一、安装与启动
kafka:kafka_2.13-3.9.1.tgz
zookeeper:apache-zookeeper-3.9.4-bin.tar.gz
bash
#解压
tar -zxvf kafka_2.13-3.9.1.tgz
#安装JDK
yum install -y java-1.8.0-openjdk-devel
# 查看 Java 版本(确认输出为 1.8.x)
java -version
#编辑 /etc/profile 文件,确保环境变量指向 JDK 1.8:
vi /etc/profile
#在文件末尾添加以下内容
# JDK 1.8 环境变量
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
# 检查 JAVA_HOME 是否正确
echo $JAVA_HOME
# 输出应是 /usr/lib/jvm/java-1.8.0-openjdk
# 进入 Kafka 目录
cd /root/kafka_2.13-3.9.1
#启动Zookeeper
nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
#启动kafka
nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
jps
#输出
1838060 Kafka
1839361 Jps
1833173 QuorumPeerMain二、常用命令
1.服务运维命令
1.1启动/停止Zookeeper
bash
# 启动
nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
# 停止
bin/zookeeper-server-stop.sh config/zookeeper.properties1.2 启动 / 停止 Kafka
bash
# 启动
nohup bin/kafka-server-start.sh config/server.properties &
# 停止
bin/kafka-server-stop.sh config/server.properties2.主题管理命令
2.1创建主题
bash
bin/kafka-topics.sh \
--create \
--topic test_topic \
--partitions 3 \
--replication-factor 1 \
--bootstrap-server localhost:9092| 参数 | 含义 | 取值说明 |
|---|---|---|
--create |
命令动作 | 固定值,标识「创建主题」 |
--topic |
指定主题名 | 自定义字符串(如 test_topic、user_log),不能含特殊字符 |
--partitions |
主题分区数 | 正整数(如 1/3/5),单节点建议 1-3,多节点根据并发调整;分区数只能增不能减 |
--replication-factor |
副本数 | 正整数,≤ Kafka 节点数(单节点只能设 1,多节点可设 2+,如 3 节点设 2) |
--bootstrap-server |
Kafka 服务地址 | 格式:IP:端口(默认 localhost:9092),指定连接的 Kafka 节点 |
2.2 查看所有主题
bash
bin/kafka-topics.sh --list --bootstrap-server localhost:90922.3 查看指定主题详情
bash
bin/kafka-topics.sh --describe --topic test_topic --bootstrap-server localhost:9092| 参数 | 含义 | 取值说明 |
|---|---|---|
--describe |
命令动作 | 固定值,标识「查看主题详情」 |
--topic |
指定要查看的主题 | 已存在的主题名(如 test_topic) |
--bootstrap-server |
Kafka 服务地址 | 同前 |
2.4修改主题(调整分区数)
bash
bin/kafka-topics.sh --alter --topic test_topic --partitions 5 --bootstrap-server localhost:9092| 参数 | 含义 | 取值说明 |
|---|---|---|
--alter |
命令动作 | 固定值,标识「修改主题配置」 |
--topic |
要修改的主题 | 已存在的主题名 |
--partitions |
新的分区数 | 必须大于当前分区数(如原 3→5,不能 3→2) |
--bootstrap-server |
Kafka 服务地址 | 同前 |
2.5删除主题
bash
bin/kafka-topics.sh --delete --topic test_topic --bootstrap-server localhost:90923.消息生产 / 消费命令
3.1生产者(发送消息)
bash
bin/kafka-console-producer.sh --topic test_topic --bootstrap-server localhost:9092| 参数 | 含义 | 取值说明 |
|---|---|---|
--topic |
要发送消息的主题 | 已存在的主题名 |
--bootstrap-server |
Kafka 服务地址 | 同前 |
(可选)--producer-property |
生产者配置 | 如 acks=1(确认机制)、retries=3(重试次数),格式:--producer-property acks=1 |
3.2消费者(接收消息)
bash
bin/kafka-console-consumer.sh --topic test_topic --from-beginning --group test_group --bootstrap-server localhost:9092| 参数 | 含义 | 取值说明 |
|---|---|---|
--topic |
要消费的主题 | 已存在的主题名 |
--from-beginning |
消费起始位置 | 无取值,加此参数表示「从头消费所有历史消息」;不加则只消费启动后新增的消息 |
--group |
消费者组名 | 自定义字符串(如 test_group),同一组内的消费者会分摊消费分区,不同组互不影响 |
--bootstrap-server |
Kafka 服务地址 | 同前 |
(可选)--max-messages |
消费最大条数 | 正整数(如 10),消费指定条数后自动退出,示例:--max-messages 10 |
4.消费者组管理
4.1查看所有消费者组
bash
bin/kafka-consumer-groups.sh --list --bootstrap-server localhost:90924.2查看消费者组详情(消费偏移量)
bash
bin/kafka-consumer-groups.sh --describe --group test_group --bootstrap-server localhost:9092| 参数 | 含义 | 取值说明 |
|---|---|---|
--describe |
命令动作 | 固定值,标识「查看消费者组详情」 |
--group |
指定消费者组 | 已存在的消费者组名(如 test_group) |
--bootstrap-server |
Kafka 服务地址 | 同前 |
(可选)--topic |
只查看指定主题的消费情况 | 已存在的主题名,示例:--topic test_topic |
4.3重置消费者组偏移量
bash
bin/kafka-consumer-groups.sh \
--reset-offsets \
--to-earliest \
--topic test_topic \
--group test_group \
--execute \
--bootstrap-server localhost:9092| 参数 | 含义 | 取值说明 |
|---|---|---|
--reset-offsets |
命令动作 | 固定值,标识「重置偏移量」 |
--to-earliest |
重置目标位置 | 固定值,重置到「最开始的偏移量」(从头消费);可选值:• --to-latest:重置到最新偏移量(只消费新消息)• --to-offset N:重置到指定偏移量(N 为正整数,如 10)• --shift-by N:偏移量增减(N 为整数,如 +5/-3) |
--topic |
要重置的主题 | 已存在的主题名,支持通配符(如 --topic 'test*') |
--group |
要重置的消费者组 | 已存在的消费者组名 |
--execute |
执行重置 | 无取值,加此参数才会真正执行重置;不加则只预览效果(建议先预览再执行) |
--bootstrap-server |
Kafka 服务地址 | 同前 |
三、集群搭建
1.为什么要用集群
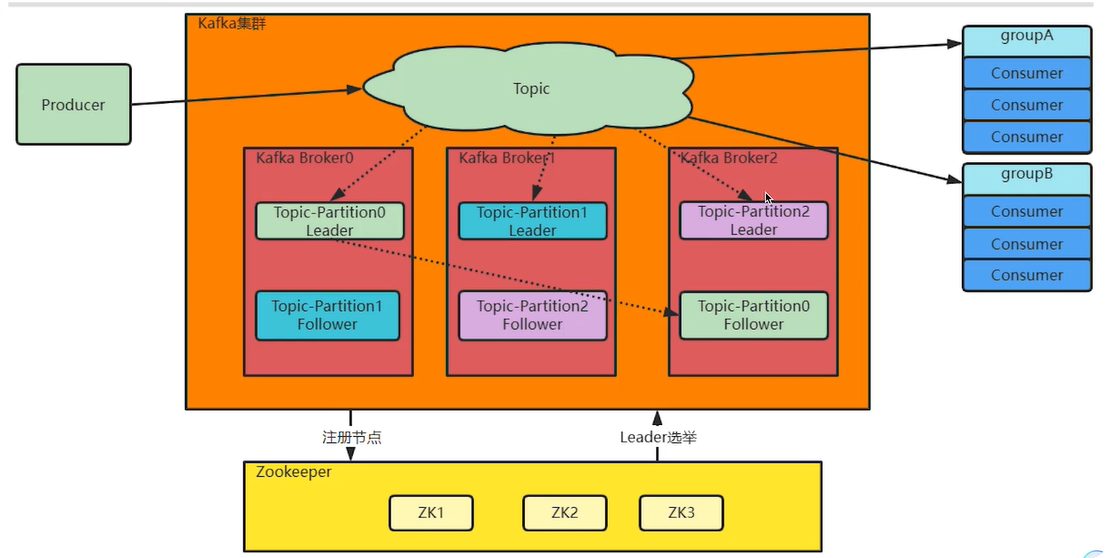
单机服务下,Kafka已经具备了非常高的性能。TPS能够达到百万级别。但是,在实际工作中使用时,单机搭建的Kafka会有很大的局限性。
一方面:消息太多,需要分开保存。 Kaka是面向海量消息设计的,一个Topic下的消息会非常多,单机服务很难存得下来。这些消息就需要分成不同的Pariion,分布到多个不同的 Broker上。这样每个Broker就只需要保存一部分数据。这些分区的个数就称为分区数。
另一方面:服务不稳定,数据容易丢失。 单机服务下,如果服务崩溃,数据就丢失了。为了保证数据安全,就需要给每个Pariion配置一个或多个备份,保证数据不丢失。Kafka的集群模式下,每个Pariion都有一个或多个备份。Kaka会通过一个统一的zookeeper集群作为选举中心 ,给每个Paniion选举出一个主节点Leader,其他节点就是从节点Folower。主节点负责响应客户端的具体业务请求,并保存消息。而从节点则负责同步主节点的数据。当主节点发生故障时,Kafka会选举出一个从节点成为新的主节点。 最后:Kafka集群中的这些Broker信息,包括Partiton的选举信息,都会保存在额外部署的Zookeper集群当中,这样,kaka集群就不会因为某一些Broker服务崩溃而中断。
Kafka也提供了另外一种不需要Zookeeper的集群机制,Kraft集群。这种方式会在后面进行介绍。
2.集群搭建
2.1准备三台云服务器
三台都要下载jdk和zookeeper
2.2搭建zookeeper集群
bash
#解压zookeeper
tar -zxvf apache-zookeeper-3.9.4-bin.tar.gz
mv apache-zookeeper-3.9.4-bin/* /root/app/zookeeper
#修改配置文件
cd conf/
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
#修改如下
dataDir=/root/app/zookeeper/data
#一个集群内部端口,一个集群外部端口
server.1=ip1:2888:3888
server.2=ip2:2888:3888
server.3=ip3:2888:3888
#创建对应的data文件夹
cd data/
#一个名为 myid 的文件,文件里只有一行内容:数字 1。
#Zookeeper 集群里的每个节点需要一个唯一的 ID(1~255 之间的整数),myid 文件就是用来存储这个 ID 的,Zookeeper 启动时会读取该文件的数字,识别自己是集群中的第几个节点。
echo 1 > myid
#将配置传到其他节点
scp -r apache-zookeeper-3.9.4-bin/ root@ip2:apache-zookeeper-3.9.4-bin
scp -r apache-zookeeper-3.9.4-bin/ root@ip3:apache-zookeeper-3.9.4-bin
#在其他节点配置myid
cd data/
echo 2 > myid
echo 3 > myid
#在三台服务器启动zookeeper集群
#首先要把之前单节点的zookeeper和kafka删除
cd apache-zookeeper-3.9.4-bin
bin/zkServer.sh --config conf start2.3搭建kafka集群
进入config目录,修改server.properties。
java
#broker 的全局唯一编号,不能重复,只能是数字。
broker.id=1
#服务监听地址:listeners=PLAINTEXT://hostname:9092
客户端通过这个连接kafka
listeners=PLAINTEXT://worker1:9092
#数据文件地址。同样默认是给的/tmp目录。
log.dirs=/app/kafka/logs
#默认的每个Topic的分区数
num.partitions=1
#Kafka 连接的 Zookeeper 集群地址
zookeeper.connect=worker1:2181,worker2:2181,worker3:2181
#可以选择指定zookeeper上的基础节点。
#zookeeper.connect=worker1:2181,worker2:2181,worker3:2181/kafka
将kafka的文件夹传递给其他节点
bash
scp -r kafka_2.13-3.9.1/ root@ip2:/root/app/kafka
scp -r kafka_2.13-3.9.1/ root@ip3:/root/app/kafka进入剩下两个的config目录,修改server.properties。
启动kafka,后台启动
bash
nohup bin/kafka-server-start.sh -daemon config/server.properties &2.4验证生产者消费者
1、Kaika设计需要支持海量的数据,而这样庞大的数据量,一个broker是存不下的。那就拆分成多个Partition,每个Broker只存一部分数据。这样极大的扩展了集群的吞吐量。
2、每个Partiion保留了一部分的消息副本,如果放到一个roker上,就容易出现单点故障。所以就给每个Parition设计Folower节点,进行数据备份,从而保证数据安全。另外,多备份的 Partition设计也提高了读取消息时的并发度。
3、在同一个Topic的多个Partition中,会产生一个Partition作为Leader。这个Leader Partition会负责响应客户端的请求,并将数据往其他Parition分发。