RAG
RAG 是 Retrieval-Augmented Generation(检索增强生成) 的缩写,是一种结合「外部知识检索」和「大语言模型生成」的技术方案。通俗的来说是通过大模型来回答问题的时候,去检索外部知识库的相关信息,在基于这些信息生成内容。
可能有的亦菲、彦祖们要问了,为啥需要检索外部的知识库,我直接问大模型不行吗。如果是问一些基本知识,是可以的。但是想要问一些最新资料,或者是私有资料的内容,是不行的!因为大模型的知识是"固化"在训练数据里的,无法实时更新,更不了解私有资料的内容。所以通过RAG检索到资料的数据,将数据传递给大模型,让其基于这些数据生成你想要的回答。
应用背景
那么RAG技术可以干什么?可以搭建以下系统:
- 企业内部知识库:将企业文档存入RAG知识库,系统回答对应的文档内容,避免人工大量的翻阅文档
- 智能客服:将最新的业务规则和产品手册存入RAG知识库,系统回答客户产品相关问题
- 金融/医疗等合规性行业:将合规文档和行业指南存入RAG数据库,让系统给出建议和总结
技术实现
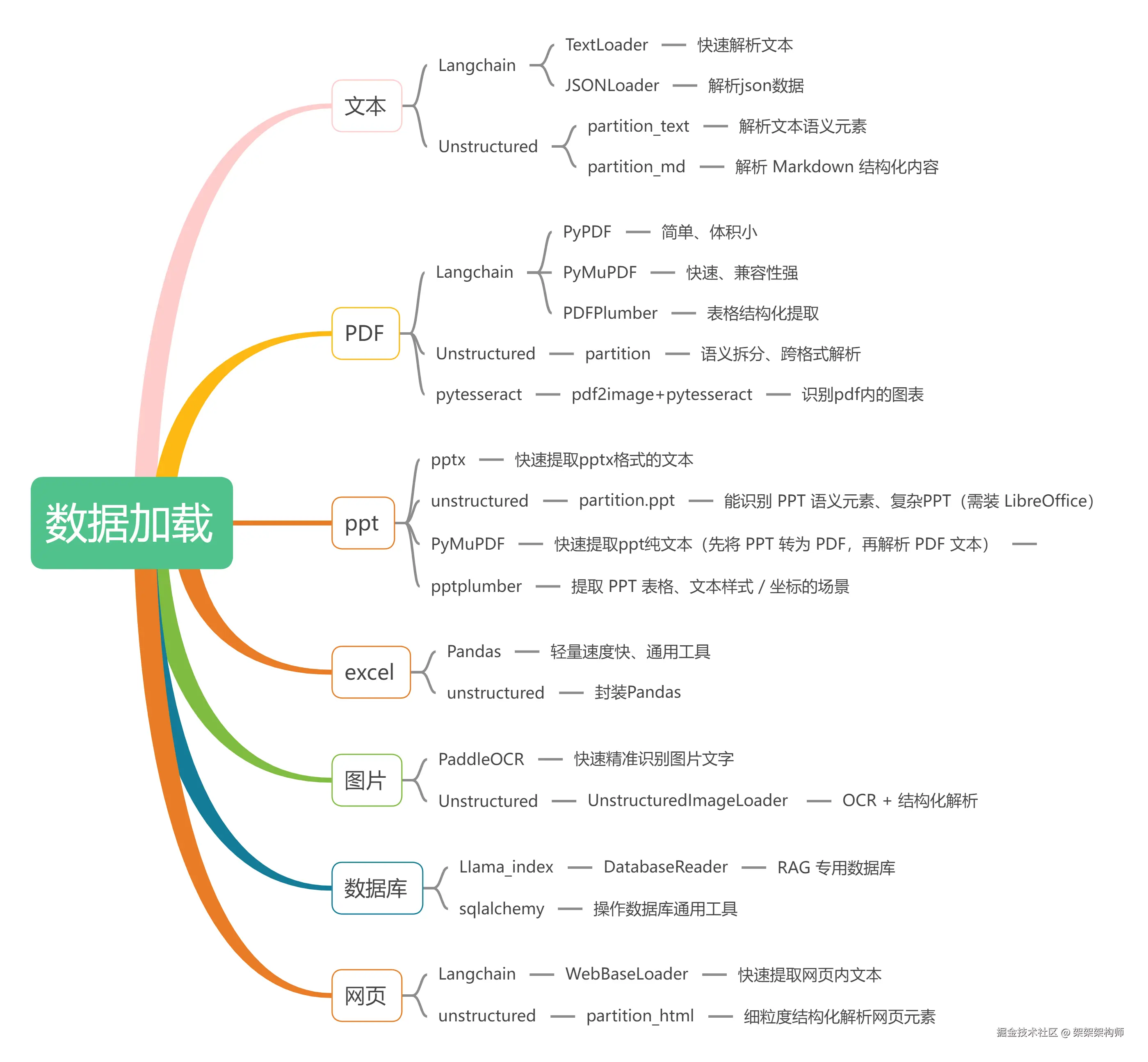
数据加载
做RAG系统的第一步就是数据的导入,接下来简单列下数据加载的各种技术,供各位亦菲、彦祖们参考
所用技术
Langchain
LangChain 是什么,是一个专为构建大语言模型(LLM)驱动的应用程序设计的开源框架。主要是让开发者能快速的构建出复杂的LLM应用,比如我们文中所提到的RAG系统。框架提供了以下的核心功能,用来构建复杂的LLM应用。
- 工具集成:连接各种API和外部工具
- 记忆:管理对话历史
- 链式调用:将多个LLM调用和工具结合起来
- 代理:让LLM自主决策和使用工具
LIamaIndex
LIamaIndex 是一套 专注于「文档理解与知识库问答」的开源框架 ,尤其适用于RAG系统,擅长文档处理、检索优化。官方网站: www.llamaindex.ai/
Unstructured
Unstructured 是一款专注于非结构化文档数据处理的开源工具库 ,核心能力将复杂的文档(PDF、Word、网页)和非结构化文档转换成规整,可直接供给大模型或RAG使用的结构化数据。官方文档:docs.unstructured.io/
看到这儿,有的小伙伴可能会问,为啥我会选择 Python的技术框架,而不用Java的 Langchain4j。因为在 Python 生态下构建 LLM/RAG 应用,LangChain 远比 langchain4j 更丰富、更好用!
环境准备
- 下载安装 Miniconda , Miniconda是一个轻量级的 Python 环境管理工具,仅包含 conda 包管理器和 Python 核心,可便捷创建、管理独立的 Python 环境。国内镜像地址: mirrors.tuna.tsinghua.edu.cn/anaconda/mi...
- 创建一个requeriment.txt文件,管理各种依赖:
shell
# 核心LLM框架依赖
llama-index>=0.10.0
python-dotenv>=1.0.0
openai>=1.0.0
langchain>=0.1.0
# 关键升级:langchain-community 需 >= 0.2.0 才支持 headers 参数
langchain-community>=0.2.0
langchain-openai>=0.1.0
langchain-text-splitters>=0.0.1
langchain-core>=0.1.0
langchain-huggingface>=0.0.3
# 文本处理/嵌入依赖
sentence-transformers>=2.2.0
markdown>=3.4.0
# 文档解析依赖
unstructured>=0.10.30
unstructured[pdf]>=0.10.30
unstructured[ppt]>=0.10.30
langchain-unstructured>=0.1.0
# Windows 系统依赖(解决文件解析/路径问题)
pywin32>=306
# Unstructured 解析 markdown 必需的依赖
markdown-it-py>=3.0.0
# PDF/OCR相关依赖
pdf2image>=1.16.0
pytesseract>=0.3.10
# 图片识别核心依赖(PaddleOCR 方案)
paddlepaddle>=2.6.0
paddleocr>=2.7.0
pillow>=10.0.0
# llama-index 核心依赖(数据库读取功能)
llama-index-readers-database>=0.1.0
# MySQL 数据库驱动(必须)
mysql-connector-python>=8.0.0
# 或备选驱动(二选一,推荐上面的)
# pymysql>=1.1.0
# 新增:SQLAlchemy 适配 MySQL 的依赖
sqlalchemy>=2.0.0
# 核心依赖
fastapi>=0.115.0
uvicorn[standard]>=0.32.0
pydantic>=2.0.0
pydantic-settings>=2.0.0
# 扩展依赖(你的场景需要)
python-multipart>=0.0.17 # 文件上传
python-dotenv>=1.0.0 # 读取.env文件
requests>=2.32.0 # 调用AI接口
#数据分析
pandas>=2.2.2实现
文本
Unstructured 加载 txt、md格式数据,代码如下:
python
from unstructured.partition.text import partition_text
from unstructured.partition.md import partition_md
text_file = "../../document/企业概况与分析框架.txt"
md_file = "../../document/企业财务报表分析.md"
def parse_and_analyze_elements(elements, file_type):
print(f"\n========== 解析 {file_type} 文件 ==========")
print("\n【原始元素输出】:")
for element in elements:
print(element)
# 详细分析每个元素的元数据
print("\n【元素详细元数据】:")
for i, element in enumerate(elements):
print(f"\n--- 第 {i+1} 个元素 ---")
print(f"元素类型: {element.__class__.__name__}")
print(f"文本内容: {element.text.strip() or '无文本内容'}")
if hasattr(element, "metadata") and element.metadata:
print("元数据:")
for key, value in element.metadata.__dict__.items():
if not key.startswith("_") and value is not None:
print(f" • {key}: {value}")
# 1. 解析文本文件
text_elements = partition_text(text_file)
parse_and_analyze_elements(text_elements, "文本(TXT)")
# 2. 解析MD文件
md_elements = partition_md(md_file)
parse_and_analyze_elements(md_elements, "Markdown(MD)")返回:
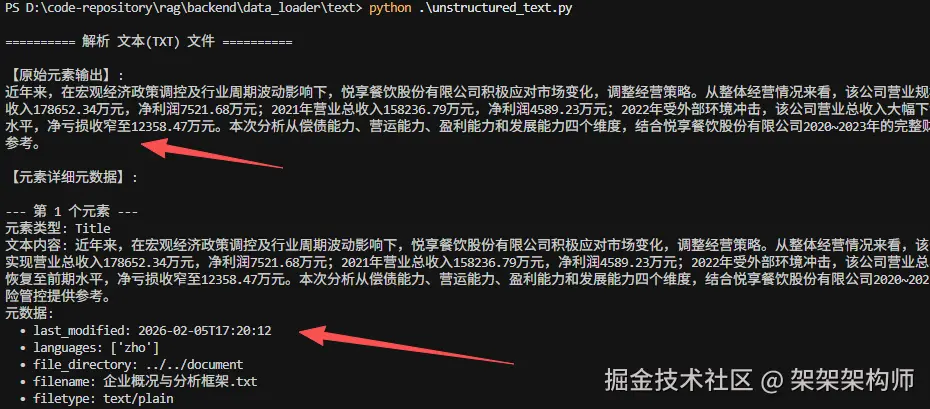
Langchain 加载 txt、md、json格式数据,代码如下:
ini
from langchain_community.document_loaders import (
TextLoader,
JSONLoader,
UnstructuredMarkdownLoader,
)
# 加载txt
loader = TextLoader("../../document/企业概况与分析框架.txt", encoding="utf-8")
documents = loader.load()
print(documents)
# 加载整个json
loader2 = JSONLoader(
file_path="../../document/企业概况与分析框架.json",
jq_schema=".",
text_content=False,
)
documents2 = loader2.load()
print(documents2)
# 加载md
markdown_path = "../../document/企业财务报表分析.md"
loader = UnstructuredMarkdownLoader(markdown_path)
data = loader.load()
print(data[0].page_content[:100])
返回:
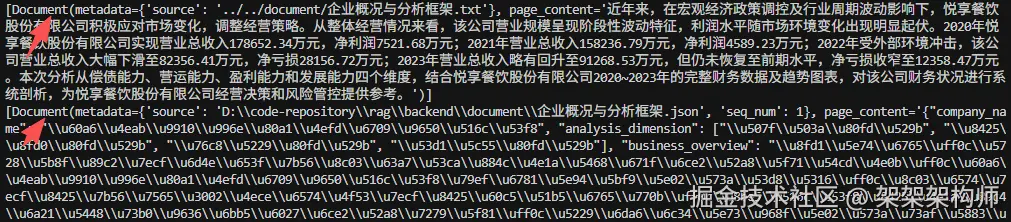
两者的不同之处:langchain输出的是 标准的Document对象,结构非常简单;Unstructured 输出的是其专属的元素对象,会按照语义进行拆分文件,能够自动识别文中的标题、段落、列表和表格等结构,拆分成不同类型的元素,元数据也更详细(比如某段文字在文件的第几行)。
Langchain加载PDF格式代码如下:
python
import time
from langchain_community.document_loaders import PyPDFLoader, PyMuPDFLoader, PDFPlumberLoader
PDF_PATH = "../../document/企业财务报表分析-图表.pdf"
LOADERS = {"PyPDFLoader": PyPDFLoader, "PyMuPDFLoader": PyMuPDFLoader, "PDFPlumberLoader": PDFPlumberLoader}
# 1. 耗时对比
print("=== 耗时对比 ===")
results = {}
for name, cls in LOADERS.items():
t0 = time.perf_counter()
docs = cls(PDF_PATH).load()
results[name] = docs
print(f"{name}:页数={len(docs)},耗时={time.perf_counter()-t0:.3f}s")
# 2. 效果预览
print("\n=== 抽取效果预览===")
for name, docs in results.items():
print("---------------------------------------------------------")
preview = docs[1].page_content[:500].strip() if docs else "无内容"
print(f"{name}: {preview}")
preview2 = docs[9].page_content[:500].strip() if docs else "无内容"
meta9 = docs[9].metadata
print(f"{name}: {preview2} {meta9}")返回:

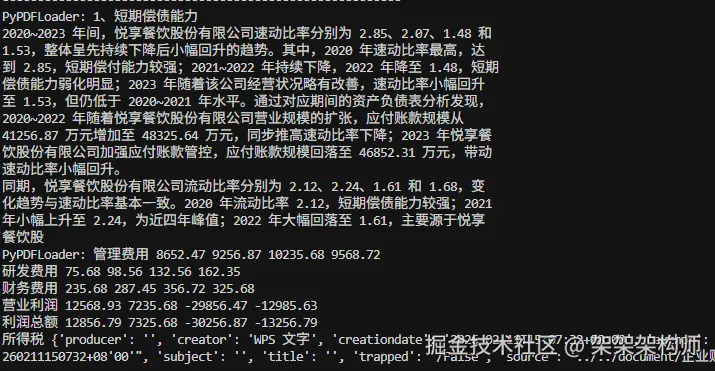


从返回的结果来看PyMuPDFLoader是最快的,但是PDF中的表格结构化提取不是很好,显示的内容很乱。其次是PyPDFLoader提取速度比PyMuPDFLoader慢点,但是可以对pdf表格结构化提取。最后PDFPlumberLoader是最慢的,不过也是可以对pdf表格结构化提取,对表格化提取支持比较好。这三个的对比如下:
| 场景 | 首选加载器 | 原因 |
|---|---|---|
| 批量解析大量纯文本 PDF | PyMuPDFLoader | 速度快、兼容性强 |
| 提取 PDF 中的表格(如财务报表) | PDFPlumberLoader | 表格结构化提取 |
| 轻量部署(无多余依赖) | PyPDFLoader | 仅依赖 PyPDF2,体积小 |
| 需提取批注 / 图片 | PyMuPDFLoader | 唯一支持图片 / 批注解析 |
| 复杂排版 PDF(分栏 / 嵌套列表) | PDFPlumberLoader | 解析结果最精准 |
Unstructured 加载PDF格式代码如下:
ini
from unstructured.partition.auto import partition
PDF_PATH = "../../document/企业财务报表分析.pdf"
elements = partition(filename=PDF_PATH,content_type="application/pdf")
print("\n\n".join([str(e) for e in elements]))结果:
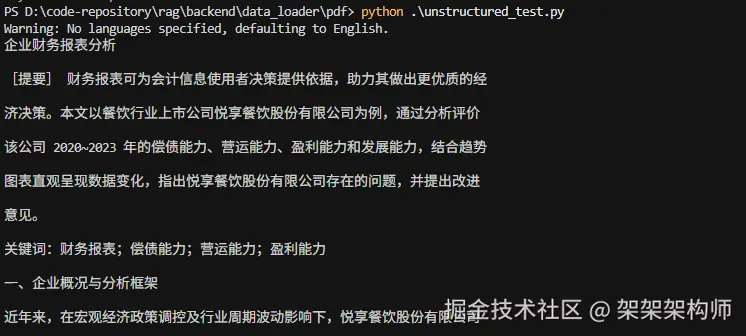
Unstructured 的特点是,语义结构化解析,会自动识别 PDF 中的标题(Title)、段落(NarrativeText)、列表项(ListItem)、表格(Table)等元素,拆分后返回不同类型的对象
不过以上说的都无法提取PDF中的折线图等图表的数据。如果遇到有很多图表数据需要解析和提取,有以下解决方案。通过"PDF 转图片 + OCR 文字识别"的方法,提取pdf中的图表数据。
PDF 转图片 + OCR 文字识别方法实现:
首先安装依赖:
PDF2image 需要手动安装 poppler
- Windows 下载地址:github.com/oschwartz10...
- macOS 通过 Homebrew 安装: brew install poppler
- Linux 命令 sudo apt install poppler-utils、sudo yum install poppler-utils
Tesseract-OCR 下载地址(github.com/tesseract-o...),需安装中文语言包(安装时勾选 "chi_sim",或手动复制语言包到tessdata目录)
- Windows 下载地址:github.com/UB-Mannheim...
- macOS 通过 Homebrew 安装:brew install tesseract tesseract-lang
- Linux 命令 sudo apt install tesseract-ocr tesseract-ocr-chi-sim、sudo yum install tesseract tesseract-langpack-chi_sim
代码:
python
import pdf2image
import pytesseract
import os
# 创建 output 目录
PDF_PATH = '../../document/企业财务报表分析-图表.pdf'
OUTPUT_DIR = 'output'
POPPLER_PATH = r'D:\Program Files\poppler-windows\poppler-25.12.0\Library\bin' # 你的poppler bin路径
TESSERACT_PATH = r'D:\Program Files\Tesseract-OCR\tesseract.exe'
pytesseract.pytesseract.tesseract_cmd = TESSERACT_PATH
# 创建output目录,已存在则不报错
os.makedirs(OUTPUT_DIR, exist_ok=True)
# PDF转图片(关键:传poppler_path参数,解决poppler依赖)
# dpi=300提高图片清晰度,让OCR识别更准确
images = pdf2image.convert_from_path(
pdf_path=PDF_PATH,
poppler_path=POPPLER_PATH,
dpi=300
)
# 保存转换后的图片
for i, image in enumerate(images):
img_save_path = f'{OUTPUT_DIR}/page_{i+1}.png'
image.save(img_save_path)
print(f"已保存PDF第{i+1}页为图片:{img_save_path}")
# 用pytesseract提取简体中文文本
print("\n开始提取各页文本:\n" + "-"*60)
for i, image in enumerate(images):
# lang='chi_sim'指定简体中文,依赖安装时勾选的中文语言包
text = pytesseract.image_to_string(image, lang='chi_sim')
print(f"【PDF第{i+1}页提取的文本】")
# 处理无文本的情况,避免打印空行
print(text if text.strip() else "该页未识别到有效文本")
print("-"*60 + "\n")返回:
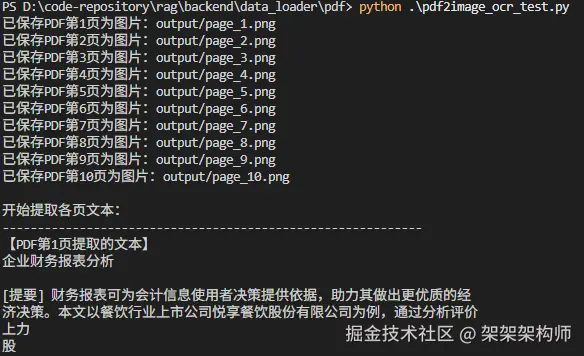
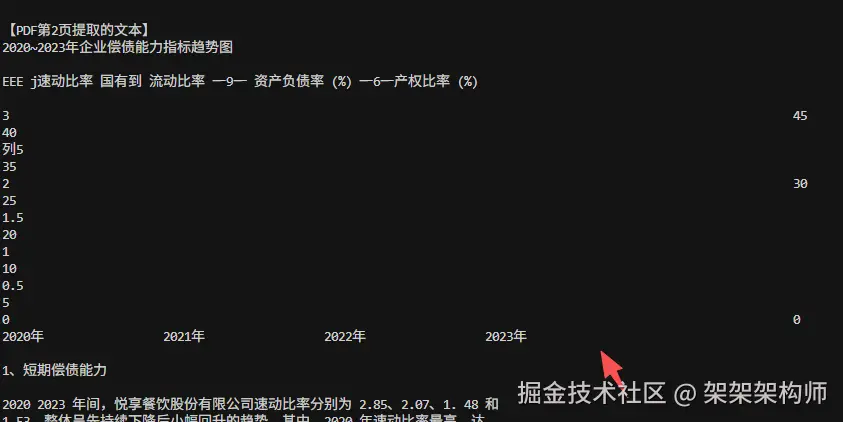 从返回可以看出将pd转换成图片后,对图片进行识别,可以识别到图表的数据,不过这种方法比较耗时。
从返回可以看出将pd转换成图片后,对图片进行识别,可以识别到图表的数据,不过这种方法比较耗时。
数据库
sqlalchemy加载数据库数据,代码如下:
python
import pandas as pd
from sqlalchemy import create_engine, text
engine = create_engine("mysql+mysqlconnector://root:root@localhost:3306/seckill")
df = pd.read_sql(text("SELECT * FROM user"), engine)
print(df)返回:
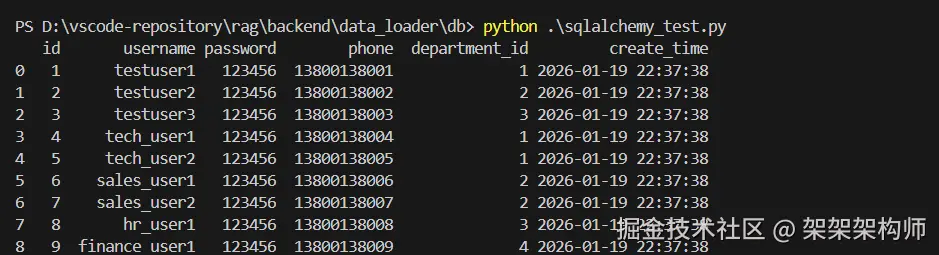
llama_index加载数据库数据,代码如下:
ini
from llama_index.readers.database import DatabaseReader
db_uri = "mysql+mysqlconnector://root:root@localhost:3306/seckill"
reader = DatabaseReader(
uri=db_uri
)
query = "SELECT * FROM user"
documents = reader.load_data(query=query)
print(f"从数据库加载的文档数量: {len(documents)}")
print(documents)结果:
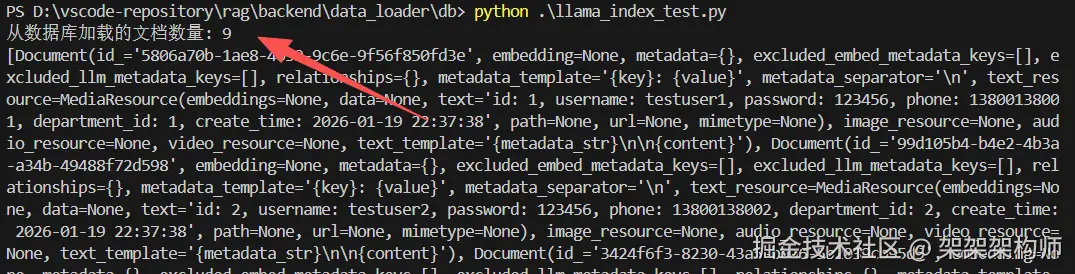
网页
Langchain加载网页数据,代码如下:
ini
import requests
from langchain_community.document_loaders import WebBaseLoader
page_url = "https://books.toscrape.com"
def custom_scrape(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers, timeout=20)
response.raise_for_status()
return response.text
loader = WebBaseLoader(web_paths=[page_url])
loader.scrape_all = lambda urls: [custom_scrape(url) for url in urls]
doc = loader.load()[0]
clean_content = " ".join(doc.page_content.replace("\n", "").replace("\r", "").replace("\t", "").split())
print("网页核心内容(无换行):\n", clean_content[:2000])结果:
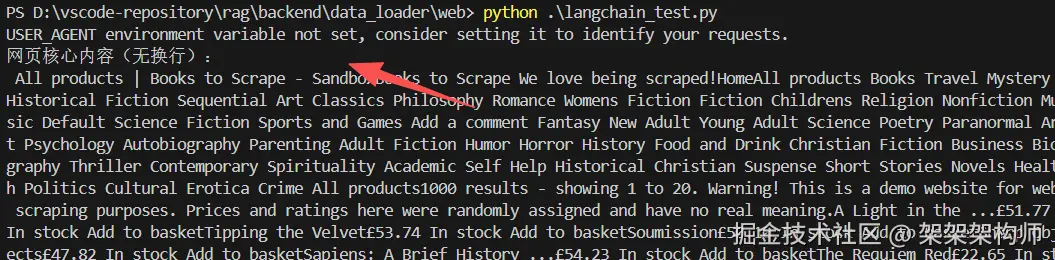
unstructured加载网页数据,代码如下:
ini
import requests
from unstructured.partition.html import partition_html
page_url = "https://books.toscrape.com"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36"}
html_content = requests.get(page_url, headers=headers).text
elements = partition_html(text=html_content)
all_text = [elem.text.strip() for elem in elements if elem.text.strip()]
clean_content = " ".join("".join(all_text).replace("\n", "").replace("\r", "").replace("\t", "").split())
print("Unstructured直接加载网页(无换行):\n", clean_content[:2000])结果:
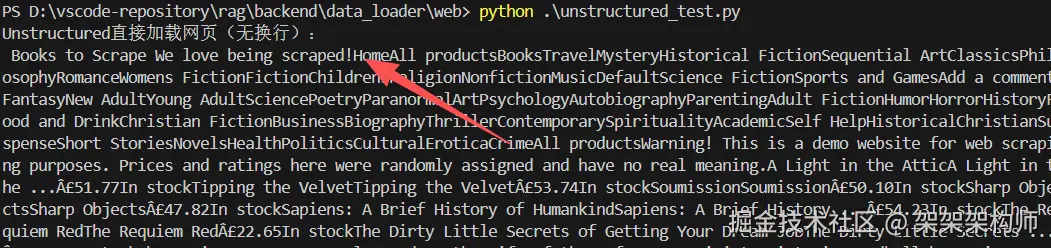
使用对比下来WebBaseLoader更快点,适合快速提取网页内的文本。而partition_html 适合细粒度结构化解析网页元素
思维导图
总结
好了,RAG系统的数据加载技术就写到这,不同格式的数据应该选择不同的技术组件进行加载,这样可以提高RAG系统的准确性。其实写了那么多也只是给各位亦菲、彦祖们一个参考,更多的是需要自己上手练习和体会。还有很多文中没有列到的数据加载技术,也欢迎各位亦菲、彦祖们在评论区讨论哦。