torch前置知识
max,sort和topk操作:返回一个元组(values,indices)
- 对于数组特定维度进行求和或排序
- 返回一个元组
(values,indices)
python
sorted_probs, sorted_indices = torch.sort(probs,descending=True,dim=-1)- TOPK函数
python
logits_topk,indices_topk = torch.topk(logits,top_k,dim=-1) mean和median:只返回数值
前缀和函数torch.cumsum
python
`cum_probs = torch.cumsum(sorted_probs,dim=-1)`*指定下标填充指定元素torch.scatter()
- 指定下标:
sorted_indices - 指定元素:
indices_to_remove - 维度必须一一匹配
python
indices_to_remove_origin.scatter_(dim=-1,index=sorted_indices,src=indices_to_remove)获得指定下标的元素torch.gather
index=targets.unsqueeze(-1):维度必须与目标变量logits匹配
python
target_logits = torch.gather(logits,dim=-1,index=targets.unsqueeze(-1))model.train() vs model.eval()
- 控制模型中特定层的行为
- 主要控制BN/LN层,控制Dropout层是否开启
常见错误:model.train()一定要放在循环内,model.eval()需要放在评估和推理时开启。
LM的推理流程
基本流程:滑动窗口(max_win_size=max_seq_len)
- LM的输入: x 1 , x 2 ⋯ , x n x_1,x_2\\cdots,x_n x1,x2⋯,xn
- LM的输出: x 2 , x 3 ⋯ , x n + 1 x_2,x_3\\cdots,x_{n+1} x2,x3⋯,xn+1
- 给定 x 1 , x 2 ⋯ , x n x_1,x_2\\cdots,x_n x1,x2⋯,xn,我们希望得到的是 x n + 1 x_{n+1} xn+1。
- 为此,我们调用LM模型推理,得到 x 2 , x 3 ⋯ , x n + 1 x_2,x_3\\cdots,x_{n+1} x2,x3⋯,xn+1
- 将 x n + 1 x_{n+1} xn+1拼接到 x 1 , x 2 ⋯ , x n x_1,x_2\\cdots,x_n x1,x2⋯,xn中去 ,得到序列 x 1 , x 2 ⋯ , x n , x n + 1 x_1,x_2\\cdots,x_n,x_{n+1} x1,x2⋯,xn,xn+1,我们通过滑动窗口的形式再下一次输入时,截取 x 2 ⋯ , x n , x n + 1 x_2\\cdots,x_n,x_{n+1} x2⋯,xn,xn+1这一部分作为输入。
python
for _ in range(max_new_tokens):
x = generated_sequence[...,-self.max_seq_len:]
logits = self.forward(x)
logits = logits[:,-1,:]# [b,vocab_size]
# 从logits中采样得到next_token
next_token = sample_token(logits)
generated_sequence = torch.cat([generated_sequence,next_token],dim=-1)从logits中采样得到next_token的方法
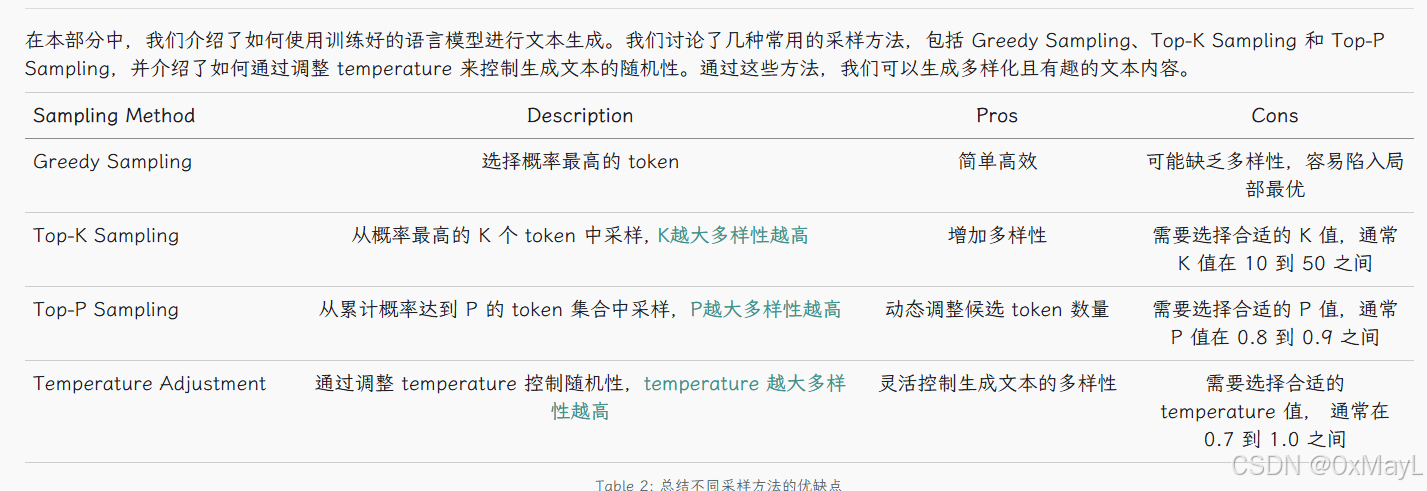
- 常见策略
- 贪心 vs topk vs topp
- 温度策略兼容
实现时的注意事项
- 不需要梯度加速计算:
@torch.no_grad() - 排序等操作会破坏数组下标,因此需要使用
scatter_等操作对原数组填充。
温度系数Temperature T T T
- 为softmax的结果除以一个常数 T T T
如果 T T T趋于+无穷,那么模型就会趋于均匀采样;如果 T T T趋于0,模型会趋于贪心策略
温度系数兼容所有采样策略 ,T = 0 T=0 T=0会使模型随机性降低!
s o f t m a x i ( z ; T ) = exp ( z i T ) ∑ j exp ( z j T ) \mathrm{softmax}_i(\mathbf{z};T)=\frac{\exp\left(\frac{z_i}{T}\right)}{\sum_j\exp\left(\frac{z_j}{T}\right)} softmaxi(z;T)=∑jexp(Tzj)exp(Tzi)
贪心
- 直接取最大概率的token
- 但它可能会导致生成的文本缺乏多样性和创造性,因为它总是选择最可能的选项,容易陷入局部最优
python
x = generated_sequence[...,-self.max_seq_len:]
logits = self.forward(x)
logits = logits[:,-1,:]# [b,vocab_size]
next_token = torch.argmax(logits,dim=-1,keepdim=True) # b 1topk采样
模型会选择概率最高的 K 个 token,然后从这 K 个 token 中根据它们的概率分布进行采样。这样可以增加生成文本的多样性,同时仍然保持一定的质量
- 从所有logits中挑选前k个,然后进行采样
- 使用topk可以得到下标和对应值,然后使用该下标进行散播对应值就行了。
python
# top-k
@torch.no_grad()
def _generate_topk(
self,
inputs_id:torch.LongTensor,
max_new_tokens:int,# max_new_tokens!=max_seq_len
eos_token_id:int,
top_k :int,
temperature:float = 1.0,
)->str:
self.eval()
generated_sequence = inputs_id.clone()# [b,l]
for _ in range(max_new_tokens):
x = generated_sequence[...,-self.max_seq_len:]
logits = self.forward(x)
logits = logits[:,-1,:]# [b,vocab_size]
# temperature sampling
logits = logits / temperature
# top-k
logits_topk,indices_topk = torch.topk(logits,top_k,dim=-1)
# 根据下标和元素填充新logits
filtered_logits = torch.full_like(logits, float("-inf"))# b v
filtered_logits.scatter_(dim=-1, index=indices_topk, src=logits_topk)# b v
filtered_probs = softmax(filtered_logits,dim=-1)
next_token = torch.multinomial(filtered_probs,num_samples=1)
# 自回归
generated_sequence = torch.cat([generated_sequence,next_token],dim=-1)
if (next_token == eos_token_id).all():
break
if self.tokenizer is not None:
return self.tokenizer.decode(generated_sequence.squeeze(0).tolist())
return generated_sequencetopp
Top-P Sampling(也称为 Nucleus Sampling)是一种更灵活的采样方法。在每一步生成时,模型会选择累计概率达到 P 的最小 token 集合,然后从这个集合中根据它们的概率分布进行采样。这样可以动态调整候选 token 的数量,既保证了多样性,又避免了选择过于罕见的 token。
- 和topk采样类似,不过基本思路不是选前k个。
- 先计算概率,对概率进行排序 ,只采样累积概率小于等于p的token。
- 实现细节:自己定义掩膜
python
@torch.no_grad()
def _generate_topp(
self,
inputs_id:torch.LongTensor,
max_new_tokens:int,# max_new_tokens!=max_seq_len
eos_token_id:int,
top_p :float,
temperature:float = 1.0,
):
# topp: 排序-累积概率-mask-过滤-采样
self.eval()
generated_sequence = inputs_id.clone()# [b,l]
for _ in range(max_new_tokens):
x = generated_sequence[...,-self.max_seq_len:]
logits = self.forward(x)
logits = logits[:,-1,:]# [b,vocab_size]
# temperature sampling
logits = logits / temperature
probs = softmax(logits,dim=-1)
# sort
sorted_probs, sorted_indices = torch.sort(probs,descending=True,dim=-1)
# cdf
cum_probs = torch.cumsum(sorted_probs,dim=-1)
# mask-value
indices_to_remove = cum_probs > top_p
indices_to_remove[...,1:] = indices_to_remove[...,:-1].clone()
indices_to_remove[...,0] = False
# filter
indices_to_remove_origin = torch.zeros_like(logits,dtype=torch.bool)
indices_to_remove_origin.scatter_(dim=-1,index=sorted_indices,src=indices_to_remove)
filtered_logits = logits.masked_fill(indices_to_remove_origin,float("-inf"))
filtered_probs = softmax(filtered_logits,dim=-1)
next_token = torch.multinomial(filtered_probs,num_samples=1)
# 自回归
generated_sequence = torch.cat([generated_sequence,next_token],dim=-1)
if (next_token == eos_token_id).all():# next_token:b 1
break
if self.tokenizer is not None:
return self.tokenizer.decode(generated_sequence.squeeze(0).tolist())
return generated_sequence训练函数
确定动态学习率->optimizer.zero_grad(set_to_none=True)->output = model(x)->train_loss = cross_entropy_loss(output,y)->train_loss.backward()->梯度裁剪->optimizer.step()
python
def train(args):
# load data, model and optimizer
train_data = np.memmap(args.train_data_path,dtype=np.uint16,mode='r')
valid_data = np.memmap(args.val_data_path,dtype=np.uint16,mode='r')
model = TransformerLM(
vocab_size = args.vocab_size,
n_layers = args.num_layers,
d_model = args.d_model,
num_heads = args.num_heads,
d_ff = args.d_ff,
bigo = args.bigo,
max_seq_len=args.max_seq_len,
is_norm = args.is_norm,# ablation parameters
norm_type = args.norm_type,
pre_norm = args.pre_norm,
is_gate = args.is_gate,
eps = args.eps,
device = args.device,
dtype = torch.float32,
tokenizer = tokenizer,
).to(args.device)
optimizer = AdamW(model.parameters(),lr=args.max_lr)
for it in range(start_iter,args.max_iters):
model.train()
# dynamic learning rate
lr = get_lr_cosine_schedule_with_warmup(it,args.max_lr,args.min_lr,args.warmup_iters,args.cosine_schedule_iters)
for group in optimizer.param_groups:
group['lr'] = lr
x, y = get_batch(train_data,args.batch_size,args.max_seq_len,args.device)
optimizer.zero_grad(set_to_none=True)
output = model(x)
train_loss = cross_entropy_loss(output,y)
train_loss.backward()
with torch.no_grad():# 不需要梯度,加速处理
train_ppl = ppl(output,y)
# gradient clipping
clip_grad_norm(model.parameters(),args.max_norm,args.eps)
optimizer.step()
if it % args.eval_interval == 0 or it == args.max_iters - 1:
model.eval()
with torch.no_grad():
x_val, y_val = get_batch(valid_data,args.batch_size,args.max_seq_len,args.device)
output_val = model(x_val)
# 评估指标
val_loss = cross_entropy_loss(output_val,y_val)
val_ppl = ppl(output_val,y_val)