-
TCP/IP 大端 = 网络字节序 = htonl/htons
-
CAN DBC 大端 = Motorola 格式(CANoe/CANdb++ 里的 MSB)
一个字节内部的 bit 是固定的
任何一个字节,硬件上永远是:
plaintext
markdown
bit7 bit6 bit5 bit4 bit3 bit2 bit1 bit0
最高位 最低位这个 bit7~bit0 的顺序,永远不会变 。不管你用大端、小端、网络序、DBC,单个字节内部的 bit 编号永远固定。
① TCP 大端(网络字节序)
- 只管字节序 ,不管位序
- 字节:高字节在前,低字节在后
- 位序:每个字节内部,位序不变
复习:
以 32 位整数 0x12345678 为例:
它在内存里(小端 CPU,比如 ARM/x86)是:
plaintext
低地址 → 高地址
0x78 0x56 0x34 0x12用 htonl 转成 TCP 大端(网络序) 后:
plaintext
0x12 0x34 0x56 0x78例:0x12345678TCP 大端传输:12 34 56 78
② DBC 大端(Motorola)
既管字节序,又管位序,是 "整段信号按位从高往低排"
规则:
- 信号的最高位(MSB)放在 CAN 报文的最高地址位
- 跨字节时,字节是大端顺序(高字节→低字节)
- 字节内部位也是大端位序(bit7→bit0)
DBC 信号解析必须:
- 按 start_bit、length、byte_order=Motorola 逐位抽取
- DBC 的 start_bit 不是从 Byte0 开始算,而是从 Byte7.bit7 开始算。
- DBC Motorola 的信号,是从「你指定的 start_bit」开始,往「更小的数字」方向,连续占 N 个 bit。
所谓的跨字节理解,取决于信号的长度
用一个 32bit 信号,给你看什么叫「跨字节」
我们定义一个信号:
- Motorola 大端
- start_bit = 63(就是 Byte7.bit7)
- length = 32 bit
它占的 bit 是:
63 → 62 → 61 → ... → 32一共 32 个 bit
对应到字节:
- 63~56 → Byte7
- 55~48 → Byte6
- 47~40 → Byte5
- 39~32 → Byte4
信号横跨:
Byte7、Byte6、Byte5、Byte4 这就是我之前说的:一个信号横跨 4 个字节。
看需求:
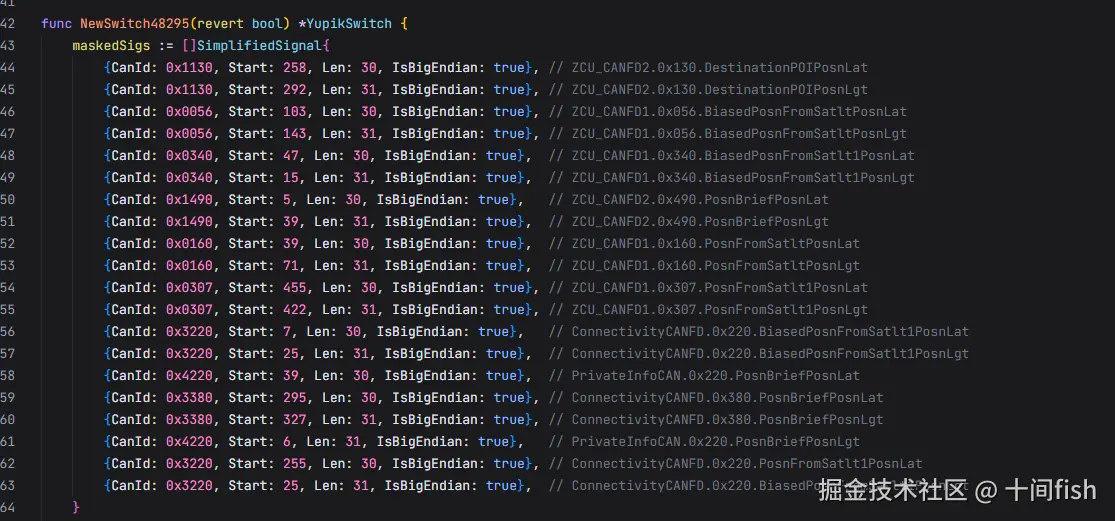
一、需求描述:(3.0)
1)位置信息共享软开关关闭状态下,位置信息相关信号上传赋值0处理;
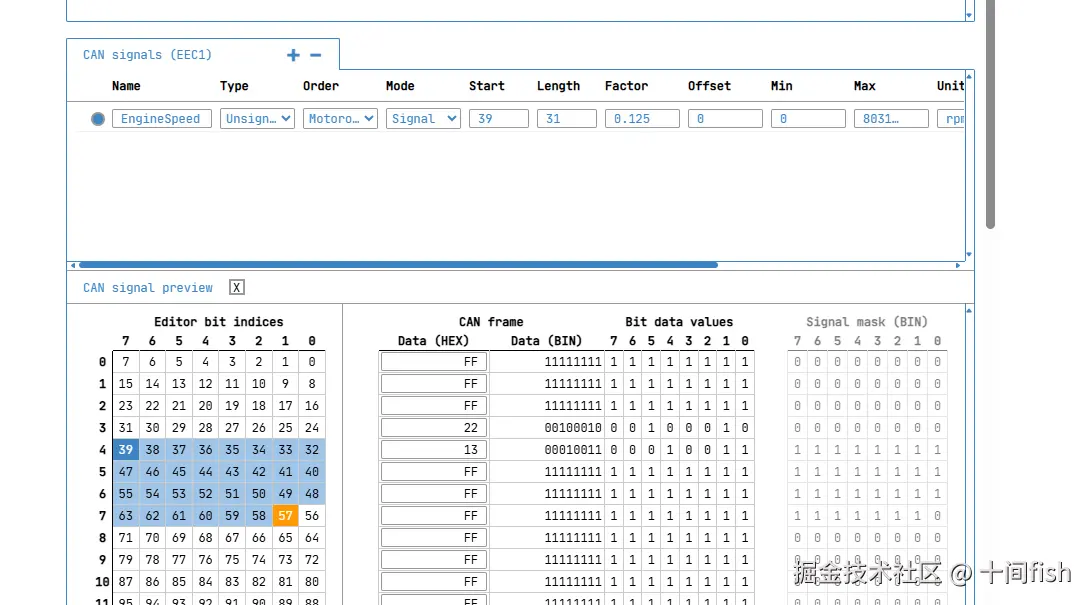
工具:DBC Editor for CAN Bus Database Files Online \| 100% Free -- CSS Electronics
2.2 MCU打包协议数据格式关键解析点
(1)整体数据格式
| 帧头(2Byte) | Payload数据长度(2Byte) | Counter(1Byte) | CRC(1Byte) | Payload(可变长度) |
|---|---|---|---|---|
| 0x514D | 包含 N 帧子数据 |
(2)Payload 中的单帧子数据格式(确认.=》报文类型&帧ID作为整体处理)
| 起始标识(1Byte) | 报文类型 + 帧 ID(2Byte) | Updatebit + 帧长度(1Byte) | 帧数据(8-64Byte) |
|---|---|---|---|
| 0x55(有效帧) | 高 4 位 = 报文类型(如 0x00=ZCU_CANFD1)低 12 位 = CanId | 最高位 = Updatebit低 7 位 = 帧数据长度 |
arduino
bool PositionSignalProcessor::clearBitsDBCBigEndian(uint8_t* data, int data_len, uint32_t start, uint32_t length) {
if (data == nullptr || data_len <= 0 || length == 0) {
debugPrint("clearBitsDBCBigEndian: (data=%p, data_len=%d, start=%d, length=%d)\n",
data, data_len, start, length);
return false;
}
// DBC大端字节序:按字节顺序,非连续位
int startByte = start / 8;
int bitsInStartByte = start % 8 + 1;
int bitsLeft = length - bitsInStartByte;
// 边界检查
if (startByte >= data_len) {
debugPrint("frame boundary: startByte=%d >= data_len=%d\n", startByte, data_len);
return false;
}
// 保存原始数据用于调试
std::vector<uint8_t> originalData;
if (m_debug) {
originalData.assign(data, data + data_len);
}
// 如果有多于一个字节的位需要处理
if (bitsLeft > 0) {
// 清除第一个字节的高位
unsigned char mask = 0xFF << bitsInStartByte;
data[startByte] &= mask;
// 清除所有中间字节
int middleByte = startByte + (bitsLeft) / 8;
for (int i = startByte + 1; i <= middleByte; ++i) {
data[i] = 0;
}
// 处理最后一个字节的低位
int lastByteBitsLeft = bitsLeft % 8;
if (lastByteBitsLeft > 0) {
/*
-1:将 1 << n 生成的「1 后跟 n 个 0」的数,转为「n 个 1」的二进制数
可以想象成「最右侧 N 个格子为 1,其余为 0」的遮挡板
掩码为 1 的格子保留原值,掩码为 0 的格子清零
*/
mask = (1 << (8 - lastByteBitsLeft)) - 1;
data[middleByte + 1] &= mask;
}
} else {
// 单字节情况
int startBit = bitsInStartByte - length;
/*
注意:单字节和上面的最后一个字节的处理不一样
上面的处理只适用于:不管清零位在哪个位置,都只把「最右侧 N 个格子」设为 1
而一旦清零位是字节中间位,就不适用。用下面数据可验证:
9A 03 BB 64 1A 0A 67 28
2.start = 36,len = 3 => 结果是 9A 03 BB 64 02 0A 67 28
*/
unsigned char mask = ((1 << length) - 1) << startBit;
data[startByte] &= ~mask;
}
// 调试输出
if (m_debug) {
debugPrint("clearBitsDBCBigEndian: 处理前数据 (start=%d, length=%d): \n", start, length);
for (int i = 0; i < data_len; ++i) {
debugPrint("%02X ", originalData[i]);
}
debugPrint("\n");
debugPrint("clearBitsDBCBigEndian: 处理后数据: \n");
for (int i = 0; i < data_len; ++i) {
debugPrint("%02X ", data[i]);
}
debugPrint("\n");
}
return true;
}
bool PositionSignalProcessor::clearBitsIntelLittleEndian(uint8_t* data, int data_len, uint32_t start, uint32_t length) {
if (data == nullptr || data_len <= 0 || length == 0) {
debugPrint("clearBitsIntelLittleEndian: (data=%p, data_len=%d, start=%u, length=%u)\n",
data, data_len, start, length);
return false;
}
// 小端边界检查
if (start - length + 1 < 0) {
debugPrint("clearBitsIntelLittleEndian: frame boundary: start=%u, length=%u, start-length+1 < 0\n", start, length);
return false;
}
int downByte = static_cast<uint32_t>(data_len) - 1 - start / 8;
if (downByte < 0) {
debugPrint("clearBitsIntelLittleEndian: frame boundary: downByte=%d >= data_len=%d\n", downByte, data_len);
return false;
}
int bitsInDownByte = 8 - start % 8;
int bitsLeft = length - bitsInDownByte;
if (bitsLeft > 0) {
debugPrint("clearBitsIntelLittleEndian: Multi byte case, start=%d, bitsInDownByte=%d, length=%d,bitsLeft=%d\n", start, bitsInDownByte, length,bitsLeft);
// 清除第一个字节的低位
unsigned char mask = static_cast<uint8_t>(0xFF >> bitsInDownByte);
data[downByte] &= mask;
// 清除中间字节
int middleByte = downByte - (bitsLeft) / 8;
for (int i = downByte - 1; i >= middleByte; --i) {
data[i] = 0;
}
// 处理最后一个字节的高位
int lastByteBitsLeft = bitsLeft % 8;
if (lastByteBitsLeft > 0) {
int lastByteIdx = middleByte - 1;
if (lastByteIdx >= 0) {
mask = static_cast<uint8_t>(0xFF << lastByteBitsLeft);
data[lastByteIdx] &= mask;
}else{
debugPrint("clearBitsIntelLittleEndian: frame boundary lastByteIdx=%d out of bounds\n", lastByteIdx);
return false;
}
}
} else {
// 单字节情况
debugPrint("clearBitsIntelLittleEndian: Single byte case, start=%d, bitsInDownByte=%d, length=%d,bitsLeft=%d\n", start, bitsInDownByte, length,bitsLeft);
int leftBit = 9 - start % 8 - length;
unsigned char mask = static_cast<uint8_t>(((1 << length) - 1) << leftBit);
data[downByte] &= ~mask;
}
return true;
}