MLDocRAG: Multimodal Long-Context Document Retrieval Augmented Generation
Authors: Yongyue Zhang, Yaxiong Wu
Deep-Dive Summary:
MLDocRAG: 多模态长上下文文档检索增强生成
作者: Yongyue Zhang (独立研究员), Yaxiong Wu (独立研究员)
摘要 (Abstract)
理解包含段落、插图和表格等多模态块(chunks)的多模态长上下文文档具有挑战性,原因在于:(1) 跨模态异构性 ,需要在不同模态间定位相关信息;(2) 跨页推理 ,需要整合分散在不同页面上的证据。为了应对这些挑战,本文提出将跨模态和跨页信息投射到一个统一的查询表示空间中,以查询作为异构多模态内容的抽象语义代理。我们提出了 MLDocRAG(Multimodal Long-Context Document Retrieval Augmented Generation) 框架,该框架利用多模态块-查询图 (MCQG) 围绕语义丰富的可回答查询来组织多模态文档内容。MCQG 通过多模态文档扩展过程构建,从异构文档块中生成细粒度查询,并将其链接到跨模态和跨页的相应内容。这种基于图的结构支持选择性的、以查询为中心的检索和结构化证据聚合,从而增强了长上下文多模态问答的接地性(grounding)和连贯性。在 MMLongBench-Doc 和 LongDocURL 数据集上的实验表明,MLDocRAG 持续提高了检索质量和答案准确性。
1 引言 (Introduction)
多模态长上下文文档(如研究论文、报告和书籍)通常跨越数十至数百页,包含文本、图像和表格等多种组件。理解此类文档面临两大核心挑战:(1) 跨模态异构性;(2) 跨页推理。这要求模型具备多模态长上下文关联能力。
虽然大型视觉语言模型(LVLMs)在局部短上下文理解方面表现出色,但在长文档场景下,当证据稀疏分布在不同页面和模态时,往往会出现"大海捞针"问题。检索增强生成(RAG)通过引入外部检索来克服上下文窗口限制。图 1 展示了现有的五种 RAG 策略:(a) 纯文本 RAG;(b) 文本+图像描述 RAG;© 基于 CLIP/SigLIP 的多模态 RAG;(d) 基于 ColPali 的页面级视觉 RAG;(e) 基于图的 RAG。然而,这些方法往往难以捕捉细粒度的跨模态和跨页关联。
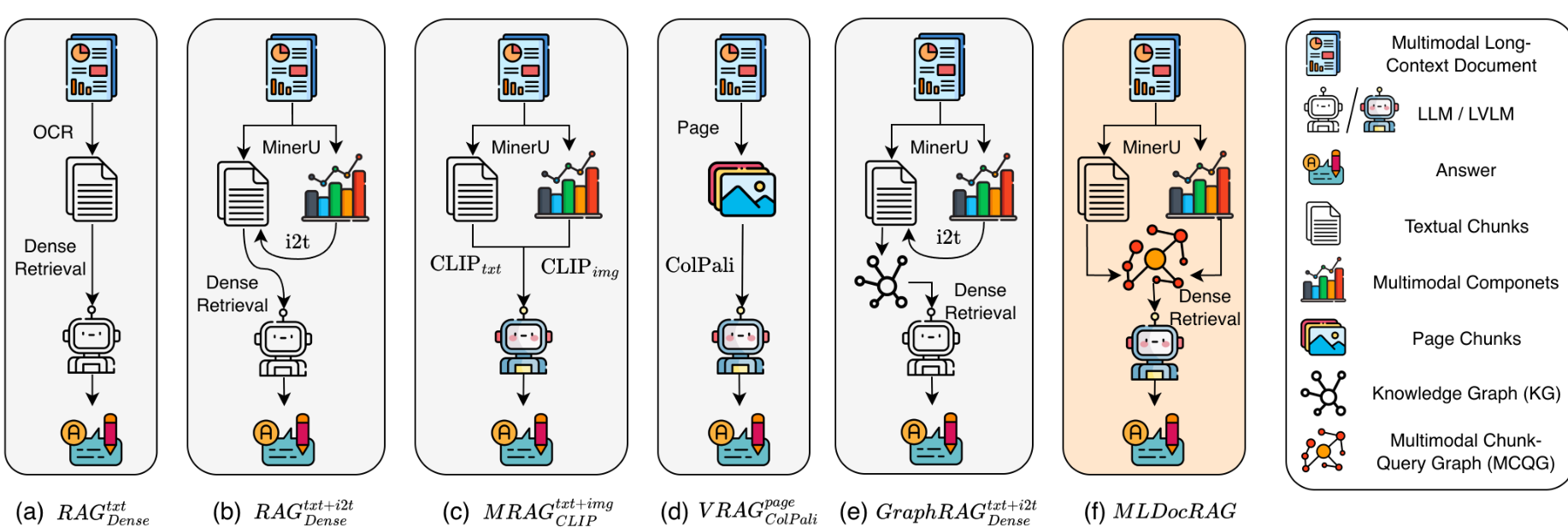
图 1:多模态长文档 RAG 示意图,对比了基线方法 (a)--(e) 与我们的 MLDocRAG (f)。
本文将以查询为中心的公式扩展到多模态设置,提出 MLDocRAG。其核心是构建 MCQG ,通过 MDoc2Query 过程从文本、图像和表格等异构块中生成语义丰富的查询。这些查询作为检索锚点,有效地连接了用户需求与多模态内容。
2 相关工作 (Related Work)
- 长上下文文档理解: 尽管 LVLMs 有较强的局部对齐能力,但固定窗口限制了其捕捉全局相关证据的能力。
- 多模态 RAG: 现有方法多在粗粒度层面运行,忽视了细粒度的跨模态关联。
- 文档扩展: 如 Doc2Query 通过生成合成查询来丰富检索索引。MLDocRAG 将此思想扩展到多模态领域。
3 方法论 (Methodology)
3.1 基础准备 (Preliminaries)
任务目标是根据多模态长文档 D D D 回答用户问题 q u q^{u} qu。文档被处理为页面序列 D = { P 1 , P 2 , ... , P X } D = \{P_{1},P_{2},\ldots ,P_{X}\} D={P1,P2,...,PX},每页包含文本、图像或表格块 c ∈ { c 1 , c 2 , ... , c N } c \in \{c_{1},c_{2},\ldots ,c_{N}\} c∈{c1,c2,...,cN}。
3.2 框架概述 (Framework Overview)
MLDocRAG 分为两个阶段:MCQG 构建 和MCQG 使用。
- 构建阶段: 将 PDF 解析为块,使用 MDoc2Query 为每个块生成查询-答案对,并构建包含块-查询(C-Q)边和查询-查询(Q-Q)边的图。
- 使用阶段: 在推理时,将用户查询与图中节点匹配,通过图遍历扩展检索范围,聚合相关多模态块,最后由 LVLM 生成答案。
3.3 MCQG 构建
- 文档解析: 使用 MinerU 等工具提取段落、公式、图像和表格。文本块采用滑动窗口切分。
- MDoc2Query: 对每个块 c i c_i ci,使用 LVLM 生成 M i M_i Mi 个查询-答案对:
Q i = { ( q 1 ( 1 ) , a 1 ( 1 ) ) , ... , ( q i ( M i ) , a i ( M i ) ) } , M i ≤ M m a x Q_{i} = \left\{(q_{1}^{(1)},a_{1}^{(1)}),\ldots ,(q_{i}^{(M_{i})},a_{i}^{(M_{i})})\right\} , \quad M_{i} \leq M_{\mathrm{max}} Qi={(q1(1),a1(1)),...,(qi(Mi),ai(Mi))},Mi≤Mmax
使用文本编码器 ϕ \phi ϕ 获得向量表示:
v i ( j ) = ϕ ( q i ( j ) ; a i ( j ) ) ∈ R d \mathbf{v}_{i}^{(j)} = \phi \left(q_{i}\^{(j)};a_{i}\^{(j)}\right) \in \mathbb{R}^{d} vi(j)=ϕ(qi(j);ai(j))∈Rd - 图组装: 构建异构图 G = ( V , E ) \mathcal{G} = (\mathcal{V}, \mathcal{E}) G=(V,E)。
- C-Q 边: 查询指向其来源块。
- Q-Q 边: 连接语义相似度前 k k k 个最近邻查询:
s i m ( q , q ′ ) = ⟨ ϕ ( q ; a ) , ϕ ( q ′ ; a ′ ) ⟩ + ϵ \mathrm{sim}(q,q^{\prime}) = \langle \phi (q;a),\phi (q\^{\\prime};a\^{\\prime})\rangle +\epsilon sim(q,q′)=⟨ϕ(q;a),ϕ(q′;a′)⟩+ϵ
- 存储: 向量存入向量数据库(如 FAISS),图结构存入图数据库(如 Neo4j)。
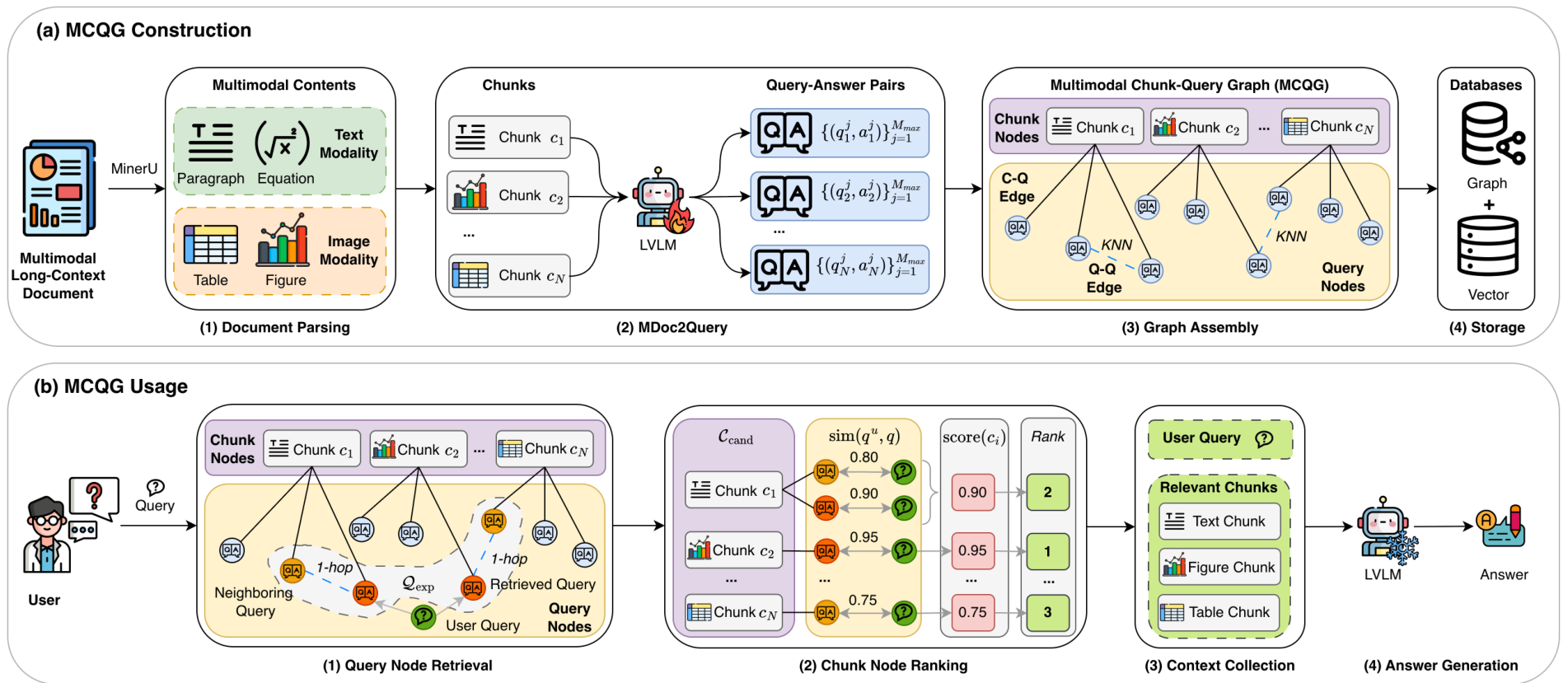
图 2:MLDocRAG 框架概览,包含 (a) MCQG 构建和 (b) MCQG 使用。
3.4 MCQG 使用
- 查询节点检索: 计算用户查询 q u q^{u} qu 的嵌入,检索前 n n n 个相似生成查询 Q r e t Q_{\mathrm{ret}} Qret。通过 h h h 跳邻居扩展获得 Q e x p Q_{\mathrm{exp}} Qexp:
Q e x p = Q r e t ∪ ⋃ q ∈ Q r e t N b r h ( q ) Q_{\mathrm{exp}} = Q_{\mathrm{ret}} \cup \bigcup_{q \in Q_{\mathrm{ret}}} \mathrm{Nbr}_h(q) Qexp=Qret∪q∈Qret⋃Nbrh(q) - 块节点排名: 收集与 Q e x p Q_{\mathrm{exp}} Qexp 相关的所有块 C c o n d C_{\mathrm{cond}} Ccond,并根据最大语义相似度评分:
s c o r e ( c i ) = max q ∈ Q e x p , ( q , c i ) ∈ E s i m ( q u , q ) \mathrm{score}(c_i) = \max_{q \in Q_{\mathrm{exp}}, (q,c_i) \in \mathcal{E}} \mathrm{sim}(q^u,q) score(ci)=q∈Qexp,(q,ci)∈Emaxsim(qu,q) - 上下文收集: 选择评分最高的 K K K 个块 C r e l C_{\mathrm{rel}} Crel。
- 答案生成:
a ^ = L V L M ( q u , C r e l ) \hat{a} = \mathrm{LVLM}(q^u, C_{\mathrm{rel}}) a^=LVLM(qu,Crel)
3.5 MDoc2Query 优化
- 非参数化优化: 采用"页面上下文感知生成",在为块生成查询时输入当前页面的渲染图,以消除局部信息的歧义。
- 参数化优化: 在高质量的多模态块-查询对数据集上微调 LVLM,使其生成的查询更精确。
4 实验设置 (Experimental Setup)
4.1 数据集与指标
- 数据集: MMLongBench-Doc(PDF 格式,包含文本/图表)和 LongDocURL(网页科学技术文档)。
- 指标: 使用 准确率 (Accuracy) 作为主要指标,并采用 LLM-as-a-judge(如 Qwen2.5-72B)协议来验证答案。
4.2 基线方法
对比了五类基线:
- 纯文本 (txt): 仅使用文本块。
- 图像转文本 (txt+it2): 将生成的图像描述融入文本。
- 多模态 (txt+img): 使用多模态编码器(CLIP/SigLIP/ColPali)检索。
- 页面级 (page): 将整页渲染为图像进行检索。
- 图 (Graph): 构建基于实体的知识图谱。
此外,本文还针对 MCQG 的节点变体(查询 vs 答案)、排名策略(Max vs Mean)、视觉噪声过滤以及超参数(跳数 h h h、 k k k 值、最大节点数 n n n)进行了消融实验。
4.3 设置细节
文档解析设置。多模态长文本分析使用 MinerU 40 进行解析,该工具能够将 PDF 中的布局有序元素提取为结构化的 JSON 文件。分块(Chunks)构建规则如下:(1)文本:段落分割采用最大 1200 个 token 的长度,重叠部分为 100 个 token。解析为 Markdown 的公式被视为常规文本。(2)图像:插图和表格及其标题(Caption)和 OCR 提取的内容被视为独立的图像模态块。此外,文档页面被渲染为图像,用于页面级方法和 MDoc2Query 优化。我们还通过 CLIP 进行零样本分类,对图像块应用视觉噪声过滤,详见附录 B。
模型配置。我们采用 BGE-m3 编码器为查询生成密集向量嵌入,并将其存储在 ElasticSearch 22 中作为核心向量数据库,以支持高效的相似度检索。对于查询生成和最终答案生成,默认使用 Qwen2.5-V-L-32B 4,而 MDoc2Query 优化则采用 Qwen2.5-V-L-7B 4。评估方面,采用 LLM-as-a-Judge 设置,使用 Qwen2.5-72B 36, 45。所有 LLM/LVLM 均通过 SGLang 51 框架部署在 NVIDIA H20 GPU 上,以实现高吞吐量推理。
默认超参数 。在 MMLongBenchDoc 和 LongDocURL 的实验中,我们采用统一的默认超参数设置。具体而言:查询-查询边构建的 KNN 邻居大小设为 k = 3 k = 3 k=3;检索最多 n = 10 n = 10 n=10 个查询节点,相似度阈值设为 α = 1.2 \alpha = 1.2 α=1.2;并执行 h = 2 h = 2 h=2 跳(hop)的查询扩展。在答案生成阶段,选择排名最靠前的 K = 5 K = 5 K=5 个多模态块作为检索上下文。
5 实验结果
在本节中,我们针对第 4 节提出的四个研究问题分析实验结果,以衡量 MLDocRAG 的有效性。
5.1 MLDocRAG 与基准方法的对比 (RQ1)
表 1 报告了 MLDocRAG 和代表性基准方法在 MMLongBench-Doc 和 LongDocURL 上的准确率(%)。总体而言,MLDocRAG 在两个数据集上均取得了最佳性能,在 MMLongBenchDoc 上的准确率为 47.9 % 47.9\% 47.9%,在 LongDocURL 上的准确率为 50.8 % 50.8\% 50.8%,一致优于所有基准方法。
特别地,与纯文本和图像转文本(image-to-text)基准相比,MLDocRAG 得益于对多模态证据的显式建模,而没有将视觉信息瓦解为扁平的文本描述,从而保留了对布局、图表和插图中心型问题至关重要的细粒度视觉语义。与独立检索文本和图像块的多模态密集检索方法相比,MLDocRAG 围绕生成的、可回答的查询组织多模态内容,并执行以查询为中心的多跳扩展,从而能够有效聚合散落在不同页面中语义相关的证据。这种优势在多页场景下尤为明显,因为简单的块级检索或页面级视觉推理往往无法捕捉长距离依赖。此外,与基于文本图谱的基准相比,MLDocRAG 通过多模态块-查询图(Multimodal Chunk-Query Graph)显式建模跨模态关联。
关于图遍历的性能表现:当 h = 3 h = 3 h=3 时性能有所下降,表明过度的扩展会引入语义噪声,其负面影响超过了额外上下文带来的收益。(2)KNN 邻居数 ( k k k):准确率通常随着最近邻数量的增加而提高,在 k = 3 k = 3 k=3 左右达到峰值。这表明适度的图密度能有效弥合查询间的语义鸿沟,而过密的连接会产生边际收益递减或引入噪声。(3)最大节点数 ( n n n):性能在 n = 10 n = 10 n=10 时达到最优。检索节点过少( n = 5 n = 5 n=5)会限制证据覆盖范围,而过多( n > 10 n > 10 n>10)则会引入无关信息,导致性能显著下降。此外,较严格的相似度阈值( α = 1.2 \alpha = 1.2 α=1.2)始终优于较宽松的阈值( α = 1.0 \alpha = 1.0 α=1.0),强调了优先考虑高质量入口节点而非数量的重要性。
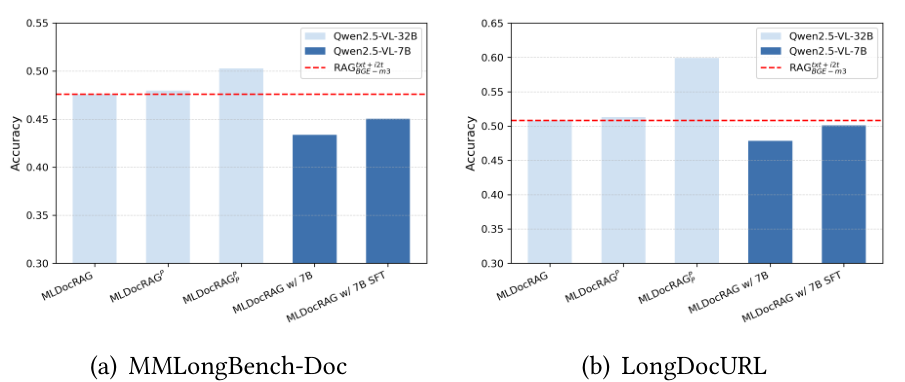
图 6:MDoc2Query 优化的消融实验。
5.4 MDoc2Query 优化的影响 (RQ4)
图 6 展示了 MDoc2Query 的非参数化和参数化优化策略对 MLDocRAG 性能的影响。(1)非参数化优化 :在查询生成过程中为每个数据块提供相应的页面图像能持续提升性能。具体而言,MLDocRAG P _P P 在两个数据集上均优于仅使用数据块的 MLDocRAG,证明引入页面级上下文可以通过缓解孤立数据块造成的语义碎片化来提高查询质量。附录 C 中提供了使用和不使用页面上下文生成的 MDoc2Query 代表性示例。此外,MLDocRAG P _P P 在查询生成和答案生成阶段均整合了页面级信息,实现了最佳的整体性能。这一结果证实,在检索索引和问答阶段全程提供参考页面上下文可以最大化证据利用率。(2)参数化优化 :MLDocRAG 在使用较小的 LVLM 部署时依然有效。虽然 32B 模型性能最强,但经过有监督微调(SFT)的 7B 模型(MLDocRAG w/ 7B SFT)在 LongDocURL 上达到了 50.1 % 50.1\% 50.1% 的准确率,非常接近 32B 基准( 50.8 % 50.8\% 50.8%)。这些结果表明,MLDocRAG 可以通过参数化优化高效适配资源受限的模型。
5.5 使用案例
图 7 展示了来自 MMLongBenchDoc 的一个代表性案例,该案例需要跨越遥远的科学图表(第 3 页和第 14 页)进行多模态推理。与 R A G B G E − m 3 t x t + i t 2 RAG_{BGE-m3}^{txt+it2} RAGBGE−m3txt+it2 和 V R A G C o l P a l i p a g e VRAG_{ColPali}^{page} VRAGColPalipage 等无法桥接长上下文差距的基准方法不同,MLDocRAG 成功检索到了分散的证据并执行了所需的多跳推理。
# 问答示例
问题 :图 1 中的哪一步映射到了图 10 的内容?
证据页面 :3, 14
标准答案:遗传物质的缺失/重复/重排(Deletion/duplication/rearrangement of the genetic material)以及遗传疾病。
R A G B G E − m 3 t x t + i t 2 RAG_{BGE-m3}^{txt+it2} RAGBGE−m3txt+it2 回答 :
问题询问图 1(遗传疾病的发病机制)中的哪一步映射到图 10 的内容。然而,提供的上下文不包含有关图 10 的任何信息。由于给定文本中未描述图 10 的内容,因此无法确定图 1 中的哪一步与其对应。
最终答案:我不知道。
V R A G C o l P a l i p a g e VRAG_{ColPali}^{page} VRAGColPalipage 回答 :
问题询问图 1 中的哪一步映射到图 10 的内容。然而,提供的图像和文本中既不包含图 1 也不包含图 10。没有这些图表,无法确定它们之间的映射关系。
最终答案:我不知道。
MLDocRAG 回答 :
为了确定图 1 中的哪一步映射到图 10 的内容,让我们逐步分析这两个图表。
图 1:遗传疾病的发病机制。
图 1 概述了导致遗传疾病的一系列事件:
(1) 突变 (2) 遗传物质的缺失/重复/重排 (3) mRNA 转录缺失/缺陷 (4) mRNA 转录后修饰缺失/缺陷 (5) mRNA 翻译缺失/缺陷 (6) 蛋白质/调节因子生成缺失/缺陷 (7) 蛋白质翻译后修饰缺失/缺陷 (8) 代谢网络功能紊乱 (9) 细胞功能病理生理改变 (10) 遗传疾病。
图 10:基因组结构和功能突变的病理后果。
图 10 插图说明了基因组印迹缺陷和染色体异常的后果,具体包括:
- 导致遗传物质改变的结构和数量染色体突变。
- 显示了由此产生的表型(例如:正常合子、雌核发育体和雄核发育体)。
内容映射:
图 10 侧重于结构和数量染色体突变的后果,这直接对应于图 1 中的第二步:遗传物质的缺失/重复/重排。图 10 中显示的表型是这些染色体突变的下游效应,与图 1 概述的发病机制一致。
最终答案:遗传物质的缺失 / 重复 / 重排。
MLDocRAG 精确地将第 14 页"图 10"中视觉呈现的"染色体突变"与第 3 页"图 1"中相应的"缺失/重复/重排"阶段对齐,证明了其在细粒度信息提取和跨页视觉对齐方面的卓越能力。更多用例见附录 D。
6 结论
我们提出了 MLDocRAG,这是一个基于多模态块-查询图(MCQG)的多模态长文档问答框架,实现了统一的、以查询为中心的检索。通过 MDoc2Query 将文档扩展延伸至多模态设置,MCQG 将异构数据块及其生成的查询组织成结构化图表,捕捉跨模态和跨页面的关联。这种以查询为中心的表示支持选择性多跳检索和基于语义的证据聚合,在 MMLongBench-Doc 和 LongDocURL 上取得了一致的性能提升。我们的结果证明了基于查询的多模态检索的有效性,以及图结构组织在多模态长文本理解中的可扩展性。
7 局限性
尽管 MLDocRAG 取得了可喜的成果,但仍存在一些局限性。首先,目前仅支持文本和图像,限制了对视频或音频等更丰富模态的泛化。其次,其有效性取决于生成查询的质量------噪声或不完整的查询可能会降低检索准确率。最后,构建大型多模态图的计算成本可能很高,这对扩展到海量文档库提出了挑战。
Original Abstract: Understanding multimodal long-context documents that comprise multimodal chunks such as paragraphs, figures, and tables is challenging due to (1) cross-modal heterogeneity to localize relevant information across modalities, (2) cross-page reasoning to aggregate dispersed evidence across pages. To address these challenges, we are motivated to adopt a query-centric formulation that projects cross-modal and cross-page information into a unified query representation space, with queries acting as abstract semantic surrogates for heterogeneous multimodal content. In this paper, we propose a Multimodal Long-Context Document Retrieval Augmented Generation (MLDocRAG) framework that leverages a Multimodal Chunk-Query Graph (MCQG) to organize multimodal document content around semantically rich, answerable queries. MCQG is constructed via a multimodal document expansion process that generates fine-grained queries from heterogeneous document chunks and links them to their corresponding content across modalities and pages. This graph-based structure enables selective, query-centric retrieval and structured evidence aggregation, thereby enhancing grounding and coherence in long-context multimodal question answering. Experiments on datasets MMLongBench-Doc and LongDocURL demonstrate that MLDocRAG consistently improves retrieval quality and answer accuracy, demonstrating its effectiveness for long-context multimodal understanding.
PDF Link: 2602.10271v1
部分平台可能图片显示异常,请以我的博客内容为准
