Chatting with Images for Introspective Visual Thinking
Authors: Junfei Wu, Jian Guan, Qiang Liu, Shu Wu, Liang Wang, Wei Wu, Tienie Tan
Deep-Dive Summary:
Chatting with Images for Introspective Visual Thinking (内省式视觉思维的"图像对话")
摘要
当前的大型视觉语言模型(LVLM)通常依赖于基于单次视觉编码的纯文本推理,这往往会导致细粒度视觉信息的丢失。最近提出的"用图像思考"(thinking with images)尝试通过外部工具或代码操作图像来缓解这一限制;然而,产生的视觉状态往往缺乏语言语义支撑,削弱了有效的跨模态对齐------特别是当视觉语义或几何关系需要在遥远区域或多张图像之间进行推理时。为了应对这些挑战,我们提出了"与图像对话"(chatting with images),这是一种将视觉操作重新定义为语言引导的特征调制的新框架。在富有表现力的语言提示引导下,模型动态地对多个图像区域进行联合重编码,从而实现语言推理与视觉状态更新之间更紧密的耦合。我们在 ViLAVT 中实例化了这一范式。ViLAVT 是一款新型 LVLM,配备了专门为此类交互式视觉推理设计的动态视觉编码器,并通过结合监督微调(SFT)和强化学习(RL)的两阶段课程进行训练,以促进有效的推理行为。在八个基准测试上的广泛实验表明,ViLAVT 取得了显著且一致的改进,特别是在复杂的多图像和基于视频的空间推理任务中收益尤为突出。
1. 引言
大型语言模型(LLM)通过长期的认知深思在复杂问题解决方面建立了新的前沿,展示了在数学和软件工程等领域令人印象深刻的能力。这激励了研究者赋予大型视觉语言模型(LVLM)类似的认知能力。尽管取得了进展,但主流的推理范式仍主要遵循"思考图像"(thinking about images)的工作流,并受限于单次视觉编码:模型先产生一组固定的视觉 token,随后主要在语言空间进行推理。这种设计假设静态视觉 token 可以保留丰富的视觉语义,但在实践中,任务相关的细节在压缩过程中会丢失,并随着纯文本推理的进行而进一步减弱,尤其是在多图空间推理中。
为了超越这一限制,近期研究倡导向"用图像思考"范式转变,模型将文本推理与有针对性的视觉操作交织在一起,并迭代地重新编码视觉输入。现有的尝试主要集中在两类操作:(1)基于工具的操作(如图像旋转);(2)编程操作(生成可执行代码)。然而,这些方法大多针对单图,且操作接口局限于低级像素/几何操作,难以表达高级关系意图。
为此,我们开发了 ViLAVT,它将视觉操作重新定义为语言引导的特征调制。我们重新架构了视觉编码器,使其能根据文本查询动态地联合处理多个非连续图像区域。
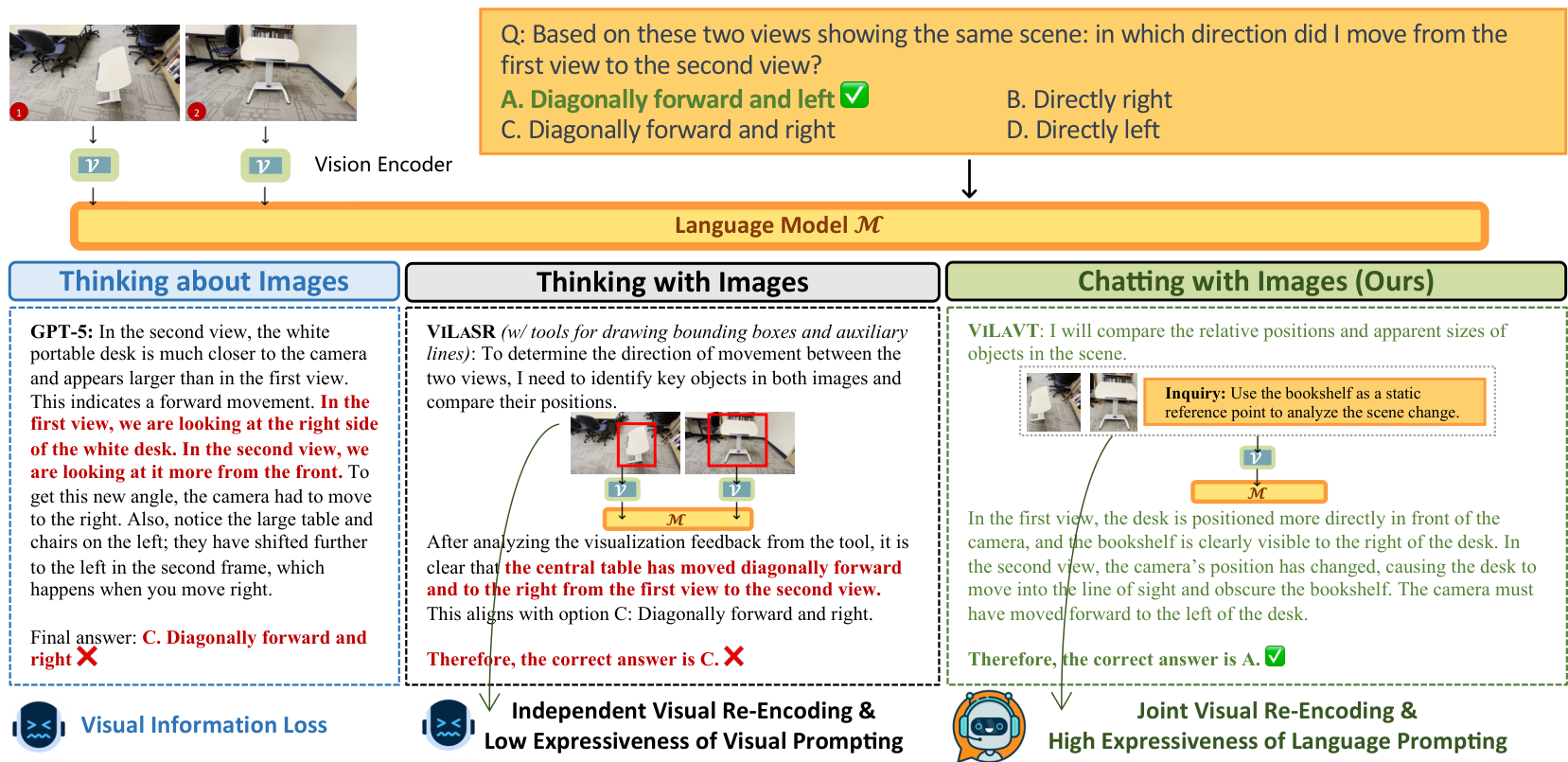
图 1:三种推理范式在多视图空间推理任务上的定性比较。
- "思考图像"(左):静态 LVLM 依赖一次性视觉编码,导致信息丢失和错误答案。
- "用图像思考"(中):通过外部工具突出显着信息并独立重编码各图,但缺乏表达力,无法传达认知意图。
- "与图像对话"(右,本文方法):利用语言提示表达高层认知意图,引导对两张图进行联合视觉重编码,在特征层面实现关系比较,从而得出正确推理。
2. 相关工作
2.1 思考图像 (Thinking about Images)
大多数最先进的 LVLM 属于此类。它们通过强大的视觉编码器将图像处理一次,生成视觉嵌入并投影到语言空间,作为 LLM 的静态"视觉前缀"。核心瓶颈是不可逆的信息丢失,因为高维视觉数据被过度压缩成有限的 token 序列。
2.2 用图像思考 (Thinking with Images)
近期研究探索了交互式推理,主要分为三类:(1)基于工具的操作 :调用外部工具,但工具的"黑盒"性质阻止了端到端优化,且工具集有限;(2)编程操作 :生成脚本进行图像处理,但存在高延迟和低表达力问题;(3)生成想象:合成新图像作为中间步骤,但计算量大且存在脱离原始数据的推理风险。相比之下,我们的框架通过语言的组合能力表达认知意图,并通过动态特征调制解决信息丢失问题。
3. 方法论
3.1 "与图像对话"范式
我们将视觉推理形式化为生成轨迹 τ = ( s 1 , s 2 , ... , s T ) \tau = (s_1, s_2, \ldots, s_T) τ=(s1,s2,...,sT) 的过程,其中每一步 s t s_t st 是一个三元组 ( r t , q t , z t ) (r_t, q_t, z_t) (rt,qt,zt):
- r t r_t rt:模型的文本推理过程。
- q t q_t qt:引导视觉编码器进行目标特征重计算的文本查询。
- z t z_t zt:一组目标视觉区域,由索引和边界框 { ( n t i , b t i ) } i = 1 M t \{(n_t^i, b_t^i)\}_{i=1}^{M_t} {(nti,bti)}i=1Mt 定义。
推理过程如下:框架从前序图像中裁剪出 z t z_t zt 指定的区域,放大后输入视觉编码器 V \mathcal{V} V。编码器联合处理查询 q t q_t qt 和区域 C t \mathcal{C}_t Ct 产生新特征 f t = V ( C t , q t ) f_t = \mathcal{V}(\mathcal{C}_t, q_t) ft=V(Ct,qt),并反馈给语言模型 M \mathcal{M} M。迭代过程公式如下:
s t + 1 ∼ M ( ⋅ ∣ f 0 , Q , { ( s k , f k ) } k = 1 t ) ( 1 ) s_{t + 1} \sim \mathcal{M}\left(\cdot \mid f_{0}, Q, \{(s_{k}, f_{k})\}_{k = 1}^{t}\right) \quad (1) st+1∼M(⋅∣f0,Q,{(sk,fk)}k=1t)(1)
其中 f 0 f_0 f0 为初始全帧编码。
3.2 视觉编码器架构
我们的动态视觉编码器 V \mathcal{V} V 需要具备解释文本查询和联合处理多个不连续区域的能力。公式如下:
V ( C , q ) = V e ( P 1 ⊕ P 2 ⊕ ... P U ⊕ h q ) , ( 2 ) \mathcal{V}(\mathcal{C}, q) = \mathcal{V}{e}(\mathbf{P}{1} \oplus \mathbf{P}{2} \oplus \dots \mathbf{P}{U} \oplus \mathbf{h}{q}), \quad (2) V(C,q)=Ve(P1⊕P2⊕...PU⊕hq),(2)
h q = V m ( q ) , ( 3 ) \mathbf{h}{q} = \mathcal{V}_{m}(q), \quad (3) hq=Vm(q),(3)
其中 V e \mathcal{V}_e Ve 是视觉 Transformer, V m \mathcal{V}_m Vm 是轻量级语言 Transformer。该设计允许在特征提取过程中进行查询引导的跨区域交互。我们采用混合注意力策略来平衡计算成本和表达能力。
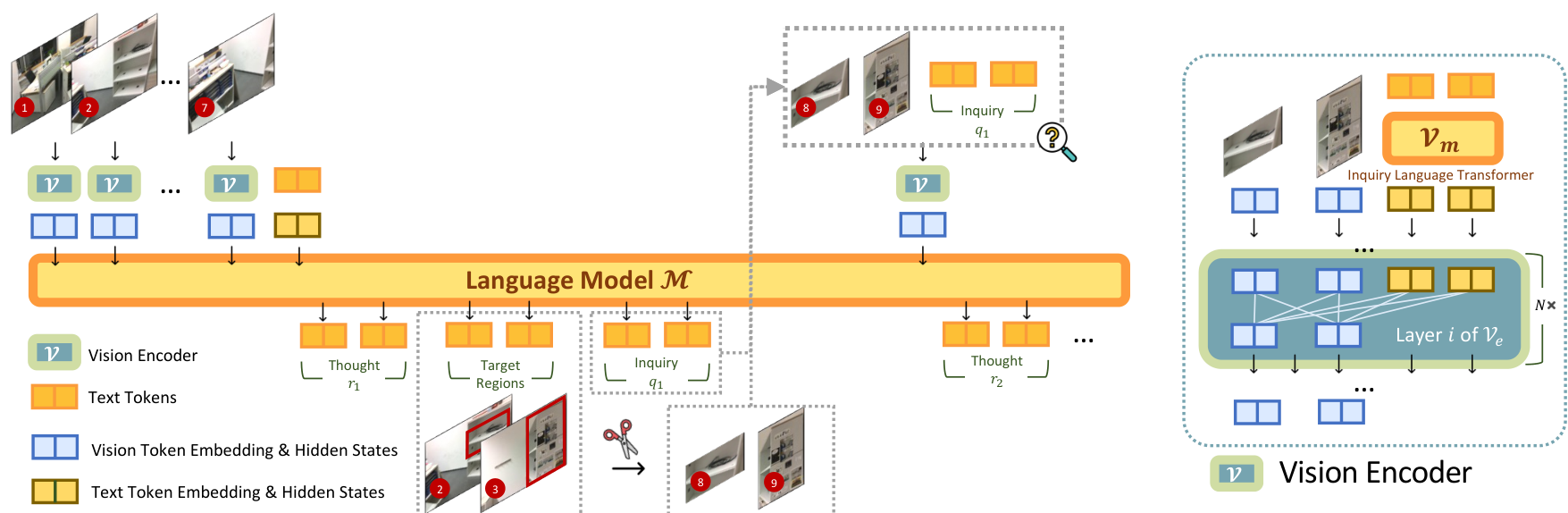
图 2:ViLAVT 的迭代推理过程(左)与动态视觉编码器架构(右)。
3.3 监督微调 (SFT)
我们构建了一个大规模多域数据集 D S F T \mathcal{D}_{\mathrm{SFT}} DSFT,包含两部分:
- 重构现有数据:将基于工具或代码的外部操作翻译为"与图像对话"的三元组格式。
- 合成复杂空间推理轨迹:通过程序化挖掘潜在空间知识(如目标定位、相机运动估计),合成为高质量的推理轨迹。
训练目标采用标准的最大似然估计:
L S F T = − E ( I , Q , { s t } t = 1 T ) ∼ D S F T ∑ t = 1 T log π θ ( s t ∣ I , Q , s < t ) . ( 4 ) \mathcal{L}{\mathrm{SFT}} = -\mathbb{E}{(\mathcal{I},Q,\{s_t\}{t = 1}^T)\sim \mathcal{D}{\mathrm{SFT}}}\sum_{t = 1}^T\log \pi_{\theta}(s_t\mid \mathcal{I},Q,s< t). \quad (4) LSFT=−E(I,Q,{st}t=1T)∼DSFTt=1∑Tlogπθ(st∣I,Q,s<t).(4)
3.4 强化学习 (RL)
使用 GRPO 算法对策略进行优化。奖励函数基于结果(Outcome-based):
R ( τ ) = 1 ( R c o r r e c t > 0 ) ( R c o r r e c t + R f o r m a t ) , ( 5 ) R(\tau) = \mathbb{1}(R_{\mathrm{correct}} > 0)(R_{\mathrm{correct}} + R_{\mathrm{format}}), \quad (5) R(τ)=1(Rcorrect>0)(Rcorrect+Rformat),(5)
其中 R c o r r e c t R_{\mathrm{correct}} Rcorrect 衡量答案准确性, R f o r m a t R_{\mathrm{format}} Rformat 衡量轨迹的语法有效性。
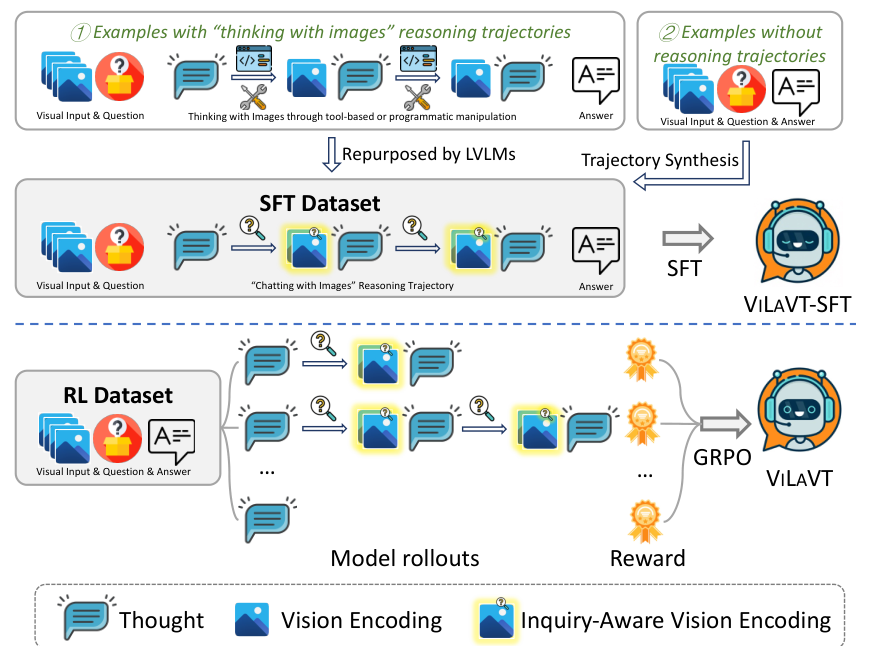
图 3:ViLAVT 的两阶段训练流水线:SFT(上)和基于 GRPO 算法的 RL(下)。
4. 实验
4.1 实验设置
我们在通用 VQA(HRBench-4K/8K)和空间推理(单图、多图、视频基准)上进行评估。模型初始化自 Qwen2.5-VL-7B,使用 Qwen3-0.6B-Embedding 作为视觉编码器中的语言组件。
4.2 主要结果
如表 1 所示,ViLAVT 在 8 个基准测试中的 5 个达到了最先进水平(SOTA),特别是在多图像和视频空间推理(如 SPAR-Bench, VSI-Bench)中提升显著。
表 1:ViLAVT 与基准模型的对比结果(准确率 %)。
| 模型 | HRBench-4K | HRBench-8K | SpatialEval-Real | EmbSpatial | ERQA | SPAR-Bench | MMSI-Bench | VSI-Bench |
|---|---|---|---|---|---|---|---|---|
| Non-Thinking | ||||||||
| Qwen2.5-VL-7B | 67.8 | 65.1 | 58.5 | 52.7 | 39.3 | 36.9 | 26.9 | 34.7 |
| Thinking about Images | ||||||||
| SpaceR-7B | 58.1 | 49.8 | 62.7 | 69.4 | 40.3 | 37.1 | 28.8 | 45.6 |
| Thinking with Images | ||||||||
| Thyme-7B | 78.3 | 72.4 | 63.7 | 65.5 | - | - | - | - |
| Chatting with Images (Ours) | ||||||||
| ViLAVT-7B | 75.5 | 69.3 | 68.9 | 69.3 | 42.2 | 52.6 | 31.3 | 52.0 |
表 2:训练阶段和模型组件的消融研究。
| 模型 | HRBench-4K | HRBench-8K | ERQA | VSI-Bench |
|---|---|---|---|---|
| Qwen2.5-VL-7B | 67.8 | 65.1 | 39.3 | 34.7 |
| ViLAVT-SFT | 73.6 | 66.1 | 39.8 | 43.3 |
| ViVAVT (Full) | 75.5 | 69.3 | 42.2 | 52.0 |
4.3 训练阶段与模型组件的消融研究
为了验证设计选择的合理性,我们对五种变体进行了消融研究:(1) Qwen2.5-VL-7B:基座模型;(2) Qwen2.5-VL-7B-SFT:在相同语料库上仅使用"问题-答案"对(无推理链)进行 SFT 训练的基座模型;(3) ViLAVT-SFT:仅经过 SFT 训练的本模型。此外,为了分离动态视觉编码器的贡献,我们训练了两个具有完整 SFT 阶段和 400 步 RL 调度的变体(对比 ViLAVT 的 1200 步 RL):(4) 采用原生 ViT 的 ViLAVT400,将动态编码器替换为标准 ViT;(5) ViLAVT400,保留完整架构但 RL 阶段仅训练 400 步。表 2 的结果揭示了几个关键见解:
范式的重要性。 将在相同语料库上训练的 Qwen2.5-VL-7B-SFT 与 ViLAVT 进行对比,前者在 HRBench-4K 上仅获得 1.0 % 1.0\% 1.0% 的微小提升,在 HRBench-8K 上相对于基座模型甚至有所下降。相比之下,ViLAVT 一致优于
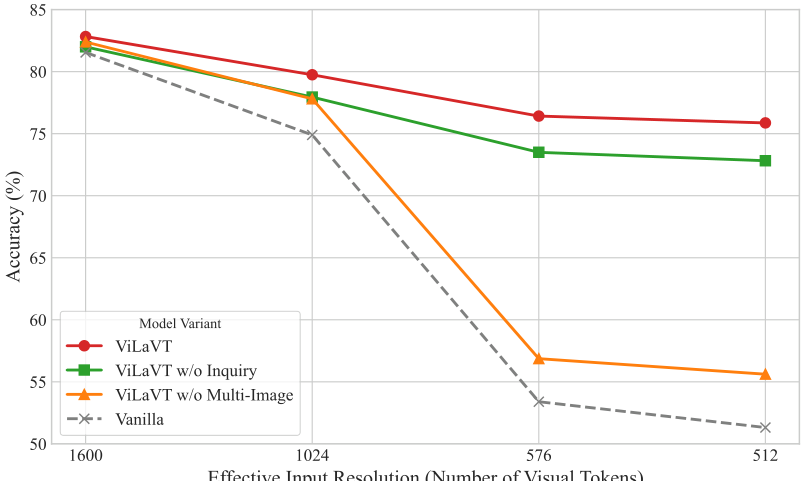
图 4. 不同分辨率下的视觉编码器分析。 随着分辨率降低,我们的全模型相对于消融实验显示出日益增长的性能优势,证明了其对信息损失的鲁棒性。
Qwen2.5-VL-7B-SFT,表明性能提升主要源于我们的框架而非单纯的数据扩展。
训练阶段的重要性。 ViLAVT-SFT 相比基座模型取得了显著进步,表明监督微调有效地使模型掌握了所提出的交互格式。在此基础上,ViLAVT 在所有基准测试中进一步优于 ViLAVT-SFT,说明强化学习(RL)在监督学习之外进一步优化了模型的交互推理能力。
视觉编码器的重要性。 在相同的全 SFT + 400 步 RL 训练调度下,我们观察到 ViLAVT400 始终优于采用原生 ViT 的 ViLAVT400,特别是在 HRBench-8K 和 VSI-Bench 上。这表明增益不仅来自迭代推理
表 3. HRBench-4K 在不同图像分辨率下的消融实验。
| 输入分辨率 | Qwen2.5-VL-7B | ViLAVT-SFT | ViLAVT |
|---|---|---|---|
| 1024 | 56.4 | 62.5 | 63.9 |
| 2048 | 61.4 | 69.8 | 70.1 |
| 4096 | 66.8 | 69.9 | 73.0 |
| 8192 | 67.8 | 73.6 | 75.5 |
理,还来自视觉编码器中基于查询调节(query-conditioned)的联合编码。
4.4 不同分辨率下的分析
为了验证动态视觉编码器的有效性,我们首先在 SPAR 数据集的一个子集上进行了受控实验,该子集包含 6,489 个训练样本和 721 个测试样本,每个样本关联 2-4 张图像。所有模型在该子集上训练 5 个 epoch 以直接预测最终答案,跳过文本推理链。训练时固定最大输入分辨率为 1600 × 28 × 28 1600 \times 28 \times 28 1600×28×28 像素,对应 1600 个视觉 token。我们将 ViLAVT 与三个消融版本进行对比:(1) 无查询调节的 ViLAVT;(2) 无多图交互的 ViLAVT;(3) 原生模型(两者均移除)。如图 4 所示,所有模型的性能都随分辨率降低而下降,但 ViLAVT 表现出更强的鲁棒性;在 512 个 token 时,它达到了 75.9 % 75.9\% 75.9% 的准确率,比原生模型的 51.1 % 51.1\% 51.1% 高出 24.8 % 24.8\% 24.8%。消融结果进一步表明,联合多图编码是该多视图基准测试中鲁棒性的主要驱动力,而查询调节提供了持续的额外增益。这些结果证明我们的架构改进对于在信息稀缺场景下保持性能至关重要。
为了验证这些发现的普适性,我们进一步评估了 ViLAVT 在不同 token 预算下在 HRBench-4K 上的表现(表 3)。在所有分辨率(包括 1,024 token 的信息稀缺设置, 63.9 % 63.9\% 63.9% 对 56.4 % 56.4\% 56.4%)下,ViLAVT 均一致优于基座 Qwen2.5-VL-7B。此外,ViLAVT-SFT 与完整 ViLAVT 之间的性能差距在各种分辨率下依然存在,证明 RL 优化了模型在不同分辨率约束下的推理策略。

4.5 案例研究
4.5.1 代表性案例
图 10 定性展示了我们的范式在复杂的基于视频的空间推理任务中的优势。ViLAVT 通过使用极具表达力的语言提示来表达清晰的认知意图,从而引导关键帧之间的联合关系重编码(例如,将图像 25-27 与图像 5 进行对比),从而成功解决了问题。这使模型能够构建连贯的空间地图。我们在附录 E 中提供了与其他"带图思考"方法的进一步对比。
4.5.2 注意力图可视化
图 5 展示了基于查询调节的编码在任务相关区域产生了更锐利的注意力。在文本查询的调节下,ViLAVT 逐步聚焦于任务相关区域------首先定位蓝色高尔夫球座,然后在重编码过程中专注于其嵌入的文本。相比之下,无查询调节的 ViLAVT 和使用原生 ViT 骨干的 Qwen2.5-VL-7B 表现出更弥散的注意力。这一定性证据支持了视觉编码器在查询调节下能改善局部感知并促进细粒度细节提取的观点。更多案例和可视化细节见附录 E.2。
5 结论
在这项工作中,我们引入了"与图像对话"(chatting with images),这是一种统一且可扩展的视觉推理范式,旨在克服现代方法的双重局限:静态"思考图像"中的信息损失,以及"带图思考"中视觉提示表达力低的问题。我们将视觉操作重新定义为语言引导的特征调制,将通过表达性语言提示表述的高层声明性意图,与通过联合特征重编码实现的深度关系分析相结合。综合实验验证了我们方法的优越性,该方法在大多数评估基准上刷新了 SOTA 结果。展望未来,我们相信这一范式为开发更具组合性和通用性的视觉推理智能体开辟了广阔前景。
影响声明
这项工作旨在通过语言引导的、与视觉证据的多轮交互,提高大型视觉语言模型的可靠性和推理能力。如果负责任地部署,此类模型可能有益于需要细致视觉感知的应用,如基于视觉的问答、教育以及科学或工程辅助。
Original Abstract: Current large vision-language models (LVLMs) typically rely on text-only reasoning based on a single-pass visual encoding, which often leads to loss of fine-grained visual information. Recently the proposal of ''thinking with images'' attempts to alleviate this limitation by manipulating images via external tools or code; however, the resulting visual states are often insufficiently grounded in linguistic semantics, impairing effective cross-modal alignment - particularly when visual semantics or geometric relationships must be reasoned over across distant regions or multiple images. To address these challenges, we propose ''chatting with images'', a new framework that reframes visual manipulation as language-guided feature modulation. Under the guidance of expressive language prompts, the model dynamically performs joint re-encoding over multiple image regions, enabling tighter coupling between linguistic reasoning and visual state updates. We instantiate this paradigm in ViLaVT, a novel LVLM equipped with a dynamic vision encoder explicitly designed for such interactive visual reasoning, and trained it with a two-stage curriculum combining supervised fine-tuning and reinforcement learning to promote effective reasoning behaviors. Extensive experiments across eight benchmarks demonstrate that ViLaVT achieves strong and consistent improvements, with particularly pronounced gains on complex multi-image and video-based spatial reasoning tasks.
PDF Link: 2602.11073v1
部分平台可能图片显示异常,请以我的博客内容为准
