文件,不进行处理
if (/\.vue$/.test(id)) {
// 省略...
// 遍历所有匹配结果进行处理
for (const { rawName, replace } of results) {
// 将字符串转换为大驼峰
const name = pascalCase(rawName);
// 只处理 My 开头的组件
if (!name.match(/^My[A-Z]/)) return;
// 组件路径转换
const partialName = kebabCase(name.slice(2));
// 定义要替换的变量名
const varName = name;
// 在代码开头添加导入语句:
// 1. 导入 MyButton 组件
// 2. 导入样式文件
// 这样写,生成的代码就是干净的两行,没有前导空格
s.prepend(
`\nimport ${varName} from 'vite-ui/dist/components/${partialName}';\nimport 'vite-ui/dist/style.css';\n`,
);
// 执行替换:将 resolveComponent("xxx") 调用替换为组件变量名
replace(varName);
}
// 返回转换后的代码
return {
code: s.toString(), // 转换后的代码字符串
map: null,
};
}
},
};
}经过上述迭代后,我们重新打包,重新启动 play 测试项目,我们发现我们的代码是能够正常运行的,说明我们上述的迭代是没有问题的。至此我们为组件自动导入提供了核心的路径解析能力。
引入解析器 (Resolver) 概念
当前插件硬编码了组件库的路径和样式文件,只能用于特定的组件库(vite-ui)。我们可以通过引入解析器(Resolver),让插件支持不同的组件库,用户可以根据需要配置不同的解析器。
解析器的作用是根据组件名返回一个解析结果,包括组件的导入路径和样式文件路径以及组件原始名称。这样,插件就可以通过解析器返回的对象信息动态获取组件的导入信息,而不是固定写死。
在实现解析器之前,我们先设计解析器返回的对象结构如下:
const component = {
name, // 组件原始名称
from: `vite-ui/dist/components/${partialName}`, // 组件的导入路径
sideEffects: ['vite-ui/dist/style.css'] // 组件的样式文件路径
}为什么要这样设计?
- 组件名 (name):
用于在导入语句中作为标识符。这里使用的是帕斯卡命名,因为它在 Vue 中通常用于组件注册和模板中。 - 导入路径 (from):
这里使用模板字符串动态构建导入路径。其中,partialName是通过将组件名去掉前两个字符(即去掉"My")并转换为 kebab-case 得到的。
例如,组件名 "MyTableColumn" 转换为 "table-column",然后拼接成路径 'vite-ui/dist/components/table-column'。
这样设计是因为组件库的目录结构可能是按照 kebab-case 命名的,而组件在代码中是以帕斯卡命名使用的。 - 副作用 (sideEffects):
这是一个数组,指定在导入组件时需要同时导入的样式文件或其他资源。这里指定了组件库的全局样式文件。
注意:这个样式文件是全局的,也就是说,不管导入哪个组件,都会导入整个组件库的样式。这可能会造成样式冗余。
更精细的做法是为每个组件指定其对应的样式文件,例如:
sideEffects: `vite-ui/dist/components/${partialName}/style.css`
但是,我们当前组件库没有为每个组件单独提供样式文件,我们只提供了固定的全局样式文件。
上面设计解析器返回的对象封装了组件的完整导入信息,作为数据载体传递给后续处理函数,我们可以基于此进行迭代:
// 省略...
// 根据传入的信息生成对应的导入语句字符串
export function stringifyImport(info) {
if (typeof info === "string") return `import '${info}'`;
if (!info.as) return `import '${info.from}'`;
else if (info.name)
return `import { ${info.name} as ${info.as} } from '${info.from}'`;
else return `import ${info.as} from '${info.from}'`;
}
// 根据组件的导入信息生成完整的导入语句,包括组件本身的导入和其副作用(如样式文件)的导入。
export function stringifyComponentImport({
as: name,
from: path,
name: importName,
sideEffects,
}) {
const imports = [
// 生成组件导入语句
stringifyImport({ as: name, from: path, name: importName }) + ";",
];
if (sideEffects) {
// 生成副作用导入语句
sideEffects.forEach((i) => imports.push(stringifyImport(i) + ";"));
}
return imports.join("\n");
}
export default function VitePluginAutoComponents() {
return {
// 插件名称,用于调试和错误信息
name: "vite-plugin-auto-component",
// transform 钩子函数,在转换模块时调用
// code: 文件内容,id: 文件路径
transform(code, id) {
// 使用正则表达式检查文件是否为.vue文件
// 如果不是.vue文件,不进行处理
if (/\.vue$/.test(id)) {
// 省略...
let no = 0;
// 遍历所有匹配结果进行处理
for (const { rawName, replace } of results) {
// 将字符串转换为大驼峰
const name = pascalCase(rawName);
// 只处理 My 开头的组件
if (!name.match(/^My[A-Z]/)) return;
// 组件路径转换
const partialName = kebabCase(name.slice(2));
// 封装了组件的完整导入信息,作为数据载体传递给后续处理函数
const component = {
name,
from: `vite-ui/dist/components/${partialName}`,
sideEffects: ["vite-ui/dist/style.css"],
};
// 使用特殊前缀减少与用户变量的冲突,以及使用递增的序号,保证唯一性,避免变量名冲突
const varName = `__unplugin_components_${no}`;
// 在代码开头添加导入语句:
// 1. 导入 MyButton 组件
// 2. 导入样式文件
// 这样写,生成的代码就是干净的两行,没有前导空格
s.prepend(
`\n${stringifyComponentImport({ ...component, as: varName })}\n`,
);
no += 1;
// 执行替换:将 resolveComponent("xxx") 调用替换为组件变量名
replace(varName);
}
// 返回转换后的代码
return {
code: s.toString(), // 转换后的代码字符串
map: null,
};
}
},
};
}我们添加了根据传入的信息生成对应的导入语句字符串的 stringifyImport 函数和根据组件的导入信息生成完整的导入语句,包括组件本身的导入和其副作用(如样式文件)的导入的 stringifyComponentImport 函数。其中 stringifyImport 处理单一导入语句,stringifyComponentImport 处理组合多个相关导入,实现了职责分离和配置灵活的设计优势。这两个函数共同构成了一个灵活的导入语句生成系统,为自动导入插件提供了强大的代码生成能力。
我们设计了一个解析结果包括:name(组件名)、from(导入路径)、sideEffects(样式等副作用导入)的数据结构对象 component 作为数据载体传递给后续处理函数,后续程序基于此来生成导入语句和替换代码。
其中变量名生成策略使用特殊前缀减少与用户变量的冲突从而避免污染 ,同时使用递增序号来保证唯一性。
最终我们实现了一个基于数据驱动的架构,将来解析器只负责识别组件和返回路径的数据信息,然后导入生成器函数,也就是上述的 stringifyComponentImport 和 stringifyImport 负责根据配置生成导入代码,我们整体的 Vite 插件就只负责协调流程和代码修改。
这种架构为后续引入真正的多解析器支持奠定了良好基础,只需要将硬编码的解析逻辑替换为可配置的解析器数组即可。